En términos generales, la relación entre las redes neuronales y los big data es muy compleja y los factores que influyen incluyen: el tamaño del modelo, el tamaño del conjunto de datos, el rendimiento informático y otros factores, como la mano de obra, el tiempo, etc. El siguiente es un resumen del contenido existente:
1. Volumen de datos versus rendimiento de la red
1. Información general
En "Revisiting Unreasonable Effectiveness of Data in Deep Learning Era", Sun y otros atribuyeron el éxito significativo de la tecnología de visión por computadora en los últimos 10 años a: 1> modelos más complejos, 2> mejoras en el rendimiento informático [Referencia 1 , Referencia 2 ], 3> La aparición de conjuntos de datos etiquetados a gran escala.
En respuesta a la primera pregunta, podemos ver mejoras en el rendimiento informático y la complejidad del modelo cada año, desde AlexNet de 7 capas en 2017 hasta ResNet de 101 capas en 2015, y ahora la tecnología Transformer con una mayor cantidad de parámetros.
Para la segunda pregunta, puede consultar 1 y 2. En general, los investigadores han descubierto que al actualizar la GPU cada año, la mejora del rendimiento obtenida al mejorar el rendimiento de la GPU es incluso mayor que la actualización del modelo en sí. La poderosa potencia informática que aporta la nueva GPU puede hacer que la inferencia de modelos sea más rápida y eficiente.
Con respecto a la tercera pregunta, todos sabemos que el aprendizaje profundo se basa en datos, por lo que si el conjunto de entrenamiento se expande 10 o 100 veces, ¿se duplicará la precisión? ¿Existe un cuello de botella? Lo siguiente se centra en este tema.
2. Objetivos de la investigación

El artículo señala que en los últimos años, el tamaño del modelo y el rendimiento de la GPU han mejorado, pero el conjunto de datos no, por lo que construyeron un conjunto de datos de 300 millones de imágenes para verificación experimental. Sus objetivos de investigación son:
1) Usando el algoritmo actual, si se proporcionan cada vez más imágenes con etiquetas ruidosas, aún se puede optimizar el rendimiento visual;
2) Para tareas de visión estándar como clasificación, detección de objetos y segmentación de imágenes, ¿cuál es la relación entre datos y rendimiento?
3) Utilizar tecnología de aprendizaje a gran escala para desarrollar modelos de última generación capaces de realizar diversas tareas en el campo de la visión por computadora.
3. Construcción de datos
El problema radica en cómo construir el conjunto de datos. Afortunadamente, Google ha estado trabajando arduamente para construir dichos conjuntos de datos para optimizar los algoritmos de visión por computadora. Con los esfuerzos de Geoff Hinton, Francois Chollet y otros, Google creó internamente un conjunto de datos que contenía 300 millones de imágenes, etiquetó las imágenes en 18291 categorías y lo llamó JFT-300M (no de código abierto).
El etiquetado de imágenes del conjunto de datos utiliza un algoritmo que combina complejas señales de red sin procesar con correlaciones entre páginas web y comentarios de los usuarios. A través de este método, estos 300 millones de imágenes recibieron más de mil millones de etiquetas (una imagen puede tener varias etiquetas). De estos mil millones de etiquetas, aproximadamente 375 millones se seleccionaron algorítmicamente para maximizar la precisión de las etiquetas para las imágenes seleccionadas. Sin embargo, todavía hay ruido en estas etiquetas: alrededor del 20% de las etiquetas de las imágenes seleccionadas son ruido. En pocas palabras, cuanto mayor es la cantidad de datos, mayor es el ruido y más difícil es entrenar el modelo.
4. Resultados experimentales básicos
El autor obtuvo algunos resultados mediante verificación experimental:
* Un mejor aprendizaje de la representación puede ayudar .
La primera observación que hacemos es que los datos a gran escala facilitan el aprendizaje de representación que optimiza el rendimiento en todas las tareas de visión que estudiamos. Nuestros hallazgos demuestran la importancia de crear conjuntos de datos a gran escala para el entrenamiento previo. Esto también muestra que el aprendizaje de representación no supervisado y los métodos de aprendizaje de representación semisupervisado tienen buenas perspectivas. Parece que el tamaño de los datos sigue suprimiendo el ruido presente en las etiquetas.
* A medida que aumenta la magnitud de los datos de entrenamiento, el rendimiento de la tarea aumenta logarítmicamente.
Quizás el hallazgo más sorprendente es la relación entre el desempeño de tareas visuales y el aprendizaje por desempeño en el logaritmo de la cantidad de datos de entrenamiento. Encontramos que la relación sigue siendo lineal. Incluso si el tamaño de la imagen de entrenamiento alcanza los 300 millones, no hemos observado ningún estancamiento en la mejora del rendimiento. Como se muestra abajo:

* La capacidad del modelo es crítica.
Observamos que si queremos utilizar plenamente el conjunto de datos de 300 millones de imágenes, necesitamos modelos más grandes (más profundos).
Por ejemplo, con ResNet-50, el aumento en la puntuación de detección de objetos COCO es muy limitado, solo 1,87%, mientras que con ResNet-152, este aumento en la puntuación alcanza el 3%.
* Entrenamiento de cola larga.
Nuestros datos tienen colas muy largas, pero el aprendizaje de representación parece funcionar. Esta larga cola no parece afectar negativamente al entrenamiento aleatorio de ConvNets (el entrenamiento seguirá convergendo).
* Nuevos resultados de última generación.
Nuestro artículo utiliza JFT-300M para entrenar el modelo y muchas puntuaciones han alcanzado el nivel más alto de la industria. Por ejemplo, para la puntuación de detección de objetos COCO, un solo modelo puede alcanzar actualmente 37,4 AP, frente a los 34,3 AP anteriores.
Cabe señalar que el sistema de capacitación, el progreso del aprendizaje y los parámetros que utilizamos se basan en la experiencia previa adquirida al entrenar ConvNets con imágenes ImageNet 1M.
Dado que no exploramos los hiperparámetros óptimos en este trabajo (lo que requeriría un esfuerzo computacional considerable), es posible que aún no hayamos logrado los mejores resultados posibles del entrenamiento con este conjunto de datos. Por lo tanto, creemos que los informes cuantitativos de desempeño pueden subestimar el impacto real en este conjunto de datos.
Este trabajo no se centró en datos específicos de la tarea, como estudiar si más cuadros delimitadores afectan el rendimiento del modelo. Creemos que a pesar de los desafíos, la obtención de conjuntos de datos a gran escala para tareas específicas debería ser el foco de futuras investigaciones.
Además, crear un conjunto de datos que contenga 300 millones de imágenes no es el objetivo final. Deberíamos explorar si el modelo puede seguir mejorando con un conjunto de datos más grande (más de mil millones de imágenes).
5. Otros resultados experimentales

* El ajuste fino de los pesos previos al entrenamiento es muy importante
2. Pesos previos al entrenamiento versus rendimiento
1. Información general
Los investigadores de Google publicaron un artículo llamado BigTransfer, "Big Transfer (BiT): aprendizaje de representación visual general" , que explora cómo utilizar eficazmente la escala de datos de imágenes súper convencional para entrenar previamente el modelo y realizar sistemáticamente el proceso de entrenamiento.
Para explorar el impacto de la escala de datos en el rendimiento del modelo, revisaron las configuraciones de preentrenamiento comúnmente utilizadas actualmente (incluidas funciones de activación y normalización de pesos, ancho y profundidad del modelo y estrategias de entrenamiento), mientras utilizaban tres escalas de datos diferentes. Los conjuntos incluyen: ILSVRC-2012 (1,28 millones de imágenes en 1.000 categorías), ImageNet-21k (14 millones de imágenes en 21.000 categorías) y JFT (300 millones de imágenes en 18.000 categorías). Más importante aún, los investigadores pueden explorar previamente basándose en estos datos. escalas de datos inexploradas.
2. Contenido de la investigación
* La relación entre el tamaño del conjunto de datos y la capacidad del modelo.
Los autores eligieron diferentes variantes de ResNet para el entrenamiento. Desde el tamaño estándar "R50x1" hasta el ancho x4, hasta el "R152x4" de 152 capas más profundo, todos fueron entrenados en el conjunto de datos anterior. Luego, los investigadores hicieron el descubrimiento clave de que si quieren aprovechar al máximo el big data, también deben aumentar la capacidad del modelo.

La mitad izquierda muestra la necesidad de expandir la capacidad del modelo a medida que aumenta la cantidad de datos. La expansión de la flecha roja significa que la arquitectura del modelo pequeño se deteriora bajo grandes conjuntos de datos, mientras que la arquitectura del modelo grande mejora. La figura de la derecha muestra que el entrenamiento previo en un gran conjunto de datos no necesariamente mejora, pero requiere un mayor tiempo de entrenamiento y sobrecarga computacional para aprovechar al máximo los big data.
El tiempo de formación también juega un papel fundamental en el rendimiento del modelo. Si no se realiza suficiente entrenamiento en un conjunto de datos a gran escala para ajustar la sobrecarga computacional, el rendimiento disminuirá significativamente (la mitad de los puntos rojos a los puntos azules en la figura anterior disminuyen), pero se puede obtener ajustando adecuadamente el tiempo de entrenamiento del modelo Mejoras significativas en el rendimiento.
* Una BN normalizada adecuada puede mejorar eficazmente el rendimiento
1> Reemplazar BN normalizado por lotes con GN normalizado por grupo puede mejorar efectivamente el rendimiento del modelo previamente entrenado en conjuntos de datos a gran escala. Las razones provienen principalmente de dos aspectos:
- Primero, el estado de BN debe ajustarse al migrar del entrenamiento previo a la tarea objetivo, pero GN no tiene estado, lo que evita la dificultad del ajuste;
- En segundo lugar, BN utiliza las estadísticas de cada lote, pero estas estadísticas se vuelven poco confiables para lotes pequeños en cada dispositivo, y el entrenamiento en múltiples dispositivos es inevitable para modelos grandes. Dado que GN no necesita calcular estadísticas para cada lote, una vez más evita este problema con éxito;
* Transferir aprendizaje
Basándose en los métodos utilizados en la construcción de BERT, los investigadores ajustaron el modelo BiT en una serie de tareas posteriores. Solo se utilizaron datos muy limitados en el proceso de ajuste. El modelo previamente entrenado ya tiene una buena comprensión de las características visuales.

Tamaño de datos, ILSVRC <ImageNet <JFT-300M. Al utilizar muy pocas muestras para realizar el aprendizaje por transferencia en BiT, los investigadores descubrieron que a medida que aumentaba la cantidad de datos y la capacidad de la arquitectura utilizada en el proceso de preentrenamiento, el modelo migrado resultante. también aumentó significativamente. Al aumentar la capacidad del modelo en el conjunto de datos más pequeño ILSVRC, las ganancias obtenidas al migrar CIFAR son menores tanto en el caso de 1 disparo como en el de 5 disparos (línea verde en la figura siguiente). Al realizar un entrenamiento previo en el conjunto de datos JFT a gran escala, el aumento en la capacidad del modelo traerá ganancias significativas (mostradas por la línea rojo-marrón). BiT-L puede alcanzar el 64% y el 95% en muestras individuales y cinco muestras. .
3. Conclusión
Este estudio encontró que bajo el entrenamiento de datos generales a gran escala, una estrategia de migración simple puede lograr resultados impresionantes, ya sea que se base en grandes datos, datos de muestras pequeñas o incluso datos de una sola muestra, a través de modelos pre-entrenados a gran escala en el proceso descendente. Las tareas pueden lograr mejoras significativas en el rendimiento. Los modelos previamente entrenados de BiT brindarán a los investigadores de la visión una nueva alternativa a los modelos previamente entrenados de ImageNet.
3. Dos excelentes respuestas de Zhihu
1. Ángulo 1
Se recomienda leer atentamente la Sección 3.2 del libro de texto clásico PRML (por supuesto, para comprender 3.2, primero debe leer el Capítulo 1), que explica en detalle qué sucederá cuando aumente la cantidad de datos . La conclusión central es la siguiente:
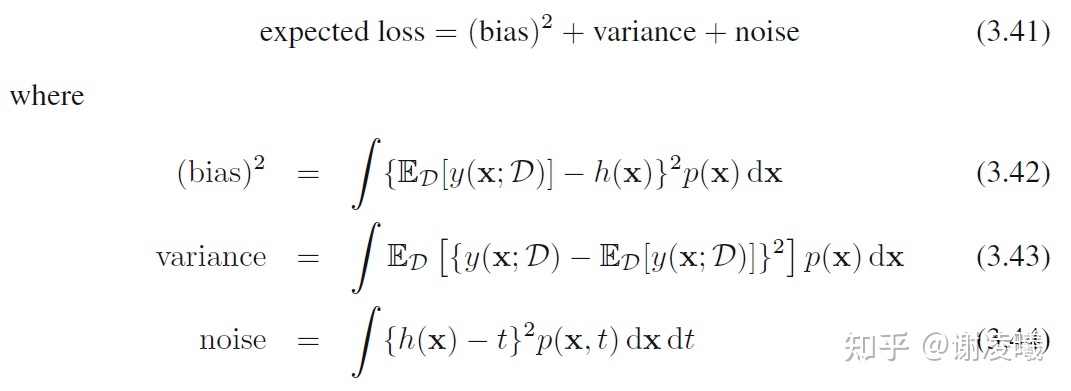
Cuando la cantidad de datos es fija, existe un equilibrio entre sesgo y varianza: cuando uno aumenta, el otro disminuye. A medida que aumenta la cantidad de datos, la suma de estos dos términos se puede reducir aún más, pero el término ruido no se puede eliminar.
Por tanto, este problema tiene las siguientes conclusiones simples y preliminares:
- Si la cantidad de datos es ilimitada y está anotada con precisión, entonces, en teoría, el modelo de aprendizaje automático puede ajustarse a una función perfecta, siempre que el modelo tenga suficiente complejidad y precisión. Por cierto, son posibles escenarios de datos infinitamente precisos, como el uso de un motor virtual para generar datos. En este momento, aunque un modelo no puede utilizar datos ilimitados en un tiempo limitado, a medida que avanza el entrenamiento, la cantidad de datos puede volverse infinita.
- Si la cantidad de datos es ilimitada pero no está etiquetada con precisión, la precisión del modelo final estará limitada por el ruido de la etiqueta.
- Si la cantidad de datos es limitada, entonces el modelo debe hacer un equilibrio entre sesgo y varianza: para que el modelo funcione de manera estable en una amplia gama de datos de prueba (la varianza es pequeña), la precisión de predicción general del modelo disminuirá. (el sesgo es grande); para hacer que el modelo funcione bien en algún subconjunto de datos de prueba (con un sesgo pequeño), el modelo debe sacrificar la precisión en otros posibles datos de prueba.
2. Ángulo 2
En particular, cuando se tienen suficientes datos de entrenamiento, es probable que el error de generalización sea muy pequeño. Esto se puede concluir de la teoría clásica del aprendizaje automático:
Si es un espacio finito y 0 <
< 1, entonces para cualquier
:
donde m representa el número de datos de entrenamiento. Cuando m tiende a infinito, es decir, hay suficientes muestras de entrenamiento, y la diferencia entre el clasificador aprendido y el clasificador ideal
se vuelve más pequeña a medida que pasa el tiempo. En la fórmula anterior, significa que la diferencia entre los dos es menor que uno, que es particularmente pequeña, la probabilidad del número es mayor que
, es decir, la probabilidad de que esto suceda es muy alta.
Una vez más, ¿se adaptará excesivamente dicha red? El sobreajuste es un tema importante en el campo del aprendizaje automático y está estrechamente relacionado con la estructura de su red, el método de capacitación, la dificultad de los datos, etc. Por ejemplo, si tiene una gran cantidad de datos, pero son casi iguales (la similitud entre los datos es alta), entonces la red en realidad no está adaptada correctamente, porque los datos en el mundo real son más complejos; desde otra perspectiva extrema , si Los datos no solo son grandes sino también diferentes, lo que, por supuesto, provocará un sobreajuste.
Finalmente, cuando la cantidad de datos es enorme, la red puede saturarse. Pero al igual que la pregunta anterior, todavía depende de la calidad de sus datos. Idealmente, si se utiliza una red para acomodar todos los datos conocidos del mundo, entonces, por supuesto, estará saturada.
Nota: En la teoría anterior se menciona que el espacio de hipótesis es limitado. Pero no podemos estar seguros de si el espacio de hipótesis es realmente limitado cuando hay muchos datos de entrenamiento, por lo que todavía no podemos responder a esta pregunta. Después de todo, el aprendizaje automático es una ciencia basada en datos.
4. Reflexiones personales:
Volumen de datos, ponderaciones de modelos previamente entrenados, calidad de los datos, capacidad de la red neuronal
Cuantos más datos, mejor será la predicción, pero cuando el tamaño de la muestra de entrenamiento es grande, si hay muy pocas capas de red y un entrenamiento de funciones insuficiente, se producirá un entrenamiento insuficiente. Por lo tanto, cuanto mayor sea el conjunto de datos, mejor será el efecto. Uno de los requisitos previos es que la capacidad de extracción de características de la red no puede ser demasiado pobre (problema de capacidad de la red neuronal).
Cuanto mayor sea la cantidad de datos, mayor será el requisito del tamaño de la muestra y es necesario mejorar la calidad de los datos, no puede contener demasiado ruido y datos similares, lo que tendrá un impacto negativo en el aprendizaje de la red.
Los pesos del modelo previamente entrenado en un gran conjunto de datos tienen buenos efectos de transferencia en otros conjuntos de datos.
referencia:
https://blog.csdn.net/emprere/article/details/98858910