Pruebas de estrés del rendimiento del sistema
1. Prueba de estrés
Las pruebas de estrés consisten en ejercer presión continua sobre el software, obligarlo a ejecutarse en condiciones extremas y observar hasta qué punto puede ejecutarse para descubrir defectos de rendimiento. Construye un entorno de prueba similar al entorno real y prueba el programa en al mismo tiempo O dentro de un cierto período de tiempo, envíe una cantidad esperada de solicitudes de transacción al sistema, pruebe la eficiencia del sistema bajo diferentes condiciones de presión y las condiciones de presión que el sistema puede soportar. Luego, realice pruebas y análisis específicos para encontrar cuellos de botella que afecten el rendimiento del sistema, evalúe la eficiencia del sistema en el entorno de uso real, evalúe el rendimiento del sistema y determine si el sistema de aplicación debe optimizarse o ajustarse estructuralmente. y optimizar los recursos del sistema.
En la prueba de estrés involucraremos algunos indicadores de desempeño relacionados:
- Tiempo de respuesta (RT): el tiempo total desde que el cliente envía la solicitud hasta que obtiene el resultado de la respuesta del servidor.
- HPS (Hits por segundo): número de clics por segundo
- TPS (Transacción por segundo): la cantidad de transacciones procesadas por el sistema por segundo, también llamada cantidad de sesiones
- QPS (consulta por segundo): la cantidad de consultas que el sistema procesa por segundo
En las empresas de Internet, si una empresa tiene una y solo una conexión de solicitud, entonces TPS = QPS = HPS y, en general, TPS se usa para medir todo el proceso comercial, QPS se usa para medir el número de consultas de interfaz y HPS es utilizado para medir El servidor hace clic en la solicitud.
Cuando realizamos pruebas, utilizamos los datos de estos indicadores (HPS, TPS, QPS) para medir el sistema. Cuanto mayor sea el indicador, mejor será el rendimiento del sistema. En general, la gama de indicadores en varias industrias es bastante diferente. La siguiente es una breve lista solo como referencia.
- Industria financiera: 1000TPS~50000TPS
- Industria de seguros: 100TPS~100000TPS
- Fabricación: 10TPS~5000TPS
- Grandes sitios web de Internet: 10000TPS~1000000TPS
- Internet otros: 1000TPS~50000TPS
Por supuesto, también incluiremos algunos otros sustantivos, como sigue:
| sustantivo | ilustrar |
|---|---|
| Tiempo máximo de respuesta | El tiempo máximo entre que el usuario realiza una solicitud y el sistema responde. |
| Tiempo mínimo de respuesta | El tiempo mínimo entre que el usuario realiza una solicitud y el sistema responde. |
| 90% de tiempo de respuesta | Se refiere al tiempo de respuesta de todos los usuarios ordenados, el percentil 90 del tiempo de respuesta |
Cuando lo miramos desde fuera, las pruebas de rendimiento se centran principalmente en estos tres indicadores de rendimiento.
| índice | ilustrar |
|---|---|
| Rendimiento | La cantidad de solicitudes y tareas que el sistema puede manejar por segundo. |
| Tiempo de respuesta | El tiempo que tarda un servicio en procesar una solicitud o una tarea |
| Tasa de error | La proporción de solicitudes en un lote que resultan en errores. |
2. JMetro
1. Instale JMeter
Dirección del sitio web oficial: https://jmeter.apache.org/download_jmeter.cgi Después de descargarlo, descomprímalo, luego vaya al directorio bin y haga doble clic en el archivo JMeter.bat para comenzar.
Esta herramienta es compatible con chino.
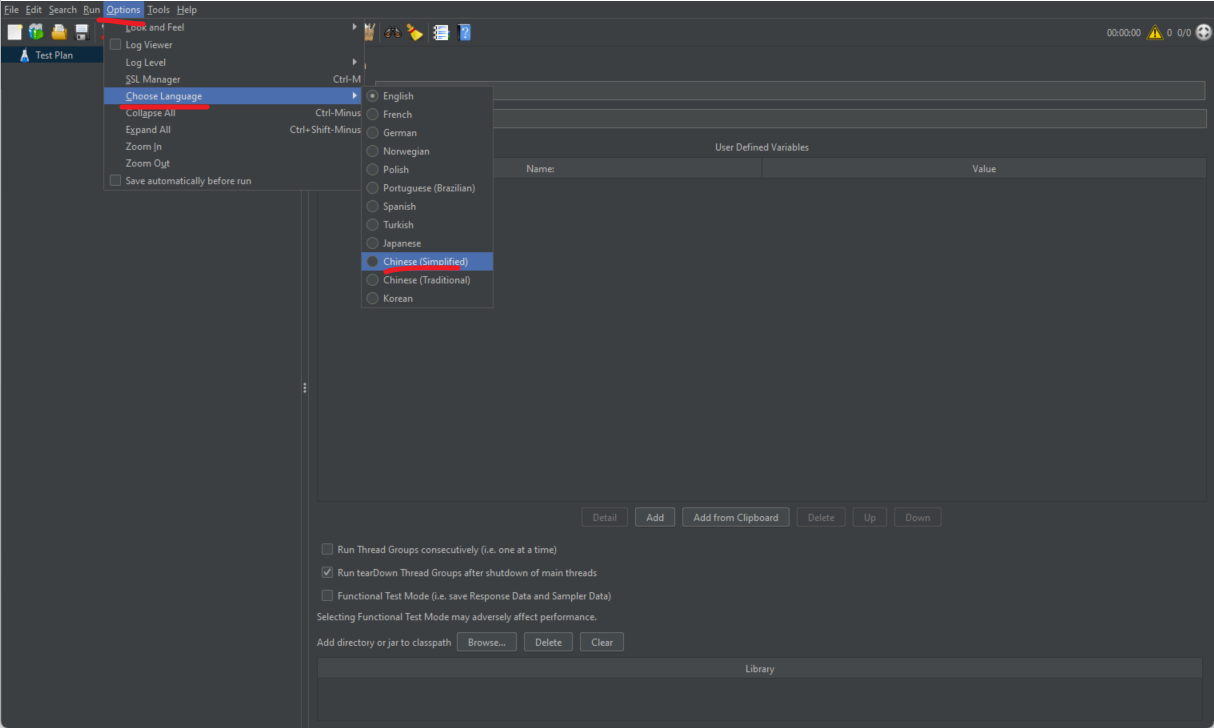
Página después del chino
2.Operaciones básicas de JMeter
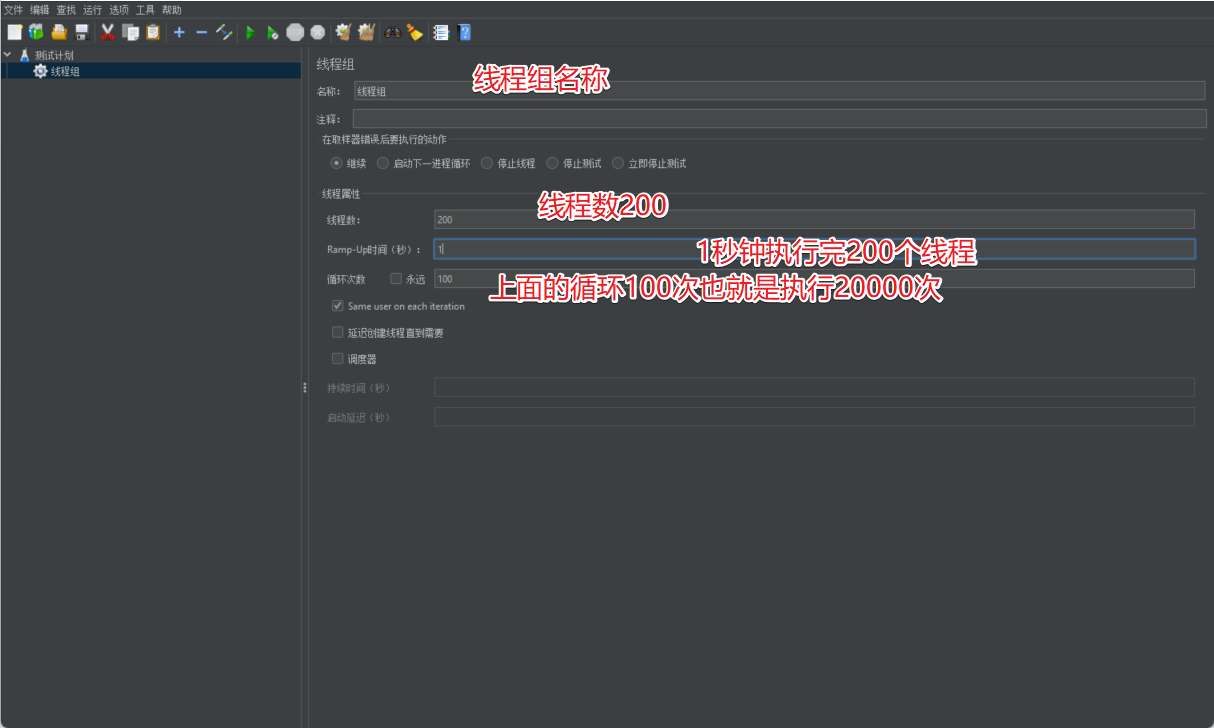
2.1 Agregar grupo de hilos
La función del grupo de subprocesos es definir los atributos relevantes de la tarea, como cuántos subprocesos se ejecutan por segundo y cuántas veces se repite la operación.
2.2 Muestreador
Luego de definir el grupo de subprocesos, tenemos que continuar definiendo el comportamiento de operación de cada subproceso, es decir, crear el sampler correspondiente, en el que definimos el protocolo y la información de dirección del servicio al que se accederá.
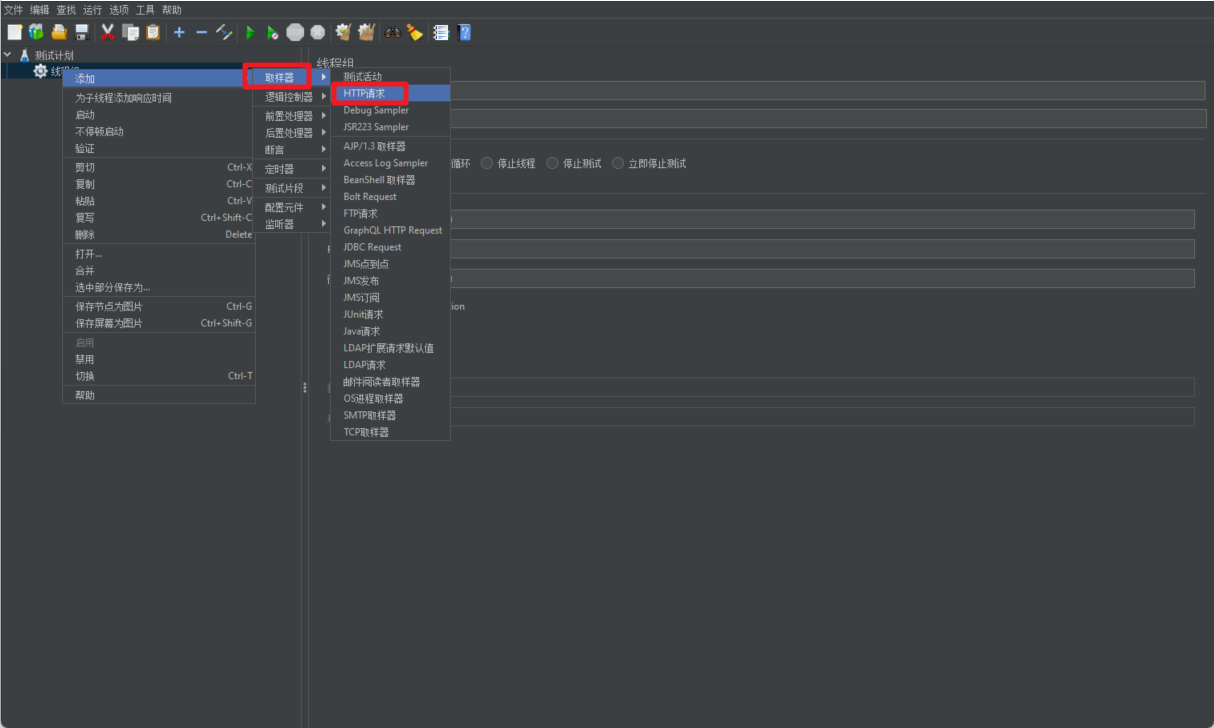
Luego necesitamos definir la información del servicio en el muestreador.
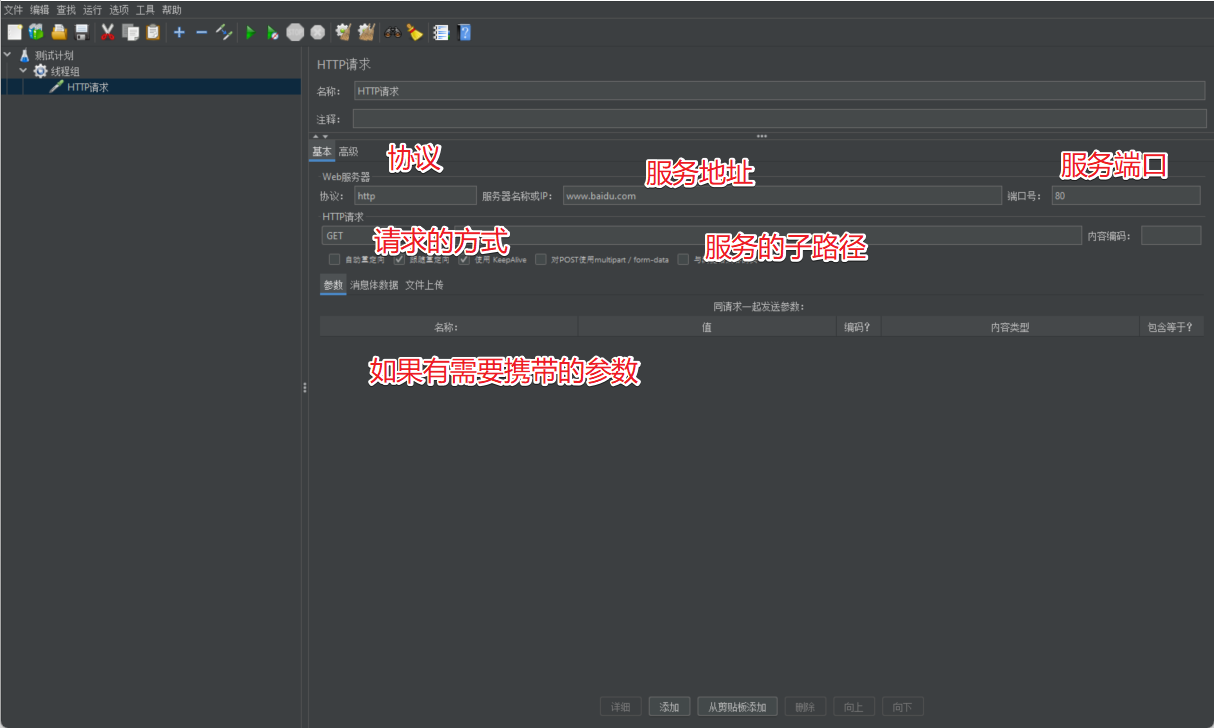
2.3 Monitorear
En el muestreador, definimos la información del servicio al que se accederá y luego debemos considerar la información del indicador relevante de la tarea que debemos obtener después de la solicitud. Aquí es donde se utiliza el monitor.
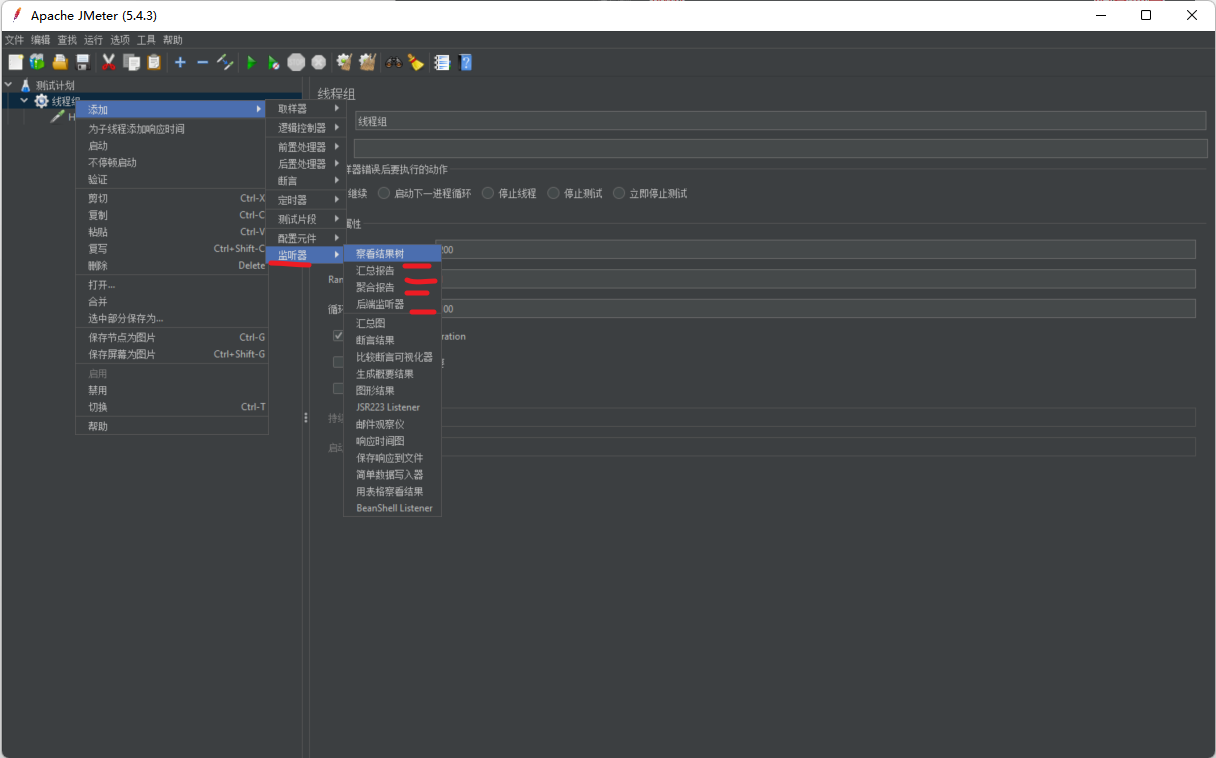
Los datos de resultados correspondientes incluyen la visualización del informe resumido del árbol de resultados, el informe de agregación y la visualización del cuadro resumido gráfico correspondiente...
2.4 Prueba Baidu
Después de escribir la muestra, comience a probar.
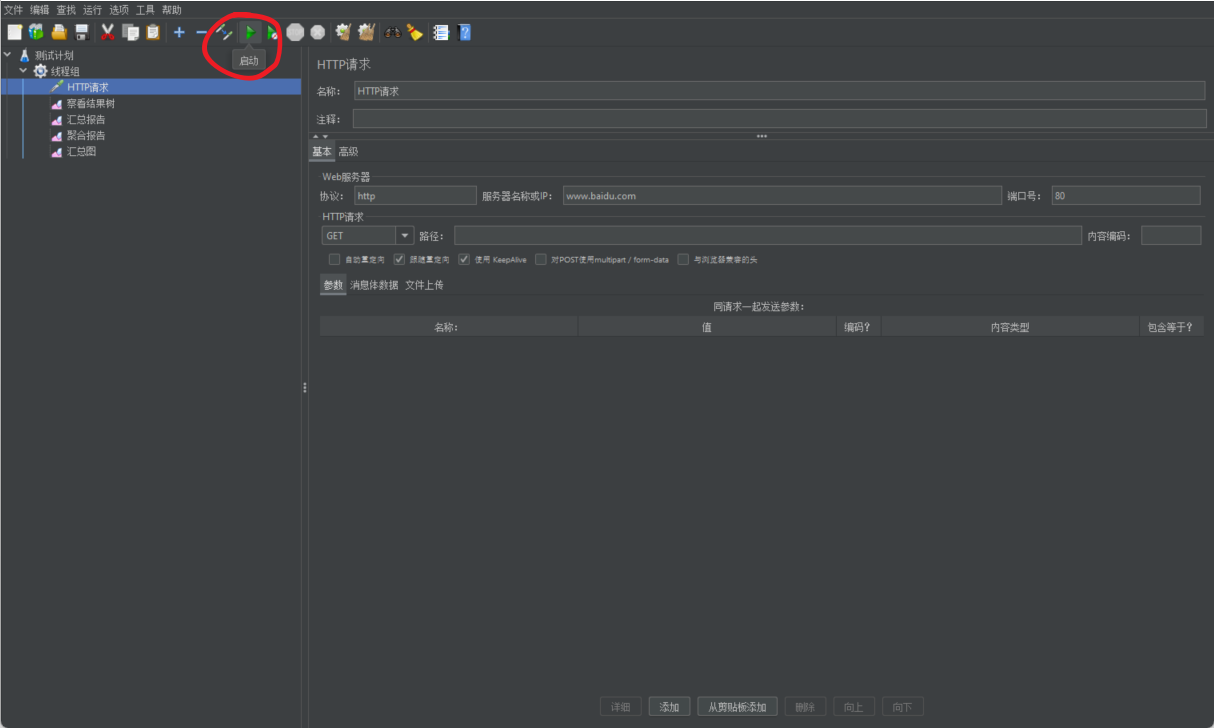
Después de comenzar, podemos consultar los datos del resultado de la prueba.
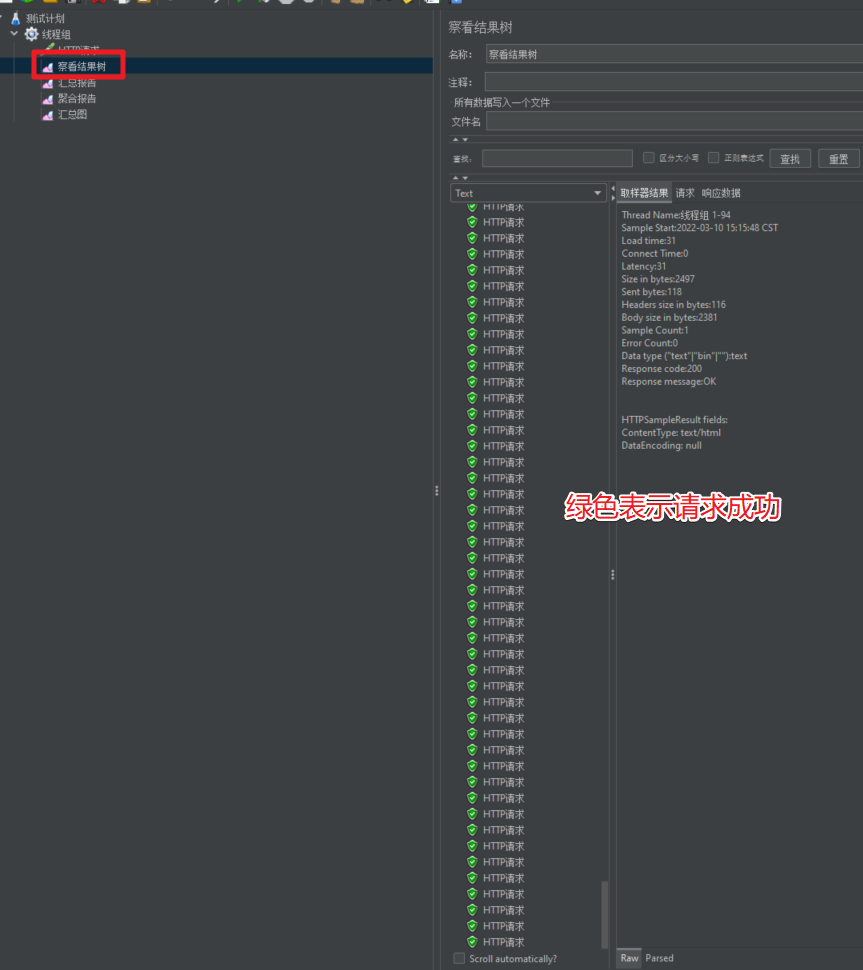


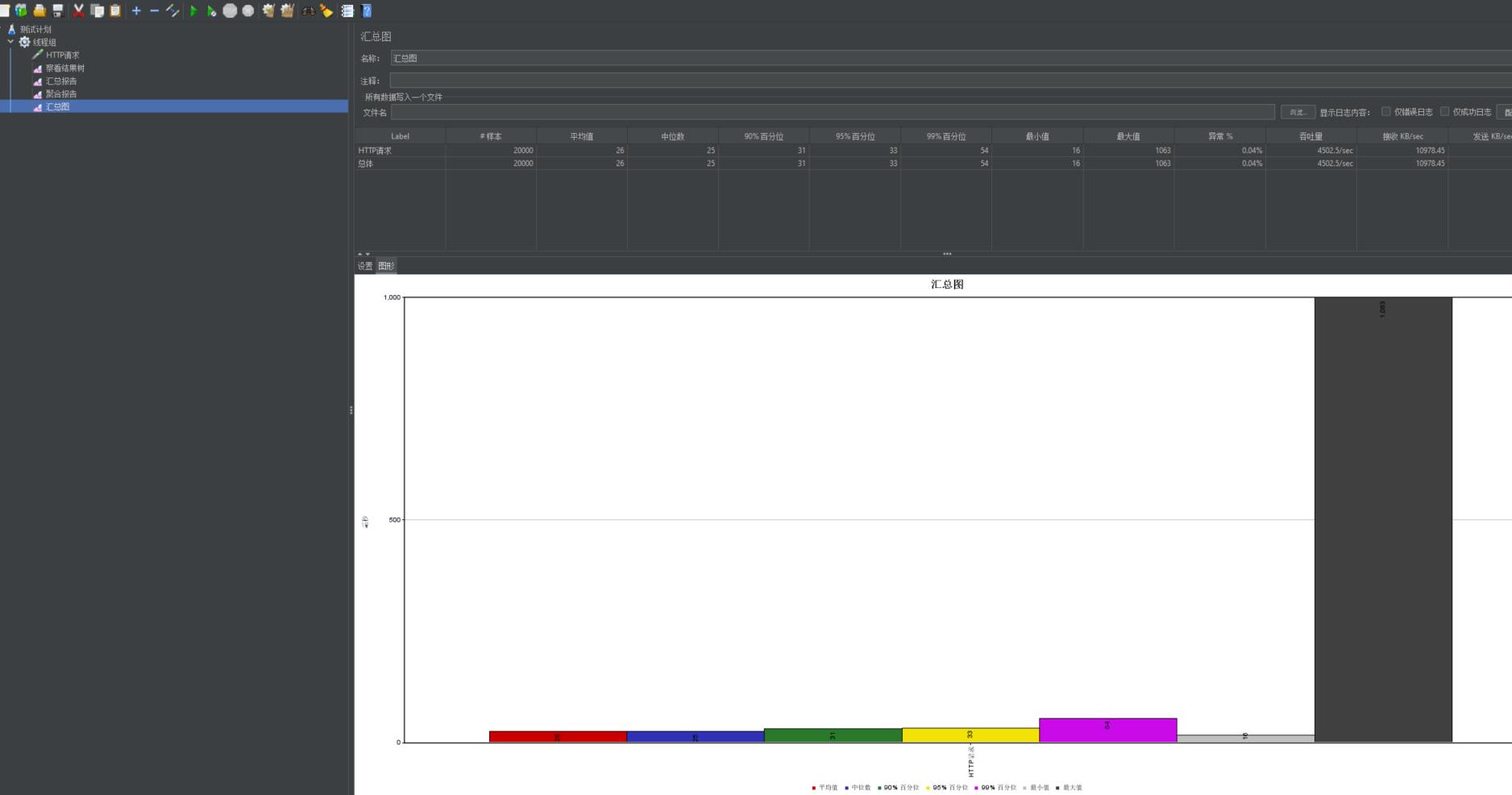
2.5 Página de inicio del centro comercial de prueba
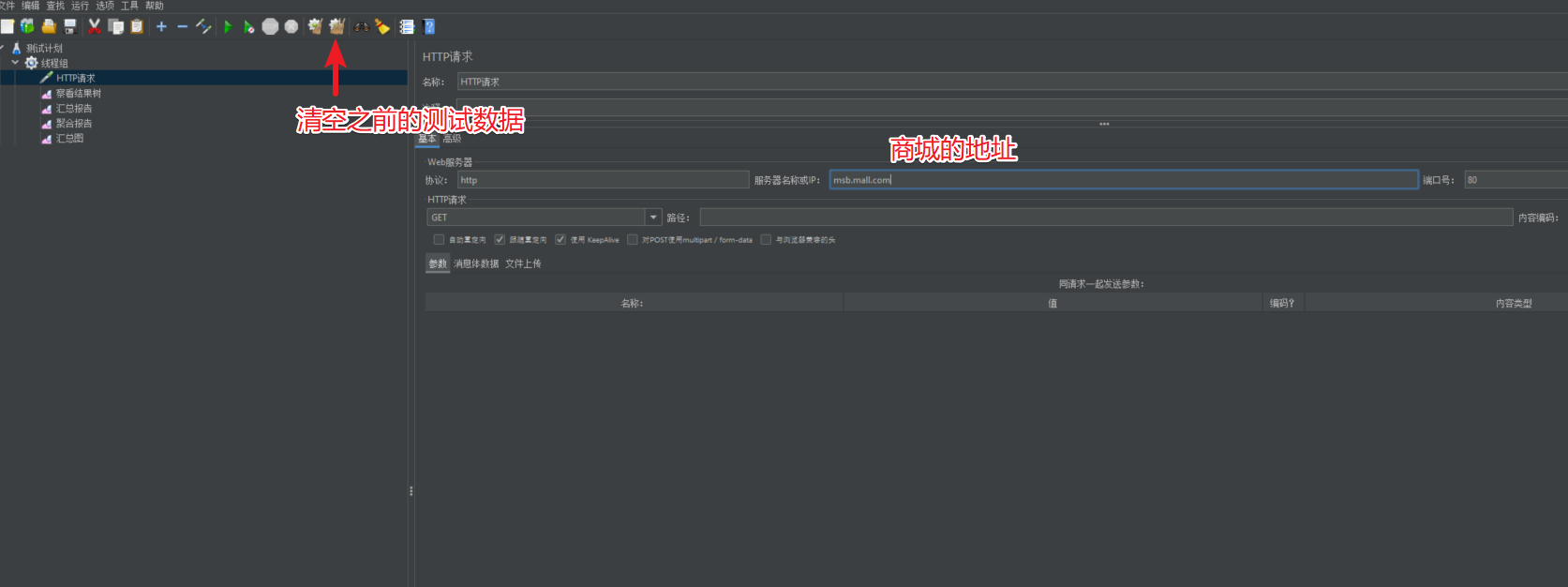
Verifique los resultados correspondientes después de comenzar.


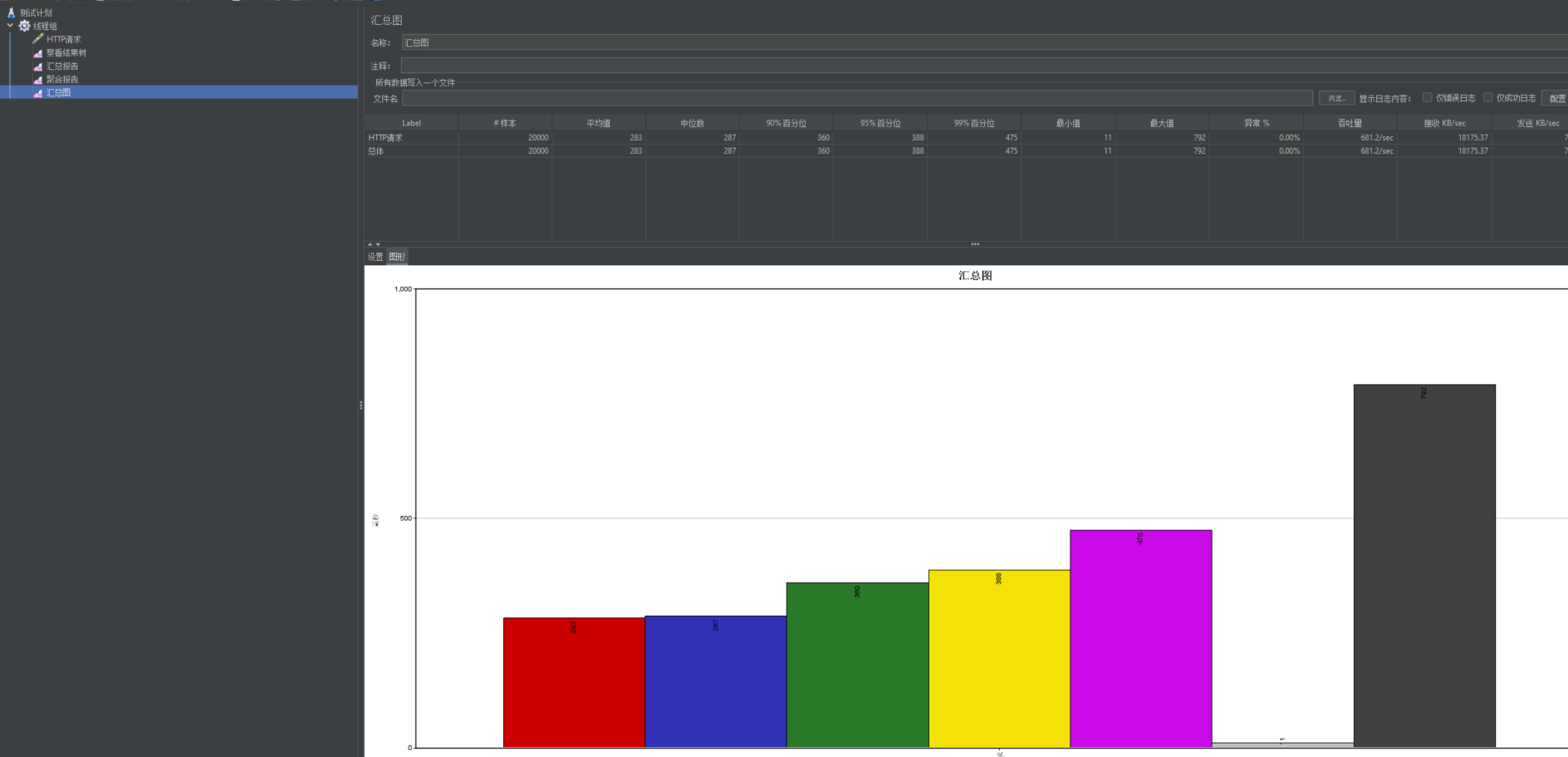
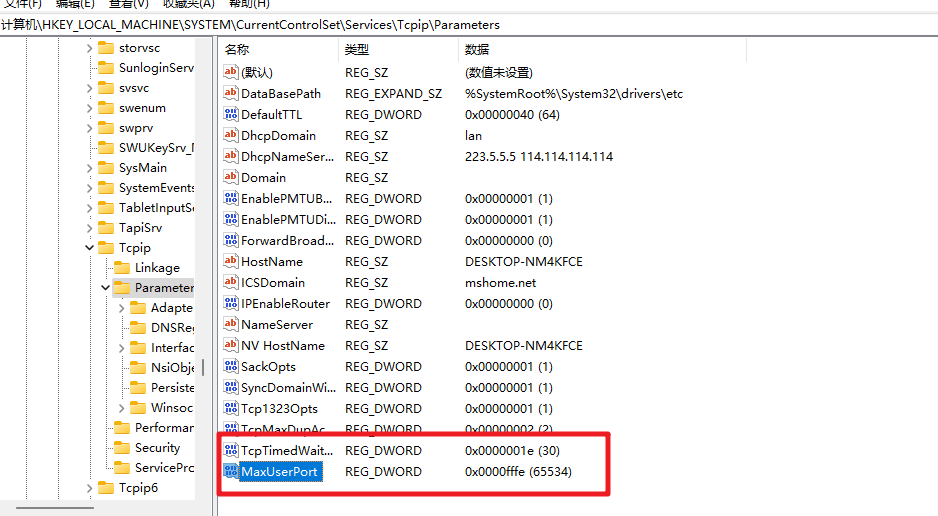
2.6 Problema de ocupación de dirección JMeter
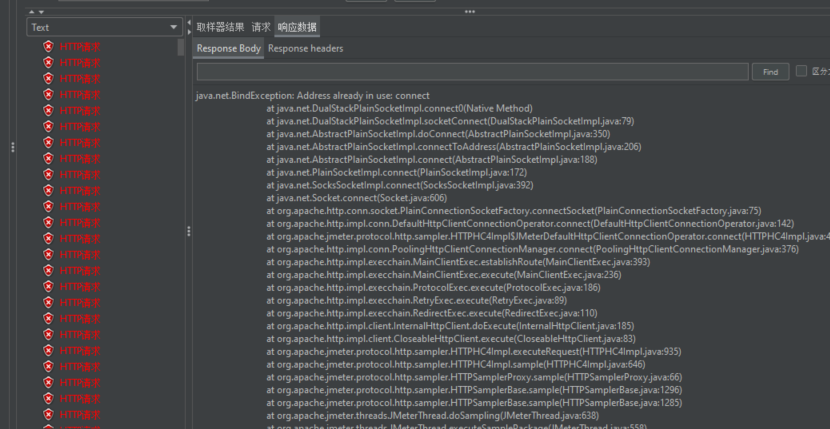
Después de buscar, descubrí que la clave de registro MaxUserPort debe agregarse a regedit y TcpTimedWaitDelay se puede resolver reiniciándolo.
Solución:
Abra el registro: ctrl+r e ingrese regedit
para ingresar al registro. La ruta es: \HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters.
Cree un nuevo valor DWORD y configúrelo (en decimal) en 30 segundos. Nombre: TcpTimedWaitDe, valor: 30
Cree un nuevo valor DWORD, (decimal) el número máximo de conexiones es 65534. Nombre: MaxUserPort, valor: 65534
Una vez completada la modificación, reinicie para que surta efecto.
3. Optimización del rendimiento
1. Considere los factores que afectan el desempeño del servicio.
Base de datos, aplicación, middleware (Tomcat, Nginx), red y sistema operativo, etc.
También tenemos que considerar que el servicio actual pertenece a
- Uso intensivo de CPU: la informática afecta el rendimiento -> agregar CPU, agregar máquina
- IO intensivo: IO de red, IO de disco, IO de lectura y escritura de base de datos, IO de lectura y escritura de Redis --> caché, agregar unidad de estado sólido, agregar tarjeta de red
2.Revisión de JVM
Establecer los parámetros de JVM y ajustar adecuadamente el tamaño de la memoria del espacio de almacenamiento dinámico correspondiente también es una acción clave para mejorar la eficiencia. En la idea del entorno local, configure el entorno de inicio y los parámetros de Opciones de VM pueden ser -Xmx512m -Xmn512m. Para ejecutar la producción entorno, luego configure los parámetros de jvm
, a través de java -Xmx512 -Xmn512m xxx.jar
[La transferencia de la imagen del enlace externo falló. El sitio de origen puede tener un mecanismo anti-leeching. Se recomienda guardar la imagen y cargarla directamente (img-s4RvI9f0-1693209241788)(./images/1693******* ******* **208858173_image.png)]
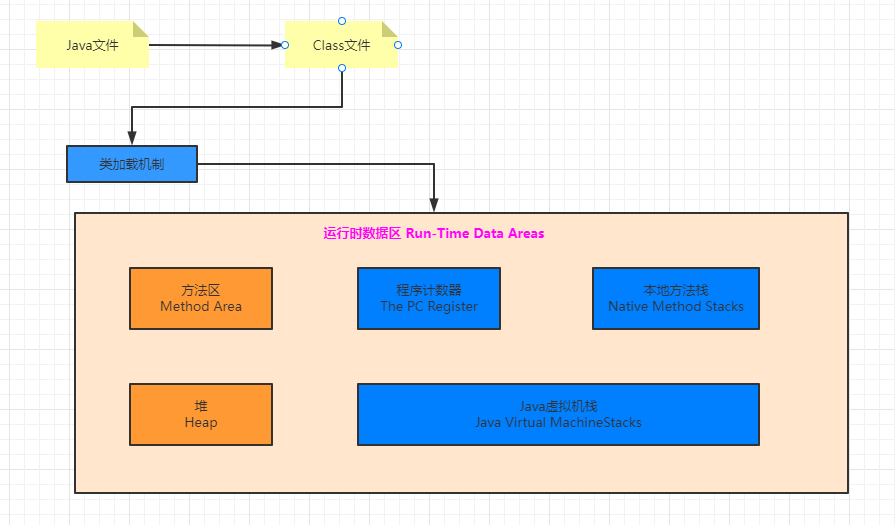
Estructura de memoria JVM
Almacenamiento y GC de objetos en JVM
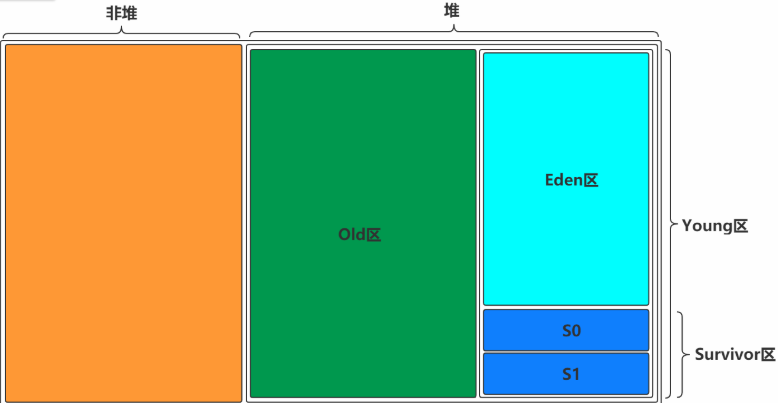
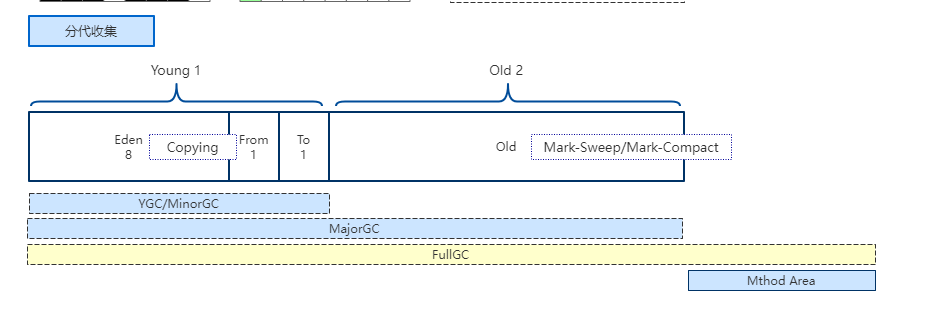
1. El espacio involucrado en la JVM: Montón: incluye la generación joven y la generación anterior + grupo constante de cadenas.La generación joven consta de un área de Eden y dos de Survivor. Área de método: la generación persistente y el metaespacio son implementaciones del área de método, y JDK1.8 lo cambió a metaespacio.
2. Configuración de parámetros de JVM, parámetros de configuración del servidor:
- -Xms: tamaño de memoria del montón inicial, establece el tamaño de la memoria ocupada cuando se inicia el programa, la memoria física predeterminada es 1/64 -Xms = -XX:InitialHeapSiz
- -Xmx: memoria dinámica máxima, establece el tamaño máximo de memoria que se puede ocupar durante la ejecución del programa. Si el programa requiere más memoria para ejecutarse que este valor de configuración, se generará una excepción OutOfMemory. La memoria física predeterminada es 1/4, -Xmx = -XX:MaxHeapSize. El tamaño de las configuraciones -Xms y -Xmx en la imagen de arriba son los mismos 6000M
- -Xss: establece el tamaño de pila de un solo subproceso, generalmente el valor predeterminado es 512 ~ 1024 kb. El tamaño de una pila de subprocesos único está relacionado con el sistema operativo y la versión de JDK, -Xss = -XX:ThreadStackSize
- -Xmn: establece el tamaño de la generación joven. El tamaño completo del montón = tamaño de la generación joven + tamaño de la generación anterior + grupo constante. La generación persistente generalmente tiene un tamaño fijo de 64 m, por lo que aumentar la generación joven reducirá el tamaño de la generación anterior. Este valor tiene un mayor impacto en el rendimiento del sistema. Sun recomienda oficialmente configurarlo en 3/8 del montón completo.
- -XX: MetaspaceSize: el tamaño del metaespacio. La naturaleza del metaespacio es similar a la generación permanente. Ambas son implementaciones del área de método en la especificación JVM. Sin embargo, la mayor diferencia entre el metaespacio y la generación permanente es que el metaespacio no está en la máquina virtual, sino que usa memoria local y está controlado por el sistema operativo. Por lo tanto, el tamaño del metaespacio está limitado únicamente por la memoria local.
- -XX:+PrintGCDetails: imprime información detallada del registro de GC
- -XX: SurvivorRatio: configuración de la proporción de supervivientes, establece la proporción de tamaño del área de Eden y el área de Supervivientes en la generación joven. Si se establece en 8, la proporción entre dos áreas de Supervivientes y un área de Edén es de 2:8, y un área de Supervivientes representa 1/10 de toda la generación joven.
- -XX:NewRatio: la relación entre la configuración de la relación de nueva generación (incluido Eden y dos áreas de Supervivientes) y la generación anterior (excluyendo la generación persistente). Si se establece en 1, la proporción entre la generación joven y la generación anterior es 1:1, y la generación joven representa la mitad de toda la pila.
- -XX: MaxTenuringThreshold: ingrese la configuración del umbral de la generación anterior
- -XX:PermSize=128m: el valor inicial de la memoria de generación persistente se asigna 128M; -XX:MaxPermSize=512m: establece el valor máximo de generación permanente en 512m
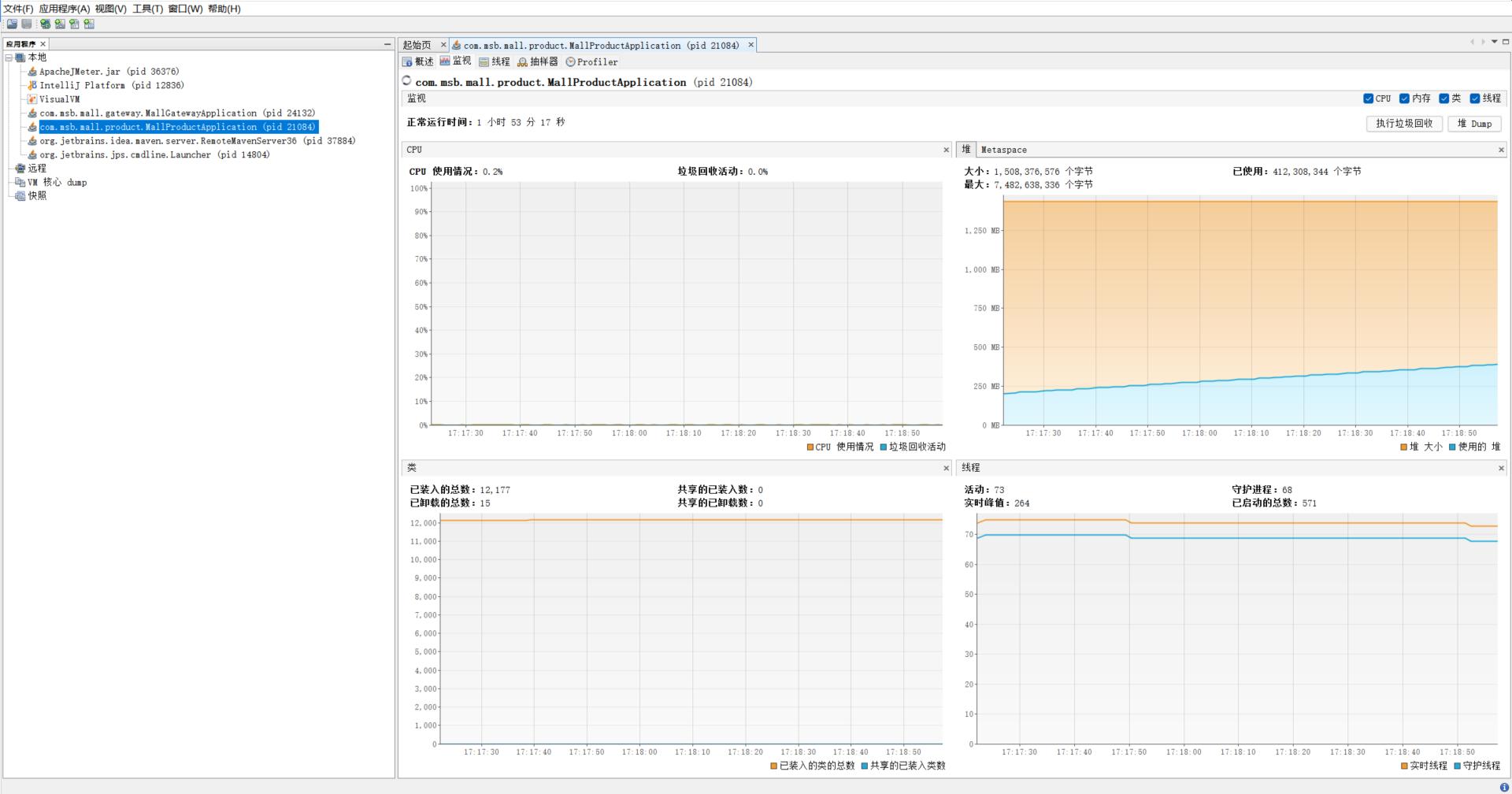
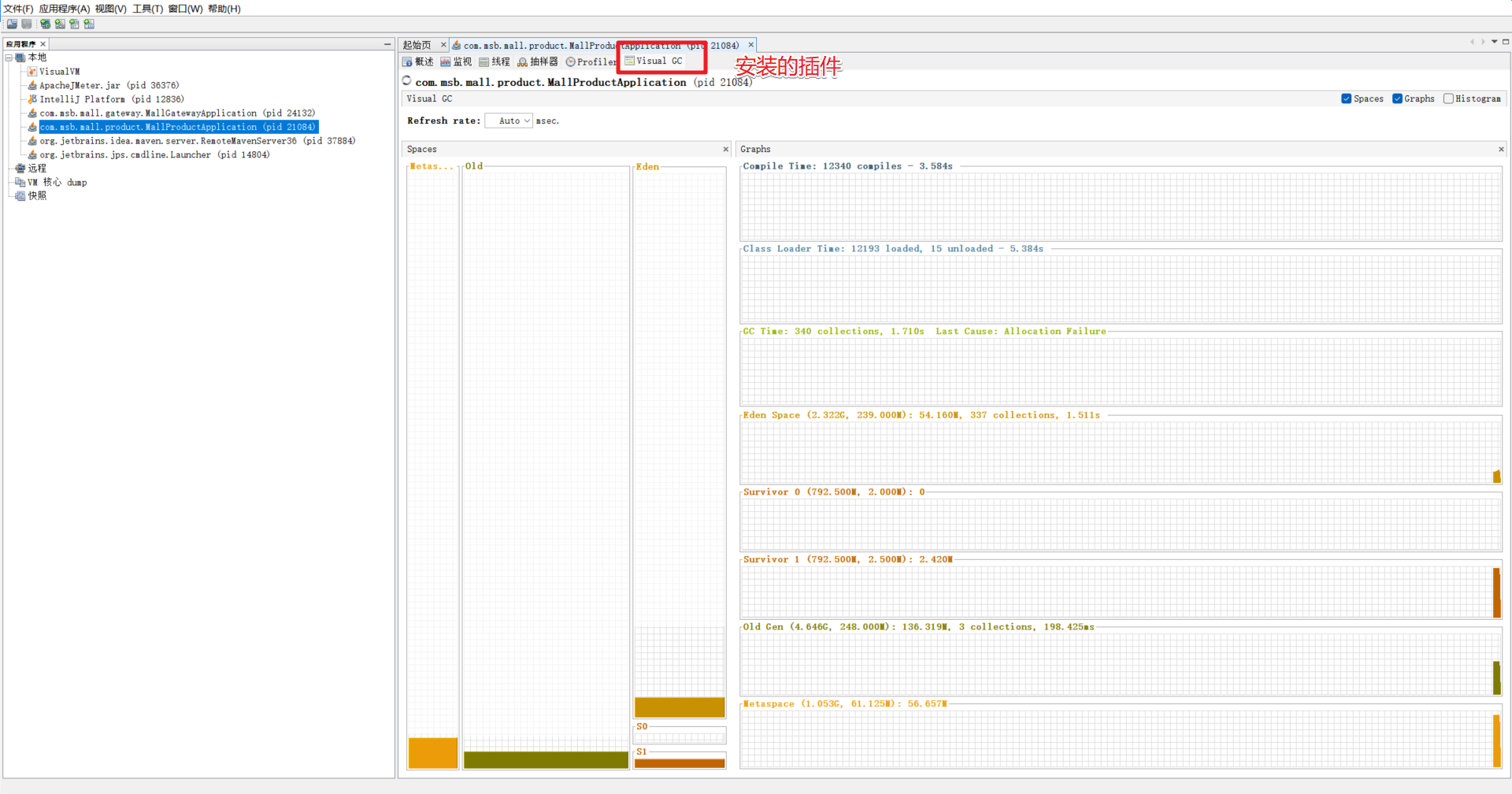
3.jconsole y jvisualvm
jconsole y jvisualvm son las herramientas de monitoreo propias de JDK. Puede ayudarnos a ver mejor la información de monitoreo relevante del servicio y la función jvisualvm será más poderosa.
3.1 jconsola
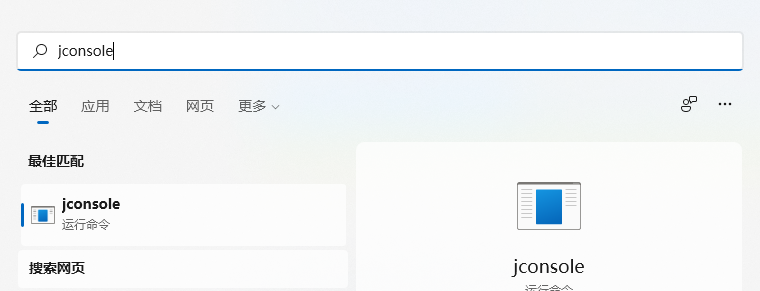
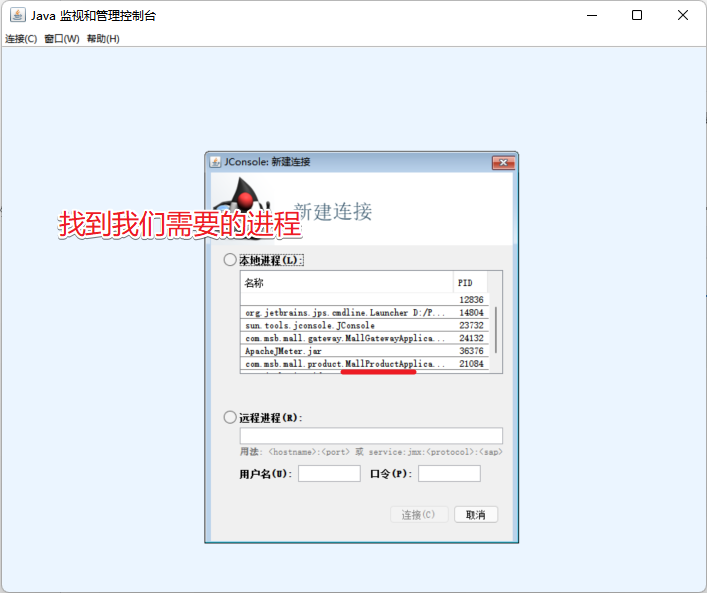
Encuentra el proceso correspondiente
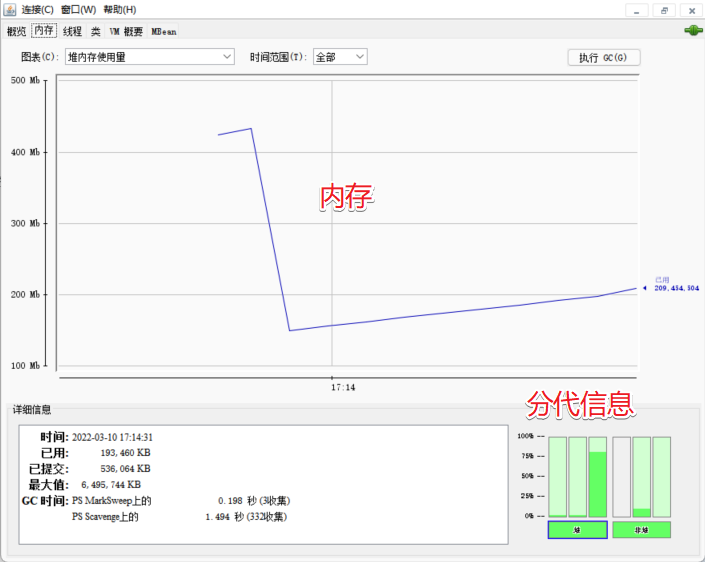
3.2 jvisualvm
Como viene con jdk6.0, también podemos encontrarlo en cmd o en el cuadro de búsqueda.
Abrir página principal
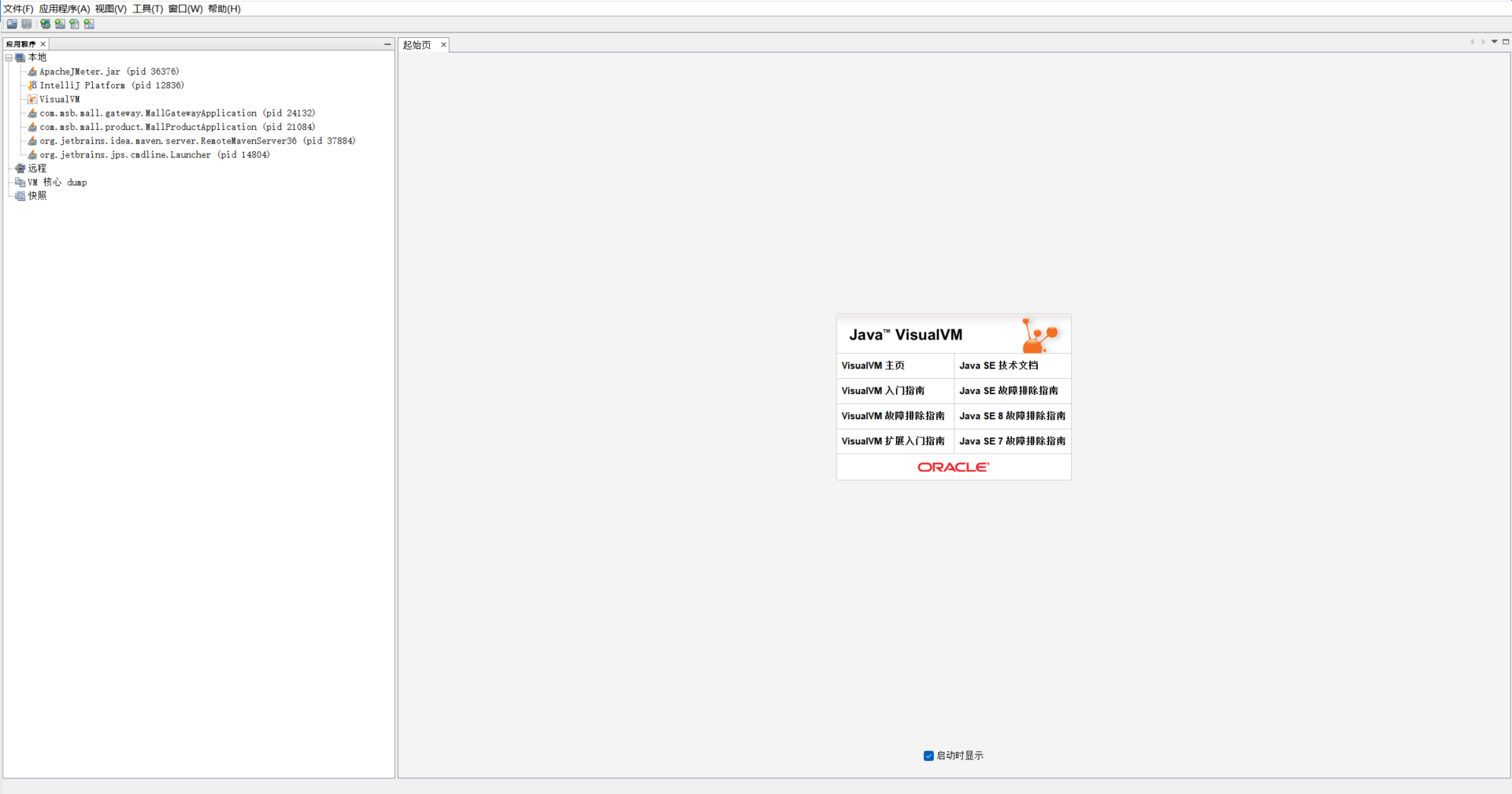
Busque el proceso correspondiente y haga doble clic para ingresar
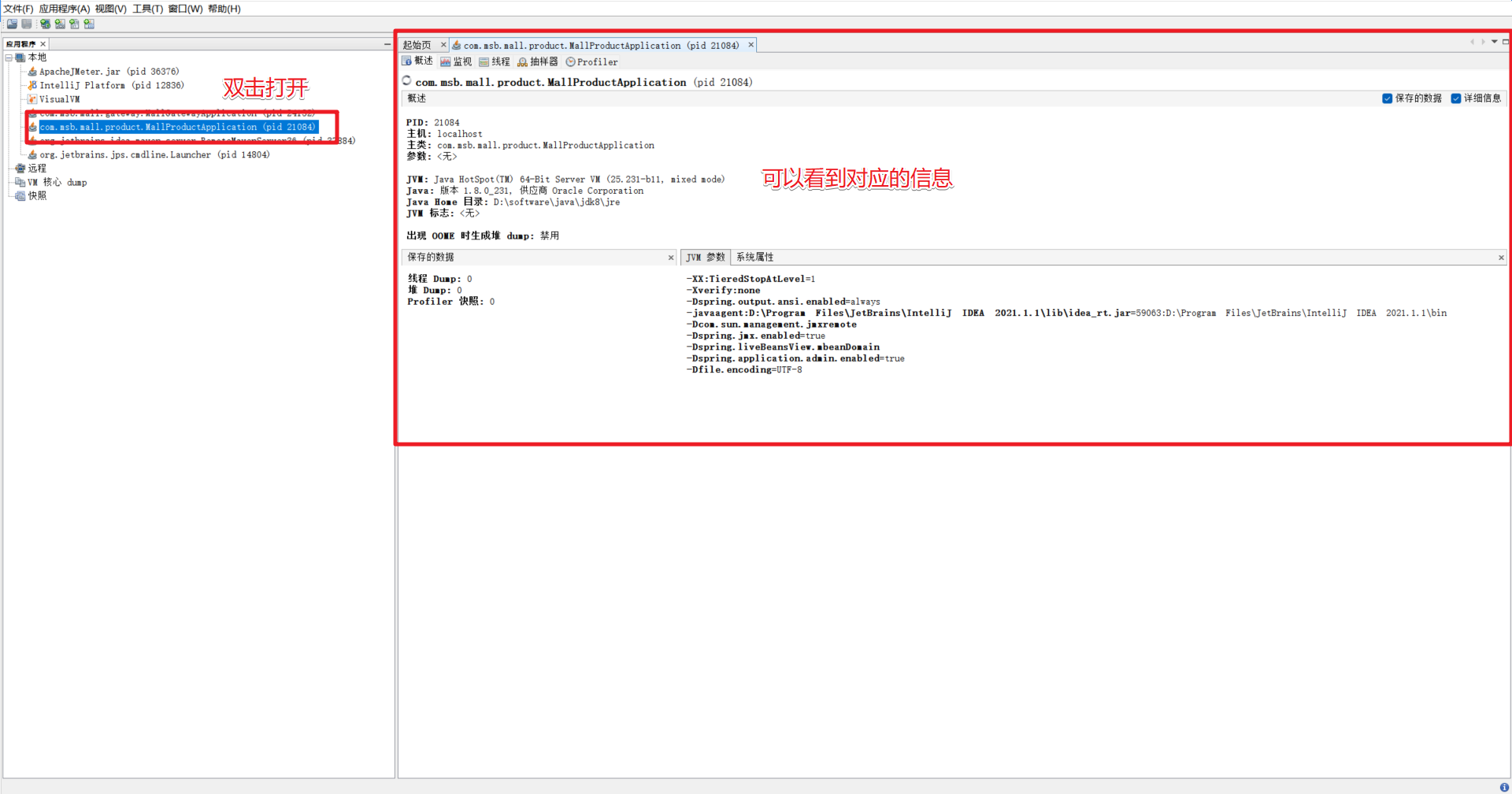
Ver la información de seguimiento correspondiente
Agregar complemento. Si el complemento no está disponible, es necesario actualizarlo.
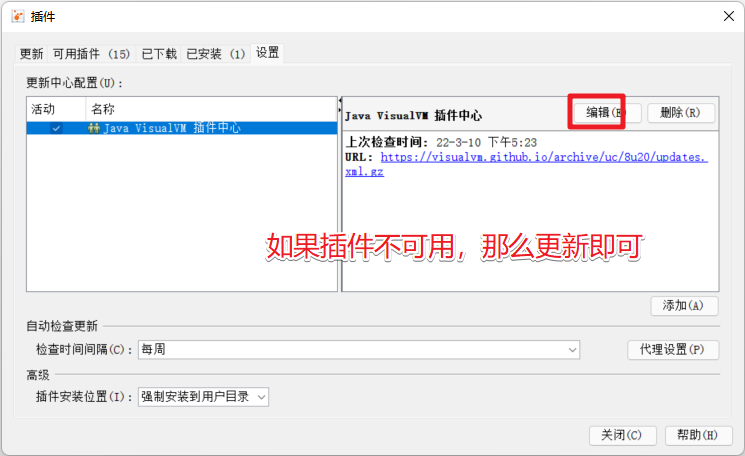
https://visualvm.github.io/pluginscenters.html Debe seleccionar la versión del complemento correspondiente según su versión de jdk.
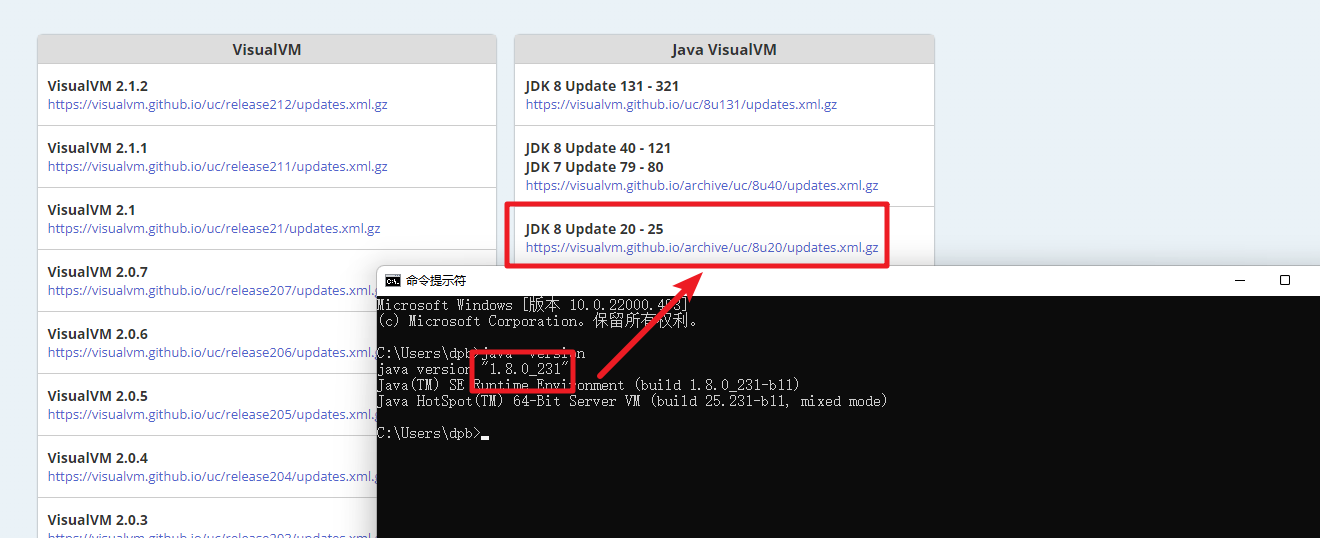
Después de la instalación, reinicie jvisualvm
%
4. Rendimiento del middleware
El siguiente es un enlace de solicitud completo.

Entonces probemos el rendimiento de los componentes relacionados.
-
Prueba de Nginx, puede usar directamente la página html predeterminada, colocar un archivo index.html en el archivo de configuración de nginx y el navegador accede a la dirección predeterminada de nginx para realizar pruebas de presión, el puerto es el 80 predeterminado
-
Obtuvo preliminarmente una situación después de la prueba, el rendimiento y otros indicadores cuantitativos.
-
Luego, podemos abrir el comando Docker Statistics para conocer el estado del contenedor en Docke y luego realizar la prueba de presión nuevamente para observar los cambios de rendimiento del servicio Nginx en tiempo real y juzgar si el tipo con uso intensivo de CPU es intensivo en IO. Durante el proceso de medición de presión, podemos ver que la CPU se dispara al máximo y podemos juzgar si la CPU requiere un uso intensivo y se puede optimizar agregando más máquinas o CPU.
-
De hecho, también es comprensible, porque Nginx no realiza procesamiento comercial, sino que principalmente distribuye más solicitudes y crea más subprocesos para mantenimiento, por lo que se necesita más soporte de CPU.
-
Prueba de puerta de enlace: acceso directo a la misma dirección del servidor más el puerto correspondiente, ninguna solicitud de dirección de interfaz específica es la misma que Nginx, dirección del método directo: puerto, y se puede lograr el efecto de prueba
-
Servicio de prueba separado: aquí puede escribir una interfaz de solicitud simple y devolver una cadena directamente sin pasar por los datos de la base de datos, que es solo para probar el rendimiento del servicio de la aplicación.
-
Puerta de enlace + servicio: Es configurar la solicitud a través de la puerta de enlace y reenviarla, la solicitud es el puerto del servicio de puerta de enlace, y luego se enrutará al servicio específico para responder a la solicitud.
-
Datos completos en la página de inicio: Esto implica el acceso a algunos recursos estáticos, por lo que debe habilitar la carga y el acceso a recursos html en la configuración avanzada de la herramienta jmeter, para que pueda acceder a las imágenes, html, css, js, etc. de esos recursos estáticos en la página de inicio
| Contenido de la prueba de estrés | Número de subprocesos para pruebas de estrés | Rendimiento/s | 90% de tiempo de respuesta | 99% de tiempo de respuesta |
|---|---|---|---|---|
| nginx | 50 | 7.385 | 10 | 70 |
| Puerta | 50 | 23.170 | 3 | 14 |
| Servicios de prueba individualmente | 50 | 23.160 | 3 | 7 |
| Puerta de enlace+servicio | 50 | 8.461 | 12 | 46 |
| Nginx+Puerta de enlace | 50 | |||
| Nginx+servicio+de puerta de enlace | 50 | 2.816 | 27 | 42 |
| Un menú | 50 | 1.321 | 48 | 74 |
| Prueba de presión de clasificación de tres niveles. | 50 | 12 | 4000 | 4000 |
| Datos completos en la página de inicio. | 50 | 2 |
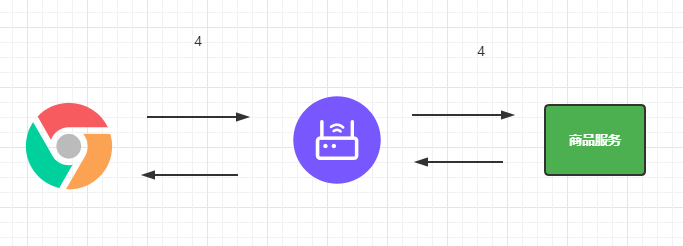
Cuanto más middleware haya, mayor será la pérdida de rendimiento. La mayor parte de la pérdida se produce en la interacción de los datos.
Optimización sencilla:
Middleware: la eficiencia individual es muy alta: cuanto más middleware esté conectado en serie, mayor será el impacto, pero en realidad es relativamente débil frente al negocio.
negocio:
- Base de datos (MySQL, optimizada)
- Representación de página de plantilla
| Contenido de la prueba de estrés | Número de subprocesos para pruebas de estrés | Rendimiento/s | 90% de tiempo de respuesta | 99% de tiempo de respuesta |
|---|---|---|---|---|
| nginx | 50 | 7.385 | 10 | 70 |
| Puerta | 50 | 23.170 | 3 | 14 |
| Servicios de prueba individualmente | 50 | 23.160 | 3 | 7 |
| Puerta de enlace+servicio | 50 | 8.461 | 12 | 46 |
| Nginx+Puerta de enlace | 50 | |||
| Nginx+servicio+de puerta de enlace | 50 | 2.816 | 27 | 42 |
| Un menú | 50 | 1.321 | 48 | 74 |
| Prueba de presión de clasificación de tres niveles. | 50 | 12 | 4000 | 4000 |
| Datos completos de la página de inicio (DB-Themleaf) | 50 | 2 | ||
| Menú de primer nivel ( índice DB ) | 50 | 1900 | 40 | 70 |
| Prueba de estrés de clasificación de tres niveles ( índice ) | 50 | 34 | 1599 | 1700 |
| Datos completos en la página de inicio ( DB-Themleaf-release cache ) | 50 | 30 | 。。。 | 。。。 |
5.Nginx realiza una separación dinámica y estática
A través de la prueba de estrés anterior, podemos encontrar que si el backend atiende y procesa solicitudes dinámicas y solicitudes estáticas, su rendimiento es muy limitado. En este momento, podemos almacenar recursos estáticos en Nginx.
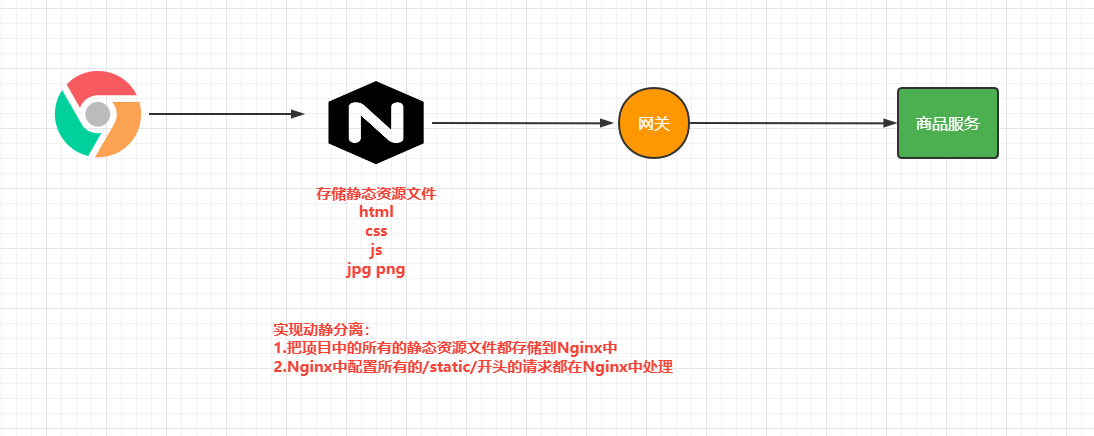
5.1 Almacenamiento de recursos estáticos
Cargue los recursos estáticos en el servicio al servicio Nginx, empaquete los archivos de recursos estáticos en un paquete zip, luego arrástrelo y suéltelo en Linux, y luego pasamos
unzip index.zip
descomprimir
Luego reemplace la ruta de acceso a los recursos en el archivo de plantilla
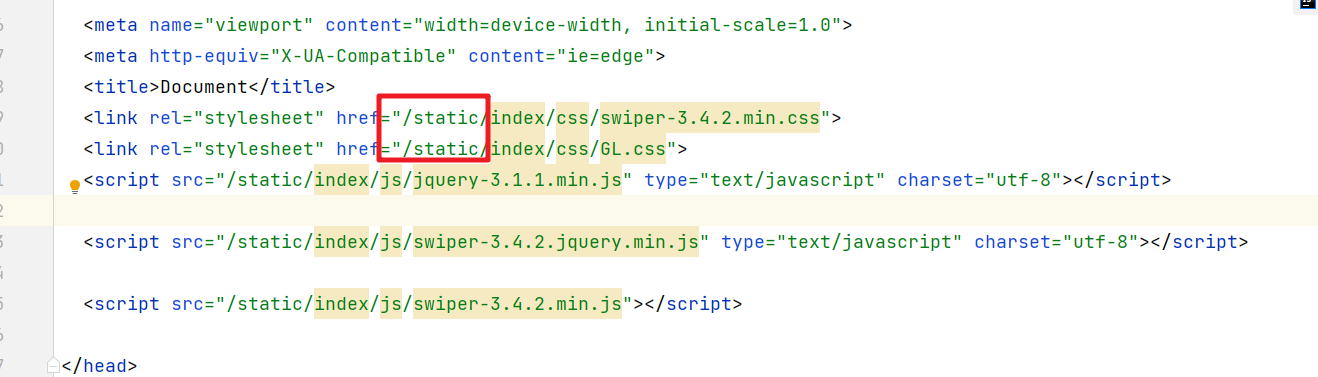
5.2 Configuración de Nginx
Luego especificamos cómo manejar las solicitudes que comienzan con estática en el archivo de configuración de Nginx.
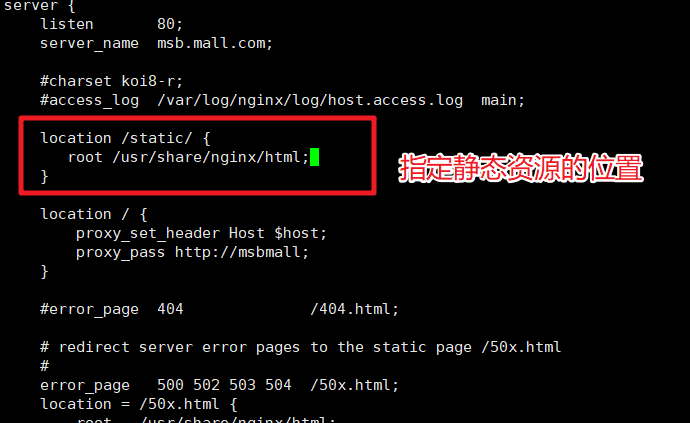
Después de guardar, reinicie el servicio Nginx y luego podrá acceder a él.
6. Optimización de clasificación de tres niveles.
Cuando obtenemos datos de clasificación de tres niveles, operamos con frecuencia la base de datos y podemos optimizar este código.
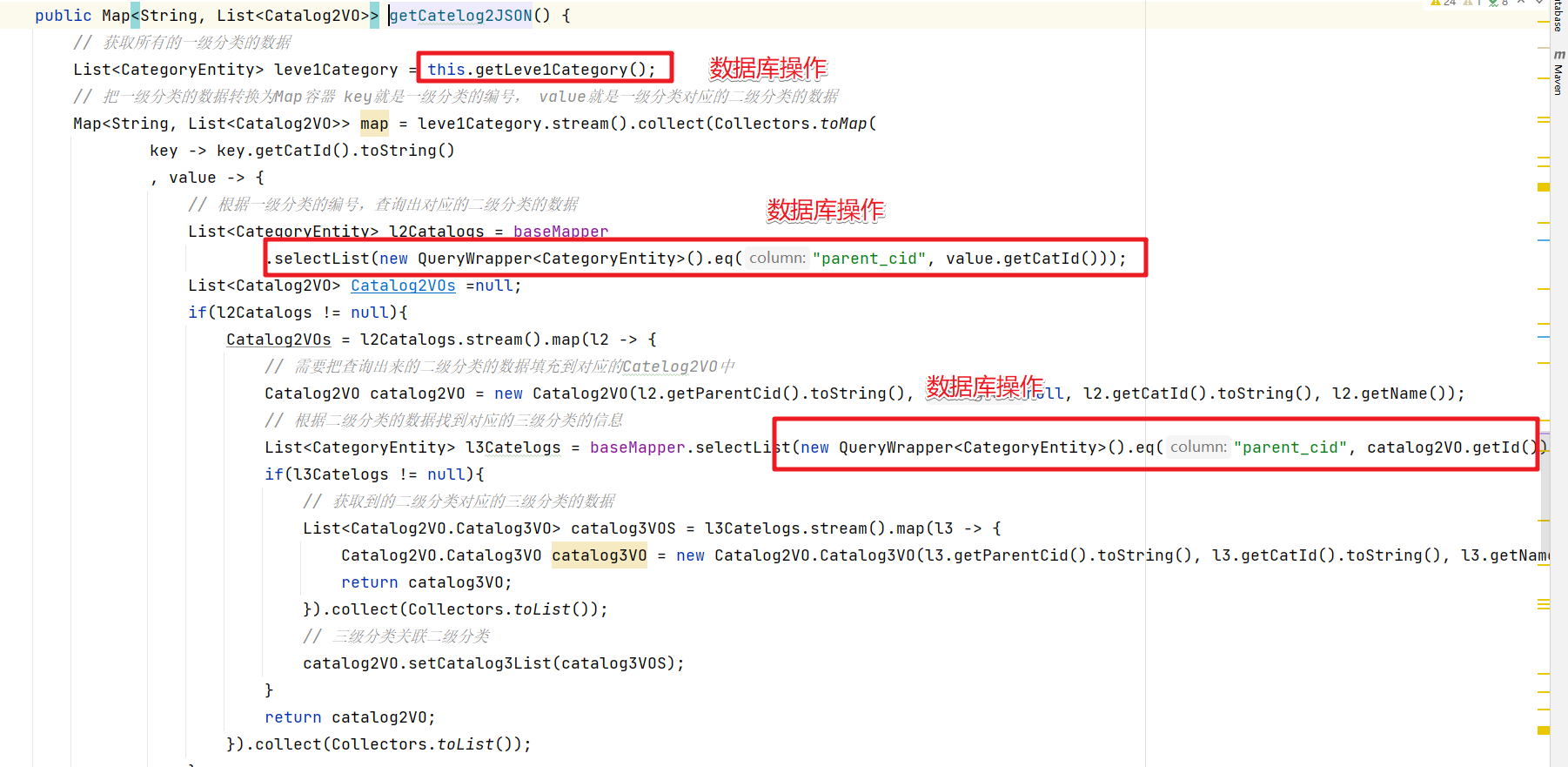
Aquí podemos consultar todos los datos clasificados a la vez y luego obtener la información correspondiente de estos datos cada vez, para reducir la cantidad de operaciones de la base de datos y mejorar el rendimiento del servicio .
/**
* 跟进父编号获取对应的子菜单信息
* @param list
* @param parentCid
* @return
*/
private List<CategoryEntity> queryByParenCid(List<CategoryEntity> list,Long parentCid){
List<CategoryEntity> collect = list.stream().filter(item -> {
return item.getParentCid().equals(parentCid);
}).collect(Collectors.toList());
return collect;
}
/**
* 查询出所有的二级和三级分类的数据
* 并封装为Map<String, Catalog2VO>对象
* @return
*/
@Override
public Map<String, List<Catalog2VO>> getCatelog2JSON() {
// 获取所有的分类数据
List<CategoryEntity> list = baseMapper.selectList(new QueryWrapper<CategoryEntity>());
// 获取所有的一级分类的数据
List<CategoryEntity> leve1Category = this.queryByParenCid(list,0l);
// 把一级分类的数据转换为Map容器 key就是一级分类的编号, value就是一级分类对应的二级分类的数据
Map<String, List<Catalog2VO>> map = leve1Category.stream().collect(Collectors.toMap(
key -> key.getCatId().toString()
, value -> {
// 根据一级分类的编号,查询出对应的二级分类的数据
List<CategoryEntity> l2Catalogs = this.queryByParenCid(list,value.getCatId());
List<Catalog2VO> Catalog2VOs =null;
if(l2Catalogs != null){
Catalog2VOs = l2Catalogs.stream().map(l2 -> {
// 需要把查询出来的二级分类的数据填充到对应的Catelog2VO中
Catalog2VO catalog2VO = new Catalog2VO(l2.getParentCid().toString(), null, l2.getCatId().toString(), l2.getName());
// 根据二级分类的数据找到对应的三级分类的信息
List<CategoryEntity> l3Catelogs = this.queryByParenCid(list,l2.getCatId());
if(l3Catelogs != null){
// 获取到的二级分类对应的三级分类的数据
List<Catalog2VO.Catalog3VO> catalog3VOS = l3Catelogs.stream().map(l3 -> {
Catalog2VO.Catalog3VO catalog3VO = new Catalog2VO.Catalog3VO(l3.getParentCid().toString(), l3.getCatId().toString(), l3.getName());
return catalog3VO;
}).collect(Collectors.toList());
// 三级分类关联二级分类
catalog2VO.setCatalog3List(catalog3VOS);
}
return catalog2VO;
}).collect(Collectors.toList());
}
return Catalog2VOs;
}
));
return map;
}
Rendimiento optimizado de la prueba de estrés
| Contenido de la prueba de estrés | Número de subprocesos para pruebas de estrés | Rendimiento/s | 90% de tiempo de respuesta | 99% de tiempo de respuesta |
|---|---|---|---|---|
| nginx | 50 | 7.385 | 10 | 70 |
| Puerta | 50 | 23.170 | 3 | 14 |
| Servicios de prueba individualmente | 50 | 23.160 | 3 | 7 |
| Puerta de enlace+servicio | 50 | 8.461 | 12 | 46 |
| Nginx+Puerta de enlace | 50 | |||
| Nginx+servicio+de puerta de enlace | 50 | 2.816 | 27 | 42 |
| Un menú | 50 | 1.321 | 48 | 74 |
| Prueba de presión de clasificación de tres niveles. | 50 | 12 | 4000 | 4000 |
| Prueba de estrés de clasificación de tres niveles (después de la optimización empresarial) | 50 | 448 | 113 | 227 |
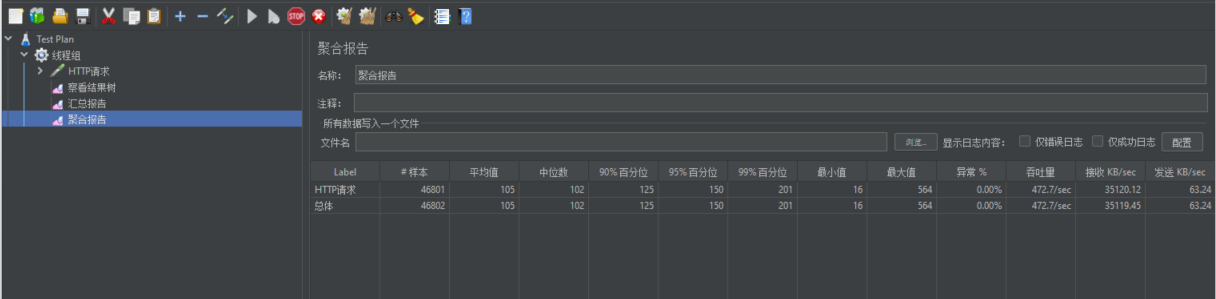
Se puede ver que la mejora del rendimiento del sistema sigue siendo muy obvia.