Directorio de artículos
Estructuras de datos comunes
Las estructuras de datos comunes incluyen matrices, listas vinculadas, pilas, colas, tablas hash, árboles, montones y gráficos, que se pueden clasificar en dos dimensiones: "estructura lógica" y "estructura física".
Las estructuras lógicas se pueden dividir en dos categorías: "lineales" y "no lineales". La estructura lineal es más intuitiva, lo que significa que los datos se organizan linealmente en relaciones lógicas; la estructura no lineal es lo contrario y se organiza de forma no lineal.
- Estructuras de datos lineales : matrices, listas enlazadas, pilas, colas, tablas hash.
- Estructuras de datos no lineales : árboles, montones, gráficos, tablas hash.
Las estructuras de datos no lineales se pueden dividir en estructuras de árbol y estructuras de red.
- Estructuras lineales : matrices, listas enlazadas, colas, pilas, tablas hash, existe una relación secuencial uno a uno entre elementos.
- Estructura de árbol : árbol, montón, tabla hash y la relación entre elementos es de uno a muchos.
- Estructura de red : gráfico, existe una relación de muchos a muchos entre elementos.
La estructura física refleja la forma en que se almacenan los datos en la memoria de la computadora , que se puede dividir en almacenamiento en espacio continuo (matriz) y almacenamiento en espacio discreto (lista vinculada). La estructura física determina los métodos operativos de acceso, actualización, adición y eliminación de datos desde el nivel inferior, y al mismo tiempo muestra características complementarias en términos de eficiencia de tiempo y eficiencia de espacio.
Todas las estructuras de datos se implementan en base a matrices, listas vinculadas o una combinación de ambas . Por ejemplo, las pilas y colas se pueden implementar utilizando matrices o listas vinculadas; y una implementación de tabla hash puede incluir tanto matrices como listas vinculadas.
- Basado en matrices, se puede realizar : pila, cola, tabla hash, árbol, montón, gráfico, matriz, tensor (matriz con dimensión ≥ 3), etc.
- Según la lista vinculada, se puede realizar : pila, cola, tabla hash, árbol, montón, gráfico, etc.
Las estructuras de datos implementadas en base a matrices también se denominan "estructuras de datos estáticas", lo que significa que dichas estructuras de datos tienen una longitud inmutable después de la inicialización. En consecuencia, las estructuras de datos implementadas en base a listas enlazadas se denominan "estructuras de datos dinámicas" y, después de la inicialización, la longitud de este tipo de estructura de datos aún se puede ajustar durante la ejecución del programa.
formación
Una matriz es una estructura de datos lineal que almacena elementos del mismo tipo en un espacio de memoria contiguo. A la posición de un elemento en una matriz la llamamos índice de ese elemento.
inicialización
Pitón:
# 初始化数组
arr: list[int] = [0] * 5 # [ 0, 0, 0, 0, 0 ]
nums: list[int] = [1, 3, 2, 5, 4]
Ir:
/* 初始化数组 */
var arr [5]int
// 在 Go 中,指定长度时([5]int)为数组,不指定长度时([]int)为切片
// 由于 Go 的数组被设计为在编译期确定长度,因此只能使用常量来指定长度
// 为了方便实现扩容 extend() 方法,以下将切片(Slice)看作数组(Array)
nums := []int{
1, 3, 2, 5, 4}
elemento de acceso
Los elementos de la matriz se almacenan en un espacio de memoria contiguo, lo que significa que calcular la dirección de memoria de un elemento de la matriz es muy sencillo. Dada la dirección de memoria de la matriz (es decir, la dirección de memoria del primer elemento) y el índice de un elemento, podemos usar la fórmula que se muestra en la figura siguiente para calcular la dirección de memoria del elemento, accediendo así directamente a este elemento. .

Encontramos que el primer elemento de la matriz tiene índice 0, lo que parece contradictorio porque sería más natural empezar a contar desde 1. Pero desde la perspectiva de la fórmula de cálculo de direcciones, el significado del índice es esencialmente el desplazamiento de la dirección de memoria . El desplazamiento de dirección del primer elemento es 0, por lo que es razonable tener un índice de 0.
Acceder a los elementos de una matriz es muy eficiente: podemos acceder aleatoriamente a cualquier elemento de la matriz en un tiempo O (1).
Pitón:
def random_access(nums: list[int]) -> int:
"""随机访问元素"""
# 在区间 [0, len(nums)-1] 中随机抽取一个数字
random_index = random.randint(0, len(nums) - 1)
# 获取并返回随机元素
random_num = nums[random_index]
return random_num
Ir:
/* 随机访问元素 */
func randomAccess(nums []int) (randomNum int) {
// 在区间 [0, nums.length) 中随机抽取一个数字
randomIndex := rand.Intn(len(nums))
// 获取并返回随机元素
randomNum = nums[randomIndex]
return
}
insertar elemento
Los elementos de la matriz están "uno al lado del otro" en la memoria y no hay espacio entre ellos para almacenar datos. Como se muestra en la figura siguiente, si desea insertar un elemento en el medio de la matriz, debe mover todos los elementos después del elemento hacia atrás uno y luego asignar el elemento al índice.
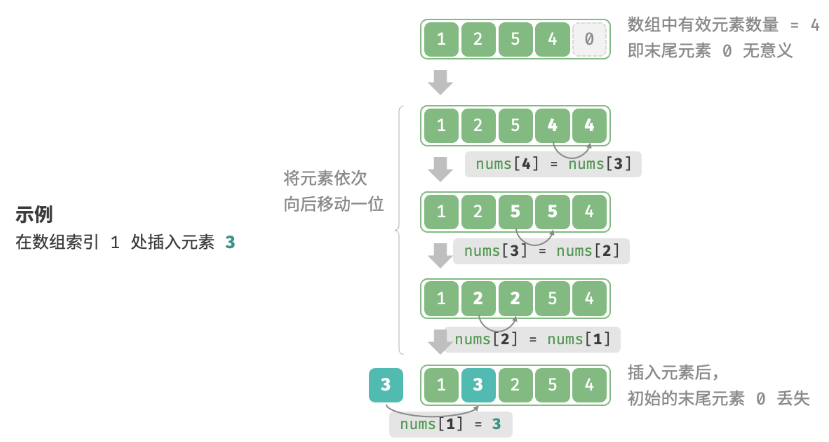
Dado que la longitud de la matriz es fija, insertar un elemento definitivamente resultará en la "pérdida" del elemento final de la matriz.
Pitón:
def insert(nums: list[int], num: int, index: int):
"""在数组的索引 index 处插入元素 num"""
# 把索引 index 以及之后的所有元素向后移动一位
for i in range(len(nums) - 1, index, -1):
nums[i] = nums[i - 1]
# 将 num 赋给 index 处元素
nums[index] = num
Ir:
/* 在数组的索引 index 处插入元素 num */
func insert(nums []int, num int, index int) {
// 把索引 index 以及之后的所有元素向后移动一位
for i := len(nums) - 1; i > index; i-- {
nums[i] = nums[i-1]
}
// 将 num 赋给 index 处元素
nums[index] = num
}
Eliminar elemento
Si desea eliminar el elemento en el índice i, debe mover todos los elementos después del índice i hacia adelante una posición.
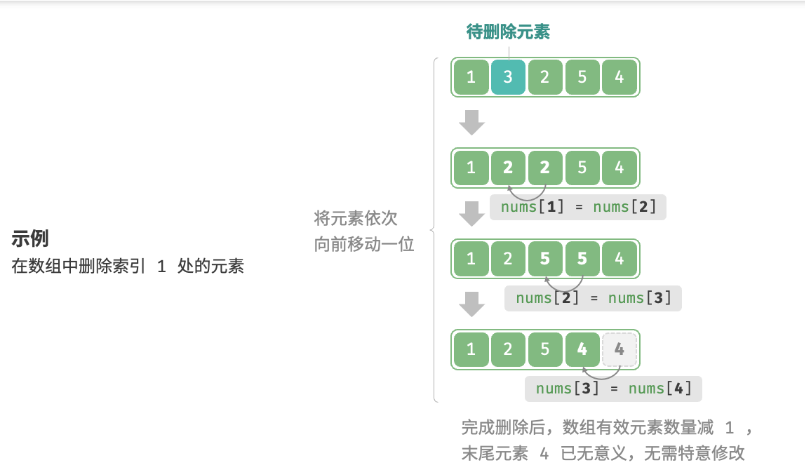
Pitón:
def remove(nums: list[int], index: int):
"""删除索引 index 处元素"""
# 把索引 index 之后的所有元素向前移动一位
for i in range(index, len(nums) - 1):
nums[i] = nums[i + 1]
Ir:
/* 删除索引 index 处元素 */
func remove(nums []int, index int) {
// 把索引 index 之后的所有元素向前移动一位
for i := index; i < len(nums)-1; i++ {
nums[i] = nums[i+1]
}
}
En general, las operaciones de inserción y eliminación de matrices tienen las siguientes desventajas.
- Alta complejidad temporal : la complejidad temporal promedio de la inserción y eliminación de matrices es O (n), donde n es la longitud de la matriz.
- Elementos faltantes : dado que la longitud de una matriz es inmutable, los elementos más allá de la longitud de la matriz se pierden después de insertar elementos.
- Desperdicio de memoria : Podemos inicializar una matriz relativamente larga y solo usar la primera parte, de modo que al insertar datos, los elementos que faltan al final "no tengan sentido", pero hacerlo también provocará un desperdicio de parte del espacio de memoria.
iterar sobre la matriz
Podemos recorrer la matriz por índice o recorrerla directamente para obtener cada elemento de la matriz.
Pitón:
def traverse(nums: list[int]):
"""遍历数组"""
count = 0
# 通过索引遍历数组
for i in range(len(nums)):
count += 1
# 直接遍历数组
for num in nums:
count += 1
# 同时遍历数据索引和元素
for i, num in enumerate(nums):
count += 1
Ir:
/* 遍历数组 */
func traverse(nums []int) {
count := 0
// 通过索引遍历数组
for i := 0; i < len(nums); i++ {
count++
}
count = 0
// 直接遍历数组
for range nums {
count++
}
}
encontrar elemento
Para encontrar un elemento específico en una matriz, es necesario recorrer la matriz. En cada ronda, se juzga si el valor del elemento coincide y, si coincide, se genera el índice correspondiente. Debido a que las matrices son estructuras de datos lineales, la operación de búsqueda anterior se denomina "búsqueda lineal".
Pitón:
def find(nums: list[int], target: int) -> int:
"""在数组中查找指定元素"""
for i in range(len(nums)):
if nums[i] == target:
return i
return -1
Ir:
/* 在数组中查找指定元素 */
func find(nums []int, target int) (index int) {
index = -1
for i := 0; i < len(nums); i++ {
if nums[i] == target {
index = i
break
}
}
return
}
Expandir matriz
En la mayoría de los lenguajes de programación, la longitud de una matriz es inmutable . Si queremos expandir la matriz, necesitamos volver a crear una matriz más grande y luego copiar los elementos de la matriz original a la nueva matriz uno por uno. Esta es una operación O (n), que requiere mucho tiempo cuando la matriz es grande.
Pitón:
def extend(nums: list[int], enlarge: int) -> list[int]:
"""扩展数组长度"""
# 初始化一个扩展长度后的数组
res = [0] * (len(nums) + enlarge)
# 将原数组中的所有元素复制到新数组
for i in range(len(nums)):
res[i] = nums[i]
# 返回扩展后的新数组
return res
Ir:
/* 扩展数组长度 */
func extend(nums []int, enlarge int) []int {
// 初始化一个扩展长度后的数组
res := make([]int, len(nums)+enlarge)
// 将原数组中的所有元素复制到新数组
for i, num := range nums {
res[i] = num
}
// 返回扩展后的新数组
return res
}
Acerca de las matrices
Las matrices se almacenan en un espacio de memoria contiguo y tienen el mismo tipo de elemento. Este enfoque contiene rica información a priori que el sistema puede utilizar para optimizar la eficiencia operativa de la estructura de datos.
- Alta eficiencia de espacio : las matrices asignan bloques de memoria contiguos para los datos sin una sobrecarga estructural adicional.
- Admite acceso aleatorio : las matrices permiten el acceso a cualquier elemento en tiempo O(1).
- Localidad de caché : cuando se accede a un elemento de la matriz, la computadora no solo lo carga, sino que también almacena en caché otros datos a su alrededor, utilizando así el caché para acelerar las operaciones posteriores.
El almacenamiento continuo de espacio es un arma de doble filo, que tiene las siguientes desventajas.
- La inserción y eliminación son ineficientes : cuando hay muchos elementos en la matriz, las operaciones de inserción y eliminación requieren mover una gran cantidad de elementos.
- Longitud inmutable : la longitud de la matriz se fija después de la inicialización. Para expandir la matriz, es necesario copiar todos los datos a una nueva matriz, lo cual es muy costoso.
- Desperdicio de espacio : si el tamaño de la matriz asignada es mayor de lo que realmente se necesita, entonces se desperdicia el espacio adicional.
Una matriz es una estructura de datos básica y común, se usa con frecuencia en varios algoritmos y también se puede usar para implementar varias estructuras de datos complejas.
- Acceso aleatorio : si queremos extraer algunas muestras al azar, podemos almacenarlas en una matriz, generar una secuencia aleatoria y realizar un muestreo aleatorio de muestras según el índice.
- Clasificación y búsqueda : las matrices son las estructuras de datos más utilizadas para ordenar y buscar algoritmos. La clasificación rápida, la clasificación por combinación, la búsqueda binaria, etc. se realizan principalmente en matrices.
- Tabla de búsqueda : cuando necesitamos encontrar rápidamente un elemento o necesitamos encontrar la correspondencia entre un elemento, podemos usar una matriz como tabla de búsqueda. Si queremos realizar la asignación de carácter a código ASCII, podemos usar el valor del código ASCII del carácter como índice y almacenar el elemento correspondiente en la posición correspondiente en la matriz.
- Aprendizaje automático : las operaciones de álgebra lineal entre vectores, matrices y tensores se utilizan ampliamente en redes neuronales y estos datos se construyen en forma de matrices. Las matrices son la estructura de datos más utilizada en la programación de redes neuronales.
- Implementación de estructura de datos : las matrices se pueden utilizar para implementar estructuras de datos como pilas, colas, tablas hash, montones y gráficos. Por ejemplo, la representación matricial de adyacencia de un gráfico es en realidad una matriz bidimensional.
lista enlazada
Una lista vinculada es una estructura de datos lineal en la que cada elemento es un objeto de nodo y cada nodo está conectado a través de "referencias". La referencia registra la dirección de memoria del siguiente nodo a través del cual se puede acceder al siguiente nodo desde el nodo actual. El diseño de la lista vinculada permite que cada nodo se almacene de forma dispersa en la memoria y no es necesario que sus direcciones de memoria sean consecutivas.
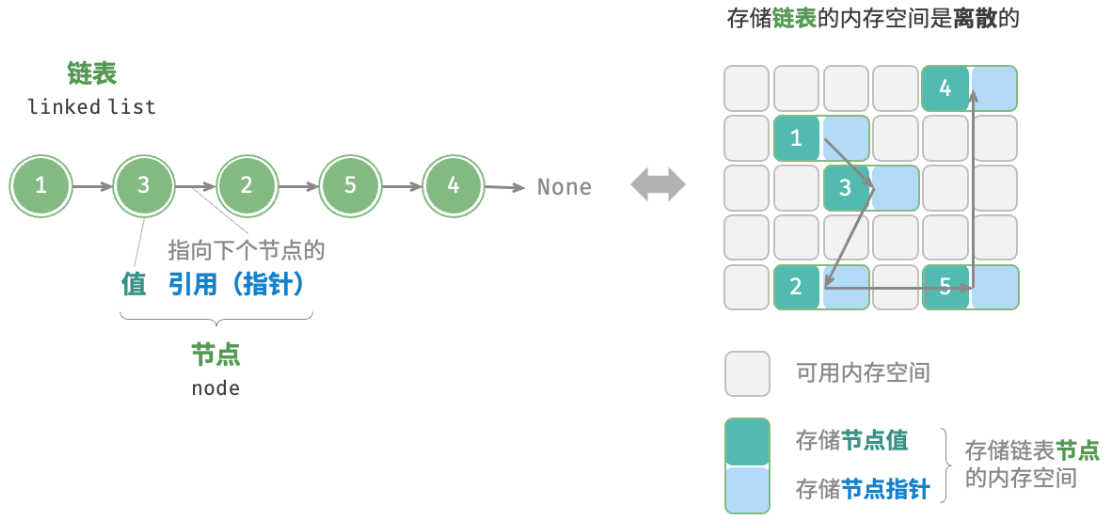
La unidad de la lista enlazada es el objeto nodo. Cada nodo contiene dos datos: el "valor" del nodo y una "referencia" al siguiente nodo.
- El primer nodo de la lista enlazada se denomina "nodo principal" y el último nodo se denomina "nodo de cola".
- El nodo de cola apunta a "nulo", que se registra como nulo, nullptr y Ninguno en Java, C++ y Python respectivamente.
- En lenguajes que admiten punteros, como C, C++, Go y Rust, la "referencia" anterior debe reemplazarse por "puntero".
Además de contener el valor, el nodo de la lista vinculada ListNodetambién necesita guardar una referencia adicional (puntero). Por lo tanto, para la misma cantidad de datos, una lista vinculada ocupa más espacio de memoria que una matriz .
Pitón:
class ListNode:
"""链表节点类"""
def __init__(self, val: int):
self.val: int = val # 节点值
self.next: Optional[ListNode] = None # 指向下一节点的引用
Ir:
/* 链表节点结构体 */
type ListNode struct {
Val int // 节点值
Next *ListNode // 指向下一节点的指针
}
// NewListNode 构造函数,创建一个新的链表
func NewListNode(val int) *ListNode {
return &ListNode{
Val: val,
Next: nil,
}
}
inicialización
Hay dos pasos para establecer una lista vinculada: el primer paso es inicializar cada objeto de nodo y el segundo paso es construir una relación de referencia. Una vez completada la inicialización, podemos comenzar desde el nodo principal de la lista vinculada y nextacceder a todos los nodos en secuencia a través de puntos de referencia.
Pitón:
# 初始化链表 1 -> 3 -> 2 -> 5 -> 4
# 初始化各个节点
n0 = ListNode(1)
n1 = ListNode(3)
n2 = ListNode(2)
n3 = ListNode(5)
n4 = ListNode(4)
# 构建引用指向
n0.next = n1
n1.next = n2
n2.next = n3
n3.next = n4
Ir:
/* 初始化链表 1 -> 3 -> 2 -> 5 -> 4 */
// 初始化各个节点
n0 := NewListNode(1)
n1 := NewListNode(3)
n2 := NewListNode(2)
n3 := NewListNode(5)
n4 := NewListNode(4)
// 构建引用指向
n0.Next = n1
n1.Next = n2
n2.Next = n3
n3.Next = n4
La matriz en su conjunto es una variable, por ejemplo, la matriz numscontiene elementos nums[0], nums[1]etc., mientras que la lista vinculada se compone de múltiples objetos de nodo independientes. Generalmente usamos el nodo principal como nombre representativo de una lista vinculada . Por ejemplo, la lista vinculada en el código anterior se puede registrar como una lista vinculada n0.
insertar nodo
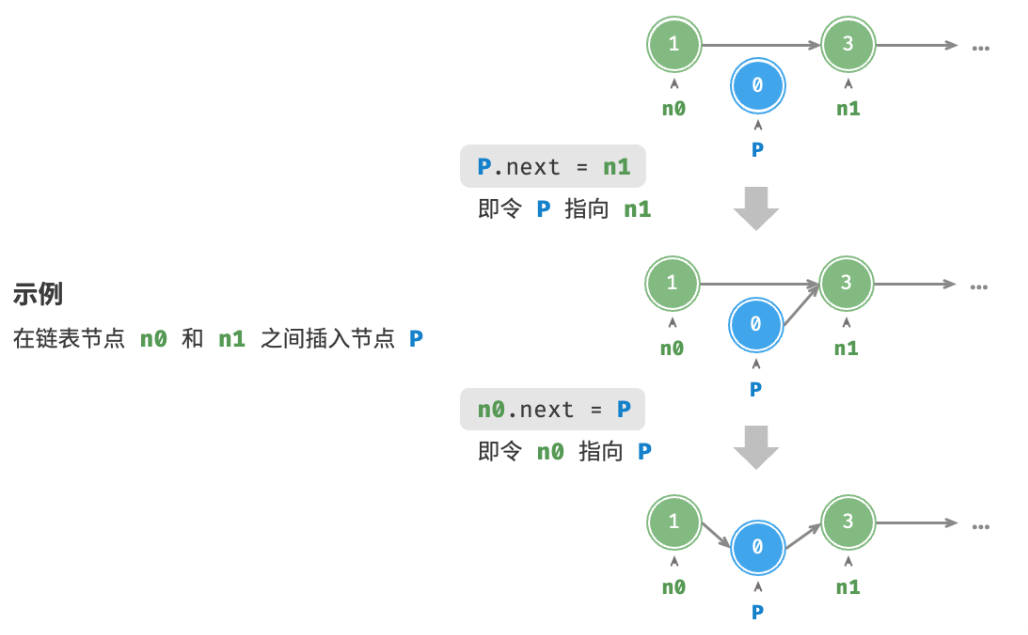
Insertar nodos en una lista vinculada es muy fácil. Como se muestra en la figura siguiente, supongamos que queremos insertar un nuevo nodo entre dos nodos adyacentes n0y , solo necesitamos cambiar dos referencias de nodo (punteros) , y la complejidad del tiempo es O (1).n1P
Por el contrario, la complejidad temporal de insertar elementos en una matriz es O (n), lo que es menos eficiente cuando se trata de grandes cantidades de datos.
Eliminar nodo
También es muy conveniente eliminar nodos en una lista vinculada, simplemente cambie la referencia (puntero) de un nodo .
PTenga en cuenta que, aunque el nodo todavía apunta a después de que se completa la operación de eliminación n1, en realidad es inaccesible para atravesar esta lista vinculada P, lo que significa que Pya no pertenece a la lista vinculada.
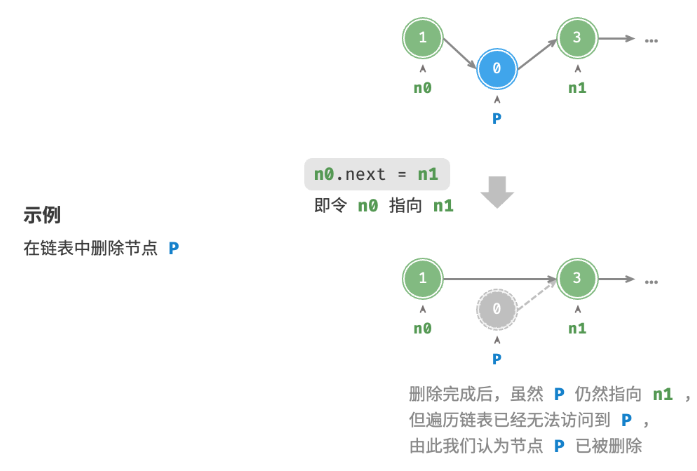
Pitón:
def remove(n0: ListNode):
"""删除链表的节点 n0 之后的首个节点"""
if not n0.next:
return
# n0 -> P -> n1
P = n0.next
n1 = P.next
n0.next = n1
Ir:
/* 删除链表的节点 n0 之后的首个节点 */
func removeNode(n0 *ListNode) {
if n0.Next == nil {
return
}
// n0 -> P -> n1
P := n0.Next
n1 := P.Next
n0.Next = n1
}
nodo de acceso
Acceder a los nodos en una lista vinculada es ineficiente . Como se mencionó en la sección anterior, podemos acceder a cualquier elemento de la matriz en tiempo O(1). Este no es el caso de las listas enlazadas: el programa debe comenzar desde el nodo principal y retroceder uno por uno hasta encontrar el nodo de destino. En otras palabras, acceder al i-ésimo nodo de la lista vinculada requiere i-1 rondas de bucle y la complejidad del tiempo es O (n).
Pitón:
def access(head: ListNode, index: int) -> ListNode | None:
"""访问链表中索引为 index 的节点"""
for _ in range(index):
if not head:
return None
head = head.next
return head
Ir:
/* 访问链表中索引为 index 的节点 */
func access(head *ListNode, index int) *ListNode {
for i := 0; i < index; i++ {
if head == nil {
return nil
}
head = head.Next
}
return head
}
encontrar nodo
Recorra la lista vinculada, busque targetel nodo con valor en la lista vinculada y genere el índice del nodo en la lista vinculada. Este proceso también es una búsqueda lineal.
Pitón:
def find(head: ListNode, target: int) -> int:
"""在链表中查找值为 target 的首个节点"""
index = 0
while head:
if head.val == target:
return index
head = head.next
index += 1
return -1
Ir:
/* 在链表中查找值为 target 的首个节点 */
func findNode(head *ListNode, target int) int {
index := 0
for head != nil {
if head.Val == target {
return index
}
head = head.Next
index++
}
return -1
}
Tipos comunes
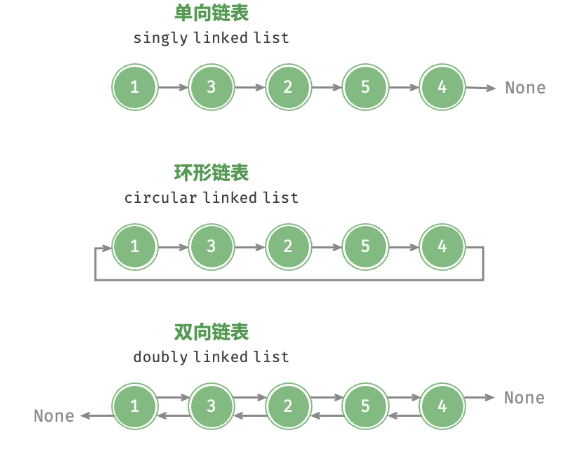
- Lista enlazada unidireccional : es decir, la lista enlazada ordinaria presentada anteriormente. Los nodos de una lista enlazada unidireccional contienen dos datos: un valor y una referencia al siguiente nodo. Llamamos al primer nodo nodo principal, al último nodo nodo de cola y el nodo de cola apunta a Ninguno.
- Lista enlazada circular : si hacemos que el nodo de cola de la lista enlazada unidireccional apunte al nodo principal (es decir, conectado de un extremo a otro), obtendremos una lista enlazada circular. En una lista enlazada circular, cualquier nodo puede considerarse como el nodo principal.
- Lista doblemente enlazada : en comparación con la lista simplemente enlazada, la lista doblemente enlazada registra referencias en ambas direcciones. La definición de nodo de una lista doblemente enlazada contiene referencias (punteros) tanto al nodo sucesor (siguiente nodo) como al nodo predecesor (nodo anterior). En comparación con las listas enlazadas unidireccionalmente, las listas doblemente enlazadas son más flexibles y pueden atravesar la lista enlazada en ambas direcciones, pero también requieren más espacio de memoria.
Pitón:
class ListNode:
"""双向链表节点类"""
def __init__(self, val: int):
self.val: int = val # 节点值
self.next: Optional[ListNode] = None # 指向后继节点的引用
self.prev: Optional[ListNode] = None # 指向前驱节点的引用
Ir:
/* 双向链表节点结构体 */
type DoublyListNode struct {
Val int // 节点值
Next *DoublyListNode // 指向后继节点的指针
Prev *DoublyListNode // 指向前驱节点的指针
}
// NewDoublyListNode 初始化
func NewDoublyListNode(val int) *DoublyListNode {
return &DoublyListNode{
Val: val,
Next: nil,
Prev: nil,
}
}
aplicación tipica
Las listas enlazadas unidireccionales se utilizan comúnmente para implementar estructuras de datos como pilas, colas, tablas hash y gráficos.
- Pila y cola : cuando las operaciones de inserción y eliminación se realizan en un extremo de la lista vinculada, muestra las características de primero en entrar, último en salir, correspondientes a la pila; cuando la operación de inserción se realiza en un extremo de la lista vinculada lista, y la operación de eliminación se realiza en el otro extremo de la lista vinculada, muestra La función primero en entrar, primero en salir corresponde a la cola.
- Tabla hash : el método de direcciones en cadena es una de las soluciones principales para resolver conflictos hash. En esta solución, todos los elementos en conflicto se colocarán en una lista vinculada.
- Gráfico : una lista de adyacencia es una forma común de representar un gráfico en el que cada vértice del gráfico está asociado con una lista vinculada, y cada elemento de la lista vinculada representa los otros vértices conectados a ese vértice.
Las listas doblemente enlazadas se utilizan a menudo en escenarios donde es necesario encontrar rápidamente los elementos anterior y siguiente.
- Estructuras de datos avanzadas : por ejemplo, en árboles rojo-negro y árboles B, necesitamos acceder al nodo principal del nodo, lo que se puede lograr guardando una referencia al nodo principal en el nodo, similar a una lista doblemente vinculada. .
- Historial del navegador : en un navegador web, cuando un usuario hace clic en el botón de avance o retroceso, el navegador necesita conocer las páginas web anteriores y siguientes que ha visitado el usuario. Las características de las listas doblemente enlazadas facilitan esta operación.
- Algoritmo LRU : en el algoritmo de desalojo de caché (LRU), necesitamos encontrar rápidamente los datos utilizados menos recientemente y admitir la rápida adición y eliminación de nodos. En este momento, es muy apropiado utilizar una lista doblemente enlazada.
Las listas enlazadas circulares se utilizan a menudo en escenarios que requieren operaciones periódicas, como la programación de recursos en el sistema operativo.
- Algoritmo de programación por turnos de intervalo de tiempo : en el sistema operativo, el algoritmo de programación por turnos de intervalo de tiempo es un algoritmo de programación de CPU común, que necesita recorrer un grupo de procesos. A cada proceso se le asigna un intervalo de tiempo y, cuando se agota el intervalo de tiempo, la CPU cambia al siguiente proceso. Esta operación cíclica se puede lograr a través de una lista enlazada circular.
- Búfer de datos : en algunas implementaciones de búfer de datos, también se pueden utilizar listas circulares enlazadas. Por ejemplo, en reproductores de audio y vídeo, el flujo de datos se puede dividir en múltiples bloques de búfer y colocar en una lista circular vinculada para lograr una reproducción perfecta.
Lista enlazada de matriz VS
| formación | lista enlazada | |
|---|---|---|
| Método de almacenamiento | espacio de memoria contiguo | espacio de memoria discreta |
| localidad de caché | amigable | antipático |
| Capacidad de expansión | Longitud inmutable | Flexible para expandirse |
| eficiencia de la memoria | Ocupa poca memoria y desperdicia algo de espacio. | Tomando mucha memoria |
| elemento de acceso | Acceso directo vía índice, O(1) | Necesidad de atravesar para encontrar, O (n) |
| Agregar elemento | Necesidad de mover elementos, O(n) | Inserción directa de nodos, O(1) |
| Eliminar elemento | Necesidad de mover elementos, O(n) | Eliminar nodos directamente, O(1) |
En comparación con las listas vinculadas, la razón por la cual las matrices son más amigables con la localidad de caché es que las matrices usan espacio de memoria continuo en la implementación. Puede usar el mecanismo de caché de la CPU para leer previamente los datos en la matriz, por lo que la eficiencia del acceso es mayor. Esto se debe a la existencia del principio de localidad del sistema operativo. Las características del espacio de almacenamiento continuo de la matriz aprovechan al máximo el principio de localidad, es decir, el caché de hardware acelera el acceso a la matriz, pero el Las características de almacenamiento discreto de la lista enlazada la condenan a no ser más rápida.
lista
La longitud de la matriz inmutable reduce la practicidad . Para solucionar este problema surgió una estructura de datos llamada matriz dinámica, que es una matriz de longitud variable, también llamada a menudo lista.
inicialización
Pitón:
# 初始化列表
# 无初始值
list1: list[int] = []
# 有初始值
list: list[int] = [1, 3, 2, 5, 4]
Ir:
/* 初始化列表 */
// 无初始值
list1 := []int
// 有初始值
list := []int{
1, 3, 2, 5, 4}
elemento de acceso
Las listas son esencialmente matrices, por lo que se puede acceder a los elementos y actualizarlos en tiempo O(1), lo cual es muy eficiente.
Pitón:
# 访问元素
num: int = list[1] # 访问索引 1 处的元素
# 更新元素
list[1] = 0 # 将索引 1 处的元素更新为 0
Ir:
/* 访问元素 */
num := list[1] // 访问索引 1 处的元素
/* 更新元素 */
list[1] = 0 // 将索引 1 处的元素更新为 0
Insertar y eliminar elementos
En comparación con las matrices, las listas pueden agregar y eliminar elementos libremente. La complejidad temporal de agregar elementos al final de la lista es O (1), pero la eficiencia de insertar y eliminar elementos sigue siendo la misma que la de la matriz, y la complejidad temporal es O (n).
Pitón:
# 清空列表
list.clear()
# 尾部添加元素
list.append(1)
list.append(3)
list.append(2)
list.append(5)
list.append(4)
# 中间插入元素
list.insert(3, 6) # 在索引 3 处插入数字 6
# 删除元素
list.pop(3) # 删除索引 3 处的元素
Ir:
/* 清空列表 */
list = nil
/* 尾部添加元素 */
list = append(list, 1)
list = append(list, 3)
list = append(list, 2)
list = append(list, 5)
list = append(list, 4)
/* 中间插入元素 */
list = append(list[:3], append([]int{
6}, list[3:]...)...) // 在索引 3 处插入数字 6
/* 删除元素 */
list = append(list[:3], list[4:]...) // 删除索引 3 处的元素
recorrer la lista
Pitón:
# 通过索引遍历列表
count = 0
for i in range(len(list)):
count += 1
# 直接遍历列表元素
count = 0
for n in list:
count += 1
Ir:
/* 通过索引遍历列表 */
count := 0
for i := 0; i < len(list); i++ {
count++
}
/* 直接遍历列表元素 */
count = 0
for range list {
count++
}
lista de empalmes
Dada una nueva lista list1, podemos concatenar la lista al final de la lista original.
Pitón:
# 拼接两个列表
list1: list[int] = [6, 8, 7, 10, 9]
list += list1 # 将列表 list1 拼接到 list 之后
Ir:
/* 拼接两个列表 */
list1 := []int{
6, 8, 7, 10, 9}
list = append(list, list1...) // 将列表 list1 拼接到 list 之后
lista ordenada
Pitón:
# 排序列表
list.sort() # 排序后,列表元素从小到大排列
Ir:
/* 排序列表 */
sort.Ints(list) // 排序后,列表元素从小到大排列
Implementación sencilla
Para profundizar la comprensión de cómo funciona la lista, intentemos implementar una versión simple de la lista, que incluya los siguientes tres diseños clave.
- Capacidad inicial : elija una capacidad inicial razonable de la matriz. En este ejemplo, elegimos 10 como capacidad inicial.
- Registro de cantidad : declare un tamaño variable para registrar el número actual de elementos en la lista y actualícelo en tiempo real a medida que se insertan y eliminan elementos. Con base en esta variable, podemos ubicar el final de la lista y determinar si es necesaria la expansión.
- Mecanismo de expansión : si la capacidad de la lista está llena cuando se insertan elementos, se requiere expansión. Primero cree una matriz más grande basada en la expansión múltiple y luego mueva todos los elementos de la matriz actual a la nueva matriz en secuencia. En este ejemplo, estipulamos que la matriz se ampliará cada vez a 2 veces el tamaño anterior.
Pitón:
class MyList:
"""列表类简易实现"""
def __init__(self):
"""构造方法"""
self.__capacity: int = 10 # 列表容量
self.__nums: list[int] = [0] * self.__capacity # 数组(存储列表元素)
self.__size: int = 0 # 列表长度(即当前元素数量)
self.__extend_ratio: int = 2 # 每次列表扩容的倍数
def size(self) -> int:
"""获取列表长度(即当前元素数量)"""
return self.__size
def capacity(self) -> int:
"""获取列表容量"""
return self.__capacity
def get(self, index: int) -> int:
"""访问元素"""
# 索引如果越界则抛出异常,下同
if index < 0 or index >= self.__size:
raise IndexError("索引越界")
return self.__nums[index]
def set(self, num: int, index: int):
"""更新元素"""
if index < 0 or index >= self.__size:
raise IndexError("索引越界")
self.__nums[index] = num
def add(self, num: int):
"""尾部添加元素"""
# 元素数量超出容量时,触发扩容机制
if self.size() == self.capacity():
self.extend_capacity()
self.__nums[self.__size] = num
self.__size += 1
def insert(self, num: int, index: int):
"""中间插入元素"""
if index < 0 or index >= self.__size:
raise IndexError("索引越界")
# 元素数量超出容量时,触发扩容机制
if self.__size == self.capacity():
self.extend_capacity()
# 将索引 index 以及之后的元素都向后移动一位
for j in range(self.__size - 1, index - 1, -1):
self.__nums[j + 1] = self.__nums[j]
self.__nums[index] = num
# 更新元素数量
self.__size += 1
def remove(self, index: int) -> int:
"""删除元素"""
if index < 0 or index >= self.__size:
raise IndexError("索引越界")
num = self.__nums[index]
# 索引 i 之后的元素都向前移动一位
for j in range(index, self.__size - 1):
self.__nums[j] = self.__nums[j + 1]
# 更新元素数量
self.__size -= 1
# 返回被删除元素
return num
def extend_capacity(self):
"""列表扩容"""
# 新建一个长度为原数组 __extend_ratio 倍的新数组,并将原数组拷贝到新数组
self.__nums = self.__nums + [0] * self.capacity() * (self.__extend_ratio - 1)
# 更新列表容量
self.__capacity = len(self.__nums)
def to_array(self) -> list[int]:
"""返回有效长度的列表"""
return self.__nums[: self.__size]
Ir:
/* 列表类简易实现 */
type myList struct {
numsCapacity int
nums []int
numsSize int
extendRatio int
}
/* 构造函数 */
func newMyList() *myList {
return &myList{
numsCapacity: 10, // 列表容量
nums: make([]int, 10), // 数组(存储列表元素)
numsSize: 0, // 列表长度(即当前元素数量)
extendRatio: 2, // 每次列表扩容的倍数
}
}
/* 获取列表长度(即当前元素数量) */
func (l *myList) size() int {
return l.numsSize
}
/* 获取列表容量 */
func (l *myList) capacity() int {
return l.numsCapacity
}
/* 访问元素 */
func (l *myList) get(index int) int {
// 索引如果越界则抛出异常,下同
if index < 0 || index >= l.numsSize {
panic("索引越界")
}
return l.nums[index]
}
/* 更新元素 */
func (l *myList) set(num, index int) {
if index < 0 || index >= l.numsSize {
panic("索引越界")
}
l.nums[index] = num
}
/* 尾部添加元素 */
func (l *myList) add(num int) {
// 元素数量超出容量时,触发扩容机制
if l.numsSize == l.numsCapacity {
l.extendCapacity()
}
l.nums[l.numsSize] = num
// 更新元素数量
l.numsSize++
}
/* 中间插入元素 */
func (l *myList) insert(num, index int) {
if index < 0 || index >= l.numsSize {
panic("索引越界")
}
// 元素数量超出容量时,触发扩容机制
if l.numsSize == l.numsCapacity {
l.extendCapacity()
}
// 将索引 index 以及之后的元素都向后移动一位
for j := l.numsSize - 1; j >= index; j-- {
l.nums[j+1] = l.nums[j]
}
l.nums[index] = num
// 更新元素数量
l.numsSize++
}
/* 删除元素 */
func (l *myList) remove(index int) int {
if index < 0 || index >= l.numsSize {
panic("索引越界")
}
num := l.nums[index]
// 索引 i 之后的元素都向前移动一位
for j := index; j < l.numsSize-1; j++ {
l.nums[j] = l.nums[j+1]
}
// 更新元素数量
l.numsSize--
// 返回被删除元素
return num
}
/* 列表扩容 */
func (l *myList) extendCapacity() {
// 新建一个长度为原数组 extendRatio 倍的新数组,并将原数组拷贝到新数组
l.nums = append(l.nums, make([]int, l.numsCapacity*(l.extendRatio-1))...)
// 更新列表容量
l.numsCapacity = len(l.nums)
}
/* 返回有效长度的列表 */
func (l *myList) toArray() []int {
// 仅转换有效长度范围内的列表元素
return l.nums[:l.numsSize]
}