
Introducción
Shuhai Supply Chain es una empresa de servicios de cadena de suministro de catering que integra ventas, investigación y desarrollo, adquisiciones, producción, control de calidad, almacenamiento, transporte, información y finanzas. A principios de 2021, el equipo de investigación y desarrollo de tecnología de big data del Centro de tecnología de la información de Shuhai comenzó a probar el uso de DolphinScheduler como herramienta de sistema de programación de tareas para el centro de datos y varios proyectos de productos comerciales. Este artículo comparte principalmente la exploración e innovación de Shuhai Supply Chain en la implementación temprana de versiones antiguas de Dolphin y su experiencia en el proceso de actualización e implementación en las versiones principales. Espero que sea inspirador y útil para todos.
Sobre el Autor

Du Quan, ingeniero de big data de la cadena de suministro de Shuhai, participó en la construcción de la plataforma de big data y la plataforma intermedia de datos de Shuhai.
Introducción a los antecedentes empresariales
El negocio principal de nuestra empresa se muestra en la siguiente figura:
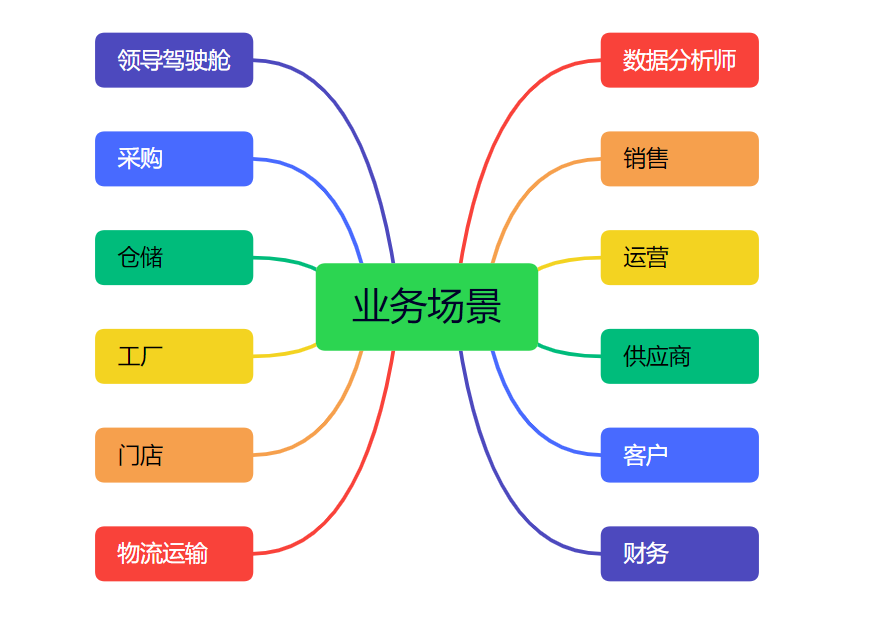
- Cabina de liderazgo: proporciona análisis de datos casi en tiempo real para que los líderes senior los vean, análisis comerciales T+1, ganancias brutas del producto, precio de mercado y otros informes.
- Finanzas: informes diarios varios, informes mensuales, informes anuales; conciliaciones, estados de utilidad bruta, tablas de indicadores, etc.
- Ventas de clientes: informes de ventas y adquisiciones de clientes en tiempo real, análisis de datos diarios y mensuales en varias dimensiones y consulta de datos detallados de ventas
- Categoría de proveedor: análisis de adquisiciones, informe de consulta, nivel de proveedor, banco de trabajo de proveedores, análisis de conciliación de proveedores, optimización de la estrategia de adquisiciones, etc.
- Almacenamiento: varios indicadores de datos dimensionales y requisitos de informes, como rotación de inventario, ubicaciones de almacenamiento e inventario en tiempo real.
- Logística y transporte: análisis de puntualidad, control de temperatura, costos de transporte, programación, etc.
- Analista de datos: responda rápidamente a diversas necesidades de análisis de datos y diversas necesidades de datos temporales de los líderes senior, minería de datos y diversos análisis interactivos en tiempo real.
- Cada operación comercial/estrategia/persona a cargo: verifique principalmente la situación general de cada operación comercial y consulte los datos agregados en tiempo real de varias dimensiones de cada negocio en el centro de datos.
- Además de algunas otras necesidades de análisis e informes de datos comerciales.
Experiencia de actualización integrada
En el proceso de construcción del centro de datos, los buenos componentes de programación de big data a menudo pueden lograr el doble de resultado con la mitad de esfuerzo. Nuestro equipo es muy consciente de esto, por lo que elegimos Dolphin Scheduling como sistema de programación para el centro de datos de la cadena de suministro de Shuhai, y Después de comenzar desde la etapa de transformación de implementación de integración de acoplamiento v1 .3.6 a la etapa de transformación de implementación de integración de desacoplamiento v3.1.8. Durante este proceso, se encontraron varios problemas y se proporcionaron soluciones de manera oportuna. Las compartiré ahora, esperando que pueda ayudar .A todos mis amigos.
Integración de la versión anterior de programación de Dolphin
La versión anterior integrada por el equipo fue la v1.3.6, que se ha estado ejecutando de manera estable en el entorno de producción durante más de dos años. Aquí presentamos brevemente los detalles de la integración en el centro de datos y los puntos débiles causados por el fuerte aumento en volumen de negocios.
(1) Los servicios API y la transformación de la interfaz de usuario están integrados en la plataforma intermedia
- Transformación de la interfaz de usuario
Basado en el desarrollo secundario del proyecto Dolphinscheduler-ui (con una gran cantidad de cambios), se adapta el estilo de la plataforma intermedia y se adaptan varios menús de programación de Dolphin (página de inicio, gestión de proyectos, centro de recursos, centro de fuente de datos, centro de monitoreo). y centro de seguridad) están integrados en la plataforma intermedia y unificados en la puerta de enlace de enrutamiento de Taiwán.

- Transformación del servicio de interfaz API backend
Basado en el desarrollo secundario del proyecto Dolphinscheduler-api, integra la transformación del sistema de usuario intermedio. Los puntos centrales de transformación son los siguientes:
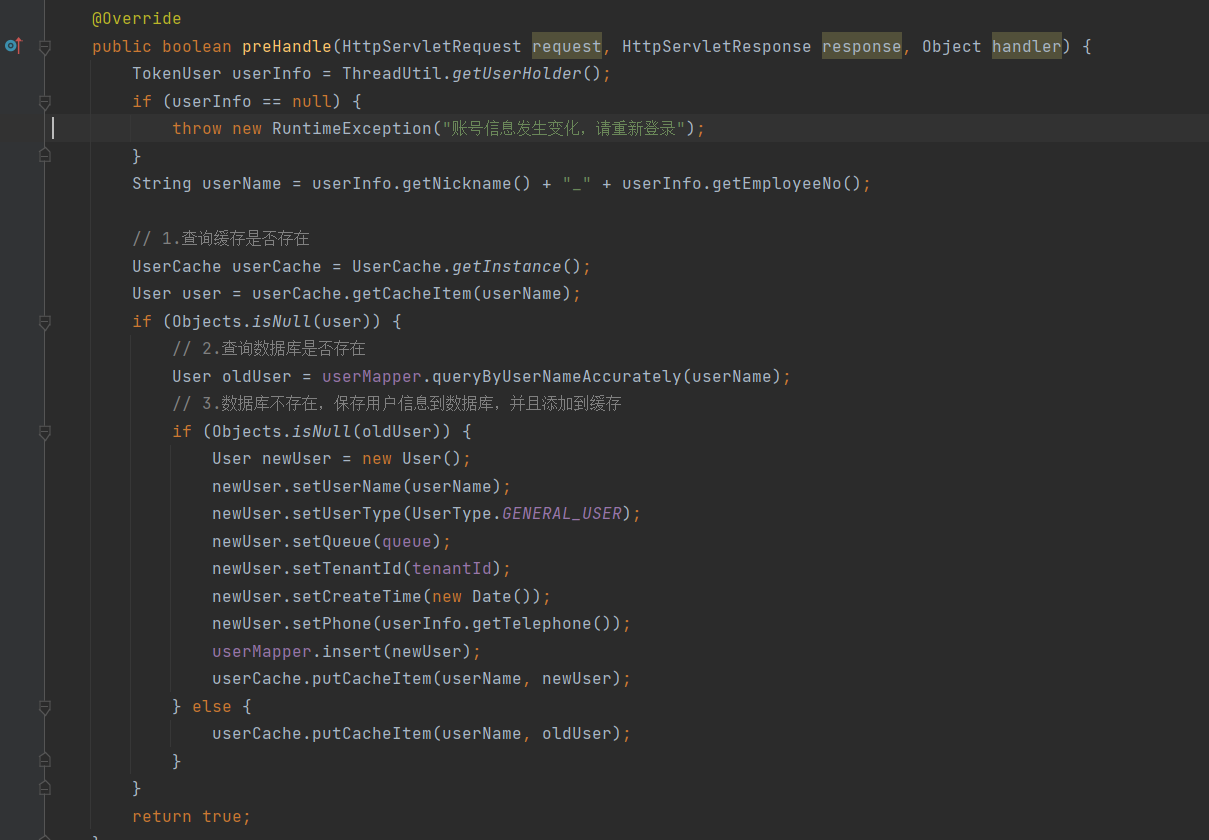
① Punto de mejora 1: reconstrucción del método preHandle () de la clase interceptora LoginHandlerInterceptor
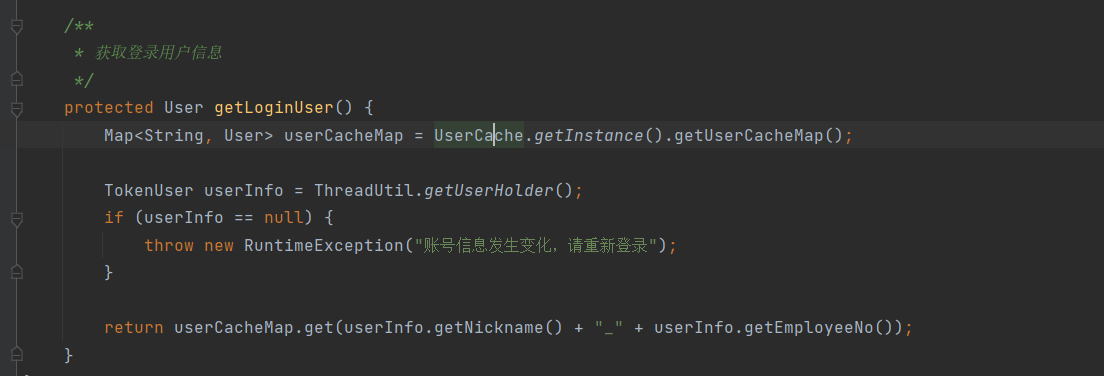
② Punto de modificación 2: se agrega el método de interfaz de cada clase de capa de control del Controlador para obtener el método de inicio de sesión del usuario getLoginUser().
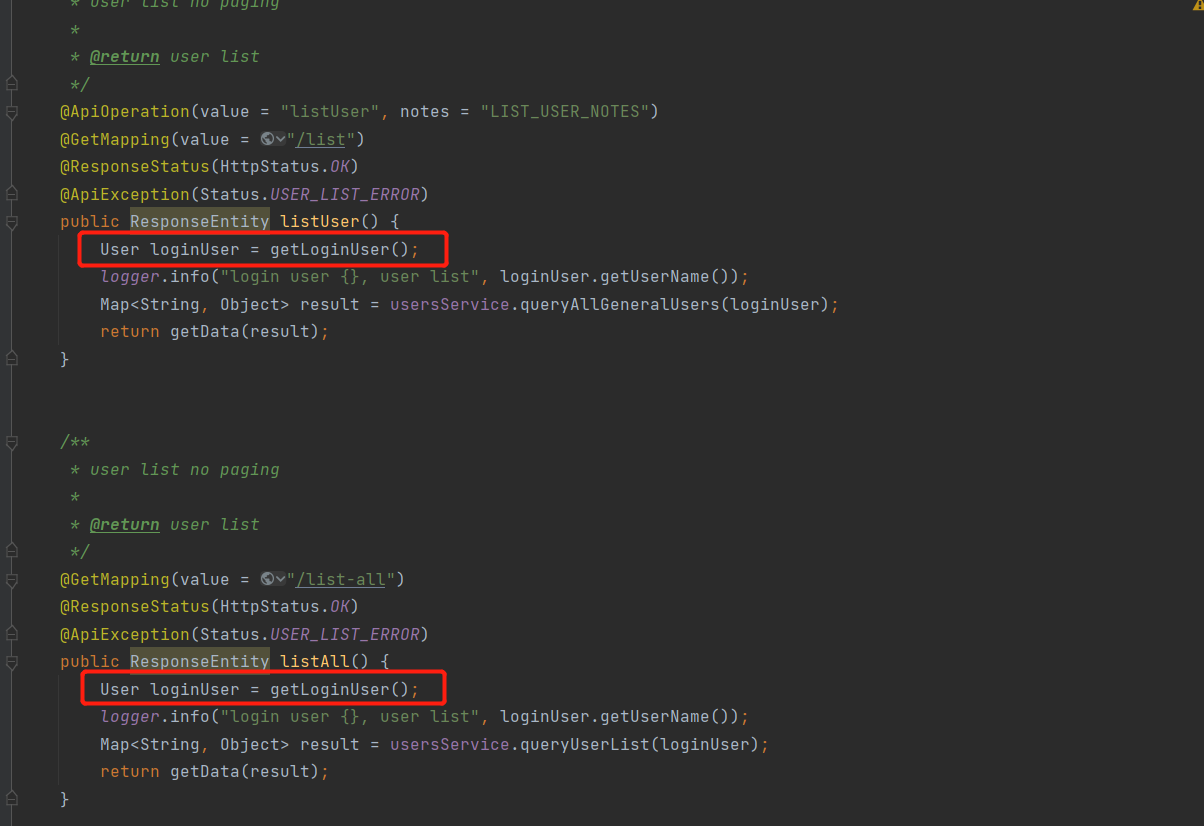
③ Punto de modificación 3: Modificación de los datos de devolución y los métodos de datos de paginación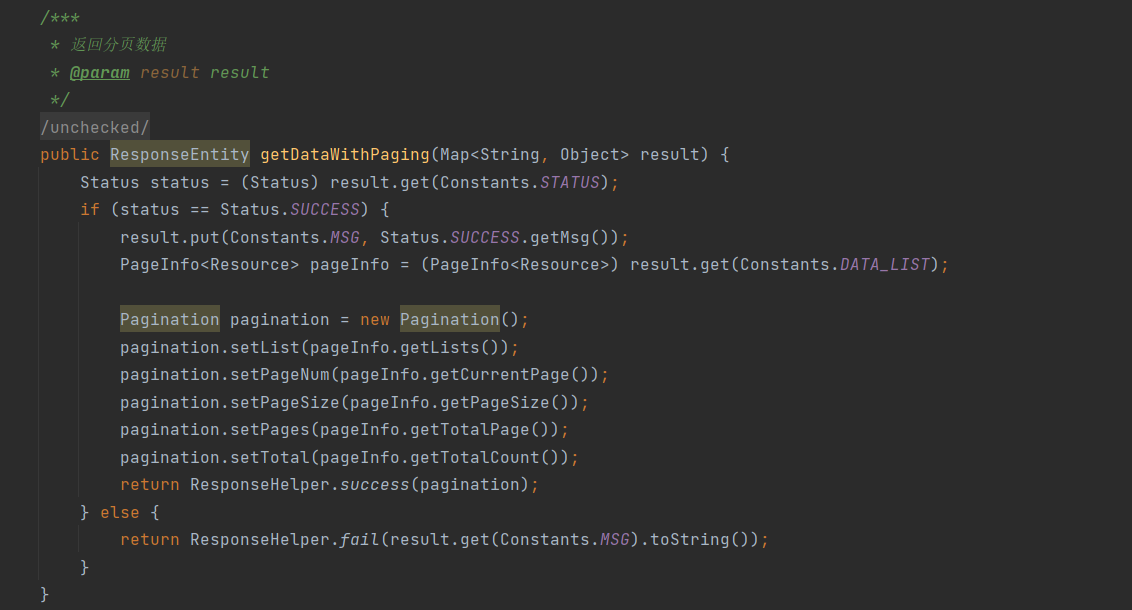
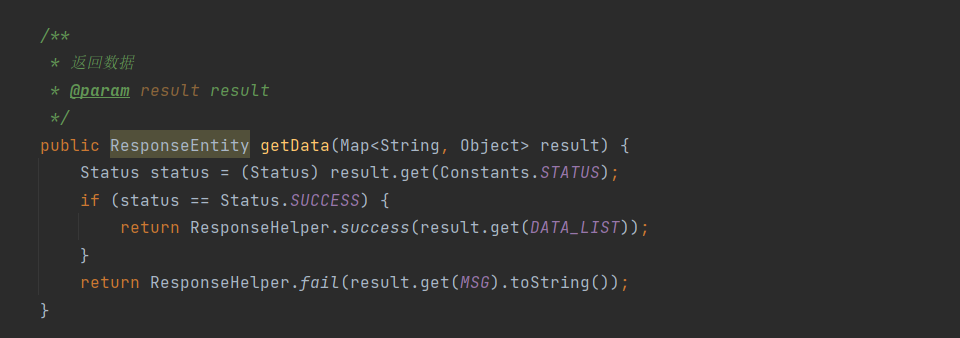
(2) Transformación de alarma para agregar alarmas de DingTalk
La versión v1.3.6 solo admite dos tipos de grupos de alarma: correo electrónico y SMS. La empresa suele recibir información de alarmas a través de DingTalk, por lo que necesita integrar los tipos de alarmas de DingTalk. Los puntos centrales de transformación son los siguientes:
① Paso 1 : Definir la clase de complemento de alarma DingAlertPlugin DingTalk para implementar la interfaz, la anulación getId()y los métodos de AlertPlugingetName()process()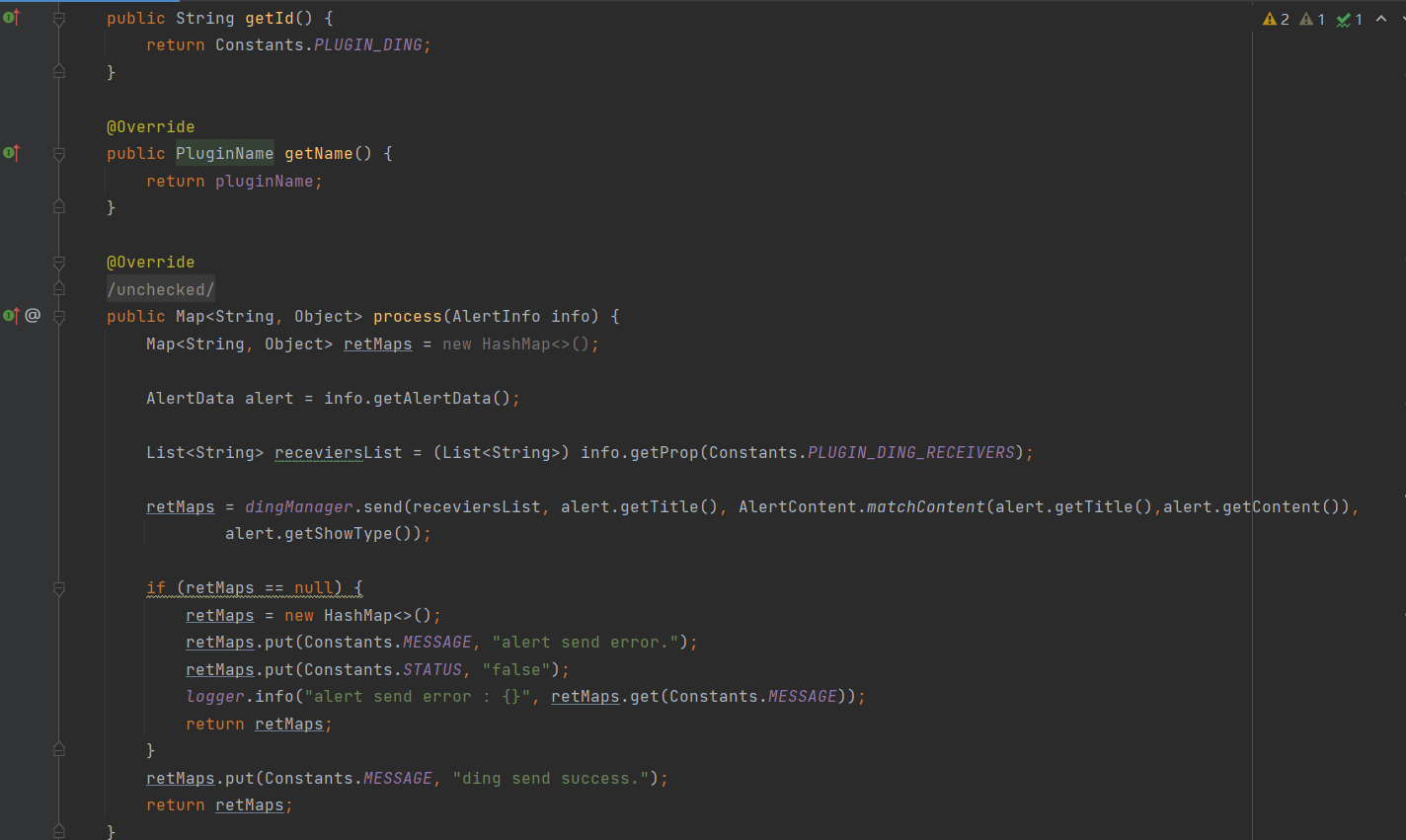
② Paso 2: Definir DingManager la clase de gestión de envío DingTalk 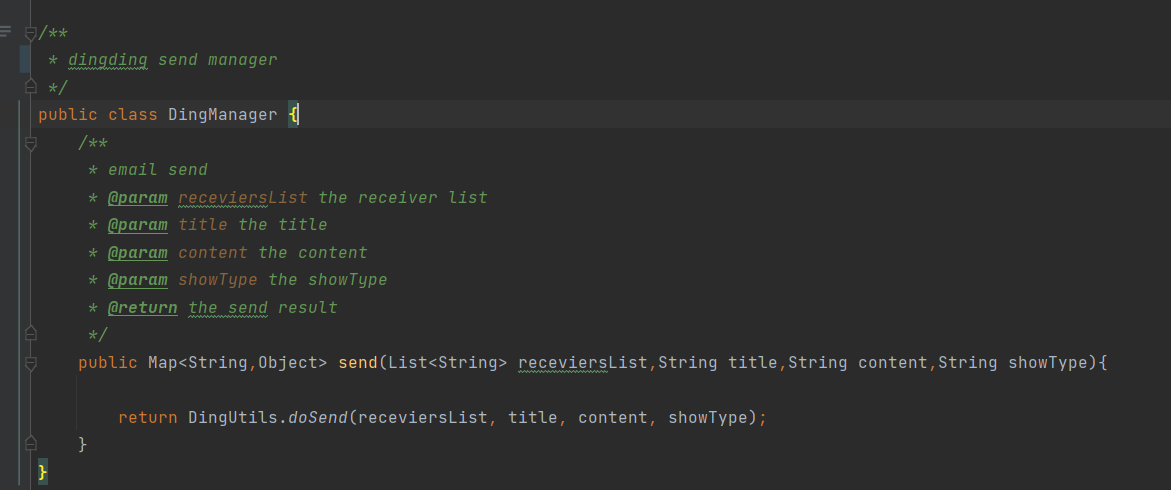 ③ Paso 3: Escribir la clase de herramienta de envío de mensajes DingTalk de DingUtils DingTalk
③ Paso 3: Escribir la clase de herramienta de envío de mensajes DingTalk de DingUtils DingTalk 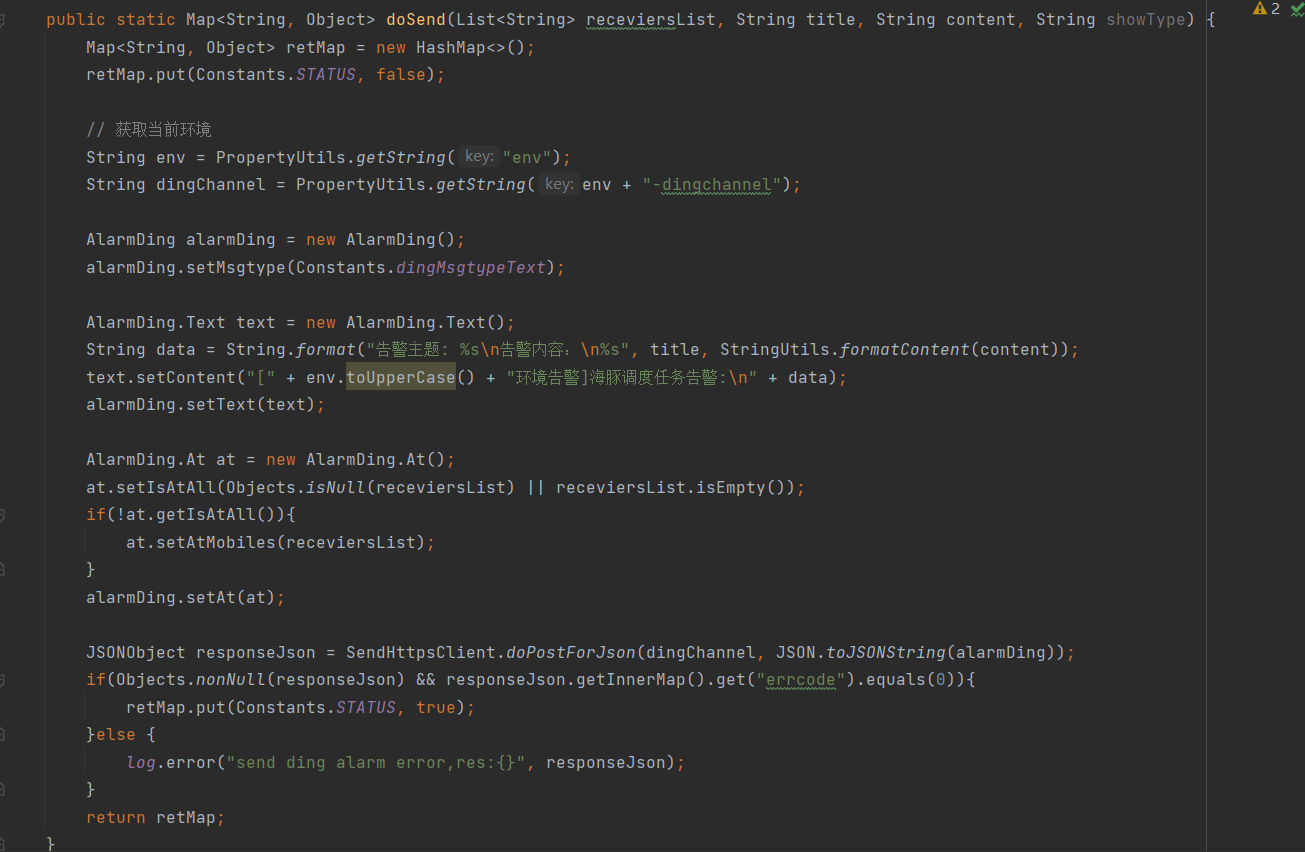 ④ Paso 4: Registrar el complemento de alarma DingTalk con AlertServer
④ Paso 4: Registrar el complemento de alarma DingTalk con AlertServer 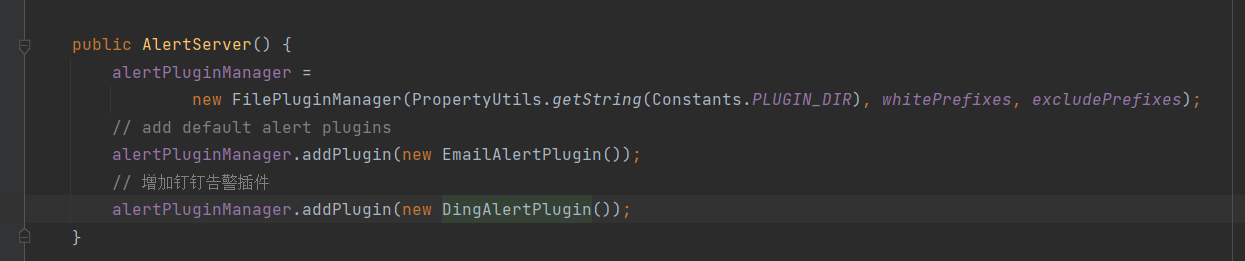 ⑤ Paso 5: Empaquetar, implementar y modificar
⑤ Paso 5: Empaquetar, implementar y modificardolphinscheduler-daemon.sh 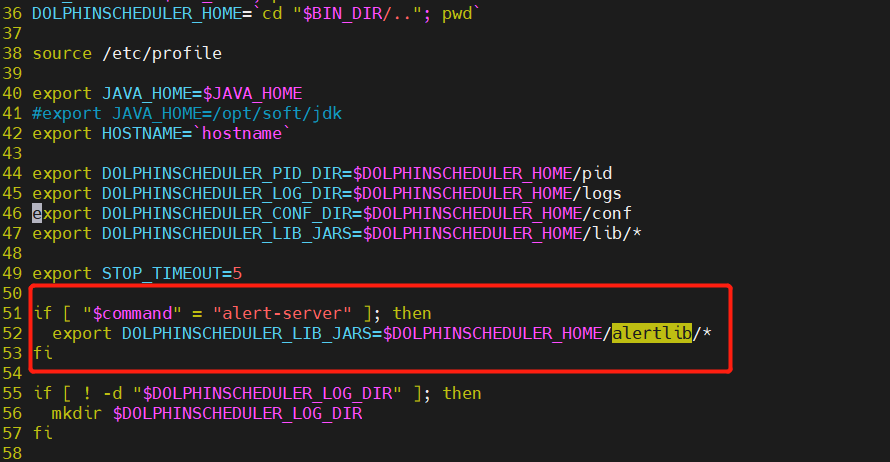
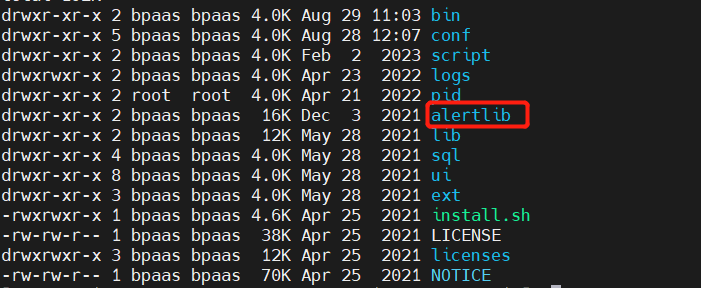
El empaquetado y la implementación se basan en una lógica de modificación específica, simplemente modifique dolphinscheduler-alert-1.3.6.jary empaquete los dos paquetes aquí. dolphinscheduler-dao-1.3.6.jarAdemás, agregue la carpeta alertlib a la ruta de instalación y agregue la lógica de carga alter-server a Dolphinscheduler-daemon.sh.
(3) Visualización de resultados de integración
El menú integrado del centro de datos es consistente con la v1.3.6 Dolphin Scheduling, que incluye principalmente: página de inicio, gestión de proyectos, centro de recursos, centro de fuente de datos, centro de monitoreo y centro de seguridad.Estos menús están integrados en nuestro centro de datos, y el El front-end está en la plataforma Puerta de enlace de enrutamiento unificado.
(4) Puntos débiles comerciales de la versión anterior v1.3.6
La tabla de definición de flujo de trabajo
process_definition_jsontiene campos JSON grandes y el acoplamiento entre tareas y flujo de trabajo es alto. El análisis de JSON requiere mucho rendimiento y las tareas no se pueden reutilizar; de lo contrario, generará una gran cantidad de datos redundantes, rendimiento deficiente y consumo grave de recursos.La actualización es difícil. La integración de 1.3.6 en el sistema de datos de extremo medio es equivalente al segundo desarrollo de servicios API. Integra el sistema de usuario de extremo medio y utiliza una puerta de enlace de enrutamiento unificado. Cada vez que los componentes de la interfaz de usuario de front-end se actualizan, aparecerán varios estilos de interfaz en Dolphin Scheduling. Problemas (el subflujo de trabajo SUB_PROCESS no se puede ingresar en este subnodo), la visualización del menú está incompleta, los registros no se pueden ver en pantalla completa, la página de inicio del proyecto no se puede deslizar hacia arriba y hacia abajo , etc. Una serie de problemas de interacción de la interfaz de usuario.
Los parámetros personalizados entre tareas no pueden depender del paso de parámetros
No existe una estrategia de ejecución de tareas para las tareas de instancias de flujo de trabajo que se cruzan. El valor predeterminado es el procesamiento paralelo, que no garantiza el modo singleton. Por ejemplo, cuando la frecuencia de programación es alta, la instancia de flujo de trabajo anterior aún no se ha ejecutado y la siguiente comienza de nuevo, provocando confusión e inexactitud en los datos.
Viene con calidad de datos a partir de 3.0.0
Admite múltiples tipos de complementos de alarma, grupos de alarmas y administración de instancias (no limitado a DingTalk), a partir de 3.0.0
Principales ajustes y optimizaciones en la interfaz de usuario.
En vista de los puntos débiles comerciales de la primera versión de integración v1.3.6 y superiores, es particularmente importante actualizar y reconstruir el método de integración.
Actualización de nueva versión de envío de delfines
Los puntos débiles que enfrentan los analistas de datos en la versión v1.3.6 durante el proceso de transferencia del análisis de negocios. Combinado con las mejores características de la nueva versión de Dolphin Scheduling, es urgente actualizar a la versión más nueva. El siguiente es un resumen de nuestros Integración de Dolphin Scheduling en el centro de datos y el proceso de actualización. Permítanme presentarles los detalles. Espero que les resulte útil cuando se encuentren con actualizaciones entre versiones.
(1) La nueva versión (v3.1.1) está integrada en el centro
- La arquitectura general del Proyecto de Oficina Intermedia de Integración de Programación Dolphin
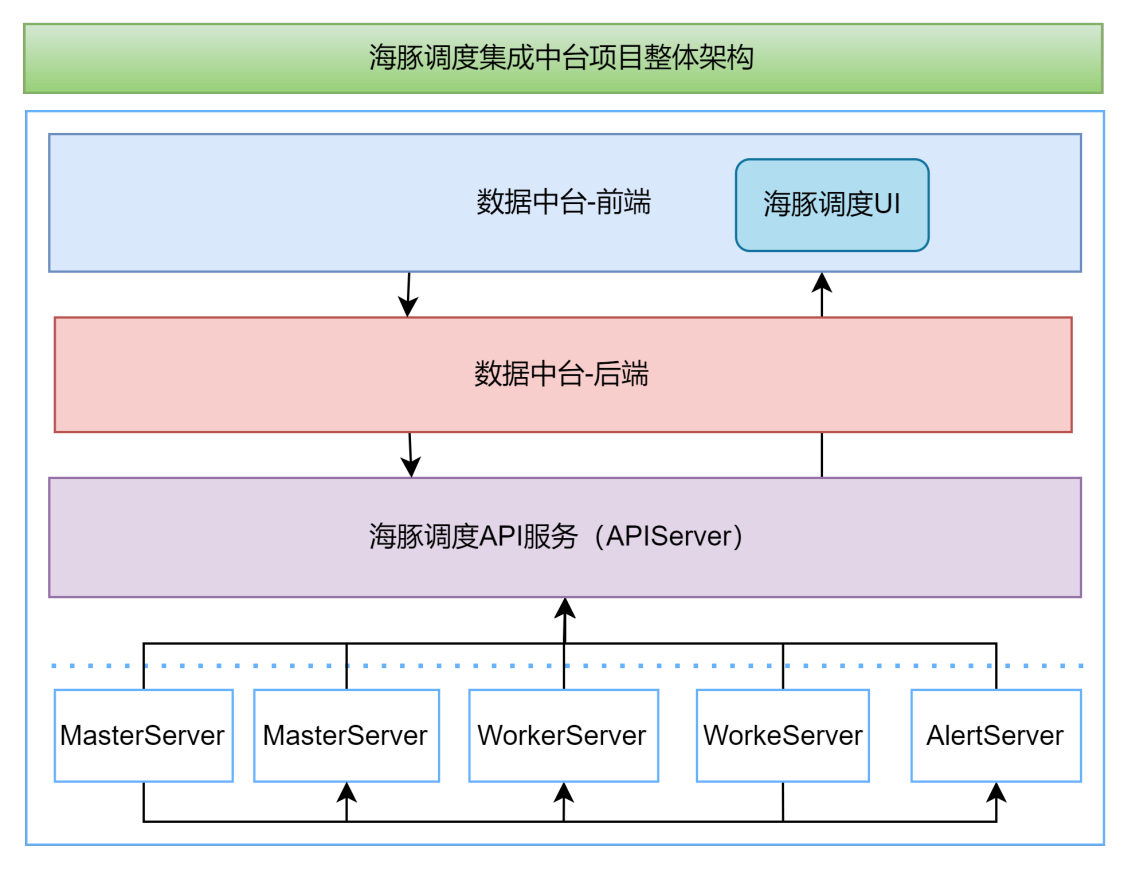
Dividido principalmente en: centro de datos-front-end, centro de datos-back-end, servicio API de programación Dolphin y clúster.
- Proceso de llamada de plataforma intermedia integrada de programación Dolphin
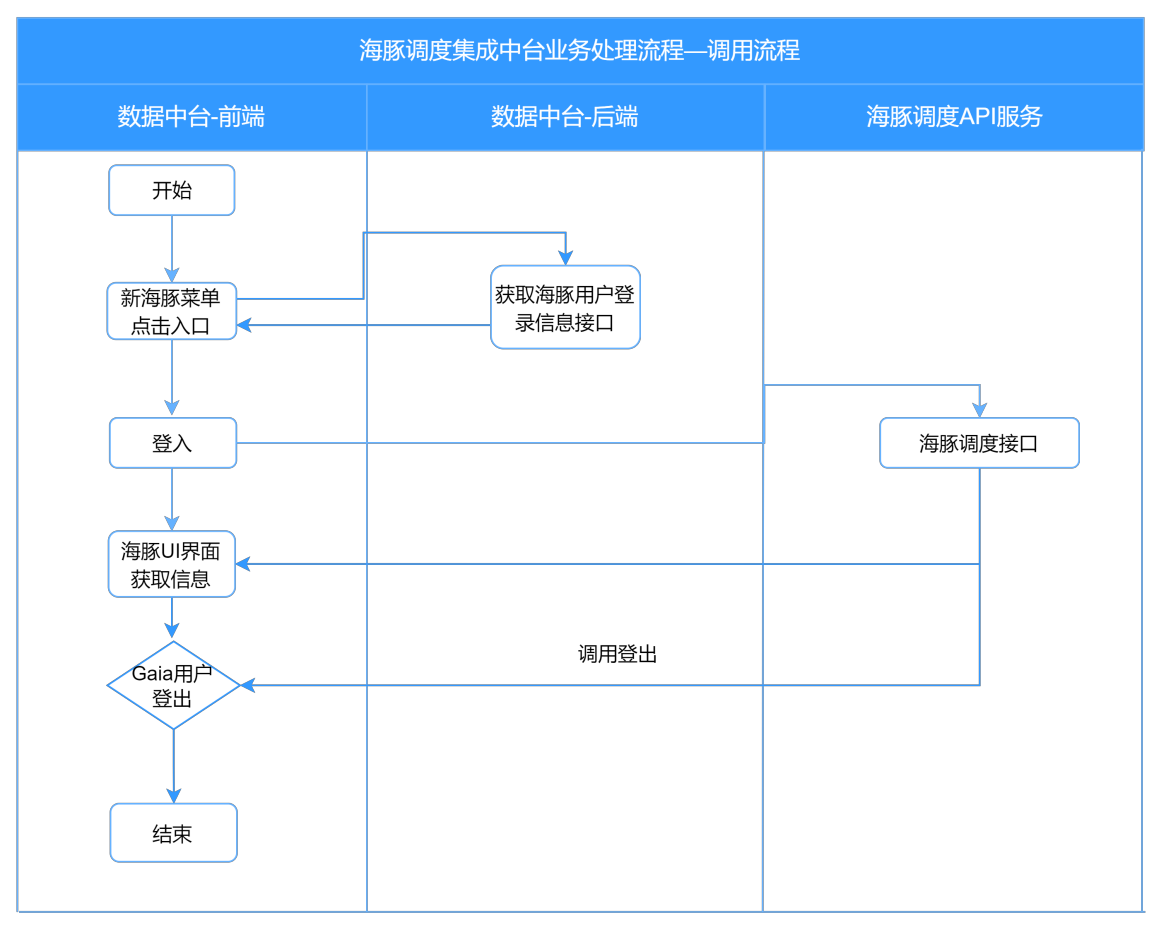
Proceso principal: centro de datos: solicitud de front-end para abrir el menú de programación de Dolphin -> llame al backend del centro de datos para obtener la interfaz de información de inicio de sesión del usuario de programación de Dolphin -> devolver nombre de usuario y contraseña -> iniciar sesión en el sistema de programación de Dolphin -> centro de datos: solicitud frontal para salir de la plataforma Cuenta->Interfaz de programación Dolphin Interfaz de cierre de sesión->Salir del sistema
- Modelo de datos y detalles de diseño.
Programación Dolphin Proyecto de centro de datos integrado Diseño de modelo de usuario intermedio
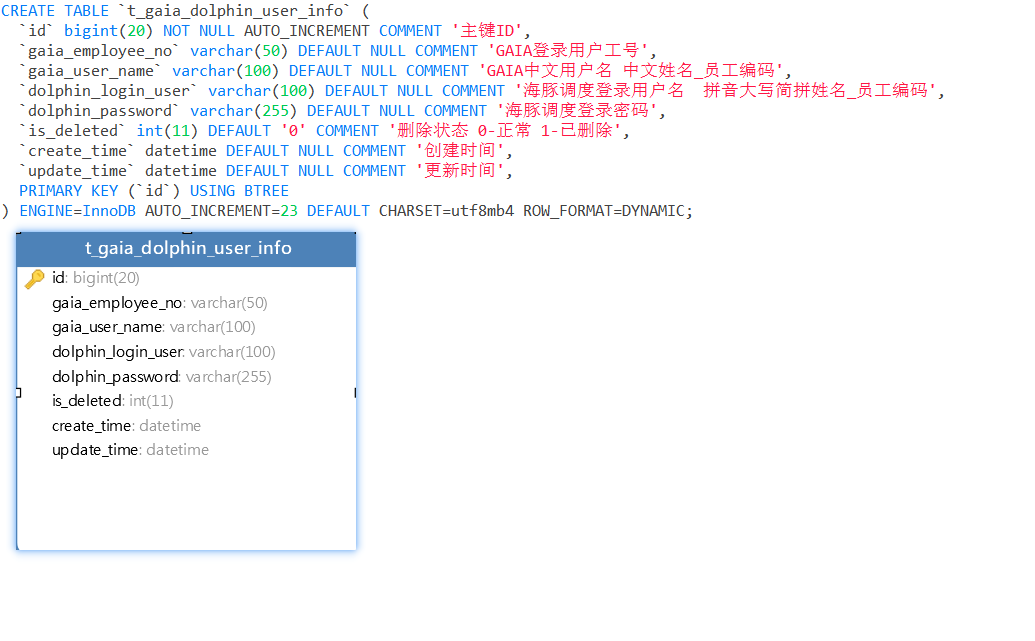
El propósito del diseño del modelo es establecer la relación entre el centro de datos y los usuarios de programación de Dolphin, de modo que después de que los usuarios del centro de datos inicien sesión, puedan obtener la información de inicio de sesión de usuario de programación de Dolphin correspondiente e iniciar sesión exitosamente cuando hagan clic en Dolphin. menú de programación.
(2) Migración continua de v1.3.6 y actualización a v3.1.8+
Aquí tomo la versión actualizada v1.3.6 de nuestro entorno de producción como punto de partida y actualizo iterativamente las versiones v2.0.0->2.0.9>3.0.0>3.1.0->3.18. Puede haber menos problemas, porque después Después de todo, el script update_schema.sh proporcionado por el sitio web oficial es adecuado para versiones pequeñas y la compatibilidad con versiones grandes no es perfecta.
Durante el proceso de actualización, parte del código fuente debe modificarse para una actualización compatible en v2.0.0, y el script ddl correspondiente al esquema debe modificarse para una actualización compatible en otras versiones. El proceso de actualización principal se resume a continuación:
- Descargue el paquete de instalación de actualización de destino (requiere la descarga del paquete de código fuente de actualización continua y del paquete binario)
Descargue todos los paquetes de instalación binarios de la nueva versión estable (versión que se actualizará) y coloque los paquetes binarios en una ruta diferente a la del servicio anterior de DolphinScheduler actual. Los pasos de actualización deben realizarse en el directorio de la nueva versión.

Nota: Si es necesario actualizar las versiones principales, especialmente las versiones v2.0.0, debe descargar el paquete de código fuente 2.0.0. Para modificaciones, consulte (3)
- Copia de seguridad de metadatos de Dolphin Scheduler (obtener script SQL de versión anterior de producción)
Vuelque desde el entorno de producción o utilice el comando de volcado para hacer una copia de seguridad del archivo de script de la base de datos. Se pueden omitir algunos datos de la tabla de registro no esenciales, pero es necesario realizar una copia de seguridad de la estructura de la tabla.
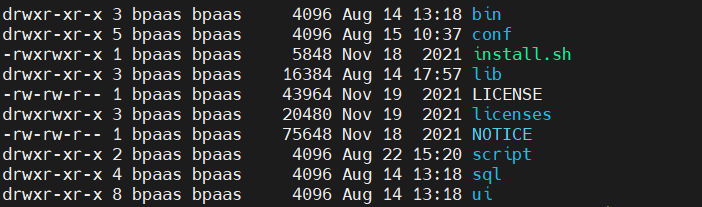
- Modificar el archivo de configuración de la versión actualizada.
Según la versión, se divide en ≤v2.0.9 y ≥v3.0.0. Antes de v2.0.9, la estructura del directorio era aproximadamente la siguiente:
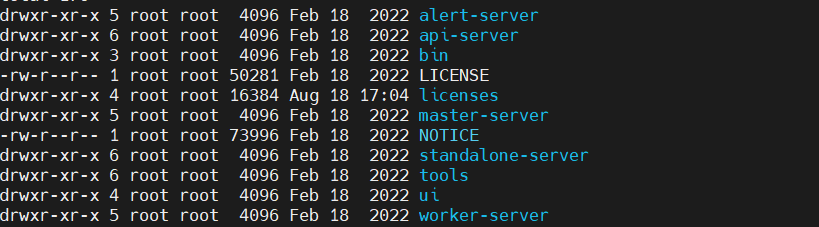
Después de la versión v3.0.0, la estructura del directorio es aproximadamente la siguiente:
Generalmente, las modificaciones siguen el principio de configurar primero el esquema de actualización y luego configurar los archivos de implementación básicos.
Para ≤v2.0.9, para configurar y actualizar el esquema, debe conf/datasource.propertiesmodificar el archivo y colocar el paquete del controlador de la base de datos en el directorio lib; y para configurar el archivo de implementación básico, debe modificar conf/common.properties, conf/config/install_config.conf, conf/env/dolphinscheduler_env.sh.
Para ≥v3.0.0, debe modificar el esquema de actualización de la configuración bin/env/dolphinscheduler_env.shy colocar el paquete del controlador de la base de datos en tools/libsel directorio; mientras configura el archivo de implementación básico, debe modificar bin/env/install_env.sh、alert/master/worker/api-server/conflos archivos common.properties, application.yaml.
- Actualizar la base de datos y ejecutar el script de actualización de la base de datos
Déjame explicarte aquí, si resulta que es una versión anterior a la v2.0.0, encontrarás un problema difícil: el JSON grande de la tabla de definición del flujo de trabajo no está dividido. Primero, debe dividir el JSON grande proporcionado por el funcionario update-schema.shy habrá muchos problemas durante el proceso de ejecución, a menos que el ID de la versión anterior de la definición del flujo de trabajo de su empresa no se haya eliminado y haya seguido aumentando desde que es ininterrumpido. Porque la definición oficial del flujo de trabajo La lógica de división de tareas se incrementa automáticamente. Si no se encuentra, se informará un error. Por lo tanto, el código fuente v2.0.0 debe modificarse para que sea compatible.
- Instalar e implementar, habilitar la última versión del servicio
Habrá un problema aquí. Después de la ejecución bin/install.sh, debería encontrarse después de la versión 3.1.x. En install.shel cuarto paso <es decir: 4.eliminar el nodo zk>, aparecerá el siguiente error:
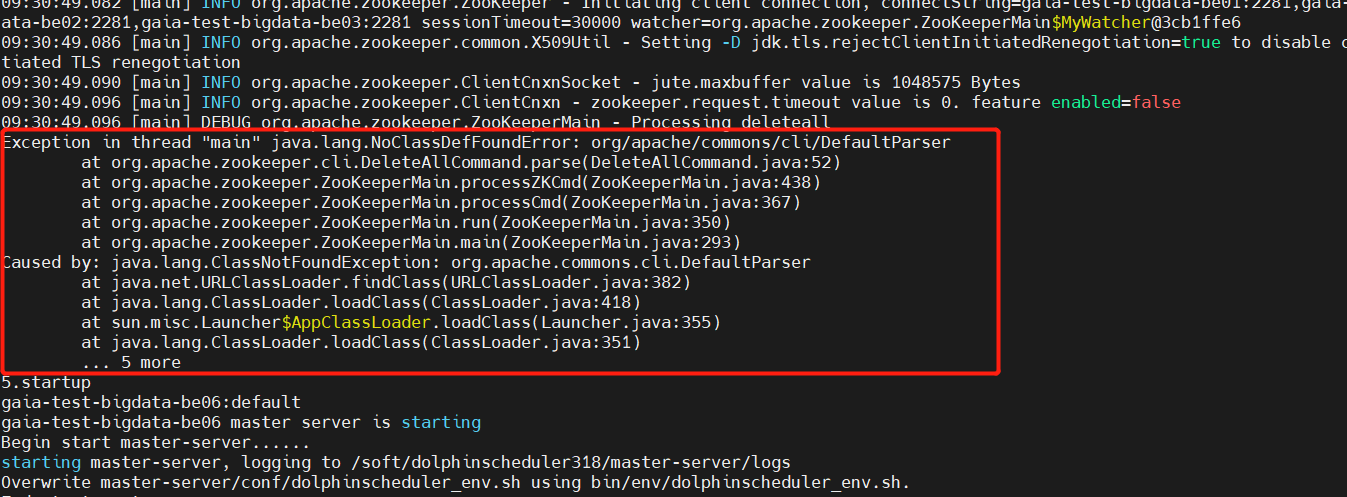
Después de un análisis aproximado, se determinó que faltaba el paquete jar después de solucionar el problema. La versión de Zookeeper que utilicé fue la v3.8.0. De hecho , no existe una clase DefaultParser en worker-server/master-server/api-server的libsel paquete fuente commons-cli-1.2.jarporque la versión 1.2 es demasiado baja.
Solución: Descargue ≥1.4 common-clipaquetes y colóquelos debajo de las bibliotecas correspondientes a cada servicio. Instálelos y despliegue nuevamente y no habrá ningún problema. https://mvnrepository.com/artifact/commons-cli/commons-cli/1.4El efecto es el siguiente:
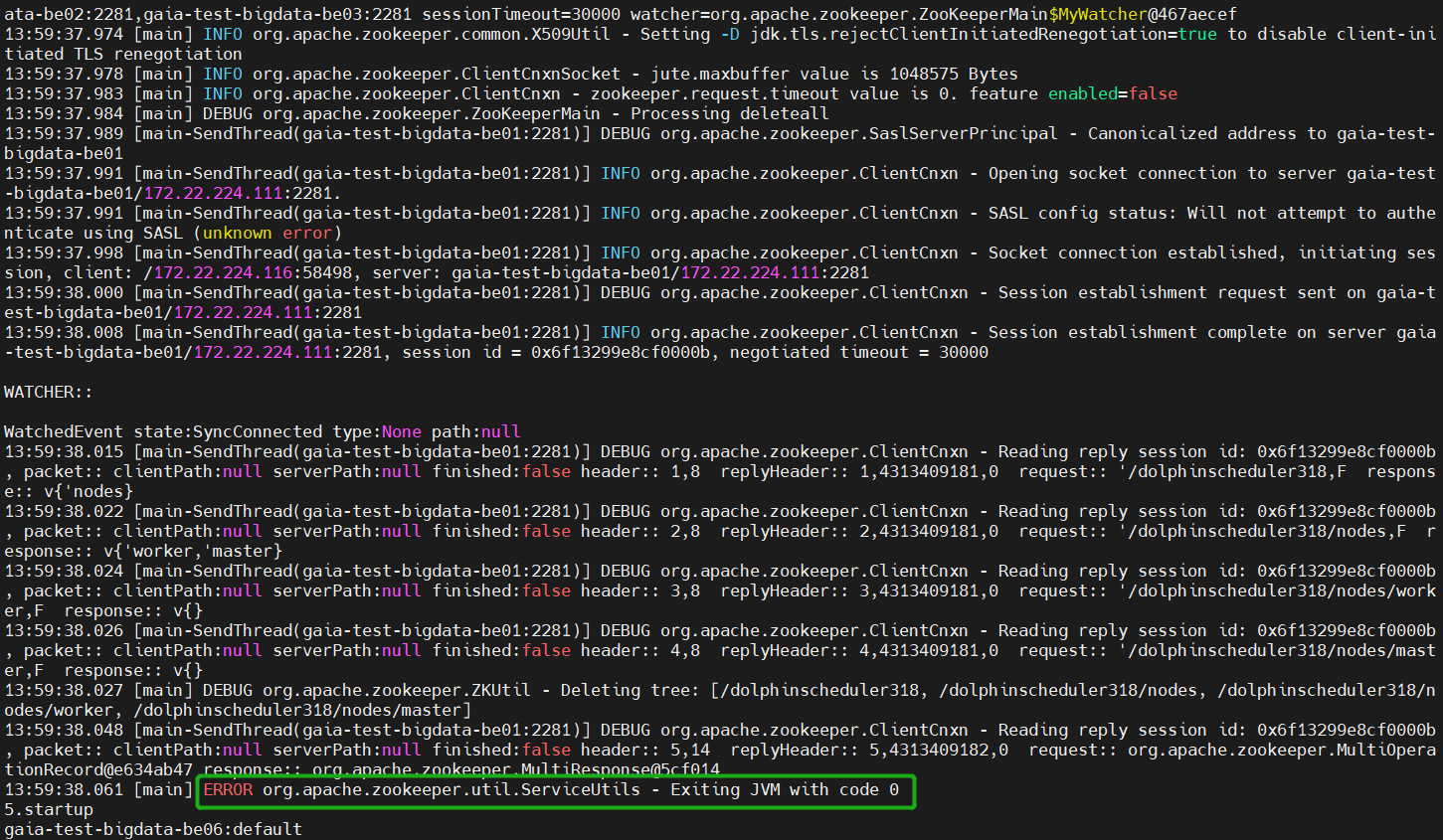
Aquí aparecerá un mensaje de ERROR visible: ERROR org.apache.zookeeper.util.ServiceUtils - Exiting JVM with code 0, aunque parece incómodo, ignore que este es el código de salida para que Zookeeper ejecute el comando normalmente, 0 significa que el programa finaliza normalmente, si aún tiene dudas, puede abrir un cliente de Zookeeper y intenta salir (bin/zkCli.sh)Ctrl+D.

- Inicializar datos y verificar funciones de nueva versión.
Los datos de inicialización incluyen principalmente: inquilinos, usuarios, grupos e instancias de alarma, centros de recursos, centros de origen de datos, gestión ambiental y otro mantenimiento de información de datos, que deben mantenerse de acuerdo con los escenarios comerciales específicos de la empresa, y la verificación de la función no será repetido aquí.
(3) Resumen de los problemas encontrados durante la actualización continua
- OutOfMemoryError: espacio de almacenamiento dinámico de Java (v1.3.6->v2.0.0)
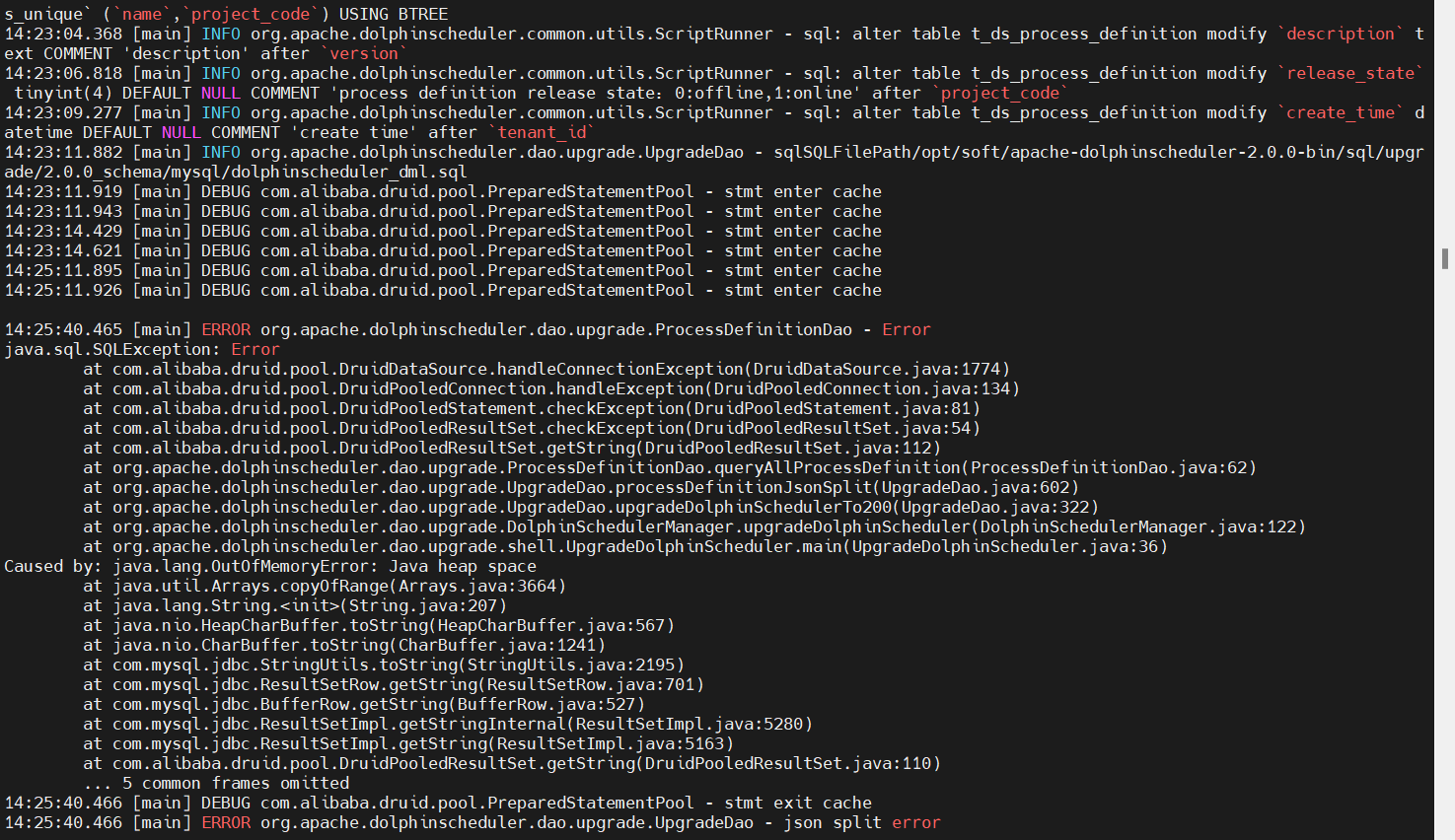
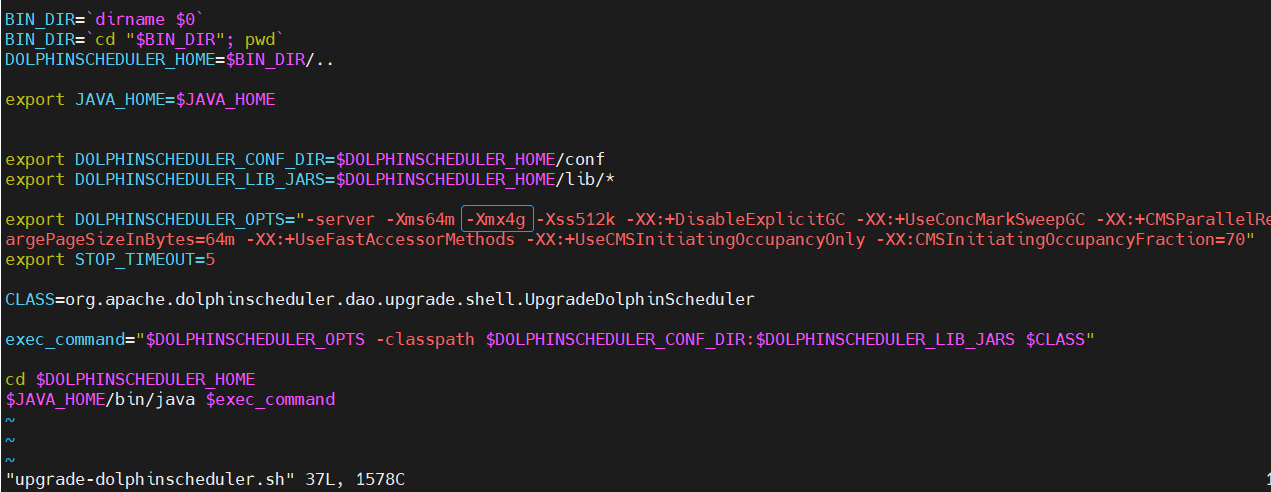
La razón de este problema es que los campos de la tabla de definición de flujo de trabajo deben dividirse durante la actualización a v2.0.0 process_definition_json, y el número de nuestras definiciones de flujo de trabajo es 6463 (dado que el volumen de negocios aún está creciendo), la división requiere mucho consumo. memoria y el espacio del montón de Java es insuficiente, lo que hace imposible asignar más memoria. Esto necesita aumentar el parámetro -Xmx adecuadamente de acuerdo con la configuración del servidor. Aquí lo ajusté a -Xmx4g, y luego la actualización estará bien.

- error de división json && NullPointException: nulo (v1.3.6->v2.0.0)
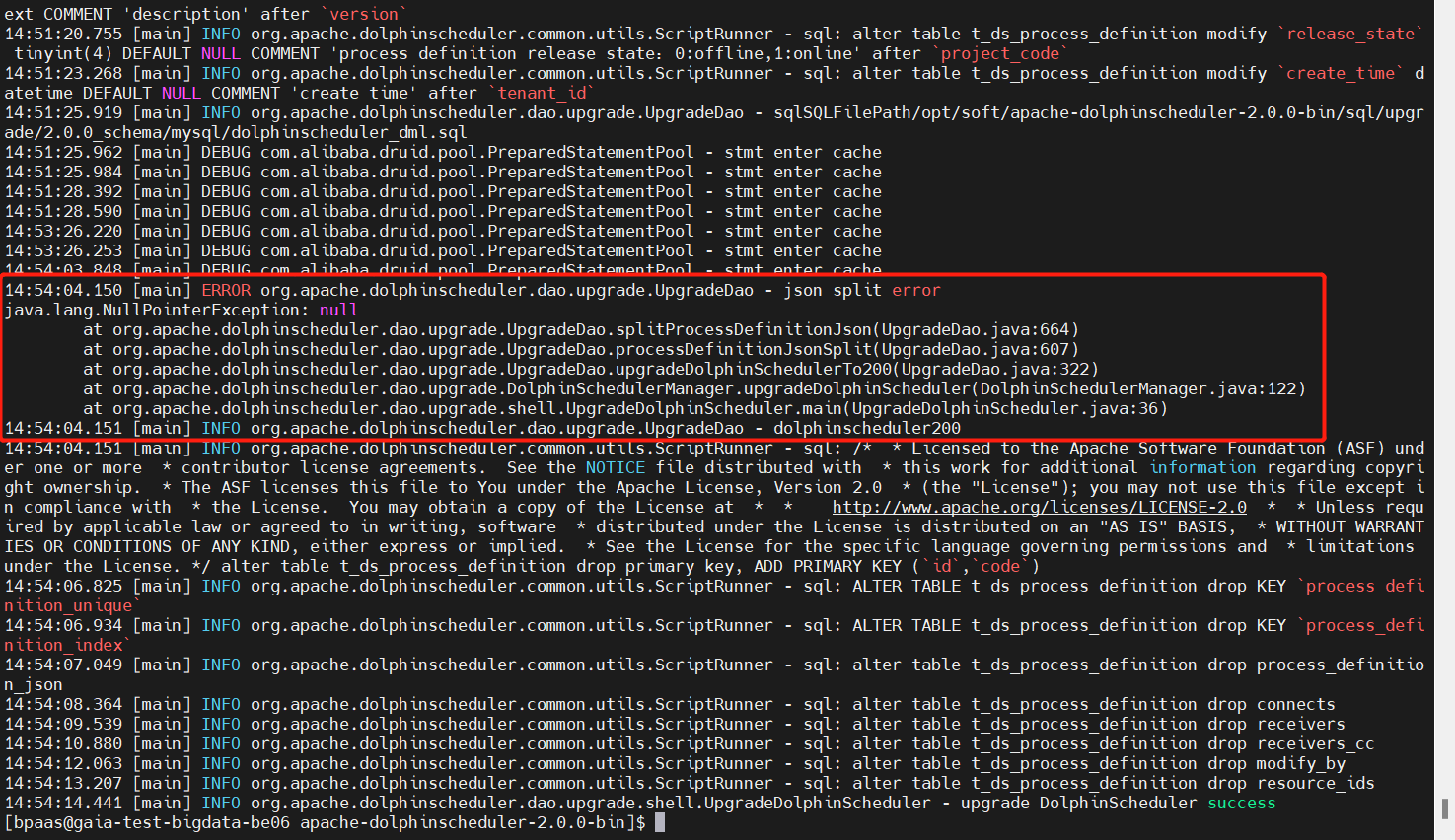
A decir verdad sobre este problema, estaba confundido al principio, lo que casi me hizo abandonar la ruta de actualización de la versión principal, y luego mi intuición me dijo que no entrara en pánico cuando encontrara problemas, sino que estuviera tranquilo, así que Descargué decisivamente el código fuente de v2.0.0 y lo posicioné Después de llegar a la ubicación del código fuente, lo modifiqué después del análisis e imprimí y registré el registro de errores para su posterior análisis. Primero, dejé que el programa se ejecutara normalmente. Aquí modifiqué principalmente lo siguiente puntos durante el proceso de depuración:
La primera modificación del código fuente es principalmente para evitar la excepción del puntero nulo causada por el procesoDefinitionMap vacío, como se muestra en la siguiente figura:
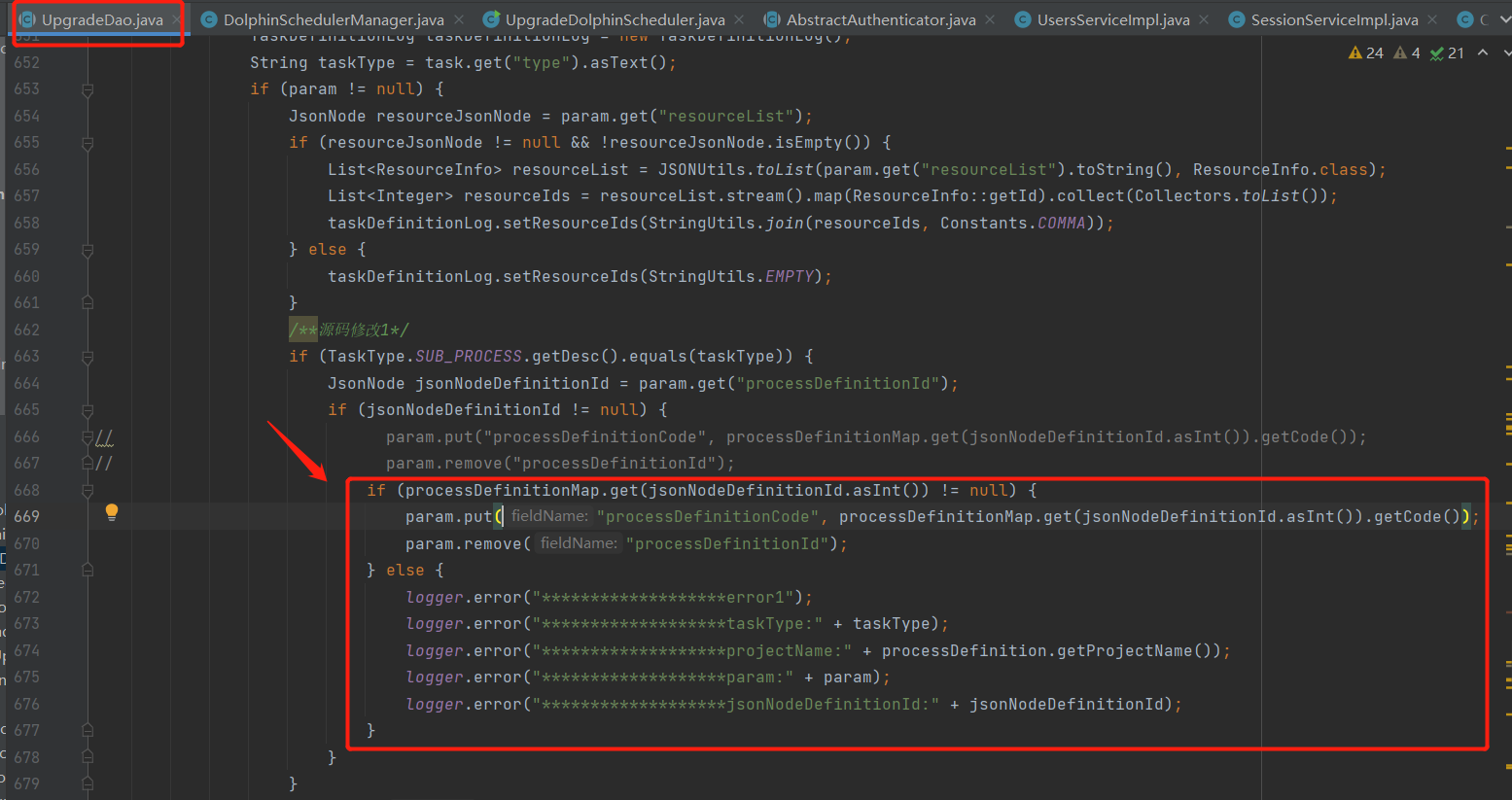
La segunda modificación del código fuente es principalmente para evitar la excepción de puntero nulo causada por el nodo del objeto de tarea que obtiene la información de descripción que está vacía, como se muestra en la siguiente figura:

La tercera modificación del código fuente es principalmente para evitar la excepción del puntero nulo causada por el nodo del objeto de tarea que obtiene preTasks, que está vacío, como se muestra en la siguiente figura:
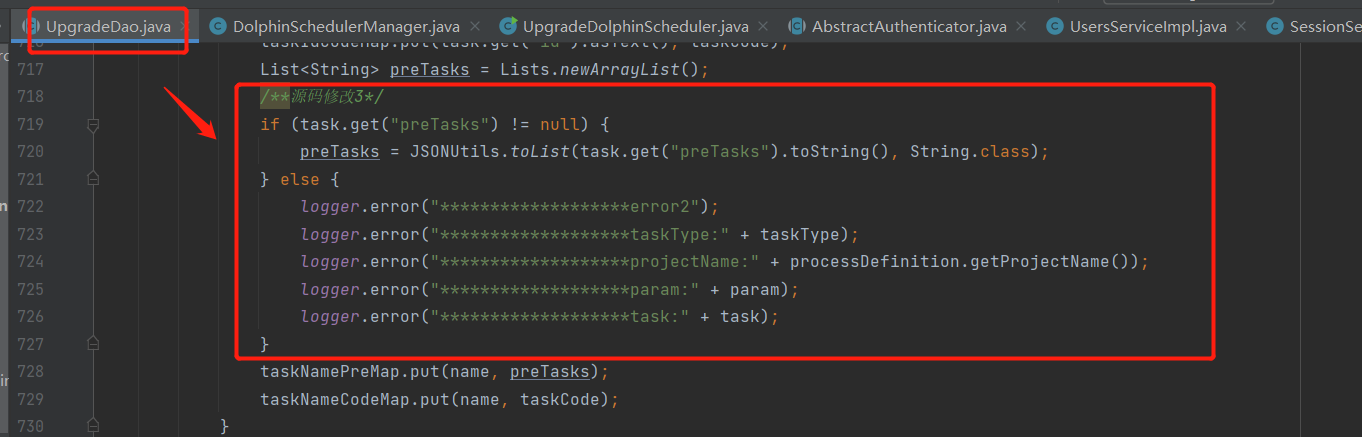
- Datos demasiado largos para la columna 'task_params' (v1.3.6->v2.0.0)
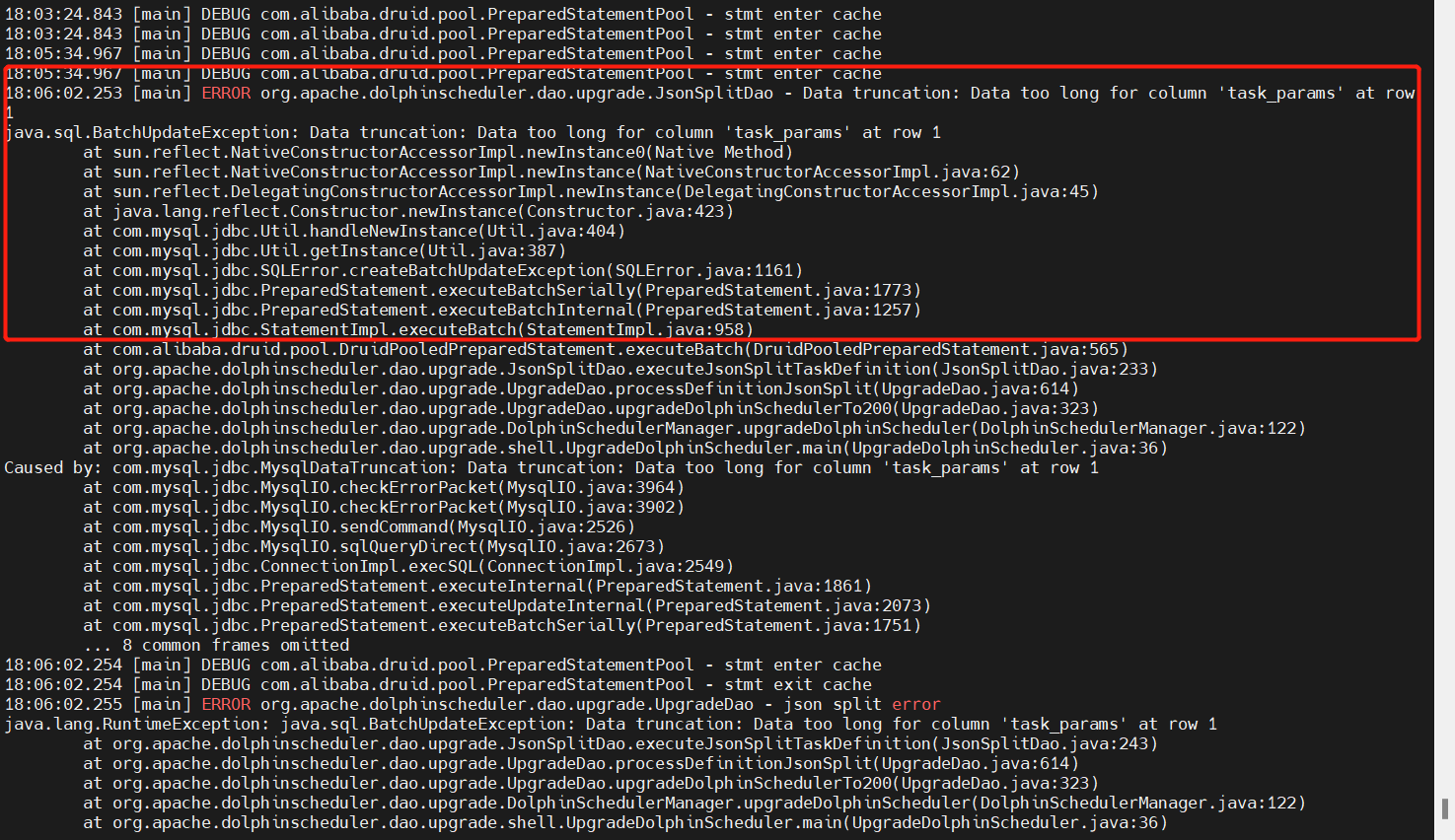
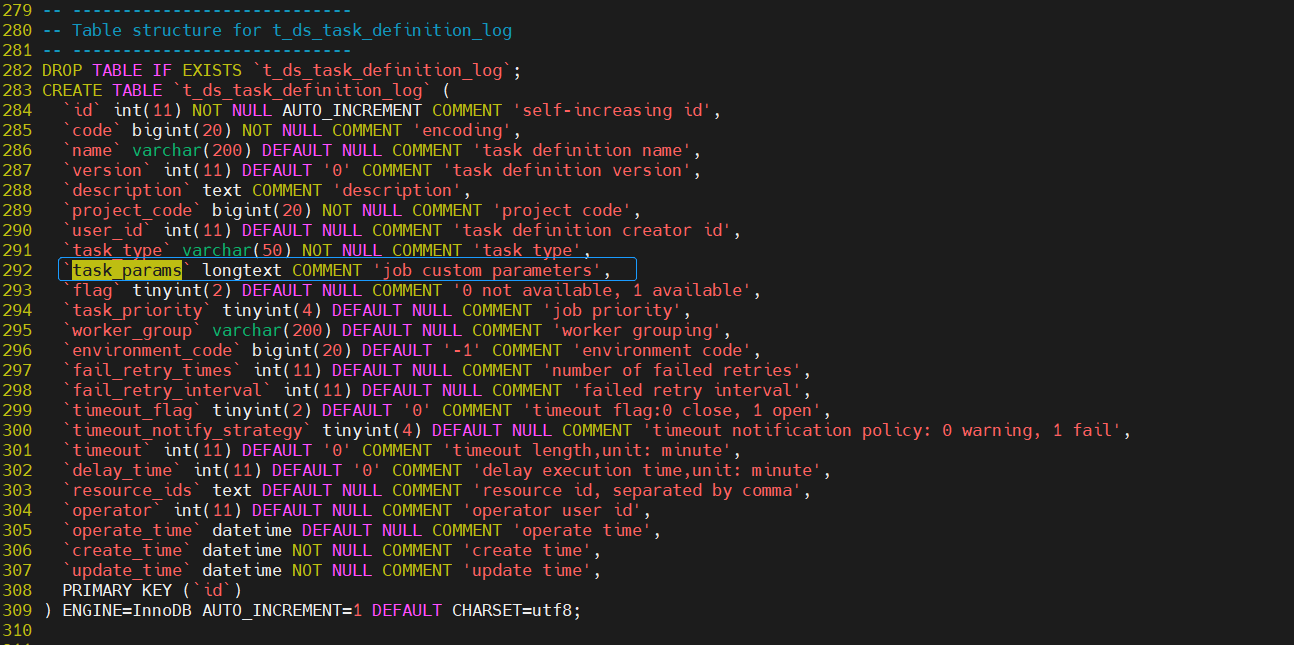
Este problema requiere modificar el script DDL oficial, específicamente la longitud del campo dolphinscheduler_ddl.sqlen el campo medio . El texto ya no puede cumplir con los requisitos de tamaño de almacenamiento de los parámetros de la tarea, como se muestra en la siguiente figura:t_ds_task_definition_log 的task_paramstext->longtext以及t_ds_task_instancetask_paramstext->longtext

- Nombre de columna duplicado 'alter_type' (v2.0.9->v3.0.0)

Este problema se debe a que se agregó en v2.0.9 y una versión anterior, y el script oficial no se ha comentado.
- El recurso de ruta de clases [sql/upgrade/2.0.0_schema/mysql/dolphinscheduler_dml.sql] no se puede abrir porque no existe (v2.0.0->v3.1.7 es un intento de investigación de premisas)
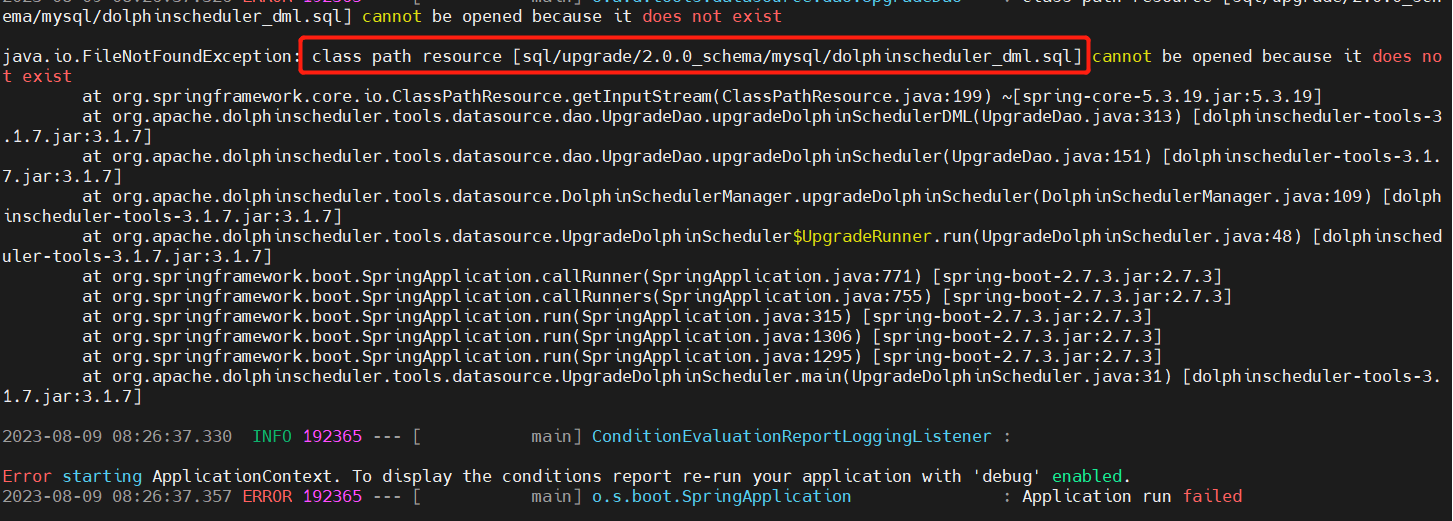
Mi resumen personal de este problema es que la variedad de versiones es demasiado grande. También confirma que el script de actualización solo se puede actualizar en pasos pequeños, no en pasos grandes. Si también encuentra una actualización de versión grande, puede consultar mi proceso continuo. Versión de actualización para evitar desvíos.
- Columna desconocida 'other_params_json' en 't_ds_worker_group' (v3.0.0->v3.1.0)
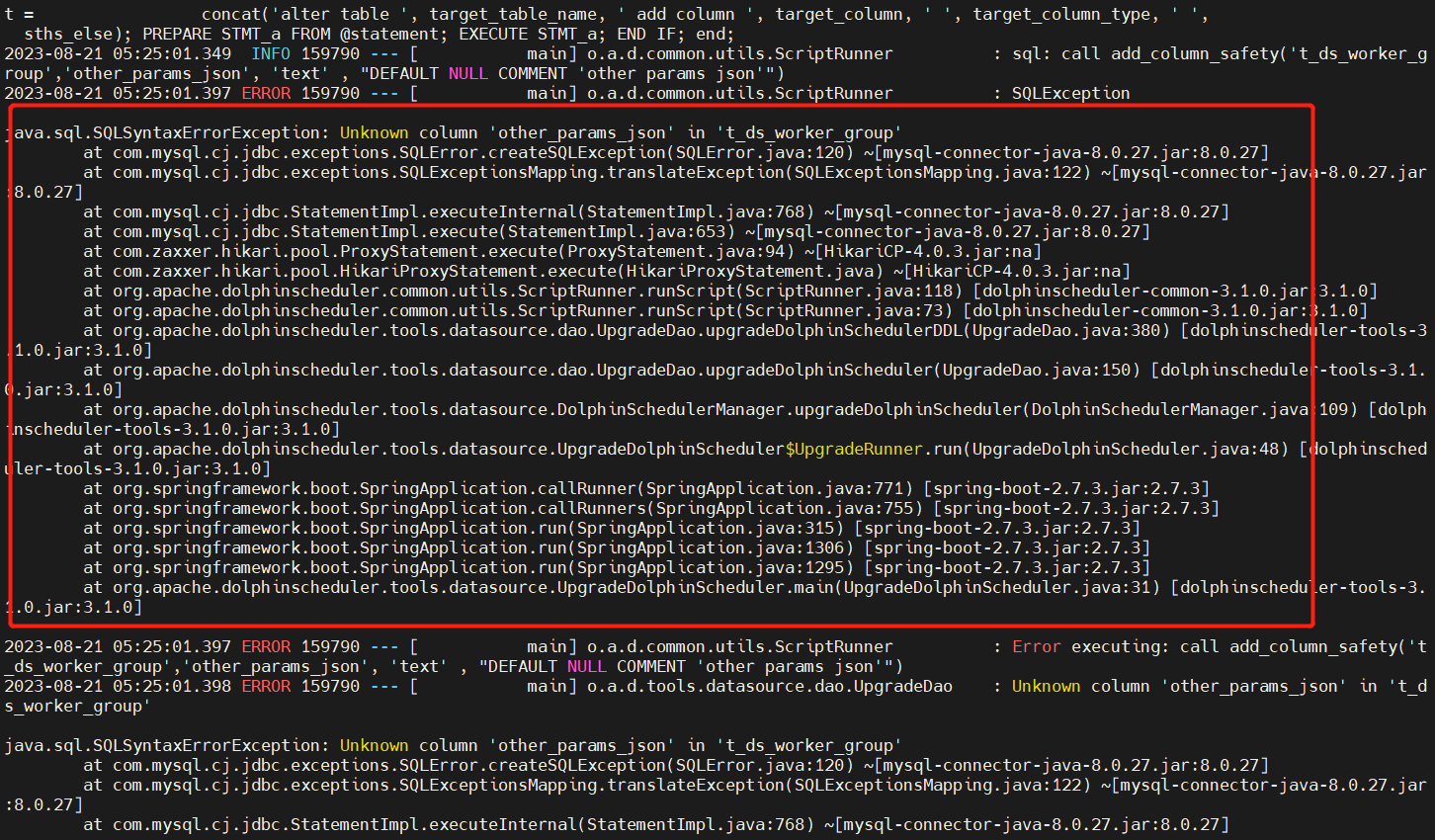
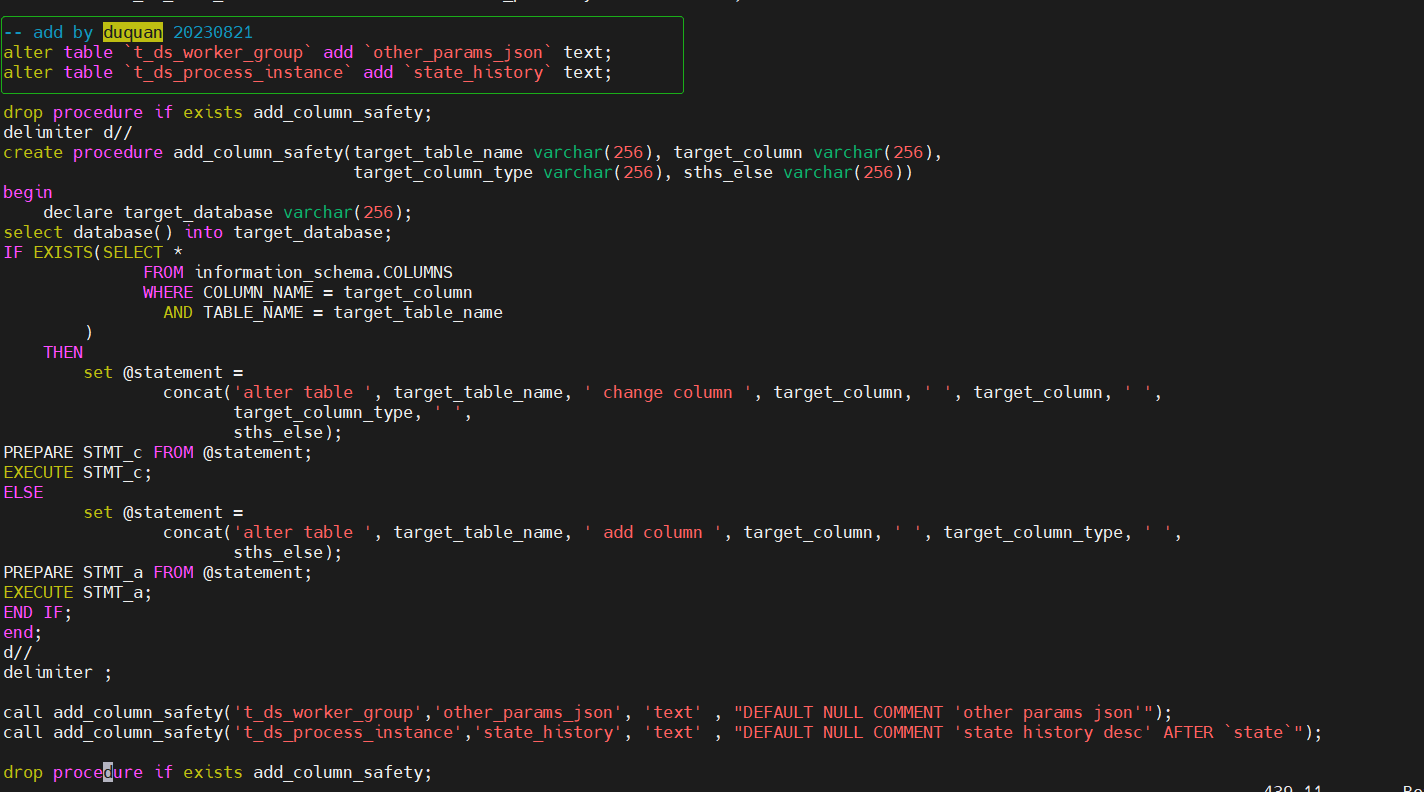
Para modificar el script DDL proporcionado oficialmente, debe ajustar dolphinscheduler_ddl.sql,t_ds_worker_groupla tabla para agregar other_params_jsoncampos y t_ds_process_instanceagregar state_historycampos a la tabla, como se muestra en la siguiente figura:
- Columna desconocida 'descripción' en 't_ds_worker_group' (v3.1.0->v3.1.8)

Modifique el script DDL proporcionado oficialmente (en v3.1.8 3.1.1_schema), que debe ajustarse dolphinscheduler_ddl.sqly t_ds_worker_groupagregarse campos a la tabla description, como se muestra en la siguiente figura:

- Actualizaciones sin compatibilidad hacia adelante
Esta compatibilidad involucra principalmente las versiones v3.0.0 y v3.1.1. Para v3.0.0, el prefijo de copia se elimina al copiar e importar flujos de trabajo; el punto y coma se utiliza como delimitador SQL predeterminado. Para v3.1.1, la forma en que Unix ejecuta el shell se cambió de sh a bash, y estos efectos básicamente se pueden ignorar.
(4) Visualización de resultados de integración
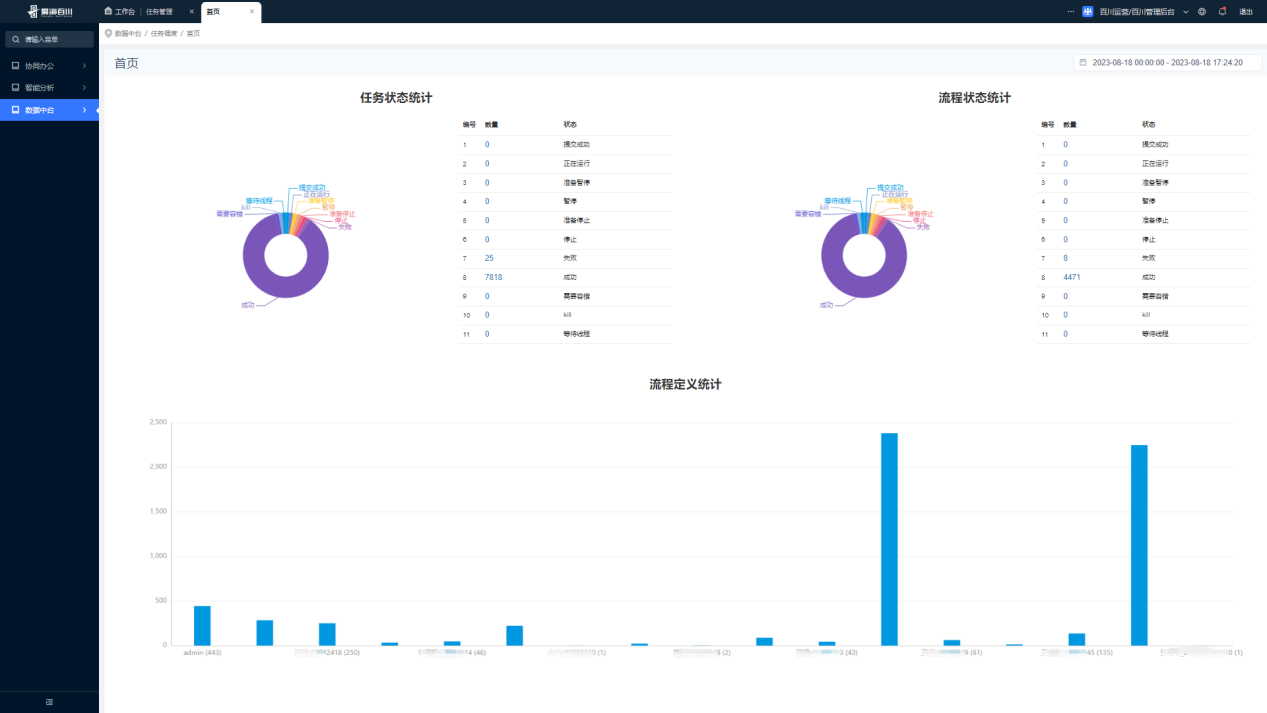
El menú de integración del centro de datos está definido por la plataforma. Solo hay un menú de entrada, a saber: Dolphin Scheduling. La captura de pantalla incrustada en el centro aquí es la versión v3.1.1. La v3.1.8 se integrará rápidamente más adelante. Además del menú básico estilos de estado y estado de sincronización No está nada mal.
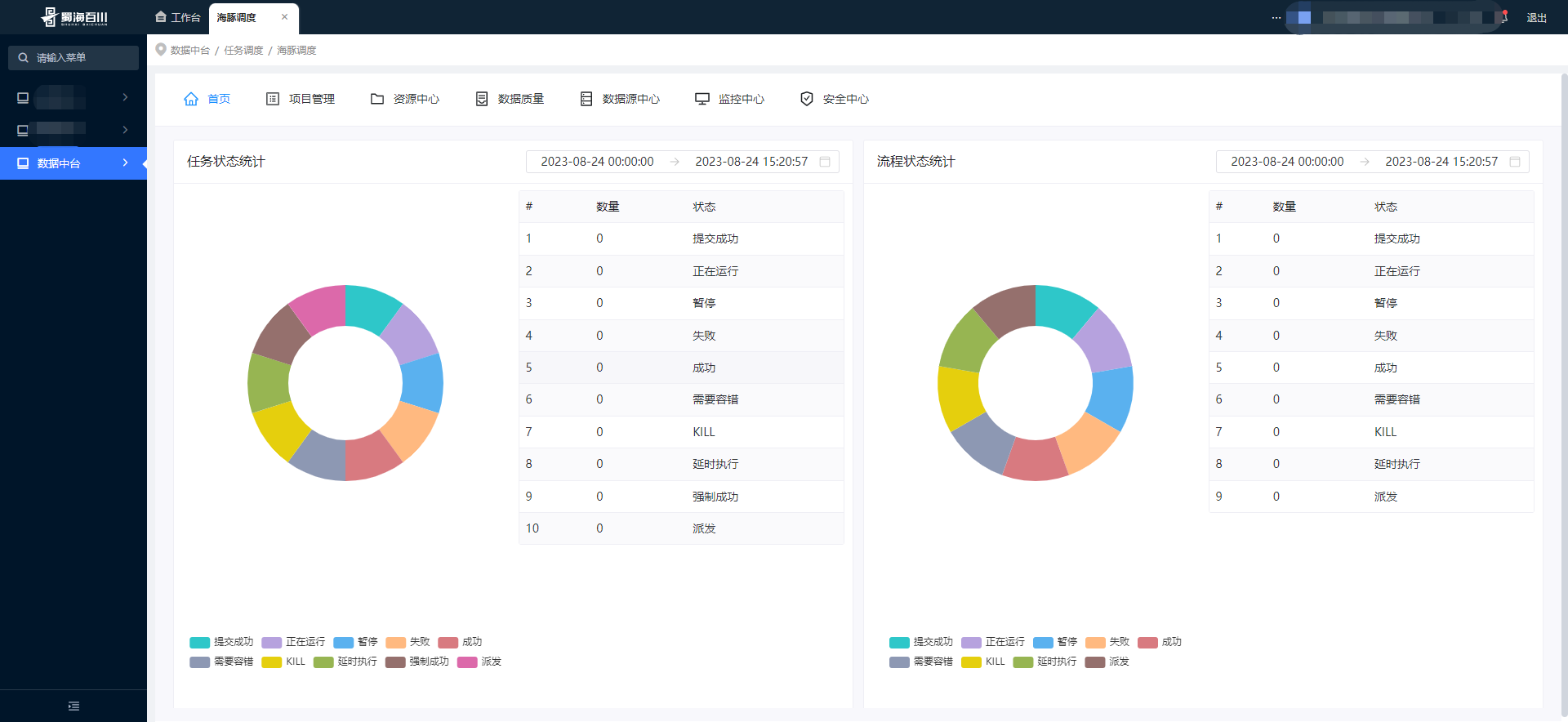
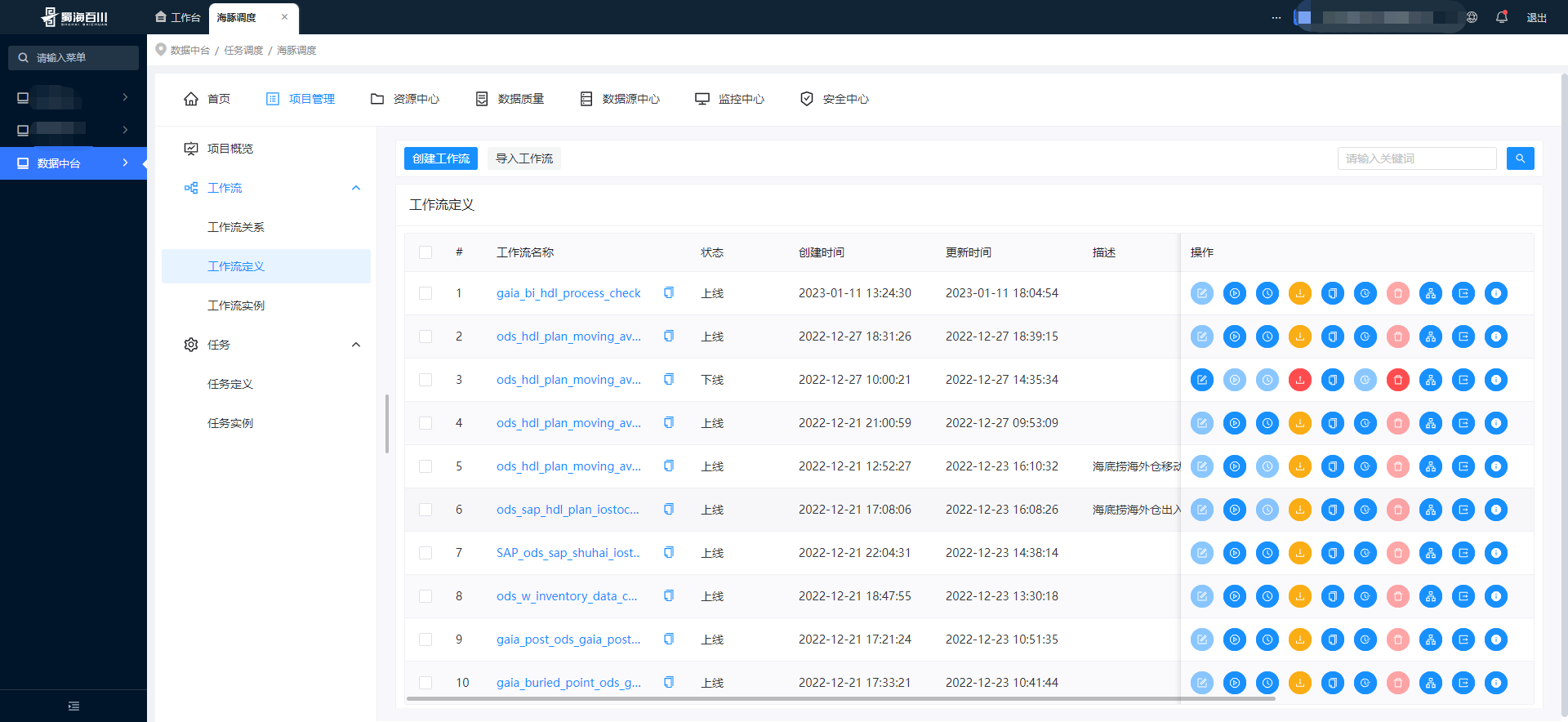
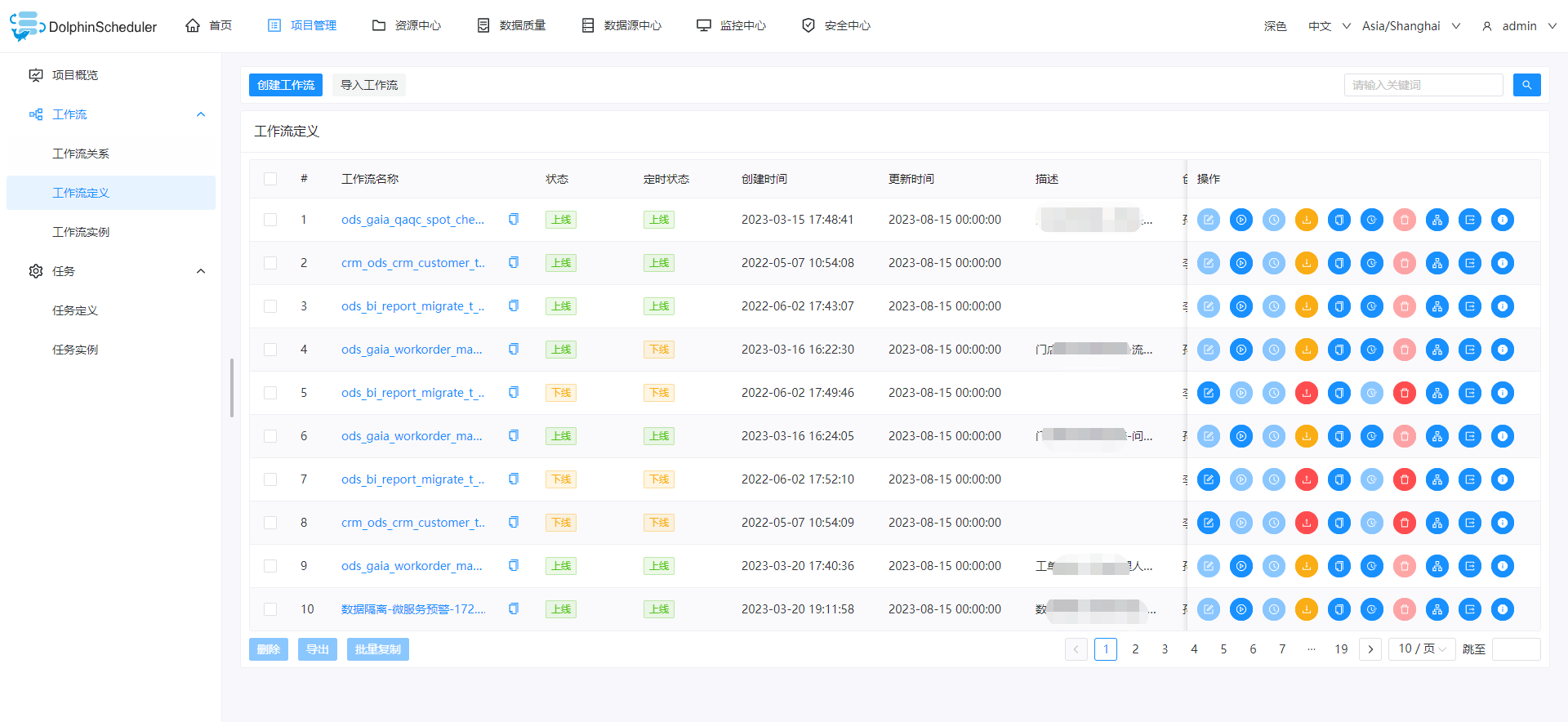
Ficha técnica origen de la innovación tecnológica
Con base en la definición del flujo de trabajo de programación de Dolphin, también hemos realizado prácticas innovadoras de linaje de tablas de datos. La lógica general se define analizando el flujo de trabajo. En el proceso de flujo de datos, esta sintaxis se utiliza básicamente, con tablas de entrada (declaraciones de selección) y salida. ( Insertar Insert...Selectdeclaración) Como proceso de transferencia, construir un diagrama de flujo DAG de linaje de datos para potenciar nuestro negocio es equivalente a insertar un par de ojos en el centro de datos para visualizar verdaderamente el proceso de transferencia de la tabla de datos. Todos estos se basan en la programación de delfines. como punto central.
Análisis de linaje de datos y consulta completa.
(1) Análisis de linaje de datos
- Estructura general
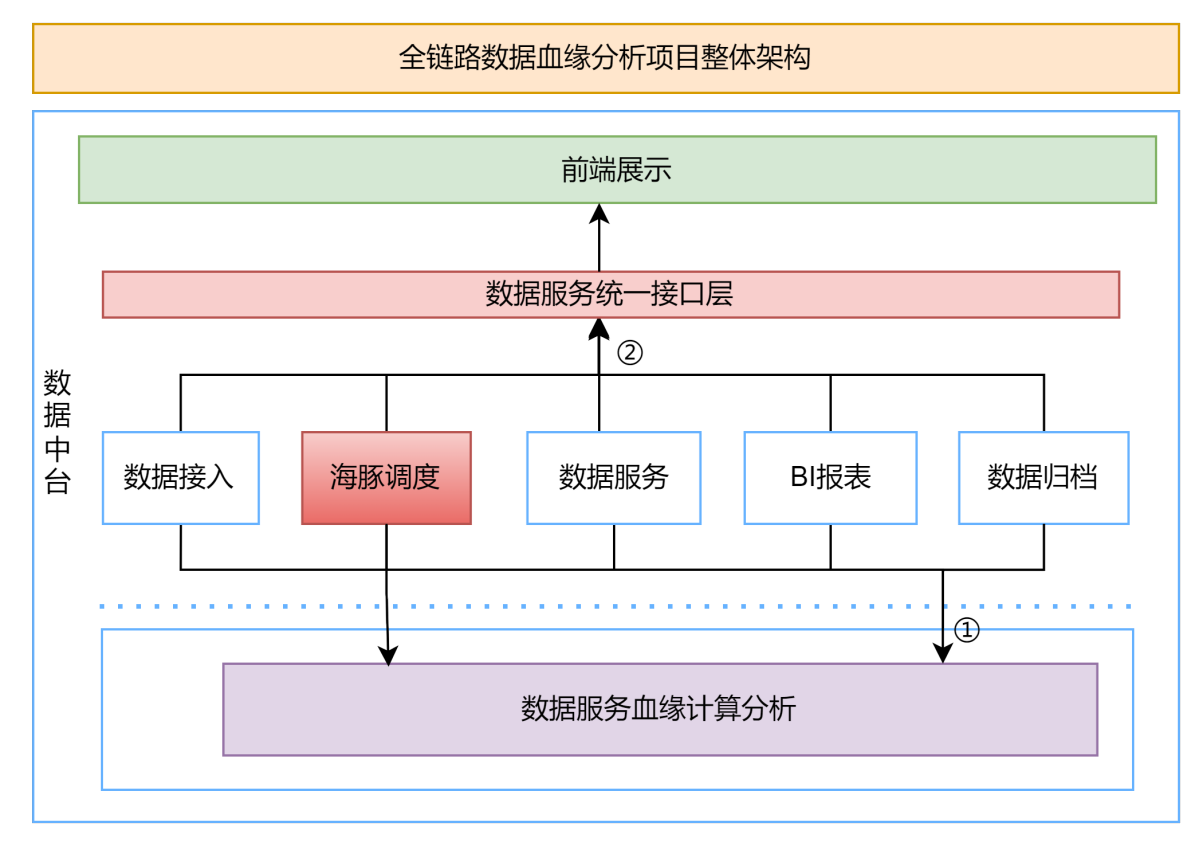
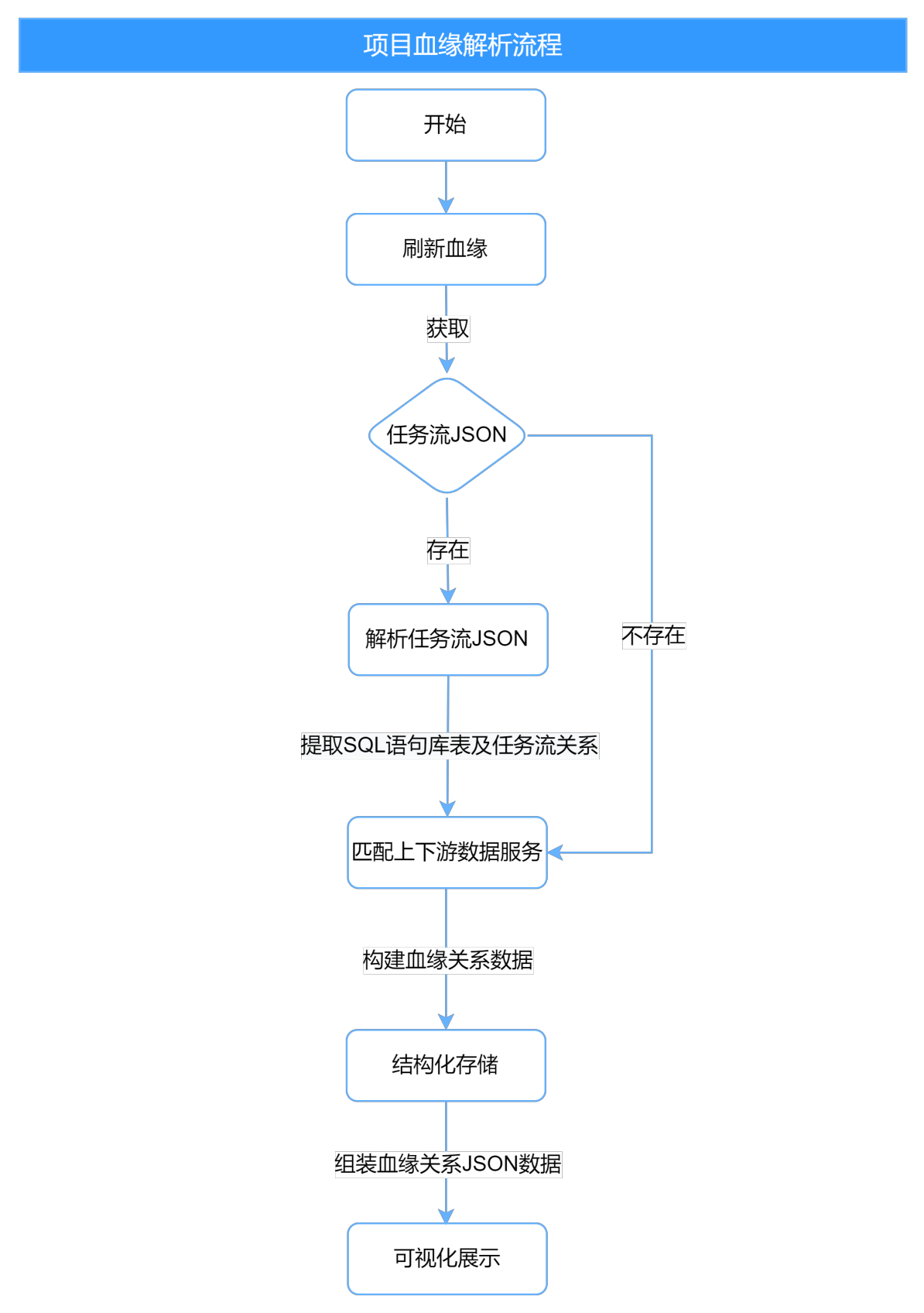
- Proceso de análisis y visualización.
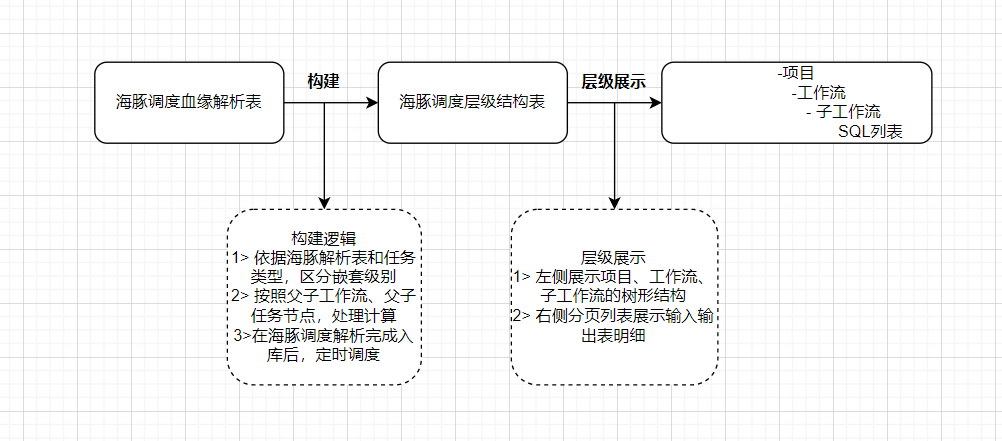
- Analizar el código central de SQL
Para analizar el linaje de tablas SQL, utilizamos Druid de Alibaba, la versión recomendada (≥V1.2.6). Druid sigue siendo muy potente en el análisis de SQL. Su TableStat admite fusionar, insertar, actualizar, seleccionar, eliminar, eliminar, crear, modificar, estos. Los tipos de CreateIndex y DropIndex se pueden combinar según la sintaxis, como: InsertSelect. Nuestro análisis de parentesco realiza un insert...selectanálisis de declaraciones múltiples, y las declaraciones múltiples están separadas por punto y coma;
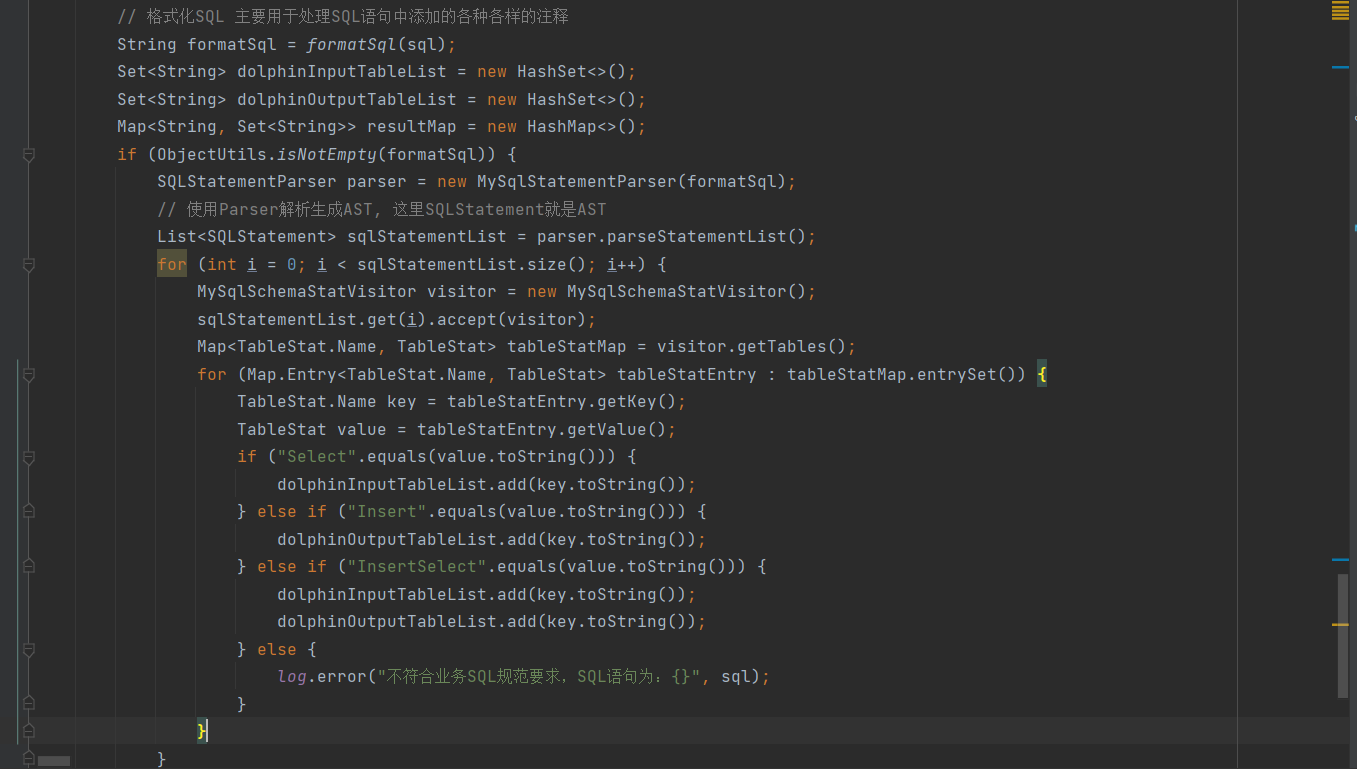
(2) Consulta de linaje de datos
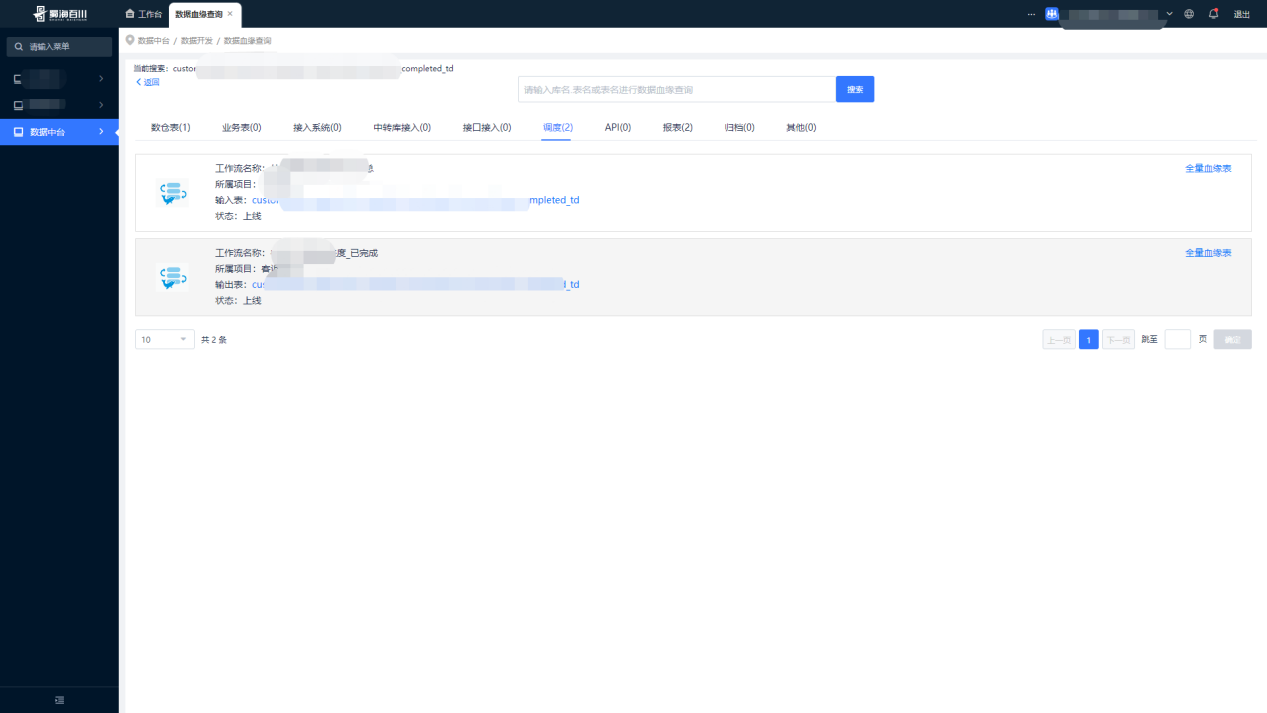
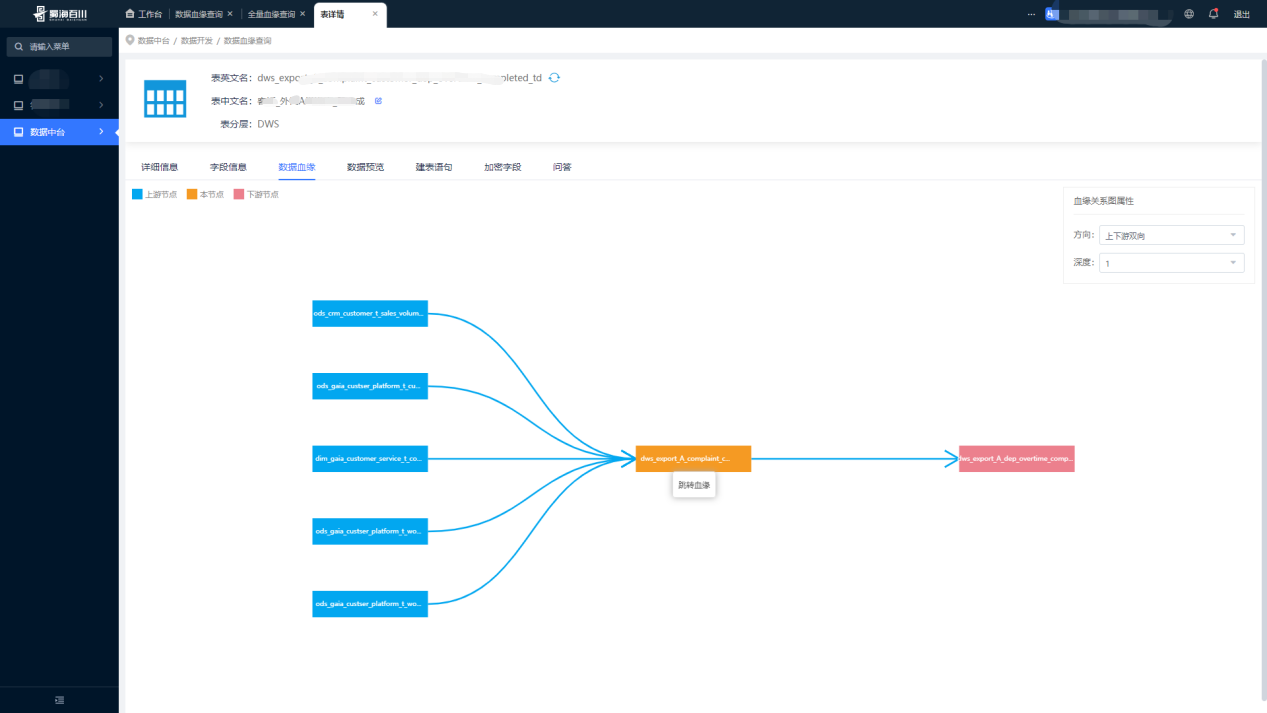
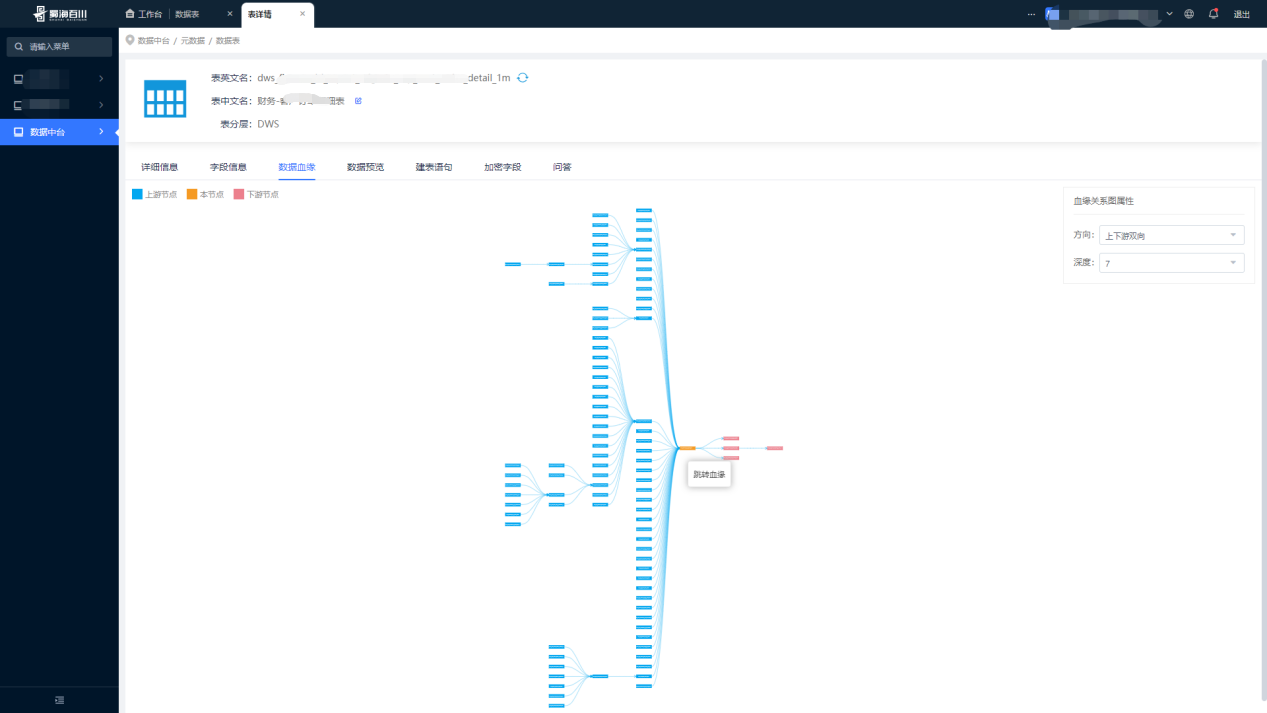
(3) Consulta completa del linaje
La consulta de línea de sangre completa puede mostrar intuitivamente la definición del flujo de trabajo del Proyecto de programación Dolphin en forma de tablas de entrada y salida, y consultar y localizar rápidamente una determinada tarea, lo que brinda una gran comodidad a nuestros analistas de datos.
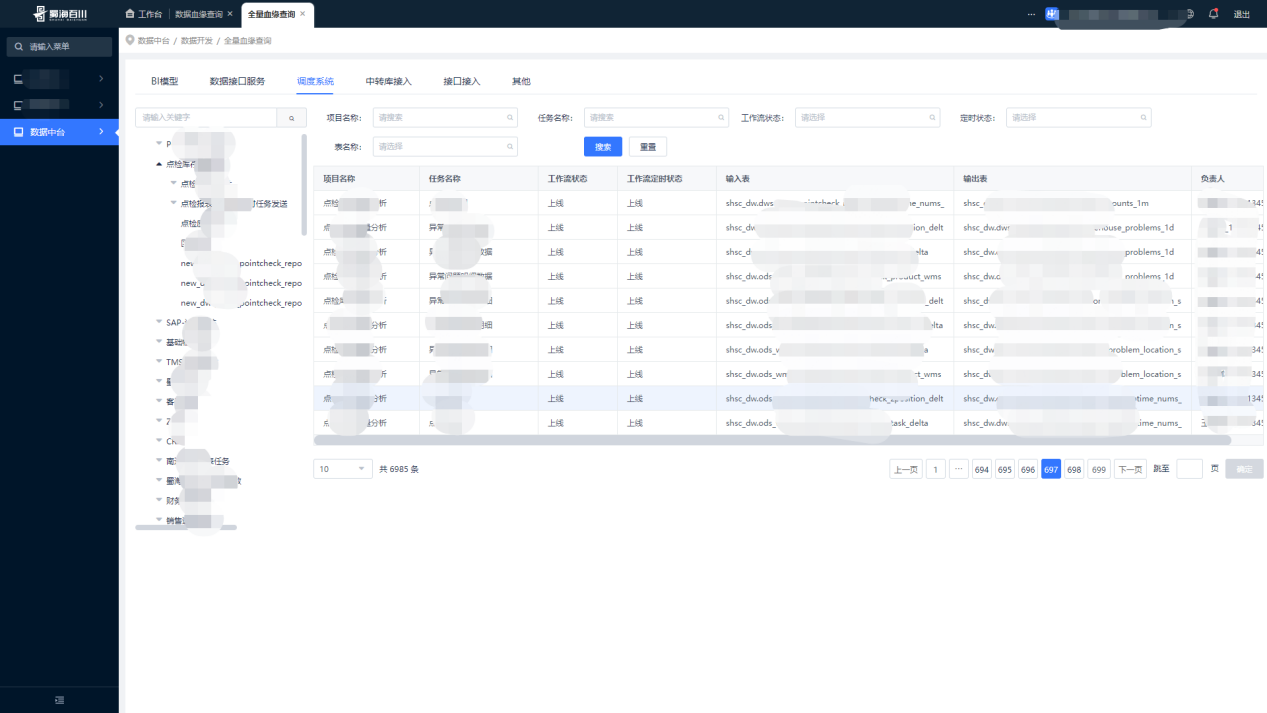
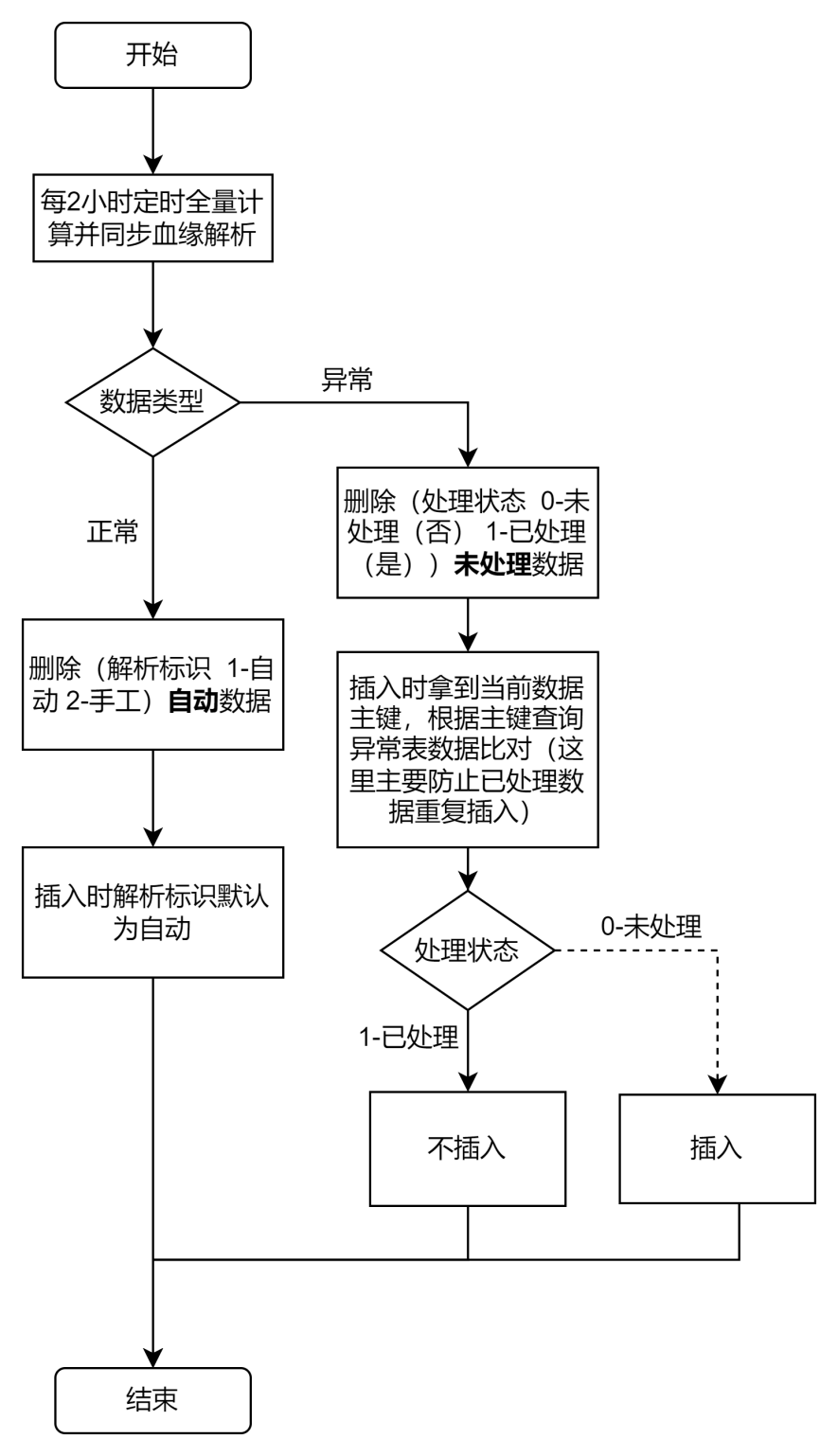
(4) Manejo de relaciones sanguíneas anormales
Durante el proceso de análisis del linaje de datos, inevitablemente se producirán excepciones en el análisis de declaraciones SQL. También hemos tenido esto en cuenta. El proceso general de manejo de excepciones es el siguiente:
ingresos del usuario
- Apoya el centro de datos de la empresa para acumular casi 7000 tareas de definición de flujo de trabajo todos los días, y los 78 proyectos cubren básicamente todos los módulos comerciales del centro de datos;
- El análisis y la consulta de las relaciones sanguíneas ascendentes y descendentes a nivel de tabla basados en el flujo de trabajo y las definiciones de tareas realmente logran una recuperación unificada y una gestión visual de las relaciones sanguíneas de las tablas, lo que mejora en gran medida la eficiencia de las tablas de recuperación diaria para los desarrolladores de datos de nivel medio y los analistas de datos;
- Proporciona un modo de configuración de estrategia de ejecución de tareas para garantizar la precisión de los datos cuando las tareas se ejecutan de forma cruzada en la misma instancia de flujo de trabajo; también resuelve el problema de la transmisión de parámetros personalizados dependientes ascendentes y descendentes entre tareas;
- Las actualizaciones iterativas posteriores pueden responder rápida y eficientemente a las necesidades de producción del centro de datos.
Resumen y agradecimientos
Hay que decir que las poderosas capacidades de complemento de extensión integrada proporcionadas por Apache DolphinScheduler han mejorado en gran medida la eficiencia del procesamiento, la integración y el desarrollo de datos empresariales, y realmente han potenciado el flujo eficiente del análisis de datos comerciales empresariales.
Nuestra primera versión de implementación de integración del centro de datos utilizó la versión v1.3.6. En la actualidad, la comunidad ha lanzado la versión 3.1.8, y esta vez también hemos actualizado a la última versión v3.1.8 de forma continua. También estamos manteniendo el ritmo de la comunidad. La comunidad oficial v3.2.0 también está calentándose La rápida velocidad de iteración también refleja la multitud de usuarios que se multiplica día a día. Si su empresa tiene dificultades para elegir un componente de programación de big data, le recomendamos encarecidamente utilizar Dolphin Scheduling.
Únase a la comunidad y únase al Grupo DS. DS también tendrá sesiones semanales de preguntas frecuentes para responder sus preguntas de manera oportuna y brindar servicios considerados. Se lo merece.
Apache DolphinScheduler es muy recomendable, si eliges bien el horario llegarás temprano a casa después de salir del trabajo, si eliges el horario correctamente podrás dormir tranquilo en mitad de la noche. Espero que todos puedan beneficiarse y decir adiós al 996.
Finalmente, deseo sinceramente que el ecosistema Apache DolphinScheduler mejore cada vez más.
Perfil del usuario
Shuhai (Beijing) Supply Chain Management Co., Ltd.
Industria: cadena general de suministro de alimentos
Shuhai Supply Chain se estableció en junio de 2014. Es una empresa de servicios de cadena de suministro de catering que integra ventas, investigación y desarrollo, adquisiciones, producción, control de calidad, almacenamiento, transporte, información y finanzas. Actualmente brinda servicios a la mayoría de las empresas de cadenas de catering. y clientes minoristas Servicios generales de solución de la cadena de suministro de alimentos.
Shuhai cuenta con modernos centros logísticos de cadena de frío, fábricas de alimentos, centros de procesamiento de frutas y verduras, procesamiento de materiales básicos y otras bases en todo el país. Brindar servicios de calidad a los clientes de catering con un sistema de cadena de suministro seguro y transparente y resolver los puntos débiles que son difíciles de estandarizar en la industria de la restauración. A través de continuas investigaciones y mejoras en los campos de producción limpia de vegetales, investigación y desarrollo de platos e industrialización de estándares de catering, Shuhai ha sido reconocida por las autoridades y clientes de la industria y se ha convertido en una empresa de referencia en el campo de la cadena de suministro.
¡ Este artículo fue publicado por Beluga Open Source Technology !