0x0.Preámbulo
Mis notas de estudio y guía del usuario de ChatRWKV Este artículo es el primer paso para aprender RWKV y, después de aprender un poco, decido qué debo hacer. Entonces, en la comunidad RWKV, vi la necesidad de implementar los modelos de la serie RWKV World en varias plataformas de hardware a través de MLC-LLM, y luego comencé a comprender el proceso de compilación e implementación de MLC-LLM y el modelo RWKV World en comparación. a MLC-LLM Los modelos de la serie Raven son especiales.
El proceso de compilación e implementación de MLC-LLM se describe en detalle en la documentación oficial de MLC-LLM, pero hay algunos errores ocultos en esta parte que debes descubrir. Por ejemplo, el tokenizador del modelo RWKV-World para El soporte ahora está personalizado y no está en el formato de Huggingface, lo que significa que no podemos usar MLC-LLM para compilar directamente este modelo, ni podemos usar la biblioteca binaria MLC-LLM precompilada para ejecutar este modelo. Además, antes de compilar el almacén MLC-LLM, necesitamos compilar el almacén Relax en lugar del almacén TVM original. Relax puede considerarse como una bifurcación de TVM. Sobre esta base, admite Relax, una nueva generación de lectores IR. Se recomienda leer esta parte de los antecedentes. Aquí hay algunos enlaces a mi almacén:
https://github.com/BBuf/tvm_mlir_learn
Este almacén ha ganado 1,4k estrellas, gracias lectores por su apoyo.
Aprendí de la comunidad RWKV que el código de razonamiento y el modelo de la serie RWKV-World son exactamente los mismos que los de la serie Raven, la principal diferencia es que el tokenizador está personalizado y el indicador del sistema es diferente.
Al compilar Relax, debe elegir su propia plataforma de compilación para compilar. Después de compilar, MLC-LLM utilizará la variable de entorno TVM_HOME para percibir la ubicación de Relax, y las opciones habilitadas al compilar Relax deben coincidir con las opciones compiladas por MLC-LLM. , para que se puedan realizar la compilación y la inferencia correctas en la plataforma especificada.
Al adaptar RWKV-World 1.5B, debido a que el modelo es relativamente pequeño y sensible a las comas, la precisión de la primera capa se amplió y finalmente se colgó en la muestra. Coloqué este lugar durante 2 noches, y luego Feng Siyuan, el oficial mlc-ai, dijo Después de descubrir cómo imprimir la precisión capa por capa en MLC-LLM, finalmente localicé el problema. Y aprendí sobre este fenómeno en la comunidad RWKV antes, es decir, la primera capa del modelo 1.5B debe calcularse con FP32, de lo contrario la precisión aumentará. Seguí con el experimento de RWKV-4-World 3B/7B, y este fenómeno es que ya no queda ninguno.
Además, también vale la pena señalar el formato organizativo del modelo: MLC-LLM no puede descubrir correctamente todos los modelos compilados en cualquier ubicación en tiempo de ejecución. Pasé aproximadamente una semana fuera del trabajo en MLC-LLM para respaldar la serie de modelos RWKV-World. El contenido principal del trabajo es:
- Vincule la implementación del tokenizador del modelo RWKV World en el almacén https://github.com/daquexian/faster-rwkv de Daquexian al tokenizers.cpp de mlc-ai y proporciónelo a MLC-LLM como una tercera biblioteca. El PR fusionado es: https://github.com/mlc-ai/tokenizers-cpp/pull/14.
- Sobre la base de lo anterior, el despliegue de los modelos de la serie RWKV World es compatible con MLC-LLM, y los modelos de la serie Prompt of the World están alineados para obtener un buen efecto de diálogo. Implementado y probado en tarjetas gráficas Apple M2 y A800 respectivamente. El PR es: https://github.com/mlc-ai/mlc-llm/pull/848, este PR todavía es wip, si desea usarlo ahora, puede cortar directamente a la rama correspondiente a este PR.
- La depuración en el modelo pequeño 1.5B RWKV World explotará el error de precisión, lo que equivale a pisar un gran pozo.
Me gustaría agradecer al oficial Feng Siyuan de mlc-ai por su apoyo durante mi implementación y por ayudarme a revisar el código que se fusionará en la comunidad mlc-ai, así como por la implementación de RWKV World Tokenizer c++ y la ayuda cuando compilando bibliotecas de terceros Un error que resolví.
El siguiente es el tutorial del modelo de implementación de la serie RWKV World de MLC-LLM, que intenta brindarle la práctica de implementación con menos pasos.
Efecto:

0x1 Implementar RWKV-4-World-7B en A800
Preparación
- Dirección del modelo RWKV-4-World: https://huggingface.co/StarRing2022/RWKV-4-World-7B
- Descargue tokenizer_model.zip aquí: https://github.com/BBuf/rwkv-world-tokenizer/releases/tag/v1.0.0 y descomprímalo en el archivo tokenizer_model, que es el archivo Tokenizer del modelo de la serie RWKV World.
- Clona https://github.com/mlc-ai/mlc-llm y https://github.com/mlc-ai/relax, presta atención al parámetro –recursive al clonar, para que sean dependientes del tercero- También se agrega la biblioteca de fiestas.
compilar relajarse
git clone --recursive git@github.com:mlc-ai/relax.git
cd relax
mkdir build
cd build
cp ../cmake/config.cmake ./
Luego modifique los archivos en el directorio de compilación config.cmake. Como estoy compilando en el A800 aquí, cambié la siguiente configuración:
set(USE_CUDA ON)
set(USE_CUTLASS ON)
set(USE_CUBLAS ON)
Es decir, CUDA está habilitada y dos bibliotecas de aceleración CUTLASS y CUBLAS están habilitadas. Luego ejecútelo en el directorio de compilación cmake .. && make -j32.
Finalmente, puede considerar agregar Relax a la variable de entorno PYTHONPATH para que sea visible globalmente. Ingrese el siguiente contenido en ~/.bashrc:
export TVM_HOME=/bbuf/relax
export PYTHONPATH=$TVM_HOME/python:${
PYTHONPATH}
Entonces source ~/.bashrcpuedes.
Compile e instale MLC-LLM
git clone --recursive git@github.com:mlc-ai/mlc-llm.git
cd mlc-llm/cmake
python3 gen_cmake_config.py
Ejecute python3 gen_cmake_config.py para seleccionar las opciones de compilación que deben abrirse según sea necesario. Por ejemplo, elijo abrir CUDA, CUBLAS y CUTLASS aquí. Además, debe tenerse en cuenta que la ruta TVM_HOME aquí debe configurarse en el camino Relax compilado anteriormente.
Luego haga lo siguiente para compilar:
cd ..
mkdir build
cp cmake/config.cmake build
cd build
cmake ..
make -j32
Al compilar aquí, debe instalar Rust, simplemente siga el comando sugerido para instalarlo y una vez completada la compilación, se instalará el programa de chat mlc_chat_cli proporcionado por mlc-llm . Luego, para realizar la conversión y cuantificación del modelo, también necesitamos ejecutar e instalar el paquete mlc_llm en el directorio mlc-llm pip install ..
conversión de modelo
La conversión del modelo aquí básicamente se refiere a este tutorial: https://mlc.ai/mlc-llm/docs/compilation/compile_models.html.
Por ejemplo, python3 -m mlc_llm.build --hf-path StarRing2022/RWKV-4-World-7B --target cuda --quantization q4f16_1podemos cuantificar el peso del modelo RWKV-4-World-7B a 4 bits ejecutando y luego la activación aún se almacena en FP16.

El objetivo especifica en qué plataforma queremos ejecutar. Aquí, el gráfico compuesto por todo el modelo se compilará en una biblioteca de enlaces dinámicos (es decir, el IRModule de TVM) para el programa mlc_chat_cli posterior (esto se genera al compilar mlc- llm). .
De forma predeterminada, se creará una nueva carpeta dist/models en el directorio actual para almacenar el modelo cuantificado, el archivo de configuración y la biblioteca de enlaces. El modelo convertido y cuantificado se almacenará en el subdirectorio dist del directorio donde se encuentra el comando actual ( se creará automáticamente), también puede clonar manualmente el modelo de huggingface en la carpeta dist/models. La estructura del modelo después de la cuantificación es la siguiente:

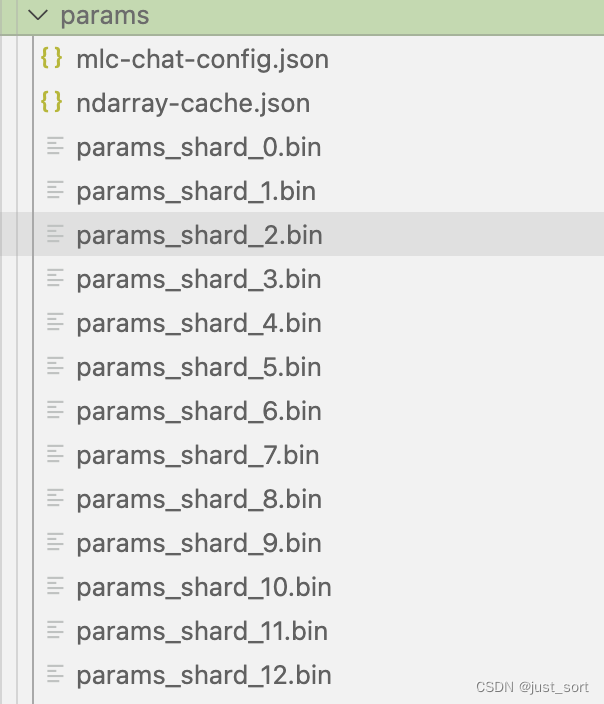
La especificación aquí mlc-chat-config.jsonproviene de algunos hiperparámetros generados por el modelo, como top_p, temperatura, etc.
Finalmente, antes de razonar, también necesitamos copiar el archivo tokenizer_model preparado al principio a esta carpeta de parámetros.
realizar razonamiento
Ejecutamos el siguiente comando en la carpeta superior de mlc-llm:
./mlc-llm/build/mlc_chat_cli --model RWKV-4-World-7B-q0f16
RWKV-4-World-7B-q0f16 se puede reemplazar con el nombre de su modelo cuantificado. Después de cargar y ejecutar el indicador del sistema, podrá charlar felizmente con el modelo RWKV-4-World.

El programa tiene algunos comandos especiales para salir, comprobar velocidad, etc.:
Pruebas de rendimiento
| hardware | Método de cuantificación | velocidad |
|---|---|---|
| A800 | q0f16 | precarga: 362,7 tok/s, decodificación: 72,4 tok/s |
| A800 | q4f16_1 | precarga: 1104,7 tok/s, decodificación: 122,6 tok/s |
Aquí hay 2 conjuntos de datos de rendimiento. Si está interesado, puede probar otras configuraciones.
Método de depuración capa por capa
Al adaptar el modelo 1.5B, el resultado del razonamiento es nan. Puede usar el archivo mlc-llm/tests/debug/dump_intermediate.py para alinear los resultados de entrada y del tokenizador y luego depurarlo. Puede simular con precisión el razonamiento del modelo e imprimir cada uno. El valor intermedio de la capa, para que podamos ver fácilmente en qué capa aparece el modelo nan.
0x2 Implementar RWKV-4-World-3B en Apple M2
No hay mucha diferencia entre implementar en Mac y implementar en cuda, la razón principal es que al compilar relax y mlc-llm, la opción de compilación ahora debería elegir Metal en lugar de cuda. Sugiero que es mejor abordar el problema de compilación en un entorno anconda, no en el entorno Python que viene con el sistema.
Al compilar relax, debe habilitar el uso de las opciones Metal y LLVM al mismo tiempo. Si el sistema no tiene LLVM, puede instalarlo primero con Homebrew.
Utilice las siguientes opciones al generar config.cmake en mlc-llm:
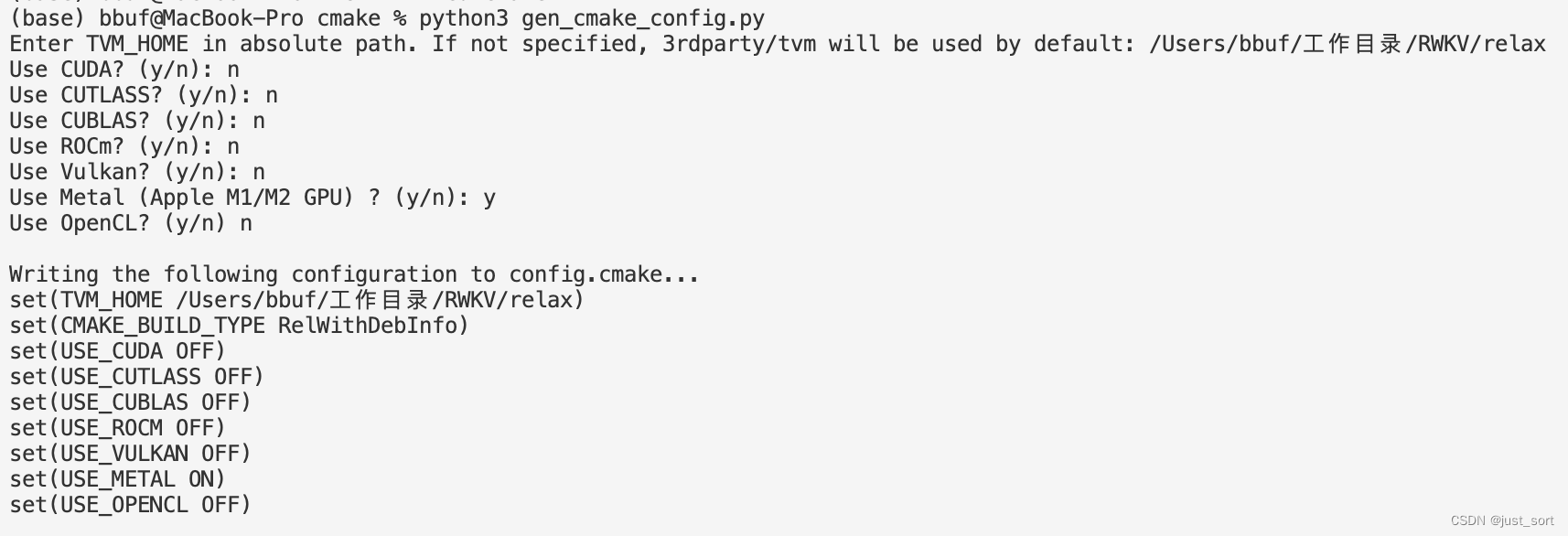 Compile y
Compile y pip install .luego cuantice el modelo usando los siguientes comandos:
python3 -m mlc_llm.build --hf-path StarRing2022/RWKV-4-World-3B --target metal --quantization q4f16_1
El registro durante el proceso de cuantificación es el siguiente:
(base) bbuf@MacBook-Pro RWKV % python3 -m mlc_llm.build --hf-path StarRing2022/RWKV-4-World-3B --target metal --quantization q4f16_1
Weights exist at dist/models/RWKV-4-World-3B, skipping download.
Using path "dist/models/RWKV-4-World-3B" for model "RWKV-4-World-3B"
[09:53:08] /Users/bbuf/工作目录/RWKV/relax/src/runtime/metal/metal_device_api.mm:167: Intializing Metal device 0, name=Apple M2
Host CPU dection:
Target triple: arm64-apple-darwin22.3.0
Process triple: arm64-apple-darwin22.3.0
Host CPU: apple-m1
Target configured: metal -keys=metal,gpu -max_function_args=31 -max_num_threads=256 -max_shared_memory_per_block=32768 -max_threads_per_block=1024 -thread_warp_size=32
Host CPU dection:
Target triple: arm64-apple-darwin22.3.0
Process triple: arm64-apple-darwin22.3.0
Host CPU: apple-m1
Automatically using target for weight quantization: metal -keys=metal,gpu -max_function_args=31 -max_num_threads=256 -max_shared_memory_per_block=32768 -max_threads_per_block=1024 -thread_warp_size=32
Start computing and quantizing weights... This may take a while.
Finish computing and quantizing weights.
Total param size: 1.6060066223144531 GB
Start storing to cache dist/RWKV-4-World-3B-q4f16_1/params
[0808/0808] saving param_807
All finished, 51 total shards committed, record saved to dist/RWKV-4-World-3B-q4f16_1/params/ndarray-cache.json
Finish exporting chat config to dist/RWKV-4-World-3B-q4f16_1/params/mlc-chat-config.json
[09:53:40] /Users/bbuf/工作目录/RWKV/relax/include/tvm/topi/transform.h:1076: Warning: Fast mode segfaults when there are out-of-bounds indices. Make sure input indices are in bound
[09:53:41] /Users/bbuf/工作目录/RWKV/relax/include/tvm/topi/transform.h:1076: Warning: Fast mode segfaults when there are out-of-bounds indices. Make sure input indices are in bound
Save a cached module to dist/RWKV-4-World-3B-q4f16_1/mod_cache_before_build.pkl.
Finish exporting to dist/RWKV-4-World-3B-q4f16_1/RWKV-4-World-3B-q4f16_1-metal.so
También es necesario copiar el archivo tokenizer_model al directorio de parámetros de la carpeta del modelo cuantificado y luego ejecutar el siguiente comando para iniciar el programa de chat:
./mlc-llm/build/mlc_chat_cli --model RWKV-4-World-3B-q0f16
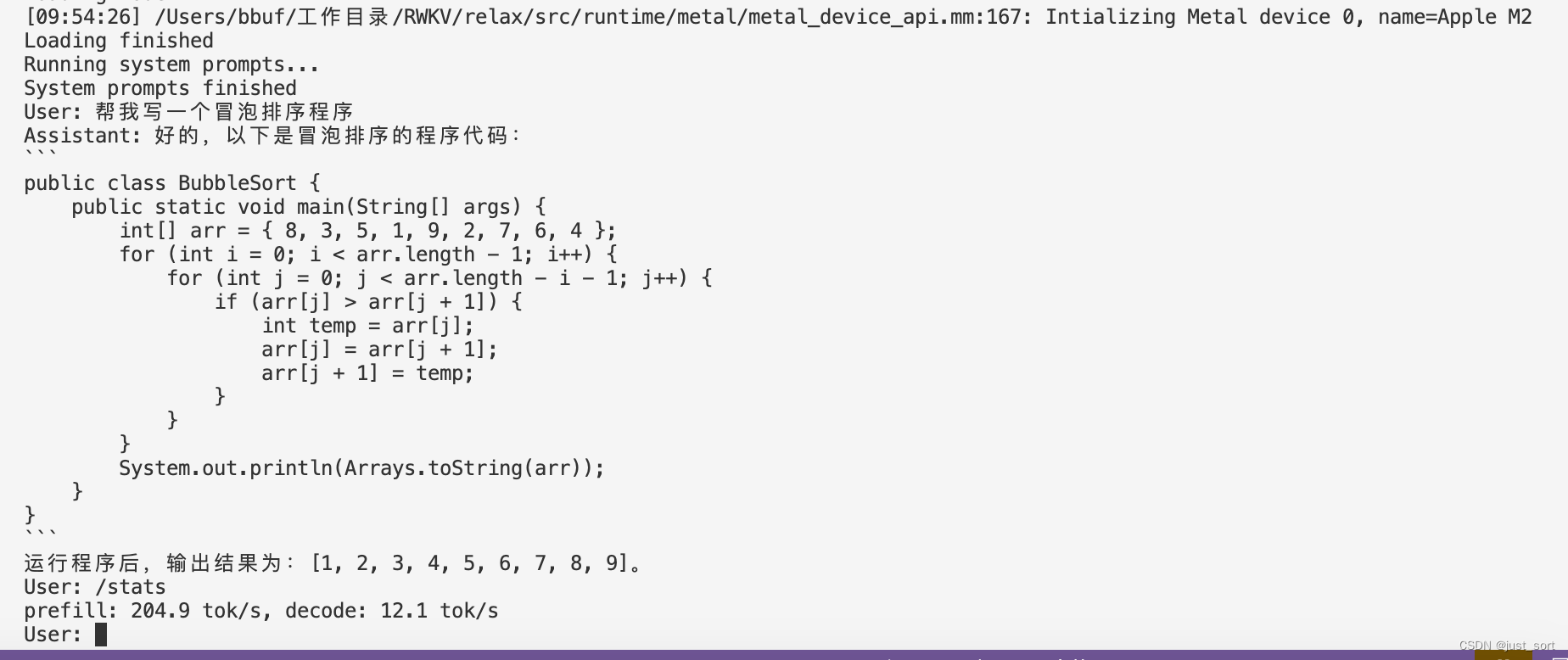
Finalmente, aquí hay una prueba de velocidad de Mac M2:
| hardware | Método de cuantificación | velocidad |
|---|---|---|
| manzana m2 | q0f16 | 204,9 tok/s, decodificación: 12,1 tok/s |
| manzana m2 | q4f16_1 | precarga: 201,6 tok/s, decodificación: 26,3 tok/s |
Se recomienda utilizar la configuración de q4f16, para que la respuesta sea más rápida.
0x3 Resumen
Este artículo presenta el trabajo de adaptación reciente del autor para mlc-llm. Bienvenidos a todos a experimentar los modelos MLC-LLM y RWKV-World.