En el último número, escribí un enlace al proyecto de currículum ¿Qué debo hacer si el proyecto de currículum es malo? Te enseñaré cómo desempeñarte mal. Después de que un lector hizo lo mismo, ganó el puesto de supervisor. Después de publicarlo en el grupo, muchos amigos han venido recientemente a instarme a actualizar los puntos de conocimiento relacionados con el proyecto del servidor.
Este resumen se basa en las preguntas de cada entrevista cuando estaba contratando en otoño, y revisé y llené los vacíos continuamente, y lo repetí muchas veces. Cada vez que encuentro un nuevo problema, lo reviso y lo resumo en Internet. En ese momento, lo leía principalmente yo solo y no había ningún problema de derechos de autor, pero ahora quiero publicarlo en la plataforma pública de la cuenta oficial de WeChat. , Así que necesito volver a consultar la fuente. La fuente del contenido original, respeta los logros del autor original. Haré todo lo posible para confirmar la fuente. ¡Avíseme si hay alguna infracción!
dicho antes
Las funciones implementadas por cada proyecto de servidor son diferentes y las direcciones que se pueden extender también serán diferentes. Los detalles del proyecto en sí en la primera sección se limitan a los proyectos mejorados individuales. Solo necesita consultar el contenido que se superpone. contigo mismo.
Las preguntas del entrevistador son muy extrañas. Por lo general, cuando le preguntan, es poco probable que le pregunten un determinado punto de conocimiento con mucha precisión como el título a continuación. Por lo general, es posible que surjan algunas preguntas generales y, en este momento, es necesario localizar rápidamente lo que le interesa. Por eso debemos mantener lo mismo y guiar al entrevistador hacia el contenido que ha preparado.
Al mismo tiempo, es necesario enfatizar que el aprendizaje no tiene fin. El contenido de este artículo solo puede considerarse como una introducción para brindarle alguna referencia, y no puede detenerse aquí. Aún debe continuar haciéndolo. Un aprendizaje más profundo y detallado ~
Por supuesto, también sé que esta es solo mi pregunta de entrevista personal y puede que no sea muy completa. Abriré esta nota más adelante. Si a algunos estudiantes se les hacen nuevas preguntas sobre este proyecto, pueden actualizarlo y mantenerlo juntos. !
1. Detalles del proyecto
Introducción al proyecto
El objetivo principal de este proyecto es analizar y procesar la solicitud de enlace del navegador y devolver una respuesta al cliente del navegador después del procesamiento, como texto, imágenes, videos, etc. El método de procesamiento del backend del servidor utiliza comunicación de socket, utilizando multiplexación IO múltiple , se pueden procesar múltiples solicitudes al mismo tiempo, el análisis de la solicitud utiliza grupo de subprocesos preparado previamente , usando el modo reactor, el subproceso principal es responsable de monitoreando IO, y después de obtener la solicitud de IO, el objeto de solicitud se coloca en la cola de solicitudes y se entrega al subproceso de trabajo. Los subprocesos de trabajo que duermen en la cola de solicitudes se activan para la lectura de datos y el procesamiento lógico. Utilice == máquina de estado == idea para analizar mensajes Http, admita solicitudes GET/POST , admita conexiones largas/cortas;
Utilice el temporizador basado en el pequeño montón raíz para cerrar la solicitud de tiempo de espera y resolver el problema del tiempo de espera y la ocupación de recursos del sistema de conexión.
Descripción general de la arquitectura
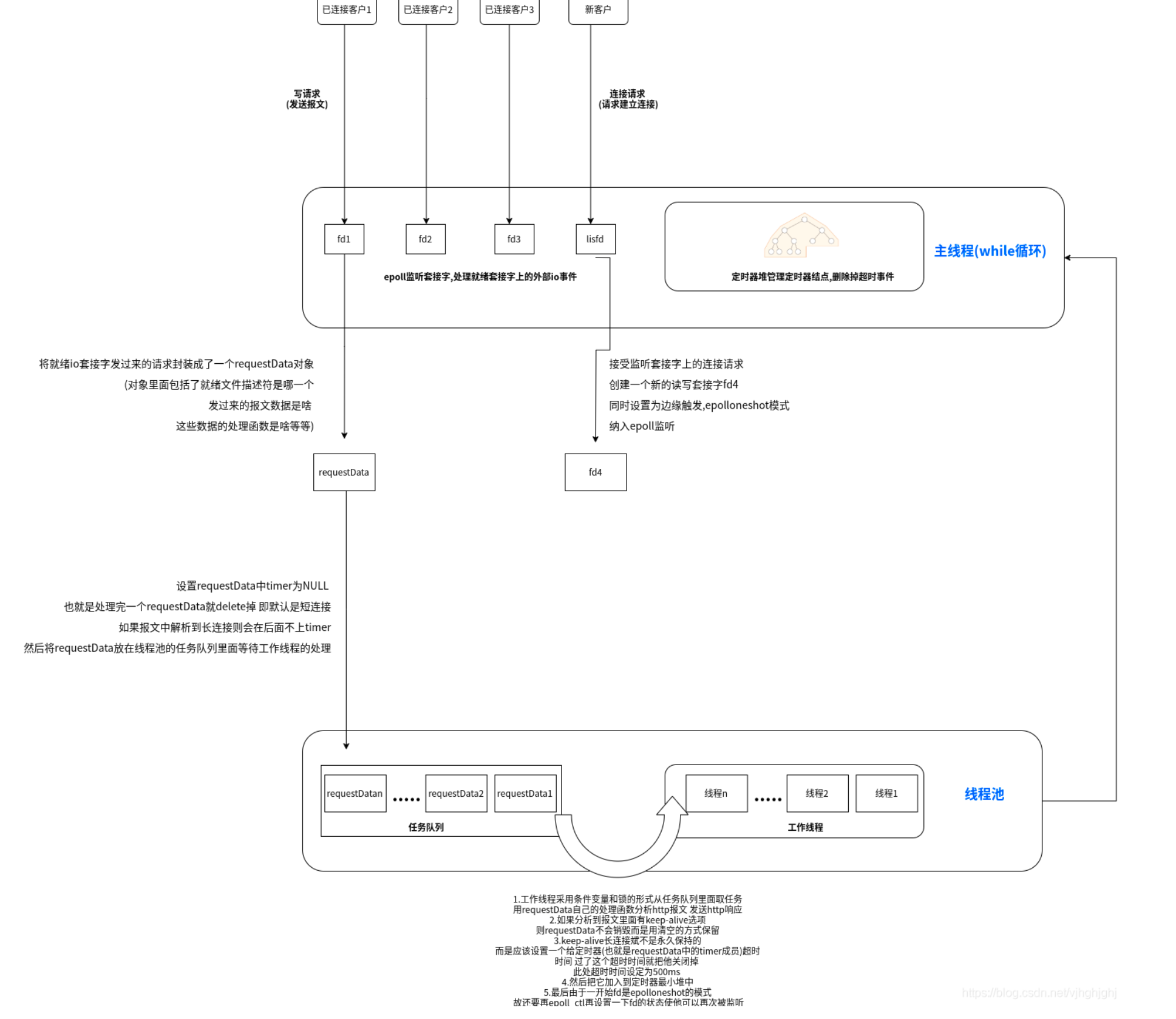
Hilo principal:
-
En el hilo principal, epoll escucha el socket y maneja eventos de IO externos en el socket listo, incluida la solicitud de escritura (enviar mensaje) del cliente conectado o la solicitud de conexión del nuevo cliente.
-
Encapsule la solicitud enviada por el socket IO listo en un objeto requestData, que incluye el descriptor del archivo listo, cuáles son los datos del mensaje enviado, cuál es la función de procesamiento de estos datos, etc.
-
Y configure el temporizador en requestData en NULL, es decir, elimínelo después de procesar un requestData, y el valor predeterminado es una conexión corta. Si el mensaje se resuelve en una conexión larga, el temporizador se agregará más tarde. Luego coloque requestData en la cola de tareas del grupo de subprocesos y espere el procesamiento del subproceso de trabajo.
-
El hilo principal también tiene un bucle while, que utiliza el montón del temporizador para administrar los nodos del temporizador y eliminar eventos de tiempo de espera.
hilo de trabajo:
-
El hilo de trabajo utiliza variables de condición y bloqueos para recuperar tareas de la cola de tareas, utiliza la función de procesamiento propia de requestData para analizar mensajes http y envía respuestas http.
-
Si se analiza que hay una opción de mantener vivo en el mensaje, los requestData no se destruirán, sino que se conservarán mediante el borrado.
-
La conexión larga de mantener vivo no está reservada permanentemente, pero un temporizador (es decir, el miembro del temporizador en mantener vivo) está configurado para que expire el tiempo de espera. Después de exceder el tiempo, se cerrará. Aquí, el tiempo de espera está configurado en 500 ms.
-
Luego agréguelo al montón mínimo del temporizador.
-
Finalmente, dado que fd está en modo epolloneshot al principio, es necesario configurar el estado de fd nuevamente con epoll ctl para que pueda ser monitoreado nuevamente.
Entre ellos, el subproceso de trabajo en el grupo de subprocesos accede a las tareas en la cola de tareas y el subproceso de trabajo llama a handleRequest en requestData para analizar la solicitud HTTP utilizando la máquina de estado.
Bloquea la señal SIGPIPE
Antes de que comience todo el ciclo de monitoreo de epoll, primero se debe bloquear la señal SIGPIPE.
De forma predeterminada, leer y escribir en un socket cerrado activará la señal sigpipe. La acción predeterminada para esta señal es cerrar el proceso, lo que obviamente no es lo que queremos. Por lo tanto, necesitamos restablecer la función de operación de devolución de llamada de señal de sigpipe, como ignorar la operación, etc., para evitar llamar a su operación predeterminada.
//处理sigpipe信号
void handle_for_sigpipe(){
struct sigaction sa; //信号处理结构体
memset(&sa, '\0', sizeof(sa));
sa.sa_handler = SIG_IGN;//设置信号的处理回调函数 这个SIG_IGN宏代表的操作就是忽略该信号
sa.sa_flags = 0;
if(sigaction(SIGPIPE, &sa, NULL))//将信号和信号的处理结构体绑定
return;
}
multiplexación de puertos
Utilice setsockopt(listen_fd, SOL_SOCKET, SO_REUSEADDR, &optval, sizeof(optval) para eliminar el error "Dirección ya en uso" durante el enlace, es decir, configure la multiplexación de puertos SO_REUSEADDR
supervisión epoll y EPOLLONESHOT
Utilice epoll al supervisar socketsDisparador de flanco + EPOLLONESHOT + IO sin bloqueo
Evento EPOLLONESHOT
Incluso si se puede utilizar el modo activado por flanco, todavía se mantiene un cierto tiempo en un enchufe.puede activarse varias veces. Por ejemplo, un hilo comienza a procesar los datos después de leer los datos en un socket, y durante el procesamiento de datos, hay nuevos datos en el socket para leer (EPOLLIN se activa nuevamente), y en este momento se despierta otro hilo para leer. los nuevos datos. Habrá una situación en la que dos subprocesos operen un socket al mismo tiempo. Una conexión de socket solo es procesada por un hilo a la vez, puede usar epollEPOLLONESHOTlograr.
Para un descriptor de archivo registrado con el evento EPOLLONESHOT, el sistema operativo activa como máximo un evento de escala, de escritura o anormal registrado por él, ydisparar solo una vez。A menos que usemos la función epoll_ctl para restablecer el evento EPOLLONESHOT registrado en el descriptor de archivo.
Cuando un subproceso de este tipo procesa un determinado socket, es imposible que otros subprocesos tengan la oportunidad de operar el socket.Restablezca inmediatamente el evento EPOLLONESHOT en el socket,Para garantizar que la próxima vez que el socket sea legible, se puede activar su evento EPOLLIN, lo que a su vez permite que otros subprocesos procesen el socket varias veces.
Subprocesos múltiples y grupos de subprocesos
Utilice subprocesos múltiples para aprovechar al máximo las CPU de múltiples núcleos y utilice grupos de subprocesos para evitar la creación y destrucción frecuentes de subprocesos y aumentar la sobrecarga del sistema.
- Cree un grupo de subprocesos para administrar subprocesos múltiples. El grupo de subprocesos contiene principalmente colas de tareas y colecciones de subprocesos de trabajo . Agregue tareas a la cola y luego inicie automáticamente estas tareas después de crear subprocesos. Se utiliza un subproceso de trabajo con un número fijo de subprocesos para limitar el número máximo de subprocesos simultáneos.
- Varios subprocesos comparten la cola de tareas, por lo que se requiere la sincronización entre subprocesos y la competencia entre subprocesos de trabajo por la cola de tareas utiliza una combinación de variables de condición y bloqueos mutex .
- Un subproceso de trabajo primero agrega un mutex . Cuando el número de tareas en la cola de tareas es 0, se bloquea en la variable de condición. Cuando el número de tareas es mayor que 0, la condición notifica el subproceso bloqueado bajo la variable de condición. variable, y estos hilos continúan compitiendo para obtener tareas.
- La programación de tareas en la cola de tareas adopta un algoritmo por orden de llegada
El factor limitante más directo para la cantidad de subprocesos en el grupo de subprocesos es la cantidad de procesadores de CPU.
Si la CPU es de cuatro núcleos, entonces para tareas que requieren un uso intensivo de la CPU, la cantidad de subprocesos en el grupo de subprocesos debe ser preferiblemente 4 o +1 para evitar que otros factores provoquen el bloqueo.
Si se trata de una tarea con uso intensivo de IO, generalmente tiene más núcleos que la CPU, porque la competencia entre subprocesos no son recursos de CPU sino IO, y el procesamiento de IO es generalmente más lento. Los subprocesos con más núcleos lucharán por más tareas para el CPU: No provocará inactividad de la CPU ni desperdiciará recursos al procesar IO en el condado.
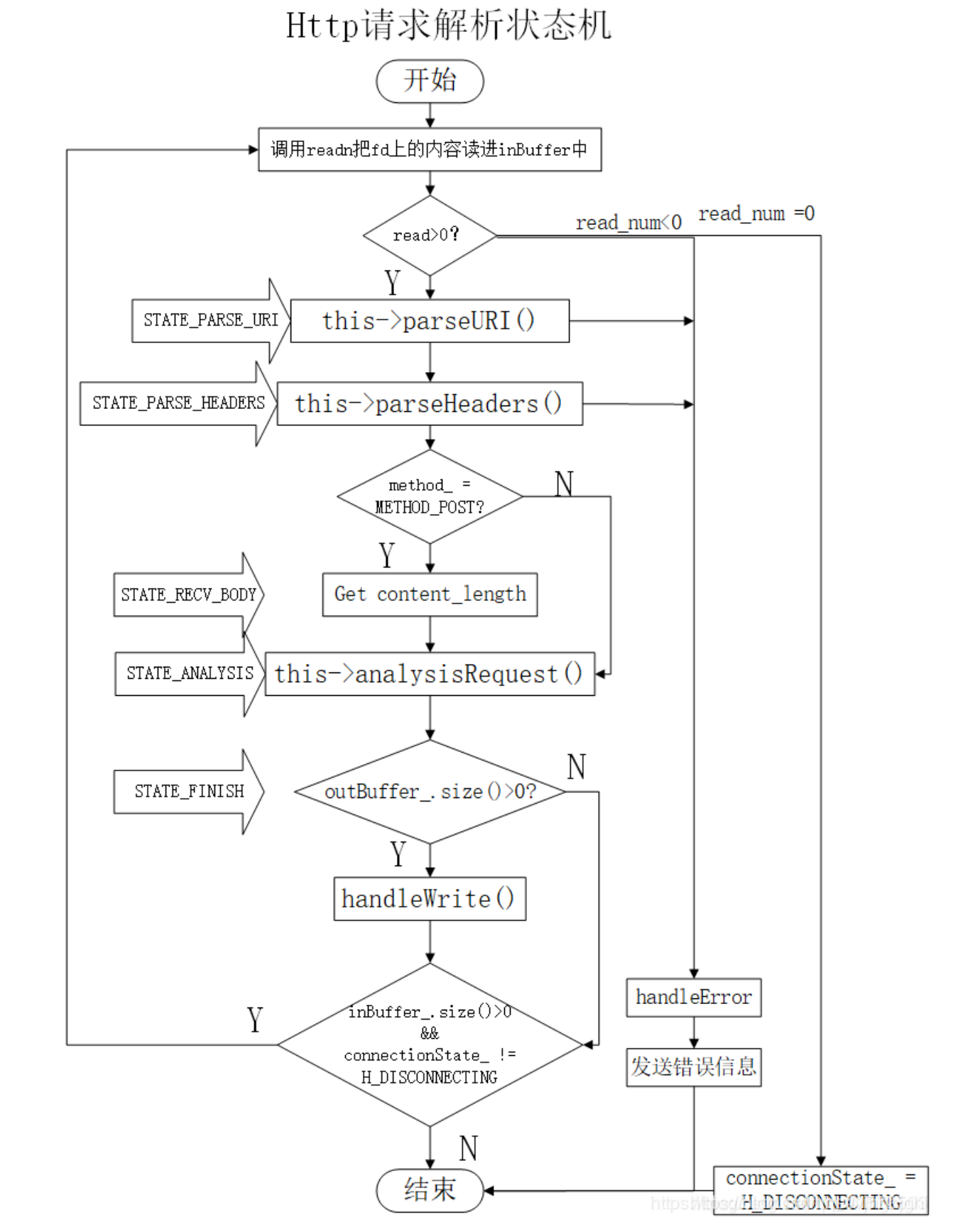
Análisis de solicitudes HTTP
-
Usando el modo de procesamiento de eventos del reactor, el hilo principal solo es responsable de monitorear IO. Después de obtener la solicitud de IO, el objeto de solicitud se coloca en la cola de solicitudes y se entrega al hilo de trabajo, que es responsable de la lectura de datos y la lógica. Procesando.
En el modo proactor, todas las operaciones de lectura y escritura de IO se entregan al subproceso principal y al kernel para su procesamiento, y el subproceso de trabajo solo es responsable de la lógica empresarial.
-
Después de que el hilo principal monitorea cíclicamente que el socket de lectura y escritura tiene un mensaje, el hilo de trabajo llama a handleRequest en requestData para analizar la solicitud HTTP utilizando la máquina de estado.
-
La máquina de estado del proceso de análisis de mensajes http y de respuesta de mensajes se muestra en la figura anterior.
Durante un ciclo, la máquina de estado primero lee un paquete de datos y luego juzga cómo procesar el paquete de datos de acuerdo con la variable de estado actual. Una vez procesado el paquete de datos, la máquina de estado realiza la transición de estado pasando el valor del estado objetivo a la variable de estado actual. Luego, cuando la máquina de estados realice el siguiente ciclo, ejecutará la lógica correspondiente al nuevo estado.
-
Análisis de mensajes GET y POST
Vale la pena señalar que aquí se admite el análisis de dos tipos de mensajes GET y POST.
```c++
//get报文:请求访问的资源。(客户端:我想访问你的某个资源)
GET /0606/01.php HTTP/1.1\r\n 请求行:请求方法 空格 URL 空格 协议版本号 回车符 换行符
Host: localhost\r\n 首部行 首部行后面还有其他的这里忽略
\r\n 空行分割
空 实体主体
```
```c++
//post报文:传输实体主体。(客户端:我要把这条信息告诉你)
POST /0606/02.php HTTP/1.1 \r\n 请求行
Host: localhost\r\n 首部行 首部行中必须有Contenr-length,告诉服务器我要给你发的实体主体有多少字节
Content-type: application/x-www-form-urlencoded\r\n
Contenr-length: 23\r\n
\r\n 空行分割
username=zhangsan&age=9 \r\n 实体主体
```
Si se trata de un mensaje de publicación, debe haber un campo de longitud del contenido en la línea del encabezado, pero get no, así que elimine este campo y encuentre la longitud que se utilizará cuando se obtenga el cuerpo de la entidad más adelante. Luego baje y envíe el mensaje de respuesta http correspondiente.
Para el mensaje de obtención, el cuerpo de la entidad está vacío, simplemente lea los datos de la URL de la línea de solicitud directamente y luego baje y envíe el mensaje de respuesta http correspondiente.
-
Cuando obtenemos una solicitud HTTP completa y correcta, llegamos a
analysisRequesla parte del código. Primero debemos realizar un procesamiento diferente para las solicitudes GET y diferentes solicitudes POST (inicio de sesión, registro, solicitud de imágenes, videos, etc.) y luego analizar las propiedades. del archivo de destino , si el archivo de destino existe, es legible por todos los usuarios y no es un directorio, entonces == use ==mmappara asignarlo a la dirección de memoriam_file_address== y dígale a la persona que llama que el archivo se obtuvo correctamente. -
Esto es para soportar el mantenimiento de conexión prolongada.
Después de leer los datos de la primera fila, si el solicitante configura una conexión larga, el campo Conexión se mantiene activo como base.
Si se lee este campo, requestData se restablecerá después de que se analice el mensaje y se envíe de vuelta.
Luego restablezca el atributo del socket con epoll_ctl y agregue epoll listening nuevamente.
Optimización del temporizador
Implementé un pequeño temporizador de montón raíz en el tiempo == eliminando solicitudes de tiempo de espera ==, usando la cola de prioridad de STL para administrar el temporizador
-
Optimización: originalmente era un temporizador basado en una lista enlazada ascendente, y la cadena de temporizadores ascendentes organiza los temporizadores en orden ascendente según el tiempo de espera. Sin embargo, según el temporizador de la lista enlazada ascendente, la eficiencia de agregar un temporizador es baja O (n), y se utiliza el temporizador de administración de cola prioritaria . La capa inferior de la cola prioritaria es un pequeño montón raíz, y el tiempo la complejidad de agregar un temporizador es O (log (n)), la complejidad de tiempo de eliminar el temporizador es O (1) y la complejidad de tiempo de ejecutar la tarea del temporizador es O (1).
La función de alarma activa la señal SIGALRM periódicamente y la función de procesamiento de señales utiliza la canalización para notificar al bucle principal que ejecute las tareas de sincronización en la lista vinculada del temporizador.
El valor predeterminado es una conexión corta. Si se detecta una conexión larga durante el procesamiento de la tarea, se unirá a epoll para continuar respondiendo, configurará un temporizador (mytimer) y lo colocará en la cola de prioridad.
El uso de dos cerraduras.
La primera son las operaciones de adición y recuperación de la cola de tareas de solicitud; ambas deben estar bloqueadas y cooperar con variables de condición para abarcar varios subprocesos.
El segundo es agregar y eliminar nodos del temporizador, que deben bloquearse, y tanto el hilo principal como el hilo de trabajo deben operar la cola del temporizador.
2. Puntos de conocimiento relacionados con exámenes comunes.
1. Cola prioritaria
Una cola de prioridad puede obtener el valor máximo en tiempo O (1) y puede extraer el valor máximo o insertar valores arbitrarios en tiempo O (log n).
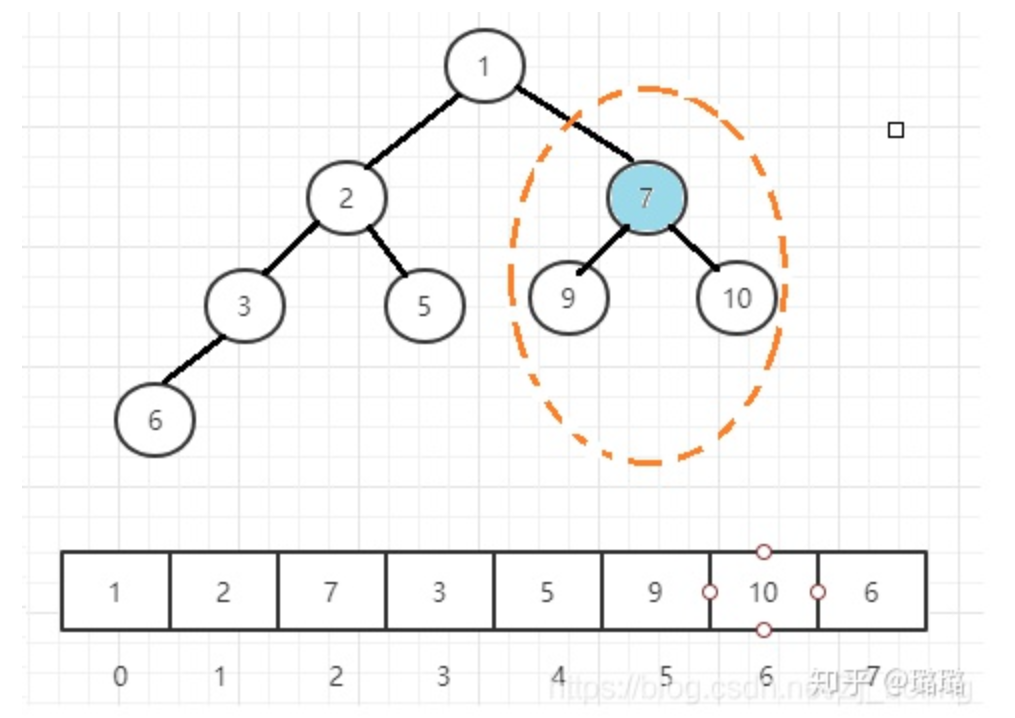
Las colas de prioridad a menudo se implementan mediante un montón. Un montón es un árbol binario completo en el que el valor de cada nodo es siempre menor o igual que el valor de sus nodos secundarios. Cuando implementamos un montón, generalmente usamos una matriz en lugar de construir un árbol con punteros. Esto se debe a que el montón es un árbol binario completo, por lo que cuando se representa mediante una matriz, la posición del nodo padre del nodo en la posición i debe ser [(i-1)/2], y las posiciones de sus dos nodos secundarios debe ser 2i+1 y 2i+2.
El siguiente es el método de implementación del montón: las dos operaciones principales son flotar y hundirse, como el montón raíz pequeño: si un nodo es más pequeño que el nodo principal, entonces los dos nodos deben intercambiarse; después del intercambio, puede ser más pequeño que su nuevo padre Los nodos son grandes, por lo que las operaciones de comparación e intercambio deben realizarse continuamente, lo que llamamos flotante; de manera similar, si un nodo es más grande que un nodo secundario, las operaciones de comparación e intercambio deben realizarse continuamente hacia abajo, lo que llamamos hundimiento. Si un nodo tiene dos hijos, siempre intercambiamos el hijo más pequeño.
vector<int> heap;
// 获得最小值
void top() {
return heap[0];
}
// 插入任意值:把新的数字放在最后一位,然后上浮
void push(int k) {
heap.push_back(k);
swim(heap.size() - 1);
}
// 上浮
void swim(int pos) {
//如果父节点大于当前插入点,则交换,即上浮
//除非父节点小于等于插入点,或者pos=0,即已经上浮到根节点最小值,停止循环
while (pos > 0 && heap[(pos-1)/2] > heap[pos])) {
swap(heap[(pos-1)/2], heap[pos]);
pos = (pos-1)/2;
}
}
//最小堆的删除指的是删除根节点的最小值,即数组的第一个值
//为了不破坏最小堆结构,y由于少了第一个元素,我们把把最后一个数字挪到开头,然后进行下沉
void pop() {
heap[0] = heap.back();
heap.pop_back();
sink(0);
}
// 下沉
//如果当前点 大于 子节点中较小的那个,则交换,即下沉
//除非当前点小于等于 子节点中较小的那个,或者当前点已经到达最底部,即已经下沉到最底部,退出循环
void sink(int pos) {
while (2 * pos + 1 < heap.size()) {
int i = 2 * pos + 1;
if (i+1 < heap.size() && heap[i] > heap[i+1]) ++i;//如果有两个子节点,找到较小的那个交换
if (heap[pos] <= heap[i]) break;
swap(heap[pos], heap[i]);
pos = i;
}
}
Al intercambiar los signos mayor que y menor que en el algoritmo, también podemos obtener una cola de prioridad que obtiene rápidamente el valor mínimo.
Cinco modelos IO
Modelo de E/S de red
Network IO implica espacio de usuario y espacio de kernel y generalmente pasa por dos etapas:
- Fase uno : esperar a que los datos estén listos , es decir, esperar a que los datos de la red se copien en el búfer del kernel
- La segunda etapa : copiar datos del búfer del kernel al búfer del usuario
Los datos anteriores listos pueden entenderse como la llegada de datos al socket. Según la diferencia entre las dos etapas anteriores , aparecen varios modelos de E/S de red, a continuación analizaremos de acuerdo con estas dos etapas.
1. Bloquear E/S
La persona que llama llama a una función, espera a que la función regrese, no hace nada durante el período y sigue verificando si la función ha regresado y debe esperar a que la función regrese antes de continuar con el siguiente paso. El proceso del usuario se bloquea hasta que se completan las dos etapas, es decir, la primera etapa bloqueará la espera de datos y la segunda etapa bloqueará los datos del kernel copyal espacio del usuario, solo cuando copyel kernel regrese después de que se completen los datos. , el proceso del usuario desbloqueará el estado y se ejecutará nuevamente.
linuxsocketpredeterminado enblocking
Desventajas: procesar inteligentemente una operación al mismo tiempo, baja eficiencia
Conclusión : al bloquear IO, ambas etapas están bloqueadas.
2. E/S sin bloqueo
Cuando el usuario procesa la llamada al sistema, si no hay datos, regresará directamente, sin importar si el evento ha ocurrido o no, si no ha ocurrido, devolverá -1. Por tanto, la preparación de datos en una sola fase no bloquea los procesos del usuario. Sin embargo, el proceso del usuario necesita preguntar constantemente si los datos del kernel están listos (lo que hará que la CPU esté inactiva y desperdicie recursos, por lo que rara vez se usa). Cuando los datos estén listos, el proceso del usuario se bloqueará hasta que los datos se copien del espacio del kernel al espacio del usuario (la segunda etapa) y el kernel devuelve el resultado.
Se puede fcntlconfigurar socketen NON-BLOCKING( fcntl(fd, F_SETFL, O_NONBLOCK);) para que no bloquee .
Aquí debe juzgar el valor de retorno de -1 por separado. Tome recvel valor de retorno como ejemplo. Cuando el valor de retorno es -1, primero debe juzgar errno.errno EAGAINsignifica que la operación de recepción no se completó, si errno es EWOULDBLOCK, significa que no hay datosNinguno de estos dos casos es un error real del sistema. Una vez excluidos estos dos, significa que se ha encontrado un error del sistema. significado:
- Si es mayor que 0 , los datos recibidos se completan y el valor de retorno es el número de bytes recibidos.
- Igual a 0 , la conexión se ha desconectado normalmente
Desventajas: el sondeo ocupado requiere recursos de CPU.
Conclusión : IO sin bloqueo no se bloquea en la primera etapa, pero se bloquea en la segunda etapa.
3. Multiplexación IO (select/poll/epoll)
select/poll/epollLinux implementa la multiplexación IO mediante el uso de funciones, que a su vez están bloqueadas . Pero la diferencia con el bloqueo de IO es que estas funciones pueden bloquear múltiples operaciones de IO al mismo tiempo . Puede monitorear múltiples conexiones de red en un solo proceso/hilo al mismo tiempo socket fd. Una vez que se activa un evento , la función de operación IO se llama y procesa en consecuencia.
Conclusión : Ambas etapas están bloqueadas y la ventaja es que un solo subproceso puede monitorear y procesar múltiples conexiones de red al mismo tiempo.
Si la cantidad de conexiones no es muy alta, es posible que el servidor web que usa select/epoll no necesariamente tenga un mejor rendimiento que el servidor web que usa subprocesos múltiples + IO de bloqueo, y el retraso puede ser mayor. Porque el primero requiere dos llamadas al sistema (select/epoll + read), mientras que el segundo solo tiene una (read). Pero en el caso de una gran cantidad de conexiones, se destacan las ventajas de select/epoll.
4. IO impulsada por señal
Linux utiliza sockets para IO controlados por señales. A través de sigactionllamadas al sistema, se establece un socket para IO controlados por señales y se vincula una función de procesamiento de señales , sigactionque no se bloqueará y regresará inmediatamente. El proceso continúa ejecutándose. Cuando los datos están listos, el kernel genera una SIGIOseñal para el proceso y luego llama a los datos recibidos en la función de procesamiento de señales recv.
La diferencia con la IO sin bloqueo es que proporciona un mecanismo de notificación de mensajes, que no requiere que los procesos del usuario realicen sondeos y comprobaciones continuas, reduce la cantidad de llamadas al sistema y mejora la eficiencia.
Conclusión : sin bloqueo de una etapa (asíncrono), bloqueo de dos etapas (síncrono)
Los cuatro modelos anteriores tienen una cosa en común : bloqueo de dos etapas , es decir, los procesos de usuario deben participar en operaciones IO reales, por lo que los cuatro modelos anteriores se denominan modelos IO sincrónicos .
5. E/S asíncrona
Linux proporciona una interfaz IO asíncrona aio_ready el kernel regresará inmediatamente después de aio_writerecibir el proceso del usuario sin bloquearse y pasará el descriptor de archivo , el puntero del búfer , el tamaño del búfer , el desplazamiento del archivo , etc. al kernel; cuando los datos estén listos, el kernel envía directamente los datos al espacio del usuario y luego envía una señal al proceso del usuario para procesar los datos del usuario de forma asincrónica ( ). Por lo tanto, el proceso de usuario en IO asíncrono no necesita participar en el proceso de transferencia de datos desde el espacio del kernel al espacio del usuario, es decir, la segunda etapa no se bloquea .aio_readaio_readcopycopyaio_readcopy
Conclusión: No hay bloqueo en ambas fases.
3. Bloqueo y no bloqueo, síncrono y asíncrono
La diferencia entre bloqueo y no bloqueo es si el proceso de usuario se bloqueará durante la preparación de datos de la primera etapa cuando los datos del kernel no estén listos ; la diferencia entre síncrono y asíncronocopy es si el proceso de usuario se bloqueará cuando los datos se transfieran desde el Kernel al espacio de usuario Fase de lectura y escritura de datos .
Síncrono significa que la lectura y escritura de datos en la segunda etapa la realiza la propia parte solicitante; asíncrono significa que la parte solicitante no participa en la lectura y escritura del evento , sino que solo transmite el evento solicitado y el método de notificación cuando sucede algo. otros, y luego la parte solicitante puede ir a Procesar otra lógica. Cuando otras personas escuchan la finalización del procesamiento del evento, notificarán a la parte solicitante sobre el resultado del procesamiento mediante un método de notificación previamente designado.
4. Multiplexación de E/S
¿Qué es la tecnología de multiplexación IO?
En pocas palabras, un solo subproceso/proceso puede monitorear múltiples descriptores de archivos y, una vez que un determinado fd está listo, puede realizar las operaciones de lectura y escritura correspondientes. Al reducir la cantidad de procesos en ejecución, se reduce efectivamente el consumo de cambio de contexto . Sin embargo, select, poll y epoll son esencialmente E / S sincrónicas y deben ser responsables de leer y escribir después de que los eventos de lectura y escritura estén listos, es decir, el proceso de lectura y escritura de datos está bloqueado.
Por qué se necesita la tecnología de multiplexación IO
Para servidores de alto rendimiento . La interfaz que bloquea IO recvfromse bloqueará hasta que se complete la copia de datos, si es un solo hilo , se bloqueará el hilo principal , es decir, todo el programa se bloqueará para siempre . Por supuesto, se puede resolver mediante subprocesos múltiples, es decir, se asigna una conexión a un subproceso para procesar, pero si hay millones de conexiones , es imposible crear millones de subprocesos, después de todo, los recursos del sistema operativo son limitado. Por lo tanto, existe la tecnología de multiplexación IO para resolver la situación en la que un solo hilo monitorea múltiples conexiones de red .
¿Cuáles son las tecnologías de multiplexación IO?
Las principales técnicas de multiplexación de E/S son: y select, tenga en cuenta que estas llamadas al sistema están bloqueadas y las configuraciones que monitorean están bloqueadas . Similar al principio.pollepollsocketnon-blockingselectpoll
seleccionar
Proceso de trabajo:
- Primero construya una lista de descriptores de archivos
readfds, agregue los descriptores de archivos que se monitorearán a la lista yFD_SETestablezcareadfdslos descriptores de archivos correspondientes en 1. - Llame
select, copie la lista de descriptores de archivosreadfdsen el espacio del kernel, monitoree los descriptores de archivos en la lista,轮询esté interesado en fd, si no llegan datos, seleccione se bloqueará hasta que uno o más de estos descriptores de archivos realicen operaciones de IO, el kernel establece el correspondiente bit a 1 y devolver el resultado al espacio de usuario. - El espacio de usuario atraviesa la lista de descriptores de archivos
readfds,FD_ISSETverifica si el fd correspondiente está configurado y, si está configurado, llama a read para leer los datos.
Ventajas : puede escuchar múltiples descriptores de archivos
Desventajas :
- El descriptor de archivo máximo que se puede escuchar tiene un límite superior, que está
fd_setdeterminado por (normalmente 1024) - Es necesario
fd_setcopiar entre el estado de usuario y el estado del kernel, lo cual es costoso - Es imposible saber exactamente qué fds están listos y es necesario atravesar todos los fds cada vez.
- La colección de la lista de descriptores de archivos no se puede reutilizar y debe restablecerse cada vez.
encuesta
pollEs similar al selectmétodo de implementación y la eficiencia es similar. La única forma de describir el conjunto fd es diferente: poll usa la estructura pollfd en lugar de la estructura fd_set de select. Esta estructura struct pollfdcontiene fdel descriptor de archivo que se le confía al kernel para que lo detecte, eventsqué evento se le confía al kernel para que detecte el descriptor de archivo y reventsel evento que realmente ocurre en el descriptor de archivo.
La diferencia es que
- No hay límite en el fd máximo que se puede monitorear , porque su capa subyacente se implementa a través de una lista vinculada ;
pollEl kernel se utilizareventspara establecer si se activan ciertos eventos, por lo que no es necesario restablecerlos cada vez.
struct pollfd{
int fd;
short events;
short revents;
}
epoll
epollEs una tecnología de multiplexación IO más eficiente selectque . pollepoll tiene tres interfaces importantes: epoll_create, epoll_ctl, epoll_wait.
Primero cree una estructura creando una nueva epoll_createen el kernel .eventpoll
Esta estructura creada en el kernel tiene dos datos importantes: uno es la información del descriptor de archivo que debe detectarse, la capa inferior es un árbol rojo-negro y la complejidad temporal de agregar, eliminar y modificar es logn . La otra es la lista lista, que almacena todos los fds (que comparten los nodos del árbol rojo-negro) con la llegada de eventos IO, y la capa inferior es una lista doblemente enlazada .
epoll_ctlEs para administrar esta instancia, incluidas tres operaciones de inserción , eliminación y actualización .
La inserción consiste en utilizar el socket fd y sus eventos correspondientes para construir la estructura e insertarla en eventpollella, y al mismo tiempoSe registrará una función de devolución de llamada para el controlador de interrupciones del kernel , diciéndole al kernel que si llega la interrupción de este identificador, colóquelo en la lista enlazada lista lista .Eliminar es eventpolleliminar y actualizar es modificar la información relacionada con el socket fd, como cambiar los eventos que monitorea.
epoll_waitComo función de detección, es una interfaz de bloqueo : si un evento llega a la lista lista, copiará el evento listo al espacio del usuario (a través epoll_eventde la estructura) y devolverá el número de eventos. Duerma si no hay datos y regrese incluso si no hay datos cuando se acabe el tiempo de espera.
Modo de trabajo de epoll: LT y ET
Suponiendo que se le ha confiado al kernel la tarea de detectar el evento de lectura y detectar el búfer de lectura de fd
Activador de nivel LT (Disparador de nivel) : siempre que haya datos en el búfer, se activará hasta que no haya datos en el búfer. Si el usuario solo lee parte de los datos, o el usuario no lee los datos, y solo el búfer todavía tiene datos, siempre se activará. No se realizará ninguna notificación a menos que se hayan leído los datos del búfer. LT es una forma predeterminada de trabajar y admite sockets tanto de bloque como sin bloque. (leer una vez)
Edge Trigger ET (Edge Trigger) : cuando el búfer cambia de sin datos a datos, epoll notificará al usuario cuando lo detecte. Si el usuario no lee los datos, los datos siempre están en el búfer y epoll no notificará la siguiente detección; si el usuario solo lee parte de los datos, epoll no notificará. epoll_waitNo se reactivará nuevamente hasta la próxima vez que llegue un nuevo paquete de datos del cliente . (lectura en bucle)
ET solo admite socket sin bloqueo; en este modo, cuando el descriptor no está estar listo , el kernel le informa a través de epoll, luego asumirá que sabe que el descriptor de archivo está listo y no volverá a escribir para ese archivo. El descriptor envía más notificaciones listas hasta que se hace algo que hace que el descriptor de archivo ya no esté listo. Si no hay ninguna operación IO en este fd (lo que hace que no esté listo aquí), el kernel no enviará más notificaciones.
ET reduce en gran medida la cantidad de veces que los eventos epoll se activan repetidamente, por lo que es más eficiente que LT. Cuando epoll funciona en modo ET, debe utilizar una interfaz sin bloqueo para evitar privar a las tareas de múltiples descriptores de archivos debido al bloqueo de la operación de lectura/escritura de un identificador de archivo .
- ¿Por qué se debe configurar el no bloqueo en el modo ET?
Debido al modo ET, cuando hay datos, solo se activará una vez, por lo que cada vez que se leen los datos, == debe leer los datos a la vez (debe esperar hasta que regresen EWOULDBLOCK(asegúrese de que se hayan leído todos los datos) o escrito)), por lo que necesitamos configurar un bucle whlie para leer datos, == pero si la lectura está en modo de bloqueo, entonces si no hay datos, se bloqueará, lo que provocará que el programa se congele. Así que leer aquí solo permite modo sin bloqueo, si no hay datos, leer Saldrá del bucle y continuará ejecutando otros programas.
-
Ventajas y desventajas
-
modo ET
Desventajas: la lógica empresarial de la capa de aplicación es compleja, los eventos son fáciles de pasar por alto y es difícil de utilizar bien.
Ventajas: en comparación con el modo LT, la eficiencia es relativamente alta. Maneje el evento tan pronto como se active.
-
Modo LT:
Ventajas: la programación está más en línea con la intuición del usuario y la lógica de la capa empresarial es más simple.
Desventajas: menor eficiencia que ET.
-
Comparación entre epoll y poll, seleccione
-
Para seleccionar y sondear, todos los descriptores de archivos se agregan a sus conjuntos de descriptores de archivos en modo usuario , y cada llamada necesita copiar el conjunto completo al modo kernel ; epoll mantiene todo el conjunto de descriptores de archivos en modo kernel , cada vez que se agrega un descriptor de archivo , es necesario ejecutar una llamada al sistema .
La sobrecarga de las llamadas al sistema es significativa y, en situaciones en las que hay muchas conexiones activas de corta duración, epoll puede ser más lento que select y poll debido a estas grandes sobrecargas de las llamadas al sistema.
-
select usa una tabla lineal para describir el conjunto de descriptores de archivos, y el descriptor de archivo tiene un límite superior ; poll usa una lista vinculada para describir; la capa inferior de epoll se describe mediante un árbol rojo-negro y mantiene una lista vinculada lista , agregando los eventos listos en la tabla de eventos aquí. Al llamar con epoll_wait, simplemente observe si hay datos en esta lista.
-
La mayor sobrecarga de selección y encuesta proviene del proceso del kernel que juzga si un descriptor de archivo está listo : cada vez que se ejecuta una llamada de selección o encuesta, utilizarán un método transversal para recorrer todo el conjunto de descriptores de archivo para determinar si cada archivo el descriptor está activo. ;epoll no necesita verificar de esta manera. Cuando hay actividad, activará automáticamente la función de devolución de llamada de epoll para notificar al descriptor de archivo epoll , y luego el núcleo colocará estos descriptores de archivos listos en la lista de listos y espere a que llamen a epoll_wait.
-
Tanto la selección como la encuesta solo pueden funcionar en el modo LT relativamente ineficiente, mientras que epoll admite los modos LT y ET.
-
En resumen, cuando el número de fds monitoreados es pequeño y cada fd está muy activo , se recomienda usar select y poll; cuando el número de fds monitoreados es grande y solo algunos fds están activos por unidad de tiempo , es obvio usar epoll Mejora el rendimiento.
5. Modo de procesamiento de eventos: reactor y proactor
En el modo de procesamiento de eventos del reactor, el hilo principal solo es responsable de monitorear IO. Después de obtener la solicitud de IO, el objeto de solicitud se coloca en la cola de solicitudes y se entrega al hilo de trabajo, que es responsable de la lectura de datos y la lógica. Procesando.
En el modo proactor, todas las operaciones de lectura y escritura de IO se entregan al subproceso principal y al kernel para su procesamiento, y el subproceso de trabajo solo es responsable de la lógica empresarial.
Los programas de servidor normalmente necesitan manejar tres tipos de eventos: eventos de E/S , señales y eventos de temporización . Con el auge de los patrones de diseño de redes, surgieron los patrones de procesamiento de eventos Reactor y Proactor.
- El modelo de E/S síncrono se utiliza a menudo para implementar el patrón Reactor.
- El modelo de E/S asíncrono se utiliza para implementar el patrón Proactor .
Modo reactor
Modo reactor: el subproceso principal solo es responsable de monitorear si ocurre un evento en el descriptor de archivo y notifica inmediatamente al subproceso de trabajo (unidad lógica) del evento si lo hay. Aparte de eso, el hilo principal no realiza ningún otro trabajo sustancial. La lectura y escritura de datos, la aceptación de nuevas conexiones y el manejo de solicitudes de clientes se realizan en subprocesos de trabajo.
- El flujo de trabajo del modo Reactor implementado utilizando el modelo de E/S síncrono (tomando epoll_wait como ejemplo):
-
El hilo principal registra el evento de lectura lista en el socket en la tabla de eventos del kernel de epoll.
-
El hilo principal llama a epoll_wait para esperar a que se lean los datos en el socket.
-
Cuando hay datos legibles en el socket, epoll_wait notifica al hilo principal. El hilo principal coloca eventos legibles por socket en la cola de solicitudes .
-
Se despierta un hilo de trabajo que duerme en la cola de solicitudes , lee datos del socket, procesa la solicitud del cliente y luego registra el evento de escritura lista en el socket en la tabla de eventos del kernel de epoll.
-
El hilo principal llama a epoll_wait para esperar a que se pueda escribir en el socket.
-
Cuando se puede escribir en el socket, epoll_wait notifica al hilo principal. El hilo principal coloca eventos grabables en el socket en la cola de solicitudes.
-
Se despierta un proceso de trabajo que duerme en la cola de solicitudes y escribe el resultado del servidor que procesa la solicitud del cliente en el socket.
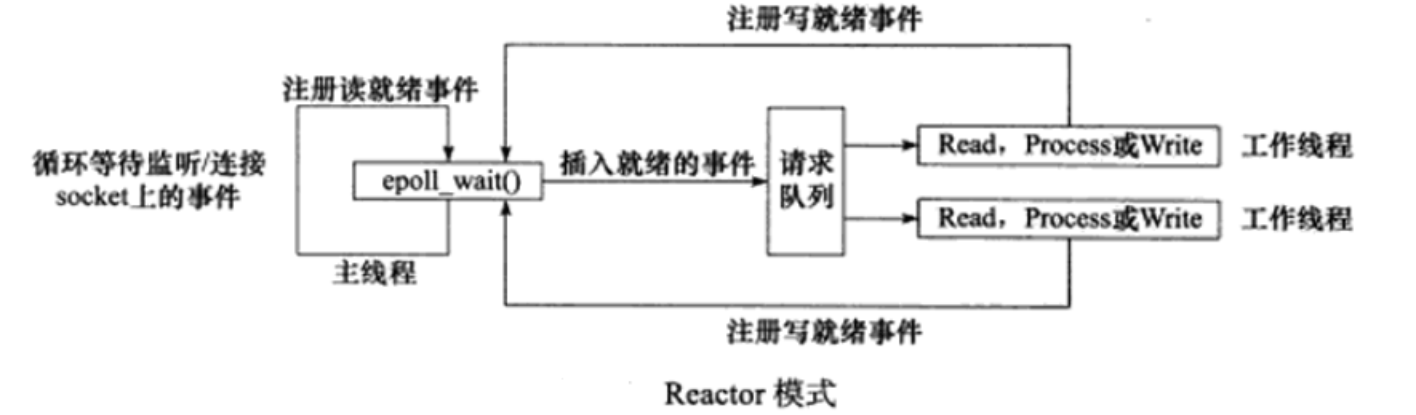
Después de que el subproceso de trabajo saque el evento de la cola de solicitudes, decidirá cómo procesarlo según el tipo de evento: para eventos legibles, realice operaciones de lectura de datos y procesamiento de solicitudes; para eventos grabables, realice operaciones de escritura de datos. Por lo tanto, no es necesario distinguir entre los llamados "hilos de trabajo de lectura" y "hilos de trabajo de escritura" en el modo Reactor.
Modo proactor
En el modo Proactor , todas las operaciones de E/S se entregan al subproceso principal y al kernel para su procesamiento, y el subproceso de trabajo solo es responsable de la lógica empresarial.
- El flujo de trabajo del modo Proactor implementado utilizando el modelo de E/S asíncrono (tome aio_read y aio_write como ejemplos):
- El hilo principal llama a la función aio_read para registrar el evento de finalización de lectura en el socket con el kernel y le dice al kernel la ubicación del búfer de lectura del usuario y cómo notificar a la aplicación cuando se completa la operación de lectura (aquí, tome una señal como ejemplo) y el hilo principal continúa procesando otra lógica
. - Cuando los datos del socket se leen en el búfer del usuario, el kernel enviará una señal a la aplicación para notificarle que los datos están disponibles.
- La función de procesamiento de señales predefinida de la aplicación selecciona un subproceso de trabajo para procesar la solicitud del cliente. Después de que el subproceso de trabajo procesa la solicitud del cliente, llama a la función aio_write para registrar el evento de finalización de escritura en el socket con el kernel y le dice al kernel dónde escribe el usuario el búfer y cómo notificar a la aplicación cuando se completa la operación de escritura. (aún tome la señal como ejemplo)
- El hilo principal continúa procesando otra lógica.
- Después de que los datos en el búfer del usuario se escriben en el socket, el kernel enviará una señal a la aplicación para notificarle que los datos han sido enviados .
- La función de procesamiento de señales predefinida de la aplicación selecciona un subproceso de trabajo para realizar el procesamiento posterior, como decidir si se cierra el socket.
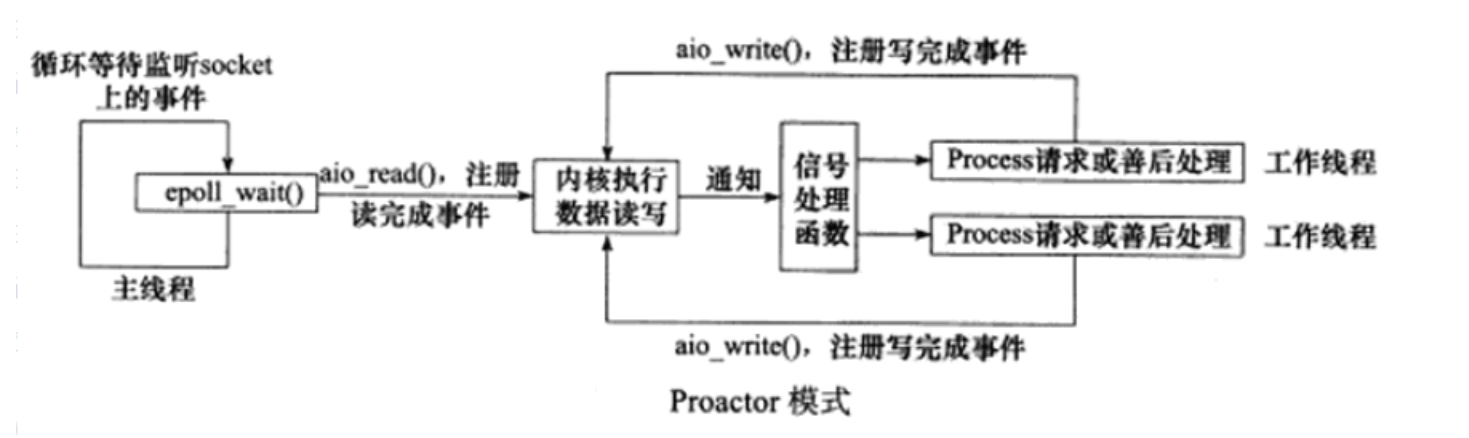
Los eventos de lectura y escritura en el socket de conexión se registran en el kernel a través de aio_read/aio_write, por lo que el kernel informará los eventos de lectura y escritura en el socket de conexión a la aplicación a través de señales. Por lo tanto, la llamada epoll_wait en el hilo principal solo se puede usar para detectar eventos de solicitud de conexión en el socket de escucha, pero no para detectar eventos de lectura y escritura en el socket.
Diferencias y ventajas y desventajas.
-
Reactor es un modo de red síncrono sin bloqueo que percibe eventos legibles y escribibles . Cada vez que se detecta un evento (como un evento legible), el proceso de la aplicación debe llamar activamente al método de lectura para completar la lectura de datos , es decir, el proceso de la aplicación debe leer activamente los datos en el búfer de recepción del socket al proceso de la aplicación. memoria En , este proceso es sincrónico y el proceso de aplicación solo puede procesar los datos después de leerlos.
-
Ventajas y desventajas:
Reactor es relativamente simple de implementar y eficiente para procesar escenarios que toman poco tiempo, la serialización de eventos es transparente para las aplicaciones y se puede ejecutar de forma secuencial y sincrónica sin bloqueo;
Las operaciones que consumen mucho tiempo en el procesamiento del reactor provocarán el bloqueo de la distribución de eventos y afectarán el procesamiento de eventos posteriores;
-
-
Proactor es un modo de red asíncrono que percibe eventos de lectura y escritura completados . Al iniciar una solicitud de lectura y escritura asincrónica, es necesario pasar información como la dirección del búfer de datos (utilizado para almacenar los datos del resultado), para que el núcleo del sistema pueda completar automáticamente el trabajo de lectura y escritura de datos por nosotros. Todo el trabajo de lectura y escritura aquí lo realiza el operador. El sistema no necesita que el proceso de la aplicación inicie activamente la lectura/escritura para leer y escribir datos como Reactor . Una vez que el sistema operativo complete el trabajo de lectura y escritura, notificará a la aplicación. proceso para procesar directamente los datos.
-
Ventajas y desventajas
Proactor tiene un mayor rendimiento. Este diseño permite ejecutar múltiples tareas simultáneamente, mejorando así el rendimiento y puede realizar tareas que requieren mucho tiempo (cada tarea no se afecta entre sí).
Proactor implementa una lógica compleja; depende del soporte de asincronía del sistema operativo.
-
Reactor puede entenderse como el sistema operativo de eventos notifica al proceso de la aplicación y deja que el proceso de la aplicación lo maneje , mientras que Proactor puede entenderse como el sistema operativo de eventos lo maneja y luego notifica al proceso de la aplicación después del procesamiento .
Escena aplicable
Reactor: reciba múltiples solicitudes de servicio al mismo tiempo y procese sus controladores de eventos de forma secuencial y sincrónica;
Proactor: un controlador de eventos que recibe y procesa múltiples solicitudes de servicio de forma asincrónica;
Grupo de subprocesos
1. Diseño del grupo de subprocesos
Utilice subprocesos múltiples para aprovechar al máximo las CPU de múltiples núcleos y utilice grupos de subprocesos para evitar la creación y destrucción frecuentes de subprocesos y aumentar la sobrecarga del sistema.
- Cree un grupo de subprocesos para administrar subprocesos múltiples. El grupo de subprocesos contiene principalmente colas de tareas y colecciones de subprocesos de trabajo . Agregue tareas a la cola y luego inicie automáticamente estas tareas después de crear subprocesos. Se utiliza un subproceso de trabajo con un número fijo de subprocesos para limitar el número máximo de subprocesos simultáneos.
- Varios subprocesos comparten la cola de tareas, por lo que se requiere la sincronización entre subprocesos y la competencia entre subprocesos de trabajo por la cola de tareas utiliza una combinación de variables de condición y bloqueos mutex .
- Un subproceso de trabajo primero agrega un mutex . Cuando el número de tareas en la cola de tareas es 0, se bloquea en la variable de condición. Cuando el número de tareas es mayor que 0, la condición notifica el subproceso bloqueado bajo la variable de condición. variable, y estos hilos continúan compitiendo para obtener tareas.
- La programación de tareas en la cola de tareas adopta un algoritmo por orden de llegada
2. Utilice el grupo de subprocesos de acuerdo con la cantidad de concurrencia y el tiempo de ejecución de la tarea.
1. ¿Cómo utilizar el grupo de subprocesos para empresas con alta concurrencia y corto tiempo de ejecución de tareas?
2. ¿Cómo utilizar el grupo de subprocesos para empresas con baja concurrencia y tiempo de ejecución de tareas prolongado?
3. ¿Cómo utilizar el grupo de subprocesos para empresas con alta concurrencia y tiempo de ejecución prolongado?
El grupo de subprocesos es esencialmente un modelo de productor y consumidor , que incluye tres elementos:
- Productores que entregan tareas a la cola del grupo de subprocesos ;
- cola de tareas ;
- El hilo de trabajo (consumidor) que recupera la ejecución de tareas de la cola de tareas .
Para configurar razonablemente el tamaño del grupo de subprocesos, se deben analizar las características de la tarea del grupo de subprocesos, que se pueden analizar desde los siguientes aspectos:
-
Dividido según la naturaleza de la tarea: tareas con uso intensivo de CPU; tareas con uso intensivo de IO; tareas mixtas.
-
Según la prioridad de la tarea: alta, media, baja
-
Según el tiempo de ejecución de la tarea: largo, medio, corto
Los grupos de subprocesos con diferentes configuraciones pueden ejecutar tareas de diferente naturaleza.
3. La cantidad de subprocesos en el grupo de subprocesos.
El factor limitante más directo es la cantidad de procesadores de CPU.
-
Si la CPU tiene 4 núcleos, entonces para tareas que requieren un uso intensivo de la CPU, la cantidad de subprocesos en el grupo de subprocesos debe ser preferiblemente 4 o +1 para evitar que otros factores causen bloqueo.
-
Si se trata de una tarea intensiva de IO, generalmente tiene más núcleos que la CPU, porque las operaciones de IO no ocupan la CPU y la competencia entre subprocesos no son recursos de CPU sino IO. El procesamiento de IO es generalmente más lento y los subprocesos tienen más núcleos. será CPU Esfuércese por realizar más tareas, para no causar inactividad de la CPU y desperdiciar recursos cuando los subprocesos procesan IO.
-
Para las tareas mixtas, si se pueden dividir, se pueden dividir en tareas intensivas de IO y de CPU, siempre que el tiempo de ejecución de las dos sea similar. Si el tiempo de procesamiento es muy diferente, no es necesario dividirlas.
Si el tiempo de ejecución de la tarea es largo y el número de subprocesos de trabajo es limitado, los subprocesos de trabajo pronto serán ocupados por la tarea, lo que provocará que las tareas posteriores no se procesen a tiempo. En este momento, el número de subprocesos de trabajo debe ser adecuado aumenta ; por el contrario, si el tiempo de ejecución de la tarea es corto , entonces el número de subprocesos de trabajo no necesita ser demasiado , demasiados subprocesos de trabajo provocarán una pérdida excesiva de tiempo en el cambio de contexto de subprocesos.
Volviendo a la pregunta en sí, la "alta concurrencia" aquí debería significar que el productor produce tareas a una velocidad relativamente rápida. En este momento, el límite superior de la cola de tareas debe aumentarse adecuadamente .
Sin embargo, para el tercer problema de alta concurrencia y largo tiempo de ejecución empresarial, no es apropiado confiar simplemente en la solución del grupo de subprocesos. Incluso si el servidor tiene una configuración de recursos alta, cada tarea ocupa recursos durante un largo período de tiempo y Al final, los recursos del servidor se agotarán, y se agotará rápidamente, por lo que en este caso, debe cooperar con el desacoplamiento empresarial y dividir algunos módulos para optimizar toda la estructura del sistema.
3. Problema de extensión
1. ¿Es este servidor web el nombre de dominio que solicitó? ¿Cuál es el nombre de dominio?
No hay ninguna aplicación, porque el servidor se coloca en una máquina virtual en el mismo segmento de red y luego se accede a él en un navegador local.
O puede experimentar en diferentes hosts en la misma LAN y puede acceder a él a través del número de puerto IP+privado en la misma LAN.
O puede colocar directamente el programa del servidor localmente y luego usar la dirección de loopback local 127.0.0.1.
La dirección de loopback local tiene dos funciones principales: una es probar la configuración de red de la máquina, y si el PING de 127.0.0.1 tiene éxito, significa que no hay problema con la instalación de la tarjeta de red y el protocolo IP de la máquina; la otra es que algunas aplicaciones de SERVIDOR/CLIENTE se están ejecutando. Los recursos en el servidor deben llamarse durante la operación y la dirección IP del servidor debe especificarse en general. También funciona para 127.0.0.1.
3. ¿Los subprocesos de trabajo en el grupo de subprocesos están esperando todo el tiempo?
Los subprocesos de trabajo en el grupo de subprocesos están siempre bloqueados y en espera. Porque cuando creamos el grupo de subprocesos al principio, creamos 5 subprocesos de trabajo en el grupo de subprocesos llamando a pthread_create circularmente, y la interfaz de la función de procesamiento del subproceso de trabajo es la función de trabajo apuntada por el puntero de función del tercer parámetro en el prototipo de función pthread_create ( función personalizada), y luego llame a la función miembro de la clase del grupo de subprocesos para ejecutar (personalizada).
¿Por qué no simplemente apuntar el tercer parámetro directamente a la función de ejecución, sino llamar a ejecutar pasando el objeto al trabajador? La razón es que hemos configurado al trabajador como una función miembro estática y todos sabemos que las funciones miembro estáticas solo pueden acceder a variables miembro estáticas, por lo que para poder acceder a variables miembro no estáticas en la clase, podemos llamar ejecutar en el trabajador.Variables miembro para lograr este requisito.
En la función de ejecución, para poder manejar problemas de alta concurrencia, configuramos los subprocesos de trabajo en el grupo de subprocesos para que se bloqueen y esperen con la condición de que la cola de solicitudes no esté vacía, por lo que los subprocesos de trabajo en el grupo de subprocesos en el El proyecto siempre está bloqueado en modo de espera.
4. ¿Cuál es el estado del subproceso de trabajo de su grupo de subprocesos después de procesar una tarea?
Hay dos casos a considerar aquí.
(1) Si la cola de solicitudes está vacía después de procesar la tarea, el hilo vuelve al estado de espera bloqueado
(2) Si la cola de solicitudes no está vacía después de procesar la tarea, entonces este subproceso estará en un estado de competencia por recursos con otros subprocesos, y quien obtenga el bloqueo estará calificado para procesar el evento.
5. Si 1000 clientes realizan solicitudes de acceso al mismo tiempo y la cantidad de subprocesos no es mucha, ¿cómo pueden responder a cada uno de manera oportuna?
Este proyecto es un modo concurrente basado en multiplexación IO. ¡Cabe señalar que ninguna conexión de cliente corresponde a un hilo ! Cuando la conexión del cliente tiene un evento que debe procesarse, epoll recordará el evento y luego agregará la tarea correspondiente a la cola de solicitudes, esperando que el hilo de trabajo compita por la ejecución. Si la velocidad aún es lenta, solo puede aumentar la capacidad del grupo de subprocesos o considerar el método distribuido en clúster.
6. Si la solicitud de un cliente necesita ocupar un hilo durante mucho tiempo, ¿afectará la siguiente solicitud del cliente? ¿Cuál es una buena estrategia?
Afectará la siguiente solicitud del cliente, porque el número de subprocesos en el grupo de subprocesos es limitado. Si la solicitud del cliente ocupa un subproceso durante demasiado tiempo, afectará la eficiencia del procesamiento de la solicitud. La cola de solicitudes está esperando ser procesada. , afectando así la siguiente solicitud del cliente.
solución preventiva:
- Podemos establecer el tiempo de espera de procesamiento del objeto de solicitud de procesamiento de subprocesos, enviar una señal para informar el tiempo de espera de procesamiento del subproceso antes de que se exceda el tiempo y luego establecer un intervalo de tiempo para verificar nuevamente. Si la solicitud aún ocupa el subproceso en este momento, se desconectará directamente.
- Establezca un umbral de tiempo para cada tarea de procesamiento de subprocesos. Cuando una determinada solicitud de cliente tarda demasiado, se colocará al final de la solicitud de tarea o se desconectará.
7. ¿Qué es Webbench e introduce el principio?
El proceso principal bifurca varios procesos secundarios y cada proceso secundario envía una solicitud de acceso real al bucle web de destino dentro del tiempo requerido por el usuario o dentro del tiempo predeterminado. Los procesos principal e secundario se comunican a través de la canalización y el proceso secundario pasa la solicitud de acceso al proceso principal a través del puerto de escritura de la canalización. La información total registrada después de la finalización, el proceso principal lee la información relevante enviada por el proceso secundario a través del lector de canalización, el proceso secundario finaliza cuando se acaba el tiempo, el proceso principal cuenta y muestra los resultados finales de la prueba al usuario después de que todos los procesos secundarios salen, luego sale.
9. Presentar a productores y consumidores
Los productores y consumidores se utilizan principalmente para el uso sincrónico de datos. Los productores producen datos y luego los colocan en el búfer compartido. Los consumidores bloquearán y esperarán hasta que no haya datos en el búfer. Cuando el productor produzca datos, utilizará la función de señal. Despierte el bloqueo, comience a consumir datos y, cuando la producción de datos llene el búfer, el productor bloqueará y esperará. Todo el bloqueo utiliza variables de condición.
Referencias
"Notas de la conferencia sobre el proyecto del servidor Niuke"
https://blog.csdn.net/a15929748502/article/details/90269859
https://github.com/KyleAndKelly/MyWebServer
https://zhuanlan.zhihu.com/p/364044293
https://zhuanlan.zhihu.com/p/269247362
Declaración de derechos de autor: el contenido proviene de Internet y los derechos de autor pertenecen al creador original. A menos que sea imposible confirmar, indicaré el autor y la fuente. Si hay alguna infracción, hágamelo saber, lo eliminaré de inmediato y me disculpo, ¡gracias!
No es fácil de organizar, ¡tus me gusta, mirar, volver a publicar y marcar estrellas son mi mayor estímulo! ¡Deseo que todos puedan obtener una oferta satisfactoria!
