A menudo veo algunas sugerencias de optimización de SQL en Internet para no usar Count (*) sino Count (1), lo que puede mejorar el rendimiento. La razón dada es que Count () traerá un escaneo completo de la tabla . Sin embargo, un experimento comparativo encontró que la eficiencia es básicamente la misma .
En primer lugar, comprendamos: count() es una función de agregación. Los parámetros de la función pueden ser no solo nombres de campos, sino también cualquier otra expresión. La función de esta función es contar los registros que cumplen con las condiciones de la consulta, y los parámetros especificados por la función no son NULL.cuantos. Supongamos que el parámetro de la función count() es el nombre del campo, de la siguiente manera:
seleccione count(1) de icaAccountingBill
seleccione COUNT( ) de icaAccountingBill
seleccione count(BillNo) de icaAccountingBill ---- la eficiencia más lenta
Primero lea la diferencia:
count(name)
es contar el número de registros cuyo campo de nombre no es NULL en la tabla icaAccountingBill. Por lo tanto, SQL Server debe leer el valor de cada fila de la columna, luego confirmar si es NULL y luego contar.
count(1)
cuenta cuántos registros hay en la tabla icaAccountingBill, la expresión 1 no es NULL. 1 Esta expresión es un número simple, nunca será NULL, por lo que la declaración anterior en realidad cuenta cuántos registros hay en la tabla icaAccountingBill.
count (*)
en realidad puede entender que count( ) solo devuelve el número de filas en la tabla, por lo que SQL Server solo necesita encontrar el encabezado del bloque de datos que pertenece a la tabla cuando procesa count() y luego calcular el número de filas en lugar de leer los datos en la columna de datos del interior.
COUNT () en SQL Server solo necesita encontrar el número de filas que no son NULL en la tabla específica, es decir, todas las filas (si una fila es completamente NULL, la fila no existe). Entonces, la forma más fácil de implementarlo es encontrar una columna NO NULA. Si la columna tiene un índice, use el índice. Por supuesto, para el rendimiento, SQL Server elegirá el índice más estrecho para reducir IO.
Sin clave primaria e índice:
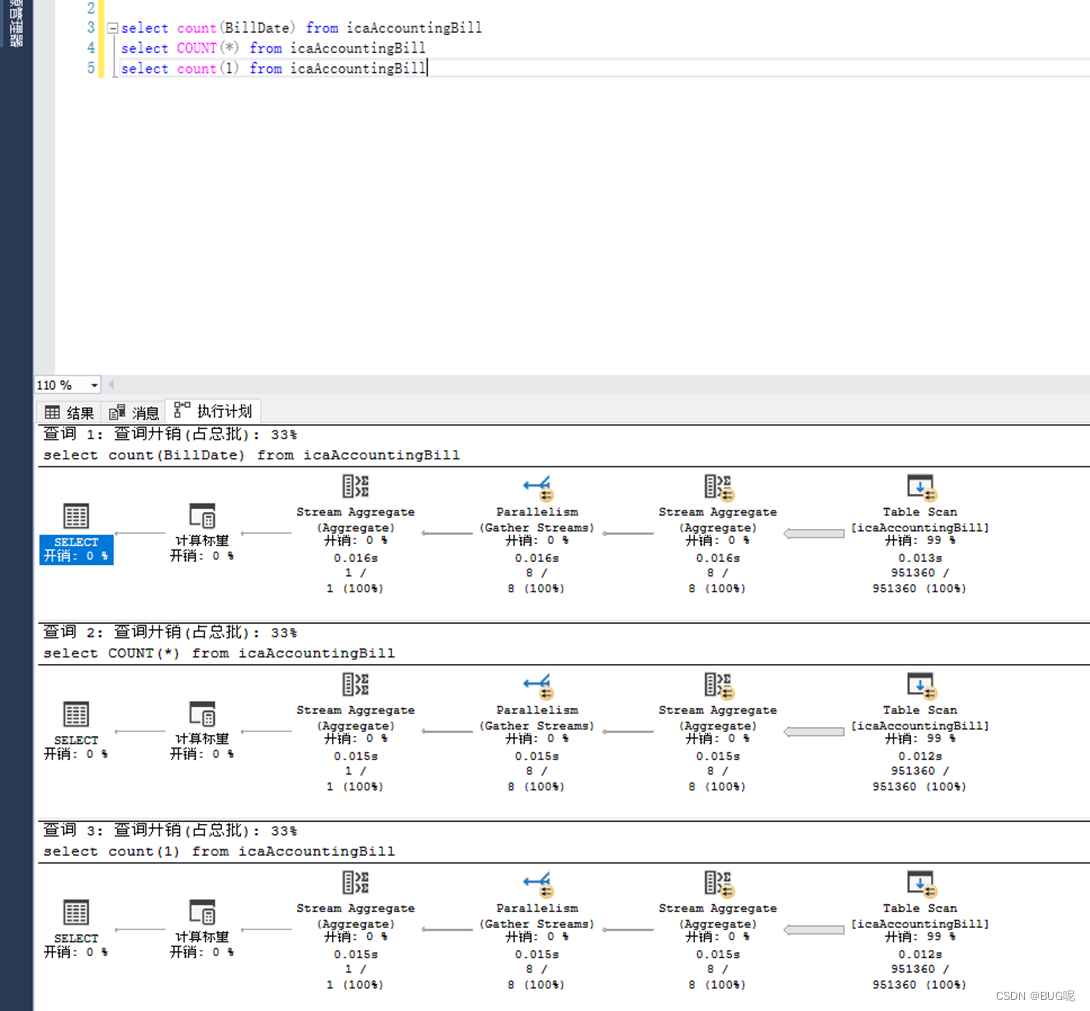
En caso de que no haya índice: busque automáticamente el índice de clave principal
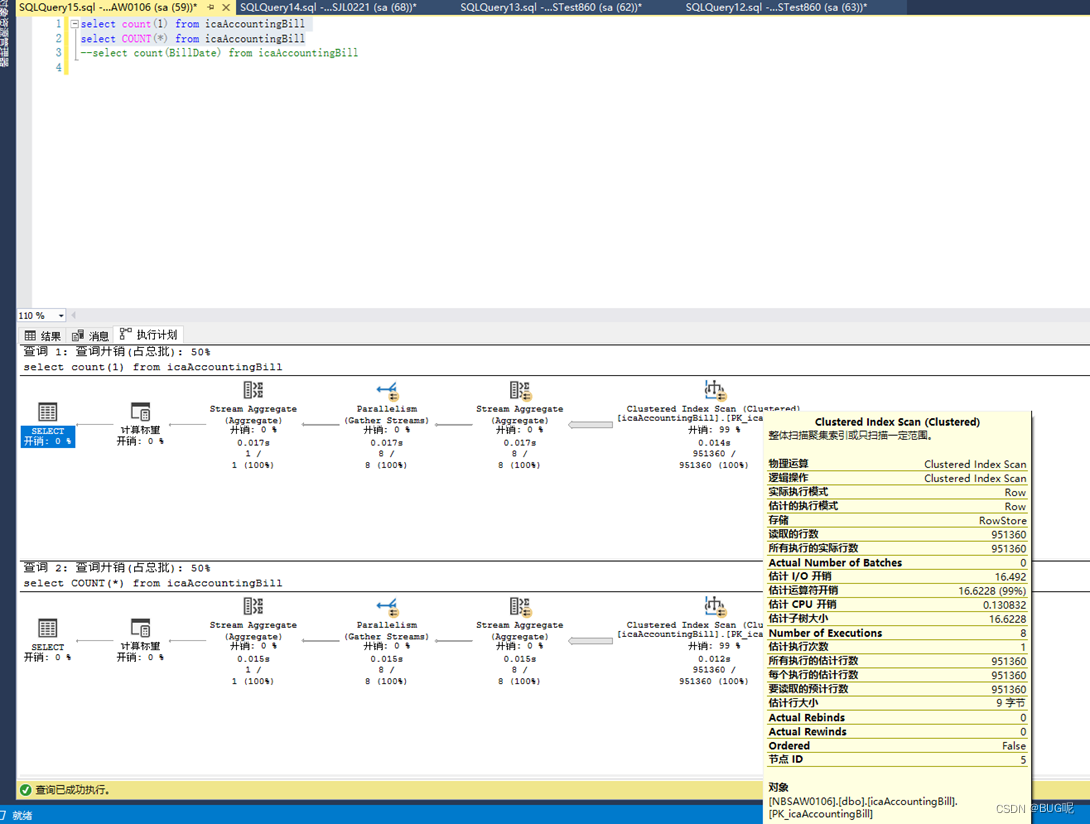
Con índices:
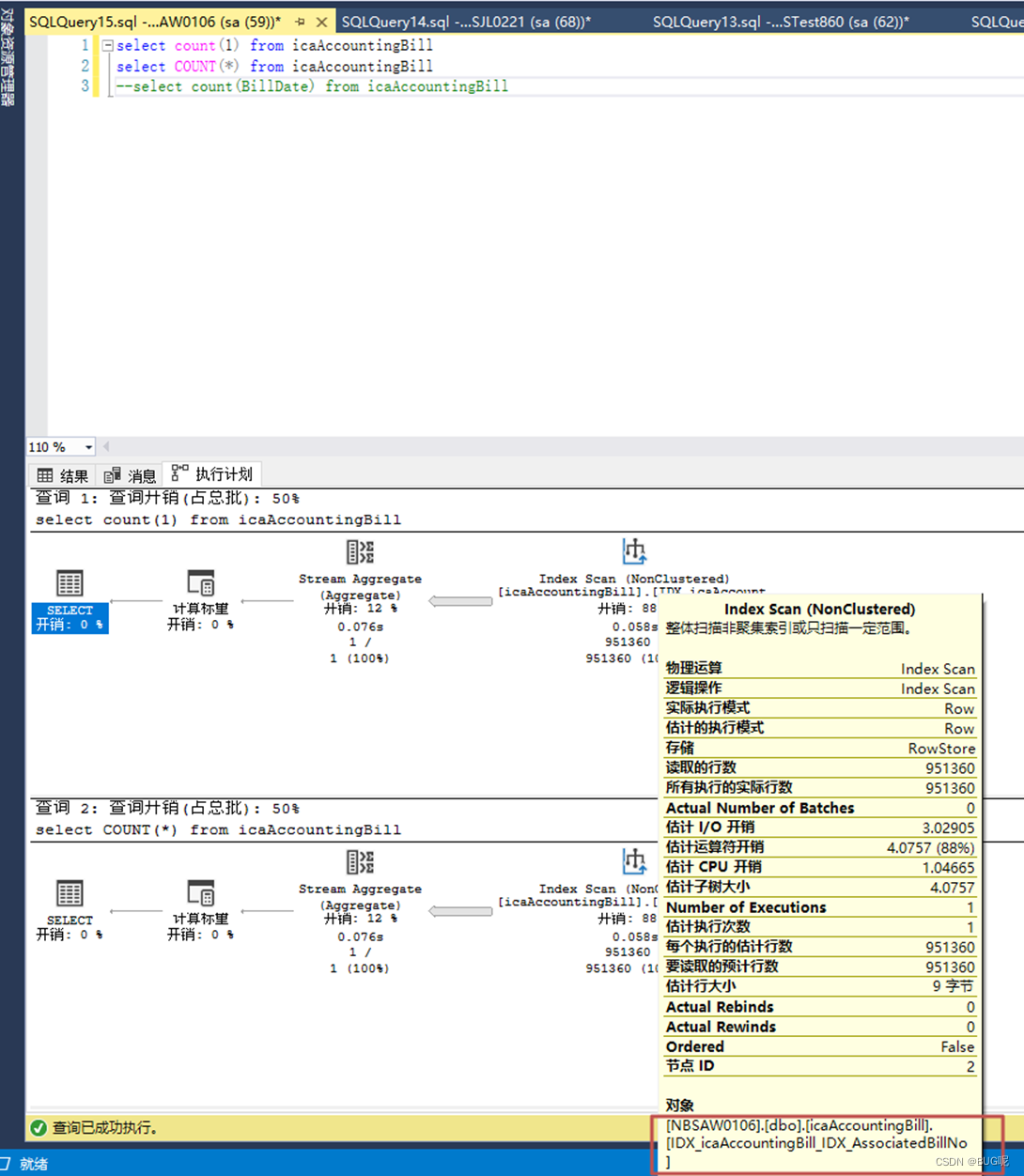

#dbcc show_statistics('NBSAW0106.dbo.icaAccountingBill',IDX_icaAccountingBill_IDX_FOrgId)----显示索引的语法
La conclusión es : si la tabla tiene solo un índice de clave principal sin ningún índice secundario, entonces tanto COUNT( ) como COUNT(1) cuentan el número de filas hasta el índice de clave principal. Si la tabla tiene un índice secundario, tanto COUNT (1) como COUNT ( ) contarán a través del índice secundario del campo que ocupa el espacio más pequeño. Aquí, la operación de contar el número de filas, la dirección de optimización del optimizador de consultas. es seleccionar el IO veces El índice mínimo, es decir, el índice construido en función del campo con el espacio más pequeño (la cantidad de datos leídos por cada IO es fija, y cuanto menor es el espacio ocupado por el índice, menor es el número de IO requeridas). El índice de clave principal es un índice agrupado (que incluye CLAVE, otros valores de campo excepto CLAVE, ID de transacción y puntero de reversión), por lo que el índice de clave principal debe ser mayor que el índice secundario (incluida CLAVE y el ID de clave principal correspondiente), es decir es decir, en el caso de índices secundarios, generalmente COUNT () no contará el número de filas a través del índice de clave principal y seleccionará la que ocupe el espacio más pequeño cuando haya varios índices secundarios.
Por lo tanto, si Count (*) se usa mucho en una tabla, considere crear un índice de una sola columna en la columna más corta, lo que mejorará enormemente el rendimiento.