Todo es un proceso desde el cambio cuantitativo hasta el cambio cualitativo, y aprender Python no es una excepción. Sólo conociendo bien las funciones comunes de un lenguaje podremos ser útiles en el proceso de resolución de problemas y encontrar rápidamente la solución óptima. Este artículo explorará con usted la función toad.quality en Python, para que pueda comprender el principio de esta función en el menor tiempo posible. También puede utilizar el tiempo fragmentado para consolidar esta función y hacerlo más eficiente en el proceso de procesamiento.
Directorio de artículos
1. Instale el paquete sapo
La calidad es una función de la biblioteca toad y primero es necesario instalar el paquete toad para llamarla. Abra cmd, la declaración de instalación es la siguiente:
pip install toad
Si la instalación es exitosa, los resultados se mostrarán de la siguiente manera:
Dos, definición de función de calidad
La función de la función de calidad es calcular los cuatro indicadores de iv, gini, entropía y único de las variables en el marco de datos. Entre ellos, la definición de iv puede referirse al artículo IV y WOE en el modelado de control de riesgos, y la definición de gini y entropía se puede encontrar en Baidu. La función de estos tres indicadores es medir la capacidad de las variables para distinguir la ocurrencia de un evento. Unique calcula el número de valores de una variable.
Su sintaxis básica de llamada es la siguiente:
import toad
toad.quality(dataframe, target='target', cpu_cores=0, iv_only=False)
marco de datos: conjunto de datos.
objetivo: columna de destino o columna de variable dependiente.
cpu_cores: el número máximo de núcleos de CPU que se utilizarán, "0" significa que se utilizarán todas las CPU, "-1" significa que se utilizarán todas las CPU excepto una.
iv_only: valor booleano, si se muestra solo la columna iv, el valor predeterminado es falso.
3. Ejemplo de función de calidad
1 Importar biblioteca y cargar datos
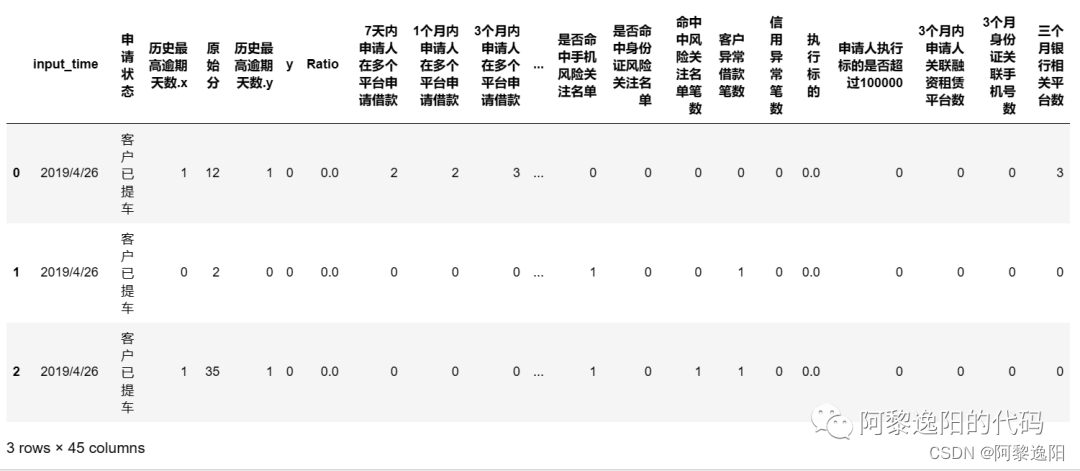
Antecedentes: es necesario analizar las posiciones largas, los riesgos relacionados, la ejecución judicial, la lista de riesgos y la información vencida de 7252 clientes para construir la tarjeta de puntuación previa al préstamo del cliente. Antes de construir el cuadro de mando, es necesario examinar la información del cliente y seleccionar las variables con alta correlación con la información vencida del cliente.
Primero lea los datos, el código específico es el siguiente:
#[1]读取数据
import os
import toad
import numpy as np
import pandas as pd
os.chdir(r'F:\公众号\70.数据分析报告')
date = pd.read_csv('testtdmodel1.csv', encoding='gbk')
date.head(3)
os.chdir: establece la ruta del archivo para el almacenamiento de datos.
pd.read_csv: leer datos.
obtuve la respuesta:
2 instancias
Ejemplo 1: llamar a la función de calidad con parámetros predeterminados
Primero veamos el efecto de ingresar solo el marco de datos y la variable dependiente, y usar los valores predeterminados para el resto de los parámetros. El código es el siguiente:
to_drop = ['input_time', '申请状态', '历史最高逾期天数.x'] # 去掉ID列和month列
quality_result = toad.quality(date.drop(to_drop,axis=1),'y')
quality_result
obtuve la respuesta:
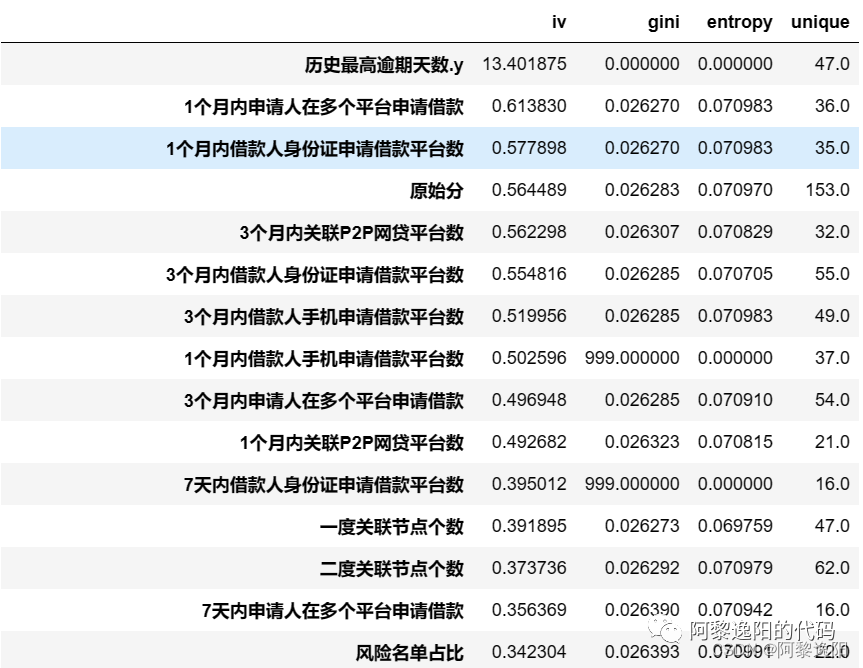
A partir de los resultados se calculan los valores de los cuatro indicadores iv, gini, entropía y único de las variables correspondientes, y se ordenan en orden descendente por iv. Los estudiantes que estén familiarizados con el modelado deben saber que esta función se puede utilizar para la selección de variables.
Ejemplo 2: el parámetro iv_only está establecido en True
A continuación, observe el resultado de configurar iv_only en True, el código es el siguiente:
to_drop = ['input_time', '申请状态', '历史最高逾期天数.x'] # 去掉ID列和month列
toad.quality(date.drop(to_drop,axis=1),'y',iv_only=True)
obtuve la respuesta:
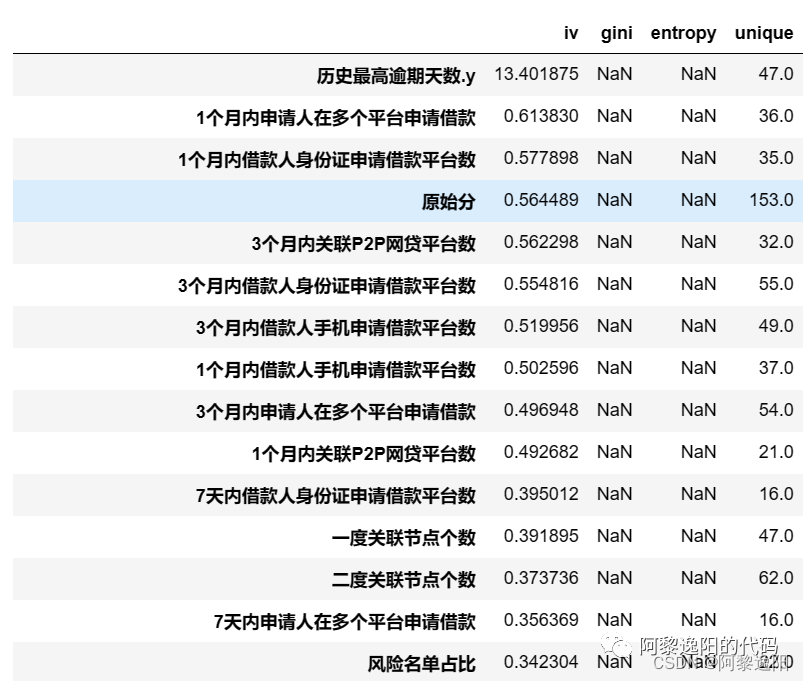
En el ejemplo comparativo 1, se puede encontrar que cuando iv_only se establece en Verdadero, los tres indicadores iv, gini y entropía solo calculan el valor de iv. Si la cantidad de datos es grande y hay muchas funciones, pero desea ahorrar tiempo de cálculo, esta configuración es más adecuada.
4. Comparación del decil para calcular el valor iv
Para comparar la diferencia entre calcular iv con la función toad.quality y calcular iv con diez divisiones iguales. Primero defina la función de calcular iv por 10 divisiones iguales, el código específico es el siguiente:
#等频切割变量函数
def bin_frequency(x,y,n=10): # x为待分箱的变量,y为target变量.n为分箱数量
total = y.count() #1 计算总样本数
bad = y.sum() #2 计算坏样本数
good = total-bad #3 计算好样本数
if x.value_counts().shape[0]==2: #4 如果该变量值是0和1则只分两组
d1 = pd.DataFrame({
'x':x,'y':y,'bucket':pd.cut(x,2)})
else:
d1 = pd.DataFrame({
'x':x,'y':y,'bucket':pd.qcut(x,n,duplicates='drop')}) #5 用pd.cut实现等频分箱
d2 = d1.groupby('bucket',as_index=True) #6 按照分箱结果进行分组聚合
d3 = pd.DataFrame(d2.x.min(),columns=['min_bin'])
d3['min_bin'] = d2.x.min() #7 箱体的左边界
d3['max_bin'] = d2.x.max() #8 箱体的右边界
d3['bad'] = d2.y.sum() #9 每个箱体中坏样本的数量
d3['total'] = d2.y.count() #10 每个箱体的总样本数
d3['bad_rate'] = d3['bad']/d3['total'] #11 每个箱体中坏样本所占总样本数的比例
d3['badattr'] = d3['bad']/bad #12 每个箱体中坏样本所占坏样本总数的比例
d3['goodattr'] = (d3['total'] - d3['bad'])/good #13 每个箱体中好样本所占好样本总数的比例
d3['WOEi'] = np.log(d3['badattr']/d3['goodattr']) #14 计算每个箱体的woe值
IV = ((d3['badattr']-d3['goodattr'])*d3['WOEi']).sum() #15 计算变量的iv值
d3['IVi'] = (d3['badattr']-d3['goodattr'])*d3['WOEi'] #16 计算IV
d4 = (d3.sort_values(by='min_bin')).reset_index(drop=True) #17 对箱体从大到小进行排序
cut = []
cut.append(float('-inf'))
for i in d4.min_bin:
cut.append(i)
cut.append(float('inf'))
WOEi = list(d4['WOEi'].round(3))
return IV,cut,WOEi,d4
Llame a la función para calcular el valor iv de una sola variable, el código específico es el siguiente:
IV,cut,WOEi,d4 = bin_frequency(date['1个月内申请人在多个平台申请借款'], date['y'], 10)
print(IV)
d4
obtuve la respuesta:
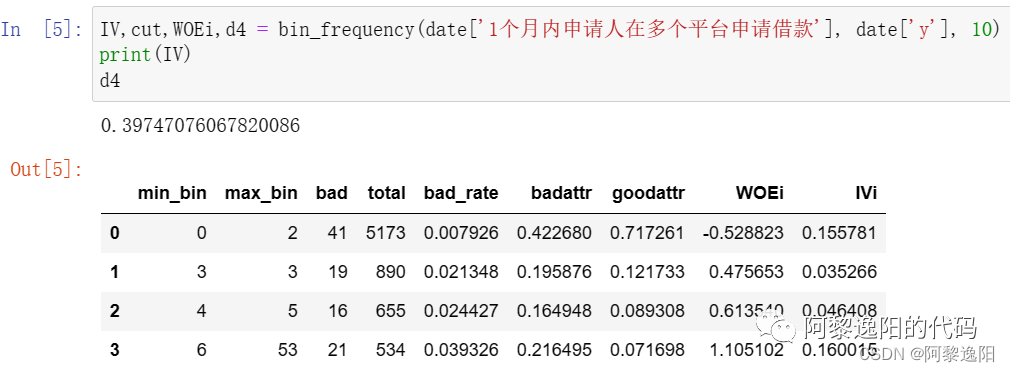
Se puede encontrar que el valor temporal iv de la variable de cálculo equivalente a 10 [el solicitante solicita préstamos en múltiples plataformas dentro de un mes] es 0,397. Sin embargo, en el ejemplo 1, el resultado calculado usando la función toad.quality es 0.613, obviamente el valor calculado por toad.quality es mayor que el valor calculado por 10 divisiones iguales. Explique que los diferentes métodos de corte tienen un mayor impacto en el valor iv de la variable.
¿Es eso cierto para todas las variables?
Usamos el método por lotes para calcular el valor iv de las variables en el marco de datos en 10 partes iguales y luego lo comparamos con el iv calculado por el método toad.quality. Primer ciclo para calcular el valor iv de 10 partes iguales, el código específico es el siguiente:
columns = list(quality_result.index)
dt = date
dt = dt.fillna(-999999)
dt = dt.replace('NaN', -999999)
pd.set_option("display.max_rows", 1000)
pd.set_option("display.max_columns", 1000)
pd.set_option('display.max_columns',None)
IV_table = [0]
IV_name = ['xx']
for i in columns:
try:
IV,cut,WOEi,d4 = bin_frequency(dt[i], dt['y'], 10)
IV_table.append(IV)
IV_name.append(i)
print('变量【', i, '】的', 'IV=', IV, end='\n')
display(d4)
except:
print(i)
pass
#print('=======================================' ,end='\n')
IV_name_table = pd.DataFrame({
'IV_name':IV_name, 'iv_value':IV_table})
IV_name_table
obtuve la respuesta:

Junte los dos resultados para comparar, el código es el siguiente:
IV_name_table = IV_name_table.loc[1:, :] #去除第一行无用值
quality_result['IV_name'] = quality_result.index #加变量名列
pd.merge(IV_name_table, quality_result, on=['IV_name'], how='left') #合并数据
Obtenga el resultado:
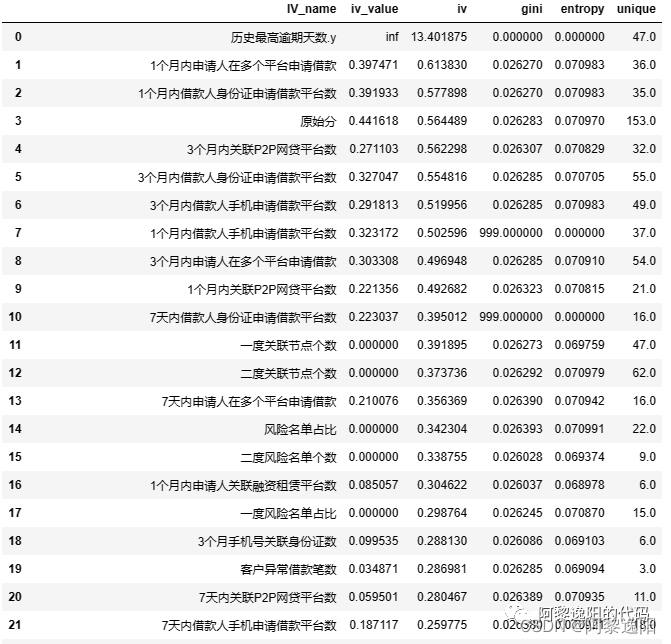
entre ellos, la columna iv_value es el valor iv calculado por el decil y la columna iv es el valor iv calculado por la función toad.quality. Se puede encontrar que la brecha entre algunas variables calculadas por los dos sigue siendo bastante grande, pero la tendencia general es la misma. Al usarlo, puede elegir uno de los dos métodos de cálculo de acuerdo con la escena específica, o puede calcular ambos y encontrar la unión para seleccionar variables.
Hasta ahora se ha explicado la función de calidad en Python, si quieres saber más sobre las funciones en Python, puedes leer los artículos relevantes del módulo "Aprender Python" en la cuenta oficial.
[ Acceso gratuito al grupo por tiempo limitado ] El grupo proporciona información de reclutamiento relacionada con el aprendizaje de Python, el juego con Python, el modelado de control de riesgos, la inteligencia artificial y el análisis de datos, excelentes artículos, videos de aprendizaje y también puede intercambiar problemas relacionados encontrados en el aprendizaje y trabajar. Los amigos que lo necesiten pueden agregar el ID de WeChat 19967879837 y agregar tiempo para anotar los grupos a los que desean unirse, como el modelado de control de riesgos.
Quizás te interese:
Dibujar a Pikachu en PythonUsar
Python para dibujar nubes de palabrasReconocimiento
facial de Python: eres el único en mis ojosPython
dibuja un hermoso mapa de cielo estrellado (hermoso fondo)
Usa la biblioteca py2neo en Python para operar neo4j y crear un mapa de asociaciónPython
Colección de código fuente de confesión romántica (amor, rosa, muro de fotos, confesión bajo las estrellas)