Autores: Wu Han, Nie Jiahao, Zhang Zhaowei, He Zhiwei, Gao Mingyu
Fuente: Ciencias de la Computación
Editar: East Bank gracias a @一点Inteligencia Artificial
Invitación a unirse al grupo: 7 grupos de intercambio de direcciones profesionales + 1 grupo de demanda de datos
Dirección original: Una revisión de la investigación sobre el seguimiento visual de múltiples objetivos basado en el aprendizaje profundo
El seguimiento de objetos múltiples (MOT) tiene como objetivo generar las trayectorias de movimiento de todos los objetos de una secuencia de video determinada y mantener la identidad de cada objeto. En los últimos años, debido a su gran potencial en la investigación académica y las aplicaciones prácticas, ha recibido cada vez más atención y se ha convertido en una dirección de investigación candente en visión por computadora. El método de seguimiento convencional actual divide la tarea MOT en tres subtareas: detección de objetivos, extracción de características y asociación de datos. Esta idea ha sido bien desarrollada. Sin embargo, debido a desafíos como la oclusión y la interferencia de objetos similares en el proceso de seguimiento real, mantener un seguimiento sólido sigue siendo una dificultad de investigación actual. Para cumplir con los requisitos de un seguimiento preciso, sólido y en tiempo real de múltiples objetivos en escenas complejas, es necesario seguir investigando y mejorando el algoritmo MOT.
En la actualidad, se ha realizado una revisión del algoritmo MOT, pero todavía existen problemas como un resumen insuficiente y la falta de los resultados de las investigaciones más recientes. Por lo tanto, en primer lugar, se introducen los principios y los desafíos de MOT; en segundo lugar, al resumir los últimos resultados de la investigación, se resume y analiza el algoritmo MOT, y varios algoritmos se dividen en tres categorías de acuerdo con el paradigma de seguimiento utilizado para completar los tres sub- Es decir, detección separada y extracción de características, detección conjunta y extracción de características, y detección y seguimiento conjuntos, y describir en detalle las características principales de varios algoritmos de seguimiento; luego, comparar y analizar el algoritmo propuesto y el algoritmo principal actual en comúnmente conjuntos de datos utilizados. Se discuten las ventajas, desventajas y tendencias de desarrollo de los algoritmos actuales y se prospecta la dirección futura de la investigación.
01 Introducción
La tarea principal del seguimiento de múltiples objetos (MOT) es generar las trayectorias de todos los objetos de un video determinado y mantener la información de identidad (Identidad, ID) de cada objeto. En donde, el objetivo de seguimiento puede ser un peatón, un vehículo u otros objetos. Con el desarrollo de la tecnología de visión por computadora, MOT se ha utilizado ampliamente en muchos campos, como el monitoreo inteligente por video, la interacción persona-computadora, la navegación inteligente, etc. Además, MOT es la base para tareas avanzadas de visión por computadora, como estimación de pose, reconocimiento de acciones, análisis de acciones y análisis de video [3-4]. Sin embargo, el seguimiento robusto en escenas complejas sigue siendo una dificultad de investigación actual, que se refleja principalmente en los siguientes tres aspectos:
1) La oclusión frecuente durante el proceso de seguimiento dificulta la localización precisa del objetivo;
2) Puede haber una gran similitud de apariencia entre diferentes objetivos, lo que aumenta la dificultad de mantener la identificación del objetivo;
3) La interacción entre objetivos puede hacer que el marco de seguimiento se desvíe.
Los algoritmos MOT tradicionales incluyen la toma de decisiones de Markov, la asociación de datos de probabilidad conjunta, el filtro de partículas, etc., pero el método tradicional tiene un gran error en la posición predicha y poca robustez ante la oclusión y la interferencia de objetos similares. Con la amplia aplicación del aprendizaje profundo en el campo de la visión por computadora, los métodos de seguimiento basados en el aprendizaje profundo han recibido amplia atención y se han convertido en la corriente principal de la investigación en los últimos años. Beneficiándose del rápido desarrollo de la tecnología de detección de objetivos, los métodos actuales basados en el aprendizaje profundo dividen principalmente el MOT en tres subtareas: detección de objetivos, extracción de características y asociación de datos [5]. Específicamente, asocia objetos detectados en diferentes cuadros de video como trayectorias basadas en la similitud de la apariencia, el movimiento y las características espacio-temporales de los objetos. El algoritmo de seguimiento basado en el aprendizaje profundo no necesita seleccionar funciones manualmente y puede permitir que el entrenamiento del modelo obtenga buenas capacidades de extracción de funciones a través de una gran cantidad de datos.
Para promover el desarrollo de MOT, la literatura relevante ha revisado los resultados de la investigación de MOT en los últimos años. La literatura [6] resume de manera integral los principales desafíos en MOT y resume las principales tecnologías en MOT; la literatura [7] resume la aplicación del aprendizaje profundo en cada paso de MOT; la literatura [8] resume en detalle la aplicación del aprendizaje profundo en MOT. La aplicación en la asociación de datos; la literatura [9] revisó el método MOT basado en información visual tridimensional RGB-D; la literatura [10] dividió el modelo MOT en métodos tradicionales y métodos basados en el aprendizaje profundo para su revisión. Sin embargo, la mayoría de los métodos de clasificación de las literaturas mencionadas carecen de novedad y no cubren los resultados de las investigaciones más recientes.
Para compensar las deficiencias de las revisiones existentes y, al mismo tiempo, permitir que la mayoría de los investigadores científicos comprendan y comprendan las últimas tendencias de desarrollo en el campo de MOT, este documento utiliza un paradigma de seguimiento para completar los tres sub- tareas de detección de objetivos, extracción de características y asociación de datos desde una perspectiva novedosa. En este artículo, los algoritmos MOT de los últimos años se dividen en tres categorías para su revisión. Al revisar los últimos resultados de las investigaciones, los algoritmos MOT y sus ventajas y desventajas en los últimos años Se resumen los años y se prospectan las futuras direcciones de investigación.
02 Introducción a los algoritmos MOT existentes
En los últimos años, el algoritmo MOT adopta principalmente la estrategia de seguimiento de asociar los objetos detectados en la secuencia de vídeo en una trayectoria completa de acuerdo con la similitud de características de los objetos. De acuerdo con el paradigma de seguimiento adoptado por el modelo para completar las tres subtareas de detección de objetivos, extracción de características y asociación de datos, los algoritmos MOT de los últimos años se pueden dividir en detección y extracción de características separadas (Detección e incrustación separadas, SDE), método de detección conjunta y extracción de características (Joint Detección e Incrustación, JDE) y el método de detección y seguimiento conjunto (Joint Detección y Seguimiento, JDT).
Como se muestra en la Figura 1, el método basado en SDE completa tres subtareas sucesivamente, es decir, primero localiza el objetivo a través de una red de detección, luego extrae las características del objetivo y finalmente calcula la afinidad entre los objetivos y asocia los objetivos a través de los datos. algoritmo de asociación . El método JDE genera las características de ubicación y apariencia del objetivo en una red al mismo tiempo y luego calcula la afinidad entre los objetivos a través del algoritmo de asociación de datos y asocia los objetivos. Mientras que el enfoque de JDT es completar 3 subtareas en una sola red para completar el proceso de seguimiento. A continuación se presentarán en detalle los modelos clásicos de estos tres métodos, así como los efectos de seguimiento y las ventajas y desventajas de los diferentes métodos.

Gracias a los incansables esfuerzos de académicos nacionales y extranjeros, muchos algoritmos MOT han logrado resultados notables en la precisión y la velocidad de seguimiento. La Figura 2 muestra varios algoritmos representativos de los últimos años según la clasificación de algoritmos, y cada algoritmo se presentará en detalle más adelante. No es difícil ver que coexisten una variedad de métodos de seguimiento, y estructuras de red y estrategias de seguimiento más diversificadas han promovido el rápido desarrollo de la tecnología MOT.

03 Algoritmo basado en el paradigma SDE
De acuerdo con los requisitos del algoritmo para el cuadro de video de entrada, el algoritmo basado en SDE se puede dividir en método fuera de línea y método en línea. El método fuera de línea considera la información de todos los cuadros de video de toda la secuencia de video en el proceso de asociación de datos, mientras que el método en línea solo se basa en la información visual y espaciotemporal de los momentos actuales y pasados en el proceso de seguimiento. La Tabla 1 detalla las características y diferencias de varios aspectos de los métodos en línea y fuera de línea.

3.1 Método de seguimiento sin conexión
El seguimiento sin conexión puede considerarse como un problema de optimización global. Dados los resultados de la detección de todos los fotogramas de vídeo, los resultados de la detección que pertenecen al mismo objeto se asocian globalmente en una trayectoria.
La clave para el seguimiento fuera de línea es encontrar la solución óptima global. La minimización continua de energía [47] es un método de optimización global comúnmente utilizado que tiene como objetivo integrar la asociación de datos y la estimación de trayectoria en la función de energía y restringir la trayectoria mediante la construcción de un modelo de movimiento. Otra estrategia de optimización global comúnmente utilizada es modelar la tarea MOT como un modelo gráfico, donde cada vértice representa un objetivo de detección y los bordes entre los vértices representan la similitud entre objetivos, y luego a través del algoritmo húngaro [48-49] o algoritmo codicioso. [50] determina la relación de coincidencia de cada vértice. Los métodos basados en modelos de gráficos incluyen flujo de red (flujo de red, NF) [11], campo aleatorio condicional (CRF) [12], subgrafo de costo mínimo multicorte (MC SM) [13] y conjunto independiente ponderado máximo (conjunto independiente de peso máximo). , MWIS) [51] y así sucesivamente.
NF es un gráfico dirigido donde cada arista tiene una determinada capacidad. Para la tarea MOT, cada nodo en el gráfico representa un objetivo de detección, un flujo se modela como un indicador de si dos nodos están conectados y una trayectoria corresponde a una ruta de flujo en el gráfico. El algoritmo basado en NF puede obtener la solución óptima global en tiempo polinómico y mejora la precisión del seguimiento al considerar la información de múltiples fotogramas al mismo tiempo. Sin embargo, es difícil para los métodos basados en NF tener en cuenta información múltiple en el proceso de seguimiento.
CRF es un modelo gráfico no dirigido que representa distribuciones de probabilidad condicional entre conjuntos de variables aleatorias. Cada nodo en la figura representa el objetivo de detección, la trayectoria se utiliza como entrada y el CRF predice la relación de probabilidad entre el objetivo de detección y cada trayectoria. La ventaja de CRF es que puede simular eficazmente la interacción y la interacción entre objetivos. Sin embargo, es fácil que el algoritmo MOT basado en CRF caiga en el óptimo local.
MCSM trata a MOT como un problema de agrupación de gráficos, donde cada grupo de salida representa un objetivo rastreado. MCSM mide la similitud entre los objetos detectados por el costo relacionado con los bordes y luego combina múltiples objetos de alta confianza en dimensiones de tiempo y espacio y realiza agrupaciones.
MWIS es el subconjunto más pesado de nodos no adyacentes en el gráfico de propiedades. Los nodos en el gráfico de propiedades representan los pares de trayectorias en cuadros de video consecutivos, y los pesos de los nodos representan la afinidad de los pares de trayectorias. Si varias trayectorias comparten el mismo objetivo de detección, los nodos están conectados. Finalmente, los resultados de asociación global se obtienen a través del gráfico de propiedades.
Dado que se pueden utilizar más cuadros de información de imagen en el proceso de seguimiento, los métodos fuera de línea generalmente tienen mayor precisión y solidez de seguimiento que los métodos en línea, pero su sobrecarga computacional es mayor y su rango de aplicación práctica es menor que los métodos en línea.
3.2 Método de seguimiento en línea
Debido a que el método de seguimiento en línea tiene las características de no depender de información futura y está más en línea con las necesidades reales, los algoritmos de seguimiento en línea se han convertido en la corriente principal de la investigación actual. Los métodos de seguimiento en línea generalmente correlacionan los objetos cuadro por cuadro en orden temporal, por lo que el seguimiento en línea también se denomina seguimiento secuencial. Los métodos actuales de seguimiento en línea suelen asociar objetos en función de sus características de movimiento y apariencia. Las primeras investigaciones rastrearon principalmente el objetivo en función de las características de movimiento del objetivo mediante la construcción de un modelo de movimiento. Posteriormente, al beneficiarse de las potentes capacidades de extracción de características de las redes neuronales, los algoritmos de seguimiento basados en características de apariencia han atraído una atención generalizada. Para mejorar aún más la precisión de seguimiento del algoritmo en varias escenas complejas, el algoritmo MOT que combina características de movimiento y apariencia se ha convertido en un punto de investigación en la actualidad.
3.2.1 Algoritmos basados en características de movimiento
Muchos algoritmos modelan características clave como la posición, la velocidad y la interacción de objetivos, y asocian objetivos en diferentes momentos según sus estados de movimiento.
En 2016, Bewley y otros [14] modelaron la posición y la velocidad de cada objetivo, y luego se basaron en el IoU entre el marco de predicción obtenido mediante el filtrado de Kalman [52] y el marco de detección obtenido por Faster R-CNN [53]. en el objetivo de seguimiento Objetivo asociado al marco. En 2019, Zhou y otros [15] se basaron en la red neuronal convolucional (CNN) [54] para modelar las reglas de movimiento del objetivo y la relación de interacción entre los objetivos. Posteriormente, Shan y otros [16] y Girbau y otros [17] diseñaron un modelo basado en convolución de gráficos y redes neuronales recurrentes para fusionar información de imágenes de múltiples cuadros para predecir el estado de movimiento del objetivo.
El método basado en las características de movimiento del objetivo puede abordar eficazmente la oclusión a corto plazo y aliviar la interferencia de objetivos similares en el modelo. Sin embargo, debido a la falta de funciones de apariencia, el rendimiento de seguimiento de estos algoritmos a menudo se degrada significativamente en escenas densas o cuando cambia la escala del objetivo.
3.2.2 Algoritmos basados en características de apariencia
Beneficiándose de las poderosas capacidades de extracción de características de CNN, muchos algoritmos actuales extraen características de apariencia más discriminativas a través de redes profundas, mejorando así la solidez del seguimiento del modelo en escenas concurridas.
En 2016, Yu y otros [18] diseñaron una red de extracción de características basada en GoogLeNet [55] para extraer las características de apariencia del objetivo y los objetivos asociados a través del algoritmo de vecinos k-denso [56]. En 2017, Son y otros [19] aprendieron características de objetos más discriminativas al aprender simultáneamente múltiples imágenes que contienen diferentes objetos. Lee y otros [20] propusieron una red de extracción de características que incorpora Feature Pyramid Network (FPN) [57] para mejorar la capacidad de discriminación de objetivos de la red fusionando múltiples niveles de características. En 2021, Sun y otros [21] propusieron una red de afinidad profunda para extraer las características de apariencia de los objetos y evaluar la similitud de apariencia entre objetos.
En comparación con el algoritmo basado en características de movimiento, el algoritmo basado en características de apariencia tiene una mayor capacidad de seguimiento en escenas con mucha gente y es más robusto para la transformación de escala objetivo. Sin embargo, los algoritmos basados únicamente en características de apariencia son propensos a errores como el seguimiento de la deriva del cuadro en escenas con interferencia de objetivos similar.
3.2.3 Algoritmos que combinan características de movimiento y apariencia
Es difícil realizar un seguimiento sólido en escenas complejas basándose únicamente en el movimiento del objetivo o en las características de apariencia, por lo que combinar el movimiento del objetivo y las características de apariencia es la dirección principal de la investigación actual.
En 2017, Wojke y otros [22] combinaron la posición predicha de KF y las características de apariencia del objetivo extraídas por CNN para calcular la afinidad entre los objetivos. Posteriormente, para aliviar el impacto de la detección ruidosa y las trayectorias de seguimiento redundantes en los resultados de seguimiento, Chen et al., [23] diseñaron un mecanismo de puntuación para eliminar los resultados de detección no confiables y las trayectorias candidatas, y luego asociar los objetivos restantes según KF y el objetivo. características de apariencia. En 2021, Li y otros [24] diseñaron un KF autocorrector para predecir la ubicación de objetos y evaluaron la similitud entre objetos a través de una red neuronal recurrente.
Los algoritmos de seguimiento que combinan funciones de movimiento y apariencia tienden a tener una mayor precisión de seguimiento y son más sólidos ante diversos desafíos en escenas complejas. Sin embargo, debido a la alta complejidad de la red y la cantidad relativamente grande de cálculos, la velocidad de seguimiento de estos algoritmos es lenta y es difícil cumplir con los requisitos del seguimiento en tiempo real.
04 Algoritmo basado en el paradigma JDE
El método SDE infiere sucesivamente dos redes profundas con grandes cargas computacionales, detección de objetos y extracción de características, durante el proceso de seguimiento. Esta alta sobrecarga computacional limita la velocidad de seguimiento del modelo. Por lo tanto, ha recibido atención el paradigma JDE, que completa la detección de objetos y la extracción de características en una sola red. Al hacer que las dos tareas clave de detección de objetos y extracción de características compartan una gran cantidad de características, el paradigma JDE puede reducir significativamente la carga computacional del algoritmo. Esta sección presenta primero el proceso de desarrollo del paradigma JDE y luego resume las direcciones de mejora de muchos académicos sobre el paradigma JDE en los últimos años.
4.1 La historia del desarrollo del paradigma JDE
El paradigma JDE genera características de ubicación y apariencia de objetos en una sola red agregando una rama de extracción de características paralela a la red de detección. Al hacer que las dos tareas compartan características, se evitan de manera efectiva algunos cálculos repetidos y se mejora la velocidad de seguimiento del modelo.
En 2019, Voigtlaender y otros [58] agregaron una rama de extracción de características a la red de detección de dos etapas MaskR-CNN [59] y propusieron TrackR-CNN. La rama de extracción de características extrae las características de apariencia de cada región candidata de las regiones candidatas generadas por la Red de propuesta de región (RPN) a través de una capa completamente conectada. Además, MaskR-CNN tiene una rama de segmentación de instancias, que permite a TrackR-CNN extraer características a nivel de píxel objetivo, mejorando así de manera efectiva la precisión del seguimiento. Aunque la cantidad de cálculo de Track-CNN es reducida en comparación con el algoritmo basado en el paradigma SDE, debido al largo tiempo de razonamiento de la red de dos etapas, TrackR-CNN todavía no cumple con los requisitos del seguimiento en tiempo real.
En 2020, Wang y otros [60] agregaron una rama de extracción de características a la red de detección de una sola etapa YOLOv3 [61] y propusieron JDE864. El método de detección de YOLOv3, que devuelve directamente la posición y categoría del objetivo en la imagen, es beneficioso para mejorar la velocidad de seguimiento del algoritmo. Además, JDE864 considera el entrenamiento de red como un problema de aprendizaje multitarea y adopta una función de pérdida de autoequilibrio [62] para equilibrar la importancia de la clasificación, la regresión del cuadro delimitador y la extracción de características de reidentificación (ReID). JDE864, que se realizó simultáneamente en una sola red, terminó siendo el primer algoritmo MOT con seguimiento en tiempo real. Sin embargo, el diseño de su rama de extracción de características es simple y la contradicción entre la detección de objetivos y ReID no se considera completamente, por lo que la solidez del seguimiento es relativamente baja.
4.2 Investigación sobre la mejora del paradigma JDE
Aunque TrackR-CNN y JDE864 reducen efectivamente la carga computacional del modelo, su precisión de seguimiento no es significativamente mejor que la del algoritmo anterior basado en el paradigma SDE. Por lo tanto, muchos académicos han analizado las razones de los resultados de seguimiento insatisfactorios y los han mejorado, centrándose principalmente en tres aspectos: red de detección sin anclajes, múltiples subtareas colaborativas y mecanismo de atención del diseño.
4.2.1 Red de detección de tramas sin anclajes
En una red de detección que utiliza cuadros de anclaje, un cuadro de anclaje puede contener múltiples objetivos y un objetivo corresponde a múltiples cuadros de anclaje al mismo tiempo. Esta incertidumbre reduce la capacidad de discriminación de las características ReID extraídas. Por lo tanto, muchos académicos en investigaciones posteriores eligen el algoritmo de diseño de red de detección basado en el marco sin anclaje.
Zhang y otros [25] agregaron una rama de extracción de características paralela a la red de detección de cuadros sin anclaje basada en puntos centrales Center-Net, y redujeron el riesgo de sobreajuste al aprender las características de baja dimensión del objetivo. En 2021, Liu y otros [26] diseñaron un módulo de conversión de regiones basado en convolución deformable [65] en la red FCOS [64] para reducir la atención de la red a regiones irrelevantes. Posteriormente, Yan et al.66 integraron una rama de extracción de características en la red FCOS. FCOS utiliza FPN para agregar múltiples niveles de funciones de destino, lo que hace que las funciones extraídas sean más adecuadas para la detección y ReID.
En comparación con la red basada en marcos de anclaje, la red sin marcos de anclaje puede extraer con mayor precisión las características del objetivo en sí, y el algoritmo basado en la red sin marcos de anclaje logra un mejor equilibrio entre la precisión del seguimiento y la velocidad de seguimiento.
4.2.2 Colaborar con múltiples subtareas
Dado que el propósito de la detección de objetivos es encontrar los puntos comunes de objetivos similares, y el propósito de ReID es encontrar las diferencias entre objetivos del mismo tipo, esta contradicción dificulta que las características extraídas satisfagan las necesidades de dos tareas al mismo tiempo. al mismo tiempo. Por lo tanto, la sinergia de múltiples subtareas dentro de una red es una dirección de investigación importante.
En 2020, Liang y otros [27] diseñaron una red de correlación cruzada para aprender características comunes compartidas por múltiples tareas y características específicas de cada tarea. Chen y otros [28] diseñaron una característica con reconocimiento de normas para mapear vectores de características en coordenadas polares, y luego usaron la norma binaria [67] y el ángulo de los vectores para la detección y ReID, respectivamente. En 2021, Wan y otros [29] diseñaron una función espacio-temporal multicanal que codifica las características de apariencia y movimiento del objetivo en diferentes canales y tiene en cuenta tanto la detección como la ReID a través de funciones más ricas. Posteriormente, Liang y otros [30] diseñaron una red de reinspección para corregir los resultados de la detección y las características ReID extraídas.
Dado que las contradicciones dentro de la red pueden aliviarse, la estrategia mejorada de coordinar múltiples subtareas puede mejorar efectivamente la precisión del seguimiento del modelo. Pero aumenta la complejidad de la red y la cantidad de cálculo del modelo, por lo que la velocidad de seguimiento se ralentiza en consecuencia.
4.2.3 Mecanismo de atención
Al diseñar diferentes mecanismos de atención para mejorar la atención de la red a áreas específicas, puede mejorar efectivamente la calidad de detección del modelo en escenas complejas y permitir que la red extraiga con precisión las características ReID más discriminativas del objetivo, mejorando así efectivamente el rendimiento de seguimiento de el algoritmo.
En 2020, Meng et al.31 diseñaron un mecanismo de atención espaciotemporal para aprender y actualizar los pesos de las características en cada momento al rastrear las características objetivo. Zhang y otros [32] introdujeron el mecanismo de atención espacial y el mecanismo de atención del canal [68] para mejorar la robustez del modelo ante interferencias de objetos similares y transformaciones de escala objetivo. En 2021, el mecanismo de atención al objetivo y el mecanismo de atención al distractor propuestos por Guo et al.59 pueden mejorar eficazmente la capacidad del modelo para distinguir diferentes objetivos. Posteriormente, Yu y otros [33] diseñaron una atención deformable para capturar la asociación entre el objetivo y el fondo circundante, y aprendieron efectivamente las características ReID más discriminativas del objetivo.
Agregar un mecanismo de atención puede centrar la atención de la red en áreas relacionadas con las tareas, y una atención diferente puede mejorar efectivamente el rendimiento de seguimiento del modelo en diferentes escenarios de seguimiento. Además, agregar un mecanismo de atención generalmente tiene poco impacto en el cálculo y la complejidad de la red.
05 Algoritmo basado en el paradigma JDT
Aunque el paradigma JDE reduce la cantidad de cálculo en comparación con el paradigma SDE, solo combina las dos partes de detección de objetivos y extracción de características, por lo que la complejidad del modelo sigue siendo alta y no se puede propagar hacia atrás, lo que dificulta la optimización global. En los últimos años, el paradigma JDT de completar tres subtareas en una sola red ha atraído la atención de muchos académicos.
El paradigma JDT toma imágenes de múltiples fotogramas adyacentes como entrada, predice su desplazamiento de posición actual o características de apariencia en función del movimiento anterior o la información de apariencia del objetivo y luego asocia el objetivo. Los algoritmos actuales basados en el paradigma JDT se dividen principalmente en métodos basados en redes siamesas y métodos basados en Transformer [70].
5.1 Método basado en red siamesa
Una red siamesa es una variante de una CNN estándar. Como se muestra en la Figura 3, el método basado en la red siamesa extrae las características del objetivo en diferentes imágenes de fotogramas de video a través de dos capas convolucionales con pesos compartidos y combina diferente información de la imagen para aprender características más discriminativas del objetivo. Posteriormente, el algoritmo busca objetos de seguimiento anteriores en la imagen del cuadro actual. Según la forma en que el modelo busca objetos, se puede dividir en métodos basados en regiones candidatas y métodos basados en puntos centrales.

5.1.1 Algoritmos basados en regiones candidatas
Los métodos basados en propuestas primero generan regiones candidatas para ubicaciones de objetos y luego buscan objetos en las regiones candidatas y hacen una regresión de los cuadros delimitadores de acuerdo con las características de los objetos en momentos anteriores.
En 2019, Bergmann y otros [71] consideraron el MOT como un problema de detección para una tarea ReID integrada y diseñaron un modelo de compensación de movimiento para aliviar el problema del movimiento de la cámara o los grandes cambios de posición del objetivo en vídeos de baja velocidad de fotogramas. Peng y otros [34] generaron una región candidata a través de RPN y luego devolvieron un par de cuadros delimitadores del objetivo de dos cuadros de imágenes adyacentes a través de cuadros de anclaje encadenados. Xu y otros [35] diseñaron una red húngara profunda basada en una red neuronal recurrente bidireccional para mejorar la precisión del objetivo de asociación del algoritmo. En 2021, Shuai y otros [61] ampliaron el cuadro de seguimiento del cuadro anterior del objetivo y lo asignaron a la imagen del cuadro actual como un área candidata, y buscaron el objetivo de seguimiento en él. [37] seleccionaron un par de imágenes adyacentes para el aprendizaje comparativo durante el proceso de capacitación. Después de generar una gran cantidad de regiones candidatas a través de RPN, compare la similitud entre las regiones candidatas de los dos cuadros de imágenes para entrenar la capacidad del modelo para extraer características.
Este método basado en propuestas es adecuado para rastrear escenarios donde la posición objetivo cambia relativamente lentamente. En escenas donde la posición del objetivo cambia mucho entre dos fotogramas adyacentes, como objetivos que se mueven rápidamente o velocidades de fotogramas de video bajas, el área candidata generada por el modelo puede desviarse mucho de la posición real del objetivo, lo que resulta en un seguimiento falso o un seguimiento perdido.
5.1.2 Algoritmo basado en punto central
El método basado en el punto central predice directamente la posición central del objetivo en la imagen y, al mismo tiempo, estima el desplazamiento de la posición de las coordenadas del objetivo de seguimiento en la imagen actual para la asociación de datos posterior y, finalmente, devuelve el cuadro delimitador del objetivo. .
En 2020, Zhou y otros [38] agregaron dos ramas paralelas para predecir el desplazamiento vertical y horizontal del objetivo entre dos cuadros adyacentes. Para abordar el problema de que el cuadro delimitador tradicional no puede representar la información espaciotemporal del objetivo, Pang et al., [39] diseñaron un tubo límite que describe el estado del objetivo con ubicaciones de momentos múltiples. En 2021, para mejorar la solidez del modelo ante la oclusión, Wu y otros [40] diseñaron un módulo de guía de movimiento para predecir el desplazamiento de la posición de las coordenadas de los puntos de píxeles correspondientes en dos fotogramas de imágenes y, en función del desplazamiento previsto para fusione el gráfico de características de momentos múltiples para mejorar las características del objetivo. Wang y otros [41] fortalecen la capacidad del modelo para discriminar cada objetivo al aprender la relación entre el objetivo y el entorno circundante y otros objetivos. Para mejorar la solidez del modelo ante la oclusión, Horna-kova y otros [42] diseñaron un módulo de memoria recursiva espaciotemporal para predecir la posición del objetivo cuando estaba ocluido en función de la posición de todos los fotogramas históricos. Posteriormente, para aprovechar al máximo la información espacio-temporal del objetivo, Wang et al.43 modelaron la relación de interacción espacio-temporal entre objetivos a través de una red neuronal gráfica, fusionando así la información de múltiples fotogramas de imágenes.
En comparación con el algoritmo basado en el área candidata, el algoritmo basado en el punto central puede extraer con mayor precisión las características del objetivo en sí. En segundo lugar, el método basado en el punto central es más adecuado para representar el desplazamiento de posición del objetivo. Al mismo tiempo, de acuerdo con el desplazamiento de posición previsto, el método basado en el punto central puede fusionar con precisión las características del objetivo en múltiples momentos pasados, a fin de mejorar la precisión de seguimiento del algoritmo en escenas complejas al hacer un uso completo de información espaciotemporal.
5.2 Método del transformador
Transformer se propuso por primera vez en el procesamiento del lenguaje natural, que extrae completamente las características profundas del objetivo a través del mecanismo de atención. En los últimos años, Transformer ha logrado un éxito notable en múltiples tareas de visión por computadora [72-74] debido a sus poderosas capacidades de representación de características y buenas capacidades de computación paralela.
En 2020, Sun y otros [44] aplicaron Transformer a la tarea MOT por primera vez. Para resolver el problema de que al Transformer básico le resulta difícil rastrear nuevos objetivos en el video, diseñaron dos decodificadores para detectar objetivos y rastrear objetivos anteriores. Posteriormente, Chu y otros [45] propusieron un transformador gráfico espacio-temporal para modelar la interacción espacio-temporal entre objetivos. Organiza las trayectorias de seguimiento de cada objetivo en un conjunto de gráficos dispersos ponderados y simula eficazmente la relación interactiva entre múltiples objetivos mediante la construcción de un codificador de gráficos espaciales, un codificador temporal y un decodificador de gráficos espaciales. Dado que el método de representar objetos mediante cuadros delimitadores en escenas complejas introducirá información de fondo y otra información de interferencia como los objetos, Xu et al.[46] propusieron un algoritmo de seguimiento de transformadores basado en mapas de calor para predecir la posición del punto central del objetivo.
Beneficiándose de la poderosa capacidad de asociación de datos de Transformer, el algoritmo basado en Transform-former tiene una gran solidez de seguimiento. Además, Transformer tiene una estructura clara y un rendimiento excelente, y todavía tiene un gran potencial de desarrollo en el campo de MOT, lo que proporciona una nueva dirección para la investigación de seguimiento.
06 Conjuntos de datos e indicadores de evaluación
6.1 Conjunto de datos MOT
Para proporcionar suficientes datos de entrenamiento para el algoritmo MOT y evaluar con precisión el nivel de rendimiento de cada algoritmo, muchos académicos han publicado múltiples conjuntos de datos MOT en los últimos años. Según los diferentes objetos de seguimiento de cada conjunto de datos, se puede dividir en un conjunto de datos de seguimiento de peatones y un conjunto de datos de seguimiento de vehículos.
MOT15 [75] es el primer conjunto de datos MOT, que contiene 22 secuencias de vídeo. MOT15 incluye principalmente desafíos como cámaras no fijas, cambios de ángulo de visión y cambios de iluminación, y proporciona los resultados de detección del algoritmo ACF [76]. Posteriormente, Milan y otros publicaron el conjunto de datos MOT16 [77] con una mayor densidad de objetivos. El conjunto de datos consta de 14 secuencias de vídeo y proporciona los resultados de detección del algoritmo DPM [78]. Las secuencias de video de MOT17 [79] y MOT16 son las mismas, pero MOT17 proporciona resultados de anotación más precisos y también proporciona resultados de detección de Faster R-CNN, DPM y SDP [80]. Los principales desafíos de los conjuntos de datos MOT16 y MOT17 incluyen el movimiento de la cámara, las interacciones frecuentes con los objetos y los cambios de iluminación. La escena de seguimiento en MOT20 [81] está extremadamente concurrida y su densidad promedio de objetos excede con creces la de otros conjuntos de datos. TAO-person [82] es un conjunto de datos de seguimiento de peatones a gran escala que contiene 418 vídeos de formación y 826 vídeos de prueba. El principal desafío del conjunto de datos de personas TAO proviene de los complejos patrones de movimiento y el desenfoque del movimiento de los peatones.
KITTI [83-84] se puede utilizar para el seguimiento de peatones y vehículos, contiene 50 secuencias de vídeo y proporciona resultados de detección de DPM y Region Lets [85]. La mayoría de los vídeos del conjunto de datos de seguimiento de vehículos UA-DETRAC [86] se graban en carreteras o autopistas concurridas de las ciudades, por lo que hay mucho desenfoque de movimiento y oclusión mutua entre los objetos. Waymo [87] contiene 1150 vídeos tomados en zonas urbanas o suburbanas. Además de imágenes 2D y sus anotaciones, Waymo también proporciona información de radar para tareas de detección y seguimiento 3D. La Tabla 2 enumera la información de los conjuntos de datos de uso común actual, donde la densidad de objetivos (Densidad) indica la cantidad de objetivos contenidos en cada cuadro del conjunto de datos en promedio.

6.2 Índice de Evaluación
Para evaluar de manera integral el rendimiento de seguimiento del algoritmo, actualmente se suelen utilizar múltiples indicadores [90-92] para evaluar el rendimiento de seguimiento del modelo. El número de cambios de ID (Identity Switches, ID) se refiere al número de intercambios de ID de todos los objetivos durante todo el proceso de seguimiento. El Identification F-Score (IDF) tiene en cuenta la precisión y la recuperación de la ID del objetivo. son modelos de respuesta Métricas importantes para el seguimiento de la solidez. FP es el número total de errores y FN es el número total de errores. La precisión de seguimiento de objetos múltiples (MOTA) es uno de los indicadores de evaluación más importantes, como se muestra en la fórmula (1), que considera de manera integral FP, FN e ID.
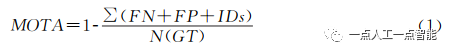
donde es el número total de valores verdaderos.
La precisión del seguimiento (Precisión de seguimiento de múltiples objetos, MOTP) considera principalmente la superposición entre el cuadro de seguimiento y el cuadro delimitador real. Mostly Tracked (MT) indica la proporción de objetivos cuyas trayectorias se rastrean con éxito en más del 80%; la proporción más perdida (Mostly Tracked, ML) indica la proporción de objetivos cuyas trayectorias no se rastrean en más del 80%. El número de segmentación de pistas (Fragmentación, Frag) indica el número total de interrupciones de todas las pistas de seguimiento. En 2021, Luiten y otros [93] propusieron una precisión de seguimiento de orden superior (HOTA). HOTA proporciona una evaluación integral del rendimiento del modelo calculando la media geométrica de la precisión de detección y la precisión de asociación en varios umbrales de error de localización. Hz se utiliza para evaluar la velocidad de seguimiento del algoritmo y la unidad es fotogramas por segundo (FPS).
07 Comparación y análisis de modelos.
Esta sección selecciona múltiples algoritmos y evalúa su desempeño en los conjuntos de datos MOT17 y MOT20. Los indicadores de rendimiento de cada algoritmo en los conjuntos de datos MOT17 y MOT20 se enumeran en la Tabla 3. Los datos de evaluación del rendimiento de cada algoritmo se proporcionan en la literatura relevante, donde la fuente en negrita indica el valor óptimo del indicador y el subrayado indica el valor subóptimo. valor del indicador.

El paradigma SDE diseña algoritmos especiales para las dos tareas de extracción de características y asociación de datos, por lo que generalmente tiene una mejor solidez de seguimiento y la mayoría de los indicadores de ID del algoritmo son pequeños.
La estrategia de ejecutar las tres tareas por separado evita las contradicciones dentro del modelo y dota al paradigma SDE de un buen límite superior de rendimiento. Por ejemplo, TPAGT[16] puede alcanzar un MOTA del 76,2% en el conjunto de datos MOT17. Sin embargo, el rendimiento de seguimiento del algoritmo basado en el paradigma SDE depende del rendimiento de detección, y los resultados de detección insatisfactorios, como detección perdida, detección falsa y detección de ruido, a menudo conducen a una disminución significativa en el rendimiento de seguimiento.
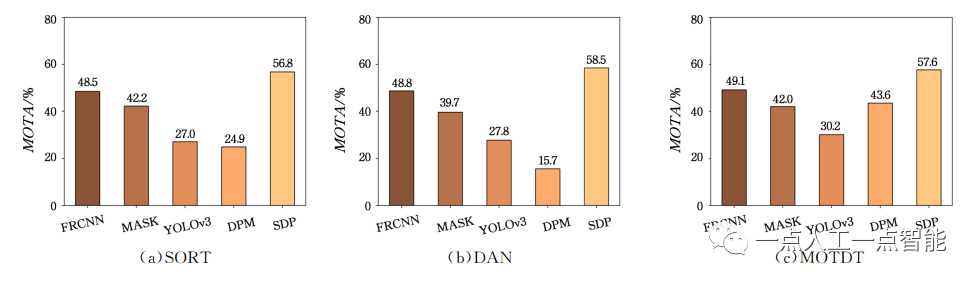
Seleccionamos algoritmos representativos SORT [14], DAN [21] y MOTDT [23] de métodos basados en movimiento, basados en apariencia y combinados basados en movimiento y apariencia, respectivamente. La Figura 4 muestra el MOTA en el conjunto de datos MOT17 cuando los tres algoritmos utilizan respectivamente Faster R-CNN (FRCNN), Mask R-CNN (MASK), YOLOv3, DPM y SDP como algoritmos de detección. Se han producido cambios significativos debido a diferentes resultados de las pruebas.
Cuando SORT y DAN utilizan los resultados de detección de SDP, el MOTA alcanza el 56,8% y 58,5% respectivamente, mientras que cuando se utilizan los resultados de detección de DPM, el MOTA cae al 24,9% y 15,7%, respectivamente. Cuando MOTDT adopta SDP como algoritmo de detección, MOTA alcanza el 57,6%, mientras que cae al 30,2% cuando se utiliza YOLOv3.
Además, SDE solo puede optimizar las tres tareas de detección de objetos, extracción de características y asociación de datos, y no puede optimizar globalmente el modelo mediante retropropagación.
Al mismo tiempo, el modelo del método SDE es complejo y computacionalmente intensivo, por lo que el algoritmo basado en el paradigma SDE tiene una velocidad de seguimiento baja. CRF_CNN[12], TPAGT[16], DAN[21] y MOTDT[23] rastrearon el conjunto de datos MOT17 Las velocidades son 1.4FPS, 6.8FPS, 3.9FPS y 6.3FPS respectivamente, que son difíciles de cumplir con los requisitos del seguimiento en tiempo real.
Al hacer que los dos submódulos con la mayor cantidad de cálculo, detección de objetos y extracción de características de apariencia de objetos, compartan características, el paradigma JDE tiene las características de una pequeña cantidad de cálculos y parámetros, por lo que se ha convertido en un método de seguimiento comúnmente utilizado en el industria.
Sin embargo, los primeros algoritmos basados en JDE no tienen ventajas obvias en términos de precisión: por ejemplo, JDE864 [38] tiene una velocidad de seguimiento de 30,3 FPS en el conjunto de datos MOT16 y MOTA es del 62,1%. En la optimización posterior del paradigma JDE, el uso de redes de detección sin anclajes es una estrategia directa y efectiva. FairMOT [25] logró un MOTA del 73,7% y 61,8% en los conjuntos de datos MOT17 y MOT20, respectivamente, y la velocidad de seguimiento alcanzó el 25,9%. .FPS y 13,2FPS.
La estrategia de aliviar la contradicción entre la detección de objetos y ReID dentro de la red puede aportar ganancias considerables a la precisión de seguimiento del modelo. Por ejemplo, CSTrack[27] logró 74,9% y 66,6% de MOTA en los conjuntos de datos MOT17 y MOT20, respectivamente, y OMC[51] alcanzó el 74,9% y el 66,6% en los conjuntos de datos MOT17, mientras que el MOTA en el conjunto de datos alcanzó el 76,3%.
Sin embargo, esta estrategia tendrá un cierto impacto en la velocidad de seguimiento del modelo. En el conjunto de datos MOT17, las velocidades de seguimiento de CSTrack y OMC son 15,8 FPS y 12,8 FPS, respectivamente. Diseñar un mecanismo de atención ayuda a mejorar el rendimiento de la red en una dirección específica. Por ejemplo, Relation Track [33] tiene un índice de ID de 1374 en el conjunto de datos MOT17, que es el mejor resultado entre todos los algoritmos. Al mismo tiempo, el MOTA alcanzó el 73,8% y el MOTA en el MOT20 alcanzó el 67,2%.
Además, diferentes redes de atención aportan diferentes cantidades de cálculos al modelo, y las redes de atención complejas a menudo provocan una grave desaceleración del modelo. Aunque Relation Track tiene una gran precisión y robustez de seguimiento, no es eficaz en MOT17 y MOT20. cayó a 6.6FPS y 4.3FPS, respectivamente.
Del análisis anterior, se puede encontrar que la mejora de la precisión del seguimiento y la solidez del paradigma JDE a menudo tiene el costo de reducir la velocidad de seguimiento del modelo. En investigaciones futuras, la optimización simultánea de la precisión y la velocidad de seguimiento del algoritmo del paradigma JDE sigue siendo el foco y la dificultad de la investigación.
JDT es la tendencia de investigación actual, su estructura es simple y clara y su rendimiento es superior. Dado que el método JDT completa tres subtareas en una sola red al mismo tiempo, la mayoría de los algoritmos pueden lograr un entrenamiento de un extremo a otro y pueden optimizarse globalmente mediante retropropagación, por lo que los algoritmos basados en el paradigma JDT generalmente tienen un MOTA más alto. Por ejemplo, Corr-Tracker [41] y GSDT [43] lograron un MOTA del 76,5 % y del 73,2 % en MOT17.
Además, el algoritmo basado en la red siamesa puede procesar múltiples fotogramas de imágenes de vídeo al mismo tiempo, aprovechando al máximo la información espacio-temporal, por lo que la mayoría de los algoritmos tienen menos errores, como CTracker[34], CenterTrack[38] y TraDeS. [40] sobre indicadores de FP Todos tienen mejor desempeño.
Además, Transformer se ha aplicado con éxito en tareas MOT [44-46], y los algoritmos de seguimiento basados en Transformer han mostrado un buen rendimiento de seguimiento. El algoritmo basado en Transformer ha logrado resultados sobresalientes en múltiples indicadores. Por ejemplo, el MOTA y la velocidad de TransTrack[72] en MOT17 alcanzaron 75,2% y 16,9FPS respectivamente. Al mismo tiempo, los indicadores MT e IDF alcanzaron los mejores. [45] ] alcanzó los mejores indicadores MOTA, MT, IDF e ID de MOT20.
Aunque los algoritmos actuales de múltiples paradigmas JDT han logrado un excelente rendimiento de seguimiento, todavía quedan algunos problemas por resolver. En primer lugar, la mayoría de los algoritmos basados en la red siamesa no son significativamente mejores que otros algoritmos en ID. Cómo mantener de manera sólida la ID de cada objetivo durante el proceso de seguimiento a largo plazo sigue siendo una dificultad de investigación actual. Los métodos basados en transformadores pueden mantener una gran precisión de seguimiento y solidez en escenas complejas [94], y aún tienen un gran potencial de investigación y espacio de desarrollo. Sin embargo, la mayoría de los algoritmos actuales basados en Transformer tienen una velocidad de seguimiento lenta, lo que dificulta cumplir con los requisitos de las aplicaciones prácticas. Además, el algoritmo MOT actual basado en Transformer tiene una gran cantidad de cálculo, por lo que tiene altos requisitos para equipos de hardware y, por lo general, se requieren múltiples GPU de alto rendimiento para optimizar la red.
08 Conclusión
MOT se utiliza ampliamente en los campos del monitoreo inteligente y la interacción persona-computadora. Este artículo presenta primero el principio de MOT y los desafíos en el proceso de seguimiento. En segundo lugar, de acuerdo con el paradigma de seguimiento adoptado por el algoritmo para completar las tres subtareas. , Los algoritmos MOT de los últimos años se dividen en tres categorías, se hace una descripción general más detallada y luego se analizan las ventajas y desventajas de cada tipo de algoritmo.
En los últimos años, la tecnología MOT basada en el aprendizaje profundo se ha desarrollado rápidamente y el rendimiento de seguimiento del modelo ha mejorado significativamente. En la actualidad, se han aplicado cada vez más tecnologías a las tareas MOT, pero todavía hay muchas direcciones de investigación que valen la pena. explorador.
(1) MOT no supervisado: la mayoría de los algoritmos MOT actuales se basan en el aprendizaje supervisado, pero la anotación del conjunto de datos MOT necesita encontrar el mismo objetivo entre diferentes imágenes cuadro por cuadro, lo que requiere mucho tiempo y costos económicos. El diseño de algoritmos MOT basados en el aprendizaje no supervisado [95-96] puede ayudar a reducir la sobrecarga de los datos anotados manualmente; sin embargo, la tarea MOT no supervisada es muy desafiante debido a la falta de conocimiento previo del objetivo de seguimiento.
(2) Relación de interacción entre objetos: al modelar la relación de interacción entre múltiples objetos, se puede mejorar la capacidad del modelo para discriminar cada objeto en una escena llena de gente. Sin embargo, el algoritmo actual todavía tiene poca exploración de la relación de interacción entre objetos. En futuros trabajos de investigación, se puede utilizar Transformer o red neuronal gráfica [97-99] para modelar la relación de interacción entre objetos, a fin de mejorar aún más el algoritmo MOT en escenas extremadamente concurridas, como estaciones de metro durante las horas pico y atracciones turísticas durante las vacaciones. .rastreo de robustez.
(3) El seguimiento facilita la detección: el rendimiento de seguimiento de los algoritmos MOT actuales se basa en algoritmos de detección, pero los algoritmos MOT actuales generalmente ejecutan algoritmos de detección solos y no exploran la información del objetivo en momentos anteriores. Aproveche al máximo la información espacio-temporal del objetivo y transfiera las características del movimiento y la apariencia del objetivo en el pasado al cuadro actual, lo que ayuda a mejorar el rendimiento del modelo al realizar el seguimiento de vehículos de tráfico y el análisis del comportamiento de los atletas en el campo, que tienen mucha oclusión y desenfoque de movimiento. Seguimiento del rendimiento.
1. Algoritmo de detección de líneas de carril de un extremo a otro basado en un perceptrón multicapa
3. Descarga del libro: "Aprendizaje profundo y visión por computadora en la conducción autónoma"