Hola a todos, soy Wei Xue AI. Hoy presentaré la aplicación de la investigación de 12 visualizaciones de visión por computadora sobre la extracción de características de imágenes en redes neuronales convolucionales, para que todos puedan comprender todo el proceso de extracción de características.
Para comprender todo el proceso de extracción de características de imágenes en redes neuronales convolucionales, podemos compararlo con el procesamiento de información visual por parte del cerebro humano. Al igual que cuando vemos un objeto, el cerebro procesará información de diferentes características a través de diferentes neuronas, como el contorno, el color y la textura.
1. Introducción a la extracción de características de imágenes
En CNN, la imagen de entrada se procesa capa por capa y cada capa extrae información de características diferente. Estas capas pueden considerarse como diferentes "filtros" que reconocen patrones y formas específicos en una imagen, como bordes, esquinas y líneas. A medida que el número de capas aumenta gradualmente, CNN puede extraer características cada vez más complejas, como textura, forma y estructura de la imagen.
Supongamos que nuestra imagen de entrada es la imagen de un gato. La primera capa de CNN puede detectar los bordes y esquinas del cuerpo del gato, la segunda capa puede extraer la forma de las orejas del gato y el contorno de la cara, y la tercera capa puede analizar más a fondo la textura del pelo, los ojos, forma. Este proceso de extracción de características se puede visualizar, lo que nos permite comprender mejor cómo CNN aprende y procesa la información de la imagen. A través de la visualización, podemos ver las características de la imagen extraídas por CNN en diferentes niveles. Podemos encontrar que las características de bajo nivel incluyen bordes y texturas, mientras que las características de alto nivel incluyen información más abstracta y semántica, como ojos, nariz y boca.
2. El principio de extracción de características de CNN
Las redes neuronales convolucionales extraen características de las imágenes mediante operaciones de convolución y agrupación. El principio es el siguiente:
imagen de entrada III es procesado por múltiples capas convolucionales y capas de agrupación para obtener el mapa de características finalFFF._ _ En la capa convolucional, utilice un conjunto de filtros que se pueden aprenderWWW realiza una operación de convolución en la imagen de entrada y agrega sesgobbb , es decir:
C = W ∗ Yo + segundo C = W * Yo + segundoC=W.∗I+b
Entre ellos, ∗ *∗ significa operación de convolución. De esta manera, cada filtro se desliza sobre la imagen de entrada y calcula una operación de convolución para obtener el mapa de características correspondiente.
En el mapa de características, la activación no lineal se realiza a través de una función de activación (como ReLU) para obtener un mapa de características de activación:
A = ReLU ( C ) A = \text{ {ReLU}}(C)A=ReLU (C)
Luego, la capa de agrupación reduce el muestreo del mapa de características de activación para reducir la dimensión espacial del mapa de características. Una operación de agrupación comúnmente utilizada es la agrupación máxima, que selecciona el valor máximo en cada ventana de agrupación como característica de salida. Esto preserva las características más destacadas al tiempo que reduce el cálculo.
Después de múltiples operaciones de convolución y agrupación, se obtienen una serie de mapas de características de diferentes tamaños. Estos mapas de características contienen diferentes niveles de características de la imagen de entrada, desde bordes y texturas de bajo nivel hasta información semántica de alto nivel.
Estos mapas de características se pueden pasar a capas completamente conectadas para clasificación, detección u otras tareas. La capa completamente conectada aplana el mapa de características en un vector, lo multiplica con la matriz de peso, agrega un sesgo y finalmente obtiene el resultado final a través de funciones de activación como la función softmax.
La red CNN aprende automáticamente las características de la imagen mediante operaciones de convolución y agrupación, lo que nos permite comprender y analizar mejor los datos de la imagen y aplicarlos a diversas tareas de visión por computadora.
3. Proceso de visualización de características de extracción de CNN
Ahora implementaré el proceso de extracción de características de imágenes mediante código:
import matplotlib.pyplot as plt
import torch
from PIL import Image
import numpy as np
import sys
sys.path.append("..")
from torchvision import transforms
# 对于给定的一个网络层的输出x,x为numpy格式的array,维度为[0, channels, width, height]
def draw_features(width, height, channels,x,savename):
fig = plt.figure(figsize=(32,32))
fig.subplots_adjust(left=0.05, right=0.95, bottom=0.05, top=0.95, wspace=0.05, hspace=0.05)
for i in range(channels):
plt.subplot(height,width, i + 1)
plt.axis('off')
img = x[0, i, :, :]
pmin = np.min(img)
pmax = np.max(img)
img = (img - pmin) / (pmax - pmin + 0.000001)
plt.imshow(img, cmap='gray')
# print("{}/{}".format(i, channels))
fig.savefig(savename, dpi=300)
fig.clf()
plt.close()
# 读取模型
def load_checkpoint(filepath):
checkpoint = torch.load(filepath)
model = checkpoint['model'] # 提取网络结构
model.load_state_dict(checkpoint['net_state_dict']) # 加载网络权重参数
for parameter in model.parameters():
parameter.requires_grad = False
model.eval()
return model
savepath = './'
def predict(model):
# 读入模型
model = load_checkpoint(model)
print(model)
##将模型放置在gpu上运行
if torch.cuda.is_available():
model.cuda()
img = Image.open(img_path).convert('RGB')
INPUT_SIZE =(224,224) # 根据需要调整图像的大小
# 创建图像转换函数
transform = transforms.Compose([
transforms.Resize(INPUT_SIZE),
transforms.ToTensor(),
])
# 对图像进行转换
img = transform(img).unsqueeze(0)
if torch.cuda.is_available():
img = img.cuda()
# 查看每一层处理的图片信息
with torch.no_grad():
x = model.conv1(img)
x = model.bn1(x)
draw_features(5,5,15, x.cpu().numpy(), "{}/f1_conv1.png".format(savepath))
x = model.relu(x)
draw_features(5,5,15, x.cpu().numpy(), "{}/f1_conv2.png".format(savepath))
x = model.layer1(x)
draw_features(5,5,15, x.cpu().numpy(), "{}/f1_conv3.png".format(savepath))
x = model.layer2(x)
draw_features(5,5,15, x.cpu().numpy(), "{}/f1_conv4.png".format(savepath))
x = model.layer3(x)
draw_features(5,5,15, x.cpu().numpy(), "{}/f1_conv5.png".format(savepath))
if __name__ == "__main__":
trained_model = 'resnet_model.pkl'
img_path = 'cat.png'
predict(trained_model)
Construya el modelo ResNet: cree un directorio en el mismo nivel que la función de visualización principal: modelos->ClassNetwork->ResNet.py
import math
import torch
import torch.nn as nn
def conv3x3(in_planes, out_planes, stride=1):
"3x3 convolution with padding"
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=1, bias=False)
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = conv3x3(planes, planes)
self.bn2 = nn.BatchNorm2d(planes)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, planes * Bottleneck.expansion, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes * Bottleneck.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
#attention block
out += residual
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, dataset='cifar10', depth=18, num_classes=10, bottleneck=False):
super(ResNet, self).__init__()
self.dataset = dataset
if self.dataset.startswith('cifar'):
self.inplanes = 16
# print(bottleneck)
if bottleneck == True:
n = int((depth - 2) / 9)
block = Bottleneck
else:
n = int((depth - 2) / 6)
block = BasicBlock
self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(self.inplanes)
self.relu = nn.ReLU(inplace=True)
self.layer1 = self._make_layer(block, 16, n)
self.layer2 = self._make_layer(block, 32, n, stride=2)
self.layer3 = self._make_layer(block, 64, n, stride=2)
self.avgpool = nn.AvgPool2d(8)
self.fc = nn.Linear(64 * block.expansion, num_classes)
elif dataset == 'imagenet':
blocks = {
18: BasicBlock, 34: BasicBlock, 50: Bottleneck, 101: Bottleneck, 152: Bottleneck, 200: Bottleneck}
layers = {
18: [2, 2, 2, 2], 34: [3, 4, 6, 3], 50: [3, 4, 6, 3], 101: [3, 4, 23, 3], 152: [3, 8, 36, 3],
200: [3, 24, 36, 3]}
assert layers[depth], 'invalid detph for ResNet (depth should be one of 18, 34, 50, 101, 152, and 200)'
self.inplanes = 64
self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(blocks[depth], 64, layers[depth][0])
self.layer2 = self._make_layer(blocks[depth], 128, layers[depth][1], stride=2)
self.layer3 = self._make_layer(blocks[depth], 256, layers[depth][2], stride=2)
self.layer4 = self._make_layer(blocks[depth], 512, layers[depth][3], stride=2)
self.avgpool = nn.AvgPool2d(7)
self.fc = nn.Linear(512 * blocks[depth].expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def _make_layer(self, block, planes, blocks, stride=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample))
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes))
return nn.Sequential(*layers)
def forward(self, x):
if self.dataset == 'cifar10' or self.dataset == 'cifar100':
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
elif self.dataset == 'imagenet':
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
4. Operación del proceso de visualización.
Aquí ingresamos una imagen de un gato:

Cuando se ejecuta el programa, podemos ver que la estructura de red de ResNet es la siguiente:
ResNet(
(conv1): Conv2d(3, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(layer1): Sequential(
(0): BasicBlock(
(conv1): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(1): BasicBlock(
(conv1): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer2): Sequential(
(0): BasicBlock(
(conv1): Conv2d(16, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(16, 32, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer3): Sequential(
(0): BasicBlock(
(conv1): Conv2d(32, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(32, 64, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(avgpool): AvgPool2d(kernel_size=8, stride=8, padding=0)
(fc): Linear(in_features=64, out_features=100, bias=True)
)
Luego se generará el proceso de procesamiento de imágenes de cada capa:
conv1 procesamiento de la primera capa:

Procesamiento de capas Relu:

Procesamiento de capa 1:
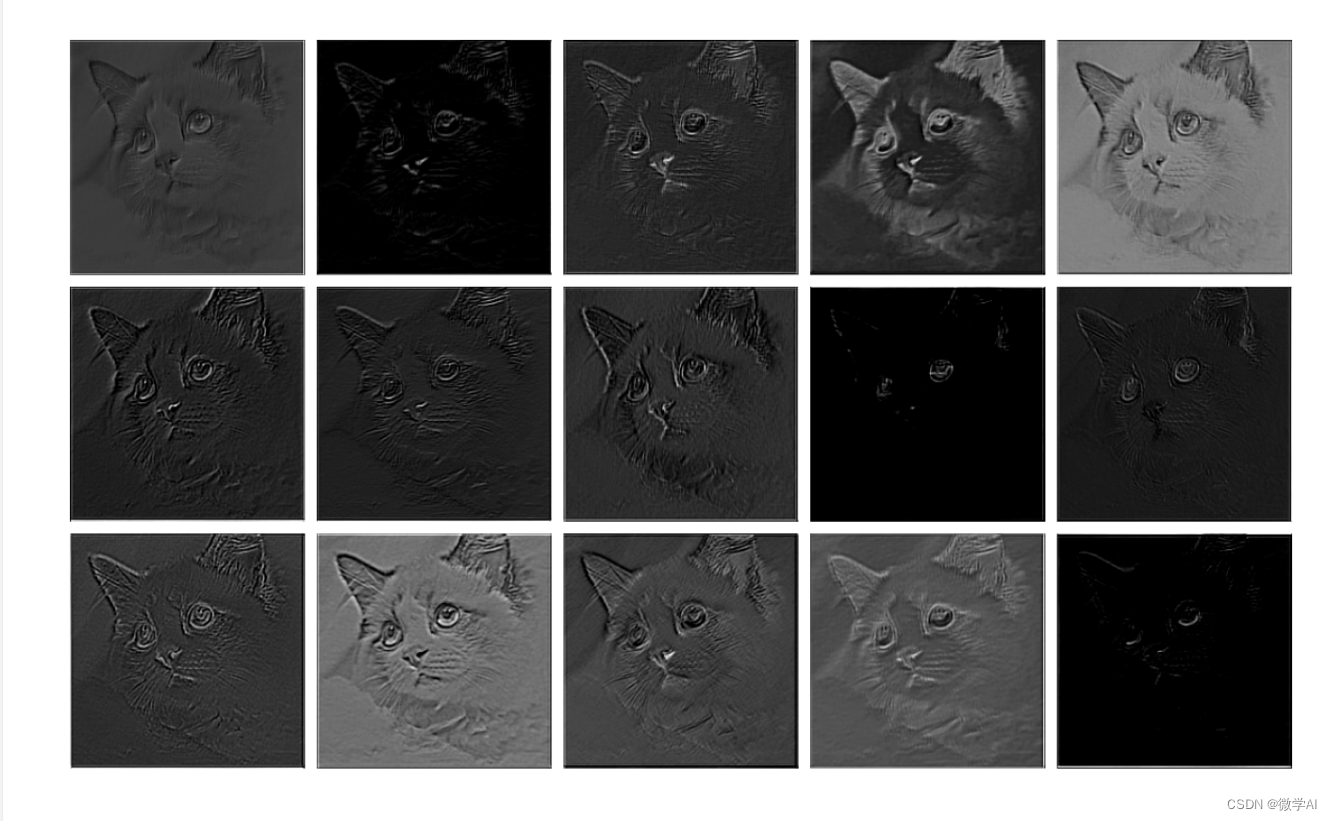
Procesamiento de capa 2:

Procesamiento de capa 3:
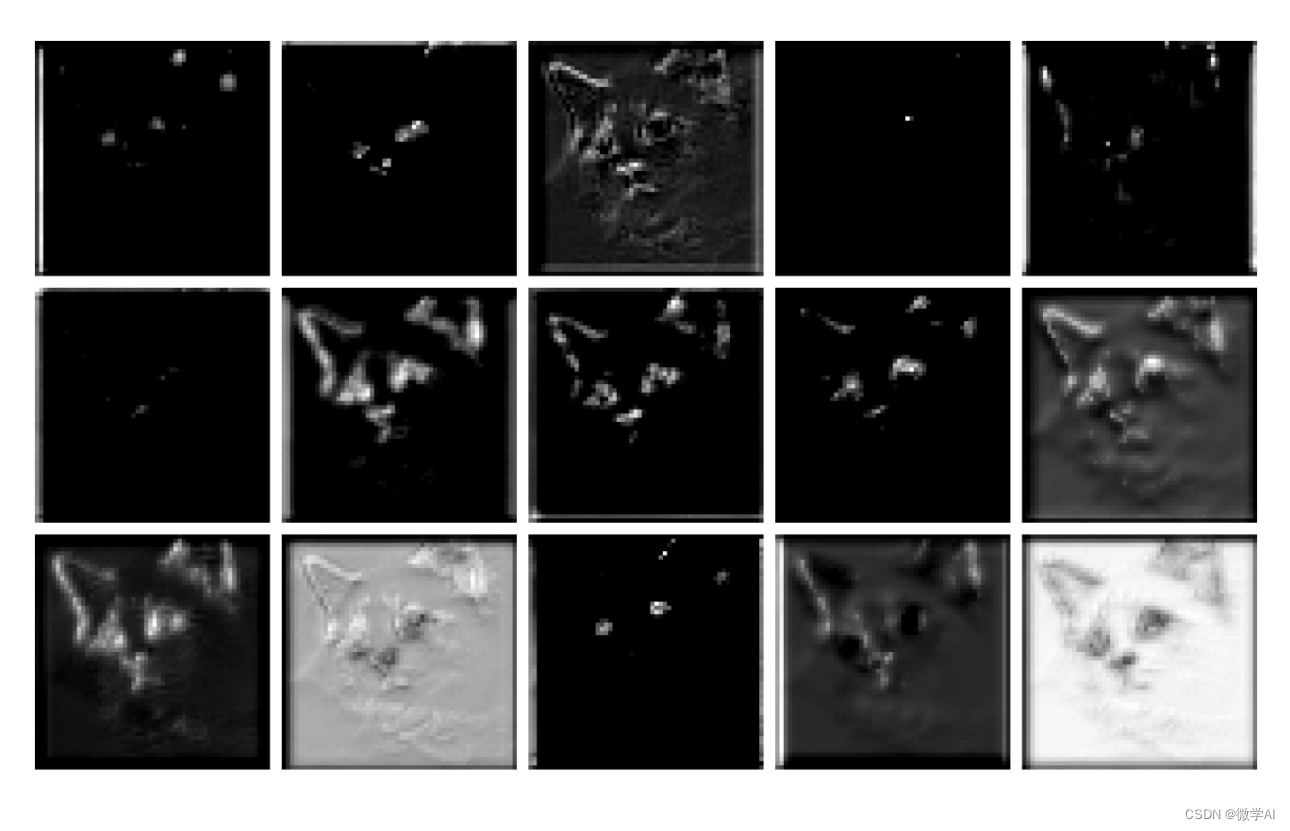
V. Resumen
La extracción de características de imagen en CNN es simular el principio de funcionamiento del sistema visual humano y extraer la representación de características de diferentes niveles de datos de entrada (como imágenes) capa por capa, para realizar un aprendizaje profundo y un análisis de los datos de entrada. A través de una estructura de múltiples capas compuesta por capas convolucionales, capas de agrupación y capas completamente conectadas, CNN puede aprender automáticamente características abstractas en los datos de entrada, desde características de bajo nivel (como bordes, texturas) hasta conceptos semánticos de nivel superior (como forma del objeto, color, textura, etc.). Esta expresión de características jerárquicas hace que CNN tenga un rendimiento excelente en diversas tareas de visión por computadora, como clasificación de imágenes, detección de objetivos, reconocimiento facial y generación de imágenes. En comparación con los métodos tradicionales de extracción manual de características, CNN no necesita diseñar características manualmente y puede aprender automáticamente la representación óptima de las características, lo que reduce en gran medida el costo de la intervención manual y tiene una mejor capacidad de generalización y solidez.