prefacio
He estado pensando durante mucho tiempo si publicar contenido de aprendizaje en profundidad. Después de todo, más de la mitad del contenido de aprendizaje automático en la columna de modelado matemático no se ha actualizado. Lo he considerado durante mucho tiempo y decidí subir. Con una serie de artículos sobre redes neuronales, de lo contrario, si las redes neuronales se utilizan en competencias de modelado matemático u otros modelos más optimizados en el futuro (como el uso de LSTM para la predicción de modelos de series de tiempo), entonces será mejor explicárselo a todos. Y explicó el principio. Sin embargo, el contenido del aprendizaje profundo no es tan fácil de dominar: contiene muchos conocimientos teóricos matemáticos y muchos principios de fórmulas de cálculo que requieren razonamiento. Y es difícil entender qué representa el código que escribimos en el marco informático de la red neuronal sin una operación real. Sin embargo, haré todo lo posible para simplificar el conocimiento y convertirlo en algo con lo que estemos más familiarizados. Haré todo lo posible para que todos comprendan y se familiaricen con el marco de la red neuronal, para garantizar una comprensión y una deducción fluidas. Trate de no utilizar demasiadas fórmulas matemáticas y conocimientos teóricos profesionales. Comprenda e implemente rápidamente el algoritmo en un artículo, domine este conocimiento de la manera más eficiente.
Aunque muchas competiciones no limitan el uso de marcos algorítmicos, cada vez más equipos galardonados utilizan algoritmos de aprendizaje profundo y los algoritmos tradicionales de aprendizaje automático están disminuyendo gradualmente. Por ejemplo, en la pregunta C de modelado matemático de estudiantes universitarios estadounidenses de 2022, el equipo de parámetros utilizó el equipo de la red de aprendizaje profundo y la proporción de victorias es muy alta. Ahora las competencias de inteligencia artificial y minería de datos están aumentando una tras otra, y la demanda de El conocimiento de las redes neuronales también está aumentando, por lo que es muy útil, es necesario dominar varios algoritmos de redes neuronales.
El blogger se ha centrado en el modelado durante cuatro años, ha participado en docenas de modelos matemáticos, grandes y pequeños, y comprende los principios de varios modelos, el proceso de modelado de cada modelo y varios métodos de análisis de temas. El propósito de esta columna es utilizar rápidamente varios modelos matemáticos, aprendizaje automático y aprendizaje profundo, y códigos con base cero. Cada artículo contiene proyectos prácticos y códigos ejecutables. Los blogueros se mantienen al día con todo tipo de competencias digitales y analógicas. Para cada competencia digital y analógica, los blogueros escribirán las últimas ideas y códigos en esta columna, así como ideas detalladas y códigos completos. Espero que los amigos necesitados no se pierdan la columna cuidadosamente creada por el autor.
capa de salida

Cuando las redes neuronales resuelven diferentes tipos de problemas, utilizan diferentes funciones de activación para adaptarse a las necesidades de la tarea. Para problemas de clasificación y regresión, elegimos diferentes estrategias para construir la red.
Primero, consideremos un problema de clasificación. En los problemas de clasificación, a menudo nos enfrentamos al desafío de separar datos en diferentes clases. Para problemas de clasificación binaria, esto significa que debemos dividir los datos en dos clases posibles. En este caso, elegimos utilizar la función sigmoidea como función de activación para la capa de salida. La función sigmoidea asigna valores de salida entre 0 y 1, lo que nos permite pensar en la salida como la probabilidad de una determinada clase.
Mientras que cuando tratamos problemas de clasificación múltiple, nuestro objetivo es dividir los datos en múltiples clases posibles. En este momento, utilizamos la función Softmax como función de activación de la capa de salida. La función Softmax convierte las puntuaciones brutas de cada categoría en una forma que representa la probabilidad de cada categoría. Esto nos permite determinar qué clase tiene más probabilidades de ser la clase correcta para una entrada determinada.
Sin embargo, en los problemas de regresión lo que nos interesa es predecir resultados numéricos continuos, no categorías discretas. En este caso, normalmente no utilizamos funciones de activación, porque queremos que la salida de la red tome cualquier valor real, para satisfacer las necesidades del problema.
En resumen, la selección de funciones de activación para redes neuronales en diferentes tipos de problemas depende de la naturaleza y los objetivos del problema. Al elegir una función de activación adecuada, podemos adaptar mejor la red a diferentes tipos de tareas.
1. Proceso de trabajo
Para facilitar la comprensión, todavía utilizamos un caso real para realizar una clasificación múltiple utilizando Softmax.
Un problema de clasificación múltiple, C = 4. La capa de salida final del modelo de clasificador lineal contiene cuatro valores de salida, que son:
Después del procesamiento de Softmax, el valor se transforma en la siguiente probabilidad:
Obviamente, según la probabilidad calculada, podemos encontrar fácilmente que S2 = 0,8390 corresponde a la probabilidad más alta. Softmax convierte valores continuos en probabilidades relativas, lo que favorece más nuestra comprensión. Por supuesto, si obtenemos [1000,1001,1002], obtendremos inf, si es [-1000,-999,-1000] o no, también obtendremos -inf.
En aplicaciones prácticas, se requiere algún procesamiento numérico en V: es decir, cada elemento en V resta el valor máximo en V.
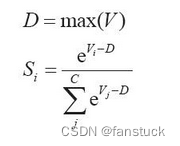
def _softmax(x):
c=np.max(x)
exp_x = np.exp(x-c)
return exp_x/np.sum(exp_x)
scores = np.array([123,456,789])
p = _softmax(scores)
print(p)El cálculo en forma numérica puede ser algo abstracto, así que tomemos la clasificación de imágenes como ejemplo:
Supongamos que dividimos a los gatos en la categoría 1, los perros en la categoría 2 y las gallinas en la categoría 3. Si no pertenecen a ninguna de las categorías anteriores, se clasifican como "otros". La primera imagen de izquierda a derecha es una gallina, entonces lo ponemos en la clase 3, y así sucesivamente:

Supongamos que ingresamos una imagen de un gato y su etiqueta real correspondiente es 0100 (la categoría se ha convertido a una forma de codificación one-hot).
El valor verdadero y es 1 y el resto son 0. Después del cálculo de Softmax ,
se obtiene el valor predicho y_predict. Suponiendo que el valor predicho lo sea,
es un vector que incluye la probabilidad de que la suma sea 1. En este caso, el valor neuronal Se calcula la red y el resultado nos dice que al gato se le asigna un valor de probabilidad del 20%. En términos generales, la red neuronal utiliza la categoría correspondiente a la neurona con el mayor valor de salida como resultado de reconocimiento, e incluso si se utiliza la función Softmax, solo cambiará el tamaño del valor pero no la posición de la neurona. Además, la operación de la función exponencial también requiere una cierta cantidad de tiempo, por lo que se puede considerar que la función Softmax se omite en el problema de clasificación múltiple.
2. La cantidad de neuronas en la capa de salida.
El número de neuronas en la capa de salida debe elegirse de acuerdo con los requisitos del problema a resolver. Cuando se trata de diferentes problemas, el número de neuronas en la capa de salida debe configurarse en consecuencia. Especialmente en problemas de clasificación, necesitamos determinar la cantidad de neuronas en la capa de salida de acuerdo con la cantidad de categorías. Tomando MNIST (reconocimiento de dígitos escritos a mano) como ejemplo, este es un problema de dividir dígitos escritos a mano en 10 categorías del 0 al 9, por lo que en la capa de salida configuraremos 10 neuronas, cada neurona corresponde a una categoría de dígitos.
Propagación hacia adelante basada en el conjunto de datos MNIST
El conjunto de datos MNIST (Instituto Nacional Modificado de Estándares y Tecnología) es un conjunto de datos clásico ampliamente utilizado en el campo de la visión por computadora para tareas de reconocimiento de dígitos escritos a mano. Este conjunto de datos fue creado por el Instituto Nacional de Estándares y Tecnología (NIST) y modificado para su uso en la investigación del aprendizaje automático.
El conjunto de datos MNIST contiene una serie de imágenes de dígitos escritos a mano, que cubren números del 0 al 9. Cada imagen tiene un tamaño de 28x28 píxeles y se presenta como una imagen en escala de grises. El conjunto de datos se divide en dos partes: conjunto de entrenamiento y conjunto de prueba.
Conjunto de entrenamiento: el conjunto de entrenamiento contiene 60.000 imágenes de dígitos escritos a mano y cada imagen tiene una etiqueta correspondiente que indica el dígito representado por la imagen. Estas imágenes y etiquetas se utilizan ampliamente para entrenar modelos de aprendizaje automático, especialmente para crear modelos de reconocimiento de dígitos escritos a mano.
Conjunto de prueba: el conjunto de prueba contiene 10.000 imágenes de dígitos escritos a mano, también con las etiquetas correspondientes. Estas imágenes se utilizan para evaluar el rendimiento del modelo entrenado en datos invisibles. A través de los resultados del conjunto de pruebas, se puede comprender la capacidad de generalización y la precisión del modelo.
Puedes descargarlo directamente a través de torch:
#MNIST dataset
train_dataset = dsets.MNIST(root = '/ml/pymnist', #选择数据的根目录
train = True, #选择训练集
transform = None, #不考#MNIST dataset
train_dataset = dsets.MNIST(root = '/ml/pymnist', #选择数据的根目录
train = True, #选择训练集
transform = None, #不考虑使用任何数据预处理
download = True #从网络上下载图片
)
test_dataset = dsets.MNIST(root = '/ml/pymnist',#选择数据的根目录
train = False,#选择测试集
transform = None, #不考虑使用任何数据预处理
download = True #从网络上下载图片
)虑使用任何数据预处理
download = True #从网络上下载图片
)
test_dataset = dsets.MNIST(root = '/ml/pymnist',#选择数据的根目录
train = False,#选择测试集
transform = None, #不考虑使用任何数据预处理
download = True #从网络上下载图片
)
En primer lugar, debemos inicializar la función init_network de la red, debemos configurar la variable Weight_scale para controlar el peso aleatorio y establecer el sesgo de manera uniforme en 1.
def init_network():
network={}
weight_scale=1e-3
network['W1']=np.random.randn(784,50)*weight_scale
network['b1']=np.ones(50)
network['W2']=np.random.randn(50,100)*weight_scale
network['b2']=np.ones(100)
network['W3']=np.random.randn(100,10)*weight_scale
network['b3']=np.ones(10)
return networkDespués de eso, se realiza el proceso de propagación hacia adelante y aquí se utiliza la función ReLU:
def _relu(x):
return np.maximum(0,x)
def forward(network,x):
w1,w2,w3 = network['W1'],network['W2'],network['W3']
b1,b2,b3 = network['b1'],network['b2'],network['b3']
a1 = x.dot(w1) + b1
z1 = _relu(a1)
a2 = z1.dot(w2) + b2
z2 = _relu(a2)
a3 = z2.dot(w3) + b3
y = a3
return yFinalmente calculamos el resultado final:
network = init_network()
accuracy_cnt = 0
x = test_dataset.test_data.numpy().reshape(-1,28*28)
labels = test_dataset.test_labels.numpy() #tensor转numpy
for i in range((len(x))):
y = forward(network,x[i])
p = np.argmax(y) #获取概率最高的元素的索引
if p == labels[i]:
accuracy_cnt += 1
print("Accuracy:"+ str(float(accuracy_cnt)/len(x)*100)+'%')![]()
Debido a que es el peso inicial, la probabilidad de acertar correctamente para 10 categorías es del 10%, sin embargo, debido a que solo nos propagamos hacia adelante y no hacia atrás, no todos los pesos de sesgo son óptimos. Luego, en el próximo capítulo, nos prepararemos para la propagación hacia atrás y describiremos en detalle el papel de la función de pérdida. En mi artículo anterior, básicamente expliqué todas las funciones de pérdida. Es muy detallado y perfecto. Le recomiendo que tenga la capacidad. para leerlo:
El próximo artículo se centrará en el uso y función de la función de pérdida en casos reales.