Vorwort
Ich habe lange darüber nachgedacht, ob ich ausführliche Lerninhalte veröffentlichen soll. Schließlich wurden mehr als die Hälfte der maschinellen Lerninhalte in der Spalte „Mathematische Modellierung“ nicht aktualisiert. Ich habe lange überlegt und beschlossen, darauf zu kommen mit einer Reihe von Artikeln über neuronale Netze. Andernfalls ist es besser, es allen zu erklären, wenn neuronale Netze in Zukunft in mathematischen Modellierungswettbewerben oder anderen optimierteren Modellen verwendet werden (z. B. die Verwendung von LSTM für die Vorhersage von Zeitreihenmodellen). Und das Prinzip erklärt. Der Inhalt des Deep Learning ist jedoch nicht so einfach zu beherrschen: Er enthält viel mathematisch-theoretisches Wissen und viele Berechnungsformelprinzipien, die eine Begründung erfordern. Und ohne tatsächlichen Betrieb ist es schwierig zu verstehen, was der von uns geschriebene Code im neuronalen Netzwerk-Computing-Framework darstellt. Ich werde jedoch mein Bestes geben, um das Wissen zu vereinfachen und in etwas umzuwandeln, mit dem wir besser vertraut sind. Ich werde mein Bestes geben, damit jeder das neuronale Netzwerk-Framework versteht und mit ihm vertraut ist, um ein reibungsloses Verständnis und reibungslose Schlussfolgerungen zu gewährleisten. Versuchen Sie, nicht zu viele mathematische Formeln und professionelles theoretisches Wissen zu verwenden. Verstehen und implementieren Sie den Algorithmus schnell in einem Artikel und beherrschen Sie dieses Wissen auf die effizienteste Weise.
Obwohl viele Wettbewerbe die Verwendung von Algorithmus-Frameworks nicht einschränken, verwenden immer mehr preisgekrönte Teams Deep-Learning-Algorithmen, und traditionelle Algorithmen für maschinelles Lernen verlieren allmählich an Bedeutung. Beispielsweise nutzte das Parameterteam bei der Frage C zur mathematischen Modellierung amerikanischer College-Studenten im Jahr 2022 das Deep-Learning-Netzwerkteam, und die Gewinnquote ist sehr hoch. Jetzt nehmen Wettbewerbe für künstliche Intelligenz und Data-Mining nacheinander zu und die Nachfrage danach Das Wissen über neuronale Netze nimmt ebenfalls zu und ist daher sehr nützlich. Es ist notwendig, verschiedene Algorithmen für neuronale Netze zu beherrschen.
Der Blogger konzentriert sich seit vier Jahren auf die Modellierung, hat an Dutzenden großen und kleinen mathematischen Modellen teilgenommen und versteht die Prinzipien verschiedener Modelle, den Modellierungsprozess jedes Modells und verschiedene Themenanalysemethoden. Der Zweck dieser Kolumne besteht darin, schnell verschiedene mathematische Modelle, maschinelles Lernen und tiefes Lernen sowie Codes ohne Grundlage zu verwenden. Jeder Artikel enthält praktische Projekte und ausführbare Codes. Blogger halten sich über alle Arten von digitalen und analogen Wettbewerben auf dem Laufenden. Zu jedem digitalen und analogen Wettbewerb schreiben Blogger in dieser Kolumne die neuesten Ideen und Codes sowie detaillierte Ideen und vollständige Codes. Ich hoffe, dass Freunde in Not die vom Autor sorgfältig erstellte Kolumne nicht verpassen werden.
Hier gibt es keinen neuen Artikel zur Verlustfunktion, da es bereits einen Artikel gibt, der alle Verlustfunktionsformen sowie Implementierungscodes und -funktionen im Detail beschreibt.
Oder erwähnen Sie es einfach, um alle zu beeindrucken. Die Verlustfunktion wird verwendet, um die Differenz oder den Fehler zwischen dem tatsächlichen Wert und dem vorhergesagten Wert an der aktuellen Position zu messen, was die Wirksamkeit einiger Modelle verbessert. Durch die Bereitstellung von Feedback an das Modell kann es angepasst werden Parameter, um Fehler zu minimieren.
Wenn wir ein neuronales Netzwerk trainieren, verwenden wir eine Verlustfunktion, um den Abstand zwischen der Vorhersage des Modells und dem wahren Wert zu messen. Diese Lücke wird oft als Fehler oder Verlust bezeichnet. Unser Ziel ist es, den Wert der Verlustfunktion durch Anpassen der Gewichte und Parameter des Modells zu minimieren. Mit anderen Worten: Wir versuchen, eine Reihe von Gewichtungen und Parametern zu finden, damit die Vorhersagen des Modells so nah wie möglich am wahren Wert liegen.
Je kleiner der Wert der Verlustfunktion ist, desto geringer ist der Unterschied zwischen der Vorhersage des Modells und den tatsächlichen Daten und desto besser ist die Leistung des Modells. Der Optimierungsprozess besteht darin, die Gewichte und Parameter des Modells durch Methoden wie Backpropagation und Gradientenabstieg schrittweise anzupassen, um den Wert der Verlustfunktion zu verringern.
1. Zufällige Initialisierung
Die Methode der zufälligen Initialisierung sollte leicht zu verstehen sein. Wir können zu Beginn viele verschiedene Gewichte zufällig ausprobieren und dann sehen, welcher Gewichtssatz am besten funktioniert. Obwohl es dumm klingt, ist es wirklich dumm. Dies ist nur eine Einführung. In Üben Sie diesen Ansatz nicht:
accuracy_cnt=0
batch_size=100
x = test_dataset.test_data.numpy().reshape(-1,28*28)
labels = test_dataset.test_labels
finallabels = labels.reshape(labels.shape[0],1)
bestloss = float('inf')
for i in range(0,int(len(x)),batch_size):
network = init_network()
x_batch = x[i:i+batch_size]
y_batch = forward(network,x_batch)
one_hot_labels = torch.zeros(batch_size,10).scatter_(1,finallabels[i:i+batch_size],1)
loss = cross_entropy_error(one_hot_labels.numpy(),y_batch)
if loss < bestloss:
bestloss = loss
bestw1,bestw2,bestw3 = network['W1'],network['W2'],network['W3']
print("best loss: is %f" %(bestloss))Dann werfen wir einen Blick auf den Effekt der Genauigkeit:

a1=x.dot(bestw1)
z1=_relu(a1)
a2=z1.dot(bestw2)
z2=_relu(a2)
a3=z2.dot(bestw3)
y=_softmax(a3)
print(y)
#找到在每列中评分最大的索引
Yte_predict=np.argmax(y,axis=1)
one_hot_labels=torch.zeros(x.shape[0],10).scatter_(1,finallabels,1)
true_labels=np.argmax(one_hot_labels.numpy(),axis=1)
#计算准确率
print(np.mean(Yte_predict==true_labels))Die endgültige Ausgabe ist:
0,0948
Es ist fast normal und die Wahrscheinlichkeit, es zu erraten, ist gleich.
2. Gradientenabstiegsmethode
Vor der Gradientenabstiegsmethode hatte ich einen Artikel über diesen Optimierungsalgorithmus. Ich habe ihn auch verwendet, als ich zuvor den Algorithmus der logistischen Regression geschrieben habe. Wenn Sie mehr darüber erfahren möchten, wird empfohlen, ihn sorgfältig zu lesen. Dieser Artikel beschreibt nur Im Detail den Gradienten bei der Rückausbreitung. Die funktionale Funktion des Abstiegsalgorithmus:
Auch das Lernen neuronaler Netze erfordert Gradienten. Die Gradienten stellen hier die Gradienten von Gewichten und Offsets (Bias) in der Verlustfunktion dar. Bei einem neuronalen Netzwerk mit einer Form von 2*2 und einem Gewicht von W wird die Verlustfunktion beispielsweise durch L dargestellt:
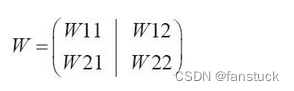
Sein Gradient wird ausgedrückt als:

Die Elemente von bestehen aus den partiellen Ableitungen jedes Elements nach W. Für jede partielle Ableitung bedeutet dies, wie stark sich die Verlustfunktion L ändert, wenn sich jedes W geringfügig ändert.
#基于数值微分的梯度下降法
def numerical_gradient(f,x):
h = 1e-4 #0.0001
grad = np.zeros_like(x)
it = np.nditer(x,flags=['multi_index'],op_flags=['readwrite'])
while not it.finished:
idx = it.multi_index
tmp_val = x[idx]
x[idx] = float(tmp_val)+h
fxh1 = f(x) #f(x+h)
x[idx] = tmp_val-h
fxh2 = f(x) #f(x-h)
grad[idx] = (fxh1 - fxh2) / (2*h)
x[idx] = tmp_val #还原值
it.iternext()
return gradNach dem ersten Zurücksetzen des Gewichtsdatensatzes lautet der Gewichtssatz unter Verwendung des Gradientenabstiegsalgorithmus:

Verlustfunktionswert:

Wenn wir den Gradientenabstiegsalgorithmus und das Funktionsprinzip kennen, können wir mit der Erforschung der Rückausbreitung beginnen.