Directorio de artículos
12: Uso de la programación de tiempos
-
Objetivo : dominar el uso de la programación temporal
-
implementar
-
http://airflow.apache.org/docs/apache-airflow/stable/dag-run.html
-
Método 1: incorporado
with DAG( dag_id='example_branch_operator', default_args=args, start_date=days_ago(2), schedule_interval="@daily", tags=['example', 'example2'], ) as dag: -
Método 2: objeto datetime.timedelta
timedelta(minutes=1) timedelta(hours=3) timedelta(days=1)with DAG( dag_id='latest_only', schedule_interval=dt.timedelta(hours=4), start_date=days_ago(2), tags=['example2', 'example3'], ) as dag: -
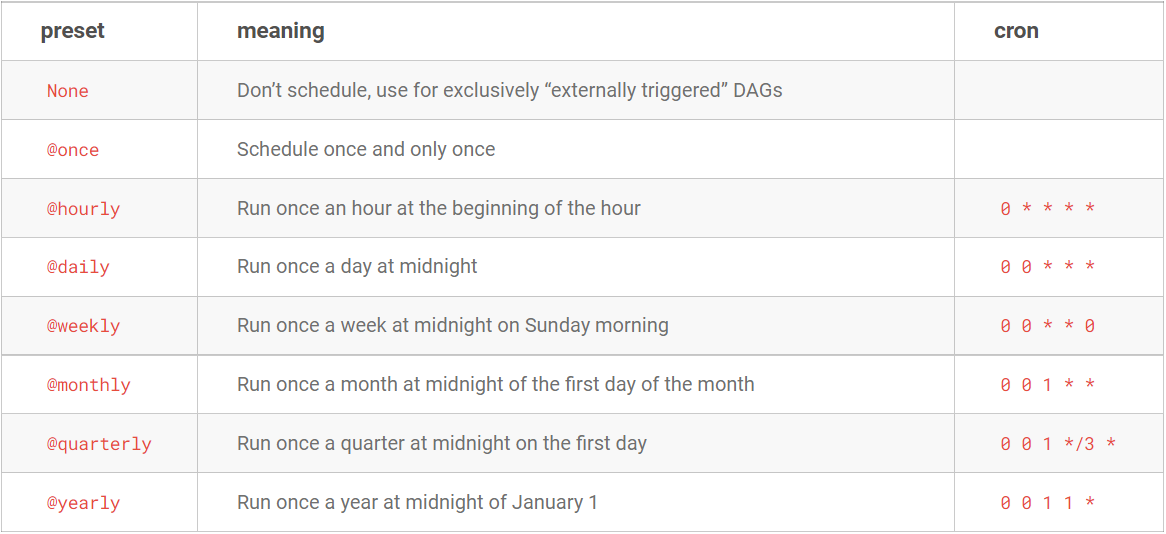
Método 3: expresión crontab
-
Consistente con el uso de Linux Crontab
with DAG( dag_id='example_branch_dop_operator_v3', schedule_interval='*/1 * * * *', start_date=days_ago(2), default_args=args, tags=['example'], ) as dag:分钟 小时 日 月 周 00 00 * * * 05 12 1 * * 30 8 * * 4
-
-
-
resumen
- Dominar el uso de la programación temporal
13: Comandos comunes de flujo de aire
-
Objetivo : comprender los comandos comunes de AirFlow
-
implementar
-
Listar todos los días actuales
airflow dags list -
Pausar un DAG
airflow dags pause dag_name -
Iniciar un DAG
airflow dags unpause dag_name -
Eliminar un DAG
airflow dags delete dag_name -
ejecutar un DAG
airflow dags trigger dag_name -
Ver el estado de un DAG
airflow dags state dag_name -
Listar todas las tareas de un DAG
airflow tasks list dag_name
-
-
resumen
- Comprender los comandos comunes de AirFlow
14: Uso de alertas por correo electrónico
-
Objetivo : comprender cómo implementar alertas por correo electrónico en AirFlow
-
camino
- paso 1: configuración de flujo de aire
- paso 2: configuración DAG
-
implementar
-
Principio: El principio del envío automático de correos electrónicos: servicio de correo electrónico de terceros
-
Cuenta del remitente: configurada en el archivo de configuración
smtp_user = [email protected] # 秘钥id:需要自己在第三方后台生成 smtp_password = 自己生成的秘钥 # 端口 smtp_port = 25 # 发送邮件的邮箱 smtp_mail_from = [email protected] -
Cuenta receptora: configurada en el programa
default_args = { 'owner': 'airflow', 'email': ['[email protected]'], 'email_on_failure': True, 'email_on_retry': True, 'retries': 1, 'retry_delay': timedelta(minutes=1), }
-
-
Implementación de AirFlow: airflow.cfg
# 发送邮件的代理服务器地址及认证:每个公司都不一样 smtp_host = smtp.163.com smtp_starttls = True smtp_ssl = False # 发送邮件的账号 smtp_user = [email protected] # 秘钥id:需要自己在第三方后台生成 smtp_password = 自己生成的秘钥 # 端口 smtp_port = 25 # 发送邮件的邮箱 smtp_mail_from = [email protected] # 超时时间 smtp_timeout = 30 # 重试次数 smtp_retry_limit = 5 -
Cerrar flujo de aire
# 统一杀掉airflow的相关服务进程命令 ps -ef|egrep 'scheduler|flower|worker|airflow-webserver'|grep -v grep|awk '{print $2}'|xargs kill -9 # 下一次启动之前 rm -f /root/airflow/airflow-* -
configuración del programa
default_args = { 'email': ['[email protected]'], 'email_on_failure': True, 'email_on_retry': True } -
Iniciar flujo de aire
airflow webserver -D airflow scheduler -D airflow celery flower -D airflow celery worker -D -
error simulado
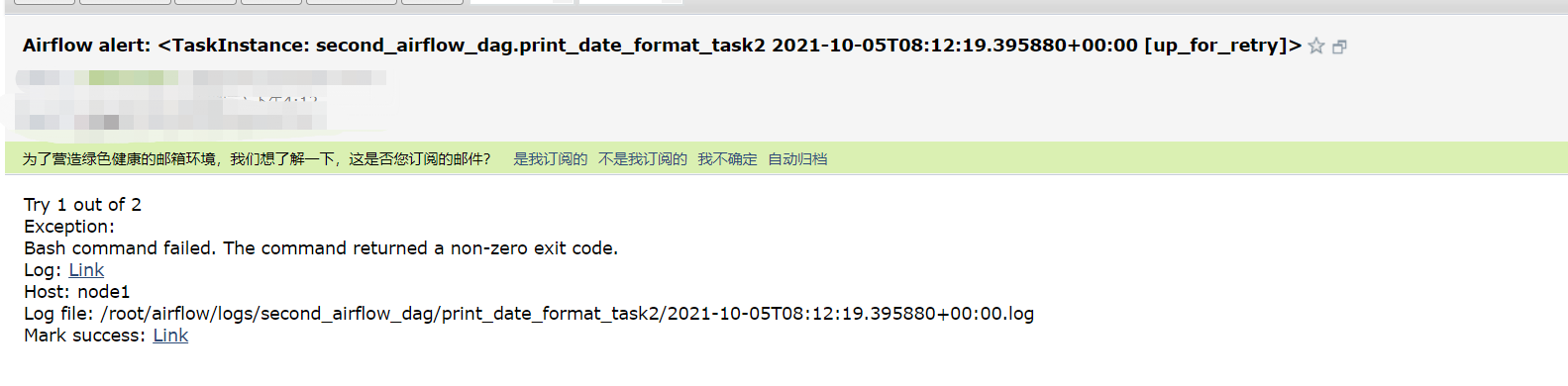
-
-
resumen
- Aprenda cómo implementar alertas por correo electrónico en AirFlow
15: Programación en fabricación integral
-
Objetivo : comprender la implementación de la programación en la fabricación integral.
-
implementar
- Capa ODS/capa DWD: programación de tiempo: comienza a funcionar a las 00:05 todos los días
- dws(11)
- dws tarda 1 hora
- Ejecutado desde la 1:30 am
- dwb(16)
- dwb tardó 1,5 horas
- La ejecución comienza a las 3:00 a.m.
- punto(10)
- st tarda 1 hora
- Ejecutado desde las 4:30 a.m.
- dm(1)
- dm tarda 0,5 horas
- Ejecutado desde las 5:30 a.m.
-
resumen
- Comprender la implementación de la programación en la fabricación integral
16: Revisión: conceptos básicos de Spark
-
¿Qué es la computación distribuida?
- Programas distribuidos: programas MapReduce, Spark, Flink
- Multiproceso: un programa es implementado por múltiples procesos y diferentes procesos pueden ejecutarse en diferentes máquinas.
- Los datos que cada proceso se encarga de calcular son diferentes y son una parte determinada de los datos generales.
- Programas desarrollados por mí basados en MapReduce o Spark API: lógica de procesamiento de datos
- Lógica dividida
- SEÑOR
- Proceso MapTask: reglas de fragmentación: cálculo basado en datos procesados
- Juicio: tamaño de archivo / 128M > 1.1
- Mayor que: según cada 128M puntos
- Menos de: entero como 1 fragmento
- Archivos grandes: cada 128 M como fragmento
- Un fragmento corresponde a una MapTask
- Juicio: tamaño de archivo / 128M > 1.1
- Proceso ReduceTask: especificado
- Proceso MapTask: reglas de fragmentación: cálculo basado en datos procesados
- Chispa - chispear
- Ejecutor: Especificar
- Recursos distribuidos: YARN, contenedor de recursos independiente
- Fusionar lógicamente los recursos físicos de varias máquinas: CPU, memoria y disco en un todo
- HILO: Administrador de recursos, Administrador de nodos 【8 núcleos 8 GB】
- Cada NM gestiona los recursos de cada máquina.
- RM gestiona todos los NM
- Independiente: Maestro, Trabajador
- Implemente una gestión unificada de recursos de hardware: MR, Flink, Spark en YARN
- Programas distribuidos: programas MapReduce, Spark, Flink
-
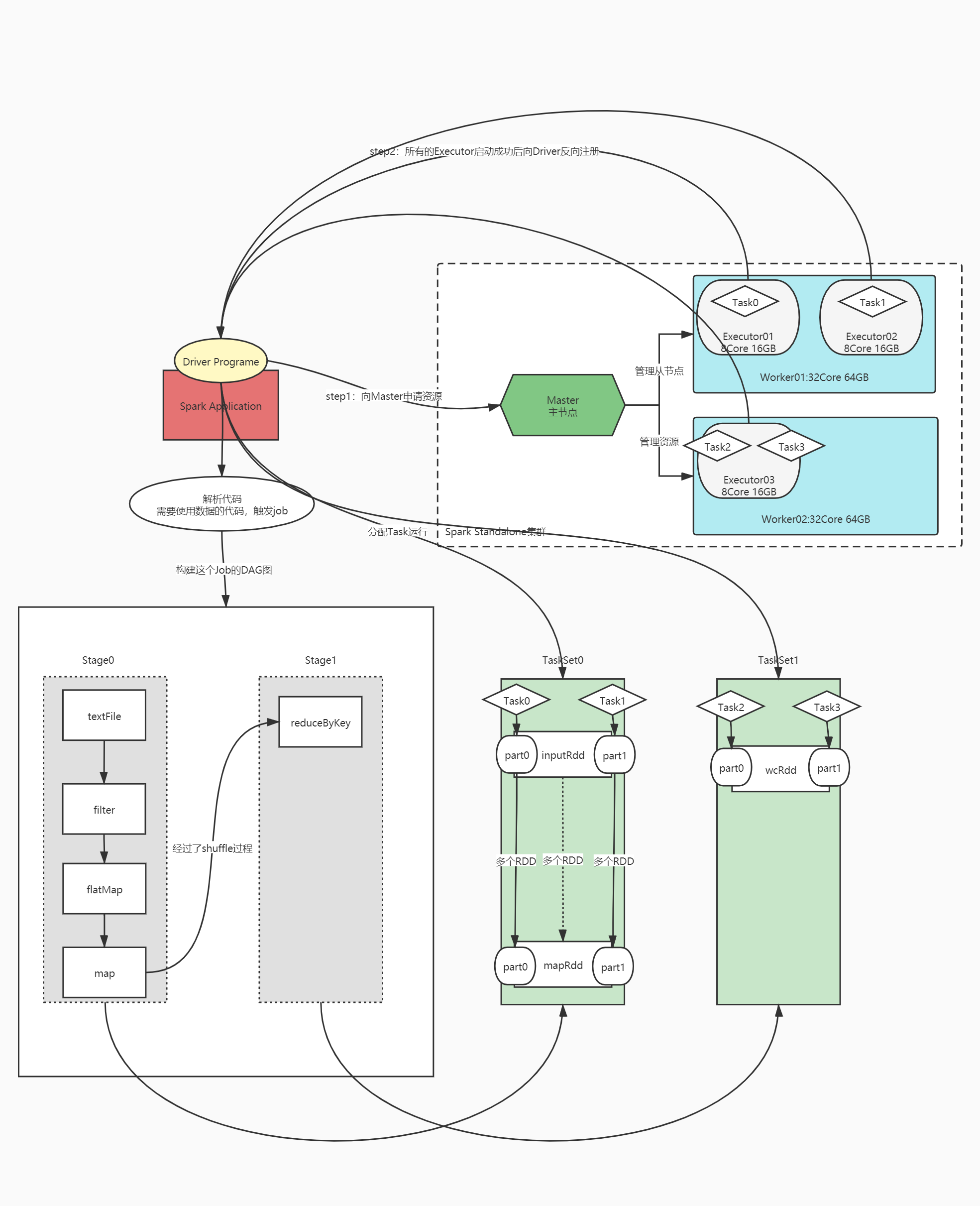
¿Cuál es la estructura de un programa Spark?
- Programa de aplicación
- Proceso: un conductor, múltiples ejecutores
- Ejecutar: múltiples trabajos, múltiples etapas, múltiples tareas
-
¿Qué es independiente?
- La propia plataforma de gestión de recursos del clúster de Spark
-
¿Por qué utilizar Spark en YARN?
- Para lograr una gestión unificada de recursos, todos los programas se envían a YARN para su ejecución.
-
¿Qué son los amos y los trabajadores?
- Arquitectura distribuida maestro-esclavo: Hadoop, Hbase, Kafka, Spark...
- Maestro: Gestión Nodo: Maestro
- Servicio al Cliente
- Administrar nodos esclavos
- gestionar todos los recursos
- De: Nodo de cálculo: Trabajador
- Responsable de realizar las tareas asignadas por el nodo maestro.
- Maestro: Gestión Nodo: Maestro
- Arquitectura distribuida maestro-esclavo: Hadoop, Hbase, Kafka, Spark...
-
¿Qué son el conductor y el ejecutor?
-
Paso 1: iniciar la plataforma de recursos distribuidos
-
Paso 2: desarrollar un programa informático distribuido
sc = SparkContext(conf) # step1:读取数据 inputRdd = sc.textFile(hdfs_path) #step2:转换数据 wcRdd = inputRdd.filter.map.flatMap.reduceByKey #step3:保存结果 wcRdd.foreach sc.stop -
Paso 3: envíe el programa distribuido al clúster de recursos distribuidos para su ejecución
spark-submit xxx.py executor个数和资源 driver资源配置 -
Inicie el proceso del controlador primero
- Solicite recursos: inicie el proceso informático del Ejecutor
- El controlador comienza a analizar el código para determinar si cada oración de código genera un trabajo
-
Luego inicie el proceso Ejecutor: ejecútelo en el nodo Trabajador de acuerdo con la configuración del recurso
- Todos los Ejecutores se registran de forma inversa con el Conductor y esperan a que el Conductor asigne Tareas
-
-
¿Cómo surgieron los trabajos?
- Cuando se utilizan los datos en RDD, se activará la generación de Trabajo: todas las funciones que utilizan datos RDD se denominan operadores de activación
- El componente DAGScheduler crea un gráfico DAG para el trabajo actual según el código
-
¿Cómo se genera DAG?
- Algoritmo: retroceso Algoritmo: retroceso
- Durante el proceso de construcción de DAG, coloque a cada operador en el escenario y construya un nuevo escenario si se encuentra un operador muy dependiente.
- División de etapas: amplia dependencia
- Ejecutar etapa: comience a ejecutar de acuerdo con el número de etapa más pequeño
- Convierta cada etapa en un TaskSet: colección de tareas
-
¿Cómo determinar el número de tareas?
- Una CPU central = una tarea = una partición
- Hay varias tareas en el conjunto de tareas convertidas desde una etapa: determinadas por el número máximo de particiones en el RDD en la etapa
-
¿Cuántos tipos de operadores Spark existen?
- Transformación: Transformación
- valor de retorno: RDD
- Es un modo diferido y no activará la generación de empleo.
- mapa, mapa plano
- Desencadenante: Acción
- Valor de retorno: no RDD
- Activar la generación de empleo
- contar, primero
- Transformación: Transformación