
Este es un artículo invitado de Nan Zhu, director técnico principal de SafeGraph, y Dave Thibault, arquitecto sénior de soluciones de Amazon Cloud Technologies.
SafeGraph es una empresa de datos geoespaciales que gestiona más de 41 millones de puntos de interés (POI) en todo el mundo y proporciona detalles sobre afiliación de marca, etiquetas de categorías avanzadas, horarios de apertura y cómo las personas interactúan con estos lugares. Utilizamos Apache Spark como motor principal de procesamiento de datos y más de 1000 aplicaciones Spark ejecutan cantidades masivas de datos todos los días. Estas aplicaciones Spark implementan nuestra lógica empresarial, incluida una amplia gama de aplicaciones como transformación de datos, inferencia de modelos de aprendizaje automático (ML) y tareas operativas.
SafeGraph descubrió que el entorno Spark de su proveedor Spark existente no era ideal. Sus costos siguen aumentando. Cuando finaliza una instancia de spot, sus trabajos se reintentan con frecuencia. Los desarrolladores dedican demasiado tiempo a solucionar problemas y cambiar configuraciones de trabajo, y no suficiente tiempo a desarrollar código de valor comercial. SafeGraph necesitaba controlar los costos, aumentar la velocidad de iteración del desarrollador y mejorar la confiabilidad del trabajo. Al final, SafeGraph eligió Amazon EMR en Amazon EKS para sus necesidades, ahorrando un 50 % en costos en comparación con su anterior proveedor de hosting Spark.
Los llamados "trabajadores primero deben perfeccionar sus herramientas si quieren ser buenos en su trabajo". Al crear aplicaciones Spark para productos, la plataforma Spark es esta "herramienta". La siguiente figura muestra el flujo de trabajo de diseño de ingeniería cuando se usa Spark, y la plataforma Spark necesita admitir y optimizar cada operación en el flujo de trabajo. Los ingenieros normalmente cierran el círculo escribiendo y creando código de aplicación Spark, enviando la aplicación a la infraestructura informática y finalmente depurando la aplicación Spark. Además, los equipos de plataforma e infraestructura necesitan operar y optimizar continuamente los tres pasos del flujo de trabajo del diseño de ingeniería.
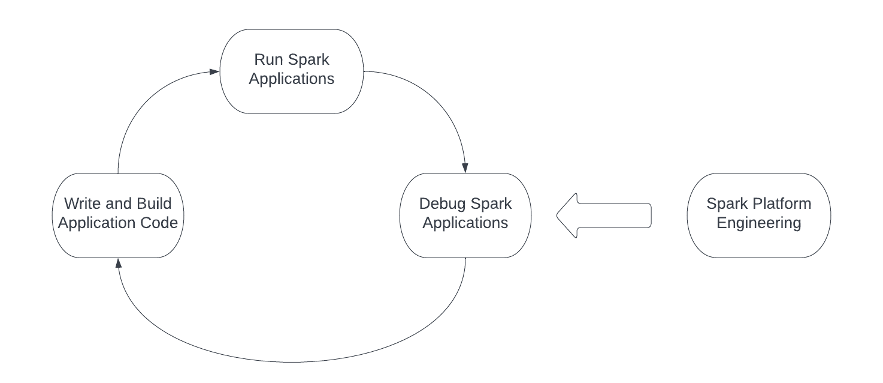
Al construir la plataforma Spark, cada operación implica varios desafíos:
Gestión sólida de dependencias : las aplicaciones Spark complejas a menudo introducen muchas dependencias. Para ejecutar una aplicación Spark, necesitamos identificar todas las dependencias, resolver cualquier conflicto, empaquetar de manera confiable las bibliotecas dependientes y transferirlas al clúster de Spark. La gestión de dependencias es uno de los mayores desafíos que enfrentan los ingenieros, especialmente cuando trabajan con aplicaciones PySpark.
Infraestructura informática confiable : la infraestructura informática que aloja las aplicaciones Spark debe ser confiable, que es la base de toda la plataforma Spark. El aprovisionamiento inestable de recursos no solo afecta negativamente la productividad de la ingeniería, sino que también aumenta los costos de infraestructura debido a la repetición de aplicaciones Spark.
Herramientas de depuración convenientes para aplicaciones Spark : las herramientas de depuración son fundamentales para que los ingenieros puedan iterar rápidamente en aplicaciones Spark. El acceso de alto rendimiento al Spark History Server (SHS, Spark History Server) es una condición necesaria para aumentar la velocidad de iteración de los desarrolladores. Por el contrario, un rendimiento deficiente de SHS ralentiza a los desarrolladores y aumenta el coste de venta de productos para las empresas de software.
Infraestructura Spark manejable : la ingeniería exitosa de la plataforma Spark implica muchos aspectos, como la administración de versiones de distribución de Spark, la administración y optimización de SKU de recursos informáticos, etc. Mucho depende de si el proveedor de servicios Spark proporciona una capa subyacente adecuada para que la utilice el equipo de la plataforma. Por ejemplo, la abstracción incorrecta de las versiones de distribución y los recursos informáticos puede reducir significativamente el ROI de la ingeniería de plataformas.
SafeGraph cumplió con todos los desafíos anteriores. Para abordar estos problemas, exploramos el mercado y descubrimos que construir nuestra nueva plataforma Spark en Amazon EMR en Amazon EKS era un enfoque que podía abordar los obstáculos que enfrentamos. En esta publicación, compartimos nuestro viaje para construir la última plataforma Spark y cómo EMR en EKS proporciona una base poderosa y eficiente para este viaje.
Gestión sólida de dependencias de Python
Uno de los mayores desafíos que enfrentan los usuarios al escribir y crear código de aplicación Spark es la dificultad de administrar dependencias de manera confiable, especialmente para las aplicaciones PySpark. La mayoría de nuestras aplicaciones Spark relacionadas con el aprendizaje automático se crean utilizando PySpark. Los proveedores de servicios Spark anteriores solo admitían una forma de administrar las dependencias de Python: utilizar archivos wheel. A pesar de su uso generalizado, la gestión de la dependencia basada en ruedas es frágil. El siguiente diagrama muestra los dos tipos de problemas de confiabilidad que enfrenta la gestión de dependencias basada en ruedas:
Dependencias directas no fijadas : si el archivo .whl no puede determinar la versión de una dependencia directa (Pandas en este ejemplo), siempre extraerá la última versión del flujo ascendente, que puede contener cambios importantes y hacer que Spark aplique el programa interrumpido.
Dependencias transitivas no fijadas : el segundo tipo de problema de confiabilidad está más fuera de nuestro control. Incluso si arreglamos la versión de dependencia directa al crear el archivo .whl, es posible que la dependencia directa en sí misma no pueda determinar la versión de dependencia transitiva (MLFlow en este caso). En este caso, las dependencias directas siempre extraerán las últimas versiones de estas dependencias transitivas, que pueden contener cambios importantes y potencialmente interrumpir la canalización.
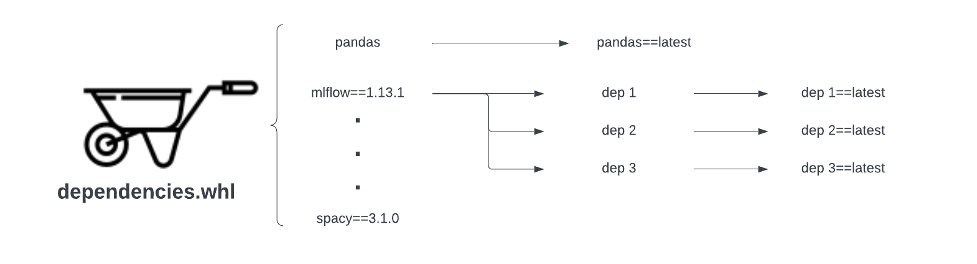
Otro problema que encontramos fue que todos los paquetes de Python a los que hace referencia el archivo wheel se instalaban innecesariamente cada vez que se inicializaba la aplicación Spark. En nuestra configuración anterior, era necesario ejecutar un script de instalación al inicio para instalar el archivo wheel para cada aplicación Spark, incluso si las dependencias no cambiaban. Esta instalación aumentó el tiempo de inicio de la aplicación Spark de 3 a 4 minutos a al menos 7 a 8 minutos. Este ritmo lento es muy perjudicial para la experiencia, especialmente cuando nuestros ingenieros están iterando cambios activamente.
Al migrar a EMR en EKS, pudimos usar pex (ejecutable de Python) para administrar las dependencias de Python. Los archivos .pex empaquetan todas las dependencias (tanto directas como transitivas) de una aplicación PySpark en un entorno ejecutable de Python, teniendo en cuenta el entorno virtual.
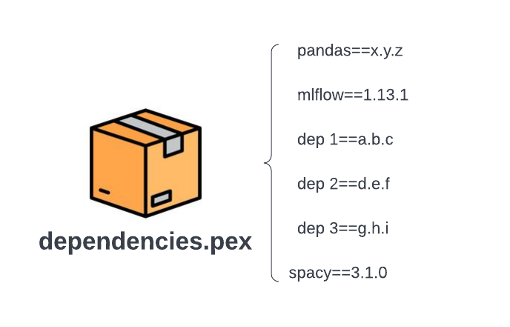
La siguiente figura muestra la estructura del archivo después de convertir el archivo de rueda en la figura anterior a un archivo .pex. En comparación con los flujos de trabajo basados en ruedas, ya no tenemos extracciones de dependencia transitivas ni recuperación automática de la última versión. Al crear un archivo .pex, todas las versiones de las dependencias se fijan en xyz, abc, etc. Para un archivo .pex determinado, todas las dependencias se fijan para que ya no experimentemos lentitud o fragilidad en la gestión de dependencias basada en ruedas. El costo de crear el archivo .pex también es un costo único.
Aprovisionamiento de recursos confiable y eficiente
El aprovisionamiento de recursos es el proceso mediante el cual la plataforma Spark obtiene recursos informáticos para las aplicaciones Spark y es la base de toda la plataforma Spark. La optimización de costos con Spot Instances hace que el aprovisionamiento de recursos sea más desafiante al crear la plataforma Spark en la nube. Las instancias puntuales son capacidad informática adicional disponible para usted, lo que le permite ahorrar hasta un 90 % en comparación con los precios bajo demanda. Sin embargo, cuando hay un aumento repentino en la demanda de ciertos tipos de instancias, las Instancias Spot pueden cancelarse para priorizar el cumplimiento de esa demanda. Debido a estas terminaciones, encontramos algunos desafíos en versiones anteriores de la plataforma Spark:
Aplicación Spark no confiable : cuando se finaliza una instancia de Spot, el tiempo de ejecución de la aplicación Spark aumenta significativamente debido a la fase de reintento de cálculo.
Mala experiencia del desarrollador : el estado de aprovisionamiento inestable de las instancias puntuales generó un rendimiento impredecible y bajas tasas de éxito para las aplicaciones Spark, lo que afectó seriamente la experiencia del ingeniero y ralentizó las iteraciones de desarrollo.
Facturas de infraestructura costosas : nuestras facturas de infraestructura en la nube aumentaron significativamente debido a los reintentos de trabajo. Para aliviar el problema, tuvimos que comprar costosas instancias de Amazon Elastic Compute Cloud (Amazon EC2) con mayor capacidad y ejecutándose en múltiples zonas de disponibilidad, lo que a su vez generó altos costos para el tráfico entre zonas de disponibilidad.
El proveedor de servicios Spark (SSP, proveedor de servicios Spark), como EMR en EKS u otros productos de software de terceros, es el intermediario entre los usuarios y los grupos de instancias de Spot y desempeña un papel clave para garantizar un suministro suficiente de instancias de Spot. Como se muestra en la figura siguiente, un usuario inicia un trabajo de Spark utilizando un orquestador de trabajos, un cuaderno o un servicio a través de SSP. Los SSP implementan su propia funcionalidad interna para acceder a instancias no utilizadas desde grupos de instancias puntuales en servicios en la nube como Amazon Web Services. Una de las mejores prácticas para utilizar instancias de spot es utilizar una variedad de tipos de instancias (para obtener más información, consulte Optimización de costos con instancias de spot EC2: https://aws.github.io/aws-emr-containers-best-practices/ optimización de costos/docs/optimización de costos/). Específicamente, SSP permite la diversificación de instancias a través de dos funciones clave:
El SSP debe tener acceso a todos los tipos de instancias en los grupos de instancias puntuales de AWS.
SSP debe brindar a los usuarios la capacidad de utilizar tantos tipos de instancias como sea posible al iniciar una aplicación Spark.
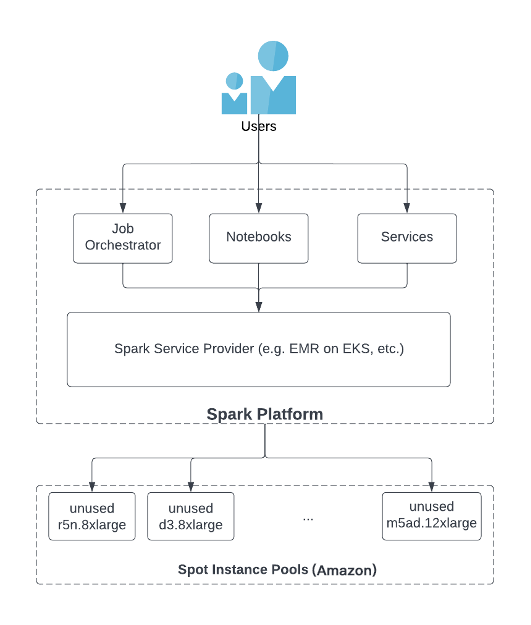
Nuestro último SSP no proporcionó la solución requerida para estos dos puntos. Solo admiten un conjunto limitado de tipos de instancias de Spot y, de forma predeterminada, solo se permite seleccionar un tipo de instancia de Spot al iniciar un trabajo de Spark. Por lo tanto, cada aplicación Spark solo puede ejecutar una instancia de spot con una capacidad menor y es vulnerable a la terminación de la instancia de spot.
EMR en EKS utiliza Amazon Elastic Kubernetes Service (Amazon EKS) para acceder a instancias puntuales en Amazon Web Services. Amazon EKS admite todos los tipos de instancias EC2 disponibles, lo que nos brinda grupos de mayor capacidad. Usamos características como grupos de nodos administrados de Amazon EKS, selectores de nodos y taints para asignar cada aplicación Spark a un grupo de nodos que consta de varios tipos de instancias. Después de migrar a EMR en EKS, vimos los siguientes beneficios:
La frecuencia de las terminaciones de instancias puntuales se reduce, lo que da como resultado tiempos de ejecución de aplicaciones Spark más rápidos y estables.
Los ingenieros ven una mayor previsibilidad del comportamiento de las aplicaciones y, por lo tanto, pueden iterar más rápido.
Los costos de infraestructura se reducen drásticamente porque ya no necesitamos soluciones alternativas costosas y tenemos una opción rentable de instancias en cada grupo de nodos en Amazon EKS. Pudimos ahorrar alrededor del 50 % de nuestros costos de computación sin soluciones alternativas, como ejecutar en múltiples zonas de disponibilidad, mientras brindamos el nivel esperado de confiabilidad.
Experiencia de depuración fluida
Al final del ciclo del flujo de trabajo del diseño de ingeniería, es fundamental tener una infraestructura que permita a los ingenieros depurar fácilmente las aplicaciones Spark. Apache Spark utiliza registros de eventos para registrar la actividad de la aplicación Spark, como el inicio y la finalización de tareas. Estos eventos están en formato JSON y SHS los utiliza para volver a representar la interfaz de usuario de la aplicación Spark. Los ingenieros pueden acceder a SHS para investigar por qué fallan las tareas o para depurar problemas de rendimiento.
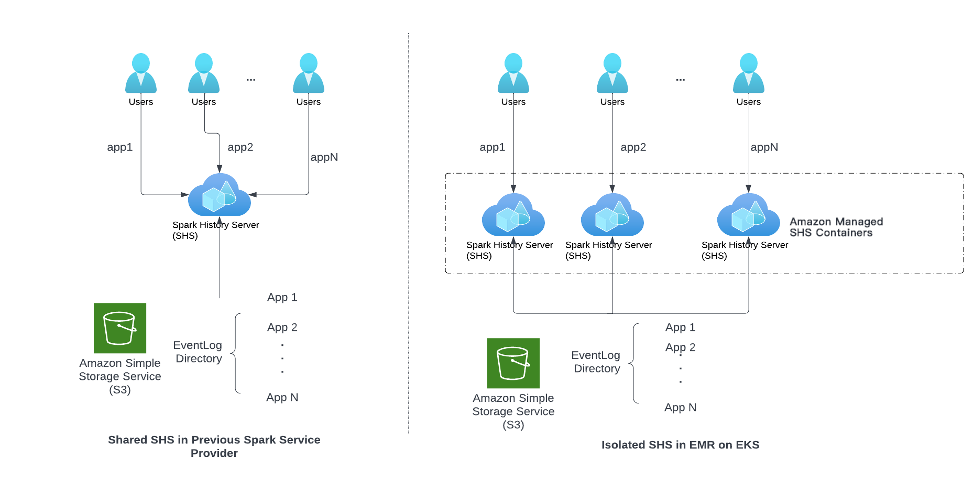
Un desafío importante para los ingenieros de SafeGraph fue el problema de la escalabilidad en SHS. Como se muestra en el lado izquierdo del diagrama siguiente, nuestro SSP anterior obligaba a todos los ingenieros a compartir la misma instancia de SHS. Como resultado, SHS se encuentra bajo una enorme presión de recursos debido al acceso simultáneo de muchos ingenieros para depurar la aplicación, o si una aplicación Spark necesita generar un registro de eventos grande. Antes de migrar a EMR en EKS, a menudo experimentábamos lentitud de SHS o que SHS fallaba por completo.
Como se muestra en la figura siguiente, para cada solicitud para ver la interfaz de usuario del historial de Spark, EMR en EKS lanza un contenedor de instancia SHS independiente en el entorno administrado de Amazon Web Technologies. Los beneficios de esta arquitectura son dos:
Los diferentes usuarios y aplicaciones Spark ya no compiten por los recursos de SHS. Como resultado, nunca volvimos a experimentar lentitud o fallas de SHS.
Todos los contenedores SHS son administrados por la tecnología en la nube de Amazon; los usuarios pueden disfrutar de una arquitectura escalable sin pagar costos financieros o de operación y mantenimiento adicionales.
Plataforma Spark fácil de administrar
Como se muestra en el flujo de trabajo de diseño de ingeniería, la construcción de la plataforma Spark no es un esfuerzo único, y el equipo de la plataforma necesita administrar la plataforma Spark y optimizar continuamente cada paso en el flujo de trabajo de desarrollo del ingeniero. La función del SSP es proporcionar instalaciones adecuadas para reducir la carga de operación y mantenimiento tanto como sea posible. Aunque existen muchos tipos de tareas operativas, en este artículo nos centramos en dos de ellas: la gestión de SKU de recursos informáticos y la gestión de versiones de distribución de Spark.
La gestión de SKU de recursos informáticos se refiere al diseño y procesamiento de la plataforma Spark para permitir a los usuarios elegir instancias informáticas de diferentes tamaños. Dicho diseño y procesamiento dependen en gran medida de las funciones relevantes implementadas por el SSP.
La siguiente imagen muestra la gestión de SKU de nuestro SSP anterior.
El siguiente diagrama muestra la gestión de SKU en EMR en EKS.

Al trabajar con nuestro SSP anterior, la configuración del trabajo solo permitía especificar explícitamente un único tipo de instancia de Spot y, si no había capacidad de Spot disponible para ese tipo, el trabajo cambiaría a instancias On-Demand o habría problemas de confiabilidad. . Esto deja a los ingenieros de plataformas con la opción de cambiar la configuración del conjunto de instancias de trabajo de Spark o correr el riesgo de picos inesperados en el presupuesto y el costo de los productos vendidos.
EMR en EKS facilita a los equipos de la plataforma la gestión de SKU informáticas. En SafeGraph, integramos un cliente de servicio Spark entre los usuarios y EMR en EKS. Los clientes del servicio Spark solo exponen diferentes niveles de recursos (como pequeños, medianos y grandes) a los usuarios. Cada nivel se asigna a un grupo de nodos específico configurado en Amazon EKS. Este diseño trae los siguientes beneficios:
Cuando los precios y las capacidades cambian, podemos actualizar fácilmente las configuraciones en los grupos de nodos sin que los usuarios lo sepan. Los usuarios no necesitan realizar ningún cambio, ni siquiera sentir nada, y pueden continuar disfrutando de configuraciones de recursos estables, mientras nosotros podemos mantener los costos y los gastos generales de operación y mantenimiento lo más bajos posible.
Los usuarios finales eliminan las conjeturas a la hora de elegir el recurso adecuado para una aplicación Spark, ya que la selección se facilita mediante una configuración simplificada.
Otro beneficio que hemos obtenido de EMR en EKS es la gestión mejorada de versiones de Spark. Antes de usar EMR en EKS, teníamos problemas con nuestro SSP que no publicaba distribuciones Spark de forma transparente. Cada 1 o 2 meses, la distribución Spark lanza una nueva versión parcheada para los usuarios. Estas versiones están expuestas a los usuarios a través de la interfaz de usuario. Esto dio lugar a que los ingenieros eligieran varias versiones de la distribución, algunas de las cuales no fueron probadas con nuestras herramientas internas. Esto aumentó drásticamente la tasa de interrupciones de nuestras tuberías y sistemas internos, y supuso una carga de soporte significativa para el equipo de la plataforma. Esperamos que después de utilizar la arquitectura EMR en EKS, el riesgo de distribución de Spark pueda minimizarse y ser transparente para los usuarios.
EMR en EKS sigue las mejores prácticas de utilizar una imagen Docker base estable con una versión fija de la distribución Spark. Para cualquier cambio en la distribución de Spark, tuvimos que reconstruir e implementar explícitamente la imagen de Docker. Con EMR en EKS, podemos ocultar nuevas versiones de distribuciones de Spark a los usuarios hasta que se prueben con herramientas y sistemas internos y se lancen oficialmente.
Resumir
En este artículo, compartimos el proceso de construcción de la plataforma Spark basándose en EMR en EKS. El uso de EMR en EKS como SSP ha sentado una base sólida para nuestra plataforma Spark. Con EMR en EKS, pudimos resolver varios desafíos, como la gestión de dependencias, el aprovisionamiento de recursos y la experiencia de depuración, y gracias a la mayor disponibilidad de los tipos y tamaños de instancias de Spot, también redujimos significativamente los costos informáticos, recortando hasta un 50 %.
Esperamos que esta publicación comparta algunas ideas en la comunidad y ayude a las empresas a elegir el SSP adecuado. Obtenga más información sobre EMR en EKS (https://aws.amazon.com/emr/features/eks/), incluidos sus beneficios, capacidades y cómo comenzar.
URL original:
https://aws.amazon.com/blogs/big-data/how-safegraph-built-a-reliable-ficient-and-user-friendly-spark-platform-with-amazon-emr-on-amazon-eks/
El autor de este artículo.

Nan Zhu
Responsable técnico principal del equipo de la plataforma SafeGraph. Lideró el equipo que creó una amplia infraestructura y herramientas internas para aumentar la confiabilidad, eficiencia y productividad del proceso de ingeniería de SafeGraph, como el ecosistema interno Spark, el almacenamiento de métricas y CI/CD para repositorios únicos grandes. También está involucrado en varios proyectos de código abierto como Apache Spark, Apache Iceberg, Gluten, etc.

David Thibault
Arquitecto de soluciones senior que atiende a clientes de proveedores de software independientes (ISV) de Amazon Web Technologies. Su pasión por construir con tecnologías sin servidor y aprendizaje automático acelera el éxito empresarial de los clientes de tecnología en la nube de Amazon. Antes de unirse a Amazon Web Technologies, Dave trabajó durante 17 años en empresas de ciencias biológicas en TI e informática para investigación, desarrollo y fabricación clínica. Sus pasatiempos incluyen esquiar, pintar y dibujar al aire libre y pasar tiempo con su familia.


He oído, haz clic en los 4 botones siguientes
¡No encontrarás errores!
