시리즈 기사 디렉토리
[자바기초] StringBuffer, StringBuilder 클래스 응용 및 소스코드 분석
[자바기초] 배열 응용 및 소스코드 분석
[자바기초] 문자열, 메모리 주소 분석, 소스코드
[JDK8 환경에서의 HashMap 클래스 응용 및 소스코드 분석] 첫 번째 빈 constructor 초기화
[JDK8 환경에서 HashMap 클래스 적용 및 소스코드 분석] 2부에서는 HashMap의 확장 메커니즘을 이해하기 위해 소스코드를 살펴본다. [
JDK8 환경에서 HashMap 클래스 적용 및 소스코드 분석] 3부에서는 용량 실험을 수정한다.
[HashMap 클래스 JDK8 환경에서의 애플리케이션 및 소스 코드 분석] 소스 코드 분석] IV부 HashMap 해시 충돌, HashMap 저장 구조, 연결된 목록이 빨간색과 검은색 트리가 됨

기사 디렉토리
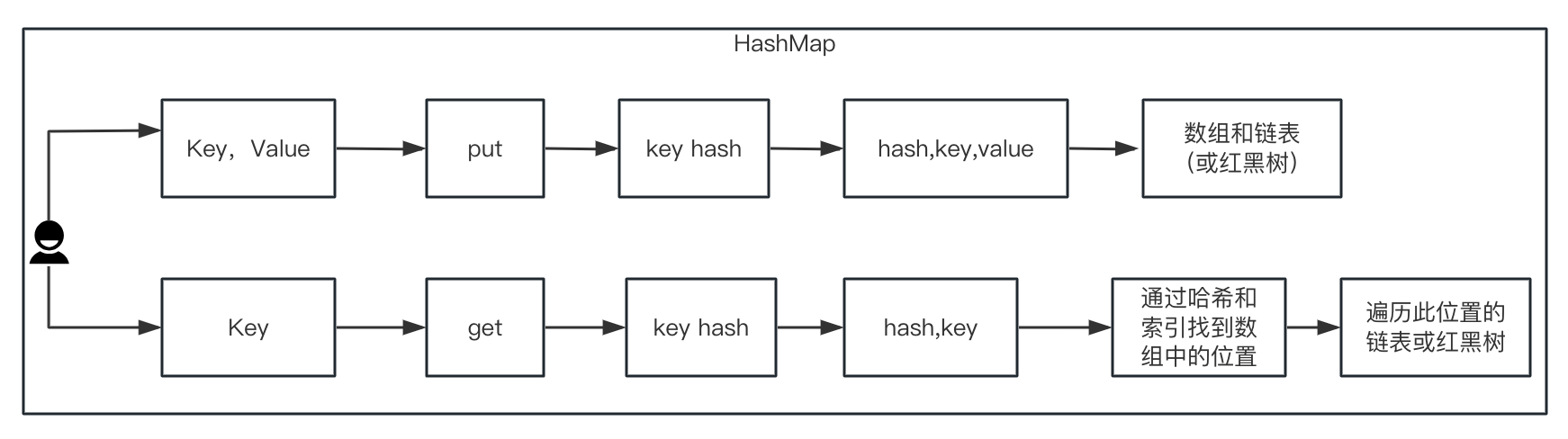
1. JDK8에서 HashMap의 데이터 구조
HashMap은 배열과 연결 목록(또는 레드-블랙 트리)을 기반으로 하는 데이터 구조로, 해시 함수를 통해 키를 배열의 위치에 매핑하고 해당 위치에 키-값 쌍의 노드를 저장합니다.
데이터를 삽입하기 전에 HashMap의 put 메소드는 먼저 해시 값(hash(key))과 키의 인덱스를 계산한 후 해당 위치에 노드를 삽입하거나 업데이트해야 합니다.노드 수가 임계값(threshold)을 초과하는 경우 , 용량( resize()) 또는 트리화를 확장합니다.
HashMap의 get 메소드는 주로 키의 해시 값과 인덱스에 따라 해당 위치를 찾은 다음 연결된 목록 또는 레드-블랙 트리를 순회하여 일치하는 값을 반환하는 것입니다.
1.1, 해시
public class HashMap {
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
}
public class Object {
public native int hashCode();
}
public final class System {
/**
* Returns the same hash code for the given object as
* would be returned by the default method hashCode(),
* whether or not the given object's class overrides
* hashCode().
* The hash code for the null reference is zero.
*
* @param x object for which the hashCode is to be calculated
* @return the hashCode
* @since JDK1.1
*/
public static native int identityHashCode(Object x);
}
다음은 HotSpot VM 내부의 Java 개체 및 클래스의 특정 구현에 대한 심층 분석 입니다.
객체 해시
_mark에는 객체의 해시 값을 나타내는 해시 코드 필드가 있습니다. 각 Java 개체에는 고유한 해시 값이 있으며, Object.hashCode() 메서드를 다시 작성하지 않으면 가상 머신이 자동으로 해시 값을 생성합니다. 해시 값 생성 전략은 목록 3-4에 나와 있습니다.
코드 목록 3-4 객체 해시 값 생성 전략
static inline intptr_t get_next_hash(Thread * Self, oop obj) { intptr_t value = 0; if (hashCode == 0) { // Park-Miller 난수 생성기 value = os::random(); } else if (hashCode = = 1) { // 무작위로 수행하기 위해 매 STW마다 stwRandom 생성 intptr_t addrBits = Cast_from_oop Java 계층은 Object.hashCode() 또는 System.identityHashCode()를 호출하고 마지막으로 가상 머신 계층의 런타임/동기화 장치의 get_next_hash()를 호출하여 생성합니다. 해시 값.
1.2, 키, 값 유형
static final int TREEIFY_THRESHOLD = 8; //链表转红黑树
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//判断table是否初始化
if ((tab = table) == null || (n = tab.length) == 0)
//如果是,调用 resize() 方法,进行初始化并赋值
n = (tab = resize()).length;
//通过hash获取下标,如果数据为null
if ((p = tab[i = (n - 1) & hash]) == null)
// tab[i]下标没有值,创建新的Node并赋值
tab[i] = newNode(hash, key, value, null);
else {
//tab[i] 下标的有数据,发生碰撞
Node<K,V> e; K k;
//判断tab[i]的hash值和传入的hash值相同,tab[i]的的key值和传入的key值相同
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
//如果是key值相同直接替换即可
e = p;
else if (p instanceof TreeNode)//判断数据结构为红黑树
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//数据结构是链表
for (int binCount = 0; ; ++binCount) {
//p的下一个节点为null,表示p就是最后一个节点
if ((e = p.next) == null) {
//创建新的Node节点并插入链表的尾部
p.next = newNode(hash, key, value, null);
//当元素>=8-1,链表转为树(红黑树)结构
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
//如果key在链表中已经存在,则退出循环
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
//更新p指向下一个节点,继续遍历
p = e;
}
}
//如果key在链表中已经存在,则修改其原先key的value值,并且返回老的value值
if (e != null) {
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);//替换旧值时会调用的方法(默认实现为空)
return oldValue;
}
}
++modCount;//修改次数
//根据map值判断是否要对map的大小扩容
if (++size > threshold)
resize();
afterNodeInsertion(evict);//插入成功时会调用的方法(默认实现为空)
return null;
}
putVal 소스 코드를 확인하세요. key 및 vlaue 데이터 유형은 제네릭을 사용하며 모든 참조 유형은 괜찮습니다. 기본 데이터 유형은 비교를 위해 hashcode() 메서드와 equals() 메서드를 호출할 수 없기 때문에 Java 기본 유형은 허용되지 않습니다. HashMap 컬렉션의 키 기본 데이터 유형이 아닌 참조 데이터 유형만 가능하며 Integer, Double, Long, Float 등과 같은 기본 데이터 유형의 래퍼 클래스를 사용할 수 있습니다.
1.3, 노드
[1.2] 코드 부분을 참고하세요. 탭 변수의 종류는 Map.Entry 인터페이스를 구현한 Node입니다.
Node에는 해시, 키, 값과 같은 속성이 있고 다음 노드 변수(연결된 목록)도 있습니다. 다음 노드
노드는 toString, hashCode 및 equals와 같은 메소드를 구현합니다.
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() {
return key; }
public final V getValue() {
return value; }
public final String toString() {
return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
interface Entry<K,V> {
K getKey();
V getValue();
V setValue(V value);
boolean equals(Object o);
int hashCode();
public static <K extends Comparable<? super K>, V> Comparator<Map.Entry<K,V>> comparingByKey() {
return (Comparator<Map.Entry<K, V>> & Serializable)
(c1, c2) -> c1.getKey().compareTo(c2.getKey());
}
public static <K, V extends Comparable<? super V>> Comparator<Map.Entry<K,V>> comparingByValue() {
return (Comparator<Map.Entry<K, V>> & Serializable)
(c1, c2) -> c1.getValue().compareTo(c2.getValue());
}
public static <K, V> Comparator<Map.Entry<K, V>> comparingByKey(Comparator<? super K> cmp) {
Objects.requireNonNull(cmp);
return (Comparator<Map.Entry<K, V>> & Serializable)
(c1, c2) -> cmp.compare(c1.getKey(), c2.getKey());
}
public static <K, V> Comparator<Map.Entry<K, V>> comparingByValue(Comparator<? super V> cmp){
Objects.requireNonNull(cmp);
return (Comparator<Map.Entry<K, V>> & Serializable)
(c1, c2) -> cmp.compare(c1.getValue(), c2.getValue());
}
}
1.4, 트리노드
[1.2] 코드부분을 참고하세요, 변수 p의 타입은 LinkedHashMap.Entry 인터페이스를 구현한 TreeNode이며, TreeNode는 red라는 속성과 parent ,
left, right, prev(red-black tree) 같은 변수를 가지고 있습니다.
treeify, find, putTreeVal 등의 메소드를 구현합니다.
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red;
TreeNode(int hash, K key, V val, Node<K,V> next) {
super(hash, key, val, next);
}
final TreeNode<K,V> root() {
for (TreeNode<K,V> r = this, p;;) {
if ((p = r.parent) == null)
return r;
r = p;
}
}
static <K,V> void moveRootToFront(Node<K,V>[] tab, TreeNode<K,V> root) {
...
}
final TreeNode<K,V> find(int h, Object k, Class<?> kc) {
TreeNode<K,V> p = this;
do {
int ph, dir; K pk;
TreeNode<K,V> pl = p.left, pr = p.right, q;
if ((ph = p.hash) > h)
p = pl;
else if (ph < h)
p = pr;
else if ((pk = p.key) == k || (k != null && k.equals(pk)))
return p;
else if (pl == null)
p = pr;
else if (pr == null)
p = pl;
else if ((kc != null ||
(kc = comparableClassFor(k)) != null) &&
(dir = compareComparables(kc, k, pk)) != 0)
p = (dir < 0) ? pl : pr;
else if ((q = pr.find(h, k, kc)) != null)
return q;
else
p = pl;
} while (p != null);
return null;
}
final TreeNode<K,V> getTreeNode(int h, Object k) {
return ((parent != null) ? root() : this).find(h, k, null);
}
static int tieBreakOrder(Object a, Object b) {
int d;
if (a == null || b == null ||
(d = a.getClass().getName().
compareTo(b.getClass().getName())) == 0)
d = (System.identityHashCode(a) <= System.identityHashCode(b) ?
-1 : 1);
return d;
}
final void treeify(Node<K,V>[] tab) {
TreeNode<K,V> root = null;
for (TreeNode<K,V> x = this, next; x != null; x = next) {
next = (TreeNode<K,V>)x.next;
x.left = x.right = null;
if (root == null) {
x.parent = null;
x.red = false;
root = x;
}
else {
K k = x.key;
int h = x.hash;
Class<?> kc = null;
for (TreeNode<K,V> p = root;;) {
int dir, ph;
K pk = p.key;
if ((ph = p.hash) > h)
dir = -1;
else if (ph < h)
dir = 1;
else if ((kc == null &&
(kc = comparableClassFor(k)) == null) ||
(dir = compareComparables(kc, k, pk)) == 0)
dir = tieBreakOrder(k, pk);
TreeNode<K,V> xp = p;
if ((p = (dir <= 0) ? p.left : p.right) == null) {
x.parent = xp;
if (dir <= 0)
xp.left = x;
else
xp.right = x;
root = balanceInsertion(root, x);
break;
}
}
}
}
moveRootToFront(tab, root);
}
final Node<K,V> untreeify(HashMap<K,V> map) {
Node<K,V> hd = null, tl = null;
for (Node<K,V> q = this; q != null; q = q.next) {
Node<K,V> p = map.replacementNode(q, null);
if (tl == null)
hd = p;
else
tl.next = p;
tl = p;
}
return hd;
}
/**
* Tree version of putVal.
*/
final TreeNode<K,V> putTreeVal(HashMap<K,V> map, Node<K,V>[] tab,
int h, K k, V v) {
Class<?> kc = null;
boolean searched = false;
TreeNode<K,V> root = (parent != null) ? root() : this;
for (TreeNode<K,V> p = root;;) {
int dir, ph; K pk;
if ((ph = p.hash) > h)
dir = -1;
else if (ph < h)
dir = 1;
else if ((pk = p.key) == k || (k != null && k.equals(pk)))
return p;
else if ((kc == null &&
(kc = comparableClassFor(k)) == null) ||
(dir = compareComparables(kc, k, pk)) == 0) {
if (!searched) {
TreeNode<K,V> q, ch;
searched = true;
if (((ch = p.left) != null &&
(q = ch.find(h, k, kc)) != null) ||
((ch = p.right) != null &&
(q = ch.find(h, k, kc)) != null))
return q;
}
dir = tieBreakOrder(k, pk);
}
TreeNode<K,V> xp = p;
if ((p = (dir <= 0) ? p.left : p.right) == null) {
Node<K,V> xpn = xp.next;
TreeNode<K,V> x = map.newTreeNode(h, k, v, xpn);
if (dir <= 0)
xp.left = x;
else
xp.right = x;
xp.next = x;
x.parent = x.prev = xp;
if (xpn != null)
((TreeNode<K,V>)xpn).prev = x;
moveRootToFront(tab, balanceInsertion(root, x));
return null;
}
}
}
final void removeTreeNode(HashMap<K,V> map, Node<K,V>[] tab,
boolean movable) {
...
}
final void split(HashMap<K,V> map, Node<K,V>[] tab, int index, int bit) {
...
}
/* ------------------------------------------------------------ */
// Red-black tree methods, all adapted from CLR
static <K,V> TreeNode<K,V> rotateLeft(TreeNode<K,V> root,
TreeNode<K,V> p) {
...
return root;
}
static <K,V> TreeNode<K,V> rotateRight(TreeNode<K,V> root,
TreeNode<K,V> p) {
...
return root;
}
static <K,V> TreeNode<K,V> balanceInsertion(TreeNode<K,V> root,
TreeNode<K,V> x) {
...
}
static <K,V> TreeNode<K,V> balanceDeletion(TreeNode<K,V> root,
TreeNode<K,V> x) {
...
}
static <K,V> boolean checkInvariants(TreeNode<K,V> t) {
...
return true;
}
}
1.5 데이터 삽입 시 데이터 구조 변경
[1.2] 코드를 참고하세요. 데이터를 삽입하면 데이터 구조는 어떻게 되나요?
효과 그림은 [1]의 두 번째 그림에서 볼 수 있습니다.
- 테이블이 초기화되었는지 확인 예
-> resize() 메서드를 호출하여 초기화 및 할당 - 초기화되지 않은 경우 해시를 통해 첨자를 가져오고, 데이터가 null이면
tab[i] 첨자에 값이 없으면 새 노드를 생성하고 할당합니다. - tab[i]의 첨자에 데이터가 있고, 해시 충돌이 발생한 경우는 세 가지 경우가 있다.
1. tab[i]의 해시 값이 전달된 해시 값과 같고, tab[i]의 키 값이 같다고 판단 전달된 키 값과 동일하다
. 동일할 경우 직접 대체
2. 데이터 구조가 레드-블랙 트리인지 판단 레드
-블랙 트리의 데이터 삽입 함수 putTreeVal 호출
3. 데이터 구조는 다음과 같다. 연결리스트
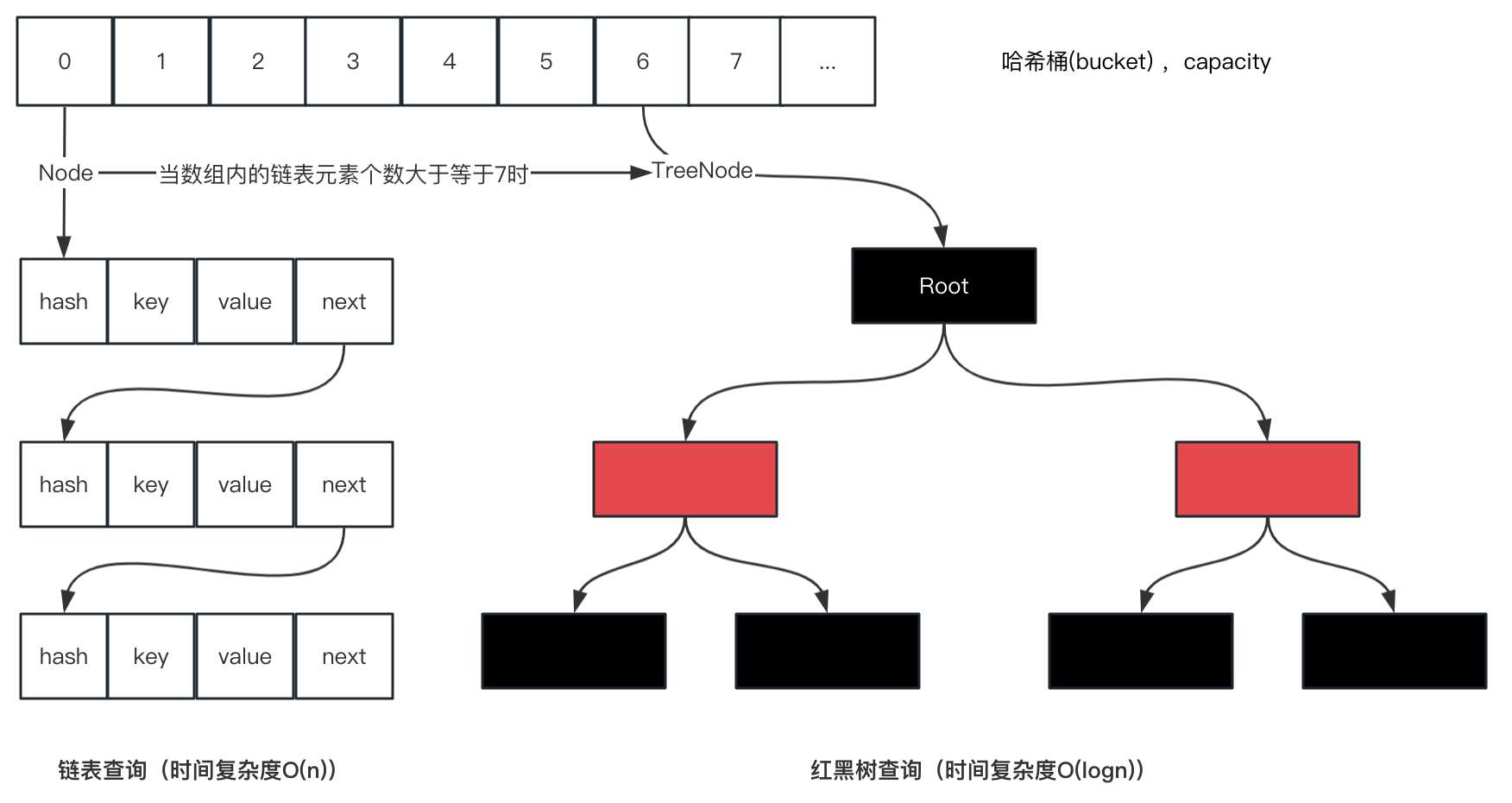
순환리스트 p의 다음 노드가 null이면 p가 마지막 노드임을 의미 마지막에 새로운 Node 노드를 삽입 이때 요소의 개수가 7 이상이면 연결리스트는 레드-블랙 트리 구조로 변하며,
연결리스트에 키가 이미 존재하는 경우 루프를 종료합니다.
2. 실험
실험에는 해시 충돌과 연결 목록이 빨간색과 검은색 트리로 변하는 것이 포함됩니다. 소스 코드를 단계별로 디버깅하고 추적하여 알아봅시다.
2.1 해시 충돌
2.1.1 및 비트 연산(&)
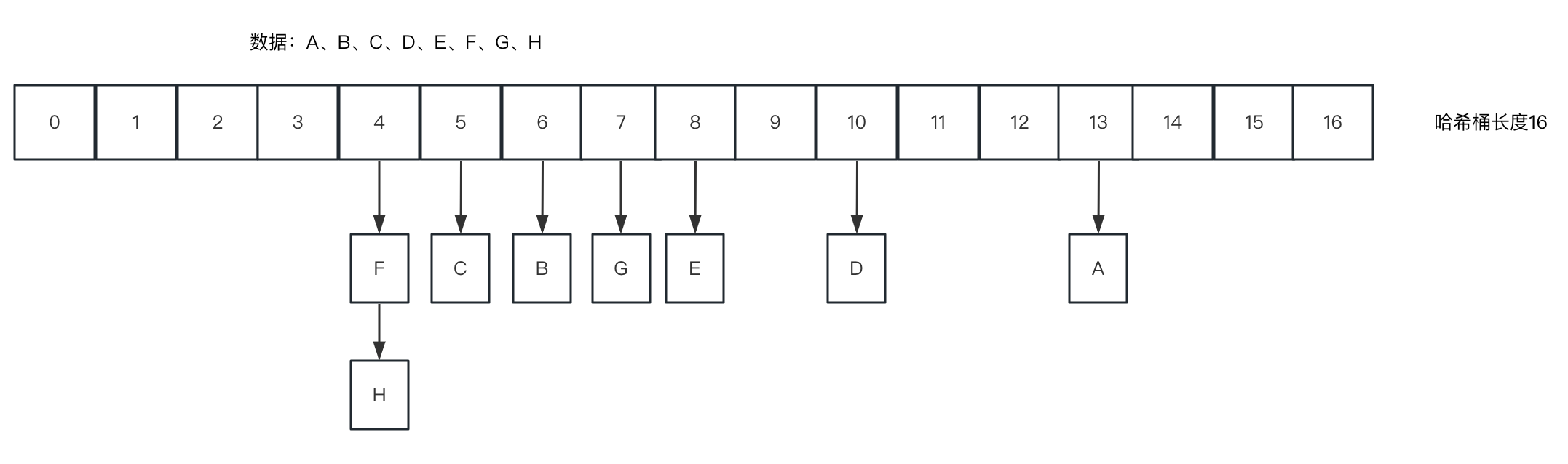
- 1. 문자열 "A", "B", "C", "D", "E", "F", "G", "H"의 hashCode를 계산합니다.
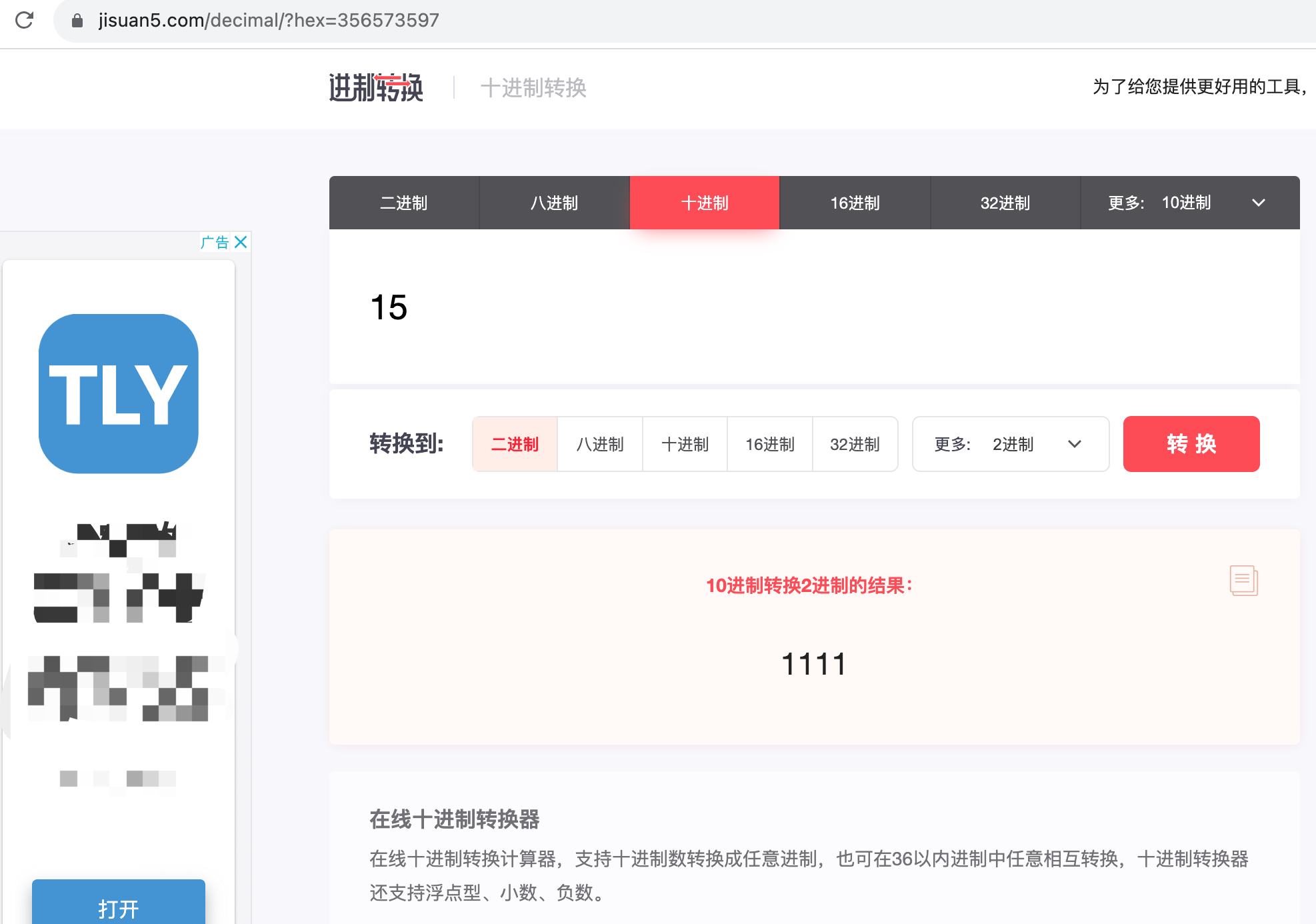
- 2. 이진수로 변환(https://jisuan5.com/decimal/?hex=356573597)
십진수 15를 이진수로 변환, 결과: 1111
"A" hashCode=356573597 이 실험에서는 2를 십진수 356573597로 변환, 결과: 10101010000001110000110011101
356573597 & 15
= 10101010000001110000110011101 & 1111
= 10101010000001110000110011101 & 000
00000000000000000000001111(높은 보수 0, 정렬 왼쪽 데이터)
= 00000000000000000000000001101 = 1101 (상위 0은 생략 가능) - 3. 15(2의 4승 -1)를 다른 데이터로 변경하는 여러 번의 실험을 통해 우리는 2 -1의 거듭제곱, 하위 비트가 모두 1이고 AND 연산을 수행할 때 데이터가 고르게 분포된다는 것을 발견했습니다. 2의 거듭제곱 또는 다른 데이터로 변경하면 낮은 비트에 0이 있고 최종 데이터 분포가 고르지 않습니다.
int n = 16 - 1; //二进制: 1111
String[] strs = {
"A" , "B" , "C" , "D" , "E" , "F" , "G" , "H"};
for (int i = 0; i < strs.length; i++) {
System.out.println("-------------------------");
System.out.println(System.identityHashCode(strs[i]) );
System.out.println("二进制:"+ Integer.toBinaryString(System.identityHashCode(strs[i])) );
System.out.println( System.identityHashCode(strs[i]) & n );
System.out.println("-------------------------");
}
-------------------------
356573597
二进制:10101010000001110000110011101
13
-------------------------
-------------------------
1735600054
二进制:1100111011100110010011110110110
6
-------------------------
-------------------------
21685669
二进制:1010010101110010110100101
5
-------------------------
-------------------------
2133927002
二进制:1111111001100010010010001011010
10
-------------------------
-------------------------
1836019240
二进制:1101101011011110110111000101000
8
-------------------------
-------------------------
325040804
二进制:10011010111111011101010100100
4
-------------------------
-------------------------
1173230247
二进制:1000101111011100001001010100111
7
-------------------------
-------------------------
856419764
二进制:110011000010111110110110110100
4
-------------------------
2.1.2 해시 충돌
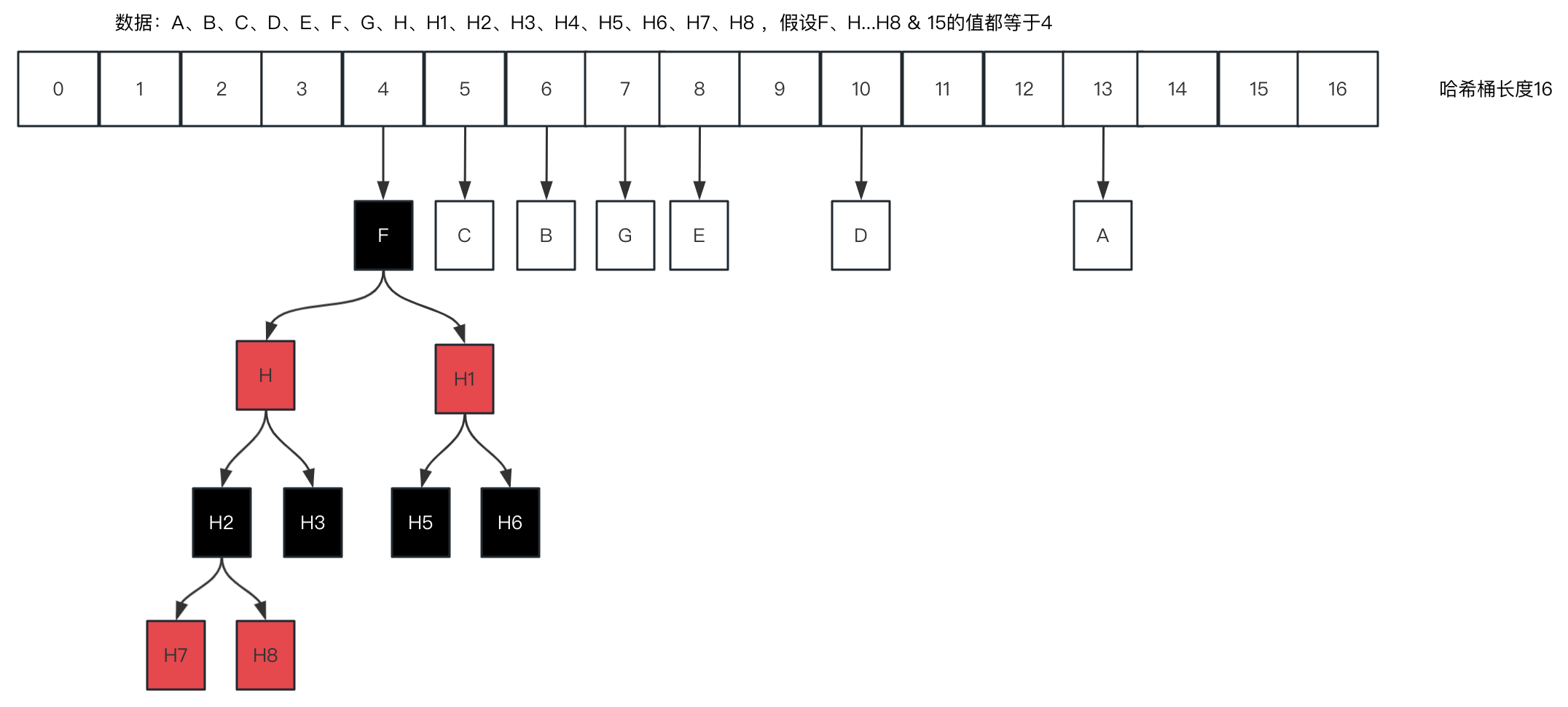
[2.1.1]의 코드 사례에서는 F와 H의 해시 값을 15로 AND한 후 값이 4가 된다. 자세한 설명은 [1.5]를 참조하면 HashMap에서 인덱스 위치를 계산하는 것과 동일하다.
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
...
if ((p = tab[i = (n - 1) & hash]) == null)
...
}
해시 충돌(해시 충돌)에 대한 몇 가지 솔루션은 다음과 같습니다.
- 체인 주소 방식
해시 충돌이 발생한 데이터는 배열에서 동일한 인덱스를 갖고 있으며, 충돌된 데이터를 연결 리스트(linked list)를 사용하여 저장한다(JDK8의 HashMap은 이 방식을 채택하고 있으며 tail 삽입 방식을 사용한다). - 재해시 (Re-hash) 방법
해시 충돌 문제가 발생하면 충돌이 더 이상 발생하지 않을 때까지 여기에서 해시합니다. 이 방법은 집계를 생성하기 쉽지 않지만 계산 시간이 늘어납니다. - 오픈 주소 방식 해시
충돌 문제가 발생하면 충돌이 발생한 단위부터 시작하여 일정한 순서로 해시 테이블에서 빈 단위를 찾습니다. 그런 다음 충돌하는 요소를 셀에 저장하는 방법입니다. - 공용 오버플로 영역 구축 해시
테이블을 공용 테이블과 오버플로 테이블로 나누어 오버플로 발생 시 모든 오버플로 데이터를 오버플로 영역에 넣음
2.2 연결리스트는 레드-블랙 트리가 된다
2가지 가정을 했을 때(HashMap에서 기본 로드 팩터는 0.75이고, 길이가 12보다 큰 경우(16*0.75=12) 32로 확장되며, 비트 연산의 다시 계산된 값도 변경되며, 재균형 분배에 대해서는 [1.5] 참조)에 대해 자세히 설명합니다.
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
...
//p的下一个节点为null,表示p就是最后一个节点
if ((e = p.next) == null) {
//创建新的Node节点并插入链表的尾部
p.next = newNode(hash, key, value, null);
//当元素>=8-1,链表转为树(红黑树)结构
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
...
}
1. 해시 버킷은 확장되지 않습니다.
2. (F, H...H8) & 15는 모두 4와 동일하여 총 9개의 요소입니다. 일곱 번째 요소가 추가되면 연결된 목록이 다음으로 전환됩니다. 레드-블랙 트리, H7, H8을 삽입하면 직접적으로 인기 있는 블랙 트리 삽입 로직