Tabla de contenido
Aplicación del aprendizaje automático en la fijación de precios de seguros de automóviles
2. Configuraciones experimentales
Conjeturas antes del experimento:
1. Preprocesamiento y división de datos
Resultados del procesamiento de codificación one-hot (tomando regiones como ejemplo)
3. Dibuja el árbol de decisión inicial.
Dibujar el árbol de decisión optimizado
6. Modifique los parámetros de búsqueda de muestra y cuadrícula para optimizar aún más el modelo.
1. Tema experimental
Aplicación del aprendizaje automático en la fijación de precios de seguros de automóviles
2. Configuraciones experimentales
1. Sistema operativo:
Inicio de Windows 11
2. IDE:
PyCharm 2022.3.1 (Edición profesional)
3. pitón :
3.8.0
4. Biblioteca:
| engordado |
1.20.0 |
|
| matplotlib |
3.7.1 |
|
| pandas |
1.1.5 |
|
| aprendizaje-scikit |
0.24.2 |
conda create -n ML python==3.8 pandas scikit-learn numpy matplotlib3. Contenido experimental
En este experimento, se utiliza un modelo de árbol de decisión para modelar y realizar el análisis de datos de seguros de automóviles. Los datos de seguros de automóviles son el siguiente conjunto de datos MTPLdata.csv:
El conjunto de datos de seguros de automóviles contiene 500.000 muestras, cada una con 8 características y 1 etiqueta. Entre ellos, etiqueta es una variable binaria con un valor de 0 o 1, que indica si el propietario ha informado un reclamo de seguro de automóvil (clm, int64); las características incluyen la edad del propietario (age, int64), la edad del vehículo (ac , int64), potencia ( power, int64), tipo de combustible (gas, objeto), marca (marca, objeto), área del propietario (área, objeto), densidad de vehículos residenciales (dens, int64) y tipo de licencia de automóvil (ct, objeto).
Conjeturas antes del experimento :
Consulte el informe del experimento para obtener más detalles.
4. Resultados experimentales
1. Preprocesamiento y división de datos
Leer datos y realizar preprocesamiento de datos, incluido el procesamiento de variables ficticias y la división de conjuntos de entrenamiento y prueba.
MTPLdata = pd.read_csv('MTPLdata.csv')
# 哑变量处理-独热编码
# 将clm列的数据类型转换为字符串
MTPLdata['clm'] = MTPLdata['clm'].map(str)
# 选择包括第1、2、3、4、5、6、7、8列的数据作为特征输入
# ac、brand、age、gas、power
X_raw = MTPLdata.iloc[:, [0, 1, 2, 3, 4]]
# X_raw = MTPLdata.iloc[:, [0, 1, 2, 3, 4, 5, 6, 7]]
# 对X进行独热编码
X = pd.get_dummies(X_raw)
# 选择第9列作为标签y
y = MTPLdata.iloc[:, 8]
# 将数据划分为训练集和测试集,测试集占总数据的20%
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, test_size=0.2, random_state=1)
Resultados del procesamiento de codificación one-hot (tomando regiones como ejemplo)
2. Entrenamiento modelo
Usamos un modelo clasificador de árbol de decisión para el entrenamiento (establezca la profundidad máxima del árbol en 2, use pesos de clase equilibrados y use el coeficiente de Gini para verificar la precisión de forma predeterminada).
model = DecisionTreeClassifier(max_depth=2, class_weight='balanced', random_state=123)
model.fit(X_train, y_train) # 数据拟合
model.score(X_test, y_test) # 在测试集上评估模型3. Dibuja el árbol de decisión inicial.
Para interpretar mejor el modelo de árbol de decisión, llame a la función plot_tree para dibujar un árbol de decisión.
plt.figure(figsize=(11, 11))
plot_tree(model, feature_names=X.columns, node_ids=True, rounded=True, precision=2)
plt.show()
4. Evaluación del modelo
pred = model.predict(X_test)
table = pd.crosstab(y_test, pred, rownames=['Actual'], colnames=['Predicted'])
# table
# 计算模型的准确率、错误率、召回率、特异度和查准率
table = np.array(table) # 将pandas DataFrame转换为numpy array
Accuracy = (table[0, 0] + table[1, 1]) / np.sum(table) # 准确率
Error_rate = 1 - Accuracy # 错误率
Sensitivity = table[1, 1] / (table[1, 0] + table[1, 1]) # 召回率
Specificity = table[0, 0] / (table[0, 0] + table[0, 1]) # 特异度
Recall = table[1, 1] / (table[0, 1] + table[1, 1]) # 查准率
5. Optimización del modelo
Para encontrar un modelo mejor, utilizamos la función cost_complexity_pruning_path para calcular la impureza total de los nodos de hoja del árbol de decisión correspondientes a diferentes ccp_alpha y dibujar la relación entre ccp_alpha y la impureza total.
model = DecisionTreeClassifier(class_weight='balanced', random_state=123)
path = model.cost_complexity_pruning_path(X_train, y_train)
plt.plot(path.ccp_alphas, path.impurities, marker='o', drawstyle='steps-post')
plt.xlabel('alpha (cost-complexity parameter)')
plt.ylabel('Total Leaf Impurities')
plt.title('Total Leaf Impurities vs alpha for Training Set')
plt.show()Muestra de 1w Muestra de 50w
A continuación, seleccionamos el ccp_alpha óptimo mediante validación cruzada y volvemos a entrenar el modelo con el ccp_alpha óptimo.
Dibujar el árbol de decisión optimizado
rangeccpalpha = np.linspace(0.000001, 0.0001, 10, endpoint=True)
param_grid = {
'max_depth': np.arange(3, 7, 1),
# 'ccp_alpha': rangeccpalpha,
'min_samples_leaf': np.arange(1, 5, 1)
}
kfold = StratifiedKFold(n_splits=10, shuffle=True, random_state=1)
model = GridSearchCV(DecisionTreeClassifier(class_weight='balanced', random_state=123),
param_grid, cv=kfold)
model.fit(X_train, y_train)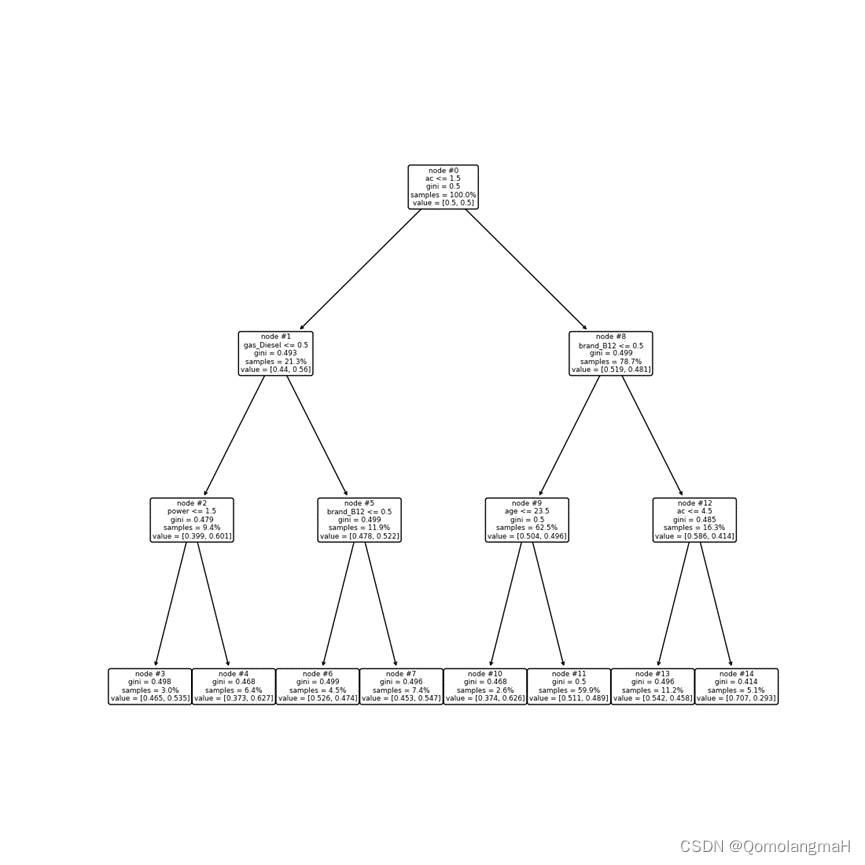
Además, se calcula la importancia de las características individuales y se traza un mapa de importancia de las características.
plt.figure(figsize=(20, 20))
sorted_index = model.feature_importances_.argsort()
plt.barh(range(X_train.shape[1]), model.feature_importances_[sorted_index])
plt.yticks(np.arange(X_train.shape[1]), X_train.columns[sorted_index])
plt.xlabel('Feature Importance')
plt.ylabel('Feature')
plt.title('Decision Tree')
plt.tight_layout()
plt.show()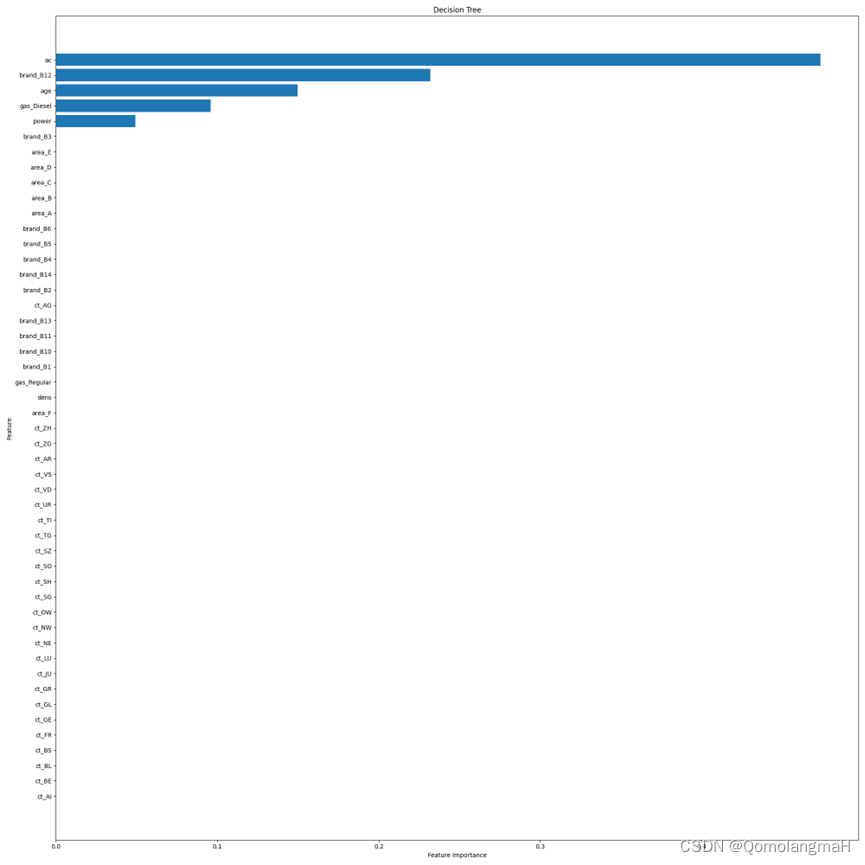
6. Modifique los parámetros de búsqueda de muestra y cuadrícula para optimizar aún más el modelo.
Consulte el informe del experimento para obtener más detalles.
5. Análisis experimental
Descargue el código y los recursos del informe del experimento correspondientes a este experimento (la parte de análisis del experimento tiene 2 páginas y 1162 palabras)