1. Problemas del entorno online
Maestros y estudiantes, ¿alguien ha encontrado este problema? Hay un campo de matriz de números enteros en el índice, y luego el valor con el subíndice 1 de la matriz se obtiene a través del script como campo de tiempo de ejecución. Se descubre que el valor devuelto es desordenado y el subíndice no es El valor de 1 es el siguiente:
DELETE my_index
PUT my_index
{
"mappings": {
"properties": {
"price": {
"type": "integer"
}
}
}
}
POST /my_index/_doc
{
"price": [
5,
6,
99,
3
]
}
POST /my_index/_doc
{
"price": [
22,
11,
19,
-1
]
}GET my_index/_search
{
"runtime_mappings": {
"price_a": {
"type": "double",
"script": {
"source": """
double v = doc['price'][1];
emit(v);
"""
}
}
},
"fields": [
{
"field": "price_a"
}
]
}¿Es porque los resultados almacenados en el valor del documento están desordenados?
El resultado es:
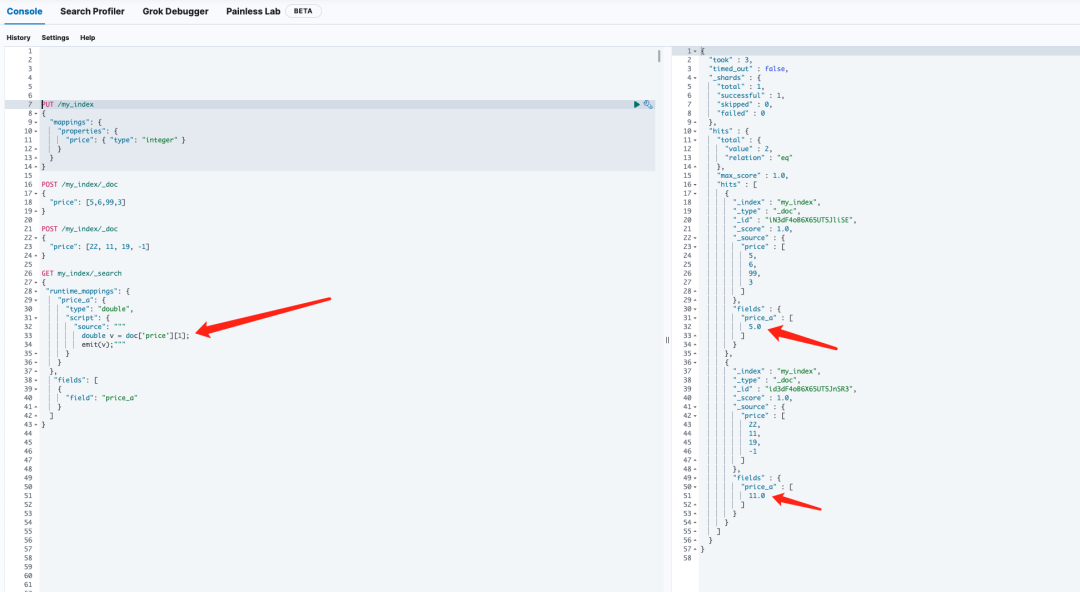 ——La pregunta proviene del grupo de intercambio técnico.
——La pregunta proviene del grupo de intercambio técnico.
2. Análisis de problemas
2.1 ¿Cómo se accede a los arreglos de Elasticsearch?
Las matrices no son un tipo de datos especial en Elasticsearch.
Cuando tiene un campo de matriz en un documento JSON y lo indexa en Elasticsearch, Elasticsearch indexará cada elemento de la matriz como un valor separado, pero no almacenará la estructura ni la información de orden de la matriz.
Por ejemplo, supongamos que tiene los siguientes documentos:
{
"tags": ["A", "B", "C"]
}Elasticsearch lo tratará como si hubiera agregado tres etiquetas "A", "B" y "C" al documento respectivamente.
Los campos de matriz (y muchos otros tipos de campos) se almacenan principalmente en Elasticsearch a través de Doc Values.
Doc Values son una estructura de datos en columnas optimizada, en disco, que hace que ordenar y agregar campos sea muy rápido y eficiente.
Sin embargo, el almacenamiento en columnas no conserva el orden de los datos originales, razón por la cual las matrices pierden su orden original en Elasticsearch.
2.2 Acceder a los datos de la matriz
Cuando accede a un campo de matriz en un script o consulta, como doc['tags'], lo que realmente obtiene es una lista de valores.
Aunque la matriz original tiene un solo valor, obtendrá una lista de valores. Por lo tanto, a menudo es necesario verificar su .size() y acceder a un valor específico a través de .value o un índice específico.
2.3 Matrices y tipos de documentos anidados Anidados
Aunque las matrices no conservan el orden, Elasticsearch proporciona un tipo de datos anidados que le permite indexar objetos en una matriz y mantener la relación entre ellos.
Esto es excelente para matrices complejas de objetos, pero también introduce algunas complejidades, como el uso de consultas y agregaciones anidadas específicas.
3. ¿Cómo obtener los datos del subíndice especificado?
3.1 Opción 1, cambios menores.
#### 删除索引
DELETE my_index
#### 创建索引
PUT my_index
{
"mappings": {
"properties": {
"price": {
"type": "integer"
}
}
}
}
#### 导入数据
POST /my_index/_doc
{
"price": [
5,
6,
99,
3
]
}
POST /my_index/_doc
{
"price": [
22,
11,
19,
-1
]
}#### 创建预处理管道
PUT _ingest/pipeline/split_array_pipeline
{
"description": "Splits the price array into individual fields",
"processors": [
{
"script": {
"source": """
if (ctx.containsKey('price') && ctx.price instanceof List && ctx.price.size() > 0) {
for (int i = 0; i < ctx.price.size(); i++) {
ctx['price_' + i] = ctx.price[i];
}
}
"""
}
}
]
}El significado de la canalización de preprocesamiento split_array_pipeline:
descripción:
Describa el propósito de este oleoducto . En este caso, ilustramos que el propósito de este canal es dividir la matriz de precios en campos individuales.
procesadores:
Es un conjunto de procesadores, cada uno de los cuales realiza una tarea específica. Aquí solo tenemos un controlador de script .
En el procesador de secuencias de comandos, escribimos una pequeña secuencia de comandos que verifica si hay un campo llamado precio, si ese campo es una matriz y si la matriz tiene al menos un elemento. Si se cumplen todas estas condiciones, el script recorre la matriz y crea un nuevo campo para cada elemento de la matriz. Los nombres de los nuevos campos serán precio_0, precio_1, etc., donde los números son los índices de la matriz.
Esta canalización de preprocesamiento es muy útil, especialmente cuando el formato de datos sin procesar no es adecuado para la indexación directa en Elasticsearch. Al utilizar una canalización de preprocesamiento, podemos realizar la transformación o limpieza deseada de los datos antes de indexarlos.
POST my_index/_update_by_query?pipeline=split_array_pipeline
{
"query": {
"match_all": {}
}
}
GET my_index/_search
{
"runtime_mappings": {
"price_a": {
"type": "double",
"script": {
"source": """
if (doc['price_0'].size() > 0) {
double v = doc['price_0'].value;
emit(v);
}
"""
}
}
},
"fields": [
{
"field": "price_a"
}
]
}Campos de tiempo de ejecución. Los campos de tiempo de ejecución son una característica introducida después de la versión 7.12 que le permite definir campos temporales cuyos valores se calculan mediante scripts en el momento de la consulta en lugar de almacenarse previamente en el momento del índice.
En el código anterior:
Definimos un nuevo campo de tiempo de ejecución llamado precio_a. El tipo de campo es doble.
Proporcionamos un script sencillo para calcular el valor de este campo.
Interpretación de guión:
si (doc['precio_0'].tamaño() > 0):
Esto verifica si el campo precio_0 existe y tiene un valor. En el script de Elasticsearch, doc['field_name'] significa obtener el valor del campo, y el método .size() se usa para verificar si el campo tiene un valor (en algunos documentos, el campo puede no existir o estar vacío ).
doble v = doc['precio_0'].valor;:
Si la condición anterior es verdadera, esta línea de código tomará el valor del campo precio_0 y lo convertirá a tipo doble.
emitir(v);:
Esta es la directiva clave del guión Painless. Genera el valor especificado como el valor del campo price_a en tiempo de ejecución.
Los resultados de la ejecución son los siguientes y los resultados han cumplido con las expectativas.
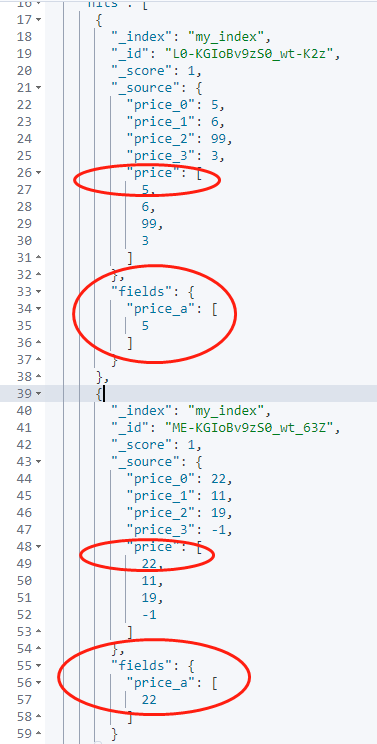
3.2 Solución 2: implementación anidada
Tipo de datos anidados anidados , hemos hablado de ello muchas veces en artículos anteriores, los estudiantes que no entienden pueden leer artículos históricos.
### 定义索引
PUT /my_nested_index
{
"mappings": {
"properties": {
"prices": {
"type": "nested",
"properties": {
"value": {
"type": "integer"
}
}
}
}
}
}
### 导入数据
POST /my_nested_index/_doc
{
"prices": [
{"value": 5},
{"value": 6},
{"value": 99},
{"value": 3}
]
}
POST /my_nested_index/_doc
{
"prices": [
{"value": 22},
{"value": 11},
{"value": 19},
{"value": -1}
]
}#### 执行检索
GET my_nested_index/_search
{
"query": {
"bool": {
"must": [
{
"nested": {
"path": "prices",
"query": {
"exists": {
"field": "prices.value"
}
},
"inner_hits": {
"size": 1
}
}
}
]
}
}
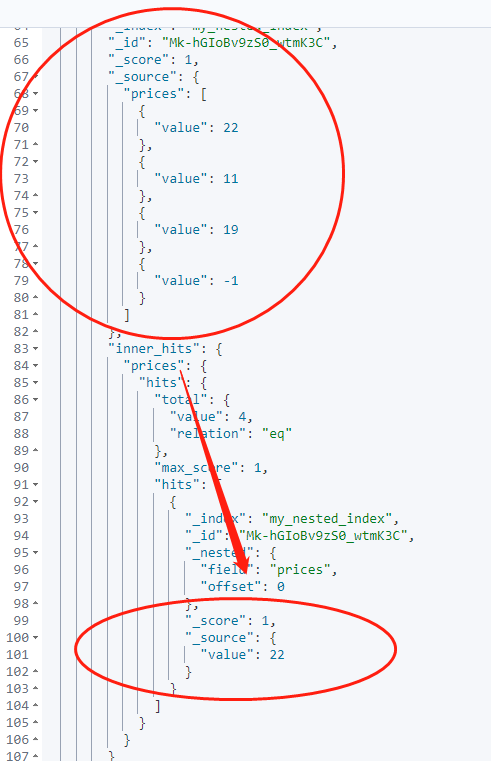
}Si desea devolver solo el primer resultado de datos en internal_hits, puede usar el parámetro de tamaño. Al establecer el tamaño en 1, puede limitar la cantidad de resultados devueltos por internal_hits.
resultado devuelto:
4. Resumen
Cuando usamos Elasticsearch con datos de matriz, es fácil malinterpretar su comportamiento real. Este artículo explora en detalle cómo Elasticsearch maneja y almacena matrices y proporciona varios métodos para obtener elementos en posiciones específicas de la matriz.
Primero, debemos comprender Elasticsearch 不是以传统的方式存储数组y, en lugar de ello, tratar cada elemento como un valor independiente. Por lo tanto, no podemos acceder directamente a un elemento específico de la matriz simplemente mediante un subíndice.
Hay varias formas de solucionar este problema:
Uso de una canalización de preprocesamiento : creando una canalización de preprocesamiento que descompone la matriz y produce un nuevo campo para cada elemento. Este enfoque es muy intuitivo y nos permite acceder fácilmente a elementos en cualquier posición particular.
Utilice el tipo de datos anidado : para matrices complejas que necesitan preservar la relación entre sus elementos, el tipo de datos anidado es una opción muy eficaz. Esto nos permite realizar consultas más complejas en cada objeto de la matriz y preservar la relación entre ellos.
Ambos metodos tienen sus ventajas y desventajas. El método a elegir depende de sus necesidades específicas y de su estructura de datos. El esquema de canalización de preprocesamiento es adecuado para aquellos escenarios en los que desea mantener los datos simples y tener acceso directo a los elementos de la matriz. El tipo de datos anidados es adecuado para escenarios más complejos que requieren mantener relaciones entre objetos de matriz.
En cualquier caso, es fundamental comprender su estructura de datos y cómo la maneja Elasticsearch. Espero que a través de este artículo tenga una comprensión más profunda del procesamiento de matrices de Elasticsearch y pueda resolver problemas relacionados con matrices de manera más efectiva.
Al final, no importa el método que elijas, asegúrate de probar y verificar la integridad y exactitud de los datos con frecuencia. De esta manera, puede asegurarse de obtener los resultados esperados en producción y evitar posibles problemas causados por una mala interpretación de las estructuras de datos.
Lectura recomendada
¡Primer lanzamiento en toda la red! De 0 a 1 vídeo de autorización de Elasticsearch 8.X
Peso pesado | Lista de cognición de la metodología Dead Elasticsearch 8.X
Productos secos | Elasticsearch Explicación detallada del tipo anidado
Selección anidada de Elasticsearch, ¡lea este artículo primero!
Productos secos | Elasticsearch Solución de tamaño de matriz anidada, ¡todo de una sola vez!
Productos secos | Desmontar un problema de consulta compleja de tipo anidado de Elasticsearch

¡Adquiere más productos secos más rápido y en menos tiempo!
¡Mejore con casi 2000+ entusiastas de Elastic en todo el mundo!

¡Uno puede ir rápido, pero un grupo puede llegar más lejos!