Fuente | Think Tank de innovación colaborativa de IA
Los agentes autónomos han sido un tema de investigación destacado en el mundo académico. Las investigaciones anteriores en esta área generalmente se centraban en entrenar agentes con conocimientos limitados en entornos aislados, que difieren mucho del proceso de aprendizaje humano, lo que dificulta que los agentes logren una toma de decisiones similar a la humana.
Recientemente, los modelos de lenguaje a gran escala (LLM) han demostrado un gran potencial para lograr inteligencia a nivel humano al capturar grandes cantidades de conocimiento de la red. Esto ha provocado un aumento en el estudio de agentes autónomos basados en LLM. Para aprovechar al máximo el potencial de LLM, los investigadores diseñaron diferentes arquitecturas de agentes adecuadas para diferentes aplicaciones.
Portal de prueba de investigación de modelos grandes
Portal GPT-4 (sin muro, se puede probar directamente, si encuentra un punto de advertencia avanzado en el navegador/continúa visitando): ¡
Hola, GPT4!
En este artículo, proporcionamos un estudio exhaustivo de estos estudios, proporcionando una revisión sistemática del campo de los agentes autónomos desde una perspectiva holística. Más específicamente, nuestro enfoque está en construir agentes basados en LLM, para lo cual proponemos un marco unificado que incorpora la mayor parte del trabajo anterior. Además, resumimos varias aplicaciones de agentes de IA basados en LLM en ciencias sociales, ciencias naturales e ingeniería. Finalmente, analizamos estrategias de evaluación comunes para agentes de IA basados en LLM.
Con base en investigaciones previas, también proponemos algunos desafíos y direcciones futuras en este campo. Para realizar un seguimiento del campo y seguir actualizando nuestra encuesta, informamos en https://github.com/Paitesanshi/LLM-Agent-Survey.
1. Antecedentes
Los agentes autónomos se han considerado durante mucho tiempo como un camino prometedor hacia la inteligencia artificial general (AGI), capaz de completar tareas mediante planificación e instrucciones autónomas.
En paradigmas anteriores, la función política que determina las acciones del agente se concibe a través de heurísticas y posteriormente se refina a través de la participación en el entorno [101, 86, 120, 55, 9, 116]. Pero existe una brecha clara: estas funciones políticas a menudo no logran replicar la competencia a nivel humano, especialmente en entornos de campo abierto sin restricciones. Esta discrepancia puede atribuirse a posibles imprecisiones inherentes al diseño heurístico y al conocimiento limitado proporcionado por el entorno de formación.
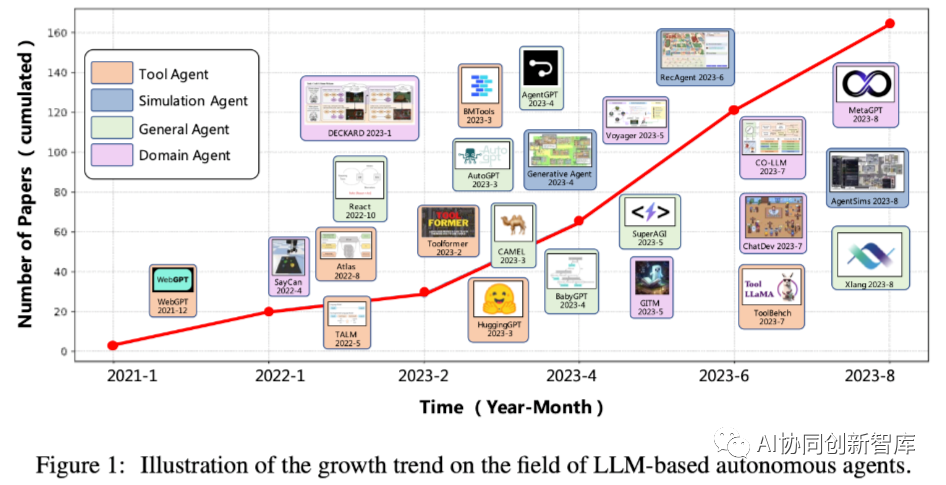
En los últimos años, los grandes modelos de lenguaje (LLM) han logrado un éxito notable, demostrando su potencial para lograr una inteligencia similar a la humana [108, 116, 9, 4, 130, 131]. Esta capacidad proviene de la utilización de conjuntos de datos de entrenamiento sintéticos junto con una gran cantidad de parámetros del modelo. Impulsado por esta capacidad, ha habido una tendencia floreciente en los últimos años (consulte la Figura 1 para ver las tendencias de crecimiento en este campo) en la que los LLM se utilizan como coordinadores centrales para la creación de agentes autónomos [19, 125, 123, 115, 119, 161]. .
Estos métodos tienen como objetivo imitar procesos de toma de decisiones similares a los humanos, proporcionando así un camino hacia sistemas de IA más complejos y adaptables.
Siguiendo la dirección de los agentes autónomos basados en LLM, se han diseñado muchos modelos prometedores, centrándose en mejorar las capacidades fundamentales de los LLM, como la memoria y la planificación, para que puedan estimular las acciones humanas y emprender hábilmente una serie de tareas.
Sin embargo, estos modelos se propusieron de forma independiente y se han realizado esfuerzos limitados para resumirlos y compararlos de manera integral. Es crucial realizar un análisis resumido completo del trabajo existente basado en LLM sobre agentes autónomos, lo cual es importante para una comprensión integral del campo y tiene implicaciones para investigaciones futuras.
En este artículo, llevamos a cabo un estudio exhaustivo del campo de los agentes autónomos basados en LLM. Específicamente, organizamos nuestra encuesta a partir de tres aspectos de la construcción, aplicación y evaluación de agentes autónomos basados en LLM.
Para la construcción de agentes, proponemos un marco unificado que consta de cuatro componentes:
-
El módulo de perfil que representa las propiedades del agente.
-
Módulo de memoria para almacenar información histórica.
-
Un módulo de planificación para desarrollar una estrategia para acciones futuras.
-
Módulos de acción para ejecutar decisiones de planificación
Al deshabilitar uno o más módulos, la mayoría de los estudios previos pueden verse como ejemplos concretos de este marco.
Después de presentar los módulos de Agent típicos, también resumimos las estrategias de ajuste más utilizadas para mejorar la adaptabilidad de los Agentes a diferentes escenarios de aplicaciones. Además de los agentes de construcción, describimos aplicaciones potenciales de agentes autónomos, explorando cómo estos agentes pueden mejorar los campos de las ciencias sociales, las ciencias naturales y la ingeniería. Finalmente, discutimos métodos para evaluar agentes autónomos, centrándonos en estrategias subjetivas y objetivas.
En conclusión, esta encuesta proporciona una revisión sistemática y establece una taxonomía clara para la investigación existente en el campo de los agentes autónomos basados en LLM. Se analiza principalmente desde tres aspectos : construcción del agente, aplicación del agente y evaluación del agente .
Sobre la base de estudios previos, identificamos varios desafíos en este campo y discutimos posibles direcciones futuras. Creemos que este campo aún se encuentra en sus primeras etapas, por lo tanto, mantenemos un repositorio Github para realizar un seguimiento de las investigaciones en este campo.
https://github.com/Paitesanshi/LLM-Agent-Survey.
2 Construcción de agente autónomo basado en LLM
Se espera que los agentes autónomos basados en LLM completen de manera eficiente diferentes tareas basadas en las habilidades humanas de LLM. Para lograr este objetivo, hay dos aspectos importantes, a saber:
(1) qué arquitectura debe diseñarse para utilizar mejor LLM;
(2) cómo aprender los parámetros de la arquitectura.
En términos de diseño arquitectónico, sintetizamos sistemáticamente la investigación existente y finalmente formamos un marco integral y unificado.
En cuanto al segundo aspecto, resumimos tres estrategias comúnmente utilizadas, que incluyen:
(1) aprender de ejemplos, donde el modelo se ajusta en función de un conjunto de datos cuidadosamente seleccionado;
(2) aprender de la retroalimentación ambiental, aprovechando la interacción en tiempo real y observación;
(3) aprender de la retroalimentación humana, utilizando la experiencia y la intervención humanas para mejorar.
2.1 Diseño de arquitectura del agente
Los avances recientes en modelos de lenguaje (LLM) han demostrado su potencial para una amplia gama de tareas. Sin embargo, basándose únicamente en LLM, es difícil implementar agentes autónomos de manera efectiva debido a sus limitaciones arquitectónicas. Para cerrar esta brecha, trabajos anteriores han desarrollado una serie de módulos para inspirar y mejorar la capacidad de los LLM para crear agentes autónomos.
En esta sección, proponemos un marco unificado para resumir las arquitecturas propuestas en trabajos anteriores. Específicamente, la estructura general de nuestro marco se muestra en la Figura 2, que consta de un módulo de perfil, un módulo de memoria, un módulo de planificación y un módulo de ejecución.
-
El propósito del módulo de elaboración de perfiles es identificar el rol del Agente.
-
El módulo de memoria y planificación coloca al agente en un entorno dinámico, permitiéndole recordar acciones pasadas y planificar acciones futuras.
-
El módulo de acción es responsable de transformar la decisión del agente en un resultado específico.
Entre estos módulos, el módulo de creación de perfiles afecta a los módulos de memoria y planificación, y estos tres módulos juntos afectan al módulo de ejecución.

2.1.1 Módulo de creación de perfiles
Los agentes autónomos suelen realizar tareas asumiendo roles específicos, como desarrolladores de código, profesores y expertos en el dominio [113, 35]. El módulo de creación de perfiles tiene como objetivo definir los perfiles de funciones del agente, que generalmente se escriben en mensajes para afectar el comportamiento de LLM. En el trabajo existente, existen tres estrategias comúnmente utilizadas para generar archivos de configuración del agente.
-
método hecho a mano
-
Método de generación basado en LLM
-
Método de alineación del conjunto de datos
Método manual : en este método, el archivo de configuración del Agente se especifica manualmente. Por ejemplo, si uno quiere diseñar un Agente con diferentes personalidades, puede describir al Agente con "Eres extrovertido" o "Eres introvertido".
El método de elaboración manual se ha utilizado en muchos trabajos anteriores para instruir el archivo de elaboración de perfiles del agente. Específicamente, Agente Generativo [156] describe un agente mediante información como nombre, objetivo y relación con otros agentes. MetaGPT [58], ChatDev [113] y Autocolaboración [29] predefinen varios roles y sus correspondientes responsabilidades en el desarrollo de software, y asignan manualmente diferentes perfiles a cada Agente para facilitar la colaboración. Un trabajo reciente [27] demostró que la asignación manual de diferentes personas puede afectar significativamente la generación de LLM, incluida la toxicidad. Al especificar personas específicas, se demostró que eran más tóxicas que las personas predeterminadas.
En términos generales, el método manual es muy flexible. Sin embargo, puede resultar laborioso, especialmente cuando se trata de una gran cantidad de agentes.
El método basado en la generación de LLM : en este método, el archivo de configuración del Agente se genera automáticamente en función de LLM.
Normalmente, comienza proporcionando indicaciones manuales, describiendo reglas de generación específicas y aclarando la composición y propiedades de los perfiles de los agentes en la población objetivo. Además, es posible especificar el perfil inicial del Agente como ejemplo de algunas tomas. Estos perfiles sirven luego como base para generar otra información de agentes basada en el LLM. Por ejemplo, RecAgent [134] primero crea perfiles semilla para una pequeña cantidad de agentes elaborando manualmente detalles como edad, sexo, características personales y preferencias de películas. Luego, aprovecha ChatGPT para generar más perfiles de agentes basados en la información inicial. Cuando la cantidad de agentes es grande, el método de generación de LLM puede ahorrar mucho tiempo, pero puede carecer de un control preciso sobre los archivos de configuración generados.
Método de alineación del conjunto de datos : en este método, los perfiles de los agentes se crean en función de conjuntos de datos del mundo real. La información básica sobre humanos reales se utiliza total o selectivamente para describir al Agente.
Por ejemplo, el agente en [5] se inicializa en función de los antecedentes demográficos de los participantes en un conjunto de datos de una encuesta del mundo real. El método de alineación del conjunto de datos puede capturar con precisión los atributos de multitudes reales, cerrando efectivamente la brecha entre el mundo virtual y el mundo real.
Además de la estrategia de generación de perfiles, otra cuestión importante es cómo especificar la información utilizada para describir (elaborar perfiles) del Agente. Ejemplos de información incluyen información demográfica, que describe las características de una población (por ejemplo, edad, género e ingresos), información psicográfica, que indica la personalidad de un agente, e información social, que describe las relaciones entre agentes.
La selección de información para configurar el Agente depende en gran medida de escenarios de aplicación específicos. Por ejemplo, si la investigación se centra en el comportamiento social de los usuarios, entonces la información del perfil social se vuelve crucial. Sin embargo, no siempre es sencillo establecer la relación entre la información del perfil y las tareas posteriores. Una posible solución es ingresar inicialmente toda la información de perfil posible y luego desarrollar métodos automáticos (por ejemplo, basados en LLM) para seleccionar el método más apropiado.
2.1.2 Módulo de memoria
El módulo de memoria juega un papel muy importante en la construcción de AI Agent. Almacena información obtenida del entorno y utiliza la memoria registrada para facilitar acciones futuras. Los módulos de memoria pueden ayudar a los agentes a acumular experiencia, evolucionar y actuar de una manera más consistente, racional y eficiente.
Esta sección proporciona una descripción general completa de los módulos de memoria, centrándose en su estructura, formato y funcionamiento.
estructura de la memoria
Los agentes autónomos basados en LLM suelen combinar los principios y mecanismos de la ciencia cognitiva para estudiar el proceso de la memoria humana. La memoria humana sigue un proceso general, desde la memoria sensorial, que registra la información sensorial, hasta la memoria a corto plazo, que mantiene la información brevemente, y la memoria a largo plazo, que consolida la información a lo largo del tiempo.
Al diseñar arquitecturas de memoria para agentes de IA, los investigadores se inspiran en estos aspectos de la memoria humana, al tiempo que reconocen diferencias clave en las capacidades.
La memoria a corto plazo en los agentes AI es similar a las capacidades de aprendizaje admitidas en las restricciones de la ventana de contexto de la arquitectura Transformer. La memoria a largo plazo es similar al almacenamiento vectorial externo que los agentes pueden consultar y recuperar rápidamente según sea necesario.
Por lo tanto, cuando los humanos transfieren gradualmente información perceptiva del almacenamiento a corto plazo al almacenamiento a largo plazo mediante refuerzo, AI Agent puede diseñar un proceso de escritura y lectura más optimizado entre sus sistemas de memoria implementados algorítmicamente.
Al simular aspectos de la memoria humana, los diseñadores pueden crear agentes que exploten los procesos de la memoria para mejorar el razonamiento y la autonomía. A continuación, presentamos dos estructuras de memoria de uso común.
• Memoria unificada . En esta estructura, la memoria se organiza en un marco único y no existe distinción entre memoria a corto y largo plazo. El marco tiene una interfaz unificada para lectura, escritura y reflexión de la memoria. Por ejemplo:
-
Atlas [65] almacena una memoria de documentos basada en vectores densos genéricos generados a partir de un modelo de codificador dual.
-
Augmented-LLM [121] adopta un almacenamiento externo unificado para su memoria, al que se puede acceder mediante sugerencias.
-
Voyager [133] también aprovecha una arquitectura de memoria unificada para agregar habilidades de diversa complejidad en un repositorio central. Durante la generación de código, las habilidades se pueden indexar en función de su relevancia de coincidencia y recuperación.
-
ChatLog [132] mantiene un flujo de memoria unificado, lo que permite que el modelo retenga información histórica importante y ajuste adaptativamente el propio agente para diferentes entornos.
• Memoria híbrida . La memoria híbrida distingue claramente entre funciones a corto y largo plazo. El componente a corto plazo amortigua temporalmente las percepciones recientes, mientras que la memoria a largo plazo consolida información importante a lo largo del tiempo. Por ejemplo:
-
[109] adopta una estructura de memoria de doble capa para almacenar la experiencia y el conocimiento del Agente, incluida la memoria a largo plazo y la memoria a corto plazo. La memoria a largo plazo se utiliza para retener la comprensión y las generalizaciones del mundo en su conjunto, mientras que la memoria a corto plazo se utiliza para retener la comprensión y las anotaciones del sujeto sobre eventos individuales.
-
AgentSims [89] también implementa una arquitectura de memoria híbrida. La memoria a largo plazo utiliza una base de datos vectorial para almacenar y recuperar de manera eficiente la memoria episódica de cada agente. Los LLM se utilizan para implementar la memoria a corto plazo y realizar tareas de abstracción, verificación, corrección y simulación.
-
En GITM [161], la memoria a corto plazo almacena la trayectoria actual, mientras que la memoria a largo plazo almacena planes de referencia resumidos de trayectorias anteriores exitosas.
La memoria a largo plazo proporciona conocimientos estables, mientras que la memoria a corto plazo permite una planificación flexible. -
Reflexion [125] aprovecha las ventanas deslizantes a corto plazo para capturar comentarios recientes, combinadas con un almacenamiento persistente a largo plazo para retener información condensada. Esta combinación permite la utilización de experiencias instantáneas detalladas y abstracciones de alto nivel.
-
SCM [84] activa selectivamente el conocimiento a largo plazo más relevante, combinado con la memoria a corto plazo, lo que permite el razonamiento en conversaciones contextuales complejas.
-
SWIFTSAGE [87] utiliza un pequeño LM para gestionar la memoria a corto plazo para generar intuición y pensamiento asociativo, mientras utiliza un LLM para procesar la memoria a largo plazo para generar una toma de decisiones deliberada.
formato de memoria
La información se puede almacenar en la memoria utilizando una variedad de formatos, cada uno con ventajas únicas. Por ejemplo, el lenguaje natural puede preservar información semántica completa, mientras que la integración puede mejorar la eficiencia de la memorización de la lectura. A continuación, presentamos cuatro formatos de memoria de uso común.
• Lenguaje natural . El uso del lenguaje natural para el razonamiento/programación de tareas permite un almacenamiento/acceso flexible y semánticamente rico. Por ejemplo, Reflexion [125] almacena comentarios de experiencias en lenguaje natural en una ventana deslizante. Voyager [133] utiliza descripciones en lenguaje natural para representar habilidades en el juego Minecraft, que se almacenan directamente en la memoria.
• Integrado . El uso de incrustaciones para almacenar información puede mejorar la recuperación de la memoria y la eficiencia de la lectura. Por ejemplo, MemoryBank [158] codifica cada segmento de memoria como un vector de incrustación, creando un corpus indexado para su recuperación. GITM [161] representa planes de referencia como incorporaciones para facilitar su comparación y reutilización. ChatDev [113] codifica historiales de diálogo como vectores para su recuperación.
• Base de datos . Las bases de datos externas proporcionan almacenamiento estructurado y el almacenamiento se puede manipular con operaciones eficientes y completas. Por ejemplo, ChatDB [61] utiliza una base de datos como almacenamiento a largo plazo para símbolos. Las declaraciones SQL generadas por el controlador LLM pueden operar con precisión en la base de datos.
• Listas estructuradas . Otro tipo de formato de memoria es una lista estructurada, a partir de la cual la información se puede transmitir de una manera más compacta y eficiente. Por ejemplo, GITM [161] almacena listas de acciones para subobjetivos en una estructura de árbol jerárquica. La jerarquía captura explícitamente la relación entre las metas y los planes correspondientes. RET-LLM [102] inicialmente convierte oraciones de lenguaje natural en frases tripletes, que luego se almacenan en la memoria.
operación de memoria
Hay tres operaciones clave de la memoria, incluida la lectura de la memoria, la escritura de la memoria y la autorreflexión, para interactuar con el entorno externo.
• Lectura de memoria . La clave para la lectura de la memoria es recuperar información de la memoria. Generalmente, existen tres criterios comúnmente utilizados para la extracción de información: actualidad, relevancia e importancia [109]. Es más probable que se recuperen recuerdos recientes, relevantes e importantes. Formalmente, derivamos las siguientes ecuaciones para extraer información:
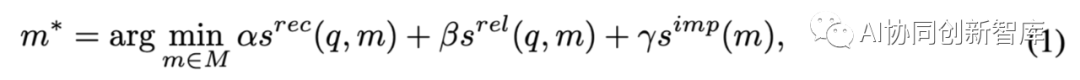
donde q es una consulta, por ejemplo, la tarea que el agente debe manejar o el contexto en el que se encuentra el agente. M es el conjunto de todos los recuerdos. s_rec( ), s_rel( ) y s_imp( ) son funciones de puntuación que miden la actualidad, relevancia e importancia de la memoria m. Cabe señalar que s_imp solo refleja las características de la propia memoria, por lo que no tiene nada que ver con la consulta. α, β y γ son parámetros de equilibrio. Al asignarles diferentes valores, se puede obtener una amplia variedad de estrategias de lectura de recuerdos. Por ejemplo, al establecer α = γ = 0, muchos estudios [102, 161, 133, 49] solo consideran la puntuación de relevancia de las lecturas de memoria. Al especificar α = β = γ = 1,0, [109] pondera las tres métricas anteriores por igual para extraer información de la memoria.
• Escritura en memoria . Los agentes pueden adquirir conocimientos y experiencia almacenando información importante en la memoria. Durante el proceso de redacción, existen dos problemas potenciales que deben abordarse cuidadosamente. Por un lado, es crucial abordar cómo almacenar información similar a la memoria existente (es decir, replicación de la memoria). Por otro lado, es importante considerar cómo eliminar información cuando una memoria alcanza su límite de almacenamiento (es decir, desbordamiento de la memoria). Estos problemas pueden abordarse mediante las siguientes estrategias.
(1) Duplicación de memoria. Para integrar información similar, se han desarrollado varios métodos para integrar registros nuevos y anteriores.
Por ejemplo, en [108], las secuencias de acciones exitosas relacionadas con el mismo subobjetivo se almacenan en una lista. Una vez que la lista alcanza el tamaño N (=5), todas las secuencias que contiene se condensan en una solución de planificación unificada utilizando LLM. La secuencia original en la memoria se reemplaza por la secuencia recién generada. Augmented-LLM [121] agrega información duplicada contando y acumulando para evitar el almacenamiento redundante. Reflexion [125] integra comentarios relevantes en conocimientos de alto nivel, reemplazando la experiencia cruda.
(2) Desbordamiento de memoria. Para poder escribir información en la memoria cuando está llena, se han ideado diferentes métodos para eliminar la información existente para continuar con el proceso de la memoria. Por ejemplo, en ChatDB [61], la memoria se puede eliminar explícitamente mediante orden del usuario. RET-LLM [102] utiliza un búfer circular de tamaño fijo como memoria, sobrescribiendo las entradas más antiguas según un esquema de primero en entrar, primero en salir (FIFO).
• Reflexión de la memoria . Esta acción tiene como objetivo darle al agente la capacidad de condensar e inferir información más avanzada, o de verificar y corregir su propio comportamiento de forma autónoma. Ayuda a los agentes a comprender los atributos, preferencias, objetivos y conexiones propios y de los demás, guiando así su comportamiento. Investigaciones anteriores han examinado varias formas de reflexión de la memoria, a saber:
(1) Autoresumen. La reflexión se puede utilizar para condensar la memoria de un agente en conceptos de nivel superior. En [109], un agente es capaz de resumir experiencias pasadas almacenadas en la memoria en conocimientos más amplios y abstractos. En concreto, el agente primero genera tres preguntas clave basadas en su memoria reciente. Estas preguntas se utilizaron luego para consultar la memoria en busca de información relevante. Con base en la información obtenida, el agente genera cinco ideas que reflejan el pensamiento de alto nivel del agente. Además, la reflexión puede ocurrir de forma jerárquica, lo que significa que se pueden generar conocimientos basados en los conocimientos existentes.
(2) Autovalidación. Otra forma de reflexión implica evaluar la eficacia de las acciones de un agente. En [133], el Agente tiene como objetivo completar tareas en Minecraft. Durante cada ronda de ejecución, el agente utiliza GPT-4 como crítico para evaluar si la operación actual es suficiente para lograr la tarea deseada. Si la tarea falla, el crítico proporciona retroalimentación sugiriendo formas de completarla. Replug [124] emplea un esquema de entrenamiento para adaptar aún más el modelo de recuperación al modelo del idioma de destino. Específicamente, utiliza el modelo de lenguaje como función de puntuación para evaluar la contribución de cada documento a reducir la perplejidad del modelo de lenguaje. Los parámetros del modelo de recuperación se actualizan minimizando el sesgo de KL entre las probabilidades de recuperación y las puntuaciones del modelo de lenguaje. Este enfoque evalúa eficazmente la relevancia de los resultados de la recuperación y realiza ajustes en función de la retroalimentación del modelo de lenguaje.
(3) Autocorrección. En este tipo de reflexión, el agente puede corregir su comportamiento incorporando retroalimentación del entorno. En MemPrompt [96], el modelo puede ajustar su comprensión de las tareas en función de los comentarios de los usuarios para generar respuestas más precisas. En [137], se diseña un agente para jugar Minecraft, que realiza acciones de acuerdo con un plan predefinido. Cuando el plan falla, el agente reconsidera su plan y lo cambia para continuar con el proceso de exploración.
(4) Empatía. Los reflejos de la memoria también se pueden utilizar para mejorar la empatía de un agente. En [49], el agente es un chatbot, pero genera expresiones considerando el proceso cognitivo humano. Después de cada ronda de conversación, el agente evalúa el impacto de sus palabras en el oyente y actualiza su percepción del estado del oyente.
2.1.3 Módulo de Planificación
Cuando los humanos se enfrentan a una tarea compleja, primero la dividen en subtareas simples y luego resuelven cada subtarea una por una. El módulo de planificación permite al agente basado en LLM pensar y planificar para resolver tareas complejas, lo que hace que el agente sea más completo, potente y confiable.
A continuación se describen dos tipos de módulos de planificación.
sin planificación de retroalimentación
En este enfoque, el agente no recibe retroalimentación durante el proceso de planificación. Estos planes se producen de manera holística. A continuación se presentan muchas estrategias de planificación representativas.
• Descomposición de submetas . Algunos investigadores pretenden pensar el LLM paso a paso para resolver tareas complejas.
-
Las cadenas de pensamiento [138] se han convertido en una técnica estándar para permitir que modelos grandes resuelvan tareas complejas. Propone un método de indicaciones simple pero eficaz, que resuelve gradualmente problemas de razonamiento complejos con una pequeña cantidad de ejemplos de lenguaje en la indicación.
-
Zero-shot-CoT [72] permite a LLM generar de forma autónoma el proceso de razonamiento de problemas complejos al incitar al modelo a "pensar paso a paso", y demuestra que LLM es un buen razonador de tiro cero a través de experimentos.
-
En [63], LLM actúa como un planificador de tiro cero para tomar decisiones basadas en objetivos en un entorno de simulación interactivo.
-
[53] utilizan además objetos ambientales y relaciones entre objetos como entradas adicionales para la generación de planes de acción LLM, proporcionando al sistema la percepción del entorno circundante para generar planes.
-
ReWOO [147] introdujo un paradigma que desacopla la planificación de las observaciones externas, lo que permite al LLM actuar como un planificador, generando directamente una serie de planes independientes sin retroalimentación externa.
En resumen, las capacidades de planificación y toma de decisiones de los modelos de lenguaje grandes mejoran enormemente al descomponer tareas complejas en subtareas ejecutables.
• Pensamiento de múltiples caminos . Basándose en CoT, algunos investigadores creen que el proceso de pensamiento y razonamiento humano es una estructura de árbol con múltiples caminos que conducen al resultado final.
-
CoT autoconsistente (CoT-SC) [135] supone que cada pregunta compleja tiene múltiples formas de pensar para derivar la respuesta final. Específicamente, CoT se utiliza para generar varios caminos y respuestas para el razonamiento, entre las cuales se seleccionará la respuesta con más ocurrencias como resultado final.
-
Tree of Thought (ToT) [150] postula que los humanos tienden a pensar en forma de árbol cuando toman decisiones sobre problemas complejos con fines de planificación, donde cada nodo del árbol es un estado mental. Utiliza LLM para generar evaluaciones o votos mentales, que se pueden buscar mediante BFS o DFS. Estos métodos mejoran el desempeño de los LLM en tareas de razonamiento complejas.
-
[153] analiza el problema de programación en lenguaje restringido. Genera scripts adicionales y los filtra para mejorar la calidad de la generación de scripts. Entre los pocos scripts generados, la selección del script está determinada por (1) la similitud del coseno entre el script y el objetivo, y (2) si el script contiene palabras clave de restricción del objetivo.
-
DEPS [137] utiliza un modelo de lenguaje visual como selector para elegir la mejor ruta entre subtareas opcionales.
-
SayCan [2] combina probabilidades de un modelo de lenguaje (probabilidad de que una acción sea útil para una instrucción de alto nivel) con probabilidades de una función de valor (probabilidad de ejecutar con éxito dicha acción) y elige una acción a realizar. Luego agrega la respuesta del robot y consulta el modelo nuevamente para repetir el proceso hasta el final del paso de salida.
En conclusión, el pensamiento de múltiples rutas permite al agente resolver tareas de planificación más complejas, pero también conlleva una carga computacional adicional.
• Planificador externo . Los LLM, incluso con notables capacidades de planificación de tiro cero, son en muchos casos menos confiables que los planificadores tradicionales, especialmente cuando se enfrentan a problemas de planificación a largo plazo específicos de un dominio.
-
LLM+P [90] convierte descripciones en lenguaje natural en un lenguaje de definición de dominio de planificación (PDDL) formal. Luego, el resultado se calcula utilizando un planificador externo y finalmente LLM lo transforma al lenguaje natural. mismo,
-
LLM-DP [24] utiliza LLM para convertir observaciones, el estado mundial actual y los objetos objetivo al formato PDDL. Luego, esta información se pasa a un planificador simbólico externo, que determina efectivamente la secuencia óptima de acciones desde el estado actual hasta el estado objetivo.
-
MRKL [71] es una arquitectura modular de IA neuronal-simbólica en la que un LLM procesa el texto de entrada, lo enruta a cada experto y luego lo pasa a través de la salida del LLM.
-
CO-LLM [156] sostiene que LLM es bueno para generar planes de alto nivel, pero no bueno para el control de bajo nivel. Utilizan un planificador de bajo nivel diseñado heurísticamente para ejecutar de manera sólida operaciones básicas basadas en un plan de alto nivel. Con planificadores expertos en dominios de subtareas, LLM puede navegar en la planificación de tareas complejas en dominios específicos.
El conocimiento generalizado de un agente basado en LLM es difícil para realizar tareas de manera óptima en todos los dominios, pero combinarlo con el conocimiento experto de un planificador externo puede mejorar efectivamente el desempeño.
planificación con retroalimentación
Cuando los humanos abordan tareas, las experiencias de éxito o fracaso los llevan a reflexionar sobre sí mismos y mejorar su capacidad de planificación. Estas experiencias a menudo se adquieren y acumulan sobre la base de retroalimentación externa. Para simular esta capacidad humana, muchos investigadores han diseñado módulos de planificación que pueden recibir retroalimentación del entorno, los humanos y los modelos, mejorando significativamente la capacidad de planificación de los agentes.
• Retroalimentación ambiental . En muchos estudios, los agentes hacen planes basados en la retroalimentación ambiental. Por ejemplo:
-
ReAct [151] expande el espacio de acción del agente en una colección de espacios de acción y lenguaje. El razonamiento explícito y las acciones se realizan de forma secuencial, y cuando la retroalimentación de las acciones no tiene una respuesta correcta, se vuelve a realizar el razonamiento hasta obtener una respuesta correcta.
-
Voyager [133] auto-refina un script de generación de agentes operando con tres tipos de retroalimentación hasta que pasa la autovalidación y se almacena en un repositorio de habilidades.
-
Ghost [161], DEPS [137] pueden recibir retroalimentación del entorno, incluida información sobre el estado actual del agente en el entorno e información sobre el éxito o el fracaso de cada acción realizada. Al incorporar esta retroalimentación, los agentes pueden actualizar su comprensión del entorno, mejorar sus estrategias y ajustar su comportamiento.
-
Basado en el planificador de disparo cero [63], la repetición [117] utiliza información de error de precondicionamiento para detectar si el agente puede completar el plan actual. También utiliza la información de requisitos previos para volver a solicitar al LLM que complete el control de circuito cerrado.
-
Inner Monologue [64] agrega tres tipos de retroalimentación ambiental a la instrucción: ejecución exitosa de subtareas, descripción de escena pasiva y descripción de escena activa, lo que permite la planificación de circuito cerrado para agentes basados en LLM.
-
Los consejos introspectivos [17] permiten a LLM realizar una introspección a través de la historia de la retroalimentación ambiental.
-
LLM Planner [127] introduce un algoritmo de replanificación basado en bases que actualiza dinámicamente los planes generados por LLM cuando se encuentran discrepancias de objetos y planes inalcanzables durante la finalización de la tarea.
-
En Progprompt [126], las afirmaciones se incorporan a los scripts generados para proporcionar información sobre el estado del entorno, lo que permite la recuperación de errores si no se cumplen las condiciones previas para una operación.
En conclusión, la retroalimentación ambiental es un indicador directo del éxito o fracaso de la planificación, mejorando así la eficiencia de la planificación de circuito cerrado.
• Retroalimentación humana . Los agentes pueden hacer planes con la ayuda de comentarios humanos reales. Esta señal puede ayudar al agente a alinearse mejor con el entorno real y también a aliviar el problema de las alucinaciones.
-
Como se menciona en Voyager [133], los humanos pueden actuar como críticos y pedirle a Voyager que cambie la ronda anterior de código a través de retroalimentación multimodelo.
-
OpenAGI [51] propone un mecanismo de aprendizaje por refuerzo con retroalimentación de tareas (RLTF) que aprovecha las evaluaciones manuales o comparativas para mejorar las capacidades de los agentes basados en LLM.
• Comentarios del modelo . El modelo de lenguaje puede actuar como crítico para criticar y mejorar los planes generados.
-
Self-Refine [97] introdujo el mecanismo Self-Refine para mejorar el resultado de LLM a través de retroalimentación y mejora iterativas. Específicamente, LLM se utiliza como generador, proveedor de retroalimentación y refinador. Primero, se usa un generador para generar una salida inicial, luego se usa un proveedor de retroalimentación para proporcionar retroalimentación específica y procesable a la salida y, finalmente, se usa un refinador para mejorar la salida usando la retroalimentación. La capacidad de razonamiento del LLM se mejora mediante un circuito de retroalimentación iterativo entre el generador y el crítico.
-
La reflexión [125] es un marco para aumentar los agentes con retroalimentación verbal, que introduce un mecanismo de memoria. Los participantes primero generan acciones, luego los evaluadores generan evaluaciones y finalmente generan resúmenes de experiencias pasadas a través de un modelo de autorreflexión. Los resúmenes se almacenarán en la memoria para mejorar aún más la generación de agentes con experiencia pasada. El modelo mundial generalmente se refiere a la representación interna del entorno por parte del agente, que se utiliza para la simulación interna y la abstracción del entorno. Ayuda al agente a razonar, planificar y predecir el impacto de diferentes acciones en el medio ambiente.
-
RAP [57] implica el uso de un LLM como modelo mundial y agente. Durante la inferencia, el agente construye un árbol de inferencia, mientras que el modelo mundial proporciona recompensas como retroalimentación. El agente realiza MCTS (Monte Carlo Tree Search) en el árbol de razonamiento para obtener el plan óptimo.
-
REX [103] introduce un enfoque MCTS acelerado en el que la retroalimentación de recompensa la proporciona el entorno o LLM.
-
Los consejos introspectivos [17] se pueden aprender de demostraciones de otros modelos expertos.
-
En el marco MAD (Debate Multiagente) [83], múltiples sujetos expresan sus argumentos en forma de “ojo por ojo”, y un juez gestiona el proceso de debate para llegar a una solución final. El marco MAD fomenta el pensamiento divergente en el LLM, lo que facilita tareas que requieren una reflexión profunda.
En resumen, el módulo de planificación es muy importante para que los agentes resuelvan tareas complejas. Si bien la retroalimentación externa siempre es útil para una planificación inteligente, no siempre está ahí. Tanto la planificación con retroalimentación como la sin retroalimentación son importantes para crear agentes basados en LLM.
2.1.4 Módulo de acción
El módulo de acción tiene como objetivo traducir las decisiones del agente en resultados concretos. Interactúa directamente con el entorno y determina la eficacia del agente para completar la tarea.
Esta sección proporciona una descripción general de los módulos de acción, centrándose en los objetivos, las estrategias, el espacio y la influencia de la acción.
objetivo de acción
El objetivo de la acción se refiere al objetivo que se espera lograr mediante la ejecución de la acción y generalmente lo especifica la persona real o el propio agente. Los tres objetivos de acción principales incluyen la finalización de la misión, la interacción del diálogo, la exploración del entorno y la interacción.
• Misión cumplida . El objetivo básico de un módulo de acción es realizar una tarea específica de manera lógica. Los tipos de tareas en diferentes escenarios son diferentes, por lo que se requiere el diseño necesario del módulo de acción. Por ejemplo:
-
Voyager [133] utiliza LLM como módulo de acción para guiar a los agentes a explorar y recopilar recursos para completar tareas complejas en Minecraft.
-
GITM [161] descompone toda la tarea en acciones ejecutables, lo que permite al agente completar las actividades diarias paso a paso.
-
Los agentes generativos [109] realizan de manera similar secuencias de acciones ejecutables descomponiendo jerárquicamente la planificación de tareas de alto nivel.
• Interacción de diálogo . La capacidad de los agentes autónomos basados en LLM para entablar conversaciones en lenguaje natural con humanos es crucial, ya que los usuarios humanos a menudo necesitan obtener el estado de agente o completar tareas colaborativas con agentes. Trabajos anteriores han mejorado la capacidad de interacción de diálogo de agentes en diferentes dominios. Por ejemplo:
-
ChatDev [113] lleva a cabo conversaciones relevantes entre empleados de empresas de desarrollo de software.
-
DERA [104] mejora las interacciones de diálogo de manera iterativa.
-
[31, 139] explotan diálogos interactivos entre diferentes sujetos, animándolos así a compartir opiniones similares sobre un tema.
• Entorno para explorar e interactuar . Los agentes pueden adquirir nuevos conocimientos interactuando con el entorno y mejorarse resumiendo experiencias recientes. De esta forma, los agentes pueden generar nuevos comportamientos cada vez más adaptados al entorno y coherentes con el sentido común. Por ejemplo:
-
Voyager [133] permite el aprendizaje continuo al permitir que el agente explore en un entorno abierto.
-
El marco de aprendizaje por refuerzo mejorado con memoria (MERL) en SayCan [2] acumula continuamente conocimiento textual y luego ajusta el plan de acción del agente en función de la retroalimentación externa.
-
GITM [161] permite a un agente recopilar continuamente conocimiento textual, ajustando así su comportamiento en función de la retroalimentación ambiental.
estrategia de acción
La estrategia de acción se refiere al método mediante el cual el Agente genera acciones.
En el trabajo existente, estas estrategias podrían ser la recuperación de recuerdos, múltiples rondas de interacción, ajuste de retroalimentación e incorporación de herramientas externas.
• Recuperación de memoria . Las técnicas de recuperación de memoria ayudan a los agentes a tomar decisiones informadas basadas en experiencias almacenadas en módulos de memoria [109, 78, 161].
-
Un agente generativo [109] mantiene un flujo de memoria de conversaciones y experiencias. Cuando se realiza una operación, el segmento de memoria relevante se recupera como entrada condicional al LLM para garantizar la coherencia de la operación.
-
GITM [161] utiliza la memoria para guiar acciones como moverse a ubicaciones descubiertas previamente.
-
CAMEL [78] construye flujos de memoria de experiencias históricas, lo que permite a LLM generar acciones informadas basadas en estos recuerdos.
• Múltiples rondas de interacción . Este enfoque intenta aprovechar el contexto de múltiples rondas de diálogo para permitir que el agente identifique respuestas apropiadas como acciones [113, 104, 31].
-
ChatDev [113] anima a los agentes a realizar acciones basadas en su historial de conversaciones con otros.
-
DERA [104] propuso un nuevo agente de diálogo; durante el proceso de comunicación, el agente investigador puede proporcionar retroalimentación útil para guiar la acción del agente tomador de decisiones.
-
[31] construyeron un sistema de debate de múltiples agentes (MAD), donde cada agente basado en LLM participa en interacciones iterativas, intercambiando desafíos e ideas, con el objetivo final de alcanzar un consenso.
-
ChatCot [20] utiliza un marco de diálogo de múltiples rondas para modelar el proceso de razonamiento de la cadena de pensamiento e integra perfectamente el razonamiento y el uso de herramientas a través de la interacción del diálogo.
• Ajustes de retroalimentación . Se ha demostrado que la eficacia de la retroalimentación humana o la participación en el entorno externo ayuda a los agentes a adaptar y fortalecer sus estrategias de acción [133, 99, 2]. Por ejemplo:
-
Voyager [133] permite a un agente mejorar su política después de experimentar fallas en las acciones o validar una política exitosa utilizando un mecanismo de retroalimentación.
-
El Agente de Aprendizaje Constructivo Interactivo (ICLA) [99] aprovecha los comentarios de los usuarios sobre las acciones iniciales para mejorar los planes de forma iterativa, lo que lleva a políticas más precisas.
-
SayCan [2] emplea un marco de aprendizaje por refuerzo en el que el agente ajusta continuamente las acciones basándose únicamente en la retroalimentación ambiental, lo que permite una mejora automática basada en prueba y error.
• Integrar herramientas externas . Los agentes autónomos basados en LLM se pueden mejorar mediante la introducción de herramientas externas y la ampliación de las fuentes de conocimiento.
Por un lado, el agente puede tener la capacidad de acceder y utilizar varias API, bases de datos, aplicaciones web y otros recursos externos durante la fase de entrenamiento o inferencia. Por ejemplo:
-
Toolformer [119] está capacitado para determinar las API apropiadas para llamar, el momento de esas llamadas y la mejor manera de integrar los resultados devueltos en futuras predicciones de tokens.
-
ChemCrow [8] diseñó un reactivo LLM basado en química que contiene 17 herramientas diseñadas por expertos para realizar tareas que incluyen síntesis orgánica, descubrimiento de fármacos y diseño de materiales.
-
ViperGPT [128] propone un marco de generación de código que ensambla modelos de visión y lenguaje en subrutinas capaces de devolver los resultados de cualquier consulta determinada.
-
HuggingGPT [123] utiliza LLM para conectar varios modelos de IA (por ejemplo, Hugging Face) en la comunidad de aprendizaje automático para resolver tareas de IA. Específicamente, HuggingGPT propone un método de metaaprendizaje para capacitar a LLM para generar fragmentos de código y luego utilizar estos fragmentos para invocar el modelo de IA deseado desde un centro comunitario externo.
Por otro lado, el alcance y la calidad del conocimiento adquirido directamente por un agente se pueden ampliar con la ayuda de fuentes de conocimiento externas. En trabajos anteriores, las fuentes de conocimiento externas incluyen bases de datos, gráficos de conocimiento, páginas web, etc. Por ejemplo:
-
Gorilla [111] puede proporcionar de manera eficiente llamadas API apropiadas porque está capacitado en tres conjuntos de datos de centros de aprendizaje automático adicionales: Torch hub, TensorFlow hub y HuggingFace.
-
WebGPT [105] propone una extensión para incorporar resultados relevantes recuperados de sitios web en sugerencias al usar ChatGPT, lo que permite conversaciones más precisas y oportunas.
-
ChatDB [61] es un asistente de base de datos de inteligencia artificial que utiliza declaraciones SQL generadas por controladores LLM para manipular con precisión bases de datos externas.
-
GITM [161] utiliza LLM para generar resultados interpretables para una tarea de minería de textos empleando un novedoso canal de minería de textos que integra LLM, extracción de conocimientos y módulos de modelado de temas.
espacio de acción
El espacio de acción de un agente basado en LLM se refiere a un conjunto de posibles acciones que un agente puede realizar. Esto proviene de dos fuentes principales:
-
Herramientas externas para ampliar las capacidades de acción
-
Los conocimientos y habilidades propios del agente, como la generación del lenguaje y la toma de decisiones basada en la memoria.
Específicamente, las herramientas externas incluyen motores de búsqueda, bases de conocimiento, herramientas computacionales, otros modelos de lenguaje y modelos de visión. Al interactuar con estas herramientas, el Agente puede realizar diversas operaciones realistas, como recuperación de información, consulta de datos, cálculo matemático, generación de lenguaje complejo y análisis de imágenes. El conocimiento autoadquirido de un agente basado en un modelo de lenguaje puede permitirle planificar, generar lenguaje y tomar decisiones, ampliando aún más su potencial de acción.
• Herramientas externas . Varias herramientas externas o fuentes de conocimiento brindan al Agente capacidades operativas más ricas, incluidas API, base de conocimientos, modelo visual, modelo de lenguaje, etc.
(1) API. El uso de API externas para complementar y ampliar el espacio operativo es un patrón popular en los últimos años. Por ejemplo:
-
HuggingGPT [123] utiliza un motor de búsqueda que convierte las consultas en solicitudes de búsqueda de códigos relevantes.
-
[105, 118] propusieron generar consultas automáticamente para extraer contenido relevante de páginas web externas en respuesta a las solicitudes de los usuarios.
-
TPTU [118] interactúa con el intérprete de Python y el compilador LaTeX para realizar cálculos complejos como operaciones de raíz cuadrada, factoriales y matriciales.
Otro tipo de API es aquella a la que el LLM puede llamar directamente en función del lenguaje natural o la entrada de código. Por ejemplo:
-
ToolFormer [119] es un sistema de transformación de herramientas basado en LLM que puede transformar automáticamente una herramienta determinada en otra herramienta con una función o formato diferente según instrucciones en lenguaje natural.
-
API-Bank [80] es un agente de recomendación de API basado en LLM que puede buscar y generar automáticamente llamadas API apropiadas en varios dominios y lenguajes de programación. API-Bank también proporciona una interfaz interactiva para que los usuarios modifiquen y ejecuten llamadas API generadas.
-
De manera similar, ToolBench [115] es un sistema de generación de herramientas basado en LLM que puede diseñar e implementar automáticamente varias herramientas de utilidad de acuerdo con los requisitos del lenguaje natural. Las herramientas generadas por ToolBench incluyen calculadoras, convertidores de unidades, calendarios, mapas, gráficos y más. Todos estos agentes utilizan API externas como herramientas externas y brindan a los usuarios una interfaz interactiva para modificar y ejecutar fácilmente las herramientas generadas o transformadas.
(2) Base de conocimientos. Conectarse a bases de conocimiento externas puede ayudar a los agentes a obtener información específica del dominio para generar acciones más realistas. Por ejemplo:
-
ChatDB [61] utiliza declaraciones SQL para consultar la base de datos para facilitar la operación del Agente de manera lógica.
-
ChemCrow [8] propone un reactivo químico basado en LLM diseñado para realizar tareas en los campos de la síntesis orgánica, el descubrimiento de fármacos y el diseño de materiales con la ayuda de 17 herramientas diseñadas por expertos.
-
El sistema MRKL [71] y OpenAGI [51] combinan varios sistemas expertos, como bases de conocimiento y planificadores, llamándolos a acceder a información específica de un dominio de forma sistemática.
(3) Modelo de lenguaje. Los modelos de lenguaje también se pueden utilizar como herramienta para enriquecer el espacio de acción. Por ejemplo:
-
MemoryBank [158] emplea dos modelos de lenguaje, uno diseñado para codificar el texto de entrada, mientras que el otro es responsable de hacer coincidir las oraciones de consulta entrantes para proporcionar una recuperación de texto asistida.
-
ViperGPT [128] primero utiliza un Codex basado en un modelo de lenguaje para generar código Python a partir de descripciones textuales y luego ejecuta el código para completar una tarea determinada.
-
TPTU [118] combina varios LLM para realizar una amplia gama de tareas de generación de lenguaje, como generación de código, generación de letras, etc.
(4) Modelo visual. La integración del modelo visual con el agente puede extender el espacio de acción al dominio multimodal.
-
ViperGPT [128] utiliza modelos como GLIP para extraer características de imagen para operaciones relacionadas con el contenido visual.
-
HuggingGPT [123] propone utilizar modelos de visión para el procesamiento y generación de imágenes.
• Autoconocimiento del agente . El conocimiento autoadquirido del agente también proporciona una variedad de comportamientos, como planificación y generación de lenguaje utilizando la capacidad de generación de LLM, toma de decisiones basadas en la memoria, etc. El agente realiza diversas acciones sin herramientas a partir de conocimientos adquiridos, como la memoria, la experiencia y la capacidad lingüística. Por ejemplo:
-
Los agentes generativos [109] consisten principalmente en un registro de memoria sintética de todas las conversaciones pasadas. Al realizar una acción, recupera fragmentos de memoria relevantes como entradas condicionales para guiar al LLM a generar planes lingüísticos lógicos y consistentes de manera autorregresiva.
-
GITM [161] construye un banco de memoria de experiencias, como pueblos descubiertos o recursos recolectados. Cuando se realiza una acción, consulta el banco de memoria en busca de entradas relevantes, como recordar direcciones anteriores a una aldea para avanzar hacia esa ubicación nuevamente.
-
SayCan [2] desarrolló un marco de aprendizaje por refuerzo en el que los agentes ajustan repetidamente las acciones basándose enteramente en la retroalimentación ambiental para una mejora automática mediante prueba y error sin ninguna demostración o intervención humana.
-
Voyager [133] explota las amplias capacidades de generación de lenguaje de LLM para sintetizar soluciones de texto de formato libre, como fragmentos de código Python o respuestas conversacionales adaptadas a las necesidades actuales. mismo,
-
LATM [10] permite a los LLM aprovechar el código Python para crear sus propias herramientas reutilizables, fomentando así la resolución flexible de problemas.
-
CAMEL [78] registra todas las experiencias históricas en un flujo de memoria. Luego, LLM extrae información de recuerdos relevantes y genera de forma autorregresiva planes textuales de alto nivel que describen los cursos de acción futuros esperados.
-
ChatDev [113] equipa a LLMAgent con una memoria de historial de diálogos para determinar las respuestas y acciones de comunicación apropiadas según el contexto.
En resumen, el conocimiento interno del agente permite diversas acciones sin herramientas a través de métodos como la recuperación de la memoria, el ajuste de la retroalimentación y la generación de lenguaje abierto.
impacto de la acción
Los efectos de la acción se refieren a las consecuencias de una acción, incluidos cambios en el entorno, cambios en el estado interno del agente, desencadenantes de nuevas acciones y efectos en la percepción humana.
• Entorno cambiante . Las acciones pueden cambiar directamente el estado del entorno, como mover la posición del agente, recolectar elementos, construir edificios, etc. Por ejemplo, GITM [161] y Voyager [133] alteran el estado del entorno ejecutando secuencias de acciones para completar tareas.
• Cambiar estado interno . Las acciones tomadas por el agente también pueden cambiar al propio agente, incluida la actualización de la memoria, la formación de nuevos planes, la adquisición de nuevos conocimientos, etc. Por ejemplo, en Generative Agents [109], los flujos de memoria se actualizan después de que se realizan acciones dentro del sistema. SayCan [2] permite a un agente tomar acciones para actualizar su comprensión del entorno y así adaptarse a acciones posteriores.
• Desencadenar nuevas acciones . Para la mayoría de los agentes autónomos basados en LLM, las acciones generalmente se realizan de manera secuencial, es decir, la acción anterior puede desencadenar la siguiente acción nueva. Por ejemplo, la Voyager [133] intentó construir edificios después de recolectar recursos ambientales en una escena de Minecraft. Los agentes generativos [109] primero descomponen el plan en submetas y luego realizan una serie de acciones relacionadas para completar cada submeta.
• Afecta la percepción y experiencia humana . El lenguaje, las imágenes y otras formas de acción afectan directamente la percepción y la experiencia del usuario. Por ejemplo, CAMEL [78] genera expresiones que son coherentes, informativas y atractivas para los temas de conversación. ViperGPT [128] produce imágenes realistas y diversas y es relevante para las tareas de generación de imágenes. HuggingGPT [123] puede generar resultados visuales, como imágenes, extendiendo la percepción humana al dominio de la experiencia visual. Además, HuggingGPT también puede generar resultados multimodales, como códigos, música y vídeos, para enriquecer las interacciones humanas con diferentes medios de comunicación.
2.2 Estrategias de aprendizaje
El aprendizaje es un mecanismo importante mediante el cual los humanos adquieren conocimientos y habilidades y ayuda a mejorar sus capacidades, un significado que llega profundamente al ámbito de los agentes basados en LLM. Durante el aprendizaje, estos agentes son capaces de demostrar una mayor competencia a la hora de seguir instrucciones, manejar hábilmente tareas complejas y adaptarse sin problemas a entornos diversos sin precedentes. Este proceso transformador permite a estos agentes ir más allá de lo que originalmente fueron programados para realizar tareas con mayor refinamiento y flexibilidad.
En este capítulo, profundizamos en varias estrategias de aprendizaje empleadas por agentes basados en LLM y exploramos sus implicaciones de largo alcance.
modelo a seguir
El aprendizaje de modelos es un proceso fundamental para el aprendizaje humano y de IA. En el ámbito de los agentes basados en LLM, este principio se manifiesta en el ajuste, donde estos agentes refinan sus habilidades mediante la exposición a datos del mundo real.
• Aprender de datos anotados por humanos . La integración de datos de retroalimentación generados por humanos se convierte en la piedra angular del ajuste del LLM en la búsqueda de la alineación con los valores humanos. Esta práctica es particularmente importante para dar forma a agentes inteligentes diseñados para complementar o incluso reemplazar a los humanos en tareas específicas.
-
El método CoH propuesto por Liu y otros [91] implica un proceso de varios pasos en el que el LLM genera respuestas, que son evaluadas por revisores humanos para distinguir los resultados favorables de los desfavorables. Esta fusión de respuestas y evaluaciones ayuda a afinar el proceso para que el LLM tenga una comprensión integral de los errores y la capacidad de corregirlos sin dejar de ser consistente con las preferencias humanas. Aunque este enfoque es sencillo, se ve obstaculizado por un costo y tiempo sustanciales de anotación, lo que plantea desafíos para adaptarse rápidamente a diferentes escenarios.
-
MIND2WEB [26] se afina utilizando datos de tareas de sitios web del mundo real anotados por humanos de diferentes dominios, lo que da como resultado un agente genérico que funciona de manera efectiva en sitios web reales.
• Aprender de los datos etiquetados por LLM . Durante la formación previa, LLM obtiene un rico conocimiento mundial a partir de amplios datos previos a la formación. Cuando se ajustan y sintonizan con humanos, exhiben capacidades de juicio similares a las humanas, como modelos como ChatGPT y GPT-4. Por lo tanto, podemos utilizar LLM para tareas de etiquetado, lo que puede reducir significativamente el costo en comparación con el etiquetado manual y brindar la posibilidad de una recopilación de datos exhaustiva.
-
Liu y otros [92] propusieron un método de alineación estable para el ajuste fino del LLM basado en la interacción social. Diseñan un entorno sandbox con múltiples agentes, cada uno de los cuales responde a una pregunta de sondeo. Luego, estas respuestas son evaluadas y calificadas por agentes cercanos y ChatGPT. Posteriormente, los agentes que respondieron refinan sus respuestas en función de estas evaluaciones, que luego ChatGPT vuelve a calificar. Este proceso iterativo produce un gran corpus de datos interactivos y, posteriormente, el LLM se perfecciona mediante aprendizaje supervisado contrastivo.
-
En Refiner [112], se le pide al generador que genere pasos intermedios y se introduce un modelo crítico para generar retroalimentación estructurada. Luego, el modelo del generador se ajusta con los registros de retroalimentación para mejorar la capacidad de inferencia.
-
En ToolFormer [119], el corpus previamente entrenado está marcado con posibles llamadas API utilizando LLM. Luego, el LLM ajusta estos datos anotados para comprender cómo y cuándo se usa la API, e integra los resultados de la API en la generación de texto. mismo,
-
ToolBench [115] también es un conjunto de datos generado completamente utilizando ChatGPT, con el objetivo de ajustar y mejorar la competencia de LLM en el uso de herramientas. ToolBench contiene descripciones extensas de API, así como instrucciones que describen las tareas que se deben realizar utilizando una API en particular y las secuencias de operaciones correspondientes para implementar esas instrucciones. El proceso de ajuste utilizando ToolBench produce un modelo llamado ToolLLaMA que tiene un rendimiento comparable al de ChatGPT. En particular, ToolLLaMA exhibe una fuerte capacidad de generalización incluso frente a API nunca antes vistas.
Aprenda de los comentarios ambientales
En muchos casos, un agente inteligente necesita explorar e interactuar activamente con el entorno que lo rodea. Por lo tanto, necesitan la capacidad de adaptarse a su entorno y mejorarse a partir de la retroalimentación ambiental. En el aprendizaje por refuerzo, los agentes aprenden explorando continuamente el entorno y adaptándose en función de la retroalimentación ambiental [68, 82, 98, 152]. Este principio también se aplica a los agentes inteligentes basados en LLM.
-
Voyager [133] sigue un enfoque de sugerencias iterativas, donde el agente realiza acciones, recopila comentarios ambientales e itera hasta que las habilidades recién adquiridas se autovalidan, validan y agregan al banco de habilidades.
-
De manera similar, LMA3 [22] establece objetivos de forma autónoma y realiza acciones en un entorno interactivo, y LLM califica su desempeño como una función de recompensa. Al repetir este proceso, LMA3 aprende de forma independiente una amplia gama de habilidades.
-
GITM [161] e Inner Monologue [64] integran la retroalimentación ambiental en el proceso de planificación de circuito cerrado basado en modelos lingüísticos a gran escala.
-
Además, crear un entorno que refleje fielmente la realidad también ayuda enormemente a mejorar el desempeño del agente. WebShop [149] desarrolló un entorno de comercio electrónico simulado en el que los agentes pueden participar en actividades como búsqueda y compra, y recibir las correspondientes recompensas y comentarios.
-
En [145], se utiliza un simulador de realización para permitir que un agente interactúe en un entorno simulado del mundo real, facilitando el compromiso físico y, por tanto, la experiencia concreta. Luego, estas experiencias se utilizan para ajustar el modelo y mejorar su rendimiento en tareas posteriores.
En comparación con el aprendizaje a partir de anotaciones, el aprendizaje a partir de la retroalimentación ambiental resume claramente las características de autonomía e independencia de los agentes basados en LLM. Esta diferencia encarna una profunda interacción entre la capacidad de respuesta ambiental y el aprendizaje autónomo, lo que facilita una comprensión matizada del comportamiento y la adaptación de los agentes.
Aprenda de la retroalimentación humana interactiva
La retroalimentación humana interactiva brinda una oportunidad para que el agente se adapte, evolucione y refine su comportamiento de manera dinámica bajo la guía humana. En comparación con la retroalimentación única, la retroalimentación interactiva está más en línea con los escenarios del mundo real. Dado que los agentes aprenden en un proceso dinámico, no sólo procesan datos estáticos, sino que participan en el refinamiento continuo de su comprensión, adaptación y alineación con los humanos. Por ejemplo:
-
[156] incorporan un módulo de comunicación que permite la realización de tareas colaborativas a través de interacciones basadas en chat y comentarios de humanos. Como se destaca en [122], la retroalimentación interactiva facilita aspectos clave como la confiabilidad, la transparencia, la inmediatez, las características de la tarea y la evolución de la confianza en el tiempo al aprender un agente.
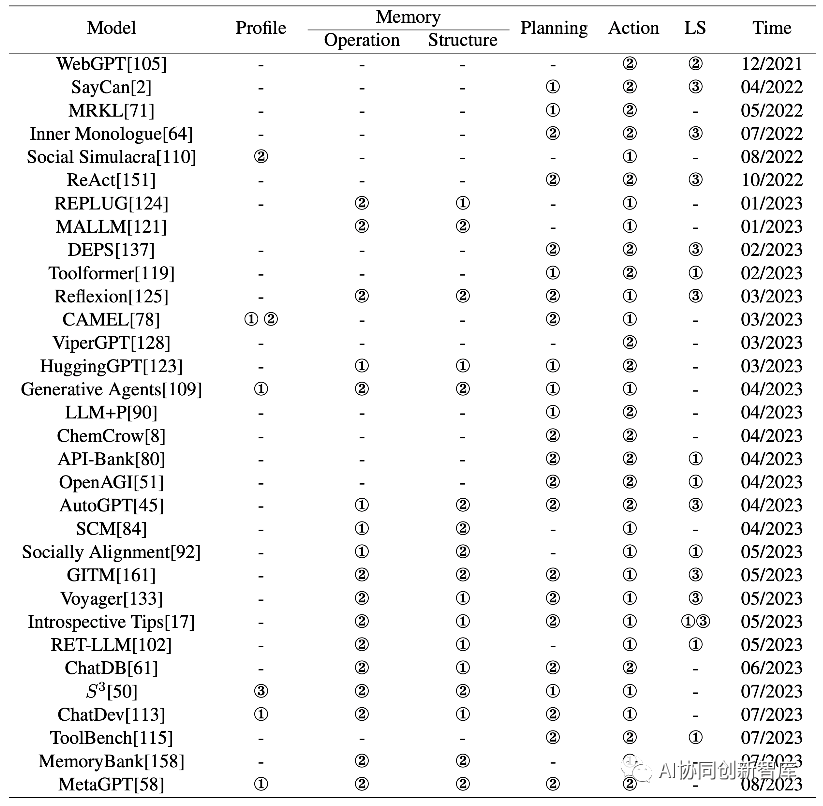
En los capítulos anteriores, resumimos el trabajo anterior sobre estrategias de construcción basadas en agentes, enfocándonos en dos aspectos del diseño de arquitectura y la optimización de parámetros. Mostramos la correspondencia entre el trabajo anterior y nuestra taxonomía en la Tabla 1.
3 Solicitud de agente autónomo basado en LLM
La aplicación de agentes autónomos basados en LLM en varios dominios representa un cambio de paradigma en la forma en que resolvemos problemas, tomamos decisiones e innovamos. Dotados de comprensión, razonamiento y adaptación al lenguaje, estos agentes están revolucionando industrias y disciplinas al proporcionar conocimientos, asistencia y soluciones sin precedentes.
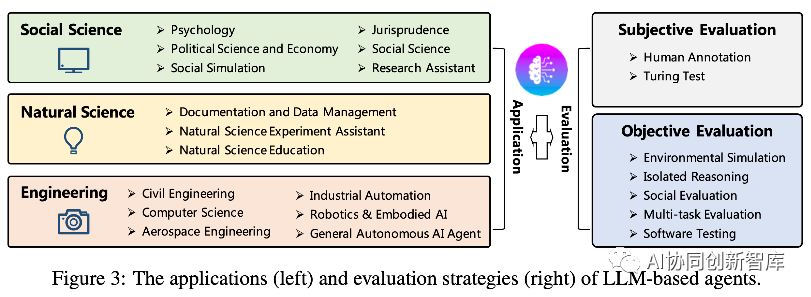
En esta sección, exploramos el impacto transformador de los agentes autónomos basados en LLM en tres dominios distintos: ciencias sociales, ciencias naturales e ingeniería (consulte la descripción general global en el lado izquierdo de la Figura 3).
3.1 Ciencias Sociales
Las ciencias sociales computacionales implican el desarrollo y la aplicación de métodos computacionales para analizar datos complejos del comportamiento humano, a menudo a gran escala, incluidos datos de escenarios simulados [74].
Recientemente, los LLM han demostrado impresionantes habilidades humanas, lo que es prometedor para la investigación en ciencias sociales computacionales [54]. A continuación, presentamos muchos dominios representativos a los que se han aplicado agentes basados en LLM.
Psicología : los agentes basados en LLM se pueden utilizar en psicología para realizar experimentos psicológicos [1, 3, 95, 163].
-
En [1], los agentes basados en LLM se utilizan para simular experimentos psicológicos, incluido el juego del ultimátum, la sentencia del camino del jardín, el experimento de choque de Milgram y la capacidad de inteligencia de enjambre. En los primeros tres experimentos, los agentes basados en LLM pudieron reproducir los hallazgos psicológicos actuales, mientras que el último experimento reveló "distorsiones de hiperprecisión" en algunos modelos de lenguaje (incluidos ChatGPT y GPT-4), que pueden afectar las aplicaciones posteriores.
-
En [3], el autor utiliza un agente basado en LLM para simular dos juegos repetidos típicos en el campo de la teoría de juegos: el dilema del prisionero y la batalla de sexos. Descubrieron que los agentes con un LLM exhiben una tendencia psicológica a priorizar el interés propio sobre la coordinación.
-
Con respecto a la aplicación en salud mental, [95] analizó las ventajas y desventajas de utilizar agentes basados en LLM para brindar apoyo a la salud mental.
Ciencias políticas y economía : estudios recientes han utilizado agentes basados en LLM en ciencias políticas y economía [5, 59, 163].
-
Estos agentes se utilizan para analizar impresiones partidistas y explorar cómo los actores políticos modifican las agendas, entre otras aplicaciones. Además, los agentes basados en LLM se pueden utilizar para la detección de ideologías y la predicción de patrones de votación [5].
-
Además, los esfuerzos de investigación recientes se han centrado en comprender la estructura discursiva y los factores persuasivos de los discursos políticos con la ayuda de agentes basados en LLM [163].
-
En el estudio realizado por Horton y otros [59], los agentes basados en LLM tienen características específicas, como talentos, preferencias y personalidades. Esto permite a los investigadores explorar el comportamiento económico en escenarios simulados y obtener nuevos conocimientos en el campo de la economía.
Simulación social : Experimentar en sociedades humanas suele ser costoso, poco ético, inmoral o incluso imposible. Por el contrario, la simulación basada en agentes permite a los investigadores construir escenarios hipotéticos bajo reglas específicas para simular una variedad de fenómenos sociales, como la difusión de información dañina. Los investigadores participan en sistemas de observación e intervención a nivel macro y micro, que les permiten estudiar eventos contrafactuales [110, 81, 76, 109, 89, 73, 50, 140]. Este proceso permite a los tomadores de decisiones crear más reglas o políticas. Por ejemplo:
-
Social Simulacara [110] simula una comunidad social en línea y explora el potencial de utilizar simulaciones de agentes basadas en LLM para ayudar a los tomadores de decisiones a mejorar la regulación comunitaria.
-
[81, 76] investigaron las características de comportamiento de los agentes basados en LLM en las redes sociales y su impacto potencial en las redes sociales.
-
Los Agentes Generativos [109] y AgentSims [89] construyen ciudades que incluyen múltiples agentes.
-
SocialAI School [73] emplea simulaciones para estudiar las habilidades cognitivas sociales básicas exhibidas durante el desarrollo de los niños.
-
S3 [50] se centra en la difusión de información, sentimientos y actitudes, mientras que [140] se centra en la propagación de enfermedades infecciosas.
Derecho : los agentes de LLM pueden desempeñar un papel auxiliar en el proceso de toma de decisiones legales y ayudar a los jueces a tomar decisiones más informadas [23, 56].
-
Blind Judgment [56] emplea varios modelos de lenguaje para simular el proceso de toma de decisiones de múltiples jueces. Recoge diferentes opiniones y consolida los resultados mediante un mecanismo de votación. ChatLaw [23] es un LLM perfeccionado en el campo del derecho chino. Para abordar el problema de la ilusión del modelo, ChatLaw incorpora técnicas de búsqueda en bases de datos y búsqueda de palabras clave para mejorar la precisión. Mientras tanto, se adopta un mecanismo de autoatención para mejorar la capacidad de LLM para aliviar la influencia de datos de referencia inexactos.
Asistentes de investigación en ciencias sociales : además de realizar investigaciones especializadas en diferentes áreas de la informática social, los agentes basados en LLM también pueden desempeñar el papel de asistentes de investigación [6, 163]. Tienen el potencial de ayudar a los investigadores en tareas como generar resúmenes de artículos, extraer palabras clave y generar guiones [163]. Además, los agentes basados en LLM pueden servir como ayudas para la redacción e incluso pueden identificar nuevas consultas de investigación para los científicos sociales [6].
El desarrollo de agentes basados en LLM ha traído nuevos métodos de investigación al campo de la investigación en ciencias sociales computacionales. Sin embargo, todavía existen algunos desafíos y limitaciones en la aplicación de agentes basados en LLM en informática social [163, 6]. Dos preocupaciones principales son el sesgo y la toxicidad, ya que los LLM se capacitan a partir de conjuntos de datos del mundo real, lo que los hace susceptibles a sesgos inherentes, contenido discriminatorio e injusticia. Cuando se introduce LLM, puede producir información sesgada, que se utiliza aún más para entrenar LLM, lo que lleva a la amplificación del sesgo.
La causalidad y la interpretabilidad presentan otro desafío, especialmente en el contexto de las ciencias sociales, donde a menudo se requiere una fuerte causalidad. Los LLM basados en probabilidades a menudo carecen de interpretabilidad explícita.
3.2 Ciencias Naturales
Debido al rápido desarrollo de modelos lingüísticos a gran escala, la aplicación de agentes basados en LLM en el campo de las ciencias naturales está en aumento. Estos agentes traen nuevas oportunidades para la investigación científica en ciencias naturales. A continuación, presentamos una serie de dominios representativos donde los agentes basados en LLM pueden desempeñar un papel importante.
Gestión de literatura y datos : en el campo de la investigación de las ciencias naturales, a menudo es necesario recopilar, organizar y extraer cuidadosamente una gran cantidad de literatura y datos, lo que requiere mucho tiempo y recursos humanos. Los agentes basados en LLM exhiben sólidas capacidades de procesamiento del lenguaje natural, lo que les permite acceder de manera eficiente a diversas herramientas para navegar por Internet, documentos, bases de datos y otras fuentes de información. Esta capacidad les permite adquirir grandes cantidades de datos, integrarlos y gestionarlos sin problemas, proporcionando así una valiosa ayuda a la investigación científica [7, 70, 8].
-
Al utilizar la API para acceder a Internet, el Agente en [7] puede consultar y recuperar de manera eficiente información relevante en tiempo real, lo que ayuda a completar tareas como responder preguntas y planificar experimentos.
-
ChatMOF [70] utiliza LLM para extraer puntos clave de descripciones textuales escritas por humanos y formula planes para invocar los conjuntos de herramientas necesarios para predecir las propiedades y estructuras de las estructuras organometálicas.
-
La utilización de bases de datos mejora aún más el rendimiento de los agentes en dominios específicos, ya que contienen datos personalizados enriquecidos. Por ejemplo, al acceder a bases de datos relacionadas con la química, ChemCrow [8] puede verificar la exactitud de la caracterización de compuestos o identificar sustancias peligrosas, contribuyendo así a investigaciones científicas más precisas e informadas.
Asistente de experimentos de ciencias naturales : los agentes basados en LLM pueden operar de forma autónoma, realizar experimentos de forma independiente y servir como herramientas valiosas para apoyar los proyectos de investigación de los científicos [7, 8]. Por ejemplo:
-
[7] introdujo un sistema de agentes innovador que utiliza LLM para automatizar el diseño, la planificación y la ejecución de experimentos científicos. Cuando se proporciona un objetivo de experimento como entrada, el sistema accede a Internet y recupera archivos relevantes para obtener la información necesaria. Luego utiliza código Python para realizar cálculos básicos y finalmente ejecutar los pasos secuenciales del experimento.
-
ChemCrow [8] contiene 17 herramientas cuidadosamente diseñadas específicamente para ayudar a los investigadores de química. Después de recibir los objetivos, ChemCrow brindó recomendaciones interesantes para los procedimientos experimentales, al tiempo que destacó cuidadosamente los posibles riesgos de seguridad asociados con el experimento propuesto.
Educación en ciencias naturales : gracias a las capacidades del lenguaje natural, LLM facilita la comunicación fluida con los humanos a través de la interacción del lenguaje natural, lo que la convierte en una herramienta educativa interesante para responder preguntas en tiempo real y difundir conocimientos [7, 129, 30, 18]. Por ejemplo:
-
[7] propusieron el sistema Agent como una valiosa herramienta educativa para estudiantes e investigadores que aprenden sobre diseño, metodología y análisis experimentales. Ayudan a desarrollar el pensamiento crítico y las habilidades de resolución de problemas al tiempo que fomentan una comprensión más profunda de los principios científicos.
-
Los agentes matemáticos [129] son entidades que utilizan técnicas de inteligencia artificial para explorar, descubrir, resolver y probar problemas matemáticos. El Agente Matemático también puede comunicarse con los humanos para ayudarlos a comprender y utilizar las matemáticas.
-
[30] aprovechan el poder de CodeX [18] para lograr la solución, interpretación y generación automáticas a nivel humano de problemas matemáticos de nivel universitario con una pequeña cantidad de aprendizaje. Este logro tiene implicaciones importantes para la educación superior, ya que ofrece ventajas como herramientas de diseño y análisis de cursos y generación automatizada de contenidos.
El uso de agentes basados en LLM para apoyar la investigación en ciencias naturales también conlleva ciertos riesgos y desafíos.
-
Por un lado, los propios LLM pueden ser susceptibles a alucinaciones y otros problemas, proporcionando ocasionalmente respuestas incorrectas, llevando a conclusiones erróneas, fracasos experimentales e incluso riesgos para la seguridad humana en experimentos peligrosos. Por lo tanto, los usuarios deben tener la experiencia y el conocimiento necesarios para tener el debido cuidado durante el experimento.
-
Por otro lado, los agentes basados en LLM pueden utilizarse con fines maliciosos, como el desarrollo de armas químicas, lo que requiere la implementación de medidas de seguridad, como la coordinación humana, para garantizar un uso responsable y ético.
3.3 Ingeniería
Los agentes autónomos basados en LLM muestran un gran potencial para ayudar y mejorar la investigación y las aplicaciones de ingeniería. En esta sección, revisamos y resumimos las aplicaciones de agentes basados en LLM en varios dominios importantes de la ingeniería.
Ingeniería civil : en ingeniería civil, los agentes basados en LLM se pueden utilizar para diseñar y optimizar estructuras complejas como edificios, puentes, presas, carreteras, etc. [99] propusieron un marco interactivo donde arquitectos humanos y agentes de IA colaboran para construir estructuras en un entorno simulado en 3D. El agente interactivo puede comprender instrucciones en lenguaje natural, colocar bloques, detectar confusión, buscar aclaraciones e incorporar comentarios humanos, lo que muestra el potencial de la colaboración entre humanos y IA en el diseño de ingeniería.
Ciencias de la Computación e Ingeniería de Software : En ciencias de la computación e ingeniería de software, los agentes basados en LLM ofrecen potencial para la codificación, prueba, depuración y generación de documentación automatizadas [115, 113, 58, 29, 33, 44, 41].
-
ChatDev [113] propone un marco de trabajo de un extremo a otro en el que múltiples roles de agentes se comunican y colaboran a través de conversaciones en lenguaje natural para completar el ciclo de vida del desarrollo de software. Este marco demuestra la generación eficiente y rentable de sistemas de software ejecutables.
-
ToolBench [115] se puede utilizar para tareas como el autocompletado de código y la recomendación de código. Por ejemplo, ToolBench puede completar automáticamente nombres de funciones y nombres de variables en el código, así como recomendar fragmentos de código.
-
MetaGPT [58] abstrae múltiples roles, como gerentes de producto, arquitectos, gerentes de proyecto e ingenieros, para supervisar internamente la generación de código y mejorar la calidad del código de salida final. Esto permite el desarrollo de software de bajo costo.
-
[29] propusieron un marco de autocolaboración para la generación de código utilizando LLM, tomando ChatGPT como ejemplo. En este marco, varios LLM asumen diferentes roles de "expertos" para subtareas específicas en una tarea compleja. Colaboran e interactúan según instrucciones asignadas, formando un equipo virtual que facilita el trabajo de cada uno. En última instancia, los equipos virtuales colaboran en tareas de generación de código sin intervención humana.
-
GPT Engineer [33], SmolModels [44] y DemoGPT [41] son proyectos de código abierto que se centran en generar código automáticamente a través de sugerencias para completar tareas de desarrollo.
-
LLM también se puede aplicar a las pruebas y corrección de errores de código. LLIFT [79] utiliza LLM para ayudar con el análisis estático para detectar vulnerabilidades del código, lo que logra un equilibrio entre precisión y escalabilidad.
Ingeniería aeroespacial : en ingeniería aeroespacial, los primeros trabajos exploraron el uso de agentes basados en LLM para modelar física, resolver ecuaciones diferenciales complejas y optimizar diseños. [107] mostraron resultados prometedores en la resolución de problemas relacionados en aerodinámica, diseño de aeronaves, optimización de trayectorias, etc. Con un mayor desarrollo, los agentes basados en LLM pueden diseñar de manera innovadora naves espaciales, simular el flujo de fluidos, realizar análisis estructurales e incluso controlar vehículos autónomos generando código ejecutable que se integra con sistemas de ingeniería.
Automatización industrial : en el campo de la automatización industrial, el agente basado en LLM se puede utilizar para realizar una planificación y control inteligentes del proceso de producción. [144] propusieron un nuevo marco para integrar modelos de lenguajes grandes (LLM) con sistemas gemelos digitales para satisfacer las necesidades de producción flexibles. El marco utiliza técnicas de ingeniería justo a tiempo para crear agentes LLMA que puedan adaptarse a tareas específicas basadas en la información proporcionada por gemelos digitales. Estos agentes pueden coordinar una serie de funciones y habilidades atómicas para completar tareas de producción en diferentes niveles de la pirámide de automatización. Esta investigación demuestra el potencial de integrar LLM en sistemas de automatización industrial para proporcionar soluciones innovadoras para procesos de producción más ágiles, flexibles y adaptables.
Robótica e IA integrada : trabajos recientes han desarrollado agentes de aprendizaje por refuerzo más eficaces para robots e IA integrada [25, 160, 106, 143, 133, 161, 60, 142, 154, 28, 2]. La atención se centra en mejorar las capacidades de planificación, razonamiento y colaboración de agentes autónomos en entornos concretos.
-
Algunos enfoques, como [25], combinan fortalezas complementarias en un sistema unificado para el razonamiento concreto y la planificación de tareas. Los comandos de alto nivel mejoran la planificación, mientras que los controladores de bajo nivel traducen los comandos en acciones.
El diálogo de recopilación de información en [160] puede acelerar el entrenamiento. Otros trabajos como [106, 143] emplean agentes autónomos para tomar decisiones y exploraciones específicas guiadas por un modelo de mundo interno. -
Teniendo en cuenta las limitaciones físicas, el agente puede generar planes ejecutables y completar tareas a largo plazo que requieren múltiples habilidades. En términos de estrategias de control, SayCan [2] se centra en el estudio de diversas habilidades de manipulación y navegación utilizando robots manipuladores móviles. Se inspira en las tareas típicas que se encuentran en un ambiente de cocina y presenta una colección de 551 habilidades (que cubren 7 familias de habilidades, 17 objetos). Estas habilidades incluyen acciones como recoger, colocar, verter, agarrar y manipular objetos.
-
Otros marcos como VOYAGAR [133] y GITM [161] proponen agentes autónomos capaces de comunicarse, colaborar y completar tareas complejas. Esto demuestra la promesa de la comprensión del lenguaje natural, la planificación de acciones y la interacción entre humanos y robots en la robótica del mundo real.
Con el desarrollo de capacidades, los agentes autónomos adaptativos pueden completar tareas específicas cada vez más complejas. En conclusión, complementar los enfoques tradicionales con capacidades de razonamiento y planificación en [60, 142, 154, 28] puede mejorar significativamente el rendimiento de los agentes autónomos en entornos integrados. La atención se centra en sistemas generales que mejoran la eficiencia de las muestras, las capacidades de generalización y realizan tareas a largo plazo.
Agente de IA general autónomo : muchos proyectos de código abierto basados en el desarrollo de LLM han llevado a cabo exploraciones preliminares de inteligencia artificial general (AGI), trabajando en el marco del Agente de IA general autónomo [45, 43, 38, 40, 35, 36, 42, 15, 32, 39, 34, 114, 47, 41, 37, 46, 141], lo que permite a los desarrolladores crear, gestionar y ejecutar agentes autónomos útiles de forma rápida y fiable. Por ejemplo:
-
LangChain [15] es un marco de código abierto que automatiza tareas de codificación, prueba, depuración y generación de documentación. Al integrar modelos de lenguaje con fuentes de datos y facilitar las interacciones con el entorno, LangChain permite el desarrollo de software eficiente y rentable a través de la comunicación en lenguaje natural y la colaboración entre múltiples roles de Agentes.
-
Basado en LangChain, XLang [36] proporciona un conjunto completo de herramientas, una interfaz de usuario completa y admite tres escenarios de Agente diferentes, a saber, procesamiento de datos, uso de complementos y webAgent.
-
AutoGPT [45] es un agente totalmente automatizado y conectable en red que simplemente necesita establecer uno o más objetivos y los descompone automáticamente en las tareas correspondientes y las recorre hasta alcanzar el objetivo.
-
WorkGPT [32] es un marco de agente similar a AutoGPT y LangChain. Al darle una instrucción y un conjunto de API, puede comunicarse con la IA hasta que se complete la instrucción.
-
AGiXT [40] es una plataforma dinámica de automatización de IA diseñada para coordinar la gestión eficiente de comandos de IA y la ejecución de tareas entre muchos proveedores.
-
AgentVerse [35] es un marco general que puede ayudar a los investigadores a crear rápidamente simulaciones de agentes personalizadas basadas en múltiples LLM.
-
GPT Researcher [34] es una aplicación experimental que explota grandes modelos de lenguaje para desarrollar eficientemente preguntas de investigación, activa rastreos web para recopilar información, agrega fuentes y agrega resúmenes.
-
BMTools [114] es un repositorio de código abierto que amplía LLM con herramientas y proporciona una plataforma para la creación y el intercambio de herramientas impulsadas por la comunidad. Admite varios tipos de herramientas, permite que múltiples herramientas realicen tareas simultáneamente y proporciona una interfaz simple para cargar complementos a través de URL, lo que facilita el desarrollo y la contribución al ecosistema BMTools.
En conclusión, los agentes autónomos basados en LLM están abriendo nuevas posibilidades en diferentes campos de la ingeniería para mejorar la creatividad y la productividad humana. A medida que los LLM continúan avanzando en capacidades de razonamiento y generalización, anticipamos que los equipos simbióticos humanos-IA abrirán nuevos horizontes y capacidades en innovación y descubrimiento de ingeniería.
Sin embargo, aún persisten problemas relacionados con la confianza, la transparencia y el control al implementar agentes basados en LLM en sistemas de ingeniería críticos para la seguridad. Encontrar el equilibrio adecuado entre las capacidades humanas y de IA y al mismo tiempo garantizar la solidez permitirá que esta tecnología alcance su máximo potencial.
En la sección anterior, presentamos trabajos previos en términos de la aplicación de agentes autónomos basados en LLM. Para una comprensión más clara, resumimos estas aplicaciones en la Tabla 3.

4 Evaluación de agentes autónomos basados en LLM
Esta sección presenta métodos de evaluación para evaluar la efectividad de los agentes autónomos basados en LLM. Al igual que el propio LLM, la evaluación de agentes de IA no es un problema fácil. Aquí, proponemos dos estrategias de evaluación comúnmente utilizadas para evaluar agentes de IA: evaluación subjetiva y evaluación objetiva. (Consulte la descripción general en el lado derecho de la Figura 3).

4.1 Basado en evaluación subjetiva
El agente de LLM tiene una amplia gama de aplicaciones. Sin embargo, en muchos casos, faltan métricas generales para evaluar el desempeño de los agentes. Algunas propiedades subyacentes, como la inteligencia y la facilidad de uso de un agente, tampoco pueden medirse con métricas cuantitativas. Por tanto, la evaluación subjetiva es fundamental en el presente estudio.
La evaluación subjetiva se refiere a la capacidad de los humanos para probar el Agente basado en LLM a través de diversas formas, como la interacción y la puntuación. En este caso, los evaluadores que participan en la prueba generalmente son reclutados a través de plataformas de crowdsourcing [75, 110, 109, 5, 156]; mientras que algunos investigadores creen que debido a diferencias individuales, el personal de crowdsourcing es inestable y utiliza anotaciones de expertos para las pruebas [163] . A continuación, presentamos dos estrategias de apalancamiento comúnmente utilizadas.
Anotación humana : en algunos estudios, los evaluadores humanos clasifican o califican directamente los resultados generados por agentes basados en LLM en función de algunas perspectivas específicas [163, 5, 156]; otro tipo de evaluación está centrada en el usuario y pide a los evaluadores humanos que respondan si el El sistema de agentes basado en LLM les resulta útil [110] y si es fácil de usar [75], etc. Específicamente, una posible evaluación es si los sistemas de simulación social pueden facilitar efectivamente el diseño de reglas de comunidades en línea [110].
Prueba de Turing : en este enfoque, siempre se pide a los evaluadores humanos que diferencien entre el comportamiento del agente y el humano. En Generative Agents [109], se pide al primer grupo de evaluadores humanos que evalúen las capacidades clave del agente en cinco dominios a través de entrevistas. Después de dos días de juego, se pedirá a otro grupo de evaluadores humanos que diferencien entre las respuestas del agente y las humanas en las mismas condiciones. En el experimento de texto partisano de forma libre [5], se pide a los evaluadores humanos que adivinen si la respuesta proviene de un humano o de un agente basado en LLM.
Dado que el sistema de agentes basado en LLM sirve en última instancia a humanos, la evaluación humana juega un papel irreemplazable en esta etapa, pero también tiene problemas de alto costo, baja eficiencia y sesgo de grupo. A medida que el LLM avanza, puede desempeñar, hasta cierto punto, el papel del ser humano que evalúa la tarea.
En algunos de los estudios actuales, se podría utilizar un agente LLM adicional como evaluador subjetivo del resultado. En ChemCrow [8], EvaluatorGPT evalúa los resultados experimentales mediante puntuación, que tiene en cuenta tanto la finalización exitosa de la tarea como la precisión del proceso de pensamiento subyacente. ChatEval [12] formó un equipo de múltiples agentes árbitros basado en LLM para evaluar los resultados producidos por el modelo a través del debate. Creemos que con el progreso de LLM, los resultados de la evaluación del modelo serán más confiables y la aplicación será más extensa.
4.2 Evaluación objetiva
La evaluación objetiva tiene varios beneficios sobre la evaluación humana. Las métricas cuantitativas permiten realizar comparaciones claras entre diferentes enfoques y realizar un seguimiento del progreso a lo largo del tiempo. Las pruebas automatizadas a gran escala son factibles, ya que permiten la evaluación de miles de tareas en lugar de unas pocas [113, 5]. Los resultados también son más objetivos y repetibles.
Sin embargo, las evaluaciones humanas pueden evaluar habilidades complementarias que son difíciles de cuantificar objetivamente, como la naturalidad, los matices y la inteligencia social. Por lo tanto, estos dos métodos se pueden utilizar en combinación.
La evaluación objetiva se refiere a la capacidad de evaluar un agente autónomo basado en LLM utilizando métricas cuantitativas que pueden calcularse, compararse y rastrearse a lo largo del tiempo. Las métricas objetivas tienen como objetivo proporcionar información específica y mensurable sobre el desempeño de los agentes, en comparación con evaluaciones subjetivas o humanas. En esta sección, revisamos y sintetizamos métodos de evaluación objetiva desde la perspectiva de métricas, estrategias y puntos de referencia.
Indicadores: Para evaluar objetivamente la efectividad de un Agente, es importante diseñar indicadores apropiados, que pueden afectar la precisión y exhaustividad de la evaluación. Una métrica de evaluación ideal debería reflejar con precisión la calidad del agente y ser coherente con la percepción humana cuando se utiliza en escenarios del mundo real. En el trabajo existente, podemos ver las siguientes métricas de evaluación representativas.
(1) Métricas de éxito de la tarea: estas métricas miden la capacidad del agente para completar tareas y alcanzar objetivos. Las métricas comunes incluyen tasa de éxito [156, 151, 125, 90], recompensa/puntuación [156, 151, 99], cobertura [161] y precisión [113, 1, 61]. Cuanto mayor sea el valor, mayor será la capacidad para completar la tarea.
(2) Medidas de similitud humana: estas medidas cuantifican en qué medida el comportamiento de un agente se parece al de un ser humano. Los ejemplos típicos incluyen precisión de trayectoria/ubicación [163, 133], similitud de diálogo [110, 1] e imitación de respuestas humanas [1, 5]. Cuanto mayor es la similitud, más humano es el razonamiento.
(3) Indicadores de eficiencia: a diferencia de los indicadores anteriores utilizados para evaluar la efectividad de los agentes, estos indicadores evalúan la eficiencia de los agentes desde diferentes perspectivas. Las métricas típicas incluyen la duración de la planificación [90], el costo de desarrollo [113], la velocidad de inferencia [161, 133] y el número de diálogos aclaratorios [99].
Estrategias: A partir de los métodos utilizados para la evaluación, podemos identificar varias estrategias comunes:
(1) Simulación del entorno: en este enfoque, los agentes se evalúan en entornos 3D inmersivos, como juegos y ficción interactiva, utilizando métricas de éxito de la tarea y semejanza humana, incluidas trayectorias, uso del lenguaje y objetivos completados [16, 156, 161, 151]. , 133, 99, 137, 85, 149, 155]. Esto demuestra las capacidades prácticas del Agente en escenarios del mundo real.
(2) Razonamiento independiente: en este enfoque, los investigadores se centran en las capacidades cognitivas básicas mediante el uso de tareas limitadas como precisión, tasa de finalización del canal y medidas de ablación [113, 51, 125, 90, 61, 21, 149, 155]. Este enfoque simplifica el análisis de las habilidades individuales.
(3) Evaluación social: [110, 1, 21, 89, 94] investigan directamente la inteligencia social utilizando estudios en humanos y métricas de imitación. Esto evalúa niveles más altos de cognición social.
(4) Multitarea: [5, 21, 114, 93, 94, 149, 155] utilizan varios conjuntos de tareas de diferentes dominios para una evaluación de cero o pocas posibilidades. Esto mide la generalización.
(5) Pruebas de software: [66, 69, 48, 94] exploran el uso de LLM en diversas tareas de prueba de software, como generar casos de prueba, reproducir errores, depurar código e interactuar con desarrolladores y herramientas externas. Miden la eficacia de los agentes basados en LLM utilizando métricas como cobertura de pruebas, tasa de detección de errores, calidad del código y capacidad de razonamiento.
Puntos de referencia: además de las métricas, la evaluación objetiva se basa en puntos de referencia, experimentos controlados y pruebas de significación estadística. Muchos artículos crean puntos de referencia utilizando conjuntos de datos de tareas y entornos para probar agentes sistemáticamente, como ALFWorld [151], IGLU [99] y Minecraft [161133137].
-
Clembench [11] es un enfoque basado en juegos para evaluar modelos de lenguaje optimizados para chat como agentes conversacionales que explora la evaluación significativa de LLM exponiéndolos a entornos restringidos similares a juegos diseñados para desafiar habilidades específicas.
-
Tachikuma [85] es un punto de referencia que utiliza registros de juegos TRPG para evaluar la capacidad de los LLM para comprender e inferir interacciones complejas con múltiples personajes y objetos novedosos.
-
AgentBench [93] proporciona un marco integral para evaluar los LLM como agentes autónomos en diferentes entornos, logrando un punto de referencia estandarizado para los LLMAgents al adoptar F1 como métrica principal. Representa la primera evaluación sistemática de LLM previamente capacitados como agentes para desafíos del mundo real en diversos dominios.
-
SocKET [21] es un punto de referencia integral para evaluar las capacidades de conocimiento social de modelos de lenguaje grandes (LLM) en 58 tareas, que cubre cinco categorías de información social que incluyen humor y sarcasmo, emociones y sentimientos, y confiabilidad.
-
AgentSims [89] es una infraestructura versátil para crear entornos limitados de prueba para modelos de lenguaje a gran escala, lo que facilita diversas tareas de evaluación y aplicaciones en la generación de datos y la investigación en ciencias sociales.
-
ToolBench [114] es un proyecto de código abierto que tiene como objetivo facilitar la construcción de modelos de lenguaje a gran escala con capacidades de uso de herramientas de propósito general al proporcionar una plataforma abierta para entrenar, servir y evaluar potentes modelos de lenguaje a gran escala para el aprendizaje de herramientas. .
-
Dialop [88] está diseñado con tres tareas: optimización, planificación y mediación para evaluar la capacidad de toma de decisiones de un agente basado en LLM.
-
WebShop [149] Benchmark evalúa la búsqueda y recuperación de productos de LLMAgent en 1,18 millones de artículos del mundo real mediante consultas de búsqueda y clics, utilizando recompensas basadas en la superposición de atributos y el rendimiento de recuperación.
-
Mobile Env [155] es una plataforma de interacción fácilmente extensible que proporciona una base para evaluar las capacidades de interacción de varios pasos de los agentes basados en LLM cuando interactúan con una interfaz de usuario de información (InfoUI).
-
WebArena [159] crea un entorno de sitio web integral que incluye dominios comunes. El entorno es una plataforma para evaluar agentes de un extremo a otro para determinar la corrección funcional de las tareas completadas.
-
GentBench [146] es un punto de referencia diseñado para evaluar diversas capacidades de los agentes, incluido el razonamiento, la seguridad, la eficiencia, etc. Además, admite la evaluación de la capacidad del agente para utilizar herramientas para manejar tareas complejas.
En resumen, la evaluación objetiva permite la evaluación cuantitativa de las capacidades de los agentes basados en LLM a través de métricas como la tasa de éxito de las tareas, la similitud humana, la eficiencia y los estudios de ablación. Desde la simulación ambiental hasta la evaluación social, ha surgido una caja de herramientas diversa de técnicas objetivas para diferentes capacidades.
Si bien las técnicas actuales tienen limitaciones a la hora de medir la capacidad general, las evaluaciones objetivas proporcionan conocimientos clave que complementan las evaluaciones humanas. El progreso continuo en los puntos de referencia y métodos de evaluación objetiva avanzará aún más en el desarrollo y la comprensión de los agentes autónomos basados en LLM.
En la sección anterior, introdujimos estrategias de evaluación subjetiva y objetiva para agentes autónomos basados en LLM. La evaluación de agentes juega un papel importante en este campo. Sin embargo, tanto las evaluaciones subjetivas como las objetivas tienen ventajas y desventajas. Quizás, en la práctica, deberían combinarse para una evaluación integral del agente. Resumimos la correspondencia entre el trabajo previo y estas estrategias de evaluación en la Tabla 3.
5 descripción general relacionada
Con el florecimiento de los grandes modelos lingüísticos, han surgido muchos estudios exhaustivos que proporcionan información detallada sobre diversos aspectos.
-
[157] presenta ampliamente los antecedentes, los principales hallazgos y las técnicas principales de LLM, incluida una gran cantidad de trabajos existentes.
-
[148] se centran principalmente en la aplicación de LLM a diversas tareas posteriores y los desafíos relacionados con la implementación. La integración de los LLM con la inteligencia humana es un área activa de investigación para abordar cuestiones como los prejuicios y las alucinaciones.
-
[136] compilaron técnicas de coordinación humana existentes, incluida la recopilación de datos y métodos de entrenamiento de modelos.
-
El razonamiento es un aspecto importante de la inteligencia que afecta la toma de decisiones, la resolución de problemas y otras habilidades cognitivas. [62] presentó el estado actual de la investigación sobre la capacidad de razonamiento de LLM y exploró formas de mejorar y evaluar sus habilidades de razonamiento. [100] proponen que los modelos de lenguaje se pueden aumentar con capacidades de razonamiento y la capacidad de explotar herramientas, llamadas Modelos de Lenguaje Aumentados (ALM). Proporcionan una revisión completa de los últimos avances en ALM.
-
A medida que el uso de modelos a gran escala se vuelve más común, evaluar su desempeño se vuelve cada vez más importante. [14] aclara la evaluación de LLM, qué evaluar, dónde evaluar y cómo evaluar su desempeño e impacto social en tareas posteriores. [13] también analiza las capacidades y limitaciones de los LLM en diversas tareas posteriores.
Los estudios antes mencionados cubren todos los aspectos de los modelos a gran escala, incluida la capacitación, la aplicación y la evaluación. Sin embargo, antes de la publicación de este artículo, ningún trabajo se había centrado específicamente en el campo altamente prometedor y de rápida aparición de los agentes basados en LLM. En este estudio, recopilamos 100 trabajos relacionados sobre agentes basados en LLM, cubriendo su proceso de construcción, solicitud y evaluación.
6 desafíos
Aunque trabajos anteriores sobre agentes de IA autónomos basados en LLM han mostrado muchas direcciones prometedoras, el campo aún está en su infancia y existen muchos desafíos en su camino de desarrollo. A continuación proponemos varios desafíos importantes.
6.1 Habilidades de juego de roles
A diferencia del LLM tradicional, los agentes de IA generalmente tienen que desempeñar roles específicos (como codificador de programas, investigador y químico) para completar diferentes tareas. Por tanto, la capacidad de interpretación de roles del agente es muy importante. Si bien para muchos roles comunes (por ejemplo, críticos de cine), los LLM pueden modelarlos bien, todavía hay muchos roles y aspectos que los LLM luchan por capturar.
En primer lugar, los LLM generalmente se capacitan en base a corpus web, por lo que para roles que rara vez se analizan en la web o roles emergentes, es posible que LLM no pueda simularlos bien. Además, investigaciones anteriores [49] mostraron que los LLM existentes pueden no ser capaces de modelar bien las características psicológicas cognitivas humanas, lo que resulta en una falta de autoconciencia en escenarios de diálogo. Las posibles soluciones a estos problemas podrían ser ajustar el LLM o diseñar cuidadosamente las sugerencias/arquitectura del agente [77]. Por ejemplo, primero se pueden recopilar datos humanos reales sobre personajes o rasgos psicológicos poco comunes y luego utilizar estos datos para perfeccionar el LLM. Sin embargo, cómo garantizar que el modelo perfeccionado aún pueda desempeñar bien las funciones comunes puede plantear más desafíos. Además del ajuste, se pueden diseñar señales/arquitecturas de agentes personalizadas para mejorar las capacidades de LLM en términos de juegos de roles. Sin embargo, encontrar sugerencias/arquitecturas óptimas no es fácil porque su espacio de diseño es demasiado grande.
6.2 Alineación de valores humanos generalizados
En el campo de los agentes autónomos de IA, especialmente cuando los agentes se utilizan en simulaciones, creemos que este concepto debería discutirse con más profundidad. Para servir mejor a los humanos, el LLM tradicional generalmente se ajusta para ajustarse a los valores humanos correctos; por ejemplo, un agente no debe planear construir una bomba para venganza social.
Sin embargo, cuando se utiliza un agente en una simulación del mundo real, un simulador ideal debería poder describir honestamente diferentes características humanas, incluidas aquellas con valores falsos. De hecho, simular los aspectos negativos de los humanos puede ser más importante, porque un objetivo importante de la simulación es descubrir y resolver problemas, y la ausencia de aspectos negativos significa que no hay problemas que resolver. Por ejemplo, para simular una sociedad del mundo real, podríamos tener que permitir que un agente planee fabricar una bomba y observar cómo llevará a cabo el plan y los efectos de su comportamiento. Con base en estas observaciones, las personas pueden tomar mejores acciones para prevenir comportamientos similares en la sociedad real.
Inspirándose en los casos anteriores, un problema importante que puede enfrentar la simulación basada en agentes es cómo realizar una alineación humana generalizada, es decir, para diferentes propósitos y aplicaciones, un agente debería poder alinearse con diferentes valores humanos. Sin embargo, la mayoría de los LLM sólidos existentes, incluidos ChatGPT y GPT-4, son consistentes con valores humanos unificados. Por lo tanto, una dirección interesante es cómo "reajustar" estos modelos mediante el diseño de estrategias de estímulo apropiadas.
6.3 Sugerencia de robustez
Para garantizar un comportamiento razonable del agente, los diseñadores suelen incorporar módulos adicionales, como memoria y módulos de planificación, en el LLM. Sin embargo, la incorporación de estos módulos requiere el desarrollo de señales adicionales para facilitar una operación consistente y una comunicación efectiva.
Estudios anteriores [162, 52] han destacado la falta de solidez de las señales de LLM, ya que incluso los cambios pequeños pueden producir resultados dramáticamente diferentes. Este problema se vuelve más pronunciado cuando se construyen agentes autónomos, ya que no contienen una sola pista, sino un marco de sugerencias que considera todos los módulos, donde una pista de un módulo tiene el potencial de afectar a otros módulos.
Además, el marco de señales puede diferir significativamente entre diferentes LLM. Desarrollar un marco unificado y sólido justo a tiempo que pueda aplicarse a varios LLM es un problema importante pero no resuelto. Hay dos posibles soluciones al problema anterior:
-
(1) Elabore manualmente elementos básicos mediante prueba y error.
-
(2) Utilice GPT para generar sugerencias automáticamente.
6.4 Alucinaciones
Las alucinaciones plantean un desafío fundamental para los LLM, donde los modelos generan por error información falsa con seguridad. Este problema también es común en agentes autónomos. Por ejemplo, en [67], se observó que los agentes pueden exhibir un comportamiento alucinatorio cuando encuentran instrucciones simplistas en una tarea de generación de código. Las alucinaciones pueden tener consecuencias graves, como códigos erróneos o engañosos, riesgos de seguridad y preocupaciones éticas [67]. Para abordar este problema, un posible enfoque es incorporar la retroalimentación de corrección humana en el ciclo de interacción humano-sujeto [58]. Puede verse más discusión sobre el problema de las alucinaciones en [157].
6.5 Límites del conocimiento
Una aplicación importante de los agentes autónomos de IA es simular diferentes comportamientos humanos del mundo real [109]. El estudio de la simulación humana tiene una larga historia, y el reciente aumento de interés puede atribuirse al notable progreso realizado en los LLM, que han demostrado capacidades notables en la simulación del comportamiento humano.
Sin embargo, es importante darse cuenta de que el poder del LLM puede no siempre ser beneficioso. Específicamente, una simulación ideal debería replicar con precisión el conocimiento humano. En este sentido, los LLM pueden exhibir un poder excesivo porque están capacitados en extensas bases de conocimiento web que están fuera del alcance de la gente común. El enorme poder de los LLM puede afectar significativamente la validez de las simulaciones.
Por ejemplo, al intentar modelar el comportamiento de selección del usuario para varias películas, es crucial asegurarse de que el LLM esté en una posición en la que no sepa nada sobre estas películas. Sin embargo, es posible que LLM haya obtenido información sobre estas películas. Si no se implementan las estrategias adecuadas, los LLM pueden tomar decisiones basadas en su amplio conocimiento, incluso si los usuarios del mundo real no tienen acceso previo al contenido de estas películas. Con base en los ejemplos anteriores, podemos concluir que para construir un entorno de simulación de agentes confiable, una cuestión importante es cómo restringir el uso del conocimiento desconocido del usuario de LLM.
6.6 Eficiencia
Debido a la arquitectura autorregresiva de LLM, su velocidad de inferencia suele ser lenta. Sin embargo, es posible que el agente necesite consultar el LLM para cada acción varias veces, como extraer información de los módulos de memoria, formular planes antes de realizar acciones, etc. Por tanto, la velocidad del razonamiento LLM afecta en gran medida la eficiencia de las acciones del Agente. La implementación de varios agentes con la misma clave API puede aumentar aún más el costo de tiempo de manera significativa.
