
Первоначальный автор науки и техники Си Сяояо
| Ван Сируо
Крупномасштабные языковые модели, такие как LLaMA и GPT-3, достигли мощных возможностей понимания и рассуждения на естественном языке и создали мощную языковую базовую модель для сообщества ИИ. Более того, GPT-4, который продолжает работать, наделяет модель визуальной способностью обрабатывать изображения.
Сегодня построение мощной мультимодальной модели стало консенсусом сообщества. задуть.
Действительно ли существующие модели визуального языка согласовывают модальности изображения и текста? Какая модель визуального языка лучше?
Шанхайская лаборатория искусственного интеллекта разработала эталонный тест LVLM-eHub для проведения комплексной оценки восьми моделей визуального текста, включая InstructBLIP и MiniGPT-4.
Исследование показало, что существующие модели визуального языка с тонкой настройкой инструкций, такие как InstructBLIP, сильно подходят для существующих задач, а их способность к обобщению в реальных сценах оставляет желать лучшего. Кроме того, модель очень склонна к объектным галлюцинациям, генерируя описания объектов, которых нет на изображении.
Портал для тестирования крупных моделей
Портал GPT-4 (без стены, можно протестировать напрямую, если вы обнаружите пункт предупреждения браузера «Дополнительно/продолжить посещение»):
Привет, GPT4!
Название диссертации:
LVLM-eHub: Комплексный тест для оценки больших моделей языка видения
Адрес статьи:
https://arxiv.org/pdf/2306.09265.pdf .
1. Создайте шесть типов наборов данных мультимодальной количественной оценки эффективности и создайте модель интерактивной платформы оценки.
LVLM-eHub состоит из количественной оценки способностей и онлайн-платформы интерактивной оценки. В частности, с одной стороны, количественная оценка способностей широко оценивает LVLM в визуальном восприятии, приобретении визуальных знаний, визуальном рассуждении, визуальном здравом смысле, объектной иллюзии и воплощенном интеллекте 6. Мультимодальные возможности.
С другой стороны, создайте онлайн-интерактивную оценочную платформу для проведения анонимных случайных парных сражений с моделями визуального языка в порядке краудсорсинга и обеспечения рейтингов моделей на уровне пользователей в сценариях вопросов и ответов в открытом мире.
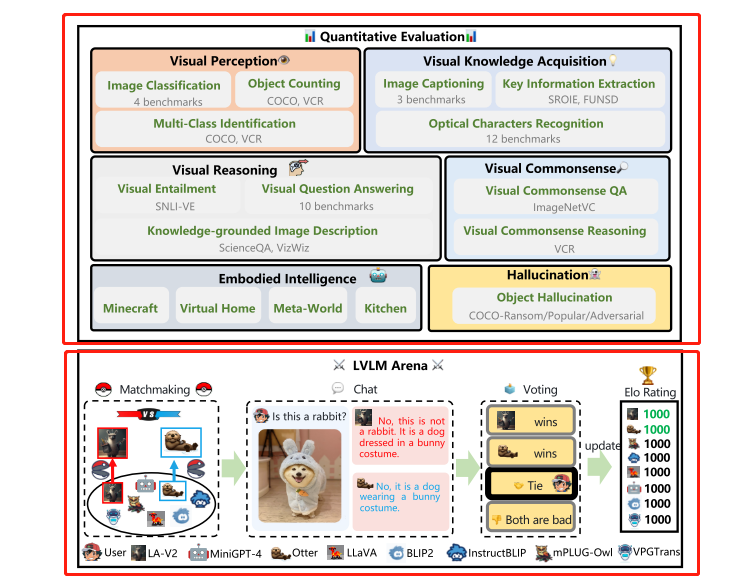
Зрительное восприятие. Зрительное восприятие — это способность распознавать сцены или объекты на изображении и является основной способностью зрительной системы человека. Включая задачи классификации изображений, многоклассовое распознавание и задачи подсчета объектов.
Приобретение визуальных знаний. Приобретение визуальных знаний требует выхода за рамки восприятия, чтобы понимать изображения и приобретать знания. Включая оптическое распознавание символов, извлечение ключевой информации и задачи описания изображений.
Визуальное мышление. Визуальное мышление требует всестороннего понимания изображений и связанного с ними текста. Чтобы оценить способность LVLM к визуальному мышлению, включены три задачи, включая визуальный ответ на вопрос (VQA), визуальное следование и задачи описания изображения на основе знаний.
Визуальный здравый смысл. Эта оценка проверяет понимание моделью общедоступных человеческих знаний с использованием ImageNetVC и визуального здравого смысла (VCR). В частности, ImageNetVC используется для нулевой визуальной оценки, такой как цвет и форма, в то время как VCR охватывает различные сценарии, такие как пространственная, причинная и психологическая здравая оценка.
Галлюцинация объекта: модель визуального языка имеет проблему галлюцинации объекта, то есть сгенерированный объект описания не соответствует целевому изображению.В этой статье оценивается проблема галлюцинации объекта модели визуального языка в наборе данных MSCOCO.
Embodied Intelligence: Цель Embodied Intelligence — создать гуманоидных роботов и позволить им научиться решать сложные задачи, требующие взаимодействия с окружающей средой. В этой статье в качестве эталона используются задачи высокого уровня в EmbodiedGPT.
В этой статье исследуются возможности нулевого выстрела моделей визуального языка в различных новых задачах для оценки вышеупомянутых шести категорий возможностей. В частности, в этом документе оценка с нулевым выстрелом рассматривается как инженерия подсказок для различных форм задач:
-
Ответ на вопрос: Разработайте соответствующие визуальные подсказки к вопросам, чтобы гарантировать, что модели визуального языка генерируют значимые результаты, например, «что написано на изображении» в качестве текстовых подсказок для задач OCR.
-
Оценки на основе префиксов: для задач с выбором из нескольких вариантов, учитывая определенный визуальный сигнал для изображения, позвольте модели сгенерировать вероятность изображения и текста и принять визуальный сигнал, который дает результат максимального правдоподобия, в качестве ответа.
-
Многоходовое рассуждение: используйте LLM, такой как ChatGPT, для создания подвопросов для данного вопроса, модель визуального языка предоставляет соответствующие дополнительные ответы, а другой LLM оценивает качество дополнительных ответов. Повторяйте этот процесс до тех пор, пока не будет получен удовлетворительный ответ или не будет достигнуто заранее определенное максимальное количество итераций.
-
Опросы пользователей. Позвольте людям оценить качество, релевантность и полезность текста, созданного с помощью моделей визуального языка в определенных контекстах. Чтобы обеспечить справедливость оценки, в этом документе порядок вывода модели будет случайным образом перетасовываться и анонимизировать выходные данные в процессе оценки.
Что еще интереснее, в ходе исследования также была создана интерактивная платформа для оценки моделей визуального языка, позволяющая объединять модели в пары в форме турнира.Пользователи могут использовать изображения и текстовые вводы, чтобы общаться с парными моделями на любую тему и моделировать реальный мир. условия. После этапа чата пользователи голосуют за модель и позволяют пользователям выступать в качестве рецензентов, что может привести к более убедительным результатам оценки, чем традиционные показатели оценки.
Пусть в мультимодальной модели будет «Чемпионат мира покемонов», это ты, Пикачу, модель LLaVA~

2. Результаты оценки существующих моделей визуального языка
В статье оценивалось 8 репрезентативных моделей, включая BLIP2, LLaVA, LLaMA-Adapter V2, MiniGPT-4, mPLUG-Owl, Otter, InstructBLIP и VPGTrans.
Основные модели показали относительно хорошие возможности нулевой выборки в шести категориях задач, особенно InstructBLIP достиг производительности, значительно превосходящей другие модели почти во всех задачах.
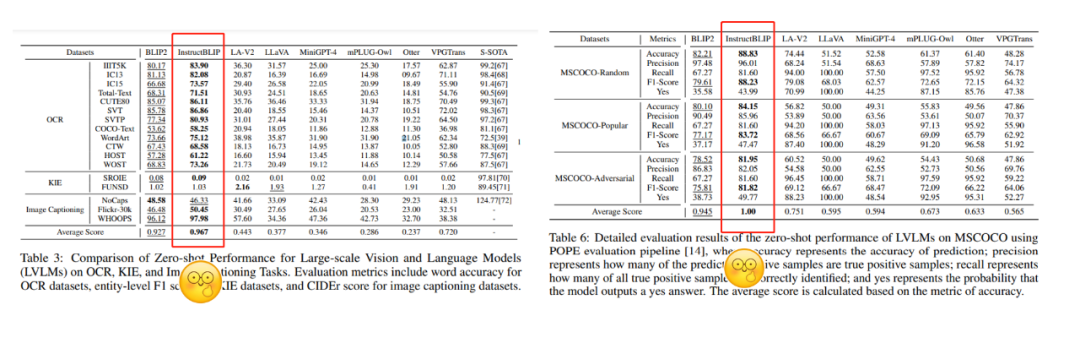
InstructBLIP показал гораздо лучшую производительность, чем другие модели, при выполнении различных задач.
Но автор пессимистично отметил, что причина такой превосходной производительности — производительность переобучения модели.
С одной стороны, InstructBLIP выполнил точную настройку инструкций на 1,6 миллионах наборов данных VQA, что намного превосходит другие модели визуального языка. Таким образом, он чрезвычайно хорошо справляется с количественной оценкой существующих задач внутри предметной области. С другой стороны, он близко к реальной сцене.В онлайн-интерактивной оценке InstructBLIP значительно хуже других моделей, но лучше всего работают mPLUG-Owl и MiniGPT-4.
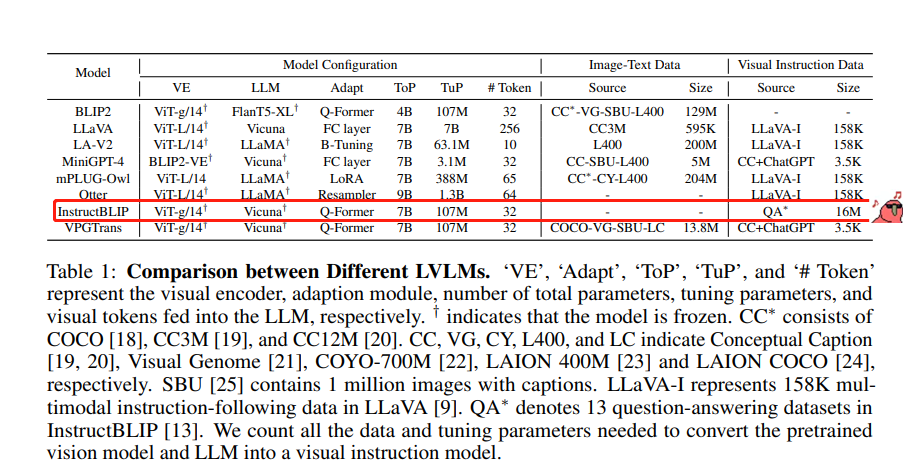
Наборы данных для точной настройки инструкций для 8 основных моделей визуального языка.

InstructBLIP показал плохие результаты в интерактивной онлайн-оценке, близкой к реальной сцене, но другие модели, такие как mPLUG-Owl, MiniGPT-4, Otter и другие, показали хорошие результаты.
Хорошая новость заключается в том, что более крупный набор данных для точной настройки инструкций может улучшить производительность модели при выполнении внутрипредметных задач, но плохая новость заключается в том, что модель переоснащает данные. Языковым моделям еще предстоит пройти долгий путь!
