Fuente del artículo Editor de Xinzhiyuan: Tao Zi
【Guía】 Enciclopedia Baidu: "Cinemagraph, la tecnología mágica de movimiento sutil en fotografías fijas. Como sugiere el nombre (cine es fotografía cinematográfica, gráfico son imágenes) es una combinación de fotografía dinámica e imágenes fijas. Este arte surgió por primera vez del sitio web cinemagraphs. , de los artistas neoyorquinos Jamie y Kevin".
El último modelo de IA, Text2Cinemagraph, puede animar las obras de los maestros del arte con una sola línea de texto.
El nuevo artículo del jefe de CV, Zhu Junyan, hizo que los animadores se sintieran en peligro.
Solo se necesita una oración y el modelo puede generar una animación con un estilo consistente y buena calidad.
Usando la Noche estrellada de Van Gogh como referencia, crea una imagen de un arroyo que fluye frente a una montaña.

O, al estilo de Afremov, crear un paisaje de cascadas que descienden de las montañas.

Recientemente, investigadores de CMU y el Snap Institute han desarrollado un método totalmente automático para crear imágenes de películas a partir de descripciones de texto: Text2Cinemagraph.

Dirección del artículo: https://arxiv.org/pdf/2307.03190.pdf
Además, los investigadores demostraron dos extensiones, animando dibujos existentes y usando texto para controlar la dirección del movimiento.
¿Por qué no vemos una demostración primero?
huelgas de demostración
La dirección del chorro sobre La noche estrellada de Van Gogh se puede controlar moviendo la boca.
Por ejemplo, de izquierda a derecha.

Luego de derecha a izquierda.

Mismo estilo, diferente paisaje.

Calidad de película, navegando en el mar.
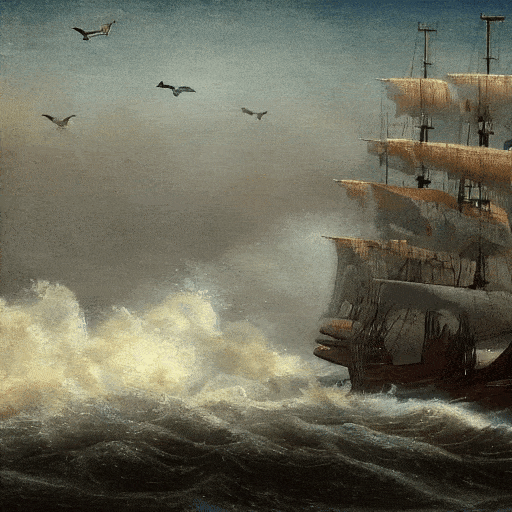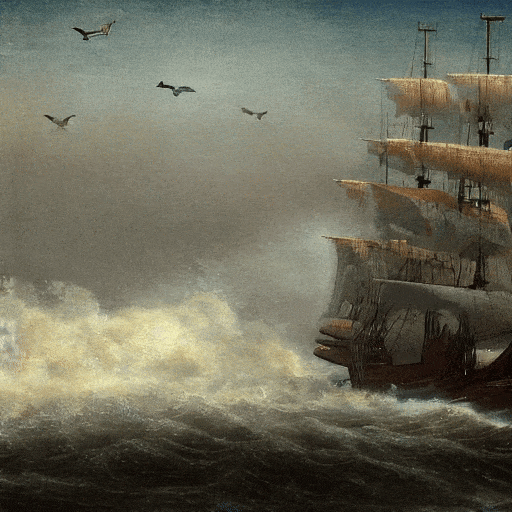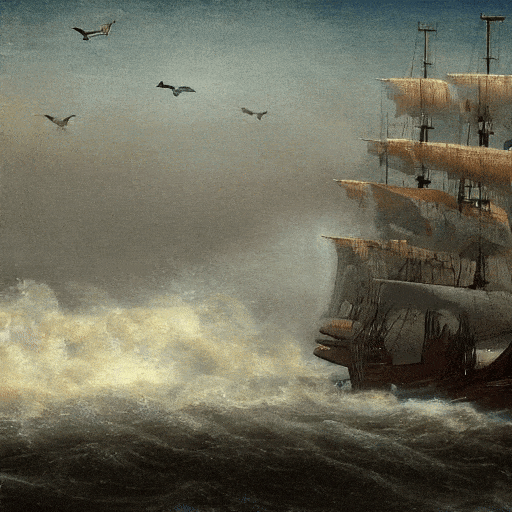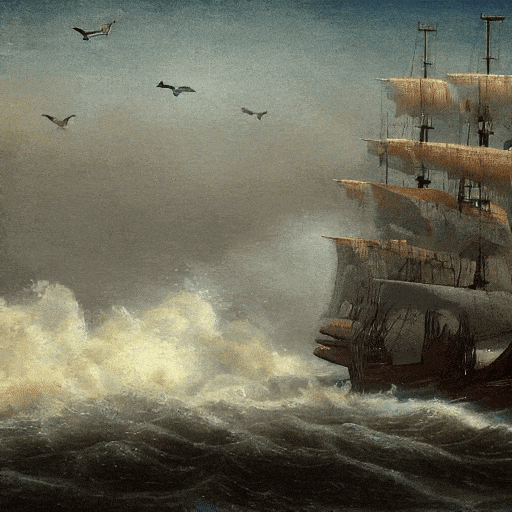
Al atardecer, al estilo del cuadro de Van Gogh, una gran cascada cae entre las colinas, 4K.

Estilo Picasso, una cabaña de madera con un barco flotando en el lago.
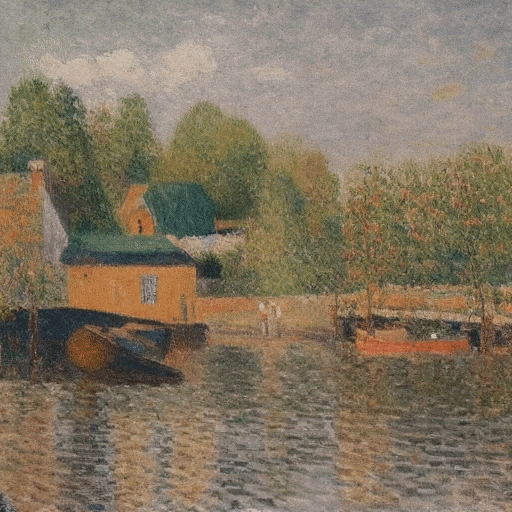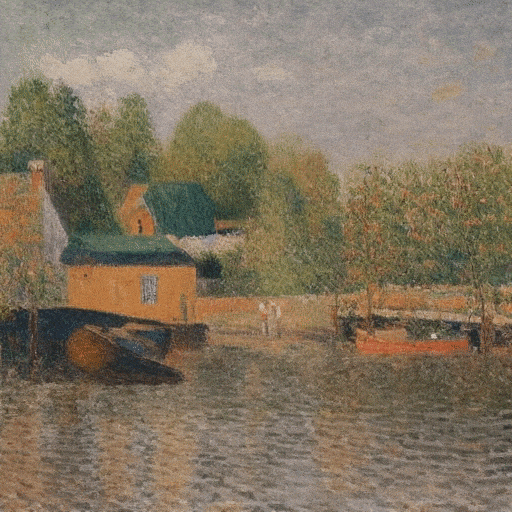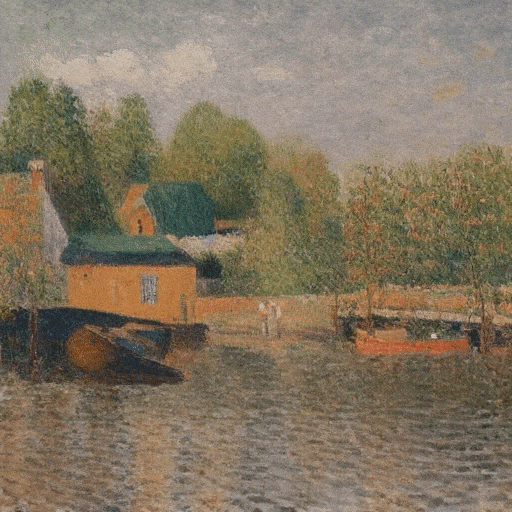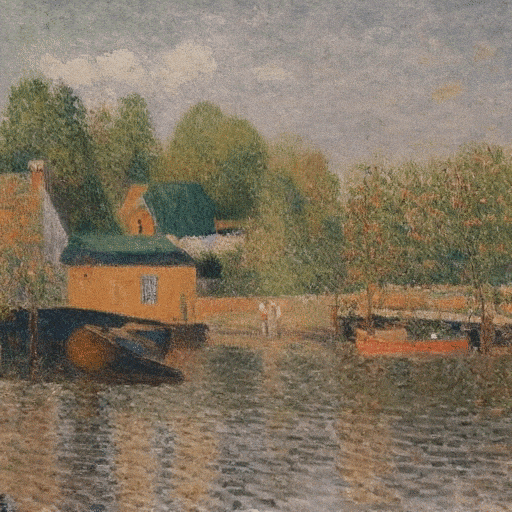
Ilustración ultrarrealista de un faro atacado por un monstruo marino y tentáculos que envuelven toda la torre.

Escena de cascada surrealista y fantástica.

Proyecto Text2Cinemagraph
Actualmente, los métodos de animación de una sola imagen existentes son insuficientes en términos de aportación artística.
Sin embargo, los métodos de vídeo más modernos basados en texto a menudo introducen inconsistencias temporales, lo que dificulta mantener estáticas ciertas regiones.
Para abordar estos desafíos, los investigadores proponen la idea de sintetizar imágenes gemelas, es decir, un par de imágenes artísticas y su alineación de píxeles, a partir de una única señal de texto.
Las imágenes artísticas representan el estilo y la apariencia detalladas en las indicaciones de texto, mientras que las imágenes realistas simplifican enormemente el diseño y el análisis de movimiento.

Utilizando conjuntos de datos de imágenes y videos naturales existentes, Text2Cinemagraph puede segmentar con precisión imágenes realistas y predecir movimientos plausibles basándose en información semántica.
Luego, el movimiento previsto se puede transferir a imágenes artísticas para crear la animación cinematográfica final.
Específicamente, dada una señal textual c, la Difusión estable se utiliza para generar imágenes gemelas, una imagen artística x en el estilo descrito en la señal textual y una contraparte realista 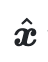 usando la señal modificada
usando la señal modificada 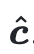 . Las imágenes siamesas tienen diseños semánticos similares.
. Las imágenes siamesas tienen diseños semánticos similares.
Luego, los investigadores extraen máscaras binarias M de regiones de movimiento de los mapas de autoatención obtenidos durante la generación de imágenes artísticas.
Utilice máscaras e imágenes realistas para predecir el flujo óptico 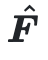 y los modelos de predicción de flujo
y los modelos de predicción de flujo  .
.
Dado que las imágenes gemelas tienen diseños semánticos muy similares, se pueden utilizar 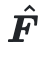 generadores de flujo óptico y de vídeo
generadores de flujo óptico y de vídeo  para animar imágenes artísticas.
para animar imágenes artísticas.
Cabe mencionar que todos los experimentos de este estudio se basan en Difusión Estable.

Los investigadores compararon el efecto real del flujo óptico.
Flujo óptico real promediado en todos los fotogramas en Text2Cinemagraph en comparación con SLR-SFS, el enfoque de animación de una sola imagen de investigación de Holynski et al.
En general, el método de última generación predice movimientos más plausibles que se adaptan mejor a la región objetivo.

Además, a través de la encuesta de preferencias de los usuarios, la mayoría de los participantes se muestran a favor de Text2Cinemagraph.

Finalmente, los investigadores también demostraron dos extensiones: animar dibujos existentes y usar texto para controlar la dirección del movimiento.
Animar una pintura existente
La siguiente es La novena ola (1850) expuesta en el Museo Ruso.

Óleo sobre lienzo Cataratas Minnehaha de Albert Bierstadt.
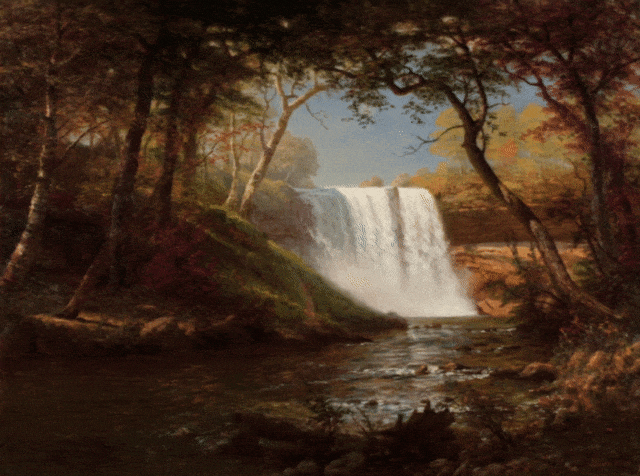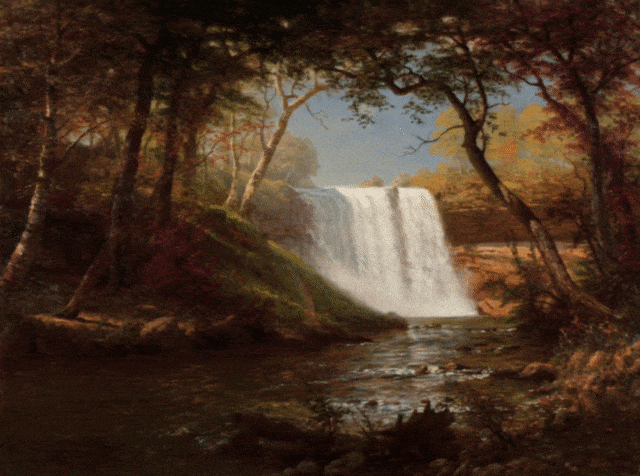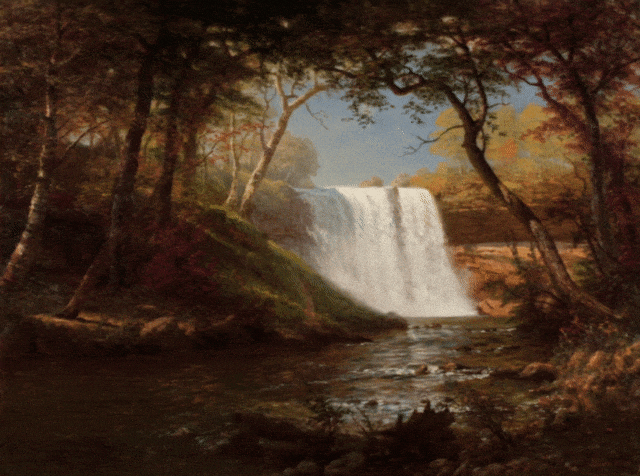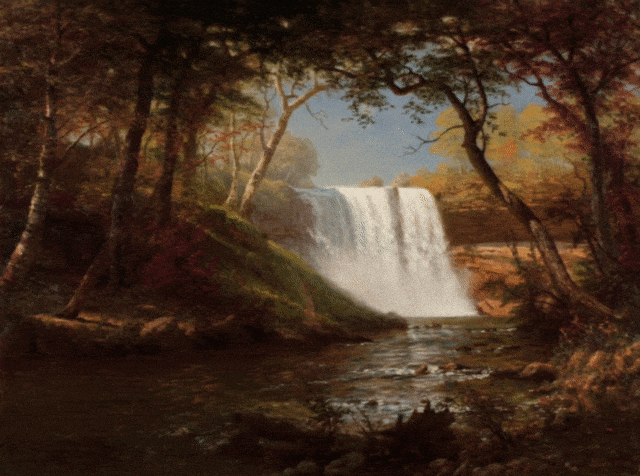
Sobre el Autor
Jun-Yan Zhu

Zhu Junyan es actualmente profesor asistente en el Instituto de Robótica de la Facultad de Ciencias de la Computación de CMU y es un pionero en la aplicación del aprendizaje automático moderno en el campo de los gráficos por computadora.
Antes de unirse a CMU, fue científico investigador en Adobe Research.
Realizó un postdoctorado en MIT CSAIL, trabajando con William T. Freeman, Josh Tenenbaum y Antonio Torralba.
También recibió su doctorado en UC Berkeley bajo la supervisión de Alexei A. Efros. Y recibió una licenciatura de la Universidad de Tsinghua, trabajando con Zhuowen Tu, Shi-Min Hu y Eric Chang.
Referencias:
https://text2cinemagraph.github.io/website/
Preste atención a la cuenta oficial [Aprendizaje automático y creación de generación de IA], hay más cosas interesantes esperando que lea
¡Explicación detallada de ControlNet, un algoritmo de generación de pintura AIGC controlable!
Classic GAN tiene que leer: StyleGAN
 ¡Haz clic en mí para ver los álbumes de la serie GAN ~!
¡Haz clic en mí para ver los álbumes de la serie GAN ~!
¡Una taza de té con leche, conviértete en la frontera de la visión AIGC + CV!
¡El último y más completo resumen de 100! Generar modelos de difusión Modelos de difusión
ECCV2022 | Resumen de algunos artículos sobre la generación de redes de confrontación GAN
CVPR 2022 | Más de 25 direcciones, los últimos 50 artículos de GAN
ICCV 2021 | Resumen de artículos de GAN sobre 35 temas
¡Más de 110 artículos! CVPR 2021 peinado de papel GAN más completo
¡Más de 100 artículos! CVPR 2020 peinado de papel GAN más completo
Desmantelando la nueva GAN: desacoplando la representación MixNMatch
StarGAN Versión 2: Generación de imágenes de diversidad multidominio
Descarga adjunta | Versión china de "Aprendizaje automático explicable"
Descarga adjunta | "Algoritmos de aprendizaje profundo de TensorFlow 2.0 en la práctica"
Descarga adjunta | "Métodos Matemáticos en Visión por Computador" compartir
Un estudio sobre la clasificación de imágenes de disparo cero: una década de progreso
"Un estudio sobre el aprendizaje en pocas oportunidades basado en redes neuronales profundas"
"Libro de los Ritos · Xue Ji" tiene un dicho: "Aprender solo sin amigos es solitario e ignorante".
¡Haga clic en una taza de té con leche y conviértase en el líder de la visión AIGC+CV! , ¡únete al planeta de la creación generada por IA y el conocimiento de la visión por computadora!