La fuente de este artículo es el departamento editorial del corazón de la máquina.
En los últimos años, los modelos de generación de imágenes basados en modelos de difusión han surgido en una corriente interminable, mostrando efectos de generación sorprendentes. Sin embargo, el marco de código del modelo de investigación relacionado existente tiene el problema de una fragmentación excesiva y la falta de un sistema de marco unificado, lo que resulta en problemas de implementación del código de "migración difícil", "umbral alto" y "mala calidad".
Con este fin, el Laboratorio de Fusión de Inteligencia Física, Computadora y Humano (HCP Lab) de la Universidad Sun Yat-sen construyó el marco HCP-Diffusion, que implementó sistemáticamente algoritmos relacionados basados en el modelo de Difusión, como el ajuste fino del modelo, el entrenamiento personalizado y el razonamiento. optimización y edición de imágenes.La estructura es la siguiente:La Figura 1 lo muestra.
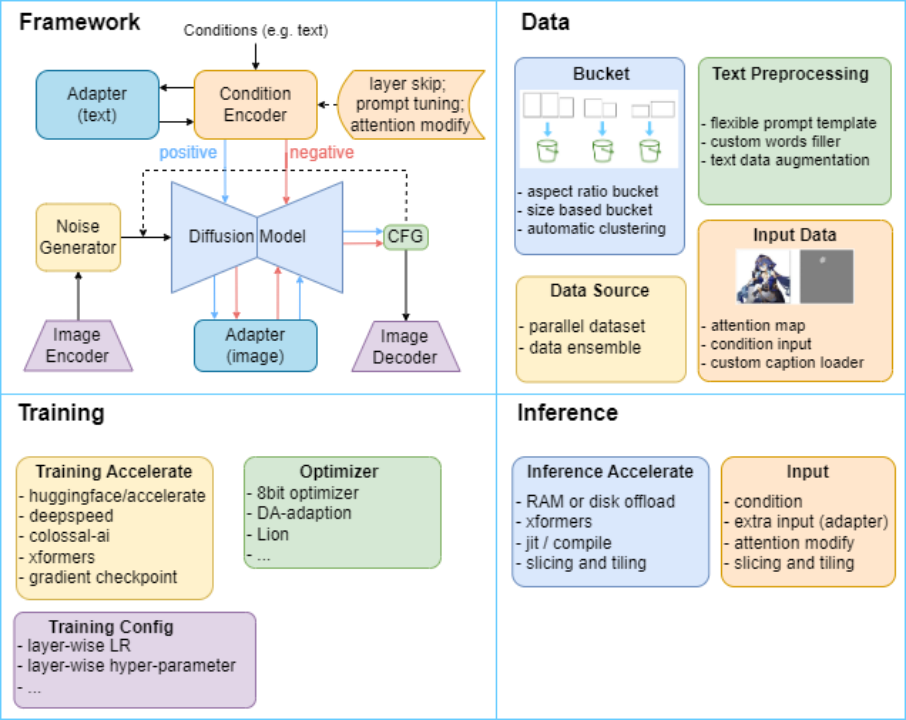
Figura 1 Diagrama de estructura del marco HCP-Diffusion, unifica los métodos existentes relacionados con la difusión a través de un marco unificado y proporciona una variedad de métodos modulares de optimización de inferencia y capacitación.
HCP-Diffusion implementa varios componentes y algoritmos a través de un archivo de configuración unificado, lo que mejora enormemente la flexibilidad y escalabilidad del marco. Los desarrolladores combinan algoritmos como bloques de construcción sin repetir los detalles del código de implementación.
Por ejemplo, según HCP-Diffusion, podemos completar la implementación y combinación de LoRA, DreamArtist, ControlNet y otros algoritmos comunes simplemente modificando el archivo de configuración. Esto no sólo reduce el umbral de innovación, sino que también hace que el marco sea compatible con varios diseños personalizados.
Herramienta de código HCP-Diffusion: https://github.com/7eu7d7/HCP-Diffusion
GUI de HCP-Diffusion: https://github.com/7eu7d7/HCP-Diffusion-webui
HCP-Diffusion: Introducción al módulo de funciones
Características del marco
HCP-Diffusion se da cuenta de la versatilidad del marco al modularizar el marco actual del algoritmo de entrenamiento de difusión convencional. Las características principales son las siguientes:
Arquitectura unificada: cree un marco de código unificado para los modelos de la serie Diffusion
Complemento de operador: admite algoritmos de operador como datos, capacitación, razonamiento y optimización del rendimiento, como velocidad profunda, IA colosal y descarga para acelerar la optimización.
Configuración con un solo clic: los modelos de la serie Diffusion pueden completar la realización del modelo modificando los archivos de configuración con alta flexibilidad
Capacitación con un solo clic: proporciona interfaz de usuario web, capacitación e inferencia con un solo clic
módulo de datos
HCP-Diffusion admite la definición de múltiples conjuntos de datos paralelos. Cada conjunto de datos puede usar diferentes tamaños de imagen y formatos de anotación. Cada iteración de entrenamiento extraerá un lote de cada conjunto de datos para el entrenamiento, como se muestra en la Figura 2. Además, cada conjunto de datos se puede configurar con múltiples fuentes de datos, admite txt, json, yaml y otros formatos de anotación o formatos de anotación personalizados, y tiene un mecanismo de carga y preprocesamiento de datos altamente flexible.
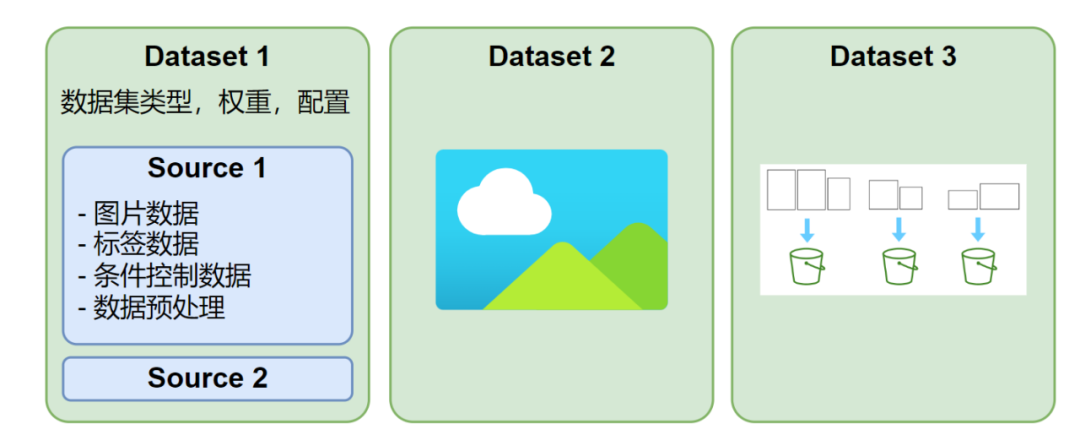
Figura 2 Diagrama esquemático de la estructura del conjunto de datos.
La parte de procesamiento de conjuntos de datos proporciona un depósito de relación de aspecto con agrupación automática, que admite el procesamiento de conjuntos de datos con diferentes tamaños de imagen. El usuario no necesita realizar procesamiento ni alineación adicionales en el tamaño del conjunto de datos, y el marco seleccionará automáticamente el método de agrupación óptimo según la relación de aspecto o la resolución. Esta tecnología reduce en gran medida el umbral del procesamiento de datos, optimiza la experiencia del usuario y permite a los desarrolladores centrarse más en la innovación del algoritmo en sí.
Para el preprocesamiento de datos de imágenes, el marco también es compatible con varias bibliotecas de procesamiento de imágenes, como visión de antorcha, albumentaciones, etc. Los usuarios pueden configurar directamente el método de preprocesamiento en el archivo de configuración según sus necesidades, o expandir el método de procesamiento de imágenes personalizado sobre esta base.
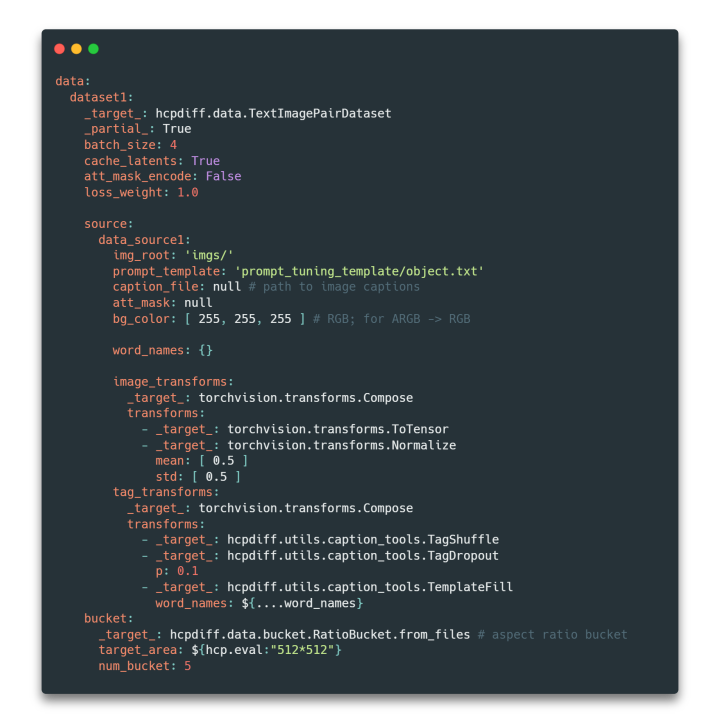
Figura 3 Ejemplo de archivo de configuración de conjunto de datos
En términos de etiquetado de texto, HCP-Diffusion ha diseñado una especificación de plantilla de aviso flexible y clara, que puede admitir métodos de capacitación y etiquetado de datos complejos y diversos. Corresponde a los nombres de palabras en el directorio fuente del archivo de configuración anterior, en el que puede personalizar los vectores de palabras incrustados y las descripciones de categorías correspondientes a los caracteres especiales entre llaves en la figura siguiente, para que sean compatibles con modelos como DreamBooth y DreamArtist.

Figura 4 plantilla de aviso
Y para la anotación de texto, también proporciona una variedad de métodos de mejora de texto, como el borrado oración por oración (TagDropout) o la codificación oración por oración (TagShuffle), que pueden reducir el problema de sobreajuste entre imágenes y datos de texto. y hacer que las imágenes generadas cambien más diversas.
Módulo de marco modelo
HCP-Diffusion se da cuenta de la versatilidad del marco al modularizar el marco actual del algoritmo de entrenamiento de difusión convencional. Específicamente, Image Encoder y Image Decoder completan la codificación y decodificación de imágenes, el Noise Generator genera ruido en el proceso directo, el modelo de difusión realiza el proceso de difusión, el codificador de condiciones codifica las condiciones de generación, el modelo de ajuste fino del adaptador está alineado con las tareas posteriores, positivas y negativas. Los canales dobles representan la generación de imágenes de control condicional positivo y negativo.

Figura 5 Ejemplo de configuración de la estructura del modelo (complementos de modelo, palabras personalizadas, etc.)
Como se muestra en la Figura 5, HCP-Diffusion puede implementar varios algoritmos de entrenamiento convencionales, como LoRA, ControlNet y DreamArtist, mediante una combinación simple en el archivo de configuración. Al mismo tiempo, admite la combinación de los algoritmos anteriores, como el entrenamiento LoRA y de inversión textual al mismo tiempo, vinculando palabras desencadenantes exclusivas para LoRA, etc. Además, a través del módulo de complemento, cualquier complemento se puede personalizar fácilmente y es compatible con todos los métodos de acceso convencionales actuales. A través de la modularización anterior, HCP-Diffusion realiza la construcción del marco de cualquier algoritmo convencional, reduce el umbral de desarrollo y promueve la innovación colaborativa de modelos.
HCP-Diffusion abstrae varios algoritmos de adaptador, como LoRA y ControlNet, en complementos de modelo. Al definir algunas clases base de complementos de modelo generales, todos estos algoritmos se pueden tratar de manera uniforme, lo que reduce los costos de usuario y los costos de desarrollo. Todas las clases de adaptador Los algoritmos están unificados .
El marco proporciona cuatro tipos de complementos, que pueden admitir fácilmente todos los algoritmos convencionales actuales:
+ SinglePluginBlock: un complemento de una sola capa que cambia la salida según la entrada de esta capa, como la serie lora. Admite expresiones regulares (re: prefijo) para definir la capa de inserción, no admite pre_hook: prefijo.
+ PluginBlock: solo hay una capa de entrada y una capa de salida, como la definición de conexiones residuales. Admite expresiones regulares (re: prefijo) para definir la capa de inserción, y tanto la capa de entrada como la de salida admiten pre_hook: prefijo.
+ MultiPluginBlock: Puede haber múltiples capas de entrada y salida, como controlnet. No admite expresiones regulares (re: prefijo), tanto la capa de entrada como la de salida admiten pre_hook: prefijo.
+ WrapPluginBlock: reemplaza una capa del modelo original y usa la capa del modelo original como un objeto de esta clase. Admite expresiones regulares (re: prefijo) para definir capas de reemplazo, no admite pre_hook: prefijo.
entrenamiento, módulo de inferencia

Figura 6 Configuración del optimizador personalizado
El archivo de configuración en HCP-Diffusion admite la definición de objetos Python, de los que se crean instancias automáticamente en tiempo de ejecución. Este diseño permite a los desarrolladores acceder fácilmente a cualquier módulo personalizado instalable por pip, como optimizadores personalizados, funciones de pérdida, muestreadores de ruido, etc., sin modificar el código del marco, como se muestra en la figura anterior. La estructura del archivo de configuración es clara, fácil de entender y altamente reproducible, lo que ayuda a conectar sin problemas la investigación académica y la implementación de ingeniería.
Soporte de optimización acelerada
HCP-Diffusion admite múltiples marcos de optimización del entrenamiento, como Accelerate, DeepSpeed y Colossal-AI, que pueden reducir significativamente el uso de memoria durante el entrenamiento y acelerarlo. Admite la operación EMA, que puede mejorar aún más el efecto de generación y la generalización del modelo. En la etapa de inferencia, se admiten operaciones como la descarga de modelos y el mosaico VAE, y la generación de imágenes se puede completar con un mínimo de 1 GB de memoria de video.

Figura 7 Archivo de configuración modular
A través de la configuración de archivo simple anterior, puede completar la configuración del modelo sin gastar mucho esfuerzo para encontrar los recursos del marco relevantes, como se muestra en la figura anterior. El diseño modular de HCP-Diffusion separa completamente la definición del método del modelo, la lógica de entrenamiento y la lógica de inferencia. Al configurar el modelo, no es necesario considerar la lógica de las partes de entrenamiento e inferencia, lo que ayuda a los usuarios a centrarse mejor en el método en sí. Al mismo tiempo, HCP-Diffusion ha proporcionado ejemplos de configuración del marco de la mayoría de los algoritmos principales, y la implementación solo se puede realizar modificando algunos de los parámetros.
HCP-Diffusion: interfaz gráfica de interfaz de usuario web
Además de modificar directamente los archivos de configuración, HCP-Diffusion ha proporcionado una interfaz de imagen de interfaz de usuario web correspondiente, que incluye múltiples módulos, como generación de imágenes y entrenamiento de modelos, para mejorar la experiencia del usuario, reducir en gran medida el umbral de aprendizaje del marco y acelerar el algoritmo desde teoría a la práctica transformar.
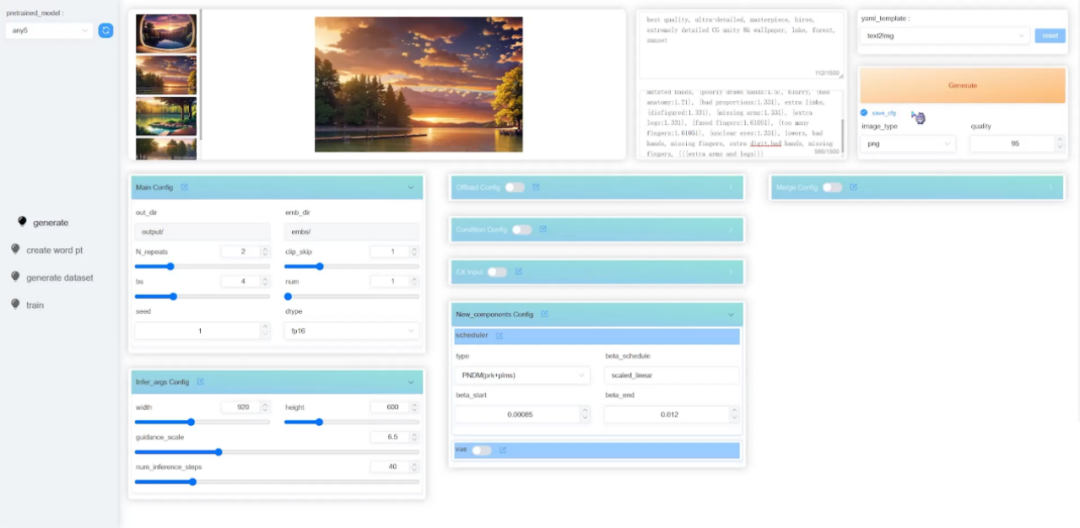
Figura 8 Interfaz de imagen de la interfaz de usuario web de HCP-Diffusion
Introducción al laboratorio
El Laboratorio HCP de la Universidad Sun Yat-sen fue fundado por el profesor Lin Ji en 2010. En los últimos años, ha logrado importantes logros académicos en comprensión de contenido multimodal, razonamiento causal y cognitivo, aprendizaje incorporado, etc., y ha ganado varios premios. Premios de ciencia y tecnología nacionales y extranjeros y premios al mejor artículo, y se compromete a crear plataformas y tecnología de IA a nivel de producto. Sitio web del laboratorio: http://www.sysu-hcp.net
Preste atención a la cuenta oficial [Aprendizaje automático y creación de generación de IA], hay más cosas interesantes esperando que lea
¡Explicación detallada de ControlNet, un algoritmo de generación de pintura AIGC controlable!
Classic GAN tiene que leer: StyleGAN
 ¡Haz clic en mí para ver los álbumes de la serie GAN ~!
¡Haz clic en mí para ver los álbumes de la serie GAN ~!
¡Una taza de té con leche, conviértete en la frontera de la visión AIGC + CV!
¡El último y más completo resumen de 100! Generar modelos de difusión Modelos de difusión
ECCV2022 | Resumen de algunos artículos sobre la generación de redes de confrontación GAN
CVPR 2022 | Más de 25 direcciones, los últimos 50 artículos de GAN
ICCV 2021 | Resumen de artículos de GAN sobre 35 temas
¡Más de 110 artículos! CVPR 2021 peinado de papel GAN más completo
¡Más de 100 artículos! CVPR 2020 peinado de papel GAN más completo
Desmantelando la nueva GAN: desacoplando la representación MixNMatch
StarGAN Versión 2: Generación de imágenes de diversidad multidominio
Descarga adjunta | Versión china de "Aprendizaje automático explicable"
Descarga adjunta | "Algoritmos de aprendizaje profundo de TensorFlow 2.0 en la práctica"
Descarga adjunta | "Métodos Matemáticos en Visión por Computador" compartir
Un estudio sobre la clasificación de imágenes de disparo cero: una década de progreso
"Un estudio sobre el aprendizaje en pocas oportunidades basado en redes neuronales profundas"
"Libro de los Ritos · Xue Ji" tiene un dicho: "Aprender solo sin amigos es solitario e ignorante".
¡Haga clic en una taza de té con leche y conviértase en el líder de la visión AIGC+CV! , ¡únete al planeta de la creación generada por IA y el conocimiento de la visión por computadora!