Campamento de verano de aprendizaje automático de DataWhale, fase II
La segunda fase del campamento de verano de aprendizaje automático de DataWhale
: desafío de predicción de modelos cuantitativos de IA
pasó la línea de base y calificó en línea, 0.51138y aprobó el código avanzado modificado y calificó en línea.0.34497
Registro de aprendizaje 1 (2023.08.06)
Según la transmisión en vivo compartida por Yulao, analice la competencia de aprendizaje automático de acuerdo con las siguientes ideas comunes:

1. Modelado de problemas
1.1 Datos del evento
Situación del conjunto de datos.
Conjunto de datos dado : Conjunto de entrenamiento dado (incluido el conjunto de verificación), que incluye 10 acciones (privadas), datos instantáneos L1 de 79 días de negociación (los primeros 64 días de negociación son datos de capacitación para la capacitación; los últimos 15 días de negociación son datos de prueba y no se pueden utilizado para capacitación), los datos se han normalizado y oculto, incluidos 5 niveles de volumen/precio, precio medio, volumen de transacciones y otros datos (para obtener más detalles, consulte la descripción de los datos de seguimiento).
Tarea de pronóstico : utilice datos pasados y actuales para predecir la dirección del futuro movimiento del precio medio y realice entrenamiento y predicción del modelo en los datos.
Datos de entrada :
frecuencia del mercado: un punto de datos cada 3 segundos (también conocido como instantánea de un tick) ;
cada punto de datos Incluye datos como el último precio de transacción actual/cinco niveles de volumen y precio/monto de transacción en los últimos 3 segundos;
cada punto de datos en el conjunto de entrenamiento contiene 5 etiquetas de predicción; se permite usar datos que no supere los 100 ticks en el pasado (incluido el tick actual) para predecir la dirección del movimiento del precio medio después de N ticks en el futuro.
Intervalo de tiempo de predicción: 5, 10, 20, 40, 60 ticks, 5 tareas de predicción,
es decir, en el momento t, predice respectivamente t+5tick, t+10tick, t+20tick, t+40tick, t+60tick más tarde: Último Comparado con el precio medio en el momento t, el precio medio: abajo/sin cambios/arriba.
Los datos se dividen en conjunto de entrenamiento y conjunto de prueba: el conjunto de entrenamiento incluye los datos de la mañana y la tarde de sym0 ~ 9un total de días 10sim , y el conjunto de prueba son los datos de los días posteriores . La cantidad de datos es grande, un problema típico de pronóstico de series de tiempo. El paso de tiempo es de 3 s y oscila entre ~ , ~ . Ideas:date0 ~ 6364date64 ~ 781409:40:0311:19:5713:10:0314:49:57
- Al construir características de series de tiempo, es necesario considerar agrupar cada mañana y tarde para garantizar que los pasos de tiempo sean consistentes.
- 10 acciones se tratan por separado
- Maneja las 5 tareas por separado,
N=5,10una categoría,N = 20,40,60una categoría
valores faltantes en los datos
train_df.isnull().sum()
no faltan valores
Distribuciones base para características categóricas y numéricas.
Ver la distribución de datos de características numéricas en el conjunto de entrenamiento y el conjunto de prueba
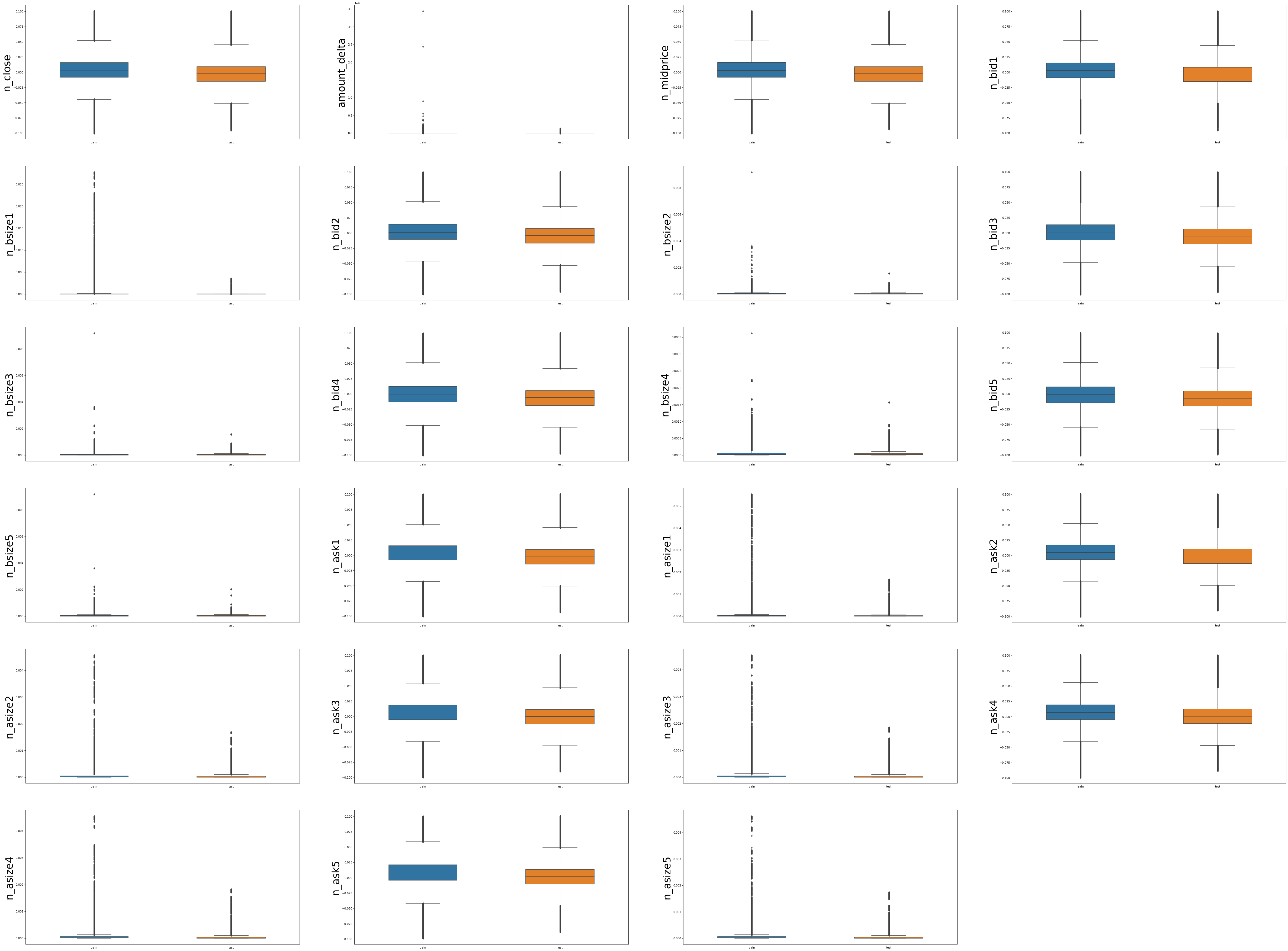
- Las variables numéricas de la categoría de precio son relativamente estables y los rangos de distribución de los conjuntos de entrenamiento y prueba son básicamente los mismos, como 'n_close', 'n_midprice', 'n_bid1', 'n_ask1', etc.
- Sin embargo, el cambio del conjunto de entrenamiento de variables numéricas relacionadas con el volumen de operaciones es mayor que el del conjunto de prueba. Hay datos en el conjunto de entrenamiento con un volumen de operaciones mucho mayor que el volumen de operaciones del conjunto de pruebas. El análisis posterior puede Estudiar si las fechas correspondientes a estos elevados volúmenes de negociación son de un solo día o si son horas especiales, y si se trata de un caso atípico
1.2 Indicadores de evaluación
Cómo calcular el precio medio
n _ precio medio = n _ oferta 1 + n _ oferta 2 2 n\_precio medio = \frac{n\_bid1+n\_bid2}{2}n _ precio medio _ _ _ _=2n _ oferta 1 _+n _ bi d 2
Entre ellos, uno toma otro valor de 0.
Análisis :
ver como n _ bid 1, n _ bid 2 n\_bid1, n\_bid2n_oferta 1 , _ _ _Filas donde existe 0 en n_bi d 2 :
train_df[(train_df['n_bid1'] == 0 )| (train_df['n_ask1'] == 0)].index
Index([ 6641, 6642, 6645, 6646, 6647, 6648, 6649, 6650,
6651, 6652,
...
2446840, 2446842, 2446844, 2446845, 2446846, 2446848, 2446918, 2446919,
2446920, 2446921],
dtype='int64', length=175414)
_ oferta 1, n _ oferta 2 n_bid1, n_bid2 como arriban_oferta 1 , _ _ _Hay un índice de fila de 0 en n_bi d 2 y un total de 175414 filas tienen un valor de 0. Esto también explica la razón por la cual el valor de la transacción está sesgado hacia el extremo inferior en el análisis del diagrama de caja anterior. Por lo tanto, se pueden realizar más análisis de las características relacionadas con el volumen de transacciones más adelante, incluyendo: 1) eliminar la distribución de observación del valor 0, 2 ) toma el logaritmo.
Después de eliminar 0, en realidad tiene poco efecto en la distribución y la cantidad de datos que contienen 0 es demasiado pequeña:
Además, no hay filas que sean todas 0, resultado que se ha obtenido en el análisis de valores faltantes.
Explicación de la dirección del movimiento de precios.
Según el ascenso y la caída, se divide en 2 (aumento), 1 (sin cambios), 0 (caída)
Etiqueta N = σ ( n _ midpricet + N − n _ midpricet ) Label_t^N = \sigma(n\_midprice_ {t+N} - n\_midprice_t)etiqueta _ _ _tnorte=σ ( n _ mi d p r i c et + norte−n _ precio medio _ _ _ _ _t)
Descripción de la fórmula de la pregunta del concurso
Aún no la he entendido claramente. Calculé las etiquetas de acuerdo con la fórmula dada y descubrí que no son consistentes. Además, si se determina este indicador específico, ¿se puede utilizar directamente para el cálculo del conjunto de prueba?
1.3 Verificación sin conexión
Baseline adopta una validación cruzada de K. Para garantizar la coherencia de los datos en las series de tiempo, data50~63en el futuro se utilizará un total de 14 días de datos en el conjunto de entrenamiento como conjunto de verificación para mantener la coherencia en línea y fuera de línea tanto como sea posible. posible y analizar el rendimiento de las características derivadas en la ingeniería de características posterior.
El siguiente paso es analizar más a fondo los datos, crear funciones cruzadas y funciones de series de tiempo para la mañana y la tarde de diferentes acciones en diferentes días, crear diferentes modelos para cinco tareas de predicción diferentes y utilizar los 14 días posteriores al entrenamiento. establecido como el conjunto de verificación para la verificación (K demasiado largo). Además, al recopilar información comercial, siento que la comprensión del tema de la competencia no es lo suficientemente clara.
PD:
- El sistema de competición de una ronda, según la clasificación actual, básicamente no
- Mire atentamente las preguntas del concurso, los dos fallos en el envío se deben a que no se dio cuenta de que las preguntas del concurso ya han explicado la descripción detallada del archivo: enviar en formato de archivo zip, codificado como UTF-8, formato de archivo: enviar archivo.zip, incluyendo la carpeta enviar
Registro de estudio II (2023.08.09)
2. Ingeniería de funciones
La velocidad de carga y entrenamiento del modelo cada vez es demasiado lenta y se han realizado algunas optimizaciones.
- Siga las indicaciones del grupo para guardar los datos en formato pickle
# 保存为 pickle
with open('train.pickle', 'wb') as f:
pickle.dump(train_df, f)
with open('test.pickle', 'wb') as f:
pickle.dump(train_df, f)
# 加载 pickle
train_df = pd.read_pickle('train_pickle')
test_df = pd.read_pickle('test_pickle')
- Para evaluar mejor las características, solo se seleccionan
sym=0las acciones de la acción 0label_5para la evaluación de características fuera de línea.
Al mismo tiempo, no se utiliza la validación cruzada K. Además, teniendo en cuenta la cuestión del tiempo,51-57los datos de los días se dividen manualmente como conjunto de verificación,63los días se descartan temporalmente y0-50los días se utilizan como conjunto de verificación. conjunto de entrenamiento.
train_df1 = train_df[train_df['sym'] == 0].sort_values(by = ['date','time'])
cols = [f for f in train_df1.columns if f not in ['uuid','time','file', 'label_5', 'label_10','label_20','label_40','label_60']]
train_df1_train = train_df1[train_df1['date'].isin(train_df1.date.unique()[:-8])]
train_df1_val = train_df1[train_df1['date'].isin(train_df1.date.unique()[-8:-1])]
train_x, train_y = train_df1_train[cols], train_df1_train['label_5']
val_x, val_y = train_df1_val[cols], train_df1_val['label_5']
Combinado con un poco de comprensión de las preguntas de la competencia la última vez y la situación actual de la competencia (varias alcanzaron 0,99), probé la idea de exploración de datos y pensé antes, y construí la función transversal, con la intención de ver qué efecto. lo tiene, fuera de línea El rendimiento fue muy bueno, y luego agregué la función transversal sobre la base de la línea de base y, al mismo tiempo, cancelé la verificación K-fold para obtener resultados más rápido. El resultado es 0.99899... Aunque el conjunto de prueba no se utiliza para entrenamiento, este método en sí no está en línea con la situación real, por lo que el juego aún debe jugarse de acuerdo con la idea normal de derivación de características.
Se recopilaron algunas ideas de modelado sobre series temporales:
- Validación cruzada: validación cruzada continua
import numpy as np
from sklearn.model_selection import TimeSeriesSplit
X = np.array([[1, 2], [3, 4], [1, 2], [3, 4], [1, 2], [3, 4]])
y = np.array([1, 2, 3, 4, 5, 6])
time_series = TimeSeriesSplit()
print(time_series)
for train_index, test_index in time_series.split(X):
print("TRAIN:", train_index, "TEST:", test_index)
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
7 métodos de validación cruzada
-
enfoque de reglas básicas
- Peso promedio
- Pronóstico de series de tiempo de suavizado exponencial
: método de suavizado exponencial e implementación de Python
-
patrón de serie de tiempo
- tendencia
- Tendencia de primer orden: construya la diferencia de datos y la proporción de unidades de tiempo adyacentes;
- Tendencia de segundo orden: refleja el cambio de tendencia de primer orden
- periódicamente
- Relación de anillo, utilizando los datos del mismo período en el ciclo anterior como característica
- Construir características temporales como la posición del tiempo en el ciclo, la diferencia de tiempo desde el pico.
- Correlación (autocorrelación): traducción de turnos, estadísticas de momentos históricos
- Aleatoriedad: marcado anormal o eliminación de preprocesamiento
- tendencia
-
extracción de características
- Traducción de historia
- estadísticas de ventana
- característica de entropía de secuencia
- función de tiempo
- Características estadísticas