Esta serie de publicaciones de blog son notas para artículos de aprendizaje profundo/visión por computadora. Indique la fuente para la reimpresión.
Siguiente: Traducción de imagen a imagen con redes adversarias condicionales
Artículo anterior: Traducción de imagen a imagen con redes adversarias condicionales | Publicación de la conferencia IEEE | Exploración IEEE
Resumen
Investigamos las redes adversarias condicionales como una solución general al problema de traducción de imagen a imagen. Estas redes no solo aprenden un mapeo de imágenes de entrada a imágenes de salida, sino que también aprenden una función de pérdida para entrenar este mapeo. Esto hace posible aplicar el mismo enfoque general a problemas que tradicionalmente requieren formulaciones de pérdidas muy diferentes. Demostramos la efectividad de este enfoque en tareas como sintetizar fotografías a partir de mapas de etiquetas, reconstruir objetos a partir de mapas de bordes y colorear imágenes. Además, desde el lanzamiento del software pix2pix asociado con este artículo, cientos de usuarios de Twitter han twitteado sobre experimentos artísticos utilizando nuestro sistema. Como comunidad, ya no diseñamos manualmente funciones de mapeo, este trabajo muestra que podemos lograr resultados razonables sin diseñar manualmente funciones de pérdida.
1. Introducción
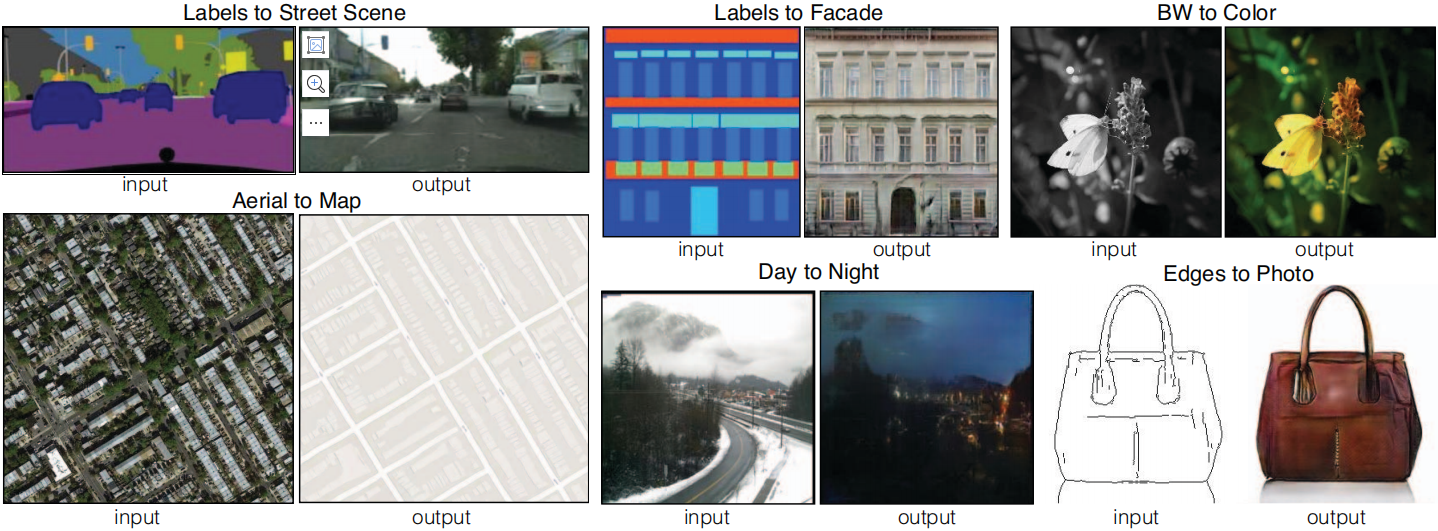
En el procesamiento de imágenes, gráficos por computadora y visión por computadora, muchos problemas pueden verse como "traducir" una imagen de entrada a una imagen de salida correspondiente. Así como un concepto se puede expresar en inglés o francés, una escena se puede representar como una imagen RGB, un campo de degradado, un mapa de bordes, un mapa de etiquetas semánticas y más. De manera análoga a la traducción automática de idiomas, definimos la traducción automática de imagen a imagen como el problema de convertir una posible representación de una escena en otra, dados suficientes datos de entrenamiento (ver Figura 1). Tradicionalmente, cada tarea se resuelve utilizando un mecanismo dedicado e independiente (por ejemplo, [14, 23, 18, 8, 10, 50, 30, 36, 16, 55, 58]), a pesar de que el contexto es siempre el mismo: Predice píxel a píxel. El objetivo de este artículo es desarrollar un marco común para todas estas preguntas.
Figura 1: Muchos problemas en el procesamiento de imágenes, gráficos y visión implican transformar una imagen de entrada en una imagen de salida correspondiente. Estos problemas suelen solucionarse mediante algoritmos específicos de la aplicación, aunque el trasfondo es siempre el mismo: mapear píxeles a píxeles. Las redes adversarias condicionales son una solución general que parece funcionar bien en una amplia variedad de estos problemas. Aquí mostramos los resultados del método en varios problemas. En cada caso utilizamos la misma arquitectura y objetivo, solo que entrenados con datos diferentes.
La comunidad ha dado pasos importantes en esta dirección y las redes neuronales convolucionales (CNN) se han convertido en una herramienta general para una variedad de problemas de predicción de imágenes. Las CNN aprenden a minimizar una función de pérdida (el objetivo de evaluar la calidad del resultado) y, si bien el proceso de aprendizaje es automático, aún requiere mucho trabajo manual para diseñar pérdidas efectivas. En otras palabras, todavía tenemos que decirle a la CNN qué queremos que minimice. Pero, al igual que el rey dorado Midas, ¡debemos tener cuidado con nuestros deseos! Si adoptamos el enfoque ingenuo de pedirle a CNN que minimice la distancia euclidiana entre los píxeles predichos y los píxeles reales, tiende a producir resultados borrosos [40, 58]. Esto se debe a que la distancia euclidiana se minimiza promediando todas las salidas posibles, lo que genera ambigüedad. Crear funciones de pérdida que puedan obligar a las CNN a hacer lo que realmente queremos (por ejemplo, generar imágenes nítidas y realistas) es un problema abierto que a menudo requiere experiencia.
Sería ideal si pudiéramos especificar un objetivo de alto nivel, como "hacer que la salida sea indistinguible de la realidad", y luego aprender automáticamente una función de pérdida adecuada para cumplir este objetivo. Afortunadamente, esto es exactamente lo que hacen las redes generativas adversarias (GAN) propuestas recientemente [22, 12, 41, 49, 59]. Las GAN aprenden una pérdida que intenta clasificar si una imagen de salida es real o falsa, mientras entrenan un modelo generativo para minimizar esta pérdida. No se tolerarán imágenes borrosas ya que parecerán claramente falsas. Debido a que las GAN aprenden pérdidas que se adaptan a los datos, se pueden aplicar a muchas tareas que tradicionalmente requieren tipos muy diferentes de funciones de pérdida.
En este artículo, exploramos las GAN en un entorno condicional. Así como las GAN aprenden un modelo generativo de datos, las redes adversarias generativas condicionales (cGAN) aprenden un modelo generativo condicional [22]. Esto hace que las cGAN sean adecuadas para tareas de traducción de imagen a imagen, donde generamos las imágenes de salida correspondientes condicionadas a las imágenes de entrada.
Si bien las GAN se han estudiado ampliamente en los últimos dos años y muchas de las técnicas exploradas en este artículo se han propuesto antes, los primeros artículos se centraron en la aplicación específica de si las GAN condicionadas por imágenes se pueden utilizar como traducción de imagen a imagen. La solución general a esto aún no está clara. Nuestra principal contribución es demostrar que las GAN condicionales pueden producir resultados razonables en una amplia variedad de problemas. Nuestra segunda contribución propone un marco simple suficiente para lograr buenos resultados y analiza el impacto de varias opciones arquitectónicas importantes. El código está disponible en https://github.com/phillipi/pix2pix.
2. Trabajo relacionado
Pérdidas estructuradas para el modelado de imágenes Los problemas de traducción de imagen a imagen a menudo se formulan como problemas de clasificación o regresión a nivel de píxeles (por ejemplo, [36, 55, 25, 32, 58]). Estas formulaciones tratan el espacio de salida como "no estructurado", lo que significa que cada píxel de salida se considera condicionalmente independiente dada la imagen de entrada. Por el contrario, las redes adversativas generativas condicionales aprenden una pérdida estructurada. Configuración conjunta de salidas estructuradas de penalización por pérdidas. Una gran cantidad de literatura considera este tipo de pérdida, con métodos que incluyen campos aleatorios condicionales [9], métricas SSIM [53], coincidencia de características [13], pérdidas no paramétricas [34], pseudo prioritarios convolucionales [54] y A basado en pérdidas. sobre estadísticas de covarianza coincidentes [27]. Las redes adversarias generativas condicionales se diferencian en que se aprende una pérdida, lo que teóricamente penaliza cualquier estructura que pueda diferir entre la salida y el objetivo.
Redes adversarias generativas condicionales No somos los primeros en aplicar GAN a entornos condicionales. Estudios anteriores han condicionado las GAN a etiquetas discretas [38, 21, 12], texto [43] e incluso imágenes. Los modelos de acondicionamiento de imágenes han abordado el problema de la predicción de imágenes a partir de mapas normales [52], la predicción de fotogramas futuros [37], la generación de fotografías de productos [56] y la generación de imágenes a partir de anotaciones escasas [28, 45] (consulte [44] para obtener una método autorregresivo para el mismo problema). Hay otros artículos que también utilizan GAN para el mapeo de imagen a imagen, pero solo aplican GAN incondicionalmente, confiando en otros términos (como la regresión L2) para forzar que la salida condicione la entrada. Estos artículos logran resultados impresionantes en pintura interna [40], predicción de estados futuros [60], procesamiento de imágenes guiado por restricciones del usuario [61], transferencia de estilo [35] y superresolución [33]. Cada método está adaptado a una aplicación específica. Nuestro marco se diferencia en que no hay nada específico de la aplicación. Esto hace que nuestra configuración sea mucho más sencilla que la mayoría de los otros métodos.
Nuestro enfoque también difiere del trabajo anterior en varias opciones arquitectónicas para el generador y el discriminador. A diferencia del trabajo anterior, para el generador usamos una arquitectura basada en “U-Net” [47], y para el discriminador usamos un clasificador convolucional “PatchGAN” que solo estructura para castigar. Anteriormente se propuso una arquitectura PatchGAN similar en [35] para capturar estadísticas de estilo local. Aquí mostramos la efectividad de este enfoque en una gama más amplia de problemas e investigamos el impacto de las diferentes dimensiones de los parches de imágenes.
3. Método
Las GAN son modelos generativos que aprenden de un vector de ruido aleatorio zzz para generar la imagenyyMapeo de y , G: z → y G: z → yGRAMO:z→y [22]. Por el contrario, las redes adversarias generativas condicionales aprenden de las imágenes observadasxxx y vector de ruido aleatoriozzz到 y y El mapeo de y , G : { x , z } → y G : \{x, z\} → yGRAMO:{ x ,z }→y。
Generador GGEl objetivo de entrenamiento de G es generar resultados que no puedan ser detectados por el discriminadorDDD para distinguir de las imágenes "reales", el discriminadorDDEl objetivo del entrenamiento de D es detectar las imágenes "falsas" del generador tanto como sea posible. Este proceso de capacitación se ilustra en la Figura 2.
Figura 2: Entrenamiento de mapeo de redes adversas generativas condicionales desde Edge Map → Foto. Discriminador DDD aprende a clasificar tuplas falsas (sintetizadas por el generador) y reales {mapas de bordes, fotos}. GeneradorGGG aprende a engañar al discriminador. A diferencia de las GAN incondicionales, tanto el generador como el discriminador observan mapas de bordes de la entrada.

3.1 Función objetivo
La función objetivo de la red adversarial generativa condicional se puede expresar como
L c GAN ( GRAMO , D ) = E x , y [ log D ( x , y ) ] + E x , z [ log ( 1 − D ( x , G ( x , z ) ) ) ] (1) L_{cGAN}(G, D) = E_{x,y}[\log D(x, y)] + E_{x,z}[\log(1 - D(x, G(x, z)) )] \etiqueta{1}lc G A N( G ,re )=mix , y[ iniciar sesiónre ( x ,y )]+mix , z[ iniciar sesión ( 1−re ( x ,G ( x ,z )))]( 1 )
donde generador GGG intenta minimizar esta función objetivo, el discriminador adversarioDDD intenta maximizarlo, es decir,G ∗ = arg min G max DL c GAN ( G , D ) G^* = \arg\min_G \max_D L_{cGAN}(G, D)GRAMO∗=arg _mín.GRAMOmáximorelc G A N( G ,D )。
Para probar la importancia del discriminador condicional, también lo comparamos con la variante incondicionada, donde el discriminador no observa xxx:
LGAN ( G , D ) = E y [ log D ( y ) ] + E x , z [ log ( 1 − D ( G ( x , z ) ) ) ] (2) L_{GAN}(G , D) = E_{y}[\log D(y)] + E_{x,z}[\log(1 - D(G(x, z)))] \tag{2}lgan _ _( G ,re )=miy[ iniciar sesiónD ( y )]+mix , z[ iniciar sesión ( 1−D ( GRAMO ( x ,z )))]( 2 )
Enfoques anteriores encontraron beneficioso combinar objetivos GAN con pérdidas más tradicionales, como la distancia L2 [40]. La tarea del discriminador sigue siendo la misma, pero el generador no sólo debe engañar al discriminador, sino también aproximar la salida de la verdad fundamental en el sentido L2. También exploramos esta opción, usando la distancia L1 en lugar de L2, ya que L1 fomenta menos desenfoque:
LL 1 ( G ) = E x , y , z [ ∥ y − G ( x , z ) ∥ 1 ] (3) L_{L1}(G) = E_{x,y,z}[\|y - G (x,z)\|_1] \tag{3}lL 1( GRAMO )=mix , y , z[ ∥ y−G ( x ,z ) ∥1]( 3 )
Nuestro objetivo final es
G ∗ = arg min G max D ( L c GAN ( G , D ) + λ LL 1 ( G ) ) (4) G^* = \arg\min_G \max_D (L_{cGAN}(G, D ). ) + \lambda L_{L1}(G)) \tag{4}GRAMO∗=arg _GRAMOminDmáximo( lc G A N( G ,re )+λL _L 1( GRAMO ))( 4 )
sin zzEn el caso de z , la red todavía está disponible desdexxx到 y y y aprende el mapeo, pero produce una salida determinista, por lo que no puede coincidir con ninguna distribución que no sea la función Delta. Las GAN condicionales anteriores reconocieron esto y proporcionaron ruido gaussianozzz , exceptoxxx (por ejemplo, [52]). En experimentos iniciales, descubrimos que esta estrategia no es efectiva (el generador simplemente aprende a ignorar el ruido), lo cual es consistente con el trabajo de Mathieu y otros [37]. En cambio, para nuestro modelo final, solo alimentamos ruido en forma de abandono en unas pocas capas del generador, que se aplica tanto en el momento del entrenamiento como en el de prueba. A pesar del ruido de caída, sólo observamos una ligera aleatoriedad en la salida de la red. El diseño de GAN condicionales capaces de producir resultados altamente estocásticos y, por lo tanto, capturar la entropía completa de la distribución condicional que se está modelando, es un problema importante sin resolver en el trabajo actual.
3.2 Arquitectura de red
Adaptamos la arquitectura del generador y discriminador de [41]. Tanto el generador como el discriminador utilizan módulos de la forma Convolution-BatchNorm-ReLU [26]. Los detalles sobre la arquitectura se pueden encontrar en el material complementario, y las características clave se analizan a continuación.
3.2.1 Generadores con conexiones skip
Una característica distintiva de los problemas de traducción de imagen a imagen es que asignan una cuadrícula de entrada de alta resolución a una cuadrícula de salida de alta resolución. Además, para los problemas que consideramos, la entrada y la salida difieren en la apariencia de la superficie, pero son representaciones de la misma estructura subyacente. Por lo tanto, la estructura de la entrada se alinea aproximadamente con la estructura de la salida. Diseñamos la arquitectura del generador en torno a estas consideraciones.
Muchas soluciones anteriores [40, 52, 27, 60, 56] a problemas en este dominio utilizan redes codificador-decodificador [24]. En tales redes, la entrada pasa a través de una serie de capas progresivamente reducidas hasta la capa de cuello de botella, momento en el que el proceso se invierte. Una red de este tipo requiere que toda la información fluya a través de todas las capas, incluidos los cuellos de botella. Para muchos problemas de traducción de imágenes, se comparte una gran cantidad de información de bajo nivel entre la entrada y la salida, y es deseable que esta información pueda pasarse directamente a la red. Por ejemplo, en el caso de la coloración de una imagen, la entrada y la salida comparten la ubicación de los bordes salientes.
Para permitir que el generador evite el cuello de botella y entregue información similar, agregamos conexiones de salto, siguiendo la forma general de "U-Net" [47]. Específicamente, en cada capa iii capan − en - inorte−Agregue conexiones de salto entre i , donde nnn es el número total de capas. Cada conexión de salto simplemente conecta la capaiii capan − en - inorte−Todos los canales en i están conectados.
3.2.2 Discriminador de Markov (PatchGAN)
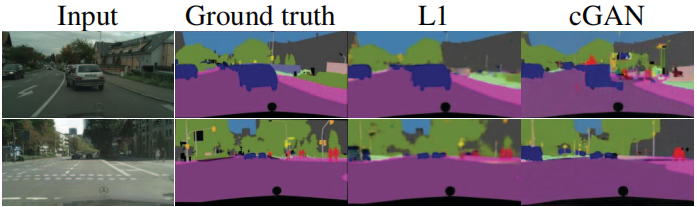
Se sabe que la pérdida de L2 (y L1, ver Fig. 3) produce resultados borrosos en problemas de generación de imágenes [31]. Aunque estas pérdidas no fomentan la claridad de alta frecuencia, en muchos casos aún capturan con precisión información de baja frecuencia. Para este caso, no necesitamos un marco completamente nuevo para imponer la corrección en bajas frecuencias. L1 es suficiente.
Figura 3: Diferentes pérdidas conducen a diferentes resultados de calidad. Cada columna muestra los resultados del entrenamiento con diferentes pérdidas. Consulte https://phillipi.github.io/pix2pix/ para ver más ejemplos.

Esto motiva a restringir los discriminadores GAN a modelar solo estructuras de alta frecuencia, confiando en el término L1 para imponer la corrección de baja frecuencia (Ecuación 4). Para simular altas frecuencias, basta con limitar la atención a la estructura de los parches de imágenes locales. Por lo tanto, diseñamos una arquitectura discriminadora, a la que llamamos PatchGAN, que solo penaliza la estructura a escala de parche. El discriminador intenta identificar cada N × NN × Nnorte×Se clasifican N bloques para determinar si es real o falso. Ejecutamos este discriminador sobre toda la imagen mediante convolución, promediando todas las respuestas para proporcionarDDEl resultado final de D.
En la Sección 4.4, demostramos que NNN puede ser mucho más pequeño que el tamaño completo de la imagen y aun así producir resultados de alta calidad. Esto es ventajoso porque los PatchGAN más pequeños tienen menos parámetros, se ejecutan más rápido y se pueden aplicar a imágenes arbitrariamente grandes.
Un discriminador de este tipo modela efectivamente la imagen como un campo aleatorio de Markov, asumiendo independencia entre píxeles mayores que el diámetro de un parche de imagen. Esta conexión se exploró previamente en [35] y es una suposición común en los modelos de textura [15, 19] y estilo [14, 23, 20, 34]. Por lo tanto, nuestro PatchGAN puede entenderse como una forma de pérdida de textura/estilo.
3.3 Optimización e inferencia
Para optimizar nuestra red, seguimos el enfoque estándar en [22]: un paso de descenso de gradiente en D seguido de un paso en G. Utilizamos el descenso de gradiente estocástico (SGD) de mini lotes y aplicamos el solucionador Adam [29].
En el momento de la inferencia, ejecutamos la red del generador exactamente de la misma manera que durante la fase de entrenamiento. Esto difiere del protocolo habitual en que aplicamos el abandono en el momento de la prueba y aplicamos la normalización por lotes [26] utilizando estadísticas de lotes de prueba, en lugar de estadísticas agregadas de lotes de entrenamiento. Cuando el tamaño del lote se establece en 1, este enfoque de normalización de lotes se denomina "normalización de instancias" y se ha demostrado que es eficaz en tareas de generación de imágenes [51]. En nuestros experimentos, utilizamos un tamaño de lote entre 1 y 10, según el experimento.
4. Experimentar
Para explorar la generalización de las GAN condicionales, probamos el método en varias tareas y conjuntos de datos, incluidas tareas gráficas (por ejemplo, generación de fotografías) y tareas de visión (por ejemplo, segmentación semántica):
- Etiquetas semánticas ↔ fotos, entrenadas en el conjunto de datos Cityscapes [11].
- Etiqueta de Arquitectura → Foto, entrenada en CMP Fachadas [42].
- Mapas ↔ fotografías aéreas, entrenadas a partir de datos obtenidos de Google Maps.
- Fotografías en blanco y negro → fotografías en color, usando [48] para entrenamiento.
- Borde → Foto, entrenado usando datos de [61] y [57]; bordes binarios generados usando el detector de bordes HED [55] y posprocesados.
- Boceto → Foto: El modelo de borde → foto se prueba en el boceto dibujado a mano de [17].
- Día → Noche, entrenado con los datos de [30].
Los detalles detallados de la capacitación sobre estos conjuntos de datos se pueden encontrar en el material complementario en línea. En todos los casos, la entrada y la salida son imágenes de 1 a 3 canales. Los resultados cualitativos se muestran en la Figura 7, Figura 8, Figura 9, Figura 10 y Figura 11; se pueden encontrar otros resultados y casos de falla en el material en línea (https://phillipi.github.io/pix2pix/).
4.1 Métricas de evaluación
La evaluación de la calidad de las imágenes sintetizadas es un problema abierto y difícil [49]. Las métricas tradicionales, como el error cuadrático medio a nivel de píxel, no evalúan las estadísticas conjuntas de los resultados y, por lo tanto, no miden la estructura que las pérdidas estructuradas están diseñadas para capturar.
Para evaluar más completamente la calidad visual de nuestros resultados, empleamos dos estrategias. Primero, realizamos un estudio de percepción "real versus falso" en Amazon Mechanical Turk (AMT). Para problemas gráficos como la coloración y la generación de fotografías, para los observadores humanos, la plausibilidad suele ser el objetivo final. Por lo tanto, probamos nuestra generación de mapas, generación de fotografías aéreas y coloración de imágenes utilizando este enfoque.
En segundo lugar, medimos si nuestros paisajes urbanos sintéticos son lo suficientemente realistas como para que los sistemas de reconocimiento disponibles reconozcan los objetos que se encuentran dentro de ellos. Esta métrica es similar a la "puntuación inicial" en [49], la evaluación de detección de objetos en [52] y la medida de "interpretabilidad semántica" en [58] y [39].
Estudios de percepción de AMT Para nuestros experimentos de AMT, seguimos el protocolo de [58]: a los turcos se les presentó una serie de pruebas en las que se comparaba una imagen "real" con una imagen "falsa" generada por nuestro algoritmo. En cada prueba, cada imagen apareció durante 1 segundo, después del cual la imagen desapareció, y a Turkers se le dio tiempo infinito para responder cuál era falsa. Las primeras 10 imágenes de cada sesión son ejercicios y los turcos reciben retroalimentación. No se proporcionó retroalimentación durante las 40 pruebas del experimento principal. Solo se prueba un algoritmo a la vez por sesión, a los turcos no se les permite completar varias sesiones. Unos 50 turcos evalúan cada algoritmo. Todas las imágenes se presentan con una resolución de 256×256. A diferencia de [58], no incluimos ensayos de vigilancia. Para nuestros experimentos de coloración, se generan imágenes reales y falsas a partir de la misma entrada en escala de grises. Para mapas ↔ fotografías aéreas, las imágenes reales y falsas no se generan a partir de la misma entrada para dificultar la tarea y evitar resultados de bajo nivel.
Puntuaciones FCN Aunque la evaluación cuantitativa de los modelos generativos es notoriamente desafiante, trabajos recientes [49, 52, 58, 39] intentan medir la discriminabilidad de los estímulos generados utilizando clasificadores semánticos previamente entrenados como pseudoindicadores. La intuición es que un clasificador entrenado con imágenes reales también podrá clasificar correctamente imágenes sintéticas si las imágenes generadas son realistas. Con este fin, adoptamos la arquitectura FCN-8s [36] para la segmentación semántica y la entrenamos en el conjunto de datos de paisajes urbanos. Luego calificamos las fotografías sintetizadas comparando la precisión de la clasificación de estas fotografías con las etiquetas generadas a partir de estas fotografías.
4.2 Análisis de la función objetiva
¿Qué componentes son importantes en el objetivo de la ecuación (4)? Realizamos estudios de ablación para separar la influencia del término L1 y el término GAN y comparar el uso de un discriminador condicional (cGAN, ecuación (1)) con un discriminador incondicional (GAN, ecuación (2)).
La Figura 3 demuestra el impacto cualitativo de estos cambios en las dos preguntas etiqueta→foto. Usar solo L1 conduce a resultados razonables pero ambiguos. Usar solo cGAN (configurando λ = 0 en la ecuación (4)) produce resultados más nítidos pero introduce artefactos visuales en algunas aplicaciones. La combinación de ambos términos (λ = 100) reduce estos artefactos.
Cuantificamos estas observaciones utilizando puntuaciones de FCN en la tarea Etiqueta de paisaje urbano → Foto (consulte la Tabla 1): los objetivos basados en GAN logran puntuaciones más altas, lo que indica que las imágenes sintéticas incluyen estructuras más reconocibles. También probamos el efecto de eliminar la condición del discriminador (etiquetado GAN). En este caso, la pérdida no penaliza el desajuste entre insumos y resultados; sólo le importa si el resultado parece real. El rendimiento de esta variante es muy pobre; la inspección muestra que el generador casi produce casi la misma salida independientemente de la foto de entrada. Claramente, en este caso la calidad de la coincidencia entre la entrada y la salida de la medición de pérdidas es muy importante y, de hecho, cGAN funciona mejor que GAN. Sin embargo, es importante señalar que agregar el término L1 también fomenta que la salida respete la entrada, ya que la pérdida de L1 penaliza la distancia entre la salida real del terreno y la salida sintética, que puede no coincidir. En consecuencia, L1+GAN también puede crear representaciones realistas de manera efectiva respetando el mapeo de etiquetas de entrada. Combinando todos los términos, L1+cGAN también funciona muy bien.
Tabla 1: Puntuaciones FCN evaluadas en la tarea Etiquetado semántico↔Foto en el conjunto de datos Paisajes urbanos

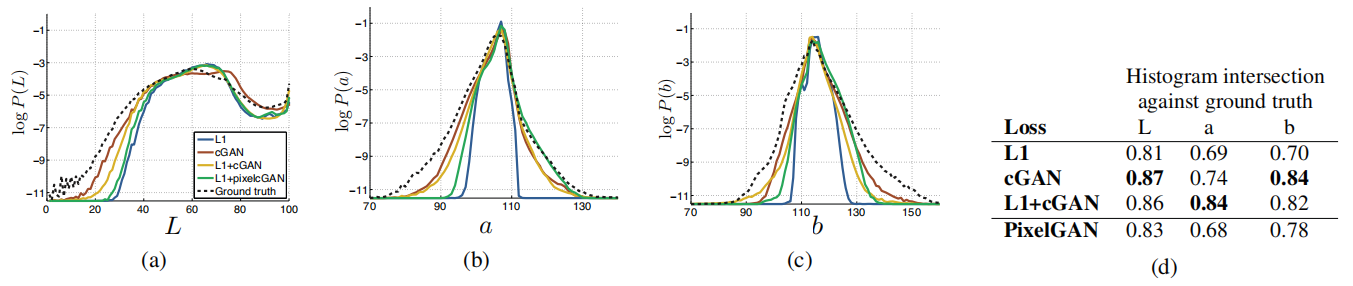
Un efecto sorprendente de las redes adversarias generativas condicionales es que producen imágenes nítidas y la ilusión de una estructura espacial incluso cuando está ausente en el mapa de etiquetas de entrada. Uno podría imaginar que la "nitidez" de la dimensión espectral de cGAN tiene un efecto similar, incluso si la imagen es más colorida. Así como L1 fomenta el desenfoque cuando no estás seguro de dónde está exactamente un borde, anima a elegir un gris promedio cuando no estás seguro de qué valor de color factible debe tomar un píxel. En particular, se elige L1 para minimizar el valor mediano de la función de densidad de probabilidad condicional de posibles colores.
Por otro lado, una pérdida adversa puede, en principio, darse cuenta de que las salidas de grises no son realistas y fomentar la coincidencia con la distribución de color real [22]. En la Figura 6, investigamos si nuestro cGAN logra este efecto en el conjunto de datos de Cityscapes. Estos gráficos muestran la distribución marginal de los valores de color de salida en el espacio de color Lab. Las líneas discontinuas indican la distribución de la verdad fundamental. Claramente, L1 conduce a una distribución más estrecha que la distribución real, validando la hipótesis de que L1 fomenta un color gris promedio. Por otro lado, el uso de cGAN empuja la distribución de salida hacia la distribución real.
4.3 Análisis de la arquitectura del generador.
La arquitectura U-Net permite transferir rápidamente información de bajo nivel en la red. ¿Esto conduce a mejores resultados? La Figura 4 compara el rendimiento de U-Net y el codificador-decodificador en la generación de paisajes urbanos. El codificador-decodificador se crea únicamente cortando las conexiones de salto en U-Net. En nuestros experimentos, el codificador-decodificador no pudo aprender a generar imágenes realistas. Las ventajas de U-Net no parecen limitarse a las GAN condicionales: U-Net nuevamente logra resultados superiores cuando tanto U-Net como el codificador-decodificador se entrenan con pérdida L1 (consulte la Figura 4).
Figura 4: Agregar conexiones de salto en el codificador-decodificador para crear una "U-Net" produce resultados de mayor calidad.

4.4 De PixelGAN a PatchGAN a ImageGAN
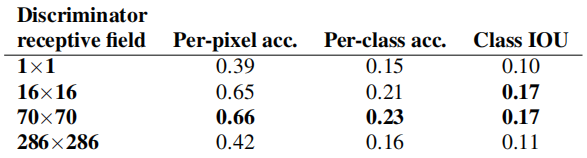
Probamos el efecto de variar el tamaño N del parche del campo receptivo del discriminador, desde 1 × 1 para “PixelGAN” hasta 286 × 286 completos para “ImageGAN” 1 . La Figura 5 muestra los resultados cualitativos de este análisis y la Tabla 2 cuantifica el efecto del uso de puntuaciones FCN. Tenga en cuenta que en el resto del artículo, a menos que se indique lo contrario, todos los experimentos utilizan un PatchGAN de 70 × 70, mientras que en esta sección, todos los experimentos utilizan la pérdida L1+cGAN.
Figura 5: Variación del tamaño del parche. Diferentes funciones de pérdida representarán la incertidumbre de la salida de diferentes maneras. Bajo L1, las regiones inciertas se vuelven borrosas y desaturadas. PixelGAN en 1x1 fomenta una mayor diversidad de colores pero no tiene ningún efecto en las estadísticas espaciales. El PatchGAN 16x16 produce resultados localmente nítidos, pero también produce artefactos de mosaico fuera de su rango observable. Un PatchGAN de 70×70 fuerza una salida nítida, aunque sea incorrecta, tanto en dimensiones espaciales como espectrales (riqueza de color). El ImageGAN completo de 286 × 286 es visualmente similar a los resultados de PatchGAN de 70 × 70, pero ligeramente más bajo según nuestra métrica de puntuación FCN (Tabla 2). Consulte https://phillipi.github.io/pix2pix/ para ver otros ejemplos.

Tabla 2: Puntuaciones FCN para diferentes tamaños de campo receptivo discriminador en la tarea Etiqueta de paisajes urbanos → fotografía. Tenga en cuenta que la imagen de entrada tiene 256 × 256 píxeles y el tamaño del campo receptivo más grande se logra rellenando con ceros.
PixelGAN no tiene ningún efecto sobre la nitidez espacial, pero aumenta la riqueza de color de los resultados (cuantificado en la Figura 6). Por ejemplo, el bus en la Figura 5 es de color gris cuando se entrena con pérdida L1, pero se vuelve rojo cuando se entrena con pérdida de PixelGAN. La coincidencia de histogramas de color es un problema común en el procesamiento de imágenes [46], y PixelGAN puede ser una solución ligera prometedora.
Figura 6: Propiedades de coincidencia de distribución de color de cGAN, probadas en el conjunto de datos Cityscapes. (Consulte la Figura 1 del documento GAN original [22]). Tenga en cuenta que las puntuaciones de cruce del histograma se ven afectadas principalmente por diferencias en regiones de alta probabilidad, que no son perceptibles en el gráfico, ya que el gráfico muestra probabilidades logarítmicas, enfatizando así las diferencias en regiones de baja probabilidad.
El uso de un PatchGAN de 16 × 16 es suficiente para generar resultados nítidos y lograr buenos puntajes FCN, pero también genera artefactos en mosaico. El PatchGAN 70 × 70 mitiga estos problemas de artefactos y logra puntuaciones similares. Más allá de este punto, alcanzar el ImageGAN completo de 286 × 286 no mejora significativamente la calidad visual de los resultados y, de hecho, reduce significativamente las puntuaciones de FCN (Tabla 2). Esto puede deberse a que ImageGAN tiene más parámetros y mayor profundidad que PatchGAN 70 × 70, lo que puede ser más difícil de entrenar.
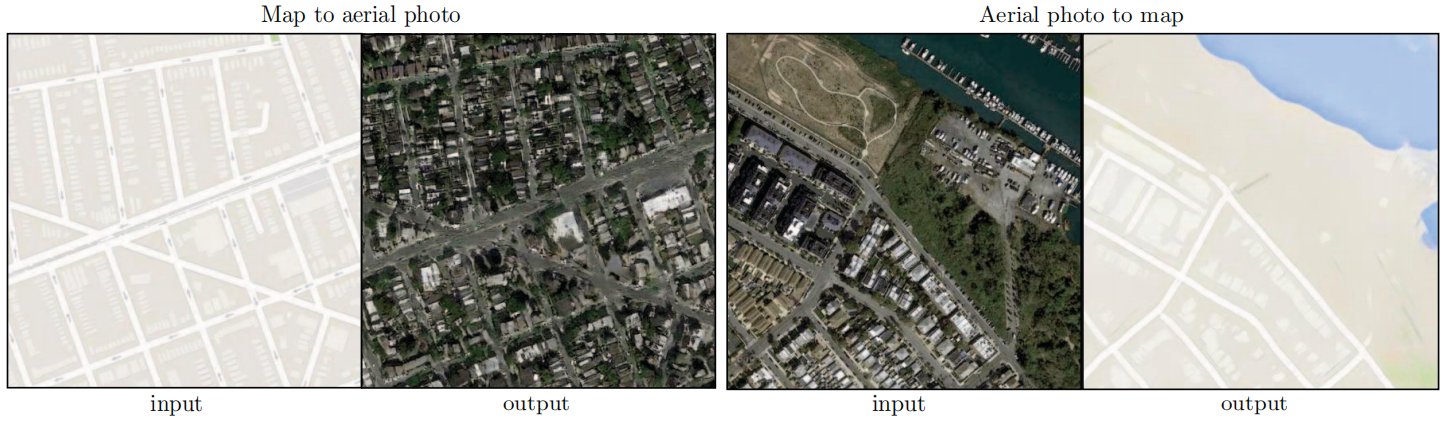
Una ventaja de las transformaciones totalmente convolucionales es que se puede aplicar un discriminador de parche de tamaño fijo a imágenes de tamaño arbitrario. También podemos convolucionar el generador en imágenes más grandes que las imágenes de entrenamiento. Lo probamos en la tarea de fotografía aérea de mapa↔. Después de entrenar el generador con imágenes de 256 × 256, lo probamos en imágenes de 512 × 512. Los resultados de la Figura 7 demuestran la eficacia de este enfoque.
Figura 7: Resultados de ejemplo de Google Maps con una resolución de 512 x 512 (el modelo se entrenó en imágenes con una resolución de 256 x 256 y convolucionó en imágenes más grandes en el momento de la prueba). Contraste ajustado para mayor claridad.
4.5 Verificación de la percepción
Validamos la fidelidad perceptiva de los resultados en las tareas de mapa↔foto aérea y escala de grises→color. Los resultados de los experimentos AMT para mapas↔fotos se muestran en la Tabla 3. Las fotografías aéreas generadas por nuestro método engañaron a los participantes en el 18,9% de los ensayos, significativamente más que la línea de base L1, lo que produjo resultados ambiguos y casi nunca engañó a los participantes. Por el contrario, en la orientación foto → mapa, nuestro método engañó a los participantes en el 6,1% de las pruebas, lo que no fue significativamente diferente del rendimiento de la línea de base L1 (según las pruebas de arranque). Esto puede deberse a que los errores estructurales leves en los mapas son más evidentes visualmente mientras que los mapas tienen una geometría rígida, mientras que las fotografías aéreas son más caóticas.
Tabla 3: Pruebas AMT “reales versus falsas” en el mapa↔tarea de fotografía aérea.

Entrenamos la coloración en ImageNet [48] y la probamos en el conjunto de prueba introducido en [58, 32]. Nuestro método, que utiliza la pérdida de L1+cGAN, engañó a los participantes en el 22,5% de los ensayos (Tabla 4). También probamos los resultados de [58], así como una variante de su método que utiliza una pérdida L2 (ver [58] para más detalles). Las GAN condicionales obtienen una puntuación similar a la variante L2 de [58] (la diferencia no es significativa mediante la prueba de arranque), pero no al nivel del método completo de [58], que engañó a los participantes en el 27,8% de las pruebas de nuestros experimentos. Observamos que su método está diseñado específicamente para funcionar bien en la coloración.
Tabla 4: Pruebas AMT "reales versus falsas" en la tarea de colorear.

Figura 8: Resultados coloreados de GAN condicionales en comparación con la regresión L2 en [58] y el método completo en [60] (clasificación por reequilibrio). Las cGAN pueden producir resultados de coloración convincentes (primeras dos filas), pero tienen un modo de falla común al producir resultados en escala de grises o desaturados (última fila).

4.6 Segmentación semántica
Las GAN condicionales parecen ser efectivas para generar problemas muy detallados o similares a fotografías, que son comunes en tareas de procesamiento de imágenes y gráficos. ¿Qué pasa con los problemas de visión, como la segmentación semántica, donde la salida es más simple que la entrada?
Para comenzar a probar esto, entrenamos un cGAN (con/sin pérdida L1) en fotografías → etiquetas de paisajes urbanos. La Figura 11 muestra los resultados cualitativos y la precisión de la clasificación cuantitativa se informa en la Tabla 5. Curiosamente, cGAN entrenado sin pérdida de L1 puede resolver este problema con una precisión razonable. Hasta donde sabemos, esta es la primera demostración de una GAN que genera con éxito "etiquetas" que son casi discretas en lugar de "imágenes" con variación continua 2 . A pesar de cierto éxito con las cGAN, están lejos de ser el mejor enfoque para este problema: usar solo la regresión L1 produce mejores puntuaciones que usar cGAN, como se muestra en la Tabla 5. Argumentamos que para problemas de visión, el objetivo (es decir, predecir una salida cercana a la verdad fundamental) puede ser menos ambiguo que el objetivo para tareas gráficas, y una pérdida de reconstrucción como L1 es básicamente suficiente.
Tabla 5: Rendimiento en la tarea de fotografía → etiqueta en el conjunto de datos del paisaje urbano.
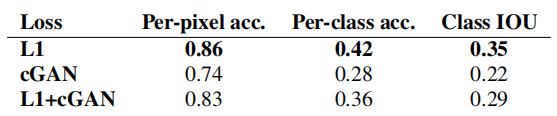
4.7 Investigación impulsada por la comunidad
Desde la publicación inicial del artículo y de nuestro código base pix2pix, la comunidad de Twitter, incluidos los profesionales de la visión por computadora y los gráficos, así como los artistas, ha aplicado con éxito nuestro marco a una variedad de tareas novedosas de traducción de imagen a imagen, mucho más allá del alcance de el papel original. La Figura 10 muestra solo algunos ejemplos bajo el hashtag #pix2pix, como boceto→retrato, transferencia de pose “Haz lo que hago”, profundidad→vista de la calle, eliminación de fondo, generación de paleta, boceto→Pokémon y el popular #edges2cats.
Figura 9: Resultados de nuestro método en varias tareas (datos de [42] y [17]). Tenga en cuenta que los resultados de Boceto → Foto son generados por un modelo entrenado en detección automática de bordes y probado en bocetos dibujados por humanos. Consulte el material en línea para ver ejemplos adicionales.

Figura 10: Una aplicación de ejemplo de comunidad en línea desarrollada en base a nuestro código base pix2pix: #edges2cats [3] de Christopher Hesse, Sketch → Portrait [7] de Mario Kingemann, "Do As I Do" Pose Transformation [2] de Brannon Dorsey, Depth → Streetview [5] de Jasper van Loenen, Eliminación de fondo [6] de Kaihu Chen, Palette Generation [4] de Jack Qiao y Sketch → Pokemon [1] de Bertrand Gondouin.

Figura 11: Aplicación de GAN condicionales a la segmentación semántica. cGAN genera imágenes nítidas que a primera vista se parecen a las reales, pero que en realidad contienen muchos objetos pequeños fantasmas.
5. Conclusión
Los resultados de este artículo demuestran que las redes adversarias condicionales son un enfoque prometedor para muchas tareas de traducción de imagen a imagen, especialmente aquellas que involucran resultados gráficos altamente estructurados. Estas redes aprenden a adaptar las pérdidas a tareas y datos específicos, lo que las hace aplicables a una variedad de contextos diferentes.
gracias
Agradecemos a Richard Zhang, Deepak Pathak y Shubham Tulsiani por sus útiles debates, a Saining Xie por su ayuda con el detector de bordes HED y a la comunidad en línea por sus contribuciones al explorar muchas aplicaciones y sugerir mejoras. Este trabajo fue apoyado en parte por NSF SMA-1514512, NGA NURI, IARPA a través de donaciones de hardware del Air Force Research Laboratory, Intel Corp, Berkeley Deep Drive y Nvidia.
referencia
- Bertrand Gondouin. https://twitter.com/bgondouin/status/818571935529377792. Consultado el 21 de abril de 2017.
- Brannon Dorsey. https://twitter.com/brannondorsey/status/806283494041223168. Consultado el 21 de abril de 2017.
- Cristóbal Hesse. https://affinelayer.com/pixsrv/. Consultado: 21-04-2017.
- Jack Qiao. http://colormind.io/blog/. Consultado: 21-04-2017.
- Jasper van Loenen. https://jaspervanloenen.com/neural-city/. Consultado el 21 de abril de 2017.
- Kaihu Chen. http://www.terraai.org/imageops/index.html. Consultado el 21 de abril de 2017.
- Mario Klingemann. https://twitter.com/quasimondo/status/826065030944870400. Consultado el 21 de abril de 2017.
- A. Buades, B. Coll y J.-M. Morel. Un algoritmo no local para eliminar el ruido de imágenes. En CVPR, volumen 2, páginas 60–65. IEEE, 2005.
- L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy y AL Yuille. Segmentación de imágenes semánticas con redes convolucionales profundas y CRF completamente conectados. En ICLR, 2015.
- T. Chen, M.-M. Cheng, P. Tan, A. Shamir y S.-M. Hu. Sketch2photo: montaje de imágenes de internet. Transacciones ACM sobre gráficos (TOG), 28(5):124, 2009.
- M. Cordts, M. Omran, S. Ramos, T. Rehfeld, M. Enzweiler, R. Benenson, U. Franke, S. Roth y B. Schiele. El conjunto de datos Cityscapes para la comprensión semántica de la escena urbana. En CVPR, 2016.
- EL Denton, S. Chintala, R. Fergus y col. Modelos de imágenes generativas profundas utilizando una pirámide laplaciana de redes adversarias. En NIPS, páginas 1486–1494, 2015.
- A. Dosovitskiy y T. Brox. Generación de imágenes con métricas de similitud perceptiva basadas en redes profundas. Preimpresión de arXiv arXiv:1602.02644, 2016.
- AA Efros y WT Freeman. Acolchado de imágenes para síntesis y transferencia de texturas. En SIGGRAPH, páginas 341–346. ACM, 2001.
- AA Efros y TK Leung. Síntesis de texturas mediante muestreo no paramétrico. En ICCV, volumen 2, páginas 1033–1038. IEEE, 1999.
- D. Eigen y R. Fergus. Predecir profundidad, normales de superficie y etiquetas semánticas con una arquitectura convolucional multiescala común. En Actas de la Conferencia Internacional IEEE sobre Visión por Computadora, páginas 2650–2658, 2015.
- M. Eitz, J. Hays y M. Alexa. ¿Cómo dibujan los humanos los objetos? SIGGRAFO, 31(4):44–1, 2012.
- R. Fergus, B. Singh, A. Hertzmann, ST Roweis y WT Freeman. Eliminar el movimiento de la cámara de una sola fotografía. En ACM Transactions on Graphics (TOG), volumen 25, páginas 787–794. ACM, 2006.
- LA Gatys, AS Ecker y M. Bethge. Síntesis de texturas y generación controlada de estímulos naturales mediante redes neuronales convolucionales. Preimpresión de arXiv arXiv:1505.07376, 2015.
- LA Gatys, AS Ecker y M. Bethge. Transferencia de estilo de imagen mediante redes neuronales convolucionales. CVPR, 2016.
- J. Gauthier. Redes adversarias generativas condicionales para generación de caras convolucionales. Proyecto de clase para Stanford CS231N: Redes neuronales convolucionales para el reconocimiento visual, semestre de invierno, 2014(5):2, 2014.
- I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville e Y. Bengio. Redes generativas adversarias. En NIPS, 2014.
- A. Hertzmann, CE Jacobs, N. Oliver, B. Curless y DH Salesin. Analogías de imágenes. En SIGGRAPH, páginas 327–340. ACM, 2001.
- GE Hinton y RR Salakhutdinov. Reducir la dimensionalidad de los datos con redes neuronales. Ciencia, 313(5786):504–507, 2006.
- S. Iizuka, E. Simo-Serra y H. Ishikawa. ¡Que haya color!: Aprendizaje conjunto de extremo a extremo de antecedentes de imágenes locales y globales para la coloración automática de imágenes con clasificación simultánea. Transacciones ACM sobre gráficos (TOG), 35(4), 2016.
- S. Ioffe y C. Szegedy. Normalización de lotes: acelerar el entrenamiento profundo de la red al reducir el cambio de covariables interno. 2015.
- J. Johnson, A. Alahi y L. Fei-Fei. Pérdidas de percepción para transferencia de estilo en tiempo real y superresolución. 2016.
- L. Karacan, Z. Akata, A. Erdem y E. Erdem. Aprender a generar imágenes de escenas exteriores a partir de atributos y diseños semánticos. Preimpresión de arXiv arXiv:1612.00215, 2016.
- D. Kingma y J. Ba. Adam: un método para la optimización estocástica. ICLR, 2015.
- P.-Y. Laffont, Z. Ren, X. Tao, C. Qian y J. Hays. Atributos transitorios para comprensión y edición de alto nivel de escenas exteriores. Transacciones ACM sobre gráficos (TOG), 33(4):149, 2014.
- ABL Larsen, SK Sønderby y O. Winther. Codificación automática más allá de los píxeles mediante una métrica de similitud aprendida. Preimpresión de arXiv arXiv:1512.09300, 2015.
- G. Larsson, M. Maire y G. Shakhnarovich. Aprendizaje de representaciones para coloración automática. ECVC, 2016.
- C. Ledig, L. Theis, F. Huszár, J. Caballero, A. Cunningham, A. Acosta, A. Aitken, A. Tejani, J. Totz, Z. Wang, et al. Superresolución fotorrealista de una sola imagen utilizando una red generativa adversaria. Preimpresión de arXiv arXiv:1609.04802, 2016.
- C. Li y M. Wand. Combinando campos aleatorios de Markov y redes neuronales convolucionales para síntesis de imágenes. CVPR, 2016.
- C. Li y M. Wand. Síntesis de texturas precalculadas en tiempo real con redes generativas adversarias de Markov. ECVC, 2016.
- J. Long, E. Shelhamer y T. Darrell. Redes totalmente convolucionales para segmentación semántica. En CVPR, páginas 3431–3440, 2015.
- M. Mathieu, C. Couprie e Y. LeCun. Predicción de vídeo profunda a múltiples escalas más allá del error cuadrático medio. ICLR, 2016.
- M. Mirza y S. Osindero. Redes adversarias generativas condicionales. Preimpresión de arXiv arXiv:1411.1784, 2014.
- A. Owens, P. Isola, J. McDermott, A. Torralba, EH Adelson y WT Freeman. Sonidos indicados visualmente. En Actas de la Conferencia IEEE sobre visión por computadora y reconocimiento de patrones, páginas 2405–2413, 2016.
- D. Pathak, P. Krahenbuhl, J. Donahue, T. Darrell y AA Efros. Codificadores de contexto: aprendizaje de funciones mediante pintura. CVPR, 2016.
- A. Radford, L. Metz y S. Chintala. Aprendizaje de representación no supervisado con redes adversas generativas convolucionales profundas. Preimpresión de arXiv arXiv:1511.06434, 2015.
- RS Radim Tyleček. Plantillas de patrones espaciales para el reconocimiento de objetos con estructura regular. En Proc. GCPR, Saarbrücken, Alemania, 2013.
- S. Reed, Z. Akata, X. Yan, L. Logeswaran, B. Schiele y H. Lee. Síntesis generativa de texto adversario a imagen. Preimpresión de arXiv arXiv:1605.05396, 2016.
- S. Reed, A. van den Oord, N. Kalchbrenner, V. Bapst, M. Botvinick y N. de Freitas. Generación de imágenes interpretables con estructura controlable. Informe técnico, Informe técnico, 2016.
- SE Reed, Z. Akata, S. Mohan, S. Tenka, B. Schiele y H. Lee. Aprender qué y dónde dibujar. En Avances en sistemas de procesamiento de información neuronal, páginas 217–225, 2016.
- E. Reinhard, M. Ashikhmin, B. Gooch y P. Shirley. Transferencia de color entre imágenes. Aplicaciones y gráficos por computadora IEEE, 21:34–41, 2001.
- O. Ronneberger, P. Fischer y T. Brox. U-net: Redes convolucionales para segmentación de imágenes biomédicas. En MICCAI, páginas 234–241. Saltador, 2015.
- O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, et al. Reto de reconocimiento visual de imágenes a gran escala. IJCV, 115(3):211–252, 2015.
- T. Salimans, I. Goodfellow, W. Zaremba, V. Cheung, A. Radford y X. Chen. Técnicas mejoradas para entrenar GAN. Preimpresión de arXiv arXiv:1606.03498, 2016.
- Y. Shih, S. Paris, F. Durand y WT Freeman. Alucinación basada en datos de diferentes momentos del día a partir de una única fotografía al aire libre. Transacciones ACM sobre gráficos (TOG), 32(6):200, 2013.
- D. Ulyanov, A. Vedaldi y V. Lempitsky. Normalización de instancias: el ingrediente que falta para una estilización rápida. Preimpresión de arXiv arXiv:1607.08022, 2016.
- X. Wang y A. Gupta. Modelado generativo de imágenes utilizando estilo y estructura de redes adversarias. ECVC, 2016.
- Z. Wang, AC Bovik, HR Sheikh y EP Simoncelli. Evaluación de la calidad de la imagen: de la visibilidad del error a la similitud estructural. Transacciones IEEE sobre procesamiento de imágenes, 13(4):600–612, 2004.
- S. Xie, X. Huang y Z. Tu. Aprendizaje de arriba hacia abajo para etiquetado estructurado con pseudoprior convolucional. 2015.
- S. Xie y Z. Tu. Detección de bordes anidada de forma integral. En ICCV, 2015.
- D. Yoo, N. Kim, S. Park, AS Paek e IS Kweon. Transferencia de dominio a nivel de píxel. ECVC, 2016.
- A. Yu y K. Grauman. Comparaciones visuales detalladas con el aprendizaje local. En CVPR, 2014.
- R. Zhang, P. Isola y AA Efros. Colorización de imágenes coloridas. ECVC, 2016.
- J. Zhao, M. Mathieu e Y. LeCun. Red generativa adversarial basada en energía. Preimpresión de arXiv arXiv:1609.03126, 2016.
- Y. Zhou y TL Berg. Aprender transformaciones temporales a partir de vídeos time-lapse. En ECCV, 2016.
- J.-Y. Zhu, P. Kr¨ahenb¨uhl, E. Shechtman y AA Efros. Manipulación visual generativa sobre la variedad de imágenes naturales. En ECCV, 2016.
Red rsarial. Preimpresión de arXiv arXiv:1609.03126, 2016. - Y. Zhou y TL Berg. Aprender transformaciones temporales a partir de vídeos time-lapse. En ECCV, 2016.
- J.-Y. Zhu, P. Kr¨ahenb¨uhl, E. Shechtman y AA Efros. Manipulación visual generativa sobre la variedad de imágenes naturales. En ECCV, 2016.
Logramos esta variación del tamaño del parche ajustando la profundidad del discriminador GAN. Los detalles de este proceso, así como la arquitectura del discriminador, se pueden encontrar en el material complementario en línea. ↩︎
Tenga en cuenta que los mapas de etiquetas que utilizamos para el entrenamiento no son exactamente valores discretos, ya que se les cambia el tamaño de los mapas originales mediante interpolación bilineal y se guardan como imágenes JPEG, que pueden tener algunos artefactos de compresión. ↩︎