
En un lago de datos, encontrar columnas similares tiene aplicaciones importantes para muchas operaciones, como la limpieza y anotación de datos, la coincidencia de esquemas, el descubrimiento de datos y el análisis de múltiples fuentes de datos. No encontrar y analizar con precisión datos de muchas fuentes diferentes crea ineficiencias significativas que afectan a todos, desde científicos de datos, investigadores médicos, académicos hasta analistas financieros y gubernamentales.
Las soluciones tradicionales implican el uso de búsquedas de palabras clave léxicas o coincidencias de expresiones regulares, que son susceptibles a problemas de calidad de los datos, como nombres de columnas faltantes o diferentes convenciones de nomenclatura de columnas en diferentes conjuntos de datos (por ejemplo, código postal, código z, código postal).
En esta publicación, demostramos una solución para realizar una búsqueda de columnas similares según el nombre de la columna y/o el contenido de la columna. La solución utiliza el algoritmo del vecino más cercano aproximado disponible en Amazon OpenSearch Service para buscar columnas con semántica similar. Para ayudar en la búsqueda, utilizamos un modelo Transformer previamente entrenado en Amazon SageMaker con la biblioteca de transformadores de oraciones para crear representaciones de características (objetos incrustados) para columnas individuales en el lago de datos. Finalmente, para interactuar desde la solución y visualizar los resultados, creamos una aplicación web interactiva Streamlit que se ejecuta en Amazon Fargate.
Proporcionamos un tutorial de código que puede utilizar para implementar recursos para ejecutar la solución en datos de muestra o en sus propios datos.
Descripción general de la solución
El siguiente diagrama de arquitectura muestra el flujo de trabajo para buscar columnas con semántica similar, dividido en dos etapas. La primera etapa ejecuta un flujo de trabajo de Amazon Step Functions que crea objetos incrustados a partir de columnas de tablas y crea un índice de búsqueda de OpenSearch Service. La segunda etapa es la etapa de inferencia en línea, ejecutando la aplicación Streamlit a través de Fargate. La aplicación web recopila una consulta de búsqueda de entrada y recupera las k columnas más similares que se aproximan a la consulta del índice del servicio OpenSearch.
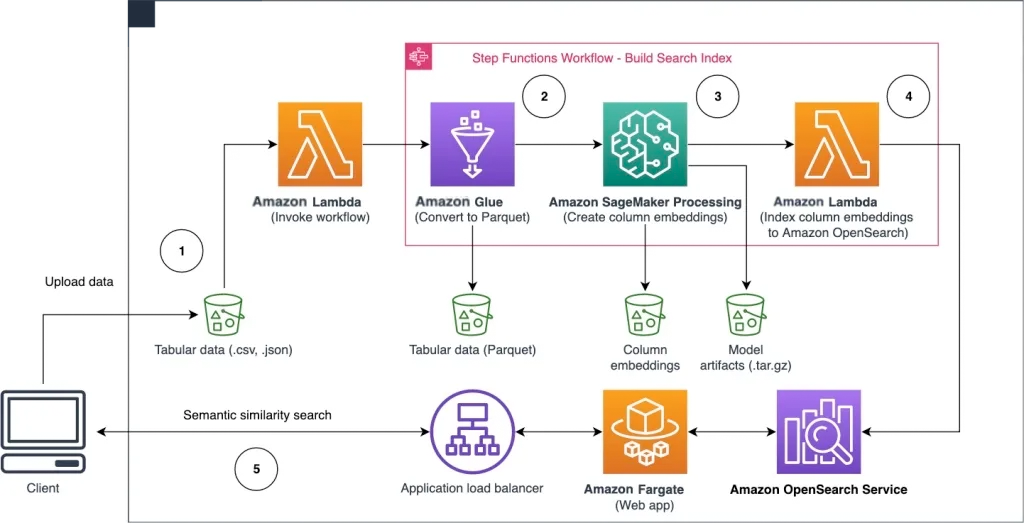
Figura 1 Arquitectura de la solución
El flujo de trabajo automatizado se desarrolla en los siguientes pasos:
Un usuario carga un conjunto de datos tabulares en un depósito de Amazon Simple Storage Service (Amazon S3), que invoca una función de Amazon Lambda para iniciar un flujo de trabajo de Step Functions.
El flujo de trabajo comienza con un trabajo de Amazon Glue que convierte el archivo CSV al formato de datos de Apache Parquet.
Un trabajo de procesamiento de SageMaker crea objetos de incrustación para columnas individuales, utilizando un modelo previamente entrenado o un modelo de incrustación de columnas personalizado. El trabajo de procesamiento de SageMaker guarda los objetos de incrustación de columnas de cada tabla en Amazon S3.
La función Lambda crea el dominio y el clúster del servicio OpenSearch para indexar los objetos de incrustación de columnas generados en el paso anterior.
Finalmente, use Fargate para implementar la aplicación web interactiva Streamlit. La aplicación web proporciona una interfaz para que el usuario ingrese una consulta para buscar columnas similares en el dominio del servicio OpenSearch.
Puede descargar el tutorial de código de GitHub para probar esta solución con datos de muestra o con sus propios datos. Las instrucciones sobre cómo implementar los recursos necesarios para este tutorial están disponibles en Github.
requisitos previos
Para implementar esta solución, necesita:
Cuenta de tecnología en la nube de Amazon.
Algunos conocimientos básicos de los servicios en la nube de Amazon, como Amazon Cloud Development Kit (Amazon CDK), Lambda, OpenSearch Service y SageMaker Processing.
El conjunto de datos tabulares utilizado para crear el índice de búsqueda. Puede utilizar sus propios datos tabulares o descargar un conjunto de datos de muestra en GitHub.
construir índice de búsqueda
El índice del motor de búsqueda de columnas se construirá en la primera fase. El siguiente diagrama muestra el flujo de trabajo de Step Functions para ejecutar esta etapa.
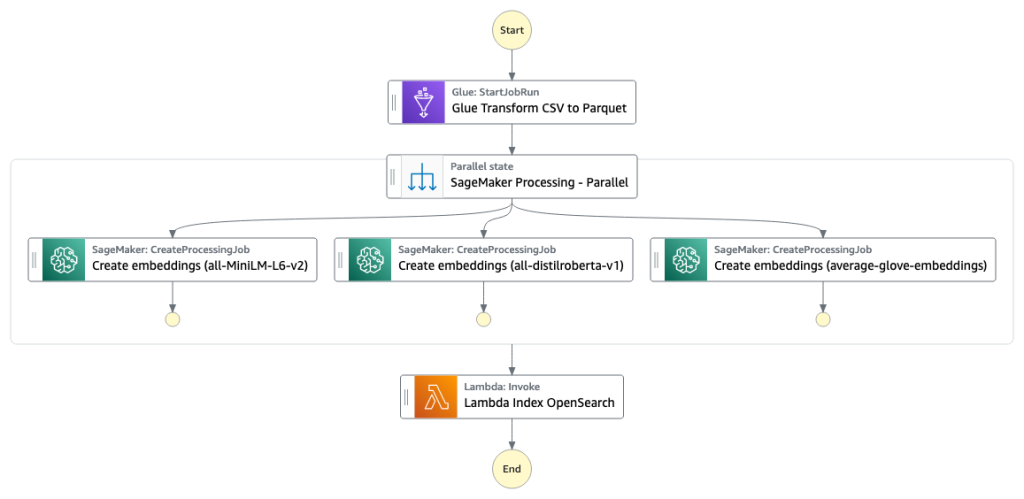
Figura 2 Flujo de trabajo de funciones de pasos: múltiples modelos integrados
conjunto de datos
En este artículo, creamos un índice de búsqueda que incluía más de 400 columnas en un conjunto de datos de más de 25 tablas. Los conjuntos de datos provienen de las siguientes fuentes públicas:
s3://sagemaker-sample-files/datasets/tabular/
Datos abiertos de Nueva York
Portal de datos de Chicago
Para obtener una lista completa de las tablas incluidas en el índice, consulte el tutorial de código en GitHub (https://github.com/aws-samples/tabular-column-semantic-search/blob/main/sample-batch-datasets.json) .
Puede aumentar los datos de ejemplo con su propio conjunto de datos tabulares o crear su propio índice de búsqueda. Proporcionamos dos funciones Lambda para iniciar el flujo de trabajo de Step Functions, que crean respectivamente un índice de búsqueda para un único archivo CSV o un lote de archivos CSV.
Convertir CSV a Parquet
Convierta el archivo CSV sin formato al formato de datos Parquet utilizando Amazon Glue. Parquet es un formato de archivo orientado a columnas y es el formato elegido en el análisis de big data, ya que proporciona una compresión y codificación eficientes. En nuestros experimentos, el formato de datos Parquet reduce significativamente el espacio de almacenamiento requerido en comparación con los archivos CSV sin formato. También utilizamos Parquet como formato de datos común para convertir otros formatos de datos como JSON y NDJSON debido a su compatibilidad con estructuras de datos anidadas avanzadas.
Crear objeto de incrustación de columna de tabla
En este artículo, para extraer incrustaciones para una sola columna de tabla en el conjunto de datos tabulares de ejemplo, utilizamos los siguientes modelos previamente entrenados de la biblioteca de transformadores de oraciones. Consulte Modelos previamente entrenados para conocer otros modelos (https://www.sbert.net/docs/pretrained_models.html)
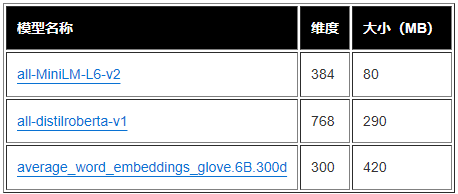
El trabajo de procesamiento de SageMaker ejecuta create_embeddings.py (código: https://github.com/aws-samples/tabular-column-semantic-search/blob/main/assets/s3/scripts/create_embeddings.py) para un único modelo. Para extraer objetos incrustados de varios modelos, el flujo de trabajo ejecuta trabajos de procesamiento de SageMaker en paralelo, como se muestra en el flujo de trabajo de Step Functions. Usamos este modelo para crear dos conjuntos de objetos incrustados:
column_name_embeddings: incrustar objetos para nombres de columnas (encabezados)
column_content_embeddings: promedio de objetos incrustados en todas las filas de una columna
Para obtener más información sobre el proceso de incrustación de columnas, consulte el tutorial de código en GitHub (https://github.com/aws-samples/tabular-column-semantic-search).
Una alternativa al paso de procesamiento de SageMaker es crear una transformación por lotes de SageMaker para obtener objetos de incrustación de columnas en conjuntos de datos grandes. Esto requerirá implementar el modelo en un punto final de SageMaker. Para obtener más información, consulte Usar transformación por lotes.
Usando el servicio OpenSearch
Indexar objetos incrustados
En el paso final de esta fase, la función Lambda agrega el objeto de incrustación de columna al índice de búsqueda aproximado de k-vecino más cercano (kNN, k-Nearest-Neighbor) del servicio OpenSearch. Asigne a cada modelo su propio índice de búsqueda. Consulte k-NN (https://opensearch.org/docs/latest/search-plugins/knn/index/) para obtener más información sobre los parámetros aproximados del índice de búsqueda de kNN.
Utilice la aplicación web
Realizar razonamiento en línea y búsqueda semántica.
La segunda etapa del flujo de trabajo ejecuta la aplicación web Streamlit, donde usted proporciona datos de entrada y luego busca en el servicio OpenSearch columnas indexadas con semántica similar. La capa de aplicación utiliza Application Load Balancer, Fargate y Lambda. La infraestructura de aplicaciones se implementa automáticamente como parte de la solución.
Con la aplicación, puede proporcionar datos de entrada y luego buscar nombres de columnas y/o contenidos de columnas con semántica similar. Además, puede elegir el modelo de incrustación y el número de vecinos más cercanos que aparecen en la búsqueda. La aplicación recibe datos de entrada, incrusta los datos de entrada utilizando el modelo especificado y utiliza la búsqueda kNN en el servicio OpenSearch para buscar los objetos incrustados de columnas indexadas y encontrar las columnas más similares a los datos de entrada proporcionados. Los resultados de búsqueda que se muestran incluyen nombres de tablas, nombres de columnas y puntuaciones de similitud para las columnas identificadas, así como la ubicación de los datos en Amazon S3 para una mayor exploración.
La siguiente figura muestra un ejemplo de una aplicación web. En este ejemplo, buscamos en el lago de datos columnas con nombres de columna ( tipo de carga ) similares al distrito ( carga ). La aplicación utiliza all-MiniLM-L6-v2 como modelo de incrustación y devuelve los 10 ( k ) vecinos más cercanos del índice del servicio OpenSearch.
Según los datos indexados en el servicio OpenSearch, la aplicación devuelve distrito_de tránsito, ciudad, municipio y ubicación como las cuatro columnas más similares. Este ejemplo demuestra el poder del método de búsqueda para identificar columnas semánticas similares en un conjunto de datos.

Figura 3: Interfaz de usuario de la aplicación web
limpiar
Para eliminar los recursos creados por Amazon CDK en este tutorial, ejecute el siguiente comando:
Intento
cdk destroy --allDesliza hacia la izquierda para ver más
Resumir
En esta publicación, presentamos un flujo de trabajo de un extremo a otro para crear un motor de búsqueda semántica para columnas tabulares.
Puede comenzar a trabajar con sus propios datos utilizando nuestros tutoriales de código en GitHub (https://github.com/aws-samples/tabular-column-semantic-search). Si necesita ayuda para acelerar el uso de capacidades de aprendizaje automático en sus productos y procesos, comuníquese con el Laboratorio de soluciones de aprendizaje automático de Amazon (https://aws.amazon.com/ml-solutions-lab/).
URL original:
https://aws.amazon.com/blogs/big-data/build-a-semantic-search-engine-for-tabular-columns-with-transformers-and-amazon-opensearch-service/
El autor de este artículo.

Kachi Odoemene
Científico Aplicado de la División de Inteligencia Artificial de Amazon Cloud Technologies. Crea soluciones de IA/ML para resolver problemas comerciales para los clientes de tecnología en la nube de Amazon.

taylor mcnally
Arquitecto de aprendizaje profundo en el laboratorio de soluciones de aprendizaje automático de Amazon. Ayuda a clientes de diferentes industrias a crear soluciones utilizando IA/aprendizaje automático en la tecnología de la nube de Amazon. Le encanta el buen café, le encanta estar al aire libre y le gusta pasar tiempo con su familia y su perro activo.

austin welch
Científico de datos en Amazon ML Solutions Lab. Desarrolla modelos personalizados de aprendizaje profundo para ayudar a los clientes del sector público de Amazon Cloud Technology a acelerar la adopción de la IA y la nube. En su tiempo libre le gusta leer, viajar y practicar jiu-jitsu.


He oído, haz clic en los 4 botones siguientes
¡No encontrarás errores!
