Zhihu:
enlace nghuyong:
https://zhuanlan.zhihu.com/p/651430181
Ingrese al grupo de PNL -> únase al grupo de intercambio de PNL
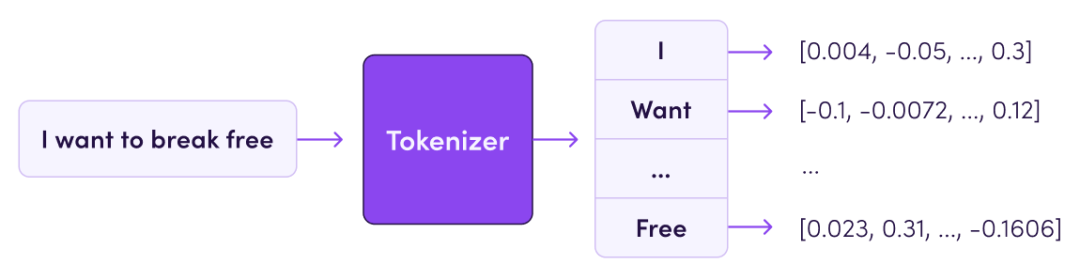
El algoritmo de segmentación de palabras de Tokenizer es el componente más básico del modelo grande de PNL. Basado en Tokenizer, el texto se puede convertir en una lista de tokens independiente y luego el vector de entrada se puede convertir en un formulario de entrada que la computadora pueda comprender. Este artículo clasificará sistemáticamente los tokenizadores, incluida la ruta de evolución del modelo de tokenizador, las herramientas disponibles y promoverá la implementación específica de cada tokenizador.
Hechos rápidos
Según las diferentes granularidades de segmentación, los tokenizadores se pueden dividir en: segmentación basada en palabras, segmentación basada en palabras y segmentación basada en subpalabras. La segmentación basada en subpalabras es el método de segmentación principal actual.
La segmentación de subpalabras incluye: modelos de segmentación de tres palabras BPE (/BBPE), WordPieza y Unigram. Entre ellos, WordPieza puede considerarse como un BPE especial.
El proceso completo de segmentación de palabras incluye: normalización de texto, presegmentación, segmentación basada en el modelo de segmentación de palabras y posprocesamiento.
SentencePieza es una herramienta de segmentación de palabras con BEP incorporado y otros métodos de segmentación de palabras. Se basa en la codificación Unicode y trata los espacios como tokens especiales. Es el esquema de segmentación de palabras principal del modelo grande actual.
| método de segmentación de palabras | modelo tipico |
|---|---|
| BPE | GPT, GPT-2, GPT-J, GPT-Neo, Roberta, BART, Llama, ChatGLM-6B, Baichuan |
| pieza de palabra | BERT, DistilBERT, móvilBERT |
| unigrama | Alberto, T5, mBART, XLNet |
1. Segmentación basada en subpalabra
La segmentación basada en subpalabras puede equilibrar las ventajas y desventajas de la segmentación basada en palabras y la segmentación basada en palabras, y actualmente es el método de segmentación más común.
Sin embargo, existen ciertos problemas en la segmentación basada en palabras y caracteres, y el efecto de la aplicación directa es relativamente pobre.
La segmentación basada en palabras dará como resultado:
vocabulario demasiado grande
Debe haber UNK, lo que resulta en pérdida de información.
La relación entre afijos no se puede aprender, por ejemplo: perro y perros, feliz e infeliz.
La segmentación basada en palabras dará como resultado:
Baja densidad de información por token
La secuencia es demasiado larga y la eficiencia de decodificación es muy baja.
Por lo tanto, los métodos de segmentación basados en palabras y basados en palabras son dos extremos, y sus ventajas y desventajas también son complementarias. La subpalabra de compromiso es una solución relativamente equilibrada.
El principio básico de segmentación de subpalabras es:
Las palabras de alta frecuencia todavía se dividen en palabras completas.
Las palabras de baja frecuencia se segmentan en subpalabras significativas, como perros => [perro, ##s]
La segmentación basada en subpalabras puede lograr:
El tamaño del vocabulario es moderado y la eficiencia de decodificación es alta.
No hay UNK y la información no se pierde.
Puede aprender la relación entre afijos.
La segmentación basada en subpalabras incluye: modelos de segmentación de tres palabras BPE, WordPieza y Unigram.
2. Proceso de segmentación
Tokenizer incluye dos enlaces de entrenamiento y razonamiento. La fase de entrenamiento se refiere a la obtención de un modelo tokenizador del corpus. La etapa de inferencia se refiere a una oración determinada, que se divide en una serie de tokens según el modelo de segmentación de palabras.
El proceso básico se muestra en la figura, que incluye cuatro pasos de normalización, presegmentación, segmentación basada en el modelo de segmentación de palabras y posprocesamiento.

2.1 Normalización
Esta es la limpieza de texto más básica, que incluye eliminar líneas nuevas y espacios redundantes, convertir a minúsculas, eliminar acentos, etc. Por ejemplo:
input: Héllò hôw are ü?
normalization: hello how are u?Implementación del tokenizador HuggingFace: https://huggingface.co/docs/tokenizers/api/normalizers
2.2 Pre-segmentación
La etapa de presegmentación dividirá la oración en unidades de "palabras" más pequeñas. La segmentación puede basarse en espacios o puntuación. Los detalles de implementación de diferentes tokenizadores son diferentes. Por ejemplo:
input: Hello, how are you?
pre-tokenize:
[BERT]: [('Hello', (0, 5)), (',', (5, 6)), ('how', (7, 10)), ('are', (11, 14)), ('you', (16, 19)), ('?', (19, 20))]
[GPT2]: [('Hello', (0, 5)), (',', (5, 6)), ('Ġhow', (6, 10)), ('Ġare', (10, 14)), ('Ġ', (14, 15)), ('Ġyou', (15, 19)), ('?', (19, 20))]
[t5]: [('▁Hello,', (0, 6)), ('▁how', (7, 10)), ('▁are', (11, 14)), ('▁you?', (16, 20))]Se puede ver que el tokenizador de BERT se basa directamente en espacios y puntuación. GPT2 también se basa en espacios y tabulaciones, pero los espacios se conservan como caracteres especiales "Ġ". T5 solo se divide según los espacios, no la puntuación. Y los espacios se reservarán como caracteres especiales " ", y se agregarán caracteres especiales " " al principio de las oraciones.
Implementación del tokenizador HuggingFace: https://huggingface.co/docs/tokenizers/api/pre-tokenizers
2.3 Segmentación basada en el modelo de segmentación de palabras.
Esto se refiere a los métodos de segmentación específicos de diferentes modelos de segmentación de palabras. Los modelos de segmentación de palabras incluyen: modelos de segmentación de tres palabras BPE, WordPieza y Unigram.
Implementación del tokenizador HuggingFace: https://huggingface.co/docs/tokenizers/api/models
2.4 Postprocesamiento
La etapa de posprocesamiento incluirá alguna lógica especial de segmentación de palabras, como agregar un token especial: [CLS], [SEP], etc. Implementación del tokenizador HuggingFace: https://huggingface.co/docs/tokenizers/api/post-processors
3.BPE
La codificación de par de bytes (BPE) es el tokenizador de subpalabras más utilizado.
Método de entrenamiento: comenzando con un pequeño vocabulario a nivel de personaje, entrenando para generar reglas de fusión y un vocabulario.
Método de codificación: divida el texto en caracteres y luego aplique las reglas de fusión obtenidas en la fase de entrenamiento
Modelos clásicos: GPT, GPT-2, RoBERTa, BART, LLaMA, ChatGLM, etc.
3.1 Fase de Formación
En la fase de entrenamiento, el objetivo es generar reglas de fusión y vocabulario a través del algoritmo de entrenamiento dado al corpus. El algoritmo BPE se basa en un vocabulario a nivel de carácter, fusionando pares y agregándolos al vocabulario, y formando gradualmente un vocabulario grande. La regla de fusión es seleccionar el par adyacente con la mayor frecuencia de palabras para fusionar.
Hagámoslo manualmente.
Supongamos que el corpus de entrenamiento (normalizado) es de 4 oraciones.
corpus = [
"This is the Hugging Face Course.",
"This chapter is about tokenization.",
"This section shows several tokenizer algorithms.",
"Hopefully, you will be able to understand how they are trained and generate tokens.",
]Primero realice la segmentación previa. Aquí se utiliza la lógica de presegmentación de gpt2. En concreto, se segmentará según espacios y puntuación, y los espacios se reservarán como caracteres especiales "Ġ".
from transformers import AutoTokenizer
# init pre tokenize function
gpt2_tokenizer = AutoTokenizer.from_pretrained("gpt2")
pre_tokenize_function = gpt2_tokenizer.backend_tokenizer.pre_tokenizer.pre_tokenize_str
# pre tokenize
pre_tokenized_corpus = [pre_tokenize_str(text) for text in corpus]El pre_tokenized_corpus obtenido es el siguiente, cada unidad es [palabra, (start_index, end_index)]
[
[('This', (0, 4)), ('Ġis', (4, 7)), ('Ġthe', (7, 11)), ('ĠHugging', (11, 19)), ('ĠFace', (19, 24)), ('ĠCourse', (24, 31)), ('.', (31, 32))],
[('This', (0, 4)), ('Ġchapter', (4, 12)), ('Ġis', (12, 15)), ('Ġabout', (15, 21)), ('Ġtokenization', (21, 34)), ('.', (34, 35))],
[('This', (0, 4)), ('Ġsection', (4, 12)), ('Ġshows', (12, 18)), ('Ġseveral', (18, 26)), ('Ġtokenizer', (26, 36)), ('Ġalgorithms', (36, 47)), ('.', (47, 48))],
[('Hopefully', (0, 9)), (',', (9, 10)), ('Ġyou', (10, 14)), ('Ġwill', (14, 19)), ('Ġbe', (19, 22)), ('Ġable', (22, 27)), ('Ġto', (27, 30)), ('Ġunderstand', (30, 41)), ('Ġhow', (41, 45)), ('Ġthey', (45, 50)), ('Ġare', (50, 54)), ('Ġtrained', (54, 62)), ('Ġand', (62, 66)), ('Ġgenerate', (66, 75)), ('Ġtokens', (75, 82)), ('.', (82, 83))]
]Cuente más la frecuencia de palabras de cada palabra completa.
word2count = defaultdict(int)
for split_text in pre_tokenized_corpus:
for word, _ in split_text:
word2count[word] += 1Obtenga word2count de la siguiente manera
defaultdict(<class 'int'>, {'This': 3, 'Ġis': 2, 'Ġthe': 1, 'ĠHugging': 1, 'ĠFace': 1, 'ĠCourse': 1, '.': 4, 'Ġchapter': 1, 'Ġabout': 1, 'Ġtokenization': 1, 'Ġsection': 1, 'Ġshows': 1, 'Ġseveral': 1, 'Ġtokenizer': 1, 'Ġalgorithms': 1, 'Hopefully': 1, ',': 1, 'Ġyou': 1, 'Ġwill': 1, 'Ġbe': 1, 'Ġable': 1, 'Ġto': 1, 'Ġunderstand': 1, 'Ġhow': 1, 'Ġthey': 1, 'Ġare': 1, 'Ġtrained': 1, 'Ġand': 1, 'Ġgenerate': 1, 'Ġtokens': 1})Debido a que BPE se fusiona gradualmente con un vocabulario pequeño a nivel de personaje en un vocabulario grande, primero es necesario obtener un vocabulario pequeño a nivel de personaje.
vocab_set = set()
for word in word2count:
vocab_set.update(list(word))
vocabs = list(vocab_set)El pequeño vocabulario inicial obtenido es el siguiente:
['i', 't', 'p', 'o', 'r', 'm', 'e', ',', 'y', 'v', 'Ġ', 'F', 'a', 'C', 'H', '.', 'f', 'l', 'u', 'c', 'T', 'k', 'h', 'z', 'd', 'g', 'w', 'n', 's', 'b']Cada palabra completa se puede segmentar en función de un pequeño vocabulario.
word2splits = {word: [c for c in word] for word in word2count}'This': ['T', 'h', 'i', 's'],
'Ġis': ['Ġ', 'i', 's'],
'Ġthe': ['Ġ', 't', 'h', 'e'],
...
'Ġand': ['Ġ', 'a', 'n', 'd'],
'Ġgenerate': ['Ġ', 'g', 'e', 'n', 'e', 'r', 'a', 't', 'e'],
'Ġtokens': ['Ġ', 't', 'o', 'k', 'e', 'n', 's']Basado en estadísticas de word2splits de frecuencia de palabras pair2count de dos pares adyacentes en vocabularios
def _compute_pair2score(word2splits, word2count):
pair2count = defaultdict(int)
for word, word_count in word2count.items():
split = word2splits[word]
if len(split) == 1:
continue
for i in range(len(split) - 1):
pair = (split[i], split[i + 1])
pair2count[pair] += word_count
return pair2countObtenga pair2count de la siguiente manera:
defaultdict(<class 'int'>, {('T', 'h'): 3, ('h', 'i'): 3, ('i', 's'): 5, ('Ġ', 'i'): 2, ('Ġ', 't'): 7, ('t', 'h'): 3, ..., ('n', 's'): 1})Cuente los pares adyacentes con la frecuencia actual más alta
def _compute_most_score_pair(pair2count):
best_pair = None
max_freq = None
for pair, freq in pair2count.items():
if max_freq is None or max_freq < freq:
best_pair = pair
max_freq = freq
return best_pairSegún las estadísticas, el par actual con mayor frecuencia es: ('Ġ', 't'), con una frecuencia de 7 veces. Fusiona ('Ġ', 't') en una palabra y agrégala al vocabulario. Al mismo tiempo, agregue la regla de combinación ('Ġ', 't') a la regla de combinación.
merge_rules = []
best_pair = self._compute_most_score_pair(pair2score)
vocabs.append(best_pair[0] + best_pair[1])
merge_rules.append(best_pair)En este momento, el vocabulario se actualiza a:
['i', 't', 'p', 'o', 'r', 'm', 'e', ',', 'y', 'v', 'Ġ', 'F', 'a', 'C', 'H', '.', 'f', 'l', 'u', 'c', 'T', 'k', 'h', 'z', 'd', 'g', 'w', 'n', 's', 'b',
'Ġt']Vuelva a segmentar el recuento de palabras de acuerdo con el vocabulario actualizado. En términos de implementación específica, las nuevas reglas de fusión ('Ġ', 't') se pueden aplicar directamente al antiguo word2split.
def _merge_pair(a, b, word2splits):
new_word2splits = dict()
for word, split in word2splits.items():
if len(split) == 1:
new_word2splits[word] = split
continue
i = 0
while i < len(split) - 1:
if split[i] == a and split[i + 1] == b:
split = split[:i] + [a + b] + split[i + 2:]
else:
i += 1
new_word2splits[word] = split
return new_word2splitsy así obtener el nuevo word2split
{'This': ['T', 'h', 'i', 's'],
'Ġis': ['Ġ', 'i', 's'],
'Ġthe': ['Ġt', 'h', 'e'],
'ĠHugging': ['Ġ', 'H', 'u', 'g', 'g', 'i', 'n', 'g'],
...
'Ġtokens': ['Ġt', 'o', 'k', 'e', 'n', 's']}Puedes ver que la nueva palabra "Ġt" se ha incluido en el nuevo word2split.
Repita el ciclo anterior hasta que el tamaño de todo el vocabulario alcance el tamaño de vocabulario preestablecido.
while len(vocabs) < vocab_size:
pair2score = self._compute_pair2score(word2splits, word2count)
best_pair = self._compute_most_score_pair(pair2score)
vocabs.append(best_pair[0] + best_pair[1])
merge_rules.append(best_pair)
word2splits = self._merge_pair(best_pair[0], best_pair[1], word2splits)Suponiendo que el tamaño del vocabulario final es 50, el vocabulario y las reglas de fusión que obtuvimos después de las iteraciones anteriores son las siguientes:
vocabs = ['i', 't', 'p', 'o', 'r', 'm', 'e', ',', 'y', 'v', 'Ġ', 'F', 'a', 'C', 'H', '.', 'f', 'l', 'u', 'c', 'T', 'k', 'h', 'z', 'd', 'g', 'w', 'n', 's', 'b', 'Ġt', 'is', 'er', 'Ġa', 'Ġto', 'en', 'Th', 'This', 'ou', 'se', 'Ġtok', 'Ġtoken', 'nd', 'Ġis', 'Ġth', 'Ġthe', 'in', 'Ġab', 'Ġtokeni', 'Ġtokeniz']
merge_rules = [('Ġ', 't'), ('i', 's'), ('e', 'r'), ('Ġ', 'a'), ('Ġt', 'o'), ('e', 'n'), ('T', 'h'), ('Th', 'is'), ('o', 'u'), ('s', 'e'), ('Ġto', 'k'), ('Ġtok', 'en'), ('n', 'd'), ('Ġ', 'is'), ('Ġt', 'h'), ('Ġth', 'e'), ('i', 'n'), ('Ġa', 'b'), ('Ġtoken', 'i'), ('Ġtokeni', 'z')]Hasta ahora hemos completado el entrenamiento del tokenizador BPE según el corpus proporcionado.
3.2 Fase de inferencia
En la fase de inferencia, dada una oración, debemos dividirla en una secuencia de tokens. En términos de implementación específica, las oraciones deben segmentarse previamente y dividirse en secuencias a nivel de caracteres, y luego fusionarse de acuerdo con las reglas de fusión.
def tokenize(self, text: str) -> List[str]:
# pre tokenize
words = [word for word, _ in self.pre_tokenize_str(text)]
# split into char level
splits = [[c for c in word] for word in words]
# apply merge rules
for merge_rule in self.merge_rules:
for index, split in enumerate(splits):
i = 0
while i < len(split) - 1:
if split[i] == merge_rule[0] and split[i + 1] == merge_rule[1]:
split = split[:i] + ["".join(merge_rule)] + split[i + 2:]
else:
i += 1
splits[index] = split
return sum(splits, [])Por ejemplo
>>> tokenize("This is not a token.")
>>> ['This', 'Ġis', 'Ġ', 'n', 'o', 't', 'Ġa', 'Ġtoken', '.']3.3. BBPE
El algoritmo BPE a nivel de bytes (BBPE) propuesto en 2019 es una actualización adicional del algoritmo BPE anterior. Consulte: Traducción automática neuronal con subpalabras a nivel de bytes para obtener más detalles . La idea central es utilizar bytes para construir el vocabulario más básico en lugar de caracteres. Primero codifique el texto de acuerdo con UTF-8, y cada carácter ocupa de 1 a 4 bytes en la representación UTF-8. Utilice el algoritmo BPE en la secuencia de bytes para realizar una fusión adyacente a nivel de bytes. El formulario de codificación se muestra en la siguiente figura:

Este método puede abordar mejor problemas especiales de idiomas cruzados y caracteres poco comunes (por ejemplo, emoji) y ahorra espacio de vocabulario en comparación con el BPE tradicional (el efecto del mismo tamaño de vocabulario es mejor), y cada token también puede obtener una mejor capacitación. .
Sin embargo, en la etapa de decodificación, una secuencia de bytes puede no ser una secuencia de caracteres legales después de la decodificación, por lo que es necesario utilizar un algoritmo de programación dinámica para decodificar tantos caracteres legales como sea posible. El algoritmo específico es el siguiente: suponga que la secuencia de caracteres representa el número máximo de caracteres legales que se pueden decodificar y que existe una subestructura óptima:
Aquí si es de carácter legal, en caso contrario.
4. pieza de palabras
La segmentación de palabras de WordPiece es muy similar a BPE, excepto que la estrategia para fusionar pares en la fase de entrenamiento no es la frecuencia de los pares sino la información mutua.
La motivación aquí es que un par tiene una frecuencia alta, pero una parte del par tiene una frecuencia más alta, y no es necesariamente necesario fusionar el par en este momento. Y si la frecuencia de un par es muy alta y ambas partes del par solo aparecen en este par, significa que vale la pena fusionar este par.
Método de entrenamiento: comenzando con un pequeño vocabulario a nivel de personaje, entrenando para generar reglas de fusión y un vocabulario.
Método de codificación: segmente el texto en palabras y realice la máxima coincidencia directa para cada palabra del vocabulario.
Modelos clásicos: BERT y sus series DistilBERT, MobileBERT, etc.
4.1 Fase de formación
En la fase de entrenamiento, dado el corpus, se genera el vocabulario final a través del algoritmo de entrenamiento. El algoritmo de WordPiece también se basa en un vocabulario a nivel de carácter y se expande gradualmente hasta convertirse en un vocabulario amplio. La regla de fusión es seleccionar el par adyacente con la mayor información mutua para fusionar.
La implementación manual específica se realiza a continuación.
Supongamos que el corpus de entrenamiento (normalizado) es
corpus = [
"This is the Hugging Face Course.",
"This chapter is about tokenization.",
"This section shows several tokenizer algorithms.",
"Hopefully, you will be able to understand how they are trained and generate tokens.",
]Primero realice la segmentación previa. Aquí se utiliza la lógica de presegmentación de BERT. En concreto, estará segmentado según espacios y puntuación.
from transformers import AutoTokenizer
# init pre tokenize function
bert_tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
pre_tokenize_function = bert_tokenizer.backend_tokenizer.pre_tokenizer.pre_tokenize_str
# pre tokenize
pre_tokenized_corpus = [pre_tokenize_str(text) for text in corpus]El pre_tokenized_corpus obtenido es el siguiente, cada unidad es [palabra, (start_index, end_index)]
[
[('This', (0, 4)), ('is', (5, 7)), ('the', (8, 11)), ('Hugging', (12, 19)), ('Face', (20, 24)), ('Course', (25, 31)), ('.', (31, 32))],
[('This', (0, 4)), ('chapter', (5, 12)), ('is', (13, 15)), ('about', (16, 21)), ('tokenization', (22, 34)), ('.', (34, 35))],
[('This', (0, 4)), ('section', (5, 12)), ('shows', (13, 18)), ('several', (19, 26)), ('tokenizer', (27, 36)), ('algorithms', (37, 47)), ('.', (47, 48))],
[('Hopefully', (0, 9)), (',', (9, 10)), ('you', (11, 14)), ('will', (15, 19)), ('be', (20, 22)), ('able', (23, 27)), ('to', (28, 30)), ('understand', (31, 41)), ('how', (42, 45)), ('they', (46, 50)), ('are', (51, 54)), ('trained', (55, 62)), ('and', (63, 66)), ('generate', (67, 75)), ('tokens', (76, 82)), ('.', (82, 83))]
]Más frecuencia estadística de palabras
word2count = defaultdict(int)
for split_text in pre_tokenized_corpus:
for word, _ in split_text:
word2count[word] += 1Obtenga word2count de la siguiente manera
defaultdict(<class 'int'>, {'This': 3, 'is': 2, 'the': 1, 'Hugging': 1, 'Face': 1, 'Course': 1, '.': 4, 'chapter': 1, 'about': 1, 'tokenization': 1, 'section': 1, 'shows': 1, 'several': 1, 'tokenizer': 1, 'algorithms': 1, 'Hopefully': 1, ',': 1, 'you': 1, 'will': 1, 'be': 1, 'able': 1, 'to': 1, 'understand': 1, 'how': 1, 'they': 1, 'are': 1, 'trained': 1, 'and': 1, 'generate': 1, 'tokens': 1})Debido a que WordPiece también se fusiona gradualmente a partir de un vocabulario pequeño a nivel de personaje en un vocabulario grande, el vocabulario pequeño a nivel de personaje se obtiene primero. Tenga en cuenta que si el carácter no es el comienzo de una palabra, deberá agregar el carácter especial "##".
vocab_set = set()
for word in word2count:
vocab_set.add(word[0])
vocab_set.update(['##' + c for c in word[1:]])
vocabs = list(vocab_set)El pequeño vocabulario inicial obtenido es el siguiente:
['##a', '##b', '##c', '##d', '##e', '##f', '##g', '##h', '##i', '##k', '##l', '##m', '##n', '##o', '##p', '##r', '##s', '##t', '##u', '##v', '##w', '##y', '##z', ',', '.', 'C', 'F', 'H', 'T', 'a', 'b', 'c', 'g', 'h', 'i', 's', 't', 'u', 'w', 'y']Segmenta cada palabra basándose en un pequeño vocabulario.
word2splits = {word: [word[0]] + ['##' + c for c in word[1:]] for word in word2count}{'This': ['T', '##h', '##i', '##s'],
'is': ['i', '##s'],
'the': ['t', '##h', '##e'],
'Hugging': ['H', '##u', '##g', '##g', '##i', '##n', '##g'],
...
'generate': ['g', '##e', '##n', '##e', '##r', '##a', '##t', '##e'],
'tokens': ['t', '##o', '##k', '##e', '##n', '##s']}Cuente más la información mutua de dos pares adyacentes en vocabularios
def _compute_pair2score(word2splits, word2count):
"""
计算每个pair的分数
score=(freq_of_pair)/(freq_of_first_element×freq_of_second_element)
:return:
"""
vocab2count = defaultdict(int)
pair2count = defaultdict(int)
for word, word_count in word2count.items():
splits = word2splits[word]
if len(splits) == 1:
vocab2count[splits[0]] += word_count
continue
for i in range(len(splits) - 1):
pair = (splits[i], splits[i + 1])
vocab2count[splits[i]] += word_count
pair2count[pair] += word_count
vocab2count[splits[-1]] += word_count
scores = {
pair: freq / (vocab2count[pair[0]] * vocab2count[pair[1]])
for pair, freq in pair2count.items()
}
return scoresLa información mutua de cada par se obtiene de la siguiente manera:
{('T', '##h'): 0.125,
('##h', '##i'): 0.03409090909090909,
('##i', '##s'): 0.02727272727272727,
('a', '##b'): 0.2,
...
('##n', '##s'): 0.00909090909090909}Cuente los pares adyacentes con mayor información mutua.
def _compute_most_score_pair(pair2score):
best_pair = None
max_score = None
for pair, score in pair2score.items():
if max_score is None or max_score < score:
best_pair = pair
max_score = score
return best_pairEn este momento, el par con mayor información mutua es: ('a', '##b') Fusionar ('a', '##b') en una palabra 'ab' y agregarla al vocabulario
best_pair = self._compute_most_score_pair(pair2score)
vocabs.append(best_pair[0] + best_pair[1])De esta forma, el vocabulario se actualiza a:
['##a', '##b', '##c', '##d', '##e', '##f', '##g', '##h', '##i', '##k', '##l', '##m', '##n', '##o', '##p', '##r', '##s', '##t', '##u', '##v', '##w', '##y', '##z', ',', '.', 'C', 'F', 'H', 'T', 'a', 'b', 'c', 'g', 'h', 'i', 's', 't', 'u', 'w', 'y',
'ab']Vuelva a segmentar el recuento de palabras de acuerdo con el vocabulario actualizado.
def _merge_pair(a, b, word2splits):
new_word2splits = dict()
for word, split in word2splits.items():
if len(split) == 1:
new_word2splits[word] = split
continue
i = 0
while i < len(split) - 1:
if split[i] == a and split[i + 1] == b:
merge = a + b[2:] if b.startswith("##") else a + b
split = split[:i] + [merge] + split[i + 2:]
else:
i += 1
new_word2splits[word] = split
return new_word2splitsObtenga el nuevo word2split
{'This': ['T', '##h', '##i', '##s'],
'is': ['i', '##s'], 'the': ['t', '##h', '##e'],
'Hugging': ['H', '##u', '##g', '##g', '##i', '##n', '##g'],
'about': ['ab', '##o', '##u', '##t'],
'tokens': ['t', '##o', '##k', '##e', '##n', '##s']}Puedes ver que la nueva palabra "ab" se ha incluido en el nuevo word2split.
Repita los pasos anteriores hasta que el tamaño de todo el vocabulario alcance el tamaño de vocabulario preestablecido.
while len(vocabs) < vocab_size:
pair2score = self._compute_pair2score(word2splits, word2count)
best_pair = self._compute_most_score_pair(pair2score)
word2splits = self._merge_pair(best_pair[0], best_pair[1], word2splits)
new_token = best_pair[0] + best_pair[1][2:] if best_pair[1].startswith('##') else best_pair[1]
vocabs.append(new_token)Suponiendo que el tamaño del vocabulario final es 70, el vocabulario que obtenemos después de las iteraciones anteriores es el siguiente:
vocabs = ['##a', '##b', '##c', '##ct', '##d', '##e', '##f', '##fu', '##ful', '##full', '##fully', '##g', '##h', '##hm', '##i', '##k', '##l', '##m', '##n', '##o', '##p', '##r', '##s', '##t', '##thm', '##thms', '##u', '##ut', '##v', '##w', '##y', '##z', '##za', '##zat', ',', '.', 'C', 'F', 'Fa', 'Fac', 'H', 'Hu', 'Hug', 'Hugg', 'T', 'Th', 'a', 'ab', 'b', 'c', 'ch', 'cha', 'chap', 'chapt', 'g', 'h', 'i', 'is', 's', 'sh', 't', 'th', 'u', 'w', 'y', '[CLS]', '[MASK]', '[PAD]', '[SEP]', '[UNK]']Tenga en cuenta que se agregan tokens especiales al vocabulario: [CLS], [MASK], [PAD], [SEP], [UNK] Hasta ahora hemos completado el entrenamiento del tokenizador de Wordpiece según el corpus dado.
4.2 Fase de inferencia
En la fase de razonamiento, dada una oración, es necesario dividirla en una secuencia de fichas. En términos de implementación específica, primero es necesario segmentar previamente la oración y luego realizar la máxima coincidencia directa en el vocabulario para cada palabra. UNK si no está presente en el vocabulario.
def _encode_word(self, word):
tokens = []
while len(word) > 0:
i = len(word)
while i > 0 and word[:i] not in self.vocabs:
i -= 1
if i == 0:
return ["[UNK]"]
tokens.append(word[:i])
word = word[i:]
if len(word) > 0:
word = f"##{word}"
return tokens
def tokenize(self, text):
words = [word for word, _ in self.pre_tokenize_str(text)]
encoded_words = [self._encode_word(word) for word in words]
return sum(encoded_words, [])Por ejemplo
>>> tokenize("This is the Hugging Face course!")
>>> ['Th', '##i', '##s', 'is', 'th', '##e', 'Hugg', '##i', '##n', '##g', 'Fac', '##e', 'c', '##o', '##u', '##r', '##s', '##e', '[UNK]']5. Unigrama
La segmentación de palabras de Unigram es diferente de BPE y WordPieza: se basa en un vocabulario amplio y se corta gradualmente en un vocabulario pequeño. Calcule la pérdida causada por la eliminación de diferentes subpalabras a través del modelo de lenguaje Unigram para medir la importancia de las subpalabras y retener las subpalabras con mayor importancia.
Método de entrenamiento: a partir de un vocabulario amplio que contiene caracteres y todas las subpalabras, a través del entrenamiento se elimina gradualmente un vocabulario pequeño y cada palabra tiene su propia puntuación.
Método de codificación: divida el texto en palabras y calcule la ruta de decodificación óptima para cada palabra según el algoritmo de Viterbi.
Modelos clásicos: AlBERT, T5, mBART, Big Bird, XLNet
5.1 Fase de Formación
En la fase de entrenamiento, el objetivo es generar el vocabulario final a través del algoritmo de entrenamiento dado el corpus, y cada palabra tiene su propio valor de probabilidad. El algoritmo Unigram se basa en un vocabulario amplio y lo corta gradualmente en un vocabulario pequeño. La regla de recorte es recortar palabras con una importancia relativamente baja en secuencia de acuerdo con la puntuación del modelo de lenguaje Unigram.
La implementación manual específica se realiza a continuación.
Supongamos que el corpus de entrenamiento (normalizado) es
corpus = [
"This is the Hugging Face Course.",
"This chapter is about tokenization.",
"This section shows several tokenizer algorithms.",
"Hopefully, you will be able to understand how they are trained and generate tokens.",
]Primero realice la segmentación previa. Aquí se utiliza la lógica de presegmentación de xlnet. Específicamente, se segmentará según espacios y la puntuación no se segmentará. Y los espacios se reservarán como caracteres especiales " ", y se agregarán caracteres especiales " " al principio de las oraciones.
from transformers import AutoTokenizer
# init pre tokenize function
xlnet_tokenizer = AutoTokenizer.from_pretrained("xlnet-base-cased")
pre_tokenize_function = xlnet_tokenizer.backend_tokenizer.pre_tokenizer.pre_tokenize_str
# pre tokenize
pre_tokenized_corpus = [pre_tokenize_str(text) for text in corpus]El pre_tokenized_corpus obtenido es el siguiente, cada unidad es [palabra, (start_index, end_index)]
[
[('▁This', (0, 4)), ('▁is', (5, 7)), ('▁the', (8, 11)), ('▁Hugging', (12, 19)), ('▁Face', (20, 24)), ('▁Course.', (25, 32))],
[('▁This', (0, 4)), ('▁chapter', (5, 12)), ('▁is', (13, 15)), ('▁about', (16, 21)), ('▁tokenization.', (22, 35))],
[('▁This', (0, 4)), ('▁section', (5, 12)), ('▁shows', (13, 18)), ('▁several', (19, 26)), ('▁tokenizer', (27, 36)), ('▁algorithms.', (37, 48))],
[('▁Hopefully,', (0, 10)), ('▁you', (11, 14)), ('▁will', (15, 19)), ('▁be', (20, 22)), ('▁able', (23, 27)), ('▁to', (28, 30)), ('▁understand', (31, 41)), ('▁how', (42, 45)), ('▁they', (46, 50)), ('▁are', (51, 54)), ('▁trained', (55, 62)), ('▁and', (63, 66)), ('▁generate', (67, 75)), ('▁tokens.', (76, 83))]
]Más frecuencia estadística de palabras
word2count = defaultdict(int)
for split_text in pre_tokenized_corpus:
for word, _ in split_text:
word2count[word] += 1Obtenga word2count de la siguiente manera
defaultdict(<class 'int'>, {'▁This': 3, '▁is': 2, '▁the': 1, '▁Hugging': 1, '▁Face': 1, '▁Course.': 1, '▁chapter': 1, '▁about': 1, '▁tokenization.': 1, '▁section': 1, '▁shows': 1, '▁several': 1, '▁tokenizer': 1, '▁algorithms.': 1, '▁Hopefully,': 1, '▁you': 1, '▁will': 1, '▁be': 1, '▁able': 1, '▁to': 1, '▁understand': 1, '▁how': 1, '▁they': 1, '▁are': 1, '▁trained': 1, '▁and': 1, '▁generate': 1, '▁tokens.': 1})Cuente todas las subpalabras del vocabulario y cuente la frecuencia de las palabras. Tome las primeras 300 palabras para formar el amplio vocabulario inicial. Para evitar OOV, es necesario reservar palabras a nivel de caracteres.
char2count = defaultdict(int)
sub_word2count = defaultdict(int)
for word, count in word2count.items():
for i in range(len(word)):
char2count[word[i]] += count
for j in range(i + 2, len(word) + 1):
sub_word2count[word[i:j]] += count
sorted_sub_words = sorted(sub_word2count.items(), key=lambda x: x[1], reverse=True)
# init a large vocab with 300
tokens = list(char2count.items()) + sorted_sub_words[: 300 - len(char2count)]El pequeño vocabulario inicial obtenido es el siguiente:
[('▁', 31), ('T', 3), ('h', 9), ('i', 13), ('s', 13), ..., ('several', 1)]Cuente más la probabilidad de cada subpalabra y conviértala en contribución de pérdida en Unigram
token2count = {token: count for token, count in tokens}
total_count = sum([count for token, count in token2count.items()])
model = {token: -log(count / total_count) for token, count in token2count.items()}model = {
'▁': 2.952892114877499,
'T': 5.288267030694535,
'h': 4.189654742026425,
...,
'sever': 6.386879319362645,
'severa': 6.386879319362645,
'several': 6.386879319362645
}Según la pérdida de cada subpalabra y el algoritmo de Viterbi, se puede obtener la ruta de segmentación de palabras óptima para una palabra de entrada. Es decir, la pérdida del modelo de lenguaje general es la más pequeña. La longitud de la palabra es N y la complejidad temporal de la decodificación es O (N ^ 2).
def _encode_word(word, model):
best_segmentations = [{"start": 0, "score": 1}] + [{"start": None, "score": None} for _ in range(len(word))]
for start_idx in range(len(word)):
# This should be properly filled by the previous steps of the loop
best_score_at_start = best_segmentations[start_idx]["score"]
for end_idx in range(start_idx + 1, len(word) + 1):
token = word[start_idx:end_idx]
if token in model and best_score_at_start is not None:
score = model[token] + best_score_at_start
# If we have found a better segmentation (lower score) ending at end_idx
if (
best_segmentations[end_idx]["score"] is None
or best_segmentations[end_idx]["score"] > score
):
best_segmentations[end_idx] = {"start": start_idx, "score": score}
segmentation = best_segmentations[-1]
if segmentation["score"] is None:
# We did not find a tokenization of the word -> unknown
return ["<unk>"], None
score = segmentation["score"]
start = segmentation["start"]
end = len(word)
tokens = []
while start != 0:
tokens.insert(0, word[start:end])
next_start = best_segmentations[start]["start"]
end = start
start = next_start
tokens.insert(0, word[start:end])
return tokens, scorePor ejemplo:
>>> tokenize("This")
>>> (['This'], 6.288267030694535)
>>> tokenize("this")
>>>(['t', 'his'], 10.03608902044192)Con base en las funciones anteriores, se puede obtener la ruta de segmentación de palabras y la pérdida de cualquier palabra. De esta forma se puede calcular la pérdida en todo el corpus.
def _compute_loss(self, model, word2count):
loss = 0
for word, freq in word2count.items():
_, word_loss = self._encode_word(word, model)
loss += freq * word_loss
return lossIntente eliminar una subpalabra en el modelo y calcule la pérdida del nuevo modelo en todo el corpus después de la eliminación, para obtener la puntuación de esta subpalabra, es decir, la cantidad de pérdida agregada al eliminar esta subpalabra.
def _compute_scores(self, model, word2count):
scores = {}
model_loss = self._compute_loss(model, word2count)
for token, score in model.items():
# We always keep tokens of length 1
if len(token) == 1:
continue
model_without_token = copy.deepcopy(model)
_ = model_without_token.pop(token)
scores[token] = self._compute_loss(model_without_token, word2count) - model_loss
return scores
scores = self._compute_scores(model, word2count)Para mejorar la eficiencia de la iteración, el 10% superior de los resultados se elimina en lotes, es decir, el 10% superior de las palabras que hacen que el incremento de pérdida general sea el más pequeño. (Eliminar estas palabras tiene poco efecto en la pérdida general).
sorted_scores = sorted(scores.items(), key=lambda x: x[1])
# Remove percent_to_remove tokens with the lowest scores.
for i in range(int(len(model) * 0.1)):
_ = token2count.pop(sorted_scores[i][0])Después de obtener un nuevo vocabulario, vuelva a calcular la probabilidad de cada palabra para obtener un nuevo modelo. Y repita los pasos anteriores hasta que el tamaño del vocabulario cumpla con el requisito.
while len(model) > vocab_size:
scores = self._compute_scores(model, word2count)
sorted_scores = sorted(scores.items(), key=lambda x: x[1])
# Remove percent_to_remove tokens with the lowest scores.
for i in range(int(len(model) * percent_to_remove)):
_ = token2count.pop(sorted_scores[i][0])
total_count = sum([freq for token, freq in token2count.items()])
model = {token: -log(count / total_count) for token, count in token2count.items()}Suponiendo que el tamaño del vocabulario preestablecido es 100, después de las iteraciones anteriores obtenemos el siguiente vocabulario:
model = {
'▁': 2.318585434340487,
'T': 4.653960350157523,
'h': 3.5553480614894135,
'i': 3.1876232813640963,
...
'seve': 5.752572638825633,
'sever': 5.752572638825633,
'severa': 5.752572638825633,
'several': 5.752572638825633
}5.2 Fase de inferencia
En la fase de razonamiento, dada una oración, es necesario dividirla en una secuencia de fichas. En términos de implementación específica, primero se segmenta previamente la oración y luego se decodifica cada palabra según el algoritmo de Viterbi.
def tokenize(self, text):
words = [word for word, _ in self.pre_tokenize_str(text)]
encoded_words = [self._encode_word(word, self.model)[0] for word in words]
return sum(encoded_words, [])Por ejemplo
>>> tokenize("This is the Hugging Face course!")
>>> ['▁This', '▁is', '▁the', '▁Hugging', '▁Face', '▁', 'c', 'ou', 'r', 's', 'e', '.']La segmentación basada en Viterbi es la mejor segmentación: basada en unigrama, se pueden realizar múltiples métodos de segmentación de una oración y se puede obtener la puntuación de cada ruta de segmentación.
6. Pieza de oración
SentencePieza es una herramienta de segmentación de palabras de Google:
Métodos de segmentación de palabras integrados para BPE, Unigram, char y word
Sin segmentación previa, la oración completa se codifica directamente en Unicode y los espacios se codificarán especialmente como
Optimizada en comparación con las implementaciones tradicionales, la velocidad de segmentación de palabras es más rápida
Los grandes modelos actuales se implementan en función de fragmentos de oraciones, como el tokenizador de ChatGLM.
...
class TextTokenizer:
def __init__(self, model_path):
self.sp = spm.SentencePieceProcessor()
self.sp.Load(model_path)
self.num_tokens = self.sp.vocab_size()
def encode(self, text):
return self.sp.EncodeAsIds(text)
def decode(self, ids: List[int]):
return self.sp.DecodeIds(ids)
...https://huggingface.co/THUDM/chatglm-6b/blob/main/tokenization_chatglm.py#L21
6.1 reserva de bytes
Cuando SentencePiece se activa durante el entrenamiento BPE --byte_fallback, el efecto es similar a BBPE. Cuando se encuentre con UNK, continuará segmentándose aún más según el byte. Ver: https://github.com/google/sentencepiece/issues/621 La implementación específica es agregar 256 tokens <0x00>... <0xFF> al vocabulario.
Al analizar el modelo ChatGLM, se puede encontrar que ChatGLM está activado--byte_fallback
from sentencepiece import sentencepiece_model_pb2
m = sentencepiece_model_pb2.ModelProto()
with open('chatglm-6b/ice_text.model', 'rb') as f:
m.ParseFromString(f.read())
print('ChatGLM tokenizer\n\n'+str(m.trainer_spec))producción:
ChatGLM tokenizer
input: "/root/train_cn_en.json"
model_prefix: "new_ice_unigram"
vocab_size: 130000
character_coverage: 0.9998999834060669
split_digits: true
user_defined_symbols: "<n>"
byte_fallback: true
pad_id: 3
train_extremely_large_corpus: truepuede ser vistobyte_fallback: true
De la misma manera, se puede verificar que los modelos grandes como LLaMA, ChatGLM-6B y Baichuan se basan en el algoritmo de segmentación de palabras BPE implementado por pieza de oración y adoptan un respaldo de bytes.
Ingrese al grupo de PNL -> únase al grupo de intercambio de PNL
referencia
Tutorial del tokenizador de HuggingFace : https://huggingface.co/learn/nlp-course/chapter6/1)
google/sentencepiece : https://github.com/google/sentencepiece/
BPE: traducción automática neuronal de palabras raras con unidades de subpalabras : https://arxiv.org/abs/1508.07909
BBPE: traducción automática neuronal con subpalabras a nivel de bytes : https://arxiv.org/pdf/1909.03341.pdf
Unigram: Regularización de subpalabras: mejora de los modelos de traducción de redes neuronales con múltiples subpalabras candidatas : https://arxiv.org/abs/1804.10959
SentencePiece : un tokenizador y detokenizador de subpalabras simple e independiente del lenguaje para el procesamiento de texto neuronal: https://arxiv.org/abs/1808.06226