Tabla de contenido
1. Primer trasplante de uboot (todo lo relacionado con uboot es para iniciar el kernel).
2. ¿Cuál es la función de uboot?
3. Explicación detallada de la función de uboot.
Segundo, trasplantar el kernel de Linux
1. ¿Qué es el kernel de Linux?
2. ¿Qué hay en el kernel de Linux?
3. Recompilar y trasplantar el archivo del árbol de dispositivos.
1. ¿Qué es el archivo del árbol de dispositivos?
2. ¿Qué son los archivos del árbol de dispositivos?
3. Introducción a la sintaxis del archivo fuente del árbol de dispositivos (.dts)
4. Árbol de dispositivos de función
Cuarto, finalmente trasplantar el sistema de archivos raíz (rootfs)
1. ¿Qué es el sistema de archivos raíz?
2. ¿Por qué es tan importante el sistema de archivos raíz?
3. Directorios comunes del sistema de archivos Linux.
1. Primer trasplante de uboot (todo lo relacionado con uboot es para iniciar el kernel).
1. ¿Qué es el arranque?
Uboot es una especie de gestor de arranque , que se utiliza para arrancar e iniciar el kernel. Su objetivo final es leer el kernel desde la memoria flash, colocarlo en la memoria e iniciar el kernel. Por lo tanto, UBOOT debe tener la capacidad de leer y escribir flash.
2. ¿Cuál es la función de uboot?
1) La función principal de uboot es iniciar el kernel del sistema operativo . Se refleja en el último código de uboot para iniciar el kernel.
2) uboot también es responsable de implementar todo el sistema informático. Se refleja en el último parámetro pasado de uboot.
3) En uboot, también hay controladores para operar hardware en placas como Flash. Por ejemplo, es necesario imprimir el puerto serie, si la red de ping fue exitosa, si el borrado y la programación del flash fueron exitosos, etc.
4) uboot tiene que proporcionar una interfaz de línea de comando para que la gente pueda operar. Por ejemplo: interfaz de línea de comandos del terminal Linux.
Por ejemplo: sistema Windows de la computadora.
Los principales componentes centrales que todos los sistemas informáticos necesitan para ejecutar son 3 cosas: CPU + memoria externa (Flash/disco duro) + memoria interna (DDR SDRAM/SDRAM/SRAM). El proceso general de inicio de la PC es: después de encender la PC, primero se ejecuta el programa BIOS (de hecho, el BIOS de la PC es NorFlash), el programa BIOS es responsable de inicializar la memoria DDR y el disco duro, y luego lee la imagen del sistema operativo desde el disco duro al DDR y luego salta a DDR para ejecutar el sistema operativo hasta que se inicia (el BIOS es inútil después de que se inicia el sistema operativo).
Entonces: el proceso de inicio del sistema integrado es casi el mismo que el de la PC, excepto que el BIOS se vuelve uboot y el disco duro se convierte en Flash.
3. Explicación detallada de la función de uboot.
Se puede iniciar directamente por sí mismo.
1) El SoC general admite múltiples métodos de arranque, como arranque con tarjeta SD, arranque NorFlash, arranque NandFlash, etc. ••••• Para permitir que uboot arranque, uboot debe diseñarse de acuerdo con el diseño de arranque de SoC específico.
2) uboot debe cambiarse y trasplantarse en el nivel de código correspondiente al hardware para garantizar que se pueda iniciar desde el medio de inicio correspondiente. Esta parte se trata específicamente en el archivo start.S de la primera etapa de uboot.
Capaz de iniciar el kernel del sistema operativo y pasar parámetros al kernel.
1) El objetivo final de uboot es iniciar el kernel.
2) Cuando se diseña el kernel de Linux, está diseñado para poder pasarse como parámetros . Es decir, podemos preparar algunos parámetros de inicio para el kernel de Linux en uboot, colocarlos en una ubicación específica en la memoria y pasarlos al kernel. Después de que se inicie el kernel, irá a esta ubicación específica para buscar los parámetros. uboot le pasa y luego los analiza en los parámetros del kernel, estos parámetros se utilizarán para guiar el proceso de arranque del kernel de Linux.
Puede proporcionar la función de implementación del sistema
1) Las personas deben poder utilizar uboot para completar la grabación y descarga de todo el sistema (incluido uboot, kernel, rootfs, etc.) en Flash.
2) Flashear en el tutorial de bare metal (la tercera parte de ARM bare metal) es usar la función fastboot en uboot para grabar varias imágenes en iNand y luego comenzar desde iNand.
Capaz de gestión de hardware a nivel de SoC y a nivel de placa
1) uboot se da cuenta de la capacidad de control de algún hardware (una parte del hardware se inicializa en uboot), porque uboot debe hacer que este hardware funcione para completar algunas tareas. Por ejemplo, uboot debe poder controlar iN y para implementar el flasheo. Por ejemplo, uboot debe poder controlar la pantalla LCD si quiere mostrar una barra de progreso en la pantalla LCD cuando parpadea. Por ejemplo, uboot debe controlar el puerto serie para proporcionar una operación interfaz a través del puerto serie. Por ejemplo, si uboot quiere realizar la función de red, debe controlar el chip de la tarjeta de red.
2) El nivel de SoC (como el puerto serie) son los periféricos internos del SoC, y el nivel de placa es el hardware en la placa de desarrollo fuera del SoC (como la tarjeta de red, iNand)
El "ciclo de vida" de uboot
1) El ciclo de vida de uboot se refiere a cuándo comienza a ejecutarse y cuándo finaliza.
2) uboot es esencialmente un programa básico (no un sistema operativo). Una vez que se inicia uboot, el SoC simplemente ejecutará uboot (lo que significa que otros programas no pueden ejecutarse al mismo tiempo cuando se ejecuta uboot). Una vez que uboot termina de ejecutarse, no puede volver a uboot (por lo que uboot en sí está muerto después de que uboot inicia el kernel, si desea volver a ver la interfaz de uboot, solo puede reiniciar el sistema. Reiniciar no revive el uboot en este momento, reiniciar es solo otra vida de arrancar)
3) La entrada y salida de uboot. La entrada de uboot es iniciarse automáticamente al arrancar, y la única salida de uboot es iniciar el kernel. Uboot también puede realizar muchas otras tareas (como grabar el sistema), pero después de ejecutar otras tareas, puede regresar a la línea de comando de uboot para continuar ejecutando el comando uboot, y una vez que se ejecuta el comando de arranque del kernel, no puede regresar.
4. Cómo funciona uboot
A partir de la imagen del programa básico uboot.bin
1) La esencia de uboot es un programa bare-metal , que no es fundamentalmente diferente del programa bare-metal xx.bin escrito en nuestra colección bare-metal. Si hay una diferencia, es: la mayor parte de lo que escribimos tiene menos de 16 KB, mientras que uboot tiene más de 16 KB (generalmente uboot está entre 180k-400k)
2) Uboot en sí es un proyecto de código abierto, que consta de varios archivos .c y .h. Después de la configuración y compilación, se generará un uboot.bin, que es el archivo de imagen del programa básico uboot. Luego, este archivo de imagen se graba correctamente en el medio de arranque y se entrega al SoC para que lo inicie. Es decir, uboot se comporta como uboot.bin cuando no se está ejecutando y generalmente se encuentra en el medio de arranque.
3) Cuando uboot se esté ejecutando, se cargará en la memoria y luego se entregará a la CPU para que ejecute una instrucción a la vez.
La imperativa interfaz de shell de Uboot
1) Los programas básicos ordinarios se ejecutan directamente cuando se ejecutan y el efecto de ejecución está relacionado con el código.
2) Algunos programas necesitan interactuar con personas, por lo que se implementa un shell en el programa (el shell es una interfaz que proporciona interacción persona-computadora, recuerde la decimosexta parte de ARM Bare Metal Complete Works), y uboot implementa un shell.
Nota: El shell no es un sistema operativo y no tiene nada que ver con el sistema operativo. Después de abrir una terminal en Linux, obtiene un shell y puede ingresar un comando y presionar Enter para ejecutarlo. El modo de funcionamiento del shell en uboot es muy similar al del shell del terminal en Linux (de hecho, es casi el mismo, pero el conjunto de comandos es diferente. Por ejemplo, ls se puede usar en Linux, pero ls en uboot no lo reconoce).
Domine los dos puntos clave del uso de uboot: comandos y variables de entorno
1) Después de iniciar uboot, la mayor parte del tiempo y el trabajo se realizan bajo el shell (por ejemplo, si uboot quiere implementar el sistema, necesita ingresar comandos bajo el shell, para configurar las variables de entorno también debe estar bajo la línea de comando , y para iniciar el kernel también debe estar bajo la línea de comando knock comando).
2) Los comandos son varios comandos que se pueden reconocer en el shell uboot. Hay docenas de comandos en uboot, algunos de los cuales se usan comúnmente y otros no (también podemos agregar comandos a uboot nosotros mismos), y usaremos algo de tiempo de clase para aprender los comandos comúnmente utilizados en uboot. .
3) Los principios y métodos de funcionamiento de las variables de entorno de uboot y las variables de entorno del sistema operativo son casi idénticos. Uboot está diseñado con la ayuda del concepto de diseño del sistema operativo (el método de trabajo de la línea de comandos toma prestado de la línea de comando del terminal de Linux, las variables de entorno toman prestado de las variables de entorno del sistema operativo y la administración del controlador de uboot copia casi por completo el marco del controlador de Linux).
4) La variable de entorno puede considerarse como la variable global del sistema y el nombre de la variable de entorno está integrado en el sistema (si lo sabe, lo sabe, si no lo sabe, no lo sabe). , esta parte es la variable de entorno predeterminada que viene con el sistema, como PATH; pero también hay algunas variables de entorno que agregamos nosotros mismos y los sistemas que agregamos nosotros mismos no lo saben, pero nosotros mismos lo sabemos). El sistema o nuestro propio programa pueden guiar el funcionamiento del programa leyendo las variables de entorno en tiempo de ejecución. La ventaja de este diseño es la flexibilidad. Por ejemplo, si queremos cambiar el método de ejecución de un programa, no necesitamos volver a modificar el código del programa y luego volver a compilarlo y ejecutarlo, solo necesitamos modificar las variables de entorno correspondientes. .
5) La variable de entorno es la propiedad de configuración en tiempo de ejecución.
Segundo, trasplantar el kernel de Linux
1. ¿Qué es el kernel de Linux?
El kernel de Linux es el nivel más bajo de software fácilmente reemplazable que interactúa con el hardware de una computadora; el kernel es responsable de conectar todas las aplicaciones que se ejecutan en "modo usuario" al hardware físico y permite que los procesos obtengan información entre sí mediante la comunicación entre procesos. .
Con más de 13 millones de líneas de código, el kernel de Linux es uno de los proyectos de código abierto más grandes del mundo.
2. ¿Qué hay en el kernel de Linux?
El kernel de Linux se compone principalmente de gestión de procesos , gestión de memoria , controladores de dispositivos , sistemas de archivos , pilas de protocolos de red y llamadas al sistema .
organización del código fuente

3. Recompilar y trasplantar el archivo del árbol de dispositivos.
1. ¿Qué es el archivo del árbol de dispositivos?
La esencia del árbol de dispositivos también es operar el registro, pero la información relevante del registro se coloca en el árbol de dispositivos. Al configurar el registro, debe usar la función OF para leer los datos del registro del árbol de dispositivos y luego configurarlo.
Antes de Linux 3.x, no había árbol de dispositivos. Linux describía la información a nivel de placa en la arquitectura ARM a través de los archivos de descripción a nivel de placa en las carpetas arch/arm/mach-xxx y arch/arm/plat-xxx en el código fuente del núcleo. A medida que aumentan los tipos de hardware ARM, hay cada vez más archivos de dispositivo relacionados con la placa, lo que da como resultado un kernel cada vez más grande. De hecho, esta información a nivel de placa de hardware no tiene nada que ver con el kernel.
En 2011, después de que Linus descubriera el problema, introdujo el mecanismo de árbol de dispositivos ya adoptado por PowerPC y otras arquitecturas, separó la información a nivel de placa del núcleo y la describió en un formato de archivo dedicado (archivo .dts). La función del árbol de dispositivos es describir los recursos de hardware de la plataforma de hardware, que el cargador de arranque puede pasar al kernel, y el kernel puede obtener información de hardware del árbol de dispositivos. El árbol de dispositivos tiene dos características al describir los recursos de hardware:
- Describir los recursos de hardware en una estructura de árbol.
- Al igual que un archivo de encabezado, un archivo de árbol de dispositivos puede hacer referencia a otro archivo de árbol de dispositivos para lograr la reutilización del código.
2. ¿Qué son los archivos del árbol de dispositivos?
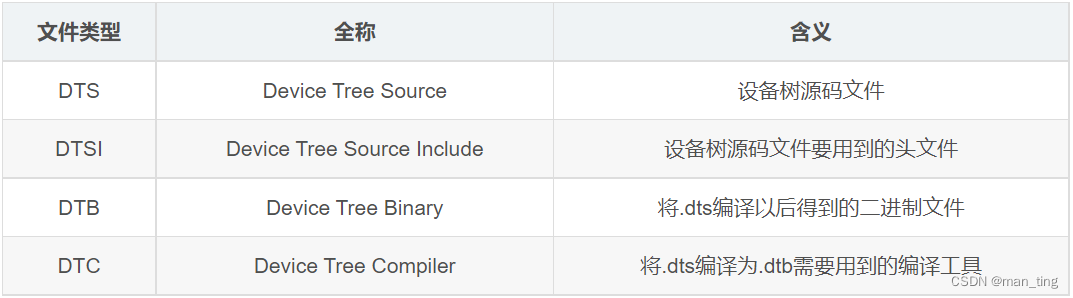
Hay cuatro tipos de archivos de árbol de dispositivos, como: archivos DTS, DTSI, DTB, DTC
El código fuente de la herramienta DTC se encuentra en el archivo scripts/dtc/Makefile del kernel de Linux:
hostprogs-y:= dtc
always:= $(hostprogs-y)
dtc-objs:= dtc.o flattree.o fstree.o data.o livetree.o treesource.o srcpos.o checks.o util.o
dtc-objs+= dtc-lexer.lex.o dtc-parser.tab.o
......De lo anterior se puede ver que la herramienta DTC depende de dtc.c, flattree.c, fstree.c y otros archivos, y finalmente compila y vincula el archivo host DTC. Para compilar un archivo DTS, solo necesita ingresar el directorio raíz del código fuente de Linux y luego ejecutar el siguiente comando:
make all #编译Linux源码中的所有东西,包括zImage、.ko驱动模块以及设备树
make dtbs #只是编译设备树Hay muchos SOC basados en la arquitectura ARM, y un SOC puede producir múltiples placas, cada placa tiene un archivo DTS correspondiente, entonces, ¿cómo determinar qué archivo DTS compilar? Tome la placa del chip I.MX6ULL como ejemplo, abra arch/arm/boot/dts/Makefile, encontrará el siguiente contenido:
dtb-$(CONFIG_SOC_IMX6UL) += \
imx6ul-14x14-ddr3-arm2.dtb \
imx6ul-14x14-ddr3-arm2-emmc.dtb \
......
dtb-$(CONFIG_SOC_IMX6ULL) += \
imx6ull-14x14-ddr3-arm2.dtb \
imx6ull-14x14-ddr3-arm2-adc.dtb \
......Después de seleccionar I.MX6ULL (es decir, CONFIG_SOC_IMX6ULL=y), todos los archivos .dts correspondientes a las placas que utilizan este SOC se compilarán en .dtb. Si crea una nueva placa, solo necesita crear un archivo .dts correspondiente y luego agregar el nombre del archivo .dtb correspondiente a dtb-$ (CONFIG_SOC_IMX6ULL), de modo que los .dts correspondientes se compilen en binario al compilar el dispositivo. archivo .dtb del árbol
3. Introducción a la sintaxis del archivo fuente del árbol de dispositivos (.dts)
El árbol de dispositivos utiliza una estructura de árbol para describir la información del dispositivo en la placa. Cada dispositivo es un nodo, llamado nodo de dispositivo. Cada nodo describe la información del nodo a través de alguna información de atributo. El atributo es un par clave-valor
node-name@unit-address{
属性1 = ...
属性2 = ...
子节点...
}
⏩ Nombre de nodo: nombre-nodo se utiliza para especificar el nombre del nodo, que debe comenzar con una letra y describir la categoría del dispositivo (el nodo raíz está representado por una barra diagonal).
⏩ Dirección de unidad: @ dirección de unidad se usa para especificar la dirección de unidad, @ es el separador, seguido de la dirección de unidad real, su valor es consistente con la primera dirección del atributo de registro del nodo, si no hay un valor de atributo de registro, la unidad se puede omitir dirección
⏩ Atributos del nodo: el contenido entre llaves { } del nodo son los atributos del nodo. Un nodo puede contener información de atributos múltiples. El contenido principal del árbol de dispositivos es escribir los atributos de los nodos. Los atributos incluyen atributos personalizados y atributos estándar.
atributo de modelo: se utiliza para especificar el fabricante y modelo del dispositivo, varias cadenas están separadas por ","
atributo compatible: compuesto por una o más cadenas, es uno de los métodos utilizados para encontrar
el estado de los nodos atributo: usado Indica el estado de funcionamiento de el dispositivo, y el dispositivo se puede deshabilitar o habilitar a través del
atributo status reg: describe la dirección del recurso del dispositivo en el espacio de direcciones definido por su bus principal, generalmente usado para indicar la dirección inicial y la longitud de un registro #address-
cells y #size -cells: estos dos atributos existen al mismo tiempo: el primero determina la longitud de la palabra ocupada por la información de dirección en el atributo de registro del subnodo, y el segundo determina la longitud de la palabra ocupada por la información de longitud., dirección principal y espacio de
direcciones La longitud se compone de tres partes
: dirección del bus secundario: la dirección física del espacio de direcciones del bus secundario, y la longitud de la palabra ocupada por esta dirección física está determinada por #celdas de dirección del nodo principal: dirección del bus principal
: La dirección física del espacio de direcciones del bus principal también está determinada por las #celdas de dirección del nodo principal
.
4. Árbol de dispositivos de función
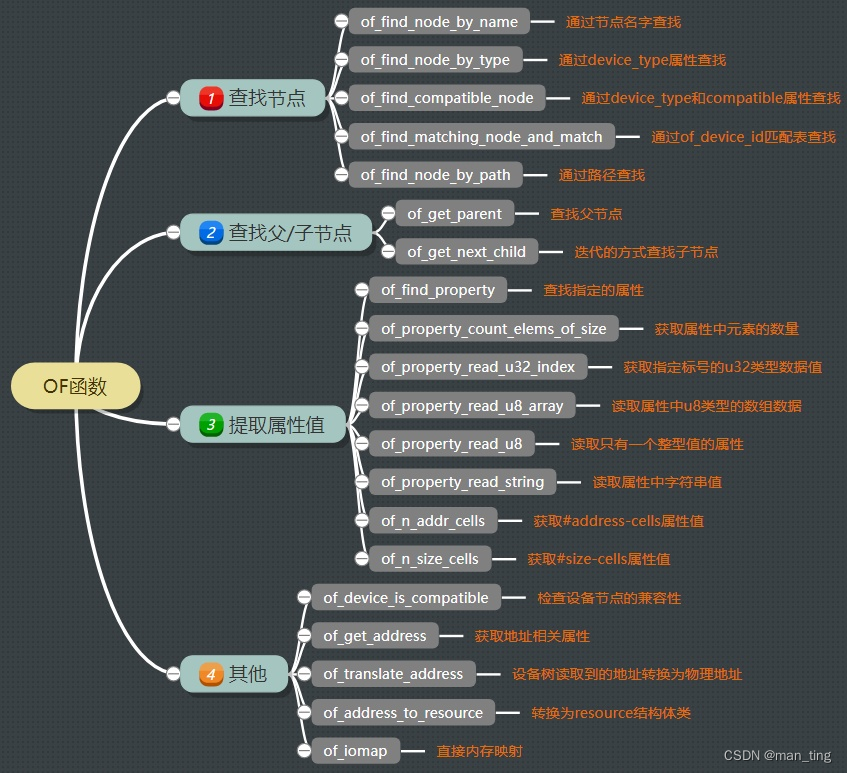
El kernel proporciona una serie de funciones para obtener los atributos definidos en el nodo del nodo del dispositivo, estas funciones comienzan con of_ y se denominan funciones OF. Al escribir el controlador de la versión del árbol de dispositivos, en términos de configuración de hardware, es necesario utilizar estas funciones OF para obtener información como direcciones de registro del archivo del árbol de dispositivos y luego configurar
Cuarto, finalmente trasplantar el sistema de archivos raíz (rootfs)
1. ¿Qué es el sistema de archivos raíz?
El sistema de archivos raíz es ante todo un sistema de archivos. Este sistema de archivos no solo tiene la función de almacenar archivos de datos del sistema de archivos ordinario, sino que, en comparación con el sistema de archivos ordinario, es especial porque se monta cuando se inicia el kernel. (mount), el archivo de imagen del código del kernel se almacena en el sistema de archivos raíz y el programa de arranque del sistema cargará algunos scripts de inicialización (como rcS, inittab) y servicios en la memoria después de montar el sistema de archivos raíz. . Necesitamos entender que el sistema de archivos y el kernel son dos partes completamente independientes. El kernel trasplantado en el sistema integrado se descarga a la placa de desarrollo, no hay forma de iniciar realmente el sistema operativo Linux y habrá un error que indica que no se puede cargar el sistema de archivos.
2. ¿Por qué es tan importante el sistema de archivos raíz?
El sistema de archivos raíz contiene directorios y archivos críticos necesarios para el inicio del sistema, así como archivos necesarios para montar otros sistemas de archivos. Por ejemplo:
El programa de aplicación del proceso de inicio debe ejecutarse en el sistema de archivos raíz;
el sistema de archivos raíz proporciona el directorio raíz "/";
la información en la que Linux se basa al montar la partición se almacena en el archivo /etc/fstab del sistema de archivos raíz; el
programa de comando de shell debe ejecutarse en el sistema de archivos raíz, como ls, cd y otros comandos;
en resumen: un conjunto de sistemas Linux, solo el kernel en sí no puede funcionar, debe ser rootfs (archivos de configuración en el directorio etc en rootfs , /bin/sbin y otros directorios), los comandos de Shell y los archivos de biblioteca en el directorio /lib, etc.) solo pueden funcionar juntos.
Cuando se inicia Linux, lo primero que se debe montar es el sistema de archivos raíz; si el sistema no puede montar el sistema de archivos raíz desde el dispositivo especificado, el sistema cometerá un error y saldrá del inicio. Después del éxito, se pueden montar otros sistemas de archivos de forma automática o manual. Por lo tanto, pueden existir diferentes sistemas de archivos en un sistema al mismo tiempo. El proceso de asociar un sistema de archivos con un dispositivo de almacenamiento en Linux se llama montaje. Utilice el comando de montaje para adjuntar un sistema de archivos a la jerarquía del sistema de archivos actual (raíz). Al realizar un montaje, proporcione el tipo de sistema de archivos, el sistema de archivos y un punto de montaje. Después de montar el sistema de archivos raíz en "/" en el directorio raíz, hay varios directorios del sistema de archivos raíz en el directorio raíz, archivos: /bin /sbin /mnt, etc., y luego se montan otras particiones en el Directorio /mnt. Hay varios directorios y archivos de esta partición en el directorio /mnt.
El sistema de archivos raíz incluye al menos los siguientes directorios:
/etc/: almacena archivos de configuración importantes.
/bin/: almacena archivos ejecutables de uso frecuente que deben usarse al iniciar.
/sbin/: almacena los archivos de ejecución del sistema necesarios durante el proceso de arranque.
/lib/: almacena la biblioteca de enlaces necesaria para los archivos de ejecución de /bin/ y /sbin/, así como el módulo del kernel de Linux.
/dev/: Archivos del dispositivo de almacenamiento.
Nota: Los cinco directorios principales deben almacenarse en el sistema de archivos raíz y no se puede prescindir de ninguno de ellos.
3. Directorios comunes del sistema de archivos Linux.
Generalmente existen los siguientes directorios en el sistema de archivos de Linux:
Directorio /bin
Este directorio almacena comandos básicos que todos los usuarios pueden usar. Estos comandos se pueden usar antes de que se monten otros sistemas de archivos, por lo que el directorio /bin debe estar en la misma partición que el sistema de archivos raíz.
Los comandos comúnmente utilizados en el directorio /bin son: cat, chgrp, chmod, cp, ls, sh, kill, mount, umount, mkdir, mknod, test, etc. Cuando usemos Busybox para crear el sistema de archivos raíz, Créelo en el directorio bin, puede ver algunos archivos ejecutables, es decir, algunos comandos disponibles.
Directorio /sbin
Este directorio almacena comandos del sistema, es decir, comandos que solo los administradores pueden usar. Los comandos del sistema también se pueden almacenar en los directorios /usr/sbin, /usr/local/sbin, y el directorio /sbin almacena comandos básicos del sistema. se utilizan para iniciar el sistema, reparar el sistema, etc. De manera similar al directorio /bin, /sbin se puede usar antes de montar otros sistemas de archivos, por lo que el directorio /sbin debe estar en la misma partición que el sistema de archivos raíz.
Los comandos comúnmente utilizados en el directorio /sbin incluyen: apagar, reiniciar, fdisk, fsck, etc. Los comandos del sistema instalados por los usuarios locales se colocan en el directorio /usr/local/sbin.
El directorio /dev
almacena archivos de dispositivo en este directorio. Los archivos de dispositivo son un tipo de archivo único en Linux. En el sistema Linux, el acceso a varios dispositivos en forma de archivos, es decir, opera un hardware específico leyendo y escribiendo un archivo de dispositivo. . Por ejemplo, el puerto serie 0 se puede operar a través del archivo "dev/ttySAC0" y se puede acceder a la segunda partición del dispositivo MTD a través de "/dev/mtdblock1".
Directorio /etc
Este directorio almacena varios archivos de configuración. Para el sistema Linux en la PC, hay muchos archivos y directorios en el directorio /etc. Estos archivos de directorio son opcionales y dependen de las aplicaciones en el sistema. Depende de si estas Los programas requieren archivos de configuración. En sistemas integrados, estos contenidos se pueden reducir considerablemente.
El directorio /lib
almacena bibliotecas compartidas y cargables (programas de controlador) en este directorio, y la biblioteca compartida se utiliza para iniciar el sistema. Ejecute programas ejecutables en el sistema de archivos raíz, como programas en el directorio /bin /sbin.
El directorio /home
es el directorio de usuarios, que es opcional. Para cada usuario normal, hay un subdirectorio con el nombre del usuario en el directorio /home, que almacena archivos de configuración relacionados con el usuario.
El directorio /root
es el directorio del usuario root y, en consecuencia, el directorio de usuarios normales es un subdirectorio en /home.
El contenido del directorio /usr
se puede almacenar en otra partición y luego montarse en el directorio /usr en el sistema de archivos raíz después de que se inicia el sistema. Almacena programas y datos compartidos de solo lectura, lo que significa que el contenido del directorio /usr se puede compartir entre múltiples hosts, y estos cumplen principalmente con el estándar FHS. Los archivos en /usr deben ser de solo lectura y otros archivos variables y relacionados con el host deben almacenarse en otros directorios, como /var. El directorio /usr se puede reducir en incrustado.
El directorio /var
es lo opuesto al directorio /usr. El directorio /var almacena datos variables, como el directorio de spool (correo, noticias), archivos de registro y archivos temporales.
El directorio /proc
es un directorio vacío, a menudo utilizado como punto de montaje del sistema de archivos proc. El sistema de archivos proc es un sistema de archivos virtual. No tiene ningún dispositivo de almacenamiento real. Los directorios y archivos que contiene son generados temporalmente por el kernel. para representar El estado operativo del sistema y el sistema de control de archivos que contiene también se puede operar.
El directorio /mnt
se utiliza para montar temporalmente el punto de montaje de un determinado sistema de archivos. Generalmente es un directorio vacío y también puede crear un subdirectorio vacío en él, como /mnt/cdram /mnt/hda1. Se utiliza para montar temporalmente CD y discos duros.
El directorio /tmp
se usa para almacenar archivos temporales, generalmente un directorio vacío, bajo el directorio /tmp usado por algunos programas que necesitan generar archivos temporales, por lo que el directorio /tmp debe existir y ser accesible.