Los modelos semánticos latentes, como LSA, pretenden asignar una consulta a sus documentos relevantes en el nivel semántico donde la concordancia basada en palabras clave a menudo falla. En este estudio nos esforzamos por desarrollar una serie de nuevos modelos semánticos latentes con una estructura profunda que proyecten consultas y documentos en un espacio común de baja dimensión donde la relevancia de un documento dada una consulta se calcula fácilmente como la distancia entre ellos. Los modelos semánticos estructurados profundos propuestos se entrenan de manera discriminativa maximizando la probabilidad condicional de que los documentos en los que se hace clic reciban una consulta utilizando los datos de clic. Para que nuestros modelos sean aplicables a aplicaciones de búsqueda web a gran escala, también utilizamos una técnica llamada hash de palabras, que ha demostrado escalar eficazmente nuestros modelos semánticos para manejar vocabularios extensos que son comunes en este tipo de tareas. Los nuevos modelos se evalúan en una tarea de clasificación de documentos web utilizando un conjunto de datos del mundo real. Los resultados muestran que nuestro mejor modelo supera significativamente a otros modelos semánticos latentes, que se consideraban de última generación en el desempeño anterior al trabajo presentado en este artículo.
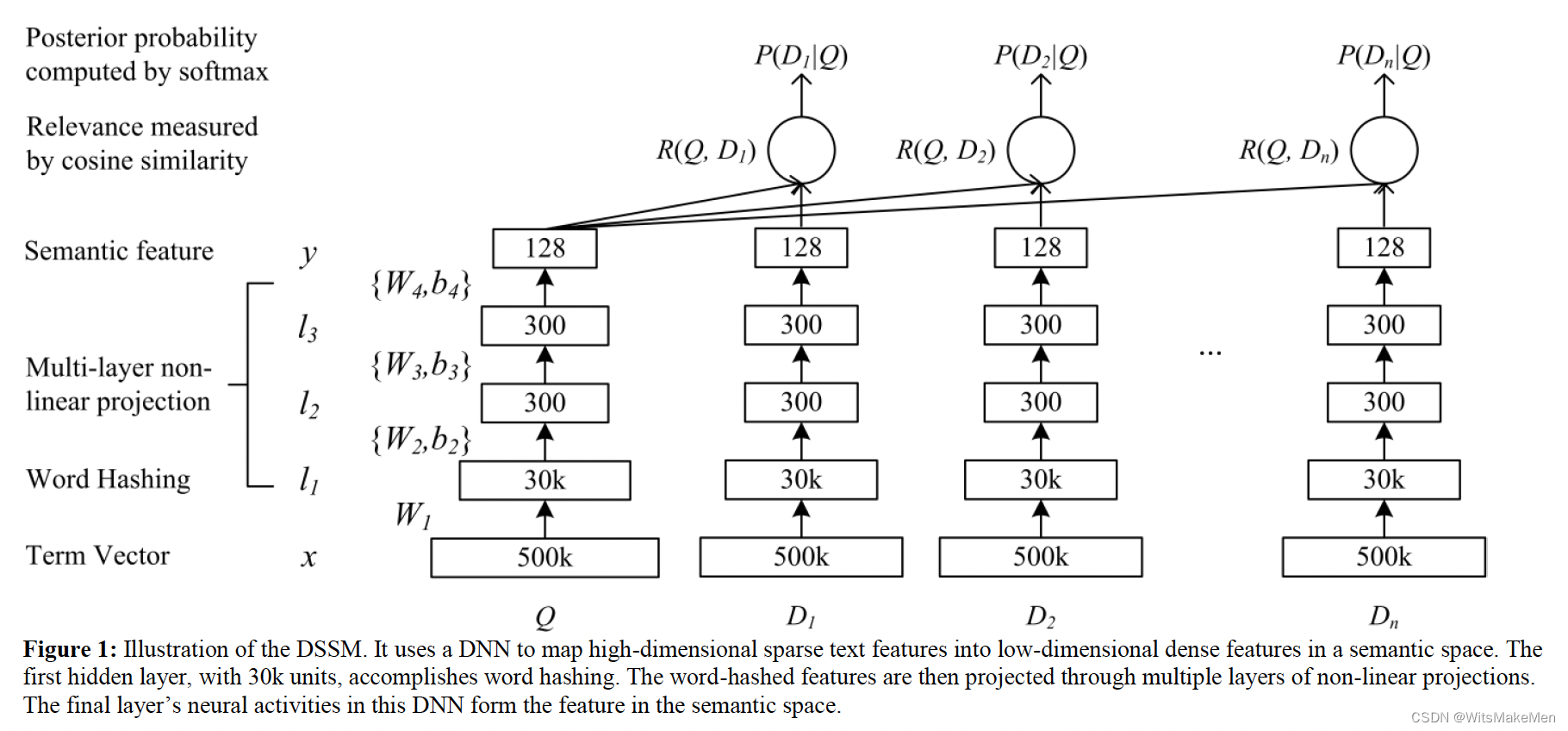

La similitud del coseno se utiliza más para calcular la relación entre consulta y documento.
Para una consulta, se toman muestras negativas mediante muestreo negativo y luego se calcula la probabilidad de muestras positivas.

