您好,我是路人,更多优质文章见个人博客:http://itsoku.comEsta pregunta ya es un cliché y se suele utilizar como pregunta final de la entrevista. También hay muchos artículos en Internet, pero recientemente me aburrí y luego tomé nota yo solo y siento que entiendo. más a fondo que antes.
Nota: Los pasos de este artículo se basan en el hecho de que la solicitud es una solicitud HTTP simple, sin HTTPS, HTTP2, el DNS más simple, sin proxy y el servidor no tiene problemas, aunque esto no es práctico.
flujo general
análisis de URL
consulta DNS
conexión TCP
solicitud de proceso
aceptar respuesta
renderizar página
1. Análisis de URL
Resolución de dirección:
En primer lugar, juzga si lo que ingresa es una URL legal o una palabra clave para buscar, y realiza operaciones como el autocompletado y la codificación de caracteres de acuerdo con el contenido que ingresa.
HSTS
Debido a implicaciones de seguridad, HSTS se utiliza para obligar a los clientes a utilizar HTTPS para acceder a las páginas.
otras operaciones
El navegador también realizará algunas operaciones adicionales, como controles de seguridad y restricciones de acceso (anteriormente, los navegadores nacionales restringían 996.icu).
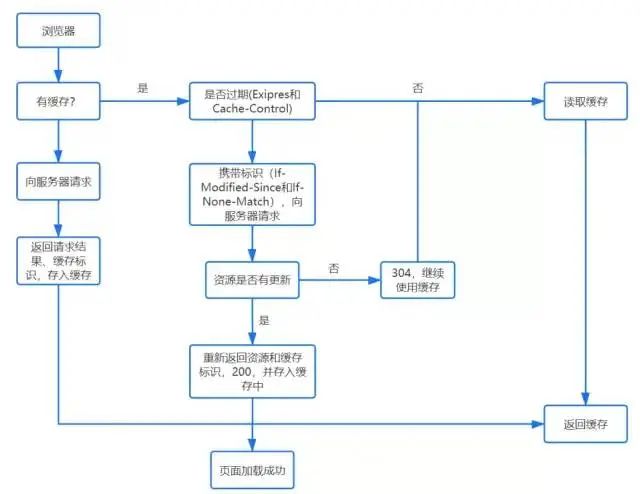
comprobar caché
2. consulta DNS
Los pasos básicos

1. Caché del navegador
El navegador primero verificará si está en el caché y, de lo contrario, llamará a la función de biblioteca del sistema para realizar la consulta.
2. Caché del sistema operativo
El sistema operativo también tiene su propia caché DNS, pero antes de eso, verificará si el nombre de dominio existe en el archivo Hosts local y, si no, enviará una solicitud de consulta al servidor DNS.
3. Caché del enrutador
Los enrutadores también tienen sus propios cachés.
4. Almacenamiento en caché de DNS del ISP
El DNS del ISP es el servidor DNS preferido configurado en la computadora cliente, que en la mayoría de los casos tendrá un caché.
Búsqueda del servidor de nombres raíz
En el caso de que no se almacenen en caché todos los pasos anteriores, el servidor DNS local reenviará la solicitud al dominio raíz en Internet. La siguiente figura ilustra bien todo el proceso:

Servidores de nombres raíz (Wikipedia)
Puntos a tener en cuenta
Método recursivo: verifique hasta el final sin regresar en el medio y solo devuelva información cuando se obtenga el resultado final (el proceso desde el navegador hasta el servidor DNS local)
El método iterativo es el método de consultar desde el servidor DNS local al servidor de nombres de dominio raíz.
¿Qué es el secuestro de DNS?
Optimización de captación previa de DNS frontal
3. Conexión TCP
TCP/IP se divide en cuatro capas. Al enviar datos, cada capa debe encapsular los datos:
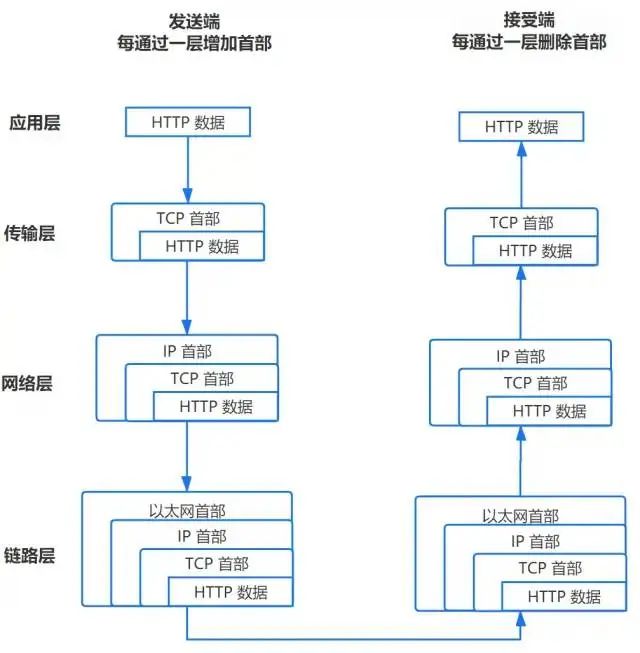
1. Capa de aplicación: enviar solicitud HTTP
Obtuvimos la dirección IP del servidor en los pasos anteriores y el navegador comenzará a construir un mensaje HTTP, que incluye:
Encabezado de solicitud (encabezado de solicitud): método de solicitud, dirección de destino, protocolo seguido, etc.
Cuerpo de la solicitud (otros parámetros)
Puntos a tener en cuenta: los navegadores solo pueden enviar métodos GET y POST, y el método GET se utiliza para abrir páginas web
2. Capa de transporte: TCP transmite paquetes
La capa de transporte iniciará una conexión TCP con el servidor. Para facilitar la transmisión, los datos se dividirán (en la unidad de segmento del mensaje) y se numerarán, de modo que el servidor pueda restaurar con precisión la información del mensaje al recibirlo.
Antes de establecer una conexión, primero se realizará un protocolo de enlace TCP de tres vías.
Con respecto al protocolo de enlace de tres vías TCP/IP, ya hay muchos párrafos e imágenes en Internet que lo describen vívidamente y puedes echarle un vistazo.
3. Capa de red: consulta de protocolo IP dirección Mac
Empaque los segmentos de datos, agregue las direcciones IP de origen y destino y sea responsable de encontrar la ruta de transmisión.
Determine si la dirección de destino está en la misma red que la dirección actual; en caso afirmativo, envíela directamente de acuerdo con la dirección Mac; de lo contrario, use la tabla de enrutamiento para encontrar la dirección del siguiente salto y use el protocolo ARP para consultar su dirección Mac.
Nota: En el modelo de referencia OSI el protocolo ARP está en la capa de enlace, pero en TCP/IP está en la capa de red.
4. Capa de enlace: protocolo Ethernet
protocolo ethernet
Según el protocolo Ethernet, los datos se dividen en paquetes de datos en unidades de "tramas", y cada trama se divide en dos partes:
Encabezado: remitente, receptor, tipo de datos del paquete
Datos: el contenido específico del paquete de datos.
dirección MAC
Ethernet estipula que todos los dispositivos conectados a la red deben tener una interfaz de "tarjeta de red", y los paquetes de datos se pasan de una tarjeta de red a otra. La dirección de la tarjeta de red es la dirección Mac. Cada dirección Mac es única y tiene capacidad uno a uno.
transmisión
El método de envío de datos es muy primitivo. Los datos se envían directamente a todas las máquinas de la red a través del protocolo ARP. El receptor compara la información del encabezado con su propia dirección Mac y la acepta si están de acuerdo; de lo contrario, la descarta.
Nota: Las respuestas del receptor son de unidifusión.
El servidor acepta la solicitud.
El proceso de aceptación consiste en revertir los pasos anteriores, consulte la imagen de arriba.
Cuarto, el servidor procesa la solicitud.
flujo general
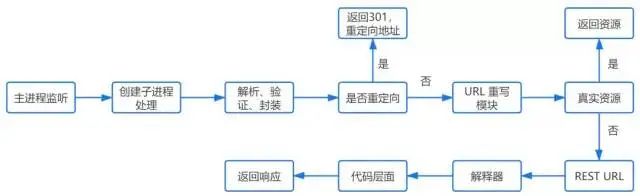
HTTPD
Los HTTPD más comunes son Apache y Nginx, comúnmente utilizados en Linux, e IIS en Windows.
Escuchará la solicitud y luego iniciará un proceso hijo para manejar la solicitud.
tratar con
Después de recibir el mensaje TCP, procesará la conexión, analizará el protocolo HTTP (método de solicitud, nombre de dominio, ruta, etc.) y realizará algunas verificaciones:
Verifique que los hosts virtuales estén configurados
Verifique que el host virtual acepte este método
Verifique que el usuario pueda utilizar el método (basado en la dirección IP, información de identidad, etc.)
redirigir
Si el servidor está configurado con redirección HTTP, devolverá una 301respuesta de redirección permanente y el navegador reenviará la solicitud HTTP (volverá a ejecutar el proceso anterior) de acuerdo con la respuesta.
Reescritura de URL
Luego verificará las reglas de reescritura de URL y, si el archivo solicitado es real, como imágenes, archivos html, css, js, etc., devolverá el archivo directamente. De lo contrario, el servidor reescribirá la solicitud en una URL RESTful de acuerdo con las reglas. Luego, de acuerdo con el script del lenguaje dinámico, se determina qué tipo de intérprete de archivos dinámicos llamar para procesar la solicitud.
Tomando el marco MVC del lenguaje PHP como ejemplo, primero inicializa algunos parámetros del entorno, hace coincidir la ruta de arriba a abajo de acuerdo con la URL y luego deja que el método definido por la ruta procese la solicitud.
5. El navegador acepta la respuesta.
Una vez que el navegador recibe el recurso de respuesta del servidor, analiza el recurso.
Primero verifique el encabezado de Respuesta y haga cosas diferentes de acuerdo con diferentes códigos de estado (como la redirección mencionada anteriormente).
Si el recurso de respuesta está comprimido (como gzip), también es necesario descomprimirlo.
Luego, almacene en caché el recurso de respuesta.
A continuación, analice el contenido de la respuesta según el tipo MIME [3] en el recurso de respuesta (por ejemplo, HTML e Imagen tienen diferentes métodos de análisis).
6. Renderizar la página
núcleo del navegador

Los diferentes núcleos de navegador tienen diferentes procesos de renderizado, pero el proceso general es similar.
proceso basico
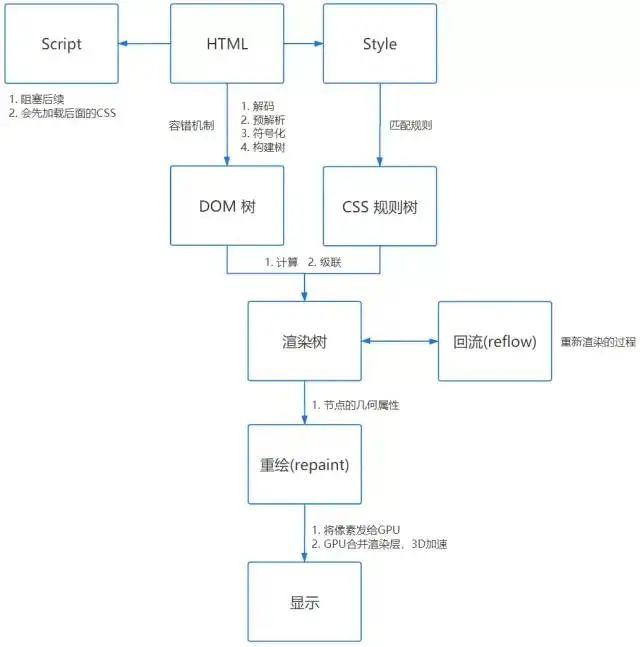
6.1 Análisis HTML
En primer lugar, debe saber que el análisis del navegador se analiza línea por línea de arriba a abajo.
El proceso de análisis se puede dividir en cuatro pasos:
① decodificación (codificación)
Lo que se transmite de vuelta son en realidad algunos datos de bytes binarios, y el navegador necesita convertirlos en una cadena de acuerdo con la codificación especificada del archivo (como UTF-8), es decir, código HTML.
② Análisis previo (análisis previo)
Lo que hace el análisis previo es cargar recursos por adelantado para reducir el tiempo de procesamiento. Identificará algunos atributos que solicitarán recursos, como los atributos imgde etiqueta src, y agregará esta solicitud a la cola de solicitudes.
③ Tokenización
La tokenización es el proceso de análisis léxico, que analiza la entrada en símbolos. Los símbolos HTML incluyen etiquetas de inicio, etiquetas de finalización, nombres de atributos y valores de atributos.
Utiliza una máquina de estados para identificar el estado del símbolo, como cuando se encuentra <, >el estado cambiará.
④ construcción de árboles
Nota: la simbolización y la construcción del árbol funcionan en paralelo, lo que significa que tan pronto como se analiza una etiqueta de inicio, se creará un nodo DOM.
En el paso anterior de la tokenización, el analizador obtiene estos tokens, luego crea el objeto de manera adecuada DOMe inserta estos tokens en DOMel objeto.
<html><head><title>Web page parsing</title></head><body><div><h1>Web page parsing</h1><p>This is an example Web page.</p></div></body></html>
tolerancia a errores del navegador
Nunca has visto un error de "sintaxis no válida" en un navegador, es porque el navegador corrige la sintaxis incorrecta y sigue funcionando.
evento
Cuando se complete todo el proceso de análisis, el navegador notificará DOMContentLoadedla DOMfinalización del análisis a través de un evento.
6.2 Análisis de CSS
Una vez que el navegador ha descargado el CSS, el analizador de CSS procesa cualquier CSS que encuentre, analiza todo el CSS de acuerdo con la especificación gramatical [4] y lo tokeniza, luego obtenemos una tabla de reglas.
Reglas de coincidencia CSS
Al hacer coincidir las reglas CSS correspondientes a un nodo, está en orden de derecha a izquierda, por ejemplo: div p { font-size :14px }primero encontrará todas plas etiquetas y luego juzgará si su elemento principal es div.
Entonces, cuando escribimos CSS, intentamos usar id y class, y no usar cascadas excesivas.
6.3 Árbol de renderizado
De hecho, este es un proceso de fusión del árbol DOM y el árbol de reglas CSS.
Nota: El árbol de renderizado ignorará aquellos nodos que no necesitan renderizarse, como display:nonelos nodos que están configurados.
calcular
Cualquier valor de tamaño se reduce a una de tres posibilidades mediante cálculo: auto, porcentaje, px, como convertir rema px.
cascada
El navegador necesita una forma de determinar qué estilos realmente deben aplicarse al elemento correspondiente, por lo que utiliza una specificityfórmula llamada , que pasa por:
nombre de etiqueta, clase, identificación
Ya sea para estilos en línea
!important
Luego obtenga un valor de peso, tome el más alto.
bloqueo de renderizado
Cuando scriptse encuentra una etiqueta, la construcción del DOM se pausa hasta que el script termina de ejecutarse y luego continúa construyendo el árbol DOM.
Pero si JS se basa en estilos CSS y no se ha descargado ni creado, el navegador retrasará la ejecución del script hasta que se creen las reglas CSS.
Todo lo que sabemos:
CSS bloquea la ejecución de JS
JS bloqueará el análisis DOM posterior
Para evitar esta situación se deben seguir los siguientes principios:
Los recursos CSS se ordenan antes que los recursos JavaScript
JS se coloca en la parte inferior del HTML, es decir,
</body>antes
Además, si desea cambiar el modo de bloqueo, puede utilizar aplazar y asíncrono.
6.4 Maquetación y dibujo
Determine las propiedades geométricas de todos los nodos en el árbol de representación, como posición, tamaño, etc., y finalmente ingrese un modelo de caja, que puede capturar con precisión la posición y el tamaño exactos de cada elemento en la pantalla.
Luego se recorre el árbol de renderizado, llamando al método paint() del renderizador para mostrar su contenido en la pantalla.
6.5 Fusionar capas de renderizado
Fusione todas las imágenes dibujadas arriba y finalmente genere una imagen.
6.6 Reflujo y Redibujado
reflujo
Cuando el navegador descubre que una determinada parte descubre que el cambio ha afectado el diseño, debe regresar y volver a renderizar, recurrirá a la htmletiqueta y volverá a calcular la posición y el tamaño.
El reflujo es básicamente inevitable, porque cuando desliza el mouse y cambia el tamaño de la ventana, la página cambiará.
repintar
El redibujado ocurre cuando cambiar el color de fondo, el color del texto, etc. de un elemento no afecta los cambios de posición de los elementos circundantes.
Después de cada nuevo dibujo, el navegador también debe fusionar las capas de renderizado y mostrarlas en la pantalla.
El costo del reflujo es mucho mayor que el de volver a dibujar, por lo que debemos intentar evitar el reflujo.
Por ejemplo: display:none se activará el reflujo, pero visibility:hidden solo se activará el redibujo.
6.7 Compilación y ejecución de JavaScript
flujo general
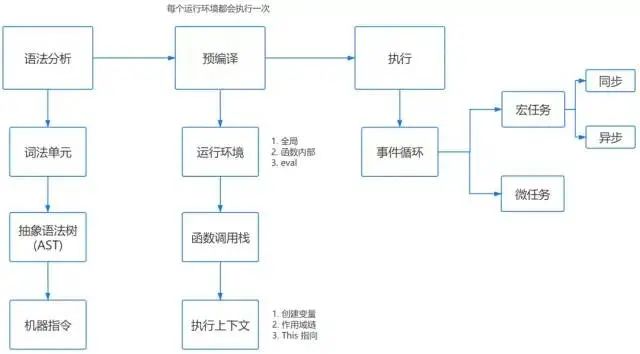
Se puede dividir en tres etapas:
1. Análisis léxico
Después de cargar el script JS, primero ingresará a la etapa de análisis de sintaxis. Primero analizará si la sintaxis del bloque de código es correcta. Si no es correcta, arrojará un "error de sintaxis" y detendrá la ejecución.
Varios pasos:
La segmentación de palabras, por ejemplo
var a = 2, divide a , en unidades léxicas comovar,a,=, .2Análisis, que convierte los tokens en un árbol de sintaxis abstracta (AST).
Generación de código, que convierte árboles de sintaxis abstracta en instrucciones de máquina.
2. Precompilar
JS tiene tres entornos de ejecución:
entorno global
entorno funcional
evaluar
Cada vez que ingresa a un entorno operativo diferente, se creará un contexto de ejecución correspondiente. Según los diferentes contextos, se forma una pila de llamadas de función. La parte inferior de la pila es siempre el contexto de ejecución global y la parte superior de la pila es siempre el contexto de ejecución actual.
Crear contexto de ejecución
En el proceso de creación del contexto de ejecución, se realizan principalmente las siguientes tres cosas:
crear objeto variable
parámetro, función, variable
Crear una cadena de alcance
Confirmar si el entorno de ejecución actual puede acceder a variables
Asegúrese de que esto apunte a
3. Ejecución
hilo js
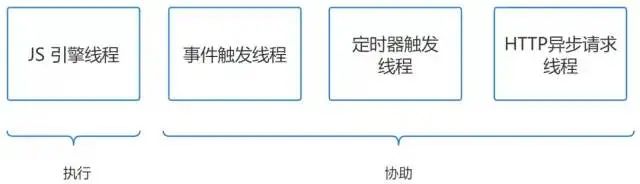
Aunque JS tiene un solo subproceso, en realidad hay cuatro subprocesos involucrados en el trabajo:
Tres de ellos son solo asistencia, solo se ejecuta el subproceso del motor JS.
Tres de ellos son solo asistencia, solo se ejecuta el subproceso del motor JS.
Hilo del motor JS: también llamado kernel JS, responsable de analizar y ejecutar el hilo principal de los programas de script JS, como el hilo de activación de eventos del motor V8: pertenece al hilo del kernel del navegador, utilizado principalmente para controlar eventos, como mouse, teclado, etc. Cuando se activa el evento, la función de procesamiento de eventos se enviará a la cola de eventos, esperando que el subproceso del motor JS ejecute el subproceso de activación del temporizador: el control principal y se utiliza
setIntervalpara elsetTimeoutcronometraje, una vez finalizado el cronometraje, la función de procesamiento del temporizador será empujado a la cola de eventos, esperando el hilo del motor JS. Hilo de solicitud asíncrona HTTP: después de conectarse a través de XMLHttpRequest, a través de un nuevo hilo abierto por el navegador, al monitorear el cambio del estado readyState, si la función de devolución de llamada de este estado está configurada, la función de procesamiento de este estado se insertará en el evento haga cola y espere a que se implemente el subproceso del motor JS.
Nota: La cantidad de conexiones simultáneas del navegador al mismo nombre de dominio es limitada, generalmente 6.
tarea macro
Dividido en:
Tareas sincrónicas: se ejecutan en orden, solo después de completar la tarea anterior, se puede ejecutar la siguiente tarea
Tarea asincrónica: no se ejecuta directamente, solo cuando se cumple la condición de activación, el subproceso relevante empuja la tarea asincrónica a la cola de tareas y espera a que se complete la ejecución de la tarea en el subproceso principal del motor JS, como Ajax asincrónico. , evento DOM, setTimeout, etc.
microtarea
Las microtareas están bajo el entorno ES6 y Node, las principales API son: Promise, process.nextTick.
Las microtareas se ejecutan después de las tareas sincrónicas de las macrotareas y antes de las tareas asincrónicas.

ejemplo de código
console.log('1'); // 宏任务 同步
setTimeout(function() {
console.log('2'); // 宏任务 异步})
new Promise(function(resolve) {
console.log('3'); // 宏任务 同步
resolve();
}).then(function() {
console.log('4')// 微任务})
console.log('5') // 宏任务 同步La secuencia de salida del código anterior es: 1,3,5,4,2

↓ ↓ ↓ Haz clic para leer el texto original e ir directamente a mi blog personal
 Estás viendo
Estás viendo