您好,我是路人,更多优质文章见个人博客:http://itsoku.comRecientemente leí el código fuente del grupo de subprocesos JDK ThreadPoolExecutor y tengo una comprensión general del proceso de ejecución de tareas en el grupo de subprocesos. De hecho, este proceso también es muy fácil de entender, por lo que no lo repetiré. Otros lo escribieron mucho mejor que yo.
Sin embargo, estoy más interesado en cómo el grupo de subprocesos recicla los subprocesos de trabajo, así que lo analicé brevemente para profundizar mi comprensión del grupo de subprocesos.
Entonces, tomemos JDK1.8 como ejemplo.
1. ejecutarTrabajador(Trabajador w)
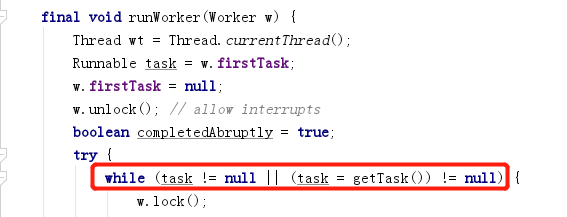
Una vez que se inicia el subproceso de trabajo, ingresa al método runWorker (Worker w).
Dentro hay un bucle while, el bucle juzga si la tarea está vacía, si no está vacía, ejecuta la tarea; si no se puede obtener la tarea, o ocurre una excepción, sal del bucle y ejecuta ProcessWorkerExit (w, completado de forma abrupta); en Con este método, el hilo de trabajo se mueve para deshacerse de él.
Hay dos fuentes para recuperar tareas. Una es firstTask, que es la tarea que se ejecuta cuando el subproceso de trabajo se ejecuta por primera vez. Solo se puede ejecutar una vez como máximo y la tarea debe recuperarse del método getTask() más adelante. Parece que getTask() es la clave. En el escenario donde no se consideran excepciones, devolver nulo significa salir del ciclo y finalizar el hilo. A continuación, tenemos que ver bajo qué circunstancias getTask() devolverá nulo.
(Espacio limitado, interceptado en secciones, omitiendo los pasos para realizar tareas en el medio)

2. getTask() devuelve nulo
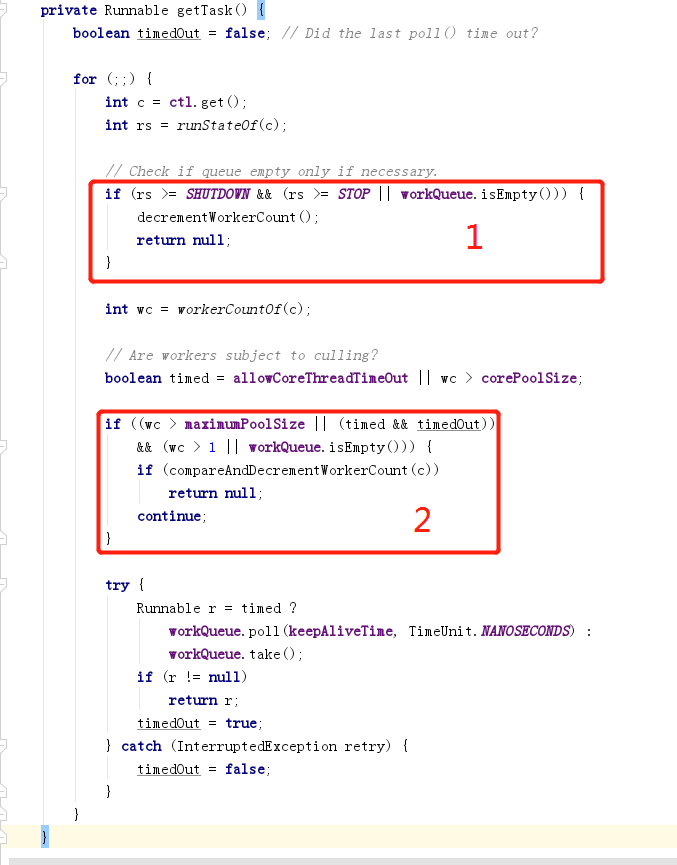
Hay dos situaciones en las que se devolverá nulo; consulte el cuadro rojo.
En el primer caso, el estado del grupo de subprocesos ya es DETENER, ORDENANDO, TERMINADO o APAGADO y la cola de trabajo está vacía;
En el segundo caso, la cantidad de subprocesos de trabajo es mayor que la cantidad máxima de subprocesos o el subproceso de trabajo actual ha agotado el tiempo de espera y hay otros subprocesos de trabajo o la cola de tareas está vacía. Esto es más difícil de entender, en resumen, recuérdelo primero y úselo después.
La condición 1 y la condición 2 se utilizan a continuación para referirse a las condiciones de sentencia de los dos casos respectivamente.
3. Grupo de subprocesos de análisis de escenarios que recicla subprocesos de trabajo
3.1 El escenario donde no se llama a apagado () y todas las tareas se completan en el estado EN EJECUCIÓN
En este escenario, la cantidad de subprocesos de trabajo se reducirá al tamaño de la cantidad de subprocesos centrales (si no se excede, no es necesario reciclar).
Por ejemplo, en un grupo de subprocesos, la cantidad de subprocesos principales es 4 y la cantidad máxima de subprocesos es 8. Al principio, hay 4 subprocesos de trabajo. Cuando las tareas llenan la cola de tareas, debe aumentar los subprocesos de trabajo a 8. Cuando las tareas posteriores estén casi ejecutadas y los subprocesos no puedan obtener tareas, se reciclarán al estado de 4 subprocesos de trabajo (dependiendo del valor de enableCoreThreadTimeOut, aquí se analiza el caso en el que el valor predeterminado es falso, es decir, el subproceso principal no expirará. Si es verdadero, todos los subprocesos de trabajo pueden destruirse).
La condición 1 mencionada anteriormente se puede excluir primero , el estado del grupo de subprocesos ya es DETENIDO, ORDENADO, TERMINADO o APAGADO y la cola de trabajo está vacía. Debido a que el grupo de subprocesos siempre está EN EJECUCIÓN, este juicio siempre es falso. En este escenario, se puede suponer que la condición 1 no existe.
A continuación se analiza cómo se ejecuta el hilo cuando la tarea no se puede eliminar.
Paso 1. Hay dos formas de recuperar tareas de la cola de tareas, y el tiempo de espera aún se puede bloquear para siempre. El factor determinante es la variable temporal. A la variable se le asigna un valor antes. Si el número actual de subprocesos es mayor que el número de subprocesos principales, la variable cronometrada es verdadera; de lo contrario, es falsa (como se mencionó anteriormente, aquí solo se analiza el caso en el que enableCoreThreadTimeOut es falso). Obviamente, lo que se está discutiendo ahora es el caso en el que el tiempo es cierto. keepAliveTime generalmente no está configurado y el valor predeterminado es 0, por lo que básicamente se puede considerar sin bloqueo y el resultado de recuperar la tarea se devolverá inmediatamente.
Después de que el hilo espera el tiempo extra para despertarse, descubre que la tarea no se puede eliminar, el tiempo de espera se vuelve verdadero y ingresa al siguiente ciclo.
Paso 2. Al juzgar la condición 1 , el grupo de subprocesos siempre está EN EJECUCIÓN y no ingresa al bloque de código.
Paso 3. Llegue al juicio de la condición 2. En este momento, la cola de tareas está vacía y la condición es verdadera. CAS reduce el número de subprocesos. Si tiene éxito, devuelve nulo; de lo contrario, repita el paso 1.
Cabe señalar aquí que es posible que varios subprocesos pasen el juicio de la condición 2 al mismo tiempo . ¿Se reducirá la cantidad de subprocesos en lugar de la cantidad esperada de subprocesos centrales?
Por ejemplo, el número actual de subprocesos es solo 5. En este momento, dos subprocesos se activan al mismo tiempo. Después de juzgar la condición 2 y reducir el número al mismo tiempo, el número restante de subprocesos es solo 3. lo cual es inconsistente con la expectativa.
En realidad no. Para evitar esta situación, compareAndDecrementWorkerCount (c) utiliza el método CAS. Si el CAS falla, continúe, ingrese a la siguiente ronda del ciclo y vuelva a juzgar.
Como en el ejemplo anterior, uno de los subprocesos fallará en CAS y luego volverá a ingresar al bucle y descubrirá que el número de subprocesos de trabajo es solo 4, el tiempo es falso, este subproceso no se destruirá y se puede bloquear para siempre ( workQueue.take()).
He estado pensando en esto durante mucho tiempo antes de llegar a la respuesta. He estado pensando en cómo garantizar que la cantidad de subprocesos centrales se pueda reciclar sin ningún bloqueo. Resultó ser el misterio del CAS.
También se puede ver desde aquí que, aunque hay subprocesos centrales, los subprocesos no distinguen si son centrales o no centrales: el núcleo no se crea primero y el no central se crea después de que se excede el número de subprocesos centrales. Los hilos que finalmente se retienen son completamente aleatorios.
3.2 Llamar a apagado (), el escenario donde se ejecutan todas las tareas
En este escenario, ya sea un subproceso central o no central, todos los subprocesos de trabajo serán destruidos.
Después de llamar a Shutdown(), se envía una señal de interrupción a todos los subprocesos de trabajo inactivos.
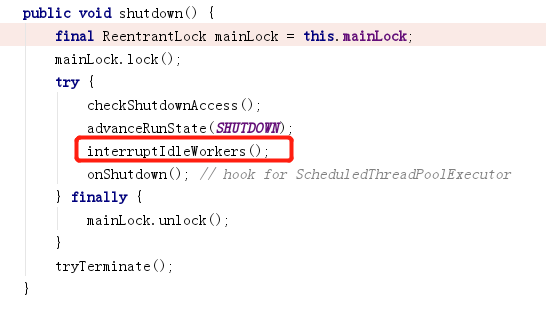
Finalmente pase false y llame al siguiente método.
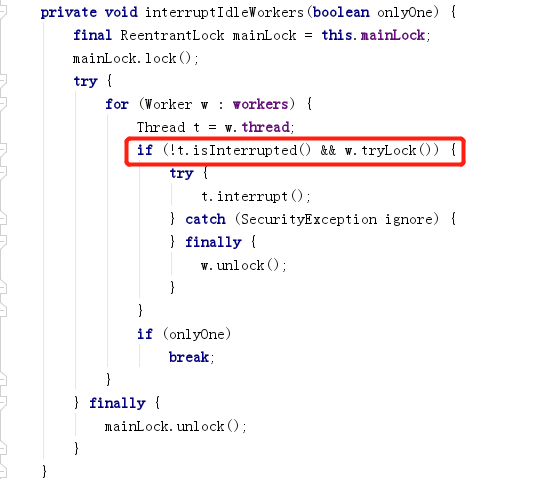
Se puede ver que antes de enviar la señal de interrupción, se juzgará si se ha interrumpido y se obtendrá el bloqueo exclusivo del hilo de trabajo.
Cuando se emite una señal de interrupción, el subproceso de trabajo se está preparando para adquirir la tarea en getTask() o está ejecutando la tarea, por lo que no la emitirá hasta que termine de ejecutar la tarea actual, porque el subproceso de trabajo también agregará la tarea cuando el hilo de trabajo está ejecutando la tarea. Después de que el hilo de trabajo ejecuta la tarea, vuelve a getTask().
Entonces solo necesitamos ver cómo lidiar con las excepciones de interrupción en getTask().

Hay dos posibilidades para el subproceso de trabajo en getTask().
3.2.1 Todas las tareas se han completado y el hilo está bloqueado y esperando.
Muy simple, la señal de interrupción lo despierta y entra al siguiente ciclo. Cuando se alcanza la condición 1 , si se cumple la condición, el número de subprocesos de trabajo se reducirá, se devolverá nulo y la capa externa finalizará este subproceso.
El decrementWorkerCount() aquí es de tipo spin y definitivamente se reducirá en 1.

3.2.2 La tarea no se ha ejecutado completamente
Después de llamar a Shutdown(), las tareas no finalizadas deben ejecutarse antes de que el grupo pueda finalizar. Entonces es posible que el hilo todavía esté funcionando en este momento.
Hay dos etapas para discutir.
La fase 1 tiene muchas tareas y los subprocesos de trabajo pueden obtener tareas.
Esto no implica la salida del subproceso, puede omitirlo , simplemente analice el rendimiento del subproceso después de recibir la señal de interrupción.
Supongamos que hay un hilo A, que obtiene tareas a través de getTask(). En este momento, A se interrumpe y, al adquirir la tarea, ya sea poll () o take (), se generará una excepción de interrupción. La excepción se detecta y vuelve a ingresar al siguiente ciclo. Siempre que la cola no esté vacía, se pueden seguir recuperando tareas.
El hilo A se interrumpe, recupera la tarea nuevamente, llama a workQueue.poll() o workQueue.take(), ¿no se lanzará una excepción? ¿Se puede recuperar la tarea normalmente?
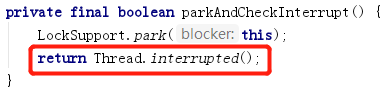
Depende de la implementación de workQueue. workQueue es un tipo BlockingQueue. Tomando como ejemplos LinkedBlockingQueue y ArrayBlockingQueue comunes, se llama a lockInterruptfully () al bloquear, lo que responde a la interrupción. Este método llama a adquirirInterruptiblemente (int arg) de AQS.
adquirirInterruptiblemente (int arg), ya sea para juzgar la excepción de interrupción en la entrada o bloquear en el método parkAndCheckInterrupt (), ser despertado por la interrupción y juzgar la excepción de interrupción, se utiliza Thread.interrupted (). ¡Este método devolverá el estado de interrupción del hilo y restablecerá el estado de interrupción! En otras palabras, el hilo ya no está en estado interrumpido, por lo que cuando se recupera la tarea nuevamente, no se informará ningún error.
Por lo tanto, esto equivale a desperdiciar un ciclo para el hilo que se está preparando para buscar tareas. Esto puede ser un efecto secundario de la interrupción del hilo. Por supuesto, no afecta la operación general.
Después de analizar este punto, no puedo evitar suspirar, BlockingQueue simplemente restablece el estado de interrupción aquí. ¿Cómo se le ocurrió un diseño tan maravilloso? Doug Lea Dios Orz.

La misión de la fase 2 está a punto de terminar
En este momento, la tarea casi ha sido recuperada, por ejemplo, hay 4 subprocesos de trabajo y solo quedan 2 tareas, entonces 2 subprocesos pueden obtener la tarea y 2 subprocesos están bloqueados.
Debido a que el juicio antes de obtener la tarea no está bloqueado, ¿sucederá que todos los subprocesos hayan pasado la verificación anterior y lleguen al lugar donde workQueue obtiene la tarea, sucede que la cola de tareas está vacía y todos los subprocesos están bloqueados? Debido a que se ha ejecutado el apagado (), ya no se puede enviar una señal de interrupción al subproceso, por lo que el subproceso se ha bloqueado y no se puede reciclar.
Esto no va a pasar.
Supongamos que hay cuatro subprocesos de trabajo A, B, C y D, y emita el juicio de la condición 1 y la condición 2 al mismo tiempo y llegue al lugar donde se recupera la tarea. Entonces, hay al menos una tarea en la cola de trabajos y al menos un subproceso puede obtener la tarea.
Supongamos que A y B obtienen la tarea, C y D están bloqueados.
A, B Los siguientes pasos son:
paso 1. Una vez completada la ejecución de la tarea, getTask() nuevamente. En este momento, se cumple la condición 1 , se devuelve nulo y el hilo está listo para ser reciclado.
step2.processWorkerExit(Trabajador w, booleano completado abruptamente) Recicla el hilo.
¿Reciclar es tan simple como matar hilos? Echemos un vistazo al método ProcessWorkerExit (Trabajador w, booleano completado de forma abrupta).
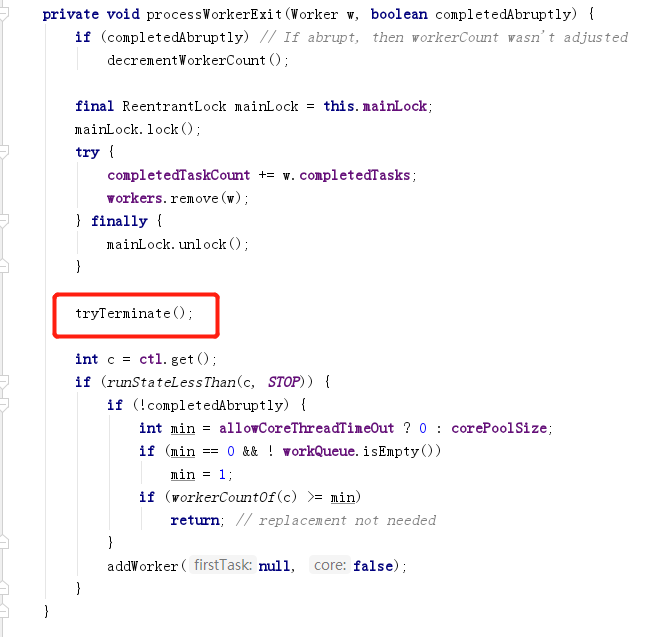
Como puede ver, además de que Workers.remove(w) elimina la línea, también se llama a tryTerminate().
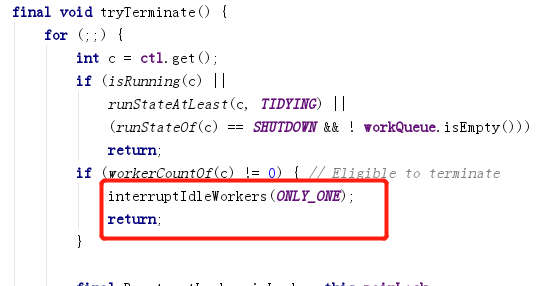
La primera condición de juicio no cumple con ninguna subcondición, omítala. La segunda condición es que el subproceso de trabajo todavía exista y luego interrumpa aleatoriamente un subproceso inactivo.
Entonces viene el problema, interrumpir un hilo inactivo no significa interrumpir el hilo que está bloqueando. Si A y B salen al mismo tiempo, ¿es posible que A interrumpa a B, B interrumpa a A y AB se interrumpa entre sí, de modo que no haya ningún hilo que interrumpa y despierte el hilo bloqueado?
La respuesta sigue siendo, piensa demasiado...
Suponiendo que A puede venir aquí, significa que A se ha eliminado de los trabajadores de la colección de subprocesos de trabajo (processWorkerExit (Worker w, boolean completeAbruptly) se ha eliminado antes de tryTerminate()). Entonces A interrumpe a B, y B viene aquí para interrumpir, y A no se encontrará entre los trabajadores.

En otras palabras, los hilos que salen no pueden interrumpirse entre sí. Después de que salgo de la colección, te interrumpo a ti, pero tú no puedes interrumpirme a mí, porque ya salí de la colección y tú solo puedes interrumpir a otros. Entonces, incluso si N hilos salen al mismo tiempo, al menos al final, habrá un hilo que interrumpirá los hilos bloqueados restantes.
Como fichas de dominó, la señal de interrupción se propagará.
Después de que cualquiera de los C y D bloqueados se interrumpa y se despierte, la acción del paso 1 se repetirá y el ciclo comenzará una y otra vez hasta que todos los subprocesos bloqueados se interrumpan y se despierten.
Es por eso que en tryTerminate(), si pasa false, solo necesita interrumpir cualquier subproceso inactivo.
Pensando en esto, una vez más siento admiración (cantonés) por Doug Lea. También está bien diseñado.
4. Resumen
ThreadPoolExecutor recicla los subprocesos de trabajo y, si un subproceso getTask() devuelve nulo, se reciclará.
Hay dos escenarios.
El escenario donde no se llama a Shutdown() y todas las tareas se ejecutan en el estado EN EJECUCIÓN
Si el número de subprocesos es mayor que corePoolSize, los subprocesos se bloquearán mediante el tiempo de espera. Después de que se active el tiempo de espera, CAS reducirá el número de subprocesos en funcionamiento. Si CAS tiene éxito, se devolverá un valor nulo y los subprocesos se reciclarán. De lo contrario, ingrese al siguiente ciclo. Cuando el número de subprocesos de trabajo es menor o igual que corePoolSize, se puede bloquear todo el tiempo.
Llame a Shutdown (), la escena donde se ejecutan todas las tareas.
Shutdown() enviará una señal de interrupción a todos los subprocesos y hay dos posibilidades.
2.1) Todos los hilos están bloqueados
La interrupción se activa y entra en el bucle, todos los cuales cumplen la primera condición de juicio if, devuelven nulo y todos los subprocesos se reciclan.
2.2) La tarea no se ha ejecutado completamente
Se reciclará al menos un hilo. En el método ProcessWorkerExit(Worker w, boolean completeAbruptly), se llama a tryTerminate() para enviar una señal de interrupción a cualquier subproceso inactivo. Todos los hilos bloqueados eventualmente se despertarán uno por uno y se reciclarán.
Para este análisis, comencé a escribir anoche, me quedé atascado a la mitad de la escritura y continué escribiendo esta mañana. Me tomó alrededor de 2 + 2 = 4 horas escribir blogs y 1 hora para pensar.
Para ser honesto, todavía estoy un poco confundido, no puedo entenderlo todo de una vez y no sé si lo entiendo correctamente.
No sé si es útil o no, solo puedo decir que ha profundizado mi comprensión del grupo de subprocesos (me consuela) y también siento la sutileza del diseño.
más buenos artículos
Hable sobre implementaciones comunes de coherencia de base de datos y caché.
La idempotencia de la interfaz es tan importante, ¿qué es? ¿Cómo lograrlo?
Los genéricos, un poco difíciles, confundirán a mucha gente, ¡eso es porque no leíste este artículo!
↓↓↓ 点击阅读原文,直达个人博客
你在看吗