Computación en la nube y Big Data: implementación del clúster Kubernetes + implementación completa de nginx (¡súper detallada!)
La idea básica de implementar un clúster de Kubernetes es la siguiente:
-
Preparar el ambiente:
- Seleccione un sistema operativo adecuado: seleccione una distribución de Linux adecuada como sistema operativo según sus necesidades y asegúrese de realizar la misma selección en todos los nodos.
- Instalar Docker: instale Docker en todos los nodos, que se utilizarán para contener aplicaciones y componentes.
- Instale las herramientas de Kubernetes: instalación
kubectly herramientas, que se utilizarán para la administración y configuración del clúster.kubeadmkubelet
-
Configurar el nodo maestro (Master Node):
- Seleccionar un nodo como nodo maestro: normalmente se selecciona uno de los nodos esclavos como nodo maestro, que puede ser cualquier máquina con recursos suficientes.
- Inicialice el nodo maestro: use
kubeadm initel comando para inicializar el nodo maestro y obtener el token de unión generado. - Configure un complemento de red: seleccione e instale un complemento de red apropiado, como franela, Calico o Weave, para habilitar la comunicación de red entre nodos.
-
Agregar nodos esclavos (nodos trabajadores):
- Ejecute el comando de unión en cada nodo esclavo: utilizando el token de unión generado previamente, ejecute el comando en cada nodo esclavo
kubeadm joinpara unirlo al clúster. - Confirmar la unión del nodo: ejecute el comando en el nodo maestro
kubectl get nodespara asegurarse de que todos los nodos se hayan unido correctamente al clúster.
- Ejecute el comando de unión en cada nodo esclavo: utilizando el token de unión generado previamente, ejecute el comando en cada nodo esclavo
-
Implemente el complemento web:
- Dependiendo del complemento de red seleccionado, siga su implementación y configuración específicas. Esto garantizará la comunicación de red entre los nodos y proporcionará las capacidades de red del clúster de Kubernetes.
-
Implemente otros componentes y aplicaciones:
- Implemente otros componentes principales necesarios, como kube-proxy y kube-dns/coredns.
- Implemente sus aplicaciones o servicios, que se pueden administrar mediante la implementación, el servicio u otros tipos de recursos de Kubernetes.
-
Verificar el estado del clúster:
- Ejecutar
kubectl get nodesy otroskubectlcomandos para garantizar que los nodos y componentes del clúster funcionen correctamente. - Aplicaciones de prueba: ejecute pruebas en las aplicaciones implementadas en el clúster para garantizar que funcionen correctamente e interactúen con otros componentes.
- Ejecutar
Lo anterior es la idea básica de implementar un clúster de Kubernetes. Los pasos y detalles exactos pueden variar según el entorno y las necesidades, pero esta breve descripción puede ayudarle a comprender el flujo general del proceso de implementación.
A continuación, implementaremos el clúster de Kubernetes y completaremos el servicio nginx en la práctica.
Comience a implementar el clúster de Kubernetes
Ejecute los siguientes comandos como root:
1. Instale y configure Docker en todos los nodos.
1. Instale las herramientas necesarias para Docker.
yum install -y yum-utils device-mapper-persistent-data lvm2

2. Configure la fuente acoplable de Alibaba Cloud
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo

3. Instale docker-ce, docker-ce-cli, containerd.io
yum install -y docker-ce docker-ce-cli containerd.io
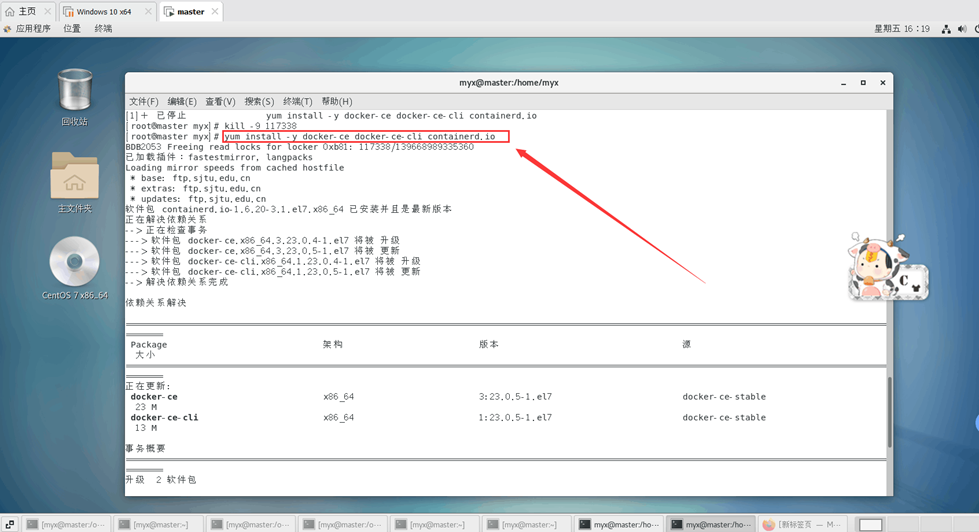
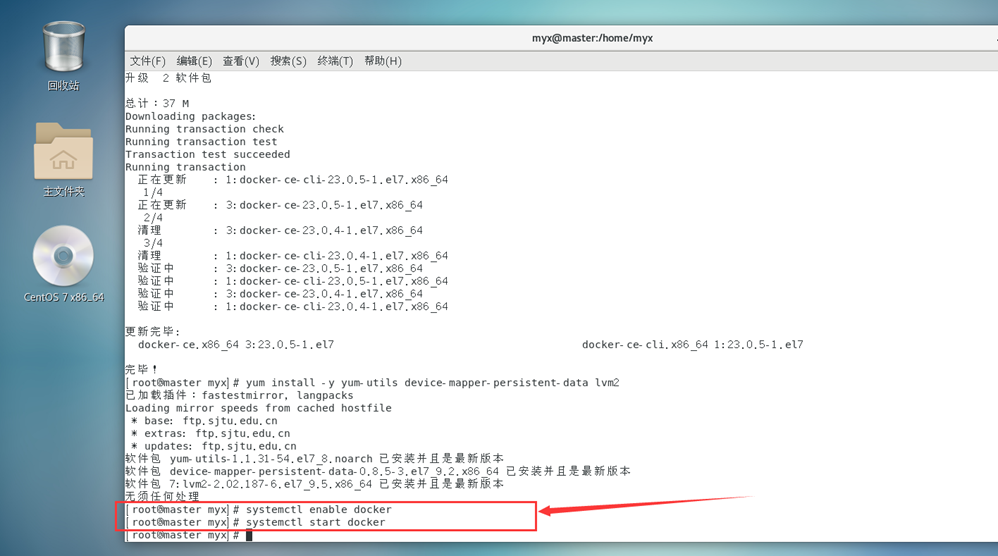
4. Inicie la ventana acoplable
systemctl enable docker #设置开机自启
systemctl start docker #启动docker
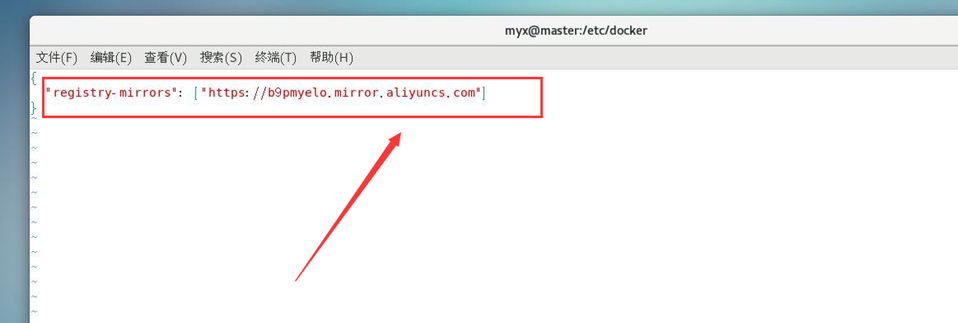
5. Configure el acelerador de espejo
#Establezca el acelerador de espejo, cree un nuevo archivo daemon.json (referencia 1)
cat <<EOF > /etc/docker/daemon.json
{
"registry-mirrors": ["https://b9pmyelo.mirror.aliyuncs.com"]
}
6. Genere y modifique el archivo de configuración predeterminado /etc/containerd/config.toml de containerd (referencia 2)
containerd config default > /etc/containerd/config.toml


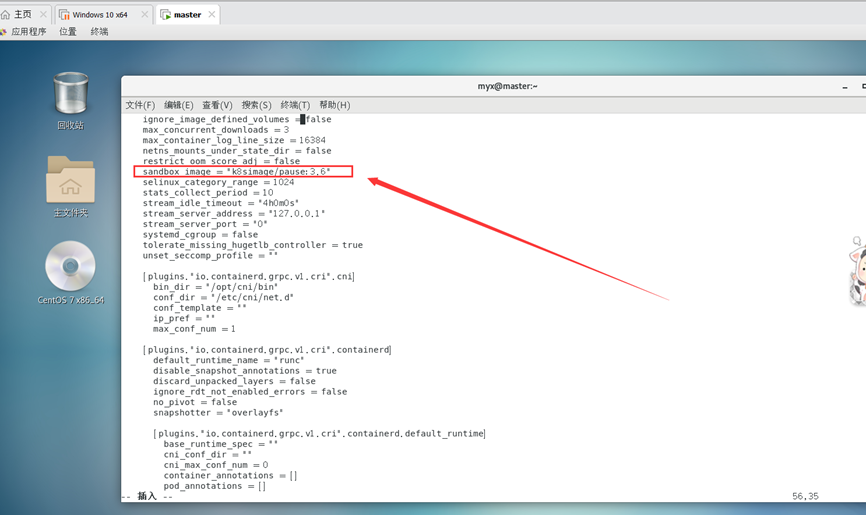
Cambie sandbox_image="registry.k8s.io/pause:3.6"
a sandbox_image="k8simage/pause:3.6"

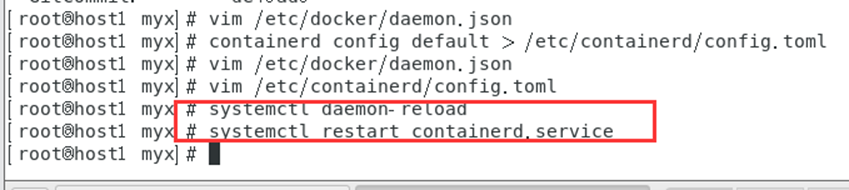
Reinicie el servicio en contenedor
systemctl daemon-reload
systemctl restart containerd.service

Nota: Este paso puede resolver el error al extraer la imagen \"registry.k8s.io/pause:3.6\"; No se pudo crear la zona de pruebas para el pod: extraer la imagen de registro.k8s.io/pause:3.6 y otros problemas (problemas de errores específicos pueden Vea los registros ejecutando el siguiente comando: journalctl -xeu kubelet)
7. Apague el firewall
systemctl disable firewalld
systemctl stop firewalld


8. Cerrar selinux
# Desactivar temporalmente selinux
setenforce 0
#O cerrar permanentemente, modificar la configuración del archivo /etc/sysconfig/selinux
sed -i 's/SELINUX=permissive/SELINUX=disabled/' /etc/sysconfig/selinux

sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config

9. Deshabilitar la partición de intercambio
swapoff -a
#O deshabilitar permanentemente, comentar la línea de intercambio en el archivo /etc/fstab
sed -i ‘s/.*swap.*/#&/’ /etc/fstab


10. Modifique los parámetros del kernel
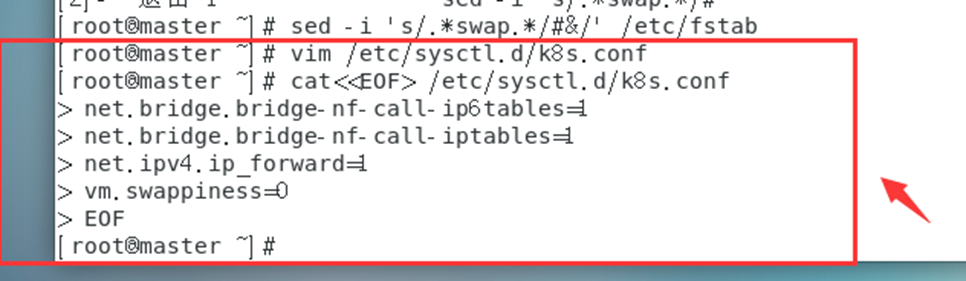
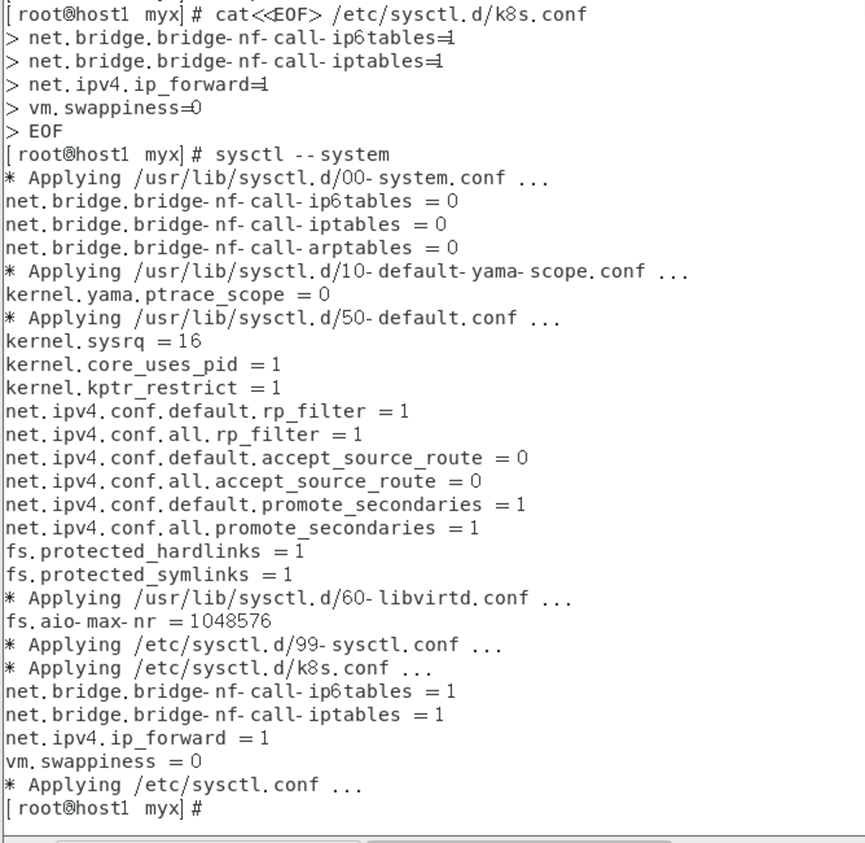
para pasar el tráfico IPv4 puenteado a la cadena de iptables (parte del tráfico ipv4 no puede pasar a través de la cadena de iptables, debido a un filtro en el kernel de Linux, cada tráfico pasará a través de él y luego determinará si puede ingresar al proceso de solicitud actual Para procesar, por lo que causará pérdida de tráfico), configure el archivo k8s.conf (el archivo k8s.conf no existe, debe crearlo usted mismo)
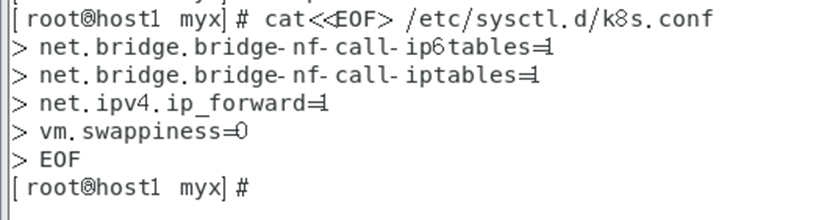
cat<<EOF> /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables=1
net.bridge.bridge-nf-call-iptables=1
net.ipv4.ip_forward=1
vm.swappiness=0
EOF
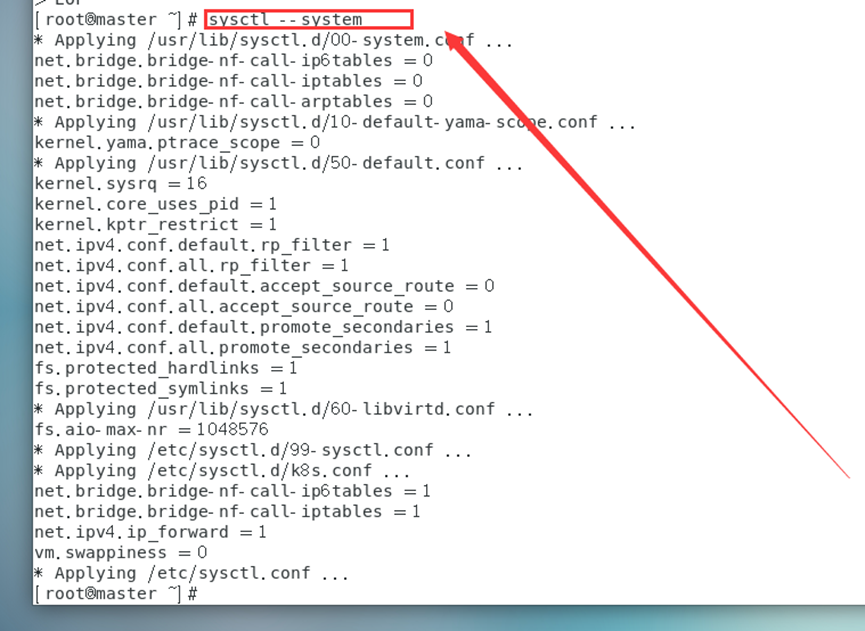
sysctl --system
#Vuelva a cargar todos los parámetros del sistema o use sysctl -p
Documento 1: https://yebd1h.smartapps.cn/pages/blog/index?blogId=123605246&_swebfr=1&_swebFromHost=bdlite
2. Instale y configure Kubernetes en todos los nodos (excepto los especificados por separado)
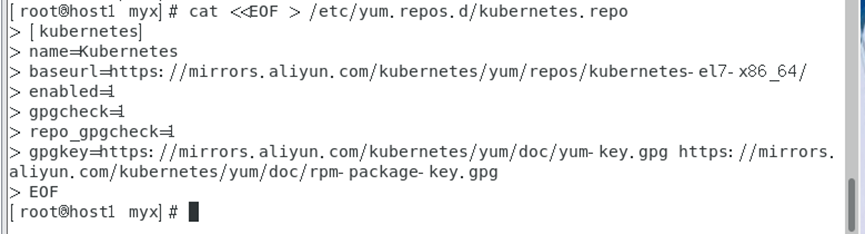
1. Configurar la fuente de Kubernetes Alibaba Cloud
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF

2. Instale kubeadm, kubectl y kubelet (kubeadm y kubectl son herramientas y kubelet es un servicio del sistema, referencia 1)
yum install -y kubelet-1.14.2
yum install -y kubeadm-1.14.2
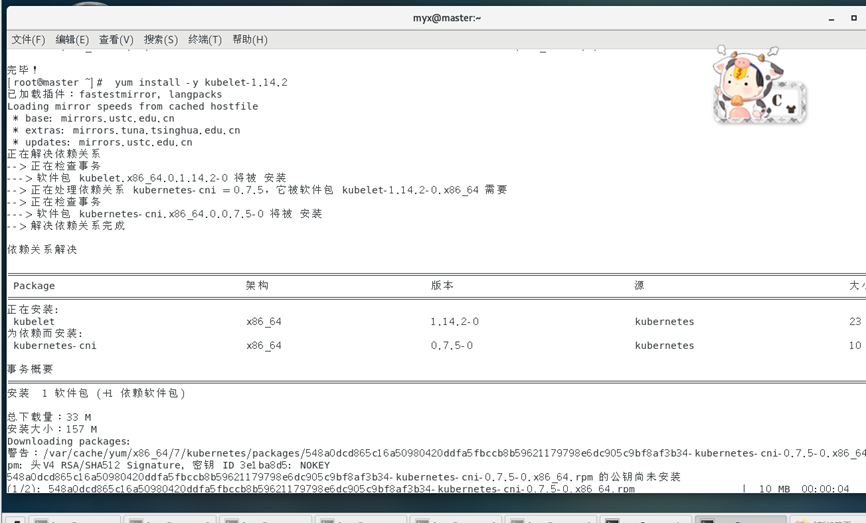
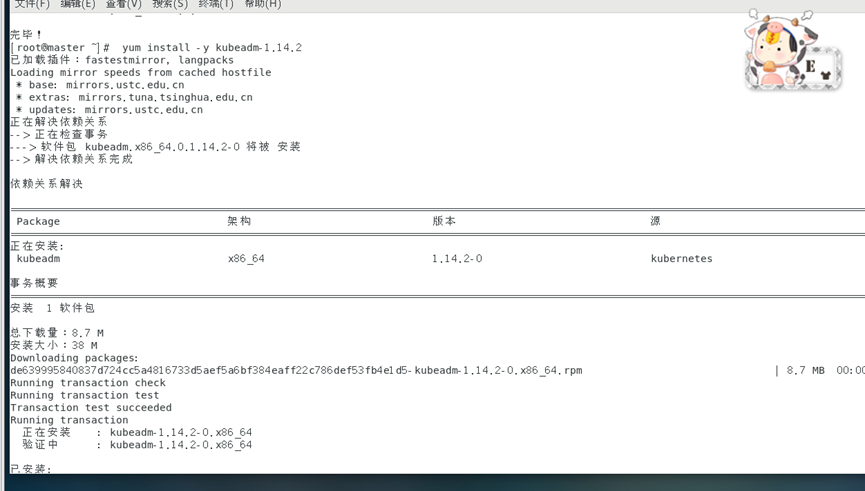
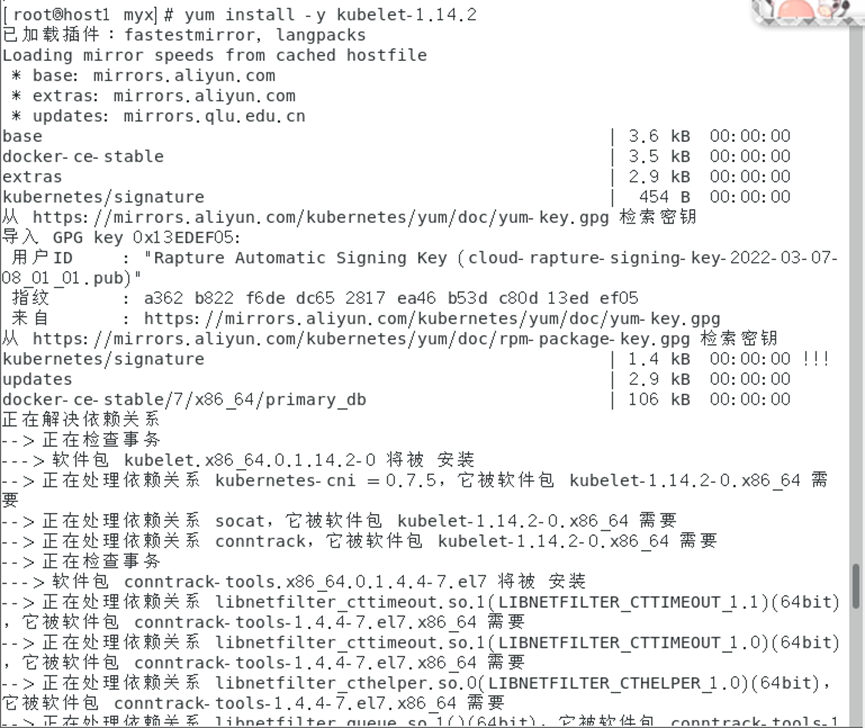
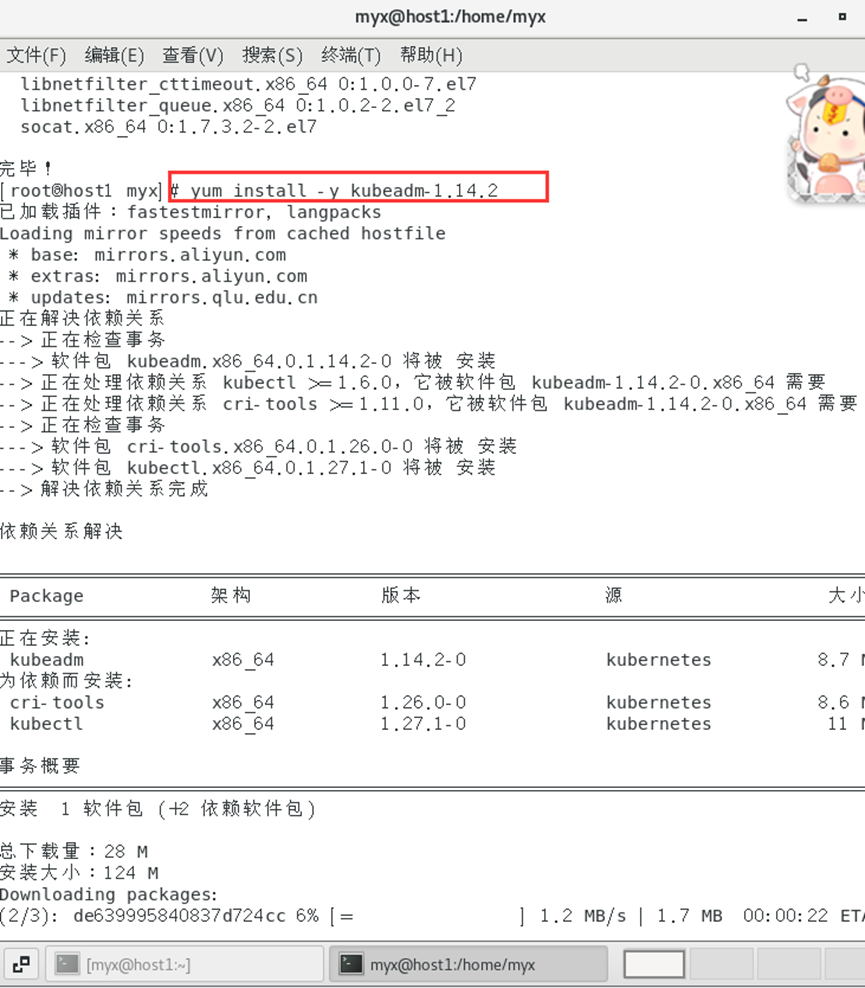
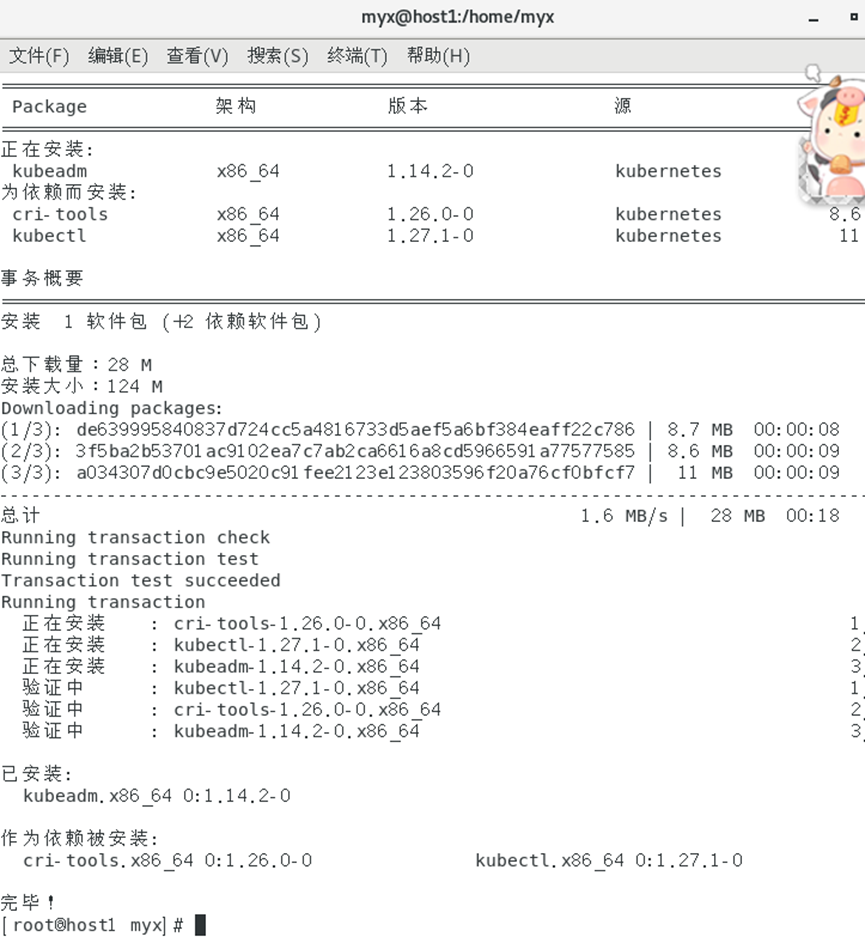
3. Inicie el servicio kubelet.
systemctl enable kubelet && systemctl start kubelet


4. Genere la versión actual del archivo de configuración de inicialización en el directorio /etc/kubernetes.
kubeadm config print init-defaults > /etc/kubernetes/init-default.yaml

1) Especifique la dirección IP que kube-apiserver transmite a otros componentes.
Este parámetro debe configurarse en la dirección IP del nodo maestro para garantizar que otros nodos puedan acceder a kube-apiserver
: publicidadAddress: 1.2.3.4 -> publicidadAddress: [IP del host (Intranet)]
Este elemento se configura de acuerdo con la dirección IP de su nodo maestro. La configuración de esta máquina es:
advertiseAddress:192.168.95.20
2) Especifique la fuente del almacén para instalar la imagen.
Se recomienda utilizar una imagen nacional como Alibaba Cloud:
imageRepository: registra.aliyuncs.com/google_containers
Nota: Nos encontraremos con los siguientes problemas de inicialización al principio:
failed to pull image registry.k8s.io/kube-apiserver:v1.26.3
Esta configuración combinada con los siguientes parámetros del comando kubeadm init puede resolver el problema:
--image-repository=registry.aliyuncs.com/google_containers
Es decir, durante la inicialización: kubeadm init --image-repository=registry.aliyuncs.com/google_containers
se inicializa más tarde
3) Edite /etc/hosts y agregue una línea:
192.168.95.20 k8s.cnblogs.com #需根据自己主机的IP地址进行修改
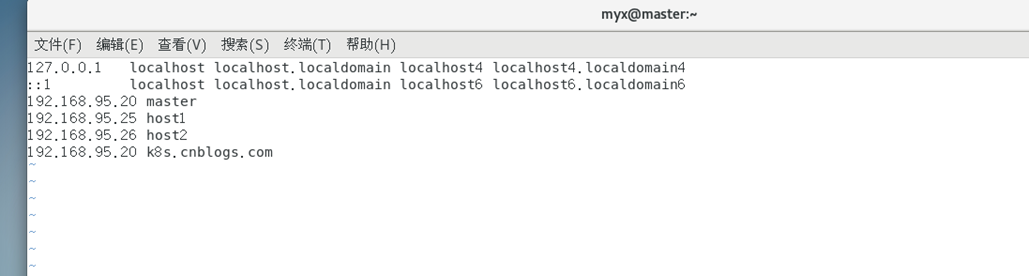
En general, el paso 4 puede resolver el complicado problema de [kubelet-check] Se pasó el tiempo de espera inicial de 40 segundos.
Referencia 2:
https://blog.csdn.net/weixin_52156647/article/details/129765134
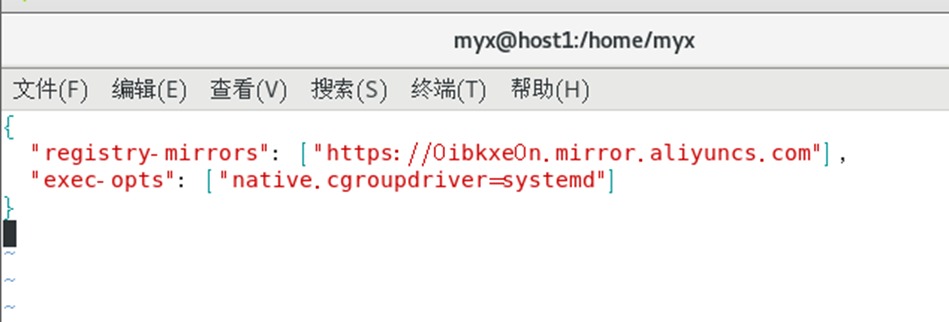
4) Unifique el controlador Cgroup de Kubernetes y Docker como systemd,
modifique el archivo /etc/docker/daemon.json y agregue los siguientes parámetros :
vim /etc/docker/daemon.json
# Para mantener consistente la configuración de la ventana acoplable de todos los nodos, también se han cambiado las ventanas acoplables de otros nodos.
{
"registry-mirrors": ["https://b9pmyelo.mirror.aliyuncs.com"],
"exec-opts": ["native.cgroupdriver=systemd"]
}
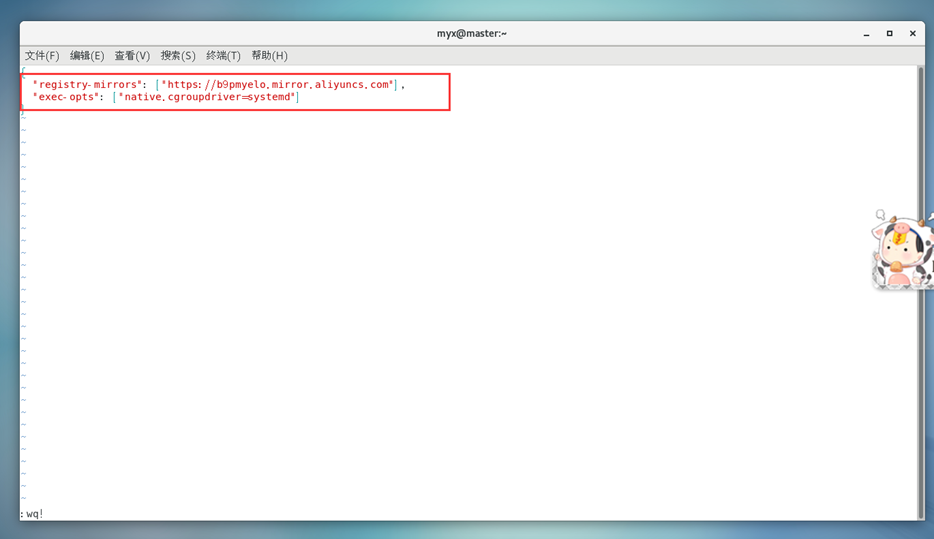
recargar la ventana acoplable
systemctl daemon-reload
systemctl restart docker
5. Antes de inicializar la inicialización de Kubernetes en el nodo maestro, ejecute:
systemctl restart docker

finalización del comando kubelet
echo "source <(kubectl completion bash)" >> ~/.bash_profile
source .bash_profile


Extraer imagen
Muestra la lista de imágenes necesarias para el inicio del clúster de Kubernetes. Estas imágenes incluyen componentes del plano de control (como kube-apiserver, kube-controller-manager y kube-scheduler) y otros componentes necesarios (como etcd, CoreDNS, etc.) y modifican la etiqueta para que sea coherente con la versión requerida.
.
kubeadm config images list

Establecer fuente espejo y programa de script
vim image.sh
#!/bin/bash
url=registry.cn-hangzhou.aliyuncs.com/google_containers
version=v1.14.2
images=(`kubeadm config images list --kubernetes-version=$version|awk -F '/' '{print $2}'`)
for imagename in ${images[@]} ; do
docker pull $url/$imagename
docker tag $url/$imagename k8s.gcr.io/$imagename
docker rmi -f $url/$imagename
done
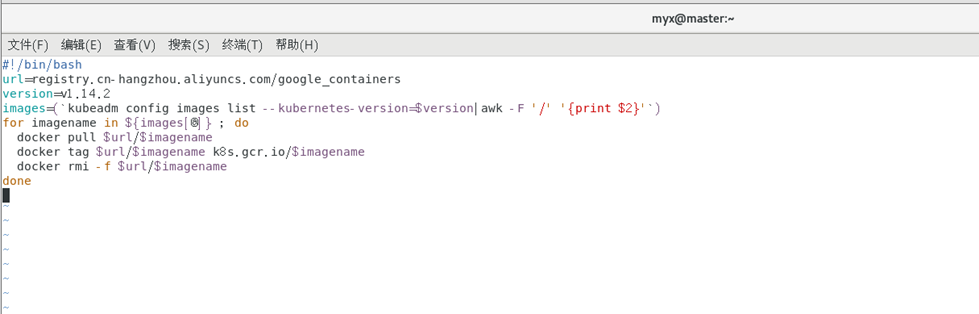
ejecutar guión
chmod u+x image.sh
./image.sh
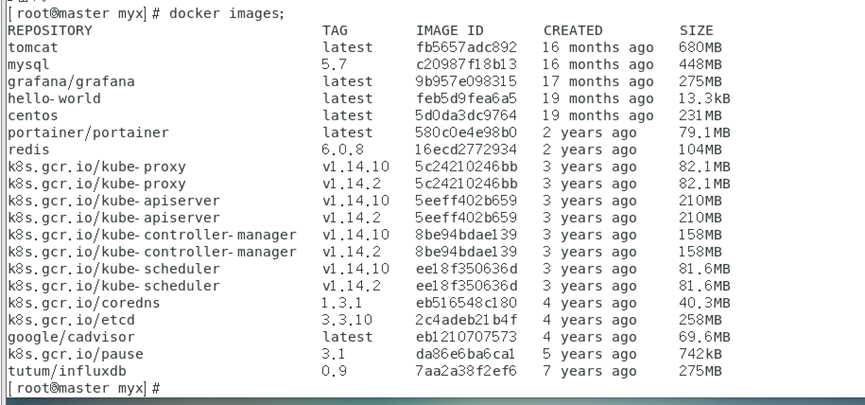
docker images
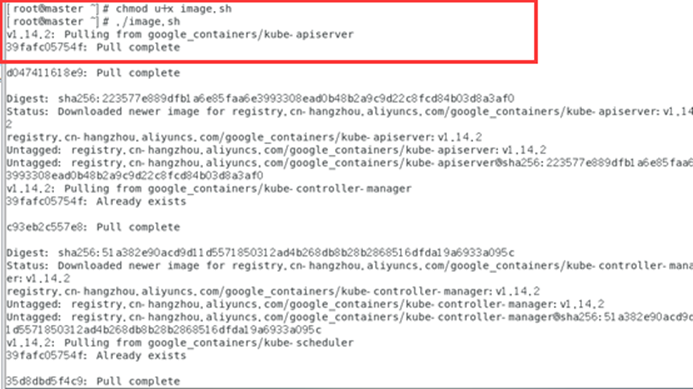
imágenes de Docker Verifique las imágenes en el almacén de Docker y descubra que todas las imágenes comienzan con registro.aliyuncs.com/google_containers/, y algunas de ellas son diferentes de los nombres de imágenes requeridos en la lista de imágenes de configuración de kubeadm. Queremos modificar el nombre de la imagen, es decir, volver a etiquetar la imagen.
docker images
Mostrar resultados:
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver:v1.14.10 k8s.gcr.io/kube-apiserver:v1.14.10
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager:v1.14.10 k8s.gcr.io/kube-controller-manager:v1.14.10
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler:v1.14.10 k8s.gcr.io/kube-scheduler:v1.14.10
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy:v1.14.10 k8s.gcr.io/kube-proxy:v1.14.10
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.1 k8s.gcr.io/pause:3.1
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/etcd:3.3.10 k8s.gcr.io/etcd:3.3.10
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:1.3.1 k8s.gcr.io/coredns:1.3.1
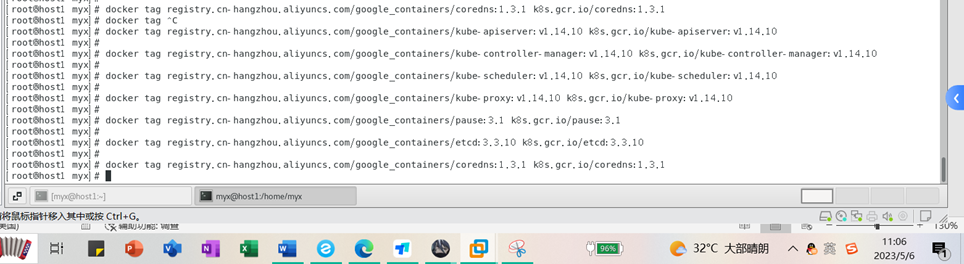
Después de modificar la etiqueta, verifique nuevamente y descubra que el nombre de la imagen y el número de versión son consistentes con la lista de imágenes requeridas para el inicio del clúster de Kubernetes que figura en el comando "kubeadm config images list".
De otra forma también podemos sacar las imágenes una por una.
kubeadm config images list

docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver:v1.40.10
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager:v1.40.10
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler:v1.40.10
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy:v1.40.10
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.1
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/etcd:3.3.10
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:1.3.1

Vea la imagen de la ventana acoplable nuevamente:
docker images
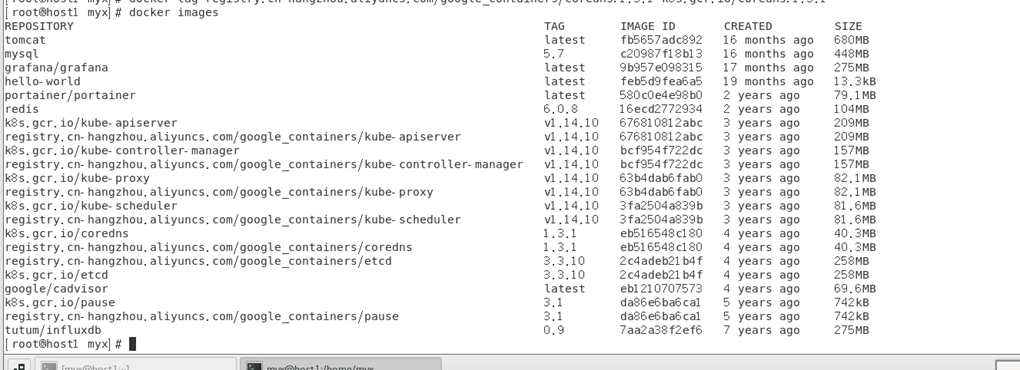
Restablecer el clúster k8s
kubeadm reset
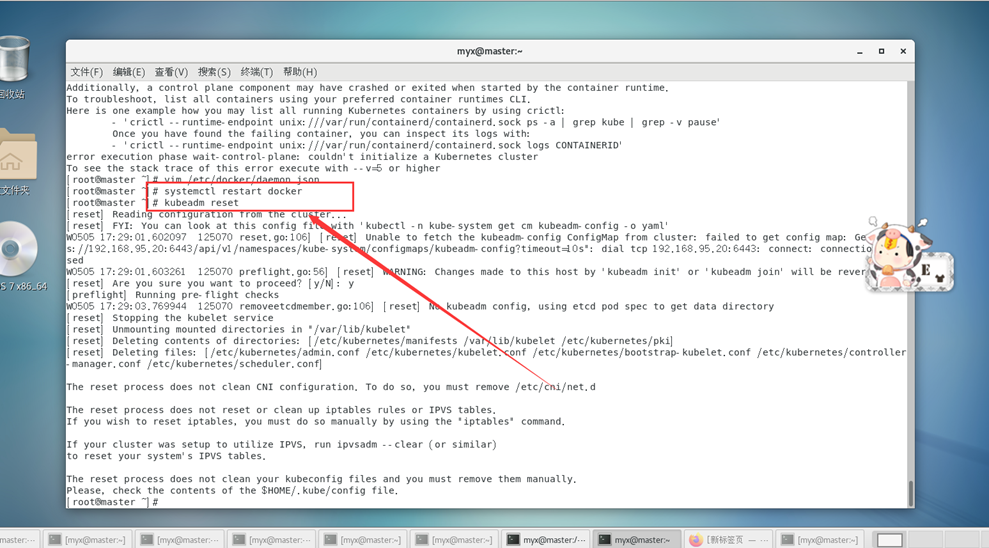
Para liberar la ocupación del puerto, elimine el archivo de configuración generado durante la inicialización anterior, etc.
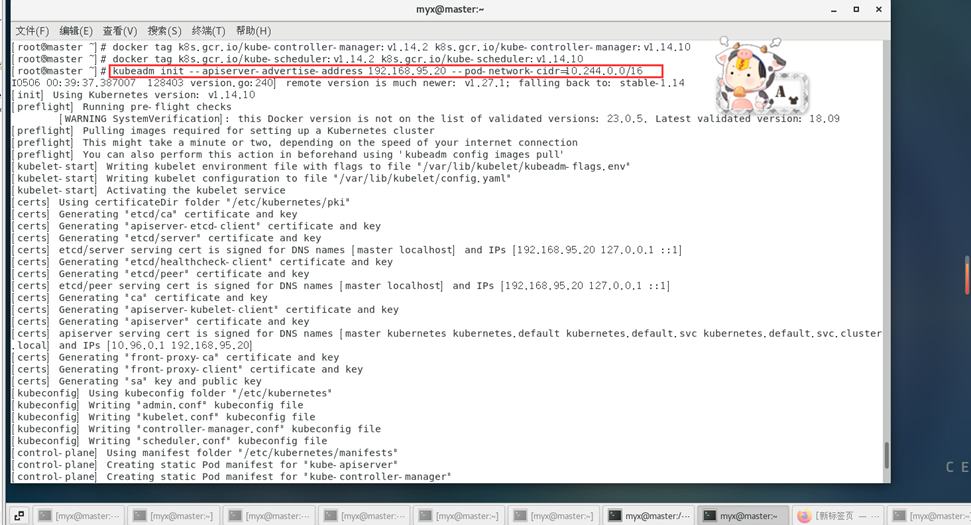
Luego comience a ejecutar formalmente la inicialización del clúster:
kubeadm init --apiserver-advertise-address 192.168.95.20 --pod-network-cidr=10.244.0.0/16
Aparece un mensaje de ejecución: Your Kubernetes control-plane has initialized successfully!La inicialización del clúster se completó correctamente.
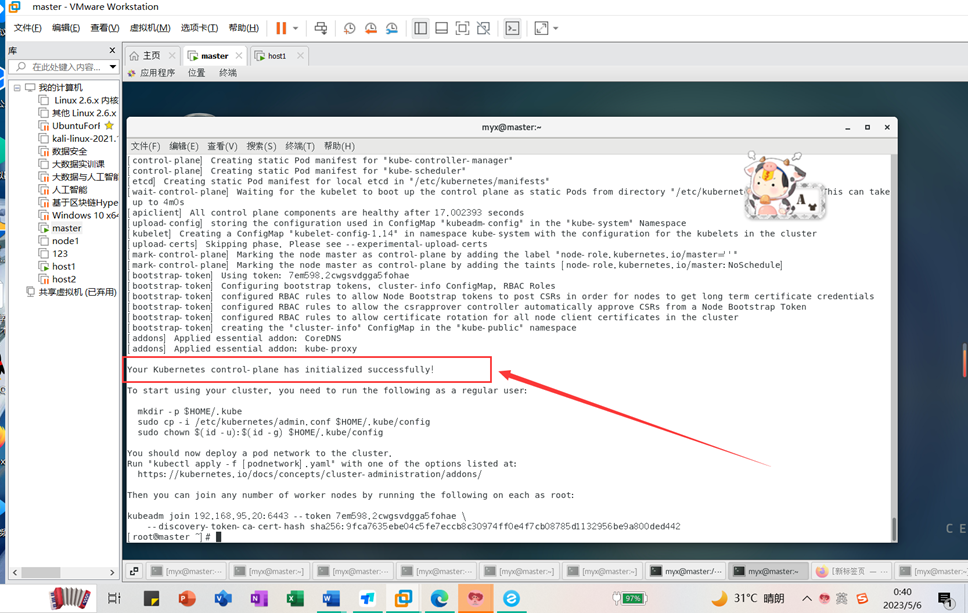

6. Configure el nodo.
Los siguientes 3 comandos utilizan usuarios normales:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
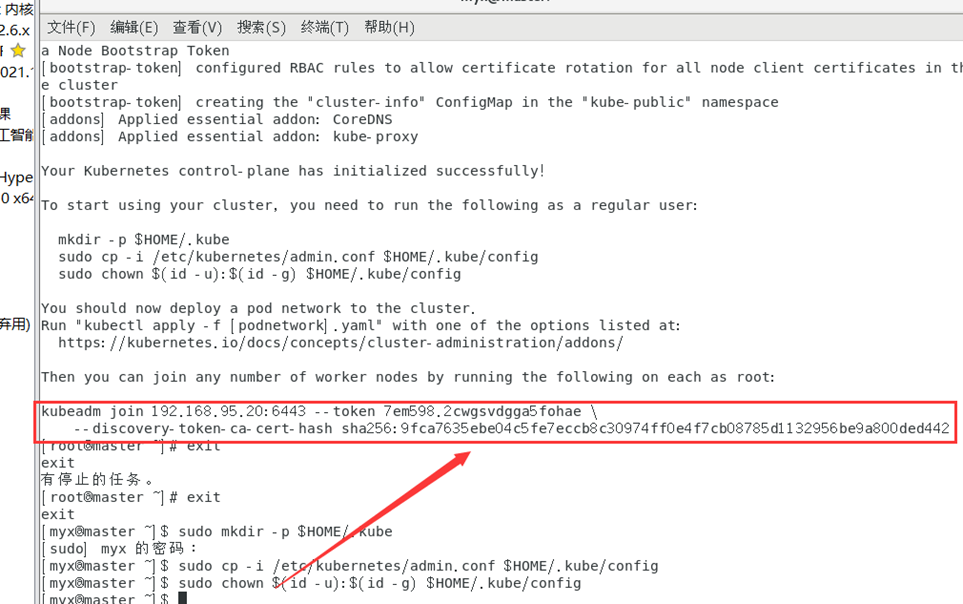
7. Preste atención al comando y la clave secreta al unirse desde el nodo.
kubeadm join 192.168.95.20:6443 --token 7em598.2cwgsvdgga5fohae \
--discovery-token-ca-cert-hash sha256:9fca7635ebe04c5fe7eccb8c30974ff0e4f7cb08785d1132956be9a800ded442
Mantenga esta clave en un lugar seguro.
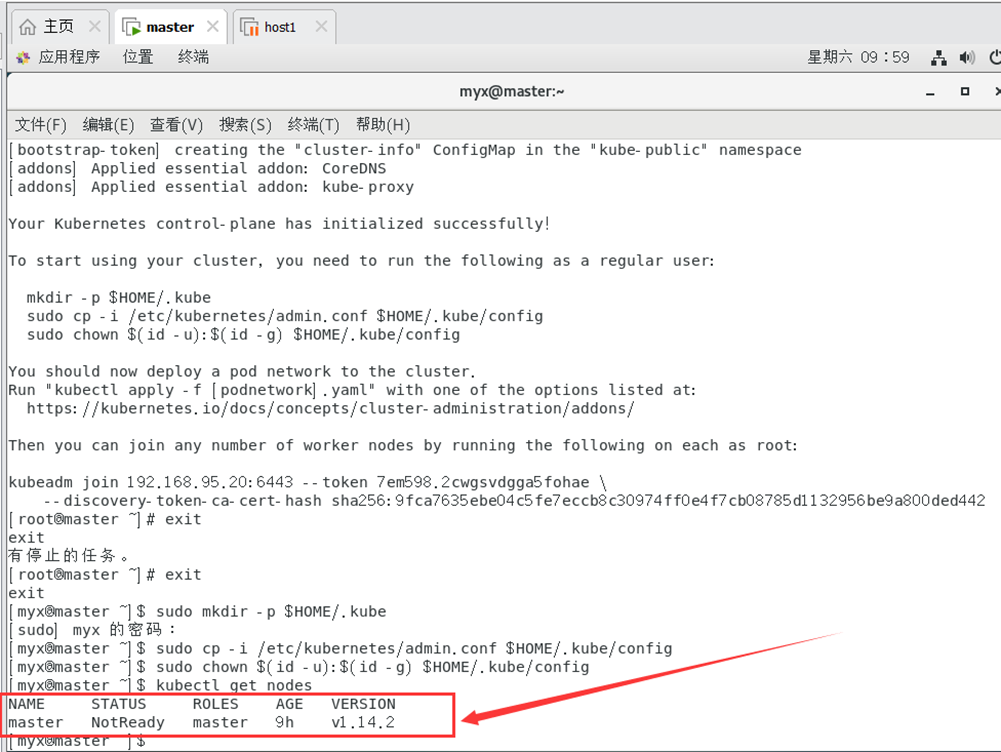
8. Verifique el estado de ejecución del nodo (estado NotReady)
kubectl get nodes
3. Instalar y configurar el nodo esclavo Kubernetes
1. Instale el software del nodo esclavo y configúrelo según el primer y segundo paso anteriores.
Configuración básica de host1:
versión acoplable
Kubectl version
kubeadm version
kubelet version
2. Únase al clúster desde el nodo (use el usuario raíz)
kubeadm join 192.168.95.20:6443 --token 7em598.2cwgsvdgga5fohae \
--discovery-token-ca-cert-hash sha256:9fca7635ebe04c5fe7eccb8c30974ff0e4f7cb08785d1132956be9a800ded442
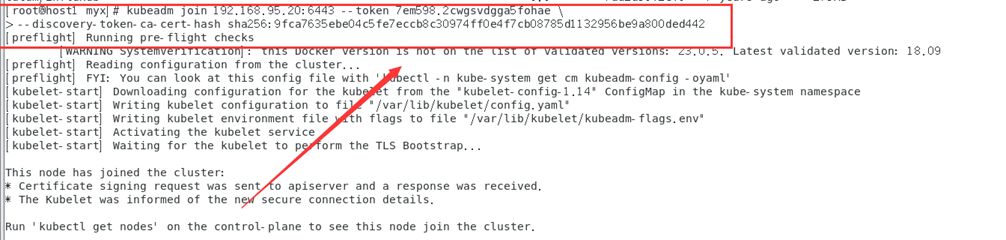
Nota: Este paso generalmente encuentra los siguientes problemas:
[ERROR CRI]: container runtime is not running:
Esto se debe a que el contenedor instalado con un subpaquete lo deshabilitará como tiempo de ejecución del contenedor de forma predeterminada:
Solución:
1) Utilice systemctl status containerdVer estado
activo: activo (en ejecución) para indicar que el contenedor se está ejecutando normalmente.
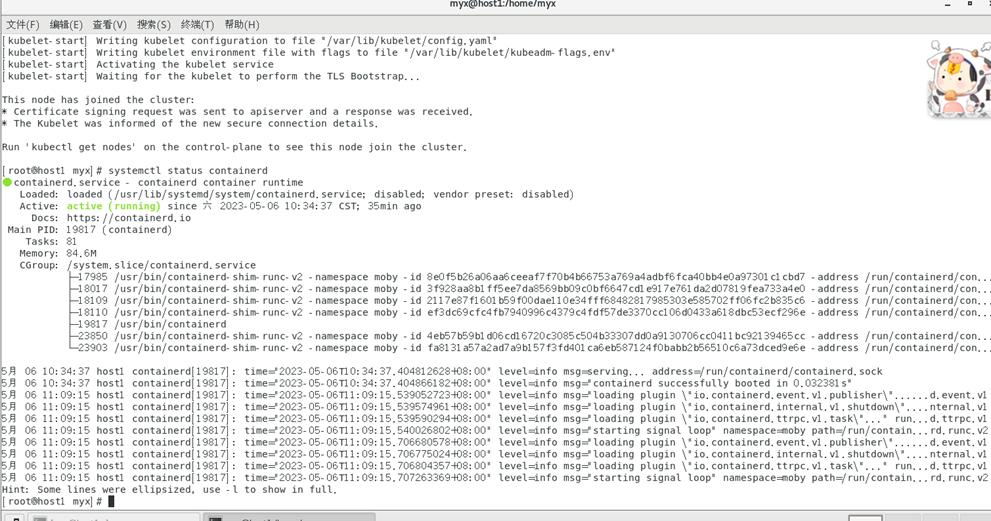
2) Verifique /etc/containerd/config. archivo toml, este es el archivo de configuración cuando el contenedor se está ejecutando
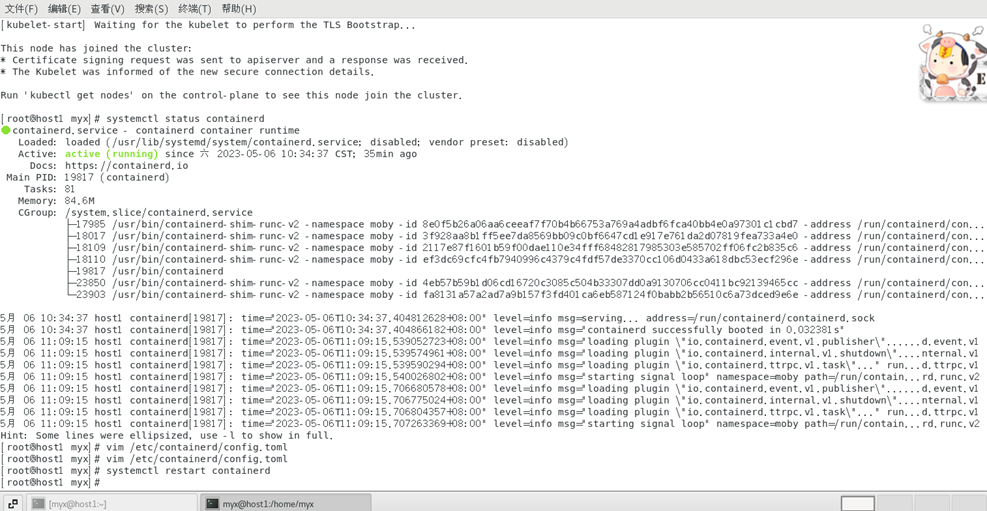
3)
vim /etc/containerd/config.toml
Si ve esta línea :disabled_plugins : ["cri"],
comente esta línea con # o elimine "cri":
#disabled_plugins: [“cri”]
odisabled_plugins: []
4) Reinicie el tiempo de ejecución del contenedor
systemctl restart containerd
Referencia 3: https://blog.csdn.net/weixin_52156647/article/details/129758753
4. Ver los nodos esclavos unidos en el nodo maestro y resolver problemas posteriores
kubectl get nodes

1. En este momento, ESTADO muestra
la solución NotReady:
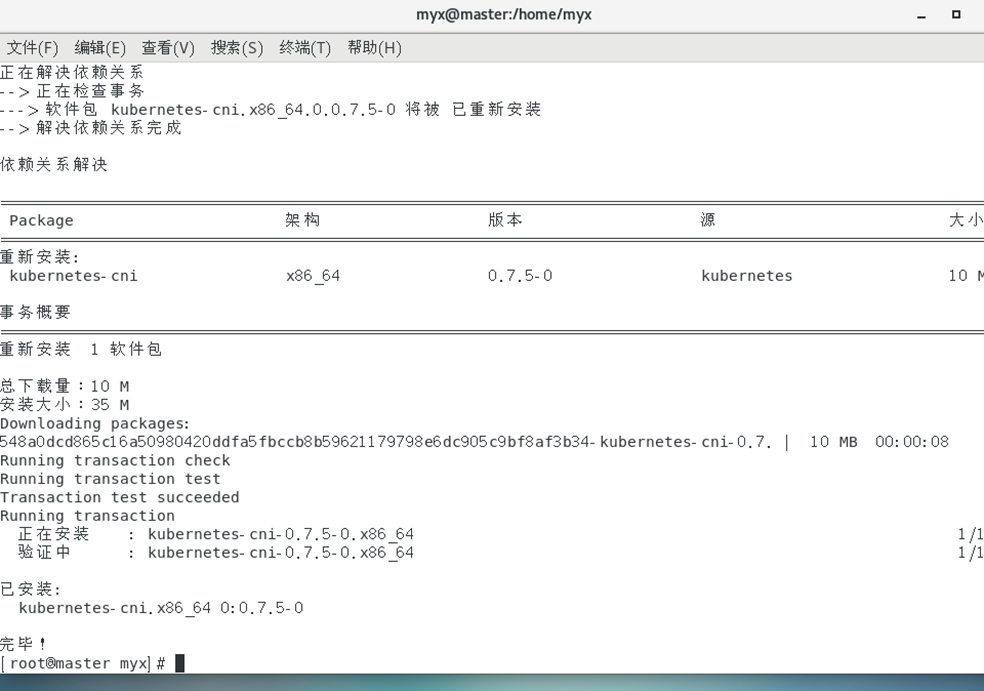
1) Reinstale kubernetes-cni en todos los nodos del clúster:
yum reinstall -y kubernetes-cni
2) Instale la red en el nodo maestro:
kubectl apply -f https://raw.githubusercontent.com/flannel-io/flannel/master/Documentation/kube-flannel.yml, donde 185.199.108.133 raw.githubusercontent.com Agregar etc/hosts
(Referencia 5: https://www.cnblogs.com/sinferwu/p/12726833.html )
3. Problemas al ejecutar kubectl get nodes
1) no se pudo obtener la lista de grupos de API del servidor actual:
resuelto:
el comando no puede ejecutarse como root.
2) problema de kubernetes-admin
La entrada de K8S muestra kubectl obtener nodos La conexión al servidor localhost:8080 fue rechazada - ¿especificó el host o puerto correcto? La razón
de este problema es que el comando kubectl debe ejecutarse con kubernetes-admin . Puede deberse a un entorno del sistema sucio, como no borrar completamente la configuración antes de reinstalar k8s.
Solución:
(1) Copie el archivo /etc/kubernetes/admin.conf generado después de que se inicializa el nodo maestro en el directorio correspondiente del nodo esclavo.
scp /etc/kubernetes/admin.conf host1:/etc/kubernetes/

(2) Establecer variables de entorno en todos los nodos y actualizar
echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
source ~/.bash_profile


Verifique la IP real de raw.githubusercontent.com en https://www.ipaddress.com/.
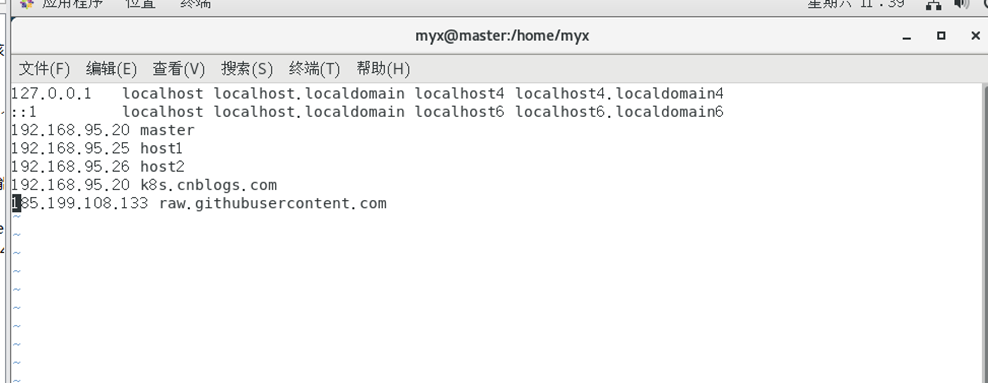
corre de nuevo
kubectl apply -f https://raw.githubusercontent.com/flannel-io/flannel/master/Documentation/kube-flannel.yml
¡Instale la franela con éxito!

Cuando la lista de nodos del clúster se obtiene nuevamente mediante el comando kubectl get nodes, se descubre que el estado del clúster host1 siempre está en el estado NotReady y se informa un error al verificar el registro:
journalctl -f -u kubelet
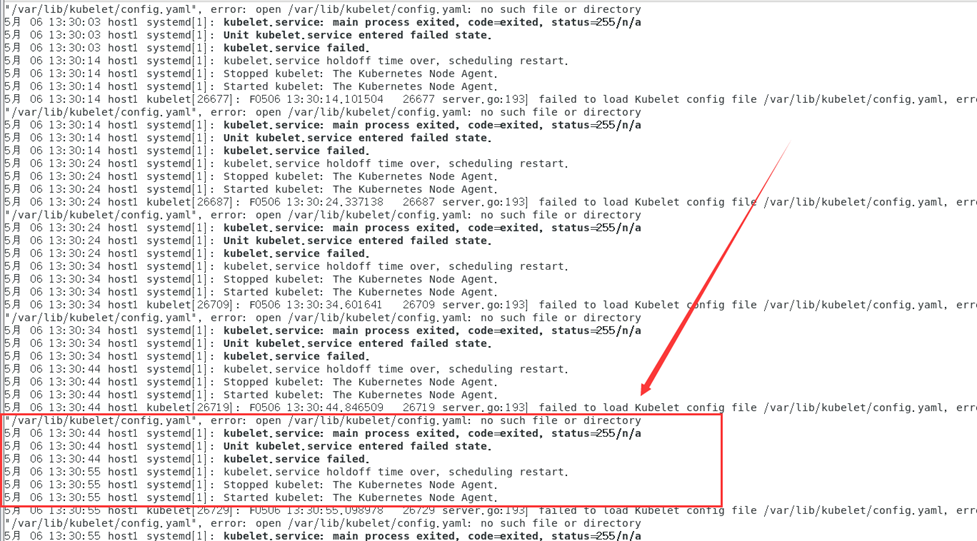
Según la información del registro, el motivo del error es que la configuración de kubelet no se puede descargar desde /var/llib/kubelet/config.yaml.
El motivo del error probablemente sea que lo ejecuté sin realizar kubeadm init antes systemctl start kubelet.
Podemos intentar actualizar el token y regenerarlo, el código es el siguiente:
kubeadm token create --print-join-command
Actualice el contenido de la salida de la copia del token en el nodo maestro g

y ejecútelo en hsot1
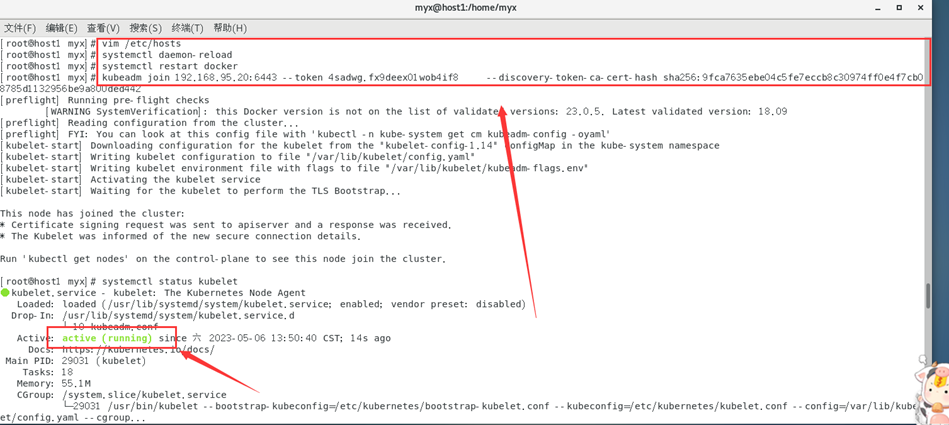
para resolver el problema con éxito.
¡Todos los grupos están en estado Listo!

Referencia seis: https://www.cnblogs.com/eastwood001/p/16318644.html
5. Pruebe Kubernetes
1. Ejecute en el nodo maestro:
kubectl create deployment nginx --image=nginx #创建一个httpd服务测试

kubectl expose deployment nginx --port=80 --type=NodePort #端口就写80,如果你写其他的可能防火墙拦截了

kubectl get svc,pod #对外暴露端口

2. Acceda a la página de inicio de Nginx utilizando la dirección IP del nodo maestro y el puerto reservado:
por ejemplo:
192.168.95.20:21729
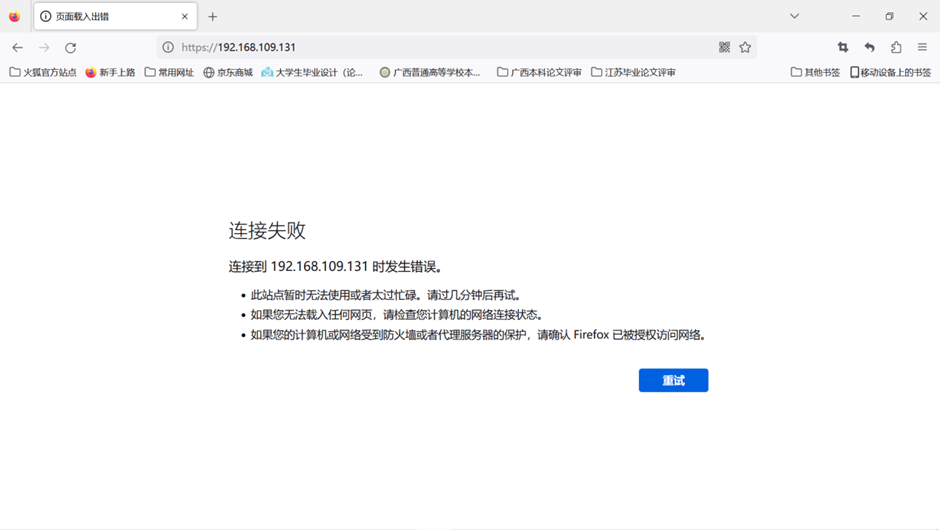
mostrar conexión fallida
usando el comando
kubectl describe pod nginx-77b4fdf86c-krqtk
Mostrar resultados:
open /run/flannel/subnet.env: no such file or directory
Descubrí que me faltaban los archivos de configuración de red cni relevantes.
Necesitamos verificar cada nodo cuidadosamente, incluido si existe el nodo principal /run/flannel/subnet.env. El contenido debe ser similar al siguiente:
FLANNEL_NETWORK=10.244.0.0/16
FLANNEL_SUBNET=10.244.0.1/24
FLANNEL_MTU=1450
FLANNEL_IPMASQ=true
Al verificar el registro de errores, descubrí que me falta el archivo de configuración de red cni relevante.
Cree archivos de configuración relacionados con la red cni:
mkdir -p /etc/cni/net.d/
cat <<EOF> /etc/cni/net.d/10-flannel.conf
{
"name":"cbr0","type":"flannel","delegate": {
"isDefaultGateway": true}}
EOF
Aquí usamos el comando cat y el operador de redirección (<<) para escribir {"name": "cbr0", "type": "flannel", "delegate": {"isDefaultGateway": true}} en / etc/cni /net.d/10-flannel.conf.
mkdir /usr/share/oci-umount/oci-umount.d -p
mkdir /run/flannel/
cat <<EOF> /run/flannel/subnet.env
FLANNEL_NETWORK=10.199.0.0/16
FLANNEL_SUBNET=10.199.1.0/24
FLANNEL_MTU=1450
FLANNEL_IPMASQ=true
EOF
Aquí, entre <<EOF y EOF, hay varias líneas de texto y cada línea contiene la definición de una variable de entorno. Específicamente:
FLANNEL_NETWORK=10.199.0.0/16 define una variable de entorno denominada FLANNEL_NETWORK y la establece en 10.199.0.0/16.
FLANNEL_SUBNET=10.199.1.0/24 define una variable de entorno denominada FLANNEL_SUBNET y la establece en 10.199.1.0/24.
FLANNEL_MTU=1450 define una variable de entorno llamada FLANNEL_MTU y la establece en 1450.
FLANNEL_IPMASQ=true define una variable de entorno llamada FLANNEL_IPMASQ y la establece en verdadero.
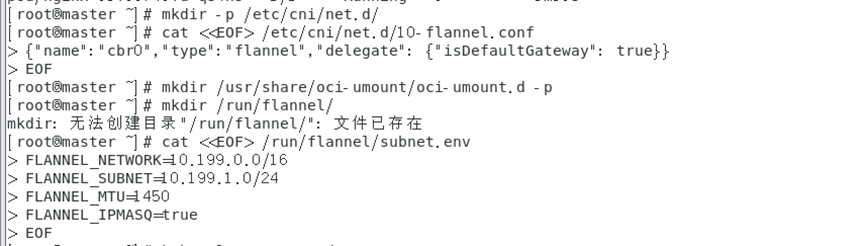
Si algún nodo no tiene el archivo, cópielo e impleméntelo nuevamente. Este error no debería informarse.
Comprobémoslo en el nodo host1:
cat /run/flannel/subnet.env
cat /etc/cni/net.d/10-flannel.conf

A través del comando, puede ver que el nodo esclavo ya tiene archivos de configuración relacionados con la red cni.
Si faltan estos archivos de configuración importantes, los errores también se informarán en el registro del clúster:
cni config uninitialized
5月 06 12:44:06 master kubelet[48391]: W0506 12:44:06.599700 48391 cni.go:213] Unable to update cni config: No networks found in /etc/cni/net.d
5月 06 12:44:07 master kubelet[48391]: E0506 12:44:07.068343 48391 kubelet.go:2170] Container runtime network not ready: NetworkReady=false reason:NetworkPluginNotReady message:docker: network plugin is not ready

Si no hay ningún problema con la configuración anterior,
nginx se muestra correctamente al final.
Kubectl get nodes
El comando kubectl get nodes aquí devolverá una tabla que contiene información sobre todos los nodos del clúster, como el nombre del nodo, el estado, la función (maestro/trabajador), etc.

entrada de URL del navegador
192.168.95.25:30722

O ingrese CLUSTER-IP:
10.100.184.180

De esta manera, implementamos con éxito el clúster de Kubernetes y completamos la implementación de nginx.
Todos estos se han probado personalmente y se pueden implementar con éxito de acuerdo con las operaciones normales anteriores. Les deseo todo lo mejor.
Por último, te deseo todo lo mejor en las vacaciones de verano, estudies sólida y exhaustivamente y te diviertas.