introducción
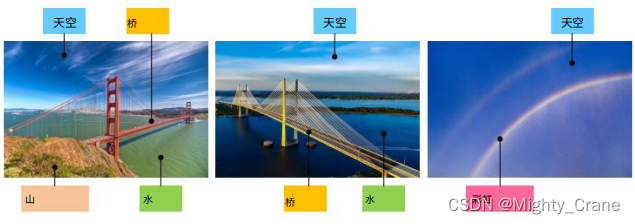
El hash tradicional existente se considera siempre que al menos una etiqueta coincida, por lo que en el ejemplo que se muestra en la figura, tanto ab como ac se consideran coincidentes, lo que hace imposible que top1 clasifique la similitud de los pares de etiquetas múltiples, por lo que
el la semántica de cada imagen Las etiquetas proponen una definición suave de similitud por pares. Específicamente, las similitudes por pares se cuantifican como porcentajes utilizando etiquetas semánticas normalizadas. (contribución: 1)
Así que se proponen dos similitudes. La similitud dura considera que todas las etiquetas coinciden, por lo que se usa el aprendizaje de entropía cruzada; la similitud suave considera la coincidencia parcial de etiquetas, por lo que se usa el error cuadrático medio (contribución 2)
trabajo relacionado
Un enfoque simple para el aprendizaje profundo de hash es umbralizar directamente las características de alto nivel, tipificadas por DLBHC [46], que aprende la representación de hash de clase. Si bien la red está bien afinada en la tarea de clasificación, las características de la capa hash latente
se consideran discriminatorias, lo que de hecho muestra un mejor rendimiento que las características hechas a mano.(也就是说deephash比特征工程好,但相比起直接deep,直接Alexnet或者传统hash效果咋样呢)
Para la recuperación de etiquetas múltiples, DSRH [25] intenta utilizar la información de clasificación de similitudes de niveles múltiples para aprender una función hash y propone una pérdida de proxy para resolver el problema de optimización de las medidas de clasificación. IAH [47] se centra en el aprendizaje de representaciones de imágenes conscientes de instancias y utiliza una pérdida de triplete ponderada para mantener clasificaciones de similitud para imágenes de etiquetas múltiples. Sin embargo, las funciones de pérdida de triplete ponderado empleadas por DSRH [25] e IAH [47] no imponen restricciones directas sobre el aprendizaje de similitud semántica multinivel de grano fino , ya que se centran en mantener la clasificación correcta de imágenes de acuerdo con su similitud con el consulta(也就是说一直在纠结于损失函数,而没有针对多标签相似度的痛点来解决问题吧)
En base a esto, DMSSPH [48] intenta construir una función hash para maximizar la discriminabilidad del espacio de salida con el fin de preservar la similitud multinivel entre imágenes multietiqueta. Aunque DMSSPH [48] ha explotado la similitud semántica multinivel de grano fino para el aprendizaje de similitud por pares, todavía hay espacio para una mayor exploración. En [36] se propone un enfoque TALR novedoso y eficiente, que considera clasificaciones vinculadas sobre distancias de Hamming de valores enteros y optimiza directamente las métricas de evaluación basadas en clasificación Precisión promedio (MAP) [49] y Ganancia acumulativa descontada normalizada (NDCG) [50 ]. Logra un alto rendimiento en varios conjuntos de datos de referencia. En [51], se proponen dos nuevos protocolos para evaluar métodos hash supervisados en el contexto del aprendizaje por transferencia.
En este documento, exploramos la diversidad de la similitud semántica por pares en conjuntos de datos de etiquetas múltiples para mejorar la calidad del hash. Específicamente, los valores de similitud por pares de grano fino se definen de forma continua (将离散的汉明距离改成连续值?). Entonces, la similitud por pares se divide en dos casos, y se construye una función de pérdida conjunta por pares para realizar simultáneamente el aprendizaje de características y la generación de código hash.
método
Para examinar la similitud de múltiples etiquetas, la etiqueta cuantitativa es un porcentaje de valor continuo, es decir, la similitud del coseno de los vectores de etiquetas semánticas de las dos imágenes (este artículo es el primero en usar la distancia del coseno para cuantificar la precisión). similitud semántica granular de imágenes emparejadas)
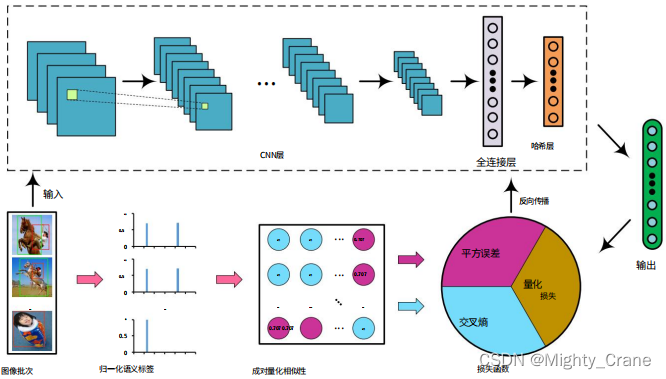
La imagen pasa a través de Alexnet y la salida de la capa fc8 final se asigna a (-1,1) a través de la siguiente función de activación(提到本文的Alexnet是可以随意替换成vgg、Googlenet等,所以为啥这俩更新的网络不如初号机有啥说道吗)
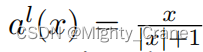
similitud dura
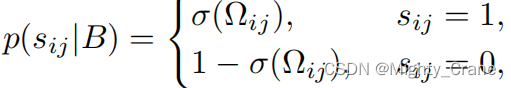
donde Ω es el producto interno de los dos códigos hash
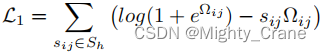
similitud suave
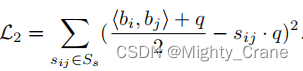
aprendizaje conjunto
Para aprender ambos casos simultáneamente y formar una forma unificada, Mij se usa para etiquetar los dos casos, donde Mij = 1 indica el caso de "similitud fuerte" y Mij = 0 indica el caso de "similitud suave". Por lo tanto, la pérdida de similitud por pares se reescribe como:(这不其实就是那俩损失函数结合嘛)
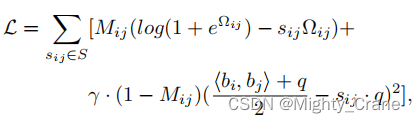
La optimización directa de la ecuación es un desafío. Debido a que la restricción binaria bi ∈ {−1, 1} q requiere umbralizar la salida de la red, esto puede conducir a un problema de gradiente de desaparición en la retropropagación durante el entrenamiento.
Pérdida de cuantificación por pares escalada

La pérdida final es C = L + λQ
experimento
Actuación
Ganancia acumulada promedio (ACG) [60],
ganancia acumulada descontada normalizada (NDCG) [50], media
Precisión media (MAP) [49] y Precisión media ponderada (WAP) [25].
Con respecto a la función de pérdida de hash, asigna datos de alta dimensión a códigos binarios de baja dimensión para mejorar la velocidad y la eficiencia de la recuperación de datos.
La entrada consta de cuatro parámetros:
D: Representa la matriz de vectores propios de la muestra, con forma(batch_size, feature_dim).label: Representa la matriz vectorial etiqueta de la muestra, la forma es(batch_size, num_class), dondenum_classrepresenta el número de categorías.alpha,beltaygama: representan los coeficientes de peso de los tres elementos de pérdida.m: Indica la longitud del código hash.
Específicamente, esta función de pérdida de hash consta de tres partes: pérdida de similitud de coseno , restricción de longitud de código de hash y término de regularización . Entre ellos, la pérdida de similitud de coseno puede coincidir con el código hash comparando la similitud de coseno entre los pares de muestras,
primero calcule la matriz de similitud de coseno de la etiqueta
label_count = tf.expand_dims(tf.sqrt(tf.reduce_sum(tf.square(label), 1)),1)
# 标签向量的模长
norm_label = label/tf.tile(label_count,[1,args.num_class])
# 标签向量的单位向量
w_label = tf.matmul(norm_label, norm_label, False, True)
# 标签向量之间的余弦相似度矩阵
semi_label = tf.where(w_label>0.99, w_label-w_label,w_label)
# 将大于阈值0.99的相似度设置为0后的相似度矩阵
Luego calcule la similitud del coseno de las muestras.
p2_distance = tf.matmul(D, D, False, True)
La restricción de longitud del código hash puede garantizar que la longitud del código hash no supere el valor especificado. En la implementación, necesitamos calcular el código hash de la muestra y compararlo con la longitud del código hash especificado para obtener la pérdida de restricción de longitud del código hash.
scale_distance = belta * p2_distance / m
# 对距离矩阵进行缩放后的值
temp = tf.log(1+tf.exp(scale_distance))
loss = tf.where(semi_label<0.01,temp - w_label * scale_distance, gama*m*tf.square((p2_distance+m)/2/m-w_label))
regularizer = tf.reduce_mean(tf.abs(tf.abs(D) - 1))
d_loss = tf.reduce_mean(loss) + alpha * regularizer
De esta manera, la restricción de longitud del código hash C=L+αQ en el documento puede garantizar que la longitud del código hash no supere el valor especificado, y el término de regularización puede ayudar al modelo a evitar el sobreajuste.
La salida de esta función consta de dos valores:
d_loss: Indica el valor total de pérdida de hash.w_label: Representa la matriz de similitud de coseno entre etiquetas, con forma de(batch_size, batch_size).
En la implementación de la función, las etiquetas de muestra primero se estandarizan y luego se calcula la matriz de similitud de coseno entre las etiquetas, y la similitud mayor que el umbral se establece en 0. A continuación, calcule la matriz de similitud de coseno entre las muestras y asigne la matriz de distancia a un rango de valores entre 0 y 1. Finalmente, se calculan tres elementos de pérdida y su suma ponderada se toma como el valor total de pérdida de hash.
principal
La función de este código es leer los datos en el archivo tfrecord, construir el modelo de AlexNet, calcular la pérdida de hash ( d_loss) y usar el optimizador para el entrenamiento.
Específicamente, primero reader.read_and_decodelea los datos del archivo tfrecord a través de la función (这个在tf2版本里要大改了,需要换成data相关函数)y obtenga un conjunto de imágenes ( img) y sus etiquetas correspondientes ( label). Luego use tf.train.shuffle_batchla función para mezclar las imágenes y etiquetas leídas para formar un args.batch_sizelote de tamaño, que se usa para entrenar el modelo.
Luego, use AlexNetla función para construir el modelo de AlexNet y tome los datos de la imagen en el lote como entrada y obtenga una salida D. Esta salida contiene el código hash correspondiente a cada imagen.(哈希码的维度由num_bits控制)
Luego, use hashing_lossla función para calcular la pérdida de hash y tome el valor de salida Dy el valor de la etiqueta label_batchcomo parámetros de entrada. Entre ellos, args.alpha, args.beltay args.gamase encuentran los hiperparámetros, que controlan el peso de la pérdida de similitud, la restricción de longitud del código hash y el término de regularización, respectivamente.
Finalmente, se devuelven la pérdida de hash calculada ( d_loss) y la salida del modelo ( ).out
A continuación, optimice el proceso de formación:
- Según las skip_layers especificadas, todas las variables entrenables se dividen en dos categorías: var_list1 y var_list2. Entre ellos, var_list1 incluye todas las variables que necesitan un ajuste fino y var_list2 incluye todas las variables que necesitan ser entrenadas desde cero.
- Defina learning_rate y establezca el decaimiento exponencial.
- Defina dos optimizadores Adam: opt1 y opt2. Entre ellos, la tasa de aprendizaje de opt1 es learning_rate*0.01, que se usa para optimizar las variables en var_list1; la tasa de aprendizaje de opt2 es learning_rate, que se usa para optimizar las variables en var_list2.
- Calcula los grados de gradiente para todas las variables y divide los grados en dos partes: grados 1 y grados 2 según var_list1 y var_list2.
- Use opt1 y opt2 para optimizar los gradientes en grads1 y grads2 respectivamente, y actualice global_step.
- Combine las operaciones de actualización de los dos optimizadores en un solo tren_op.
Por lo tanto, se realiza el proceso de entrenamiento de todo el modelo y se actualizan los gradientes de los dos tipos de variables a través de diferentes optimizadores, realizando así dos métodos de entrenamiento diferentes de ajuste fino y entrenamiento desde cero.
En el ciclo de entrenamiento, el Nodo en el gráfico de cálculo de TensorFlow (Graph) se ejecuta a través del objeto session (Session).
Primero, se define un objeto Saver para guardar el modelo entrenado. A continuación, utilice sess.runel método para inicializar las variables globales y locales, y para cargar los pesos del modelo previamente entrenados en la red. Luego, inicie el subproceso de la cola del conjunto de datos (这个应该只能用在tf1中,tf2就尬住了)e ingrese al ciclo de entrenamiento.
En el ciclo de entrenamiento, sess.runse ejecutan tres nodos a través del método, a saber, train_op(nodo de entrenamiento), d_loss(nodo de pérdida) y global_step(nodo de pasos globales). Entre ellos, train_opestá el nodo de operación que aplica el gradiente calculado a la variable, y el valor de retorno es Ninguno, d_losses el nodo que calcula la pérdida, y el valor de retorno es un escalar, global_stepes una variable, y su valor se incrementa por uno cada vez que se ejecuta el nodo de entrenamiento.
Durante el proceso de entrenamiento, se step1 % 10 == 0controla para generar información de entrenamiento cada 10 iteraciones, incluido el número de iteración actual (paso 1), el valor de pérdida (loss_t) y el tiempo que consume (elapsed_time). Úselo para controlar guardar el modelo step1 % args.save_freq == 0cada iteración veces. args.save_freqCuando se han recorrido todas las muestras del conjunto de datos, finaliza el entrenamiento. Finalmente, detenga el hilo de la cola y salga de la sesión.
Con respecto a alexnet, el método de convolución es similar a caffe, cuando los grupos son iguales a 1, la operación de convolución se realiza directamente, cuando los grupos son mayores a 1, la entrada y el kernel de convolución se agrupan según el número de grupos, y la operación de convolución se realiza por separado y finalmente se combina el resultado. Los resultados finales de salida se procesan mediante polarización, activación de ReLU, etc. (grupos: el número de grupos para la convolución de grupo, el valor predeterminado es 1)