Introducción: Apache Flink es un marco y un motor de procesamiento distribuido para el cálculo con estado en flujos de datos ilimitados y limitados. Este artículo comienza principalmente con casos reales y combina la experiencia práctica del autor para compartir con los lectores cómo lograr el equilibrio de carga dinámico de clústeres heterogéneos a través de subprocesos múltiples personalizados de Flink cuando los clústeres heterogéneos no pueden lograr el equilibrio de carga en escenarios de aplicaciones.
● 1. Prefacio
● 2. Problemas y soluciones
● 2.1 Algo salió mal
● 2.2 Ideas de análisis
● 2.3 Soluciones
● 3. Arquitectura Técnica
● 4. Eficacia de la construcción
● 5. Conclusión
prefacio
En escenarios de aplicaciones informáticas en tiempo real, a menudo hay requisitos de llamadas en tiempo real para clústeres heterogéneos.Cuando los servicios de clústeres heterogéneos no pueden lograr el equilibrio de carga debido a la configuración de la máquina, la carga del nodo, etc. Equilibrio de carga dinámico para clústeres heterogéneos.
Aquí hay un ejemplo:
Los requisitos de producción de funciones, como la identificación de contenido de texto, la identificación de contenido de imagen y el OCR de imagen, deben interactuar con clústeres heterogéneos basados en la implementación de GPU. Si la configuración de las máquinas del clúster de GPU no se puede unificar, se producirá un desequilibrio de carga. Es decir: algunos nodos en un clúster de GPU procesan rápido y algunos nodos procesan lentamente, y los nodos de procesamiento lento a menudo provocan una gran cantidad de excepciones de tiempo de espera, lo que provoca la contrapresión de todo el trabajo.
Su diagrama de flujo es el siguiente:
Con la ayuda de las ventajas inherentes distribuidas de Flink, llamamos al servicio modelo a través de Thrift RPC en la tarea, obtenemos el resultado en tiempo real y luego lo escribimos en la ingeniería de funciones, para construir la función y generar el enlace completo.
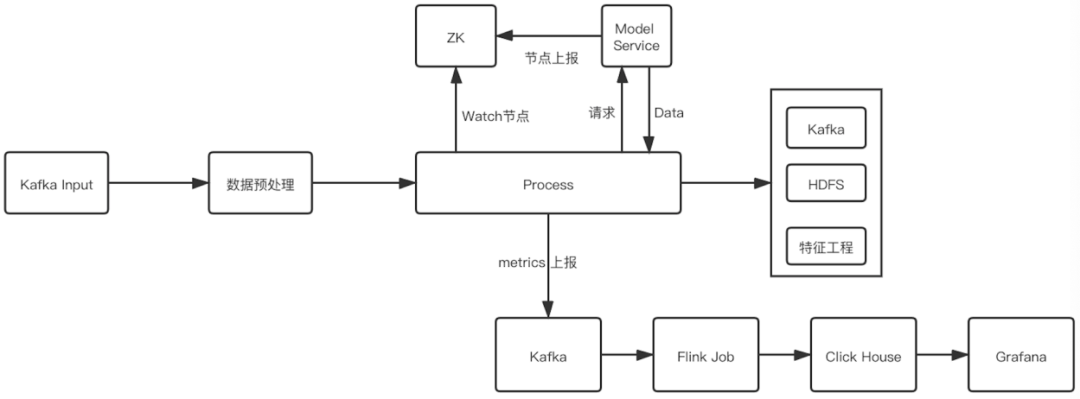
Problemas y soluciones
aparece el problema:
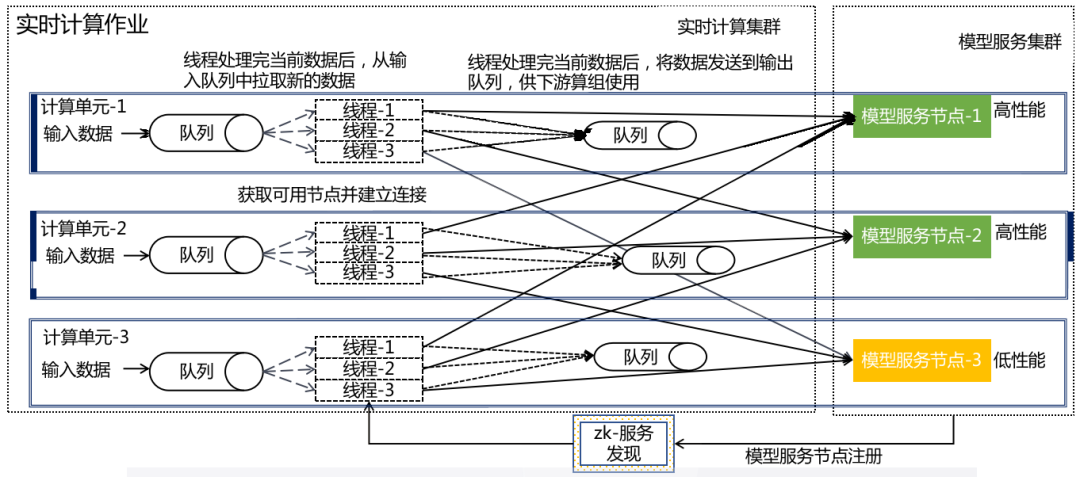
Los diversos nodos implementados en el servicio modelo son completamente independientes entre sí, y cada nodo actualizará su estado a ZooKeeper después de conectarse o desconectarse. Cada subtarea de una tarea de Flink registrará un reloj para obtener todos los nodos más recientes y disponibles. Para cada dato que fluye hacia la subtarea, se debe seleccionar un nodo para completar el razonamiento de los datos.
En la etapa inicial, usamos la estrategia aleatoria para seleccionar nodos, pero en el proceso de uso, descubrimos que si el rendimiento de un nodo modelo en el lado del servidor es bajo, seguirá el razonamiento de datos que consume mucho tiempo, lo que eventualmente puede conducir a tareas de Flink contrapresión. Desde la perspectiva del servidor, muchos nodos del modelo no se ejecutan a plena capacidad, pero el rendimiento del servidor reflejado por el cliente no es suficiente y el QPS total del procesamiento es muy bajo.
Además, cuando nos comunicamos con el servicio modelo, adoptamos una estrategia de sincronización.Para algunas tareas que toman mucho tiempo para inferir y tienen un QPS alto, se requiere una concurrencia lo suficientemente grande para completar la solicitud de datos. Sin embargo, la utilización de recursos de estas tareas es baja, lo que también es un problema importante en el entorno de producción.
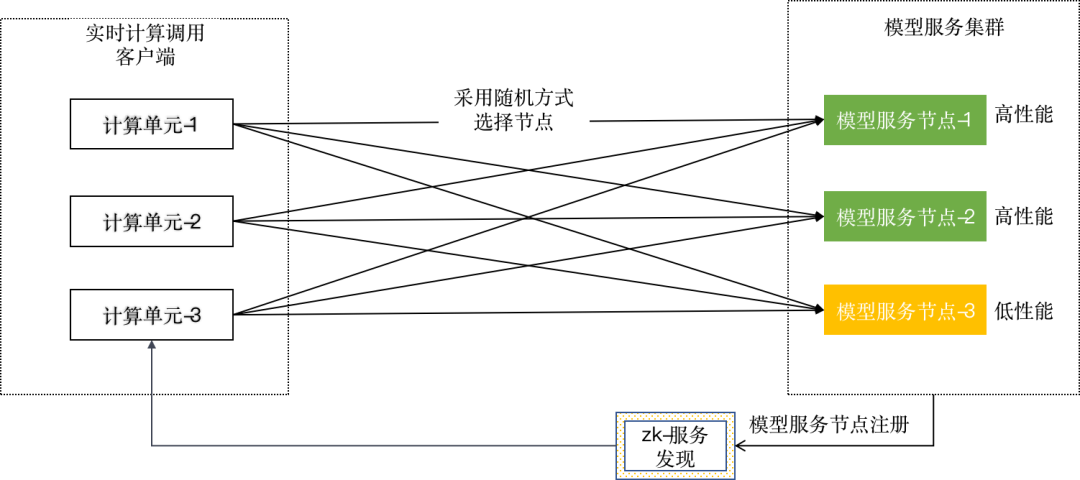
análisis de la idea:
En base a la figura anterior, hacemos el siguiente análisis:
En una situación ideal, asumimos que el servidor tiene el Nodo 1, el Nodo 2 y el Nodo 3, y el rendimiento de los tres nodos es el mismo, y cada nodo tiene 32 procesamientos en paralelo. Suponiendo que el tiempo de procesamiento de cada pieza de datos es de 800 ms, la capacidad de procesamiento de cada nodo debe ser de 40 piezas/s, y la capacidad de procesamiento debe ser de 120 piezas/s cuando los tres nodos están completamente cargados.
En el entorno de producción real, las capacidades de procesamiento de cada nodo de la máquina implementada en el servidor son diferentes y existen tres razones principales para la diferencia.
■ Las máquinas físicas GPU tienen varias especificaciones y el rendimiento varía mucho Es difícil garantizar que los nodos se implementen en el mismo lote de máquinas durante la implementación;
■ La combinación de varios servicios de modelo en una máquina se afectará entre sí;
■ Las fallas en la red de la máquina y el disco donde se ubican algunos nodos también generarán diferencias.
Por ejemplo, los nodos 1 y 2 se implementan en máquinas de alto rendimiento, el paralelismo de los nodos es de 32 y el tiempo de procesamiento de un solo dato es de 800 ms. El nodo 3 se implementa en una máquina de bajo rendimiento, el paralelismo del nodo es 32 y un solo procesamiento de datos tarda 2400 ms, por lo que la capacidad de procesamiento del nodo 3 puede considerarse de 13,3 registros/s. También se adopta la estrategia de seleccionar nodos aleatoriamente, si se envía un total de 40 datos en un segundo, ya se ha alcanzado el cuello de botella de rendimiento para el nodo 3. Suponiendo que se seleccionan más datos para ser procesados por el nodo 3 en este momento, solo se pueden poner en cola en la cola del lado del servidor, y si la cola está llena, se rechazará la conexión.
A medida que se ejecuta la tarea, los datos de la cola de espera del nodo 3 aumentarán, y el tiempo que pasa el cliente desde que envía la solicitud hasta que devuelve el resultado también aumentará en consecuencia. En este momento, una vez que una subtarea selecciona este nodo, la subtarea debe esperar mucho tiempo para completar esta solicitud. Durante este proceso, si los datos ascendentes continúan fluyendo, el canal de entrada de la subtarea se agotará gradualmente y luego el espacio del grupo de búfer público se llenará, lo que provocará que la subtarea2 se bloquee. Y debido a que el operador ascendente usa Rebalance, toda la tarea de Flink finalmente se bloqueará.
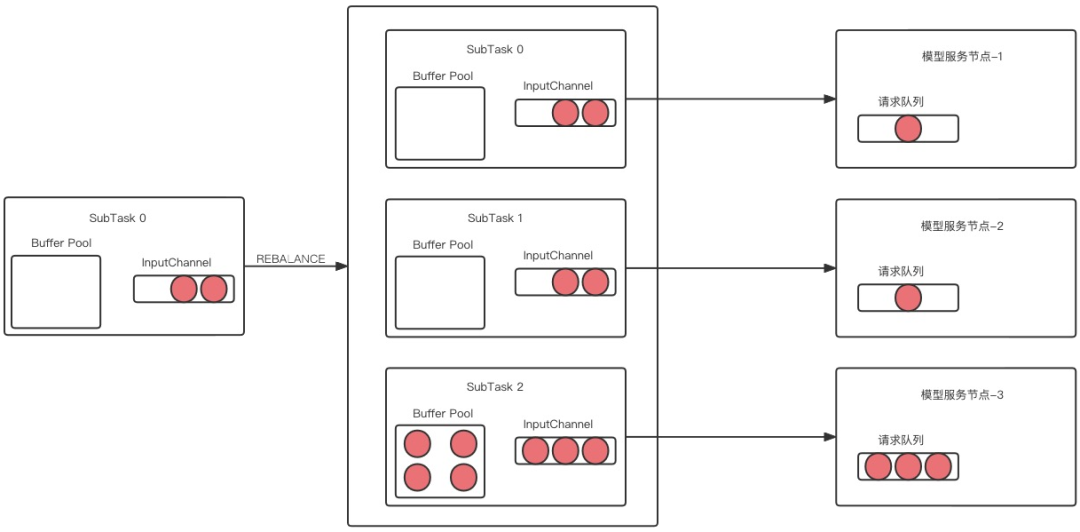
Este es un efecto de barril típico En escenarios de aplicación práctica, una vez que un solo nodo tiene un rendimiento deficiente o falla, afectará la estabilidad de toda la tarea.
solución:
Después de analizar la causa del accidente, proponemos configurar un peso para cada nodo, y los nodos del modelo informan regularmente el valor del peso a ZooKeeper, y el cliente asigna el tráfico correspondiente a cada nodo a través del peso. Esta idea es muy buena y ha logrado ciertos resultados en la práctica, pero tiene un pequeño problema: hacerlo hará que el tráfico de cada nodo se altere todo el tiempo, y la frecuencia de la fluctuación se correlaciona positivamente con el tiempo para informar. el peso, y desde el punto de vista del monitoreo, hacerlo también hará que la cantidad total de datos procesados sea inestable.
Después de que el problema se solucionó inicialmente, comenzamos a pensar si había otras formas mejores de resolver este problema. Se sabe que si el nodo del modelo es lento, una subtarea se atascará, y esta subtarea es esencialmente una ranura, es decir, un subproceso, entonces, ¿podemos usar subprocesos múltiples para resolver este problema? Con esto en mente, probamos otras dos soluciones: E/S asíncrona y subprocesamiento múltiple.
■ Solución de E/S asíncrona
Flink introdujo Async I/O en la versión 1.2 Su objetivo principal es resolver el problema de que el retraso de la red se convierte en un cuello de botella del sistema cuando interactúa con sistemas externos. A través de la API expuesta, podemos establecer el número máximo de operaciones, que se entiende simplemente como el número máximo de solicitudes asíncronas simultáneas en Slot. Durante la prueba, preparamos tres nodos, un nodo tardó 2000 ms en procesarse y los otros dos nodos tardaron 500 ms en procesarse.
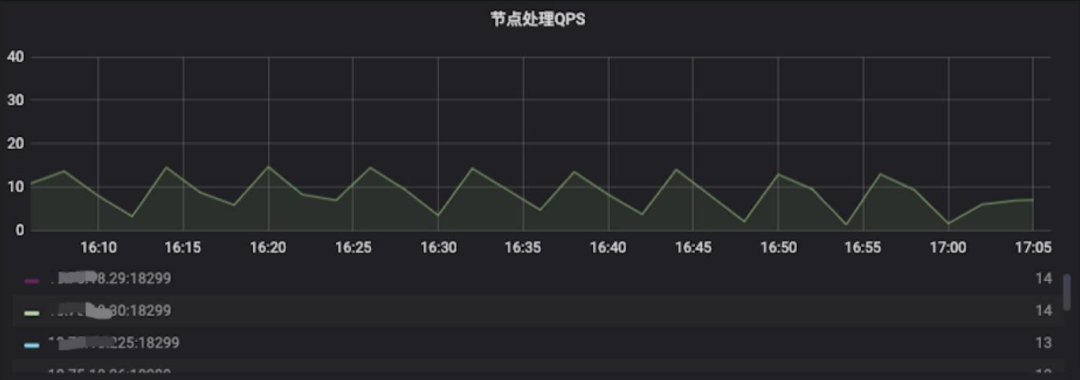
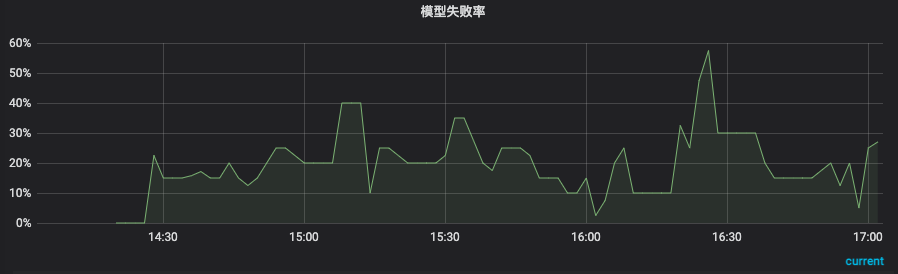
La tarea se ejecuta normalmente unos minutos después del inicio, y luego la longitud de acumulación de la cola del servidor del nodo con una velocidad de procesamiento más lenta se vuelve cada vez más grande y finalmente se estabiliza en alrededor de 150. Al mismo tiempo, la tasa de fallas de tiempo de espera también comienza a aumentar. alto Podemos ver que aunque este método puede resolver el problema de la contrapresión atascada y la utilización de recursos causada por nodos rápidos y lentos, todavía no puede resolver el problema de la distribución del tráfico.
■ Solución de subprocesos múltiples
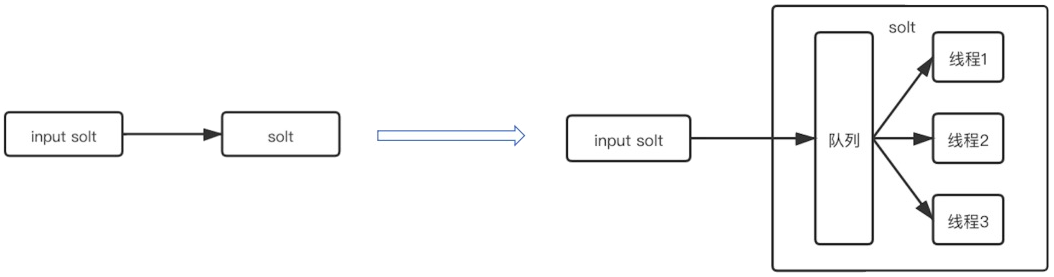
Implementamos un modelo de productor-consumidor dentro de cada ranura, y luego creamos la misma cantidad de subprocesos que los nodos del modelo, de modo que cada subproceso solicite un nodo fijo. Incluso si este nodo está atascado o la velocidad de procesamiento es lenta, solo afectará los subprocesos actuales tienen un impacto limitado en toda la subtarea.
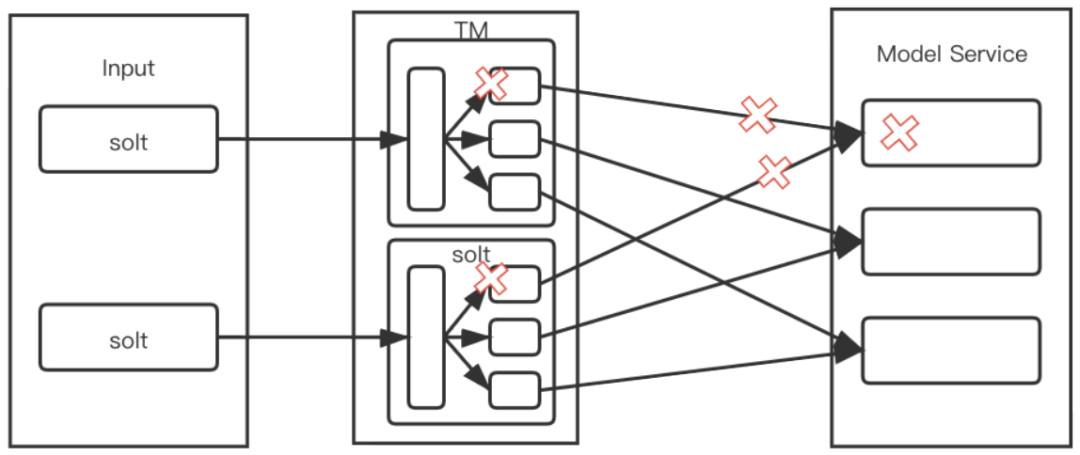
Como se muestra en la figura anterior, una ranura contiene múltiples subprocesos y los problemas con los nodos de servicio correspondientes a subprocesos individuales no afectarán el consumo de otros subprocesos. De esta manera, se puede realizar una estrategia de distribución de tráfico adaptativo.Cada hilo corresponde a un servidor Pod.Este método de bloqueo adaptativo de hilos puede lograr el propósito de menor consumo por parte de los nodos lentos y más consumo por parte de los nodos rápidos.
Cuando Flink toma Slot como la granularidad mínima de recursos y luego la refina, iniciar varios subprocesos desde Slot puede aumentar la simultaneidad, lo que reduce la cantidad total de Slots y mejora la utilización de recursos mientras reduce los recursos.
Arquitectura Tecnológica
En la tarea Flink, se utiliza una solución de subprocesos múltiples para resolver el problema del equilibrio de carga de comunicación RPC. El modelo de programación debe modificarse en consecuencia. La modificación específica es la siguiente:
Efectividad de la construcción
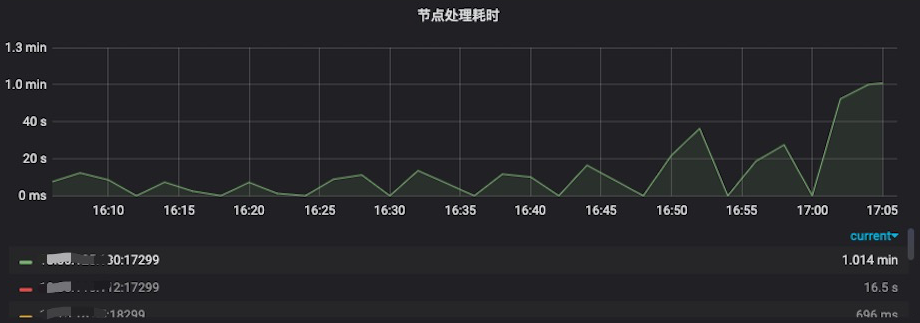
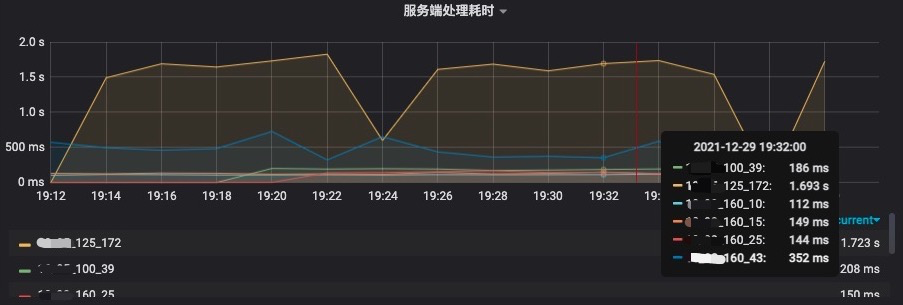
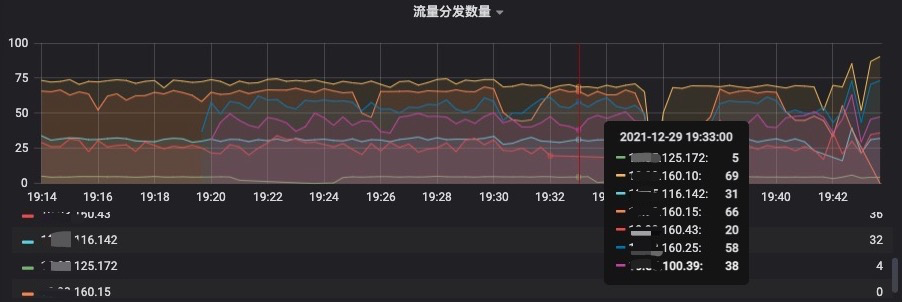
Al comparar los datos antes y después, descubrimos que después de adoptar la solución de subprocesos múltiples, el efecto sigue siendo evidente. En el indicador de tiempo de procesamiento del lado del servidor que se muestra en la siguiente figura, podemos ver que el tiempo de procesamiento del nodo que termina en 125.172 es de aproximadamente 1,7 s, y en el indicador de cantidad de distribución de tráfico, podemos ver que el tráfico asignado a es de aproximadamente 5 piezas/s; el tiempo de procesamiento del nodo 160,25 es de aproximadamente 0,14 s, y el tráfico asignado es de aproximadamente 58/s, lo que generalmente está en línea con las expectativas.
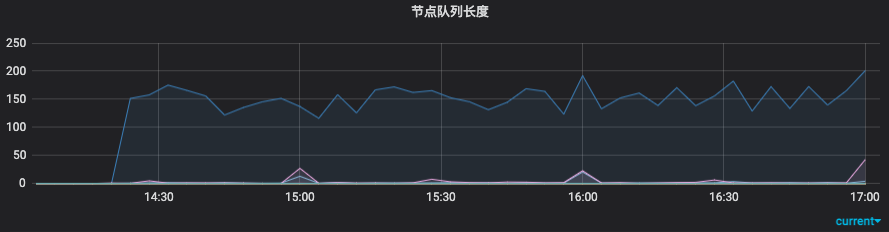
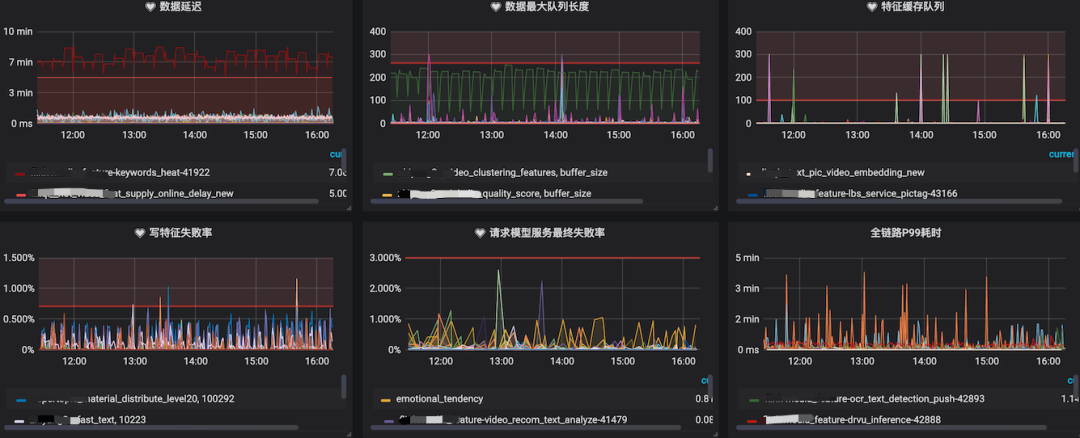
Al mismo tiempo, para garantizar la estabilidad de todo el servicio, hemos agregado algunos indicadores de monitoreo, tales como: longitud de la cola de caché, tasa de falla del modelo, consumo de tiempo de enlace, tasa de falla de la función de escritura, etc.
epílogo
Este artículo presenta principalmente que cuando se llama a Flink en un clúster heterogéneo, si el servidor no puede distribuir el tráfico, el cliente puede implementar un equilibrio de carga dinámico del tráfico a través de subprocesos múltiples, lo que puede ayudar al servidor a ser compatible con modelos de configuración alta y baja. Mejorar la eficiencia de utilización de la máquina. Sin embargo, debe señalarse que los operadores de subprocesos múltiples utilizados en este artículo son sin estado (stateless), y los operadores con estado deben considerarse adecuadamente. Además, si el servidor es un componente que puede asignar nodos de forma autónoma, puede optar por utilizar la solución de E/S asíncrona.