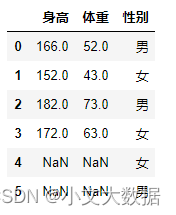
Primero mira los datos:
import pandas as pd
x = pd.DataFrame([[166,52,'男'],[152,43,'女'],[182,73,'男'],[172,63,'女'],[np.nan,np.nan,'女'],[np.nan,np.nan,'男']],columns = ['身高','体重','性别'])
x
El método comúnmente utilizado para completar los valores faltantes es usar la media, la moda, etc. para completar, de la siguiente manera:
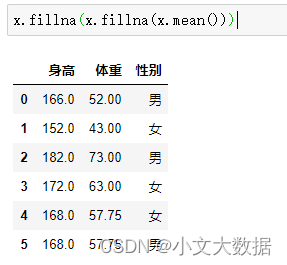
Sin embargo, cuando necesitamos completar el valor medio de diferentes categorías de datos, puede ser problemático. Las ideas comúnmente utilizadas pueden ser las siguientes, es decir, sacar diferentes categorías de datos y luego completarlas a su vez:
labels = x['性别'].unique()
for label in labels:
for col in x.columns[:-1]:
data_ = x.loc[x['性别']==label, col]
x.loc[x['性别']==label, col] = data_.fillna(data_.mean())
print(x) 
Pero podemos hacer esto más fácilmente usando los métodos de agregación de agrupación y transformación:
x = pd.DataFrame([[166,52,'男'],[152,43,'女'],[182,73,'男'],[172,63,'女'],[np.nan,np.nan,'女'],[np.nan,np.nan,'男']],columns = ['身高','体重','性别'])
x.loc[:,x.columns != '性别'] = x.groupby('性别').transform(lambda x:x.fillna(x.mean()))
print(x)
La función del método transform es devolver el número obtenido por la agregación de los datos agrupados a cada fila (si la agregación es un solo escalar, se devolverá a cada fila, es decir, los datos de cada fila del mismo grupo es igual, si la agregación son los datos originales El tamaño del retorno correspondiente a los datos originales, como el resultado aquí), después de agrupar el género aquí, complete cada grupo y luego regrese a los datos originales, puede completar diferentes grupos