Directorio de artículos
- instalar elasticsearch
- 1. Implementar puntos únicos
- 2. Departamento kibana
- 3. Instalar el tokenizador IK
- 4. Implementar el clúster es
instalar elasticsearch
1. Implementar puntos únicos
1.1 Crear una red
Kibana puede ayudarnos a escribir declaraciones de DSL de manera conveniente, por lo que debemos instalar kibana
Debido a que también necesitamos implementar el contenedor kibana, necesitamos interconectar los contenedores es y kibana. Aquí primero crea una red:
docker network create es-net
1.2 Cargar imagen
Aquí usamos la imagen de la versión 7.12.1 de elasticsearch, que es muy grande, cercana a 1G. No se recomienda que lo tire usted mismo.
Los materiales previos a la clase proporcionan paquetes de alquitrán reflejados:
Lo subes a la máquina virtual y luego ejecutas el comando para cargarlo:
# 导入数据
docker load -i es.tar
De la misma forma, existen kibanapaquetes tar que también necesitan hacer esto.
1.3 Ejecutar
Ejecute el comando docker para implementar un solo punto es:
docker run -d \
--name es \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-e "discovery.type=single-node" \
-v es-data:/usr/share/elasticsearch/data \
-v es-plugins:/usr/share/elasticsearch/plugins \
--privileged \
--network es-net \
-p 9200:9200 \
-p 9300:9300 \
elasticsearch:7.12.1
Explicación del comando:
-e "cluster.name=es-docker-cluster": establecer el nombre del clúster-e "http.host=0.0.0.0": La dirección de escucha, a la que se puede acceder desde la red externa-e "ES_JAVA_OPTS=-Xms512m -Xmx512m": (tiempo de ejecución futuro) tamaño de la memoria-e "discovery.type=single-node": modo sin clúster-v es-data:/usr/share/elasticsearch/data: Monte el volumen lógico, enlace el directorio de datos de es-v es-logs:/usr/share/elasticsearch/logs: Monte el volumen lógico, vincule el directorio de registro de es-v es-plugins:/usr/share/elasticsearch/plugins: Monte el volumen lógico, vincule el directorio de complementos de es--privileged: otorgar acceso al volumen lógico--network es-net: únase a una red llamada es-net (kibana también se unirá, los dos pueden comunicarse entre sí)-p 9200:9200: Configuración de asignación de puertos (los usuarios del puerto 9200 acceden al puerto 9300, el puerto que se interconectará entre los nodos en el futuro, que actualmente no está disponible)
-v Volumen local: directorio contenedor
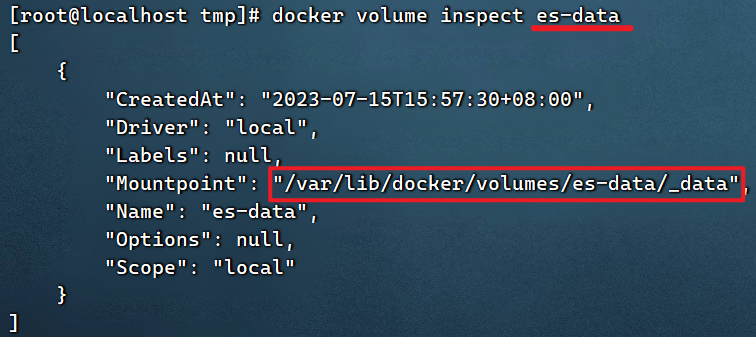
Si no hay un volumen local, debe crearse para usted Aldocker volume inspect 卷名ver la información del volumen, hay un directorio local
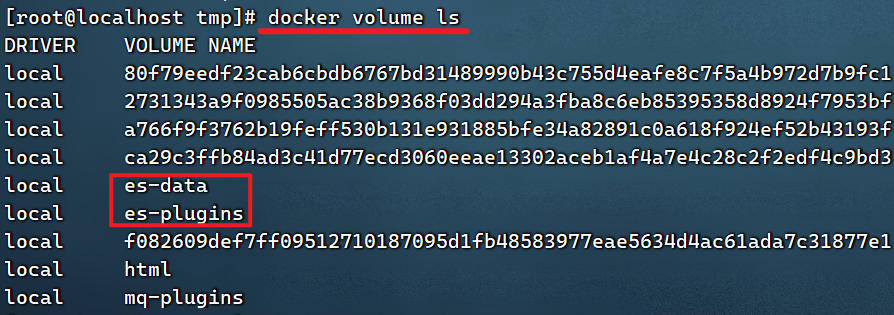
# 查看所有数据卷
docker volume ls
# 查看数据卷详细信息卷
docker volume inspect html
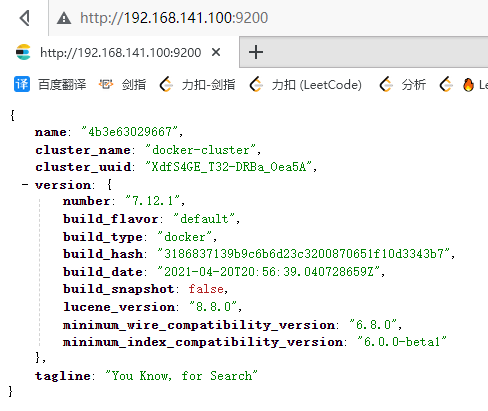
docker run ...Después de ejecutar el comando anterior , docker pspuede ver el proceso correspondiente y el navegador también puede acceder a él. Ingrese
en el navegador: http://192.168.141.100:9200 (tenga en cuenta que la ip se reemplaza por la suya) para ver el Resultado de la respuesta de búsqueda elástica:
2. Departamento kibana
Kibana puede proporcionarnos una interfaz visual de búsqueda elástica para que aprendamos.
2.1 Despliegue
Ejecute el comando docker para implementar kibana
docker run -d \
--name kibana \
-e ELASTICSEARCH_HOSTS=http://es:9200 \
--network=es-net \
-p 5601:5601 \
kibana:7.12.1
--network es-net: únase a una red llamada es-net, en la misma red que elasticsearch-e ELASTICSEARCH_HOSTS=http://es:9200": establezca la dirección de elasticsearch, porque kibana ya está en la misma red que elasticsearch, por lo que puede acceder directamente a elasticsearch con el nombre del contenedor-p 5601:5601: configuración de mapeo de puertos
Por lo general, Kibana tarda en iniciarse y necesita esperar un rato. Puedes usar el comando:
docker logs -f kibana
Compruebe el registro en ejecución. Cuando vea el siguiente registro, significa que se ha realizado correctamente:

En este punto, ingrese la dirección en el navegador para acceder: http://192.168.141.100:5601 , puede ver el resultado
Ver kibana ~
haga clic en Explorar por mi cuenta, y luego
2.2.Herramientas de desarrollo
Se proporciona una interfaz de DevTools en kibana:
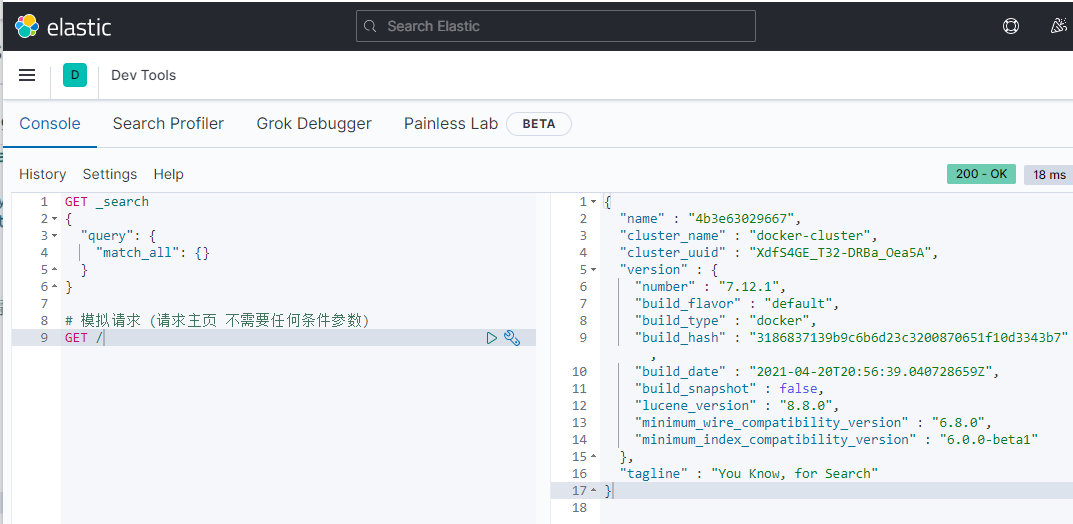
En esta interfaz, se puede escribir DSL para operar elasticsearch. Y hay una función de finalización automática para declaraciones DSL.
La declaración de formato json a la izquierda es la declaración de consulta DSL,
la esencia es enviar una solicitud Restful a es
2.3 Problema de segmentación de palabras (el chino no es amigable)
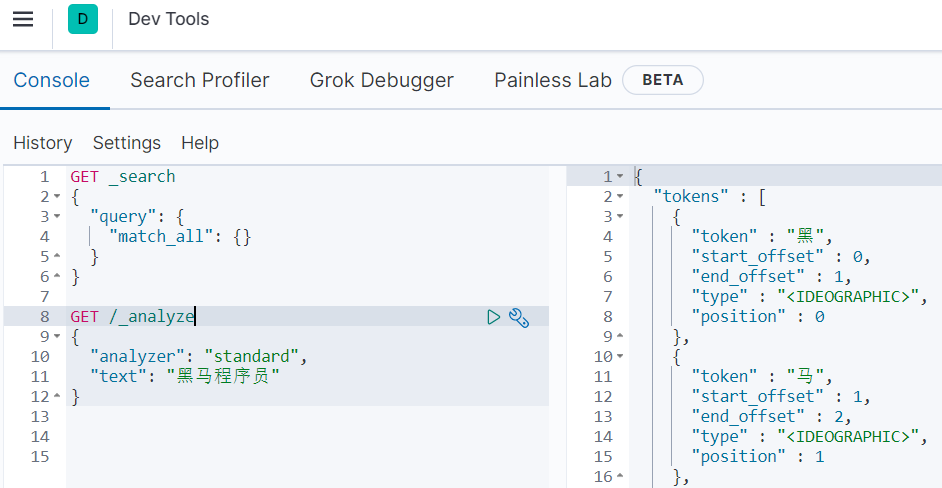
# 测试分词器
POST /_analyze
{
"text": "李白讲的java太棒了",
"analyzer": "english"
}
{
"tokens" : [
{
"token" : "李",
"start_offset" : 0,
"end_offset" : 1,
"type" : "<IDEOGRAPHIC>",
"position" : 0
},
{
"token" : "白",
"start_offset" : 1,
"end_offset" : 2,
"type" : "<IDEOGRAPHIC>",
"position" : 1
},
{
"token" : "讲",
"start_offset" : 2,
"end_offset" : 3,
"type" : "<IDEOGRAPHIC>",
"position" : 2
},
{
"token" : "的",
"start_offset" : 3,
"end_offset" : 4,
"type" : "<IDEOGRAPHIC>",
"position" : 3
},
{
"token" : "java",
"start_offset" : 4,
"end_offset" : 8,
"type" : "<ALPHANUM>",
"position" : 4
},
{
"token" : "太",
"start_offset" : 8,
"end_offset" : 9,
"type" : "<IDEOGRAPHIC>",
"position" : 5
},
{
"token" : "棒",
"start_offset" : 9,
"end_offset" : 10,
"type" : "<IDEOGRAPHIC>",
"position" : 6
},
{
"token" : "了",
"start_offset" : 10,
"end_offset" : 11,
"type" : "<IDEOGRAPHIC>",
"position" : 7
}
]
}
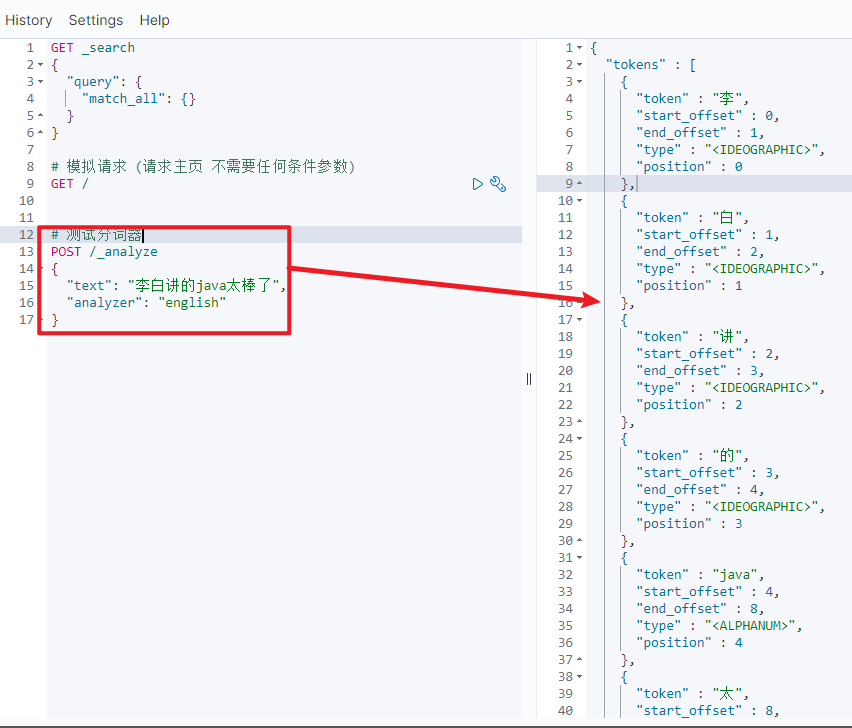
Cambiar el analizador de 'inglés' a 'chino' u otro 'estándar' sigue siendo el mismo, y el resultado de ejecución sigue siendo el mismo
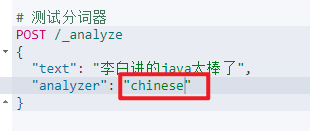

Se puede ver que la segmentación de palabras en inglés sigue siendo buena, y 'java' se divide en una sola palabra. Pero en chino, la tierra se divide carácter por carácter, lo que obviamente es inapropiado. El es predeterminado no puede entender el significado chino
3. Instalar el tokenizador IK
Dirección Git: https://github.com/medcl/elasticsearch-analysis-ik
Se puede ver que se usa especialmente para ES
3.1 Instalar el complemento ik en línea (más lento)
# 进入容器内部
docker exec -it elasticsearch /bin/bash
# 在线下载并安装
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.1/elasticsearch-analysis-ik-7.12.1.zip
#退出
exit
#重启容器
docker restart elasticsearch
3.2 Instalar el complemento ik sin conexión (recomendado)
1) Ver el directorio de volumen de datos
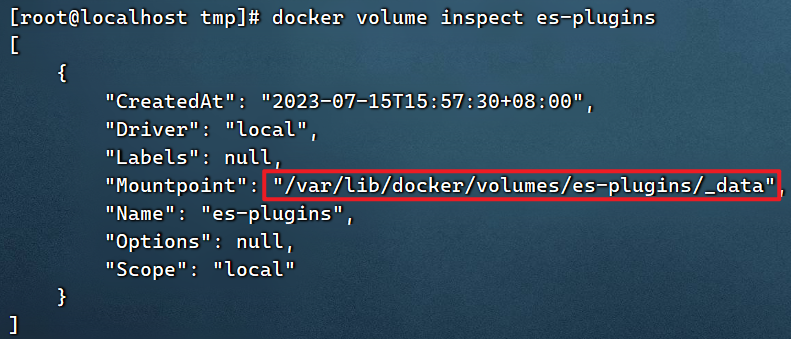
Para instalar el complemento, debe conocer la ubicación del directorio de complementos de elasticsearch, y usamos el montaje de volumen de datos, por lo que debemos ver el directorio de volumen de datos de elasticsearch y verificarlo con el siguiente comando:
docker volume inspect es-plugins
Mostrar resultados:
[
{
"CreatedAt": "2023-07-15T15:57:30+08:00",
"Driver": "local",
"Labels": null,
"Mountpoint": "/var/lib/docker/volumes/es-plugins/_data",
"Name": "es-plugins",
"Options": null,
"Scope": "local"
}
]
Muestra que el directorio de complementos está montado en: /var/lib/docker/volumes/es-plugins/_data este directorio.
2) Descomprima el paquete de instalación del tokenizador
A continuación, debemos descomprimir el tokenizador ik en los materiales previos a la clase y cambiarle el nombre a ik
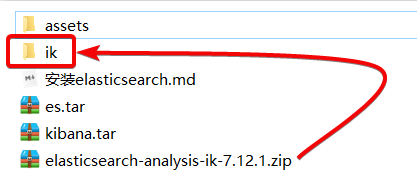
3) Subir al volumen de datos del complemento del contenedor es
Eso es /var/lib/docker/volumes/es-plugins/_data :
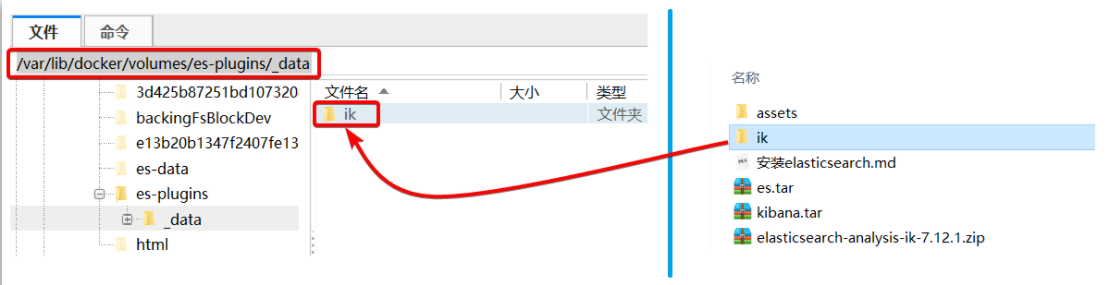
4) Reiniciar el contenedor
# 4、重启容器
docker restart es
# 查看es日志
docker logs es | grep analysis-ik
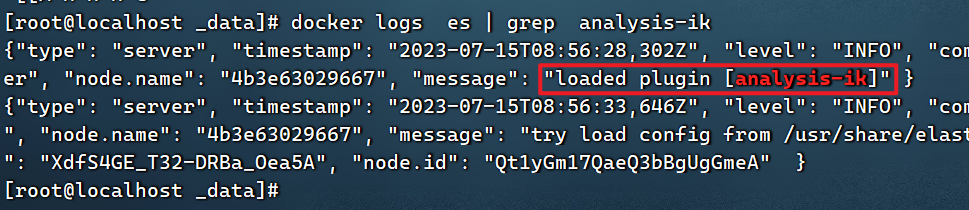
Cargado con éxito, el separador de palabras está instalado
5) Prueba:
El tokenizador IK contiene dos modos:
-
ik_smart: Menos segmentación (palabras de grupo lo más largas posible y luego no más segmentación) -
ik_max_word: La segmentación más fina (más divisiones, si es una palabra, se dividirá y la palabra se puede usar repetidamente)
POST /_analyze
{
"text": "胡老师讲的java太棒了",
"analyzer": "ik_max_word"
}
resultado:
{
"tokens" : [
{
"token" : "胡",
"start_offset" : 0,
"end_offset" : 1,
"type" : "CN_CHAR",
"position" : 0
},
{
"token" : "老师",
"start_offset" : 1,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "讲",
"start_offset" : 3,
"end_offset" : 4,
"type" : "CN_CHAR",
"position" : 2
},
{
"token" : "的",
"start_offset" : 4,
"end_offset" : 5,
"type" : "CN_CHAR",
"position" : 3
},
{
"token" : "java",
"start_offset" : 5,
"end_offset" : 9,
"type" : "ENGLISH",
"position" : 4
},
{
"token" : "太棒了",
"start_offset" : 9,
"end_offset" : 12,
"type" : "CN_WORD",
"position" : 5
},
{
"token" : "太棒",
"start_offset" : 9,
"end_offset" : 11,
"type" : "CN_WORD",
"position" : 6
},
{
"token" : "了",
"start_offset" : 11,
"end_offset" : 12,
"type" : "CN_CHAR",
"position" : 7
}
]
}
3.3 Diccionario de palabras extendidas
Con el desarrollo de Internet, los "movimientos de creación de palabras" se han vuelto cada vez más frecuentes. Aparecieron muchas palabras nuevas que no existían en la lista de vocabulario original. Por ejemplo: "Olige", "Forever Drop God", etc.

Por lo tanto, nuestro vocabulario también debe actualizarse constantemente, y el tokenizador IK proporciona la función de ampliar el vocabulario.
1) Abra el directorio de configuración del tokenizador IK:
/var/lib/docker/volumes/es-plugins/_data/ik/config
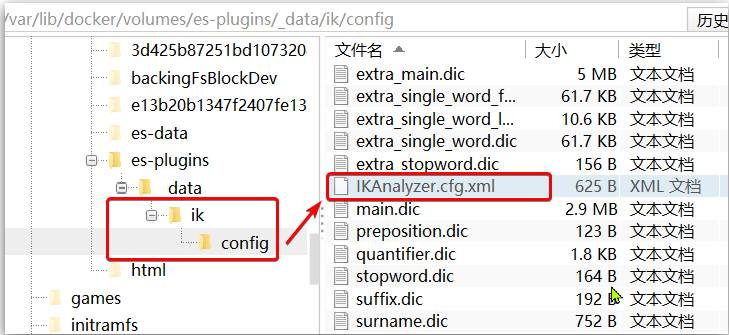
2) Agregue el contenido del archivo de configuración IKAnalyzer.cfg.xml:
La configuración se ha escrito de forma predeterminada, solo complete el nombre del archivo
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 *** 添加扩展词典-->
<entry key="ext_dict">ext.dic</entry>
</properties>
3) Cree un nuevo ext.dic, puede consultar el directorio de configuración para copiar un archivo de configuración para modificarlo
De hecho, solo enumere cada palabra línea por línea
全红禅
永远滴神
奥力给
4) reiniciar la búsqueda elástica
docker restart es
# 查看 日志
docker logs -f elasticsearch
El registro mostrará que el archivo de configuración ext.dic se ha cargado correctamente
O espere pacientemente por un tiempo, básicamente se puede cargar normalmente
5) efecto de prueba:
POST /_analyze
{
"text": "全红禅永远滴神,我的神,奥力给",
"analyzer": "ik_max_word"
}
Tenga en cuenta que la codificación del archivo actual debe estar en formato UTF-8, y la edición con el Bloc de notas de Windows está estrictamente prohibida.
3.4 Diccionario de palabras vacías
En los proyectos de Internet, la velocidad de transmisión entre redes es muy rápida, por lo que no se permite la transmisión de muchos idiomas en la red, como: palabras sensibles sobre religión, política, etc., entonces también debemos ignorar el vocabulario actual al buscar.
El tokenizador IK también proporciona una poderosa función de palabras vacías, lo que nos permite ignorar el contenido del vocabulario de parada actual al indexar.
1) Agregue el contenido del archivo de configuración IKAnalyzer.cfg.xml:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典-->
<entry key="ext_dict">ext.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典 *** 添加停用词词典-->
<entry key="ext_stopwords">stopword.dic</entry>
</properties>
De hecho, están todos configurados, pero los nombres de los dos diccionarios están vacíos por defecto.
3) Agregue palabras vacías a stopword.dic
Este archivo ya existe de manera predeterminada, solo agréguelo directamente
的
地
了
哦
啊
嘤
4) reiniciar la búsqueda elástica
# 重启服务
docker restart elasticsearch
docker restart kibana
# 查看 日志
docker logs -f elasticsearch
El archivo de configuración stopword.dic se ha cargado correctamente en el registro
5) efecto de prueba:
POST /_analyze
{
"text": "全红禅永远滴神,我的神,奥力给",
"analyzer": "ik_max_word"
}
Tenga en cuenta que la codificación del archivo actual debe estar en formato UTF-8, y la edición con el Bloc de notas de Windows está estrictamente prohibida.
{
"tokens" : [
{
"token" : "全红禅",
"start_offset" : 0,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "永远滴神",
"start_offset" : 3,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "永远",
"start_offset" : 3,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "滴",
"start_offset" : 5,
"end_offset" : 6,
"type" : "CN_CHAR",
"position" : 3
},
{
"token" : "神",
"start_offset" : 6,
"end_offset" : 7,
"type" : "CN_CHAR",
"position" : 4
},
{
"token" : "我",
"start_offset" : 8,
"end_offset" : 9,
"type" : "CN_CHAR",
"position" : 5
},
{
"token" : "神",
"start_offset" : 10,
"end_offset" : 11,
"type" : "CN_CHAR",
"position" : 6
},
{
"token" : "奥力给",
"start_offset" : 12,
"end_offset" : 15,
"type" : "CN_WORD",
"position" : 7
}
]
}
全红禅, 永远滴神, 奥利给. pueden ser reconocidos como modismos
的. ya no será participio
- resumen

4. Implementar el clúster es
La implementación del clúster es se puede hacer directamente usando docker-compose, pero se requiere que su máquina virtual Linux tenga al menos 4G de espacio de memoria (si no es suficiente, vuelva a asignarlo y auméntelo)
4.1 Crear clúster es
Primero escriba un archivo docker-compose con el siguiente contenido:
docker-compose.yml
version: '2.2'
services:
es01:
image: elasticsearch:7.12.1
container_name: es01
environment:
- node.name=es01
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es02,es03
- cluster.initial_master_nodes=es01,es02,es03
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
volumes:
- data01:/usr/share/elasticsearch/data
ports:
- 9200:9200
networks:
- elastic
es02:
image: elasticsearch:7.12.1
container_name: es02
environment:
- node.name=es02
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es01,es03
- cluster.initial_master_nodes=es01,es02,es03
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
volumes:
- data02:/usr/share/elasticsearch/data
ports:
- 9201:9200
networks:
- elastic
es03:
image: elasticsearch:7.12.1
container_name: es03
environment:
- node.name=es03
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es01,es02
- cluster.initial_master_nodes=es01,es02,es03
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
volumes:
- data03:/usr/share/elasticsearch/data
networks:
- elastic
ports:
- 9202:9200
volumes:
data01:
driver: local
data02:
driver: local
data03:
driver: local
networks:
elastic:
driver: bridge
Puede ver en el archivo yml:
es01 puerto 9200
es02 puerto 9201
es03 puerto 9202
Para cargar a linux
es, debe modificar algunos permisos del sistema linux y modificar /etc/sysctl.confarchivos
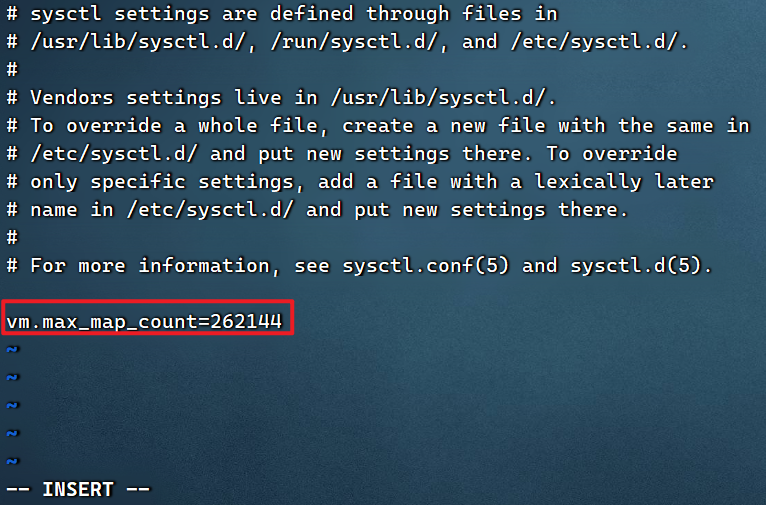
vi /etc/sysctl.conf
Agrega el siguiente contenido:
vm.max_map_count=262144
Luego ejecute el comando para que la configuración surta efecto:
sysctl -p

Si reinicia la máquina virtual, primero debe iniciar la ventana acoplable
systemctl start docker
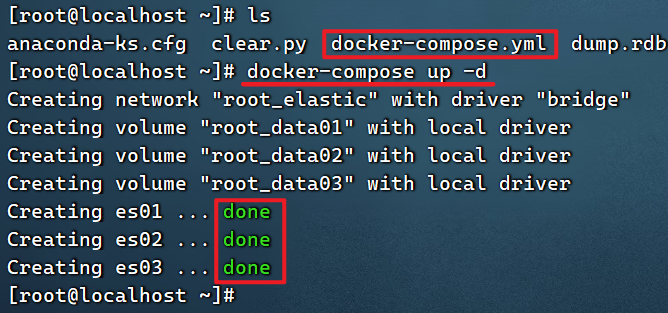
Ejecutar docker-composepara abrir el clúster:
docker-compose up -d
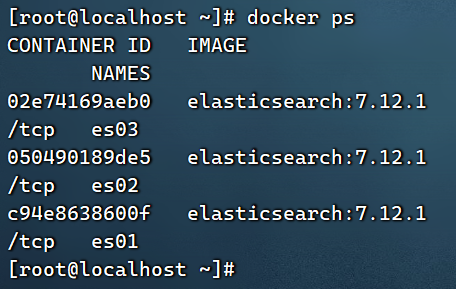
Ver registros para cada nodo
docker logs -f es01
docker logs -f es02
docker logs -f es03
4.2 Supervisión del estado del clúster
Kibana puede monitorear clústeres de es, pero la nueva versión necesita confiar en la función x-pack de es, y la configuración es más complicada.
Se recomienda usar cerebro para monitorear el estado del clúster es, sitio web oficial: https://github.com/lmenezes/cerebro
Los materiales de pre-clase han proporcionado el paquete de instalación:
Enlace: https://pan.baidu.com/s/1zrji4O8niH_UmQNKBhNIPg
Código de extracción: hzan
Se puede usar después de la descompresión, lo cual es muy conveniente.
El directorio descomprimido es el siguiente:
Introduzca el directorio bin correspondiente:

Haga doble clic en el archivo cerebro.bat para iniciar el servicio.

Cuando se inicie una versión superior como jdk17, se informará un error: simplemente
Caused by: java.lang.IllegalStateException: Unable to load cache item
cambie java en la variable de entorno a la variable de entorno de jdk8, es decir,
use jdk8
Visite http://localhost:9000 para ingresar a la interfaz de administración:
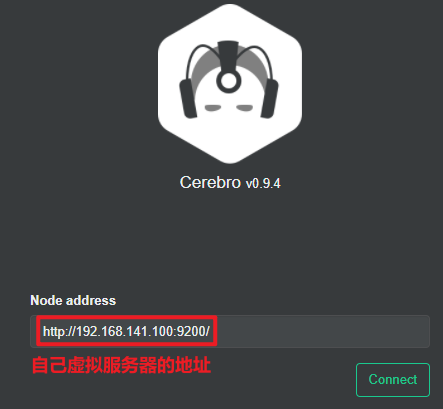
http://192.168.141.100:9200/
Ingrese la dirección y el puerto de cualquier nodo de su elasticsearch y haga clic en conectar:

Una barra verde indica que el clúster es verde (bueno).
4.3 Crear biblioteca de índices
1) Use DevTools de Kibana para crear una biblioteca de índices
Ingrese el comando en DevTools:
Múltiples nodos almacenan la biblioteca de índices en fragmentos y luego se respaldan entre sí.¿Cómo
fragmentar y cuántas copias? Configurado al crear la biblioteca de índice
PUT /itcast
{
"settings": {
"number_of_shards": 3, // 分片数量
"number_of_replicas": 1 // 副本数量
},
"mappings": {
"properties": {
// mapping映射定义 ...
}
}
}
Kibana se ha detenido, de hecho, también puede usar cerebro para crear una biblioteca de índice
2) Use cerebro para crear una biblioteca de índices
También puede crear una biblioteca de índices con cerebro:
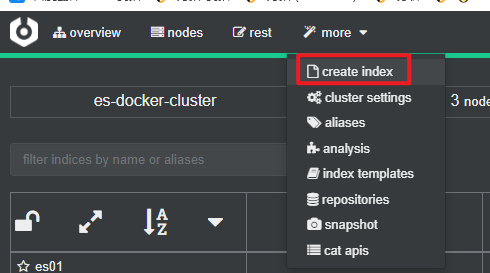
Complete la información de la biblioteca del índice:
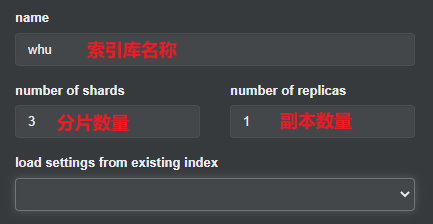
Haga clic en el botón Crear en la esquina inferior derecha:

4.4 Ver el efecto de fragmentación
Regrese a la página de inicio y podrá ver el efecto de la fragmentación de la biblioteca de índices:
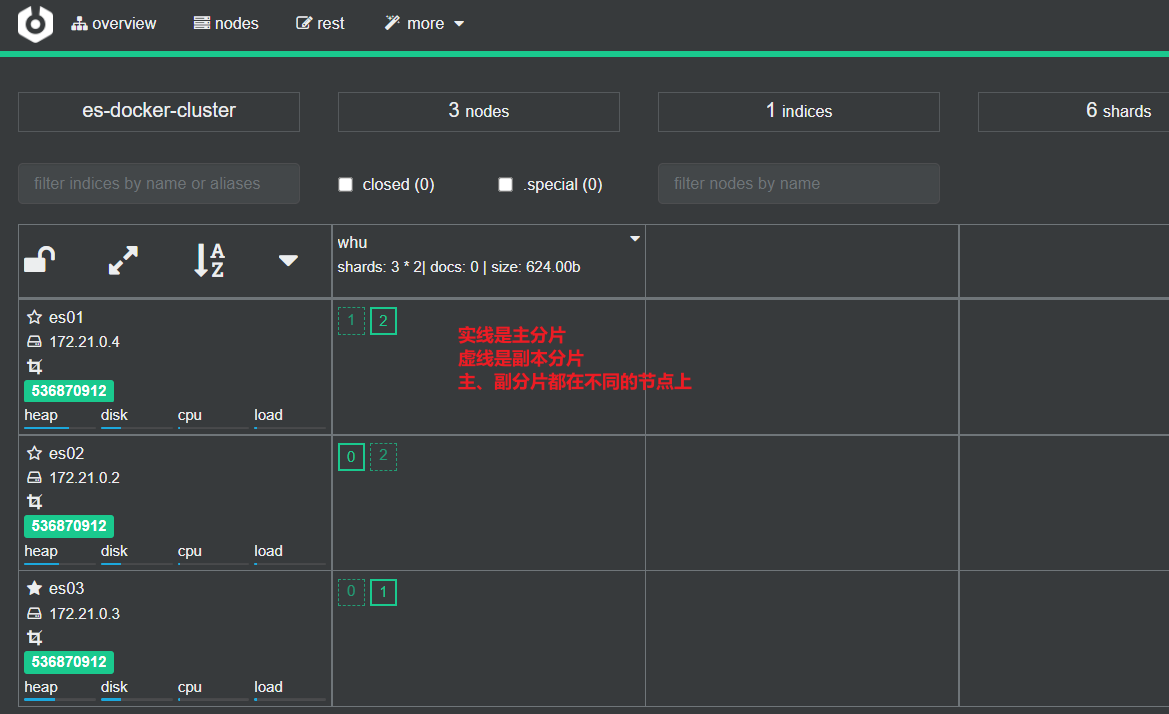
es exactamente igual que la imagen en el diagrama del caso
. Estos encontraron un malentendido. La imagen de arriba no tiene 3 bibliotecas de índices, sino una biblioteca de índices. se divide en 3 segmentos para el almacenamiento. Los fragmentos se almacenan en diferentes instancias de es, y los fragmentos entre las tres instancias son copias de seguridad mutuas