Haga clic en la tarjeta a continuación para seguir la cuenta oficial de " CVer "
Mercancías secas pesadas AI/CV, entregadas por primera vez
Haga clic para ingresar —> [Visión artificial y envío en papel] Grupo de intercambio
Reimpreso de: El corazón de la máquina
Autor: Sebastian Raschka | Editor: Panda W
Usando el método correcto, acelerar el entrenamiento de PyTorch a veces no es tan complicado.
Recientemente, Sebastian Raschka, un conocido investigador en el campo del aprendizaje profundo y principal educador de inteligencia artificial de Lightning AI, pronunció un discurso de apertura "Escalando el entrenamiento del modelo PyTorch con cambios mínimos de código" en CVPR 2023.

Para compartir los resultados de la investigación con más personas, Sebastian Raschka organizó el discurso en un artículo. El artículo explora cómo escalar el entrenamiento del modelo PyTorch con cambios mínimos en el código y muestra que el enfoque está en aprovechar los enfoques de precisión mixta y los modos de entrenamiento de múltiples GPU, en lugar de las optimizaciones de máquina de bajo nivel.
El artículo utiliza Visual Transformer (ViT) como modelo básico. El modelo ViT comienza desde cero con un conjunto de datos básicos. Después de aproximadamente 60 minutos de entrenamiento, logra un 62 % de precisión en el conjunto de prueba.
Dirección de GitHub: https://github.com/rasbt/cvpr2023
El siguiente es el texto original del artículo:
construir punto de referencia
En las siguientes secciones, Sebastian explora cómo mejorar el tiempo y la precisión del entrenamiento sin una refactorización extensa del código.
Quiero señalar que los detalles del modelo y el conjunto de datos no son la principal preocupación aquí (solo están destinados a ser lo más simples posible para que los lectores puedan reproducir en sus propias máquinas sin descargar e instalar demasiadas dependencias). Todos los ejemplos compartidos aquí están disponibles en GitHub, donde los lectores pueden explorar y reutilizar el código completo.
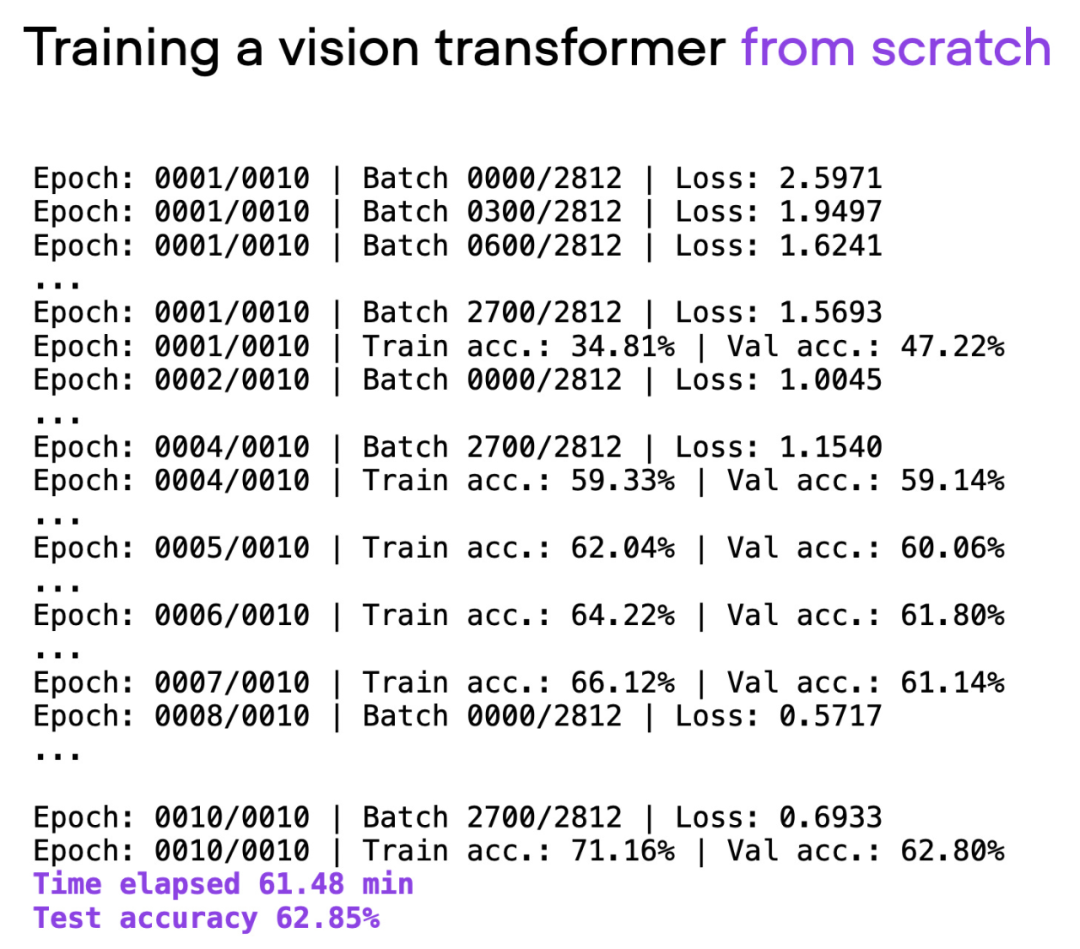
Salida del script 00_pytorch-vit-random-init.py.
no entrenes desde cero
Hoy en día, entrenar modelos de aprendizaje profundo para texto o imágenes desde cero suele ser ineficiente. Usualmente usamos modelos pre-entrenados y ajustamos los modelos para ahorrar tiempo y recursos informáticos mientras logramos mejores resultados de modelado.
Si considera la misma arquitectura de ViT utilizada anteriormente, entrene previamente en otro conjunto de datos (ImageNet) y ajústelo, puede lograr un mejor rendimiento predictivo en menos tiempo: 20 minutos (3 épocas de entrenamiento) para lograr una precisión de prueba del 95 %.
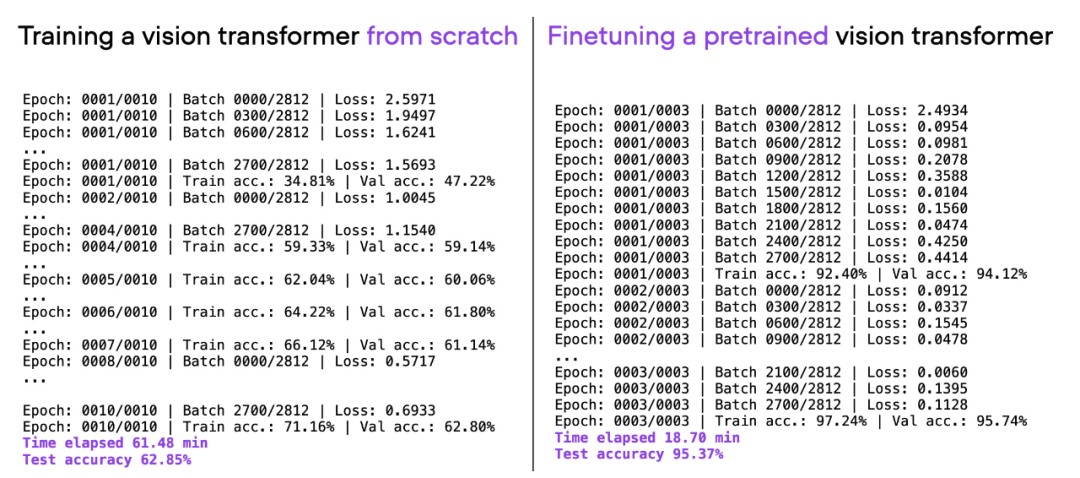
Comparación de 00_pytorch-vit-random-init.py y 01_pytorch-vit.py.
Mejorar el rendimiento informático
Podemos ver que el ajuste fino puede mejorar en gran medida el rendimiento del modelo en comparación con el entrenamiento desde cero. El siguiente histograma resume esto.
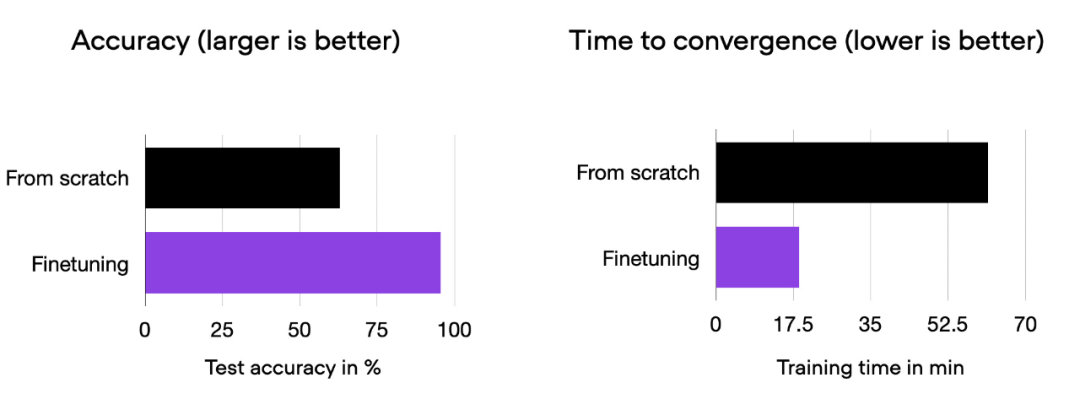
Histograma de comparación de 00_pytorch-vit-random-init.py y 01_pytorch-vit.py.
Por supuesto, el rendimiento del modelo puede variar con diferentes conjuntos de datos o tareas. Pero para muchas tareas de texto e imágenes, vale la pena comenzar con un modelo entrenado previamente en un conjunto de datos público común.
Las siguientes secciones exploran varias técnicas para acelerar el tiempo de entrenamiento sin sacrificar la precisión de la predicción.
Biblioteca de código abierto Fabric
Una forma de escalar de manera eficiente el entrenamiento en PyTorch con cambios mínimos en el código es usar la biblioteca Fabric de código abierto, que se puede ver como una biblioteca/interfaz contenedora liviana para PyTorch. Instalar a través de pip.
pip install lightningTodas las técnicas exploradas a continuación también se pueden implementar en PyTorch puro. El objetivo de Fabric es facilitar este proceso.
Antes de explorar "Técnicas avanzadas para acelerar su código", cubramos los pequeños cambios necesarios para integrar Fabric en su código PyTorch. Una vez que se realizan estos cambios, las funciones avanzadas de PyTorch se pueden usar fácilmente cambiando solo una línea de código.
Las diferencias entre el código de PyTorch y el código modificado para usar Fabric son sutiles e implican solo modificaciones menores, como se muestra en el siguiente código:

Código PyTorch simple (izquierda) y código PyTorch usando Fabric
Resumiendo la figura anterior, puede obtener los tres pasos para convertir el código ordinario de PyTorch en PyTorch+Fabric:
Importe Fabric y cree una instancia de un objeto Fabric.
Utilice Fabric para configurar el modelo, el optimizador y el cargador de datos.
La función de pérdida usa fabric.backward() en lugar de loss.backward().

Estos cambios menores brindan una forma de aprovechar las funciones avanzadas de PyTorch sin refactorizar más el código existente.
Antes de sumergirse en las "características avanzadas" a continuación, asegúrese de que el tiempo de ejecución de entrenamiento y el rendimiento predictivo del modelo sean los mismos que antes.
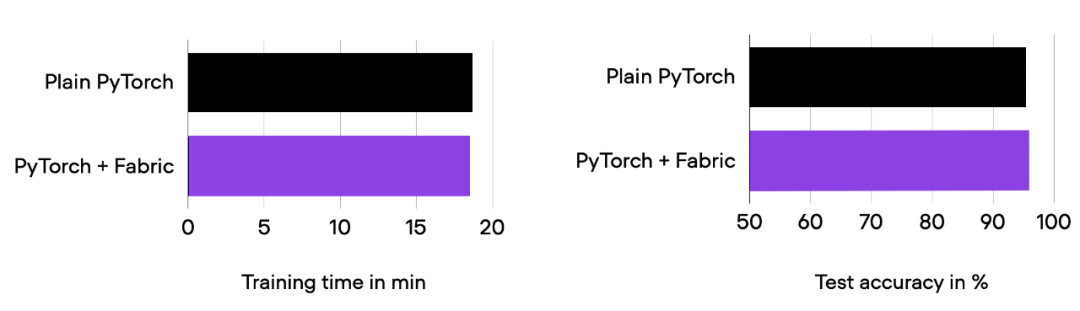
Resultados de la comparación de 01_pytorch-vit.py y 03_fabric-vit.py.
Como puede ver en el histograma anterior, el tiempo de ejecución y la precisión del entrenamiento son exactamente los mismos que antes, como se esperaba. Entre ellos, cualquier fluctuación puede atribuirse a la aleatoriedad.
En las secciones anteriores, modificamos el código PyTorch usando Fabric. ¿Por qué molestarse? A continuación, probará técnicas avanzadas como precisión mixta y entrenamiento distribuido, solo cambie una línea de código, coloque el siguiente código
fabric = Fabric(accelerator="cuda")cambiado a
fabric = Fabric(accelerator="cuda", precision="bf16-mixed")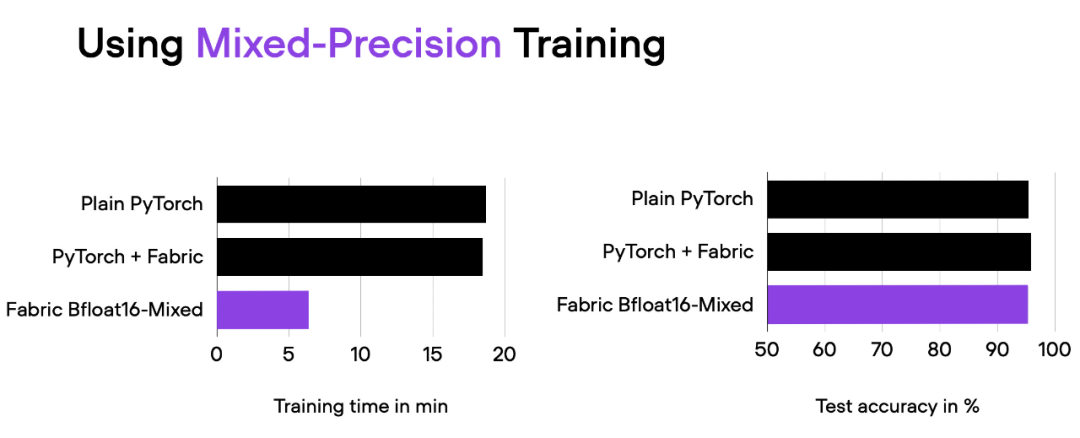
Resultados de la comparación del script 04_fabric-vit-mixed-precision.py. Dirección de la secuencia de comandos: https://github.com/rasbt/cvpr2023/blob/main/04_fabric-vit-mixed-precision.py
Con el entrenamiento mixto de precisión, reducimos el tiempo de entrenamiento de unos 18 minutos a 6 minutos manteniendo el mismo rendimiento predictivo. Esta reducción en el tiempo de entrenamiento se puede lograr simplemente agregando el parámetro "precision="bf16-mixed"" al instanciar el objeto Fabric.
Comprender el mecanismo de precisión mixto
El entrenamiento de precisión mixto utiliza esencialmente precisión de 16 y 32 bits para garantizar que no se pierda la precisión. Calcular gradientes en la representación de 16 bits es mucho más rápido que en el formato de 32 bits y también ahorra mucha memoria. Esta estrategia es muy beneficiosa en situaciones con limitaciones de memoria o computación.
La razón por la que se denomina entrenamiento de precisión "mixto" en lugar de "bajo" es que no todos los parámetros y operaciones se convierten en números de coma flotante de 16 bits. En cambio, cambia entre operaciones de 32 bits y 16 bits durante el entrenamiento, de ahí el nombre de precisión "mixta".
Como se muestra en la siguiente figura, el entrenamiento mixto de precisión implica los siguientes pasos:
Convierta pesos a una precisión más baja (FP16) para un cálculo más rápido;
Calcular el gradiente;
Convierta los gradientes de nuevo a mayor precisión (FP32) para lograr estabilidad numérica;
Actualice los pesos originales con los gradientes escalados.
Este enfoque permite un entrenamiento eficiente mientras mantiene la precisión y la estabilidad de la red neuronal.
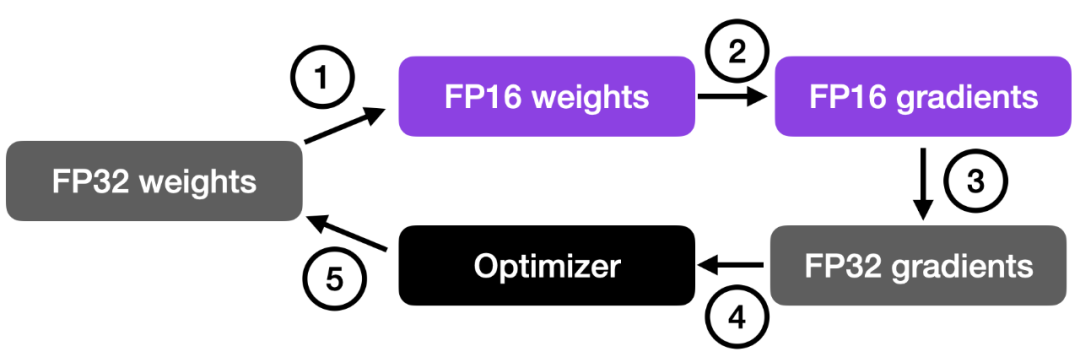
Los pasos más detallados son los siguientes:
Convertir pesos a FP16: en este paso, los pesos (o parámetros) de la red neuronal, originalmente representados en formato FP32, se convierten al formato FP16 de menor precisión. Esto reduce el consumo de memoria y, dado que las operaciones de FP16 requieren menos memoria, el hardware puede procesarlas más rápido.
Compute Gradients: use pesos FP16 de menor precisión para la propagación hacia adelante y hacia atrás de las redes neuronales. Este paso calcula los gradientes (derivadas parciales) de la función de pérdida con respecto a los pesos de la red, y estos gradientes se utilizan para actualizar los pesos durante la optimización.
Convierta los gradientes de nuevo a FP32: después de calcular los gradientes en formato FP16, vuelva a convertirlos al formato FP32 de mayor precisión. Esta transformación es importante para mantener la estabilidad numérica, evitando problemas como la desaparición o explosión de gradientes que pueden ocurrir cuando se utiliza aritmética de menor precisión.
Multiplicar tasa de aprendizaje y actualizar pesos: El gradiente en formato FP32 multiplicado por la tasa de aprendizaje se utilizará para actualizar los pesos (valores escalares utilizados para determinar el tamaño del paso durante la optimización).
El producto del paso 4 se utiliza para actualizar los pesos originales de la red neuronal FP32. La tasa de aprendizaje ayuda a controlar la convergencia del proceso de optimización y es importante para lograr un buen rendimiento.
flotador cerebral 16
Anteriormente hablamos sobre el entrenamiento de precisión "flotante de 16 bits". Cabe señalar que en el código anterior, se especificó precision="bf16-mixed" en lugar de precision="16-mixed". Ambas son opciones válidas.
Aquí, "bf16" en "bf16-mixed" significa Brain Floating Point (bfloat16). Google desarrolló este formato para su uso en aplicaciones de aprendizaje automático y aprendizaje profundo, especialmente en unidades de procesamiento de tensor (TPU). En comparación con el formato tradicional float16, Bfloat16 amplía el rango dinámico, pero sacrifica cierta precisión.
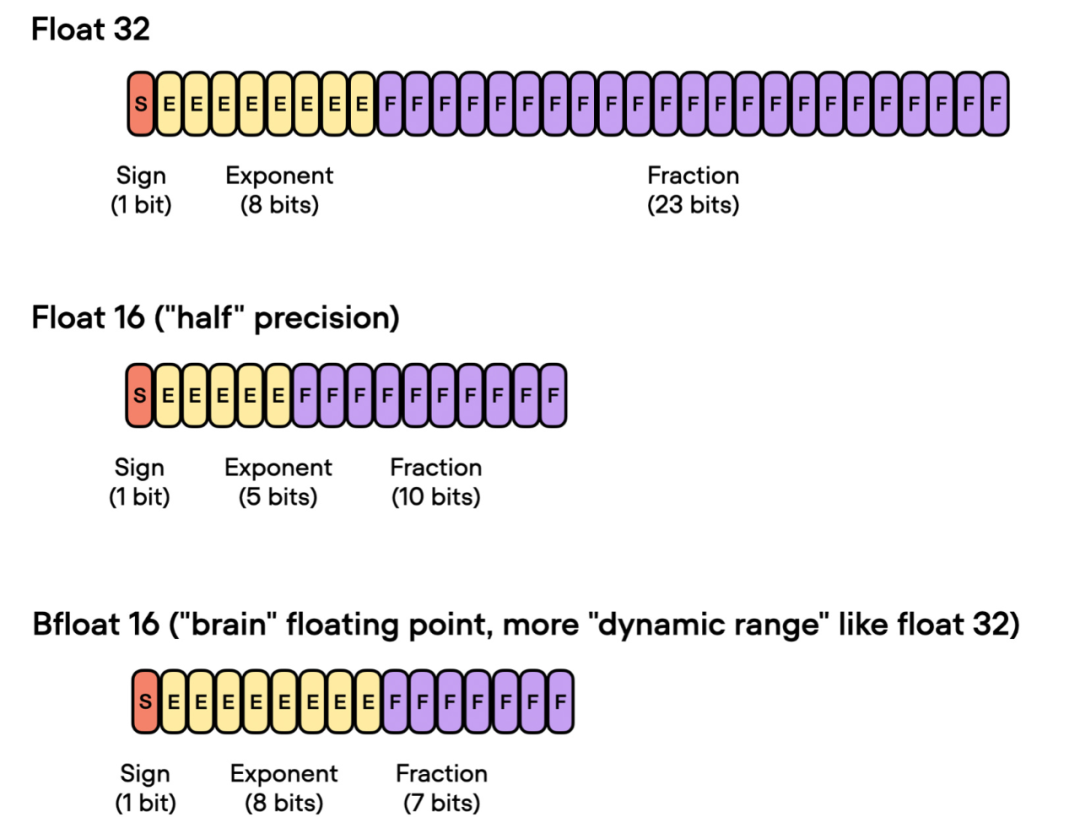
El rango dinámico extendido permite que bfloat16 represente números muy grandes y muy pequeños, lo que lo hace más adecuado para el rango de valores que se pueden encontrar en las aplicaciones de aprendizaje profundo. Sin embargo, una menor precisión puede afectar la exactitud de algunos cálculos o causar errores de redondeo en algunos casos. Pero en la mayoría de las aplicaciones de aprendizaje profundo, esta precisión reducida tiene poco impacto en el rendimiento del modelado.
Aunque bfloat16 se desarrolló originalmente para TPU, varias GPU NVIDIA admiten bfloat16, comenzando con la GPU A100 Tensor Core de la arquitectura NVIDIA Ampere.
Podemos comprobar si la GPU soporta bfloat16 con el siguiente código:
>>> torch.cuda.is_bf16_supported()
TrueSi su GPU no es compatible con bfloat16, puede cambiar precision="bf16-mixed" a precision="16-mixed".
Entrenamiento multi-GPU y paralelismo de datos totalmente fragmentados
Lo siguiente que debe intentar es modificar el entrenamiento multi-GPU. Esto es beneficioso si tenemos varias GPU a nuestra disposición, ya que permite que nuestro modelo se entrene mucho más rápido.
Aquí se presenta una técnica más avanzada: el paralelismo de datos totalmente fragmentados (FSDP), que utiliza tanto el paralelismo de datos como el paralelismo de tensor.

En Fabric, podemos usar FSDP para agregar la cantidad de dispositivos y estrategias de entrenamiento multi-GPU de las siguientes maneras:
fabric = Fabric(
accelerator="cuda", precision="bf16-mixed",
devices=4, strategy="FSDP" # new!
)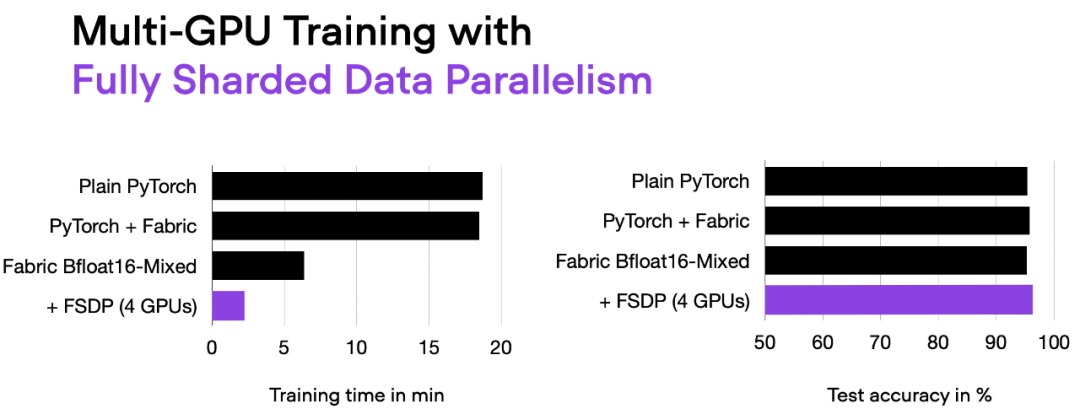
Salida del script 06_fabric-vit-mixed-fsdp.py.
Ahora, con 4 GPU, nuestro código se ejecuta en aproximadamente 2 minutos, casi 3 veces más rápido que cuando se entrena solo con precisión mixta.
Comprender el paralelismo de datos y el paralelismo de tensores
En el paralelismo de datos, los minilotes de datos se dividen y hay una copia del modelo en cada GPU. Este proceso acelera el entrenamiento del modelo al trabajar en paralelo en varias GPU.
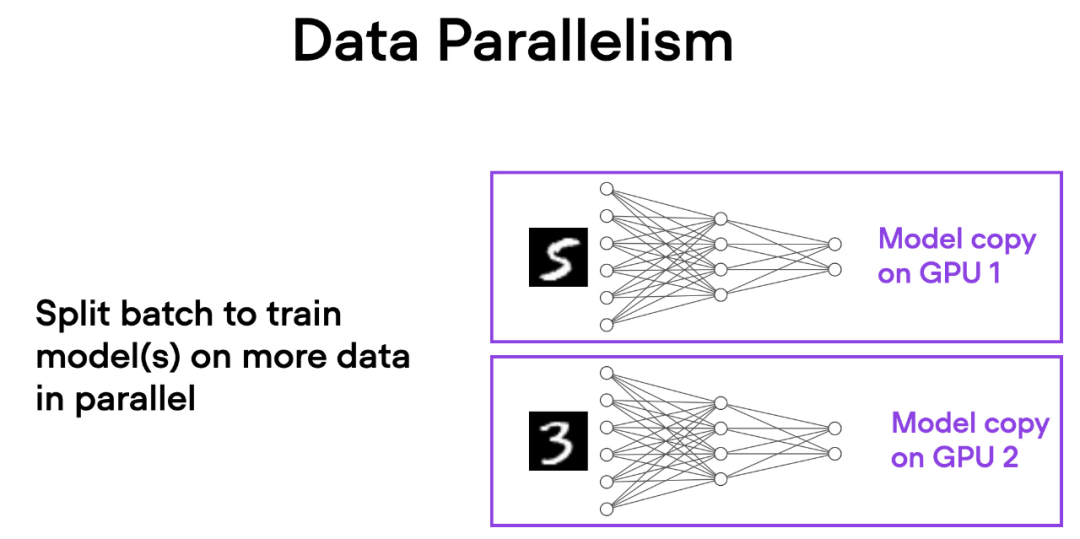
Aquí hay una breve descripción de cómo funciona el paralelismo de datos:
El mismo modelo se replica en todas las GPU.
Cada GPU recibe un subconjunto diferente de datos de entrada (diferentes mini lotes).
Todas las GPU propagan el modelo hacia adelante y hacia atrás de forma independiente, calculando sus respectivos gradientes locales.
Los gradientes se recopilan y promedian en todas las GPU.
El gradiente medio se utiliza para actualizar los parámetros del modelo.
Cada GPU procesa diferentes subconjuntos de datos en paralelo, y el proceso de entrenamiento de todo el modelo se puede acelerar mediante el promedio de gradientes y la actualización de parámetros.
La principal ventaja de este enfoque es la velocidad. Dado que cada GPU procesa diferentes minilotes de datos simultáneamente, el modelo puede procesar más datos en menos tiempo. Esto puede reducir significativamente el tiempo necesario para entrenar un modelo, especialmente cuando se trata de grandes conjuntos de datos.
Sin embargo, el paralelismo de datos también tiene algunas limitaciones. Lo más importante es que cada GPU debe tener una copia completa del modelo y los parámetros. Esto limita el tamaño del modelo que se puede entrenar, ya que el modelo debe caber en la memoria de una sola GPU. Esto no es factible para los ViT o LLM modernos.
A diferencia del paralelismo de datos, el paralelismo de tensor divide el propio modelo en varias GPU. Y en el paralelismo de datos, cada GPU debe adaptarse a todo el modelo, lo que puede convertirse en una limitación a la hora de entrenar modelos más grandes. El paralelismo de tensor permite el entrenamiento de modelos que pueden ser demasiado grandes para una sola GPU al dividir y distribuir el modelo en varios dispositivos para el entrenamiento.
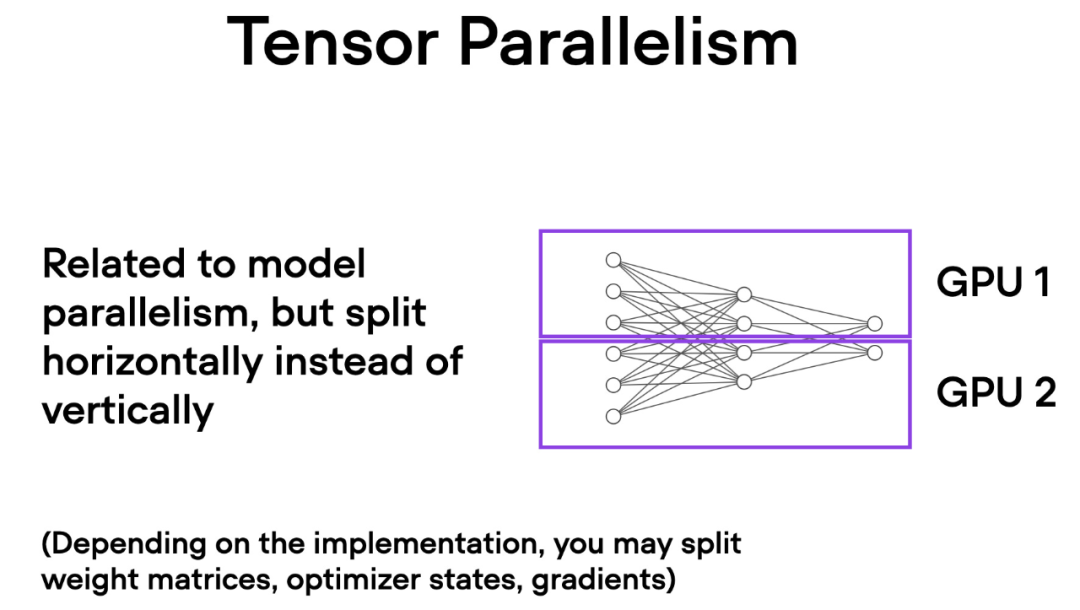
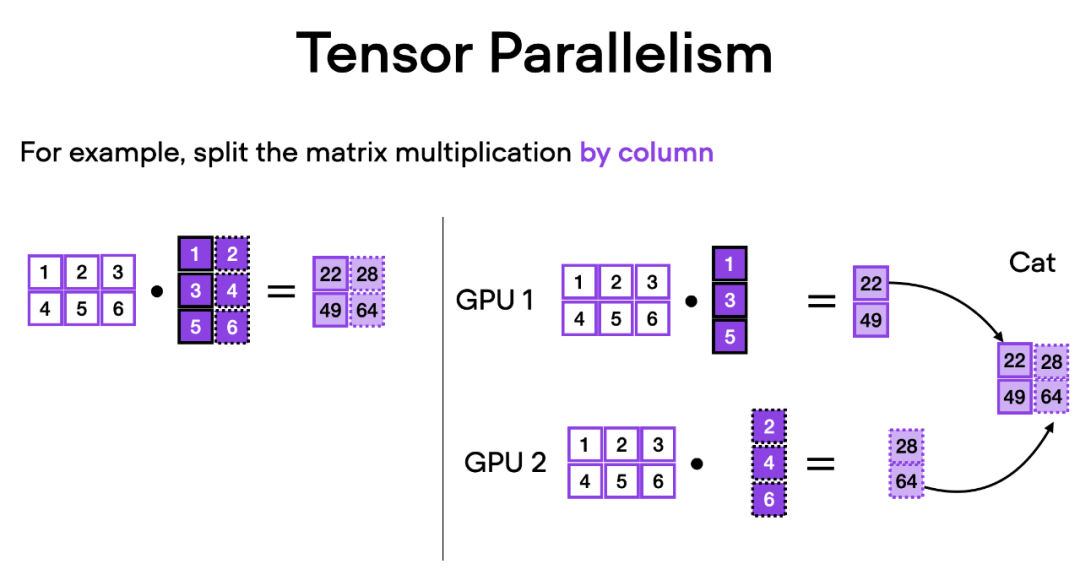
¿Cómo funciona el paralelismo tensorial? Imagine la multiplicación de matrices, hay dos formas de hacer cálculos distribuidos: por fila o por columna. Para simplificar, considere cálculos distribuidos por columnas. Por ejemplo, podemos descomponer una gran operación de multiplicación de matrices en múltiples cálculos independientes, cada uno de los cuales se puede realizar en una GPU diferente, como se muestra en la siguiente figura. Luego, los resultados se concatenan para obtener el resultado, que amortiza efectivamente la carga computacional.
Enlace original: https://magazine.sebastianraschka.com/p/accelerating-pytorch-model-training
Haga clic para ingresar —> [Visión artificial y envío en papel] Grupo de intercambio
ICCV/CVPR 2023 Descarga de papel y código
Respuesta de antecedentes: CVPR2023, puede descargar la colección de documentos CVPR 2023 y codificar documentos de código abierto
后台回复:ICCV2023,即可下载ICCV 2023论文和代码开源的论文合集目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer333,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer333,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉,已汇集数千人!
▲扫码进星球
▲点击上方卡片,关注CVer公众号No es fácil de organizar, dale me gusta y mira![]()