Introducción:
Prometheus es un sistema de monitoreo y alerta de sistemas de código abierto desarrollado a partir del sistema de monitoreo BorgMon de Google. Se utiliza principalmente para monitorear y medir varios datos de series temporales, como el rendimiento del sistema, la latencia de la red, errores de aplicación, etc. Prometheus recopila datos de monitoreo y los almacena en una base de datos de series temporales y luego usa el lenguaje de consulta PromQL para el análisis y la visualización de datos.
Las siguientes son algunas tecnologías que Prometheus utiliza básicamente:
- Instalación y configuración: aprenda a instalar y configurar Prometheus, incluidos componentes como Prometheus Server, Exporters y Pushgateway.
- Recopilación de datos: aprenda a usar Prometheus para recopilar varios datos de monitoreo, incluido el rendimiento del sistema, la latencia de la red, los errores de la aplicación, etc.
- Almacenamiento de datos: aprenda cómo Prometheus almacena los datos de monitoreo recopilados en una base de datos de series temporales y cómo usar diferentes backends de almacenamiento, como el disco local y el almacenamiento remoto.
- Consulta y análisis de datos: aprenda a usar el lenguaje de consulta PromQL para consultar y analizar datos de monitoreo, y cómo mostrar datos a través de herramientas de visualización.
- Reglas de alerta: aprenda a crear y administrar reglas de alerta y cómo enviar alertas a diferentes receptores, como correo electrónico, Slack, PagerDuty, etc.
- Visualización de datos: aprenda a usar la interfaz del tablero proporcionada por Prometheus para mostrar los datos de monitoreo y el estado de las alarmas, y cómo crear su propio tablero arrastrando y soltando y personalizando la configuración.
- Descubrimiento de servicios: aprenda a usar varios mecanismos de descubrimiento de servicios, como Kubernetes, EC2, GCE, etc., para descubrir y monitorear automáticamente el estado de ejecución de los servicios.
- Seguridad y control de permisos: aprenda cómo Prometheus proporciona mecanismos de seguridad y control de permisos, como autenticación, autorización, etc., para garantizar la seguridad del acceso a los datos.
Uso básico y comprensión de la configuración:
Instalación y configuración: aprenda a instalar y configurar Prometheus, incluidos componentes como Prometheus Server, Exporters y Pushgateway.
Servidor Prometeo
Prometheus Server es la parte central de los componentes de Prometheus, responsable de la adquisición, el almacenamiento y la consulta de datos de monitoreo.
En primer lugar, Prometheus Server puede administrar objetivos de monitoreo a través de una configuración estática y también puede usar Service Discovery para administrar dinámicamente objetivos de monitoreo y obtener datos de estos objetivos de monitoreo. Esto significa que Prometheus Server puede descubrir y monitorear varios servicios y objetivos de acuerdo con reglas preestablecidas, ya sean objetivos configurados estáticamente o objetivos descubiertos dinámicamente.
En segundo lugar, Prometheus Server necesita almacenar los datos recopilados. Prometheus Server en sí mismo es una base de datos de series de tiempo, que almacena los datos de monitoreo recopilados en el disco local en forma de series de tiempo. Este método de almacenamiento permite que Prometheus Server guarde efectivamente una gran cantidad de datos de series temporales y realice consultas y análisis de datos rápidos en el futuro.
Finalmente, Prometheus Server proporciona un lenguaje PromQL personalizado y los usuarios pueden usar PromQL para consultar y analizar datos. Al mismo tiempo, Prometheus Server también proporciona API HTTP, los usuarios pueden usar estas API para consultar datos mediante programación. Además, la capacidad de agrupamiento federado de Prometheus Server le permite obtener datos de otras instancias de Prometheus Server, a fin de compartir y administrar unificadamente los datos de monitoreo.
En resumen, Prometheus Server es el componente central del ecosistema Prometheus, que es responsable de recopilar, almacenar y consultar datos de monitoreo, brindando a los usuarios una solución de monitoreo integral y en tiempo real.
Exportadores
Los exportadores son un componente de Prometheus que es responsable de exponer los datos de monitoreo de una aplicación o servicio específico a Prometheus. Los exportadores pueden convertir los datos de monitoreo de la aplicación a un formato que Prometheus pueda reconocer y enviar los datos a Prometheus a través de HTTP u otros métodos.
La función principal de los exportadores es expandir las capacidades de monitoreo de Prometheus para que pueda monitorear más tipos de aplicaciones y servicios. Dado que los formatos de datos de monitoreo de diferentes tipos de aplicaciones y servicios pueden ser diferentes, se requieren diferentes Exportadores para monitorearlos.
El ecosistema Prometheus proporciona muchos exportadores comunes, como Node Exporter para monitorear el rendimiento del sistema, Redis Exporter para monitorear la base de datos Redis, MySQL Exporter para monitorear la base de datos MySQL, etc. Los usuarios pueden elegir los Exportadores apropiados para expandir las capacidades de monitoreo de Prometheus según sus necesidades.
Además de utilizar los exportadores existentes, los usuarios también pueden personalizar sus propios exportadores según sea necesario. Los exportadores personalizados pueden realizar la recopilación y conversión de datos de seguimiento de acuerdo con las necesidades específicas de la aplicación.
En resumen, los exportadores son componentes muy importantes en Prometheus, amplían las capacidades de monitoreo de Prometheus, permitiéndoles monitorear más tipos de aplicaciones y servicios. Los usuarios pueden optar por utilizar los exportadores existentes según sus necesidades o personalizar sus propios exportadores para monitorear aplicaciones específicas.
En esta columna, se actualizará el método de implementación de exportadores.
Pasarela de empuje
Pushgateway es un componente de Prometheus que recibe datos de métricas de trabajos de corta duración.
Dado que Prometheus obtiene principalmente datos de monitoreo a través del modo de extracción, pero algunos trabajos a corto plazo pueden no ser compatibles con el sondeo, o Prometheus no puede extraer los datos directamente debido a razones de red, entonces se puede usar Pushgateway. Los usuarios pueden enviar los datos para ser monitoreados a Pushgateway escribiendo scripts personalizados, y luego Pushgateway envía los datos al servicio de Prometheus correspondiente.
Pushgateway puede ejecutarse de forma independiente en cualquier nodo y no necesita ejecutarse en el cliente supervisado. Puede almacenar los datos de monitoreo recibidos en el disco local y admite métodos de almacenamiento de series temporales personalizados. Al mismo tiempo, Pushgateway también proporciona API HTTP y los usuarios pueden usar estas API para enviar datos a Pushgateway a través de la programación.
En resumen, Pushgateway es un componente importante en Prometheus, se utiliza principalmente para recibir datos de indicadores de trabajos a corto plazo, lo que resuelve el problema de que Prometheus no puede obtener directamente estos datos.
Más información sobre la escritura de archivos de configuración:
La escritura personalizada debe realizarse de acuerdo con nuestro archivo de configuración realista
Cabe señalar que al usar estas configuraciones en Docker, es mejor montarlas en forma de volúmenes de datos de montaje.
Los archivos de configuración de Prometheus suelen incluir los siguientes tipos:
rule_files: archivo de reglas, utilizado para configurar las reglas de alarma y la configuración de agregación de datos.scrape_configs: configuración de recopilación, utilizada para especificar la lista de destino y las reglas de recopilación que se recopilarán.static_configs: Configuración estática, utilizada para especificar la lista de objetivos a recopilar.global: Configuración global, incluida la configuración predeterminada global, como el intervalo para capturar datos de monitoreo, el período de tiempo de espera para capturar la interfaz de datos comerciales, el ciclo de ejecución de las reglas de alarma, etc.alerting: Configuración de alertas, se utiliza para configurar la dirección del Alertmanager al que se envían las alertas.remote_writeyremote_read: Configuración remota de escritura y lectura, utilizada para enviar o leer datos desde direcciones remotas.
Los archivos de configuración anteriores están todos escritos en prometheus.yml.
A continuación se describen las funciones de estos archivos de configuración:
rule_files: este archivo de configuración se utiliza para especificar la ubicación del archivo de reglas de alarma. Los archivos de reglas de alerta contienen condiciones y acciones para activar alertas. Estos archivos de reglas se pueden definir en función de datos agregados para una lógica de alerta más compleja.scrape_configs: este archivo de configuración se utiliza para especificar la lista de objetivos y las reglas de recopilación que se recopilarán. Contiene información como la dirección del servicio, el puerto y el tiempo de espera de la solicitud de cada objetivo, así como también cómo obtener datos del objetivo y las reglas de procesamiento de datos, etc.static_configs: este archivo de configuración es una configuración estática, que se utiliza para especificar manualmente la lista de objetivos que se va a recopilar. A diferencia descrape_configs, la configuración aquí no puede agregar o eliminar objetivos dinámicamente, por lo que es adecuada para entornos estables.global: este archivo de configuración contiene configuraciones predeterminadas globales, como el intervalo para capturar datos de monitoreo, el período de tiempo de espera para capturar interfaces de datos comerciales y el ciclo de ejecución de las reglas de alarma. Estas configuraciones afectan el funcionamiento de todo el sistema Prometheus.alerting: este archivo de configuración se utiliza para especificar la dirección del Alertmanager al que se envía la alerta. Alertmanager es un componente independiente para procesar y enviar información de alerta. Al configurar este archivo, Prometheus puede enviar información de alarma a Alertmanager para su procesamiento.remote_writeyremote_read: estos dos archivos de configuración se utilizan para publicar o leer datos de direcciones remotas. Esto permite que Prometheus se integre con otros sistemas para lograr capacidades de procesamiento y análisis de datos más potentes. Por ejemplo, los datos de monitoreo recopilados se pueden escribir de forma remota en otros sistemas de almacenamiento, o los datos se pueden leer desde una dirección remota para su posterior análisis y procesamiento.
Cabe señalar que los archivos de configuración de Prometheus generalmente deben modificarse y ajustarse adecuadamente antes de su uso para cumplir con los requisitos de entornos y necesidades específicos.
Caso básico del archivo de configuración
archivos_de_reglas:
rule_files se utiliza para especificar la ubicación del archivo de reglas de alarma. Estos archivos de reglas contienen condiciones y acciones para activar alertas. Por ejemplo, se puede definir en función de datos agregados para una lógica de alarma más compleja.
rule_files:
- "first_rules.yml"
- "second_rules.yml"
La configuración anterior especifica dos archivos de reglas, a saber, "first_rules.yml" y "second_rules.yml". Prometheus cargará estos archivos de reglas y aplicará las reglas de alerta en ellos.
Caso específico:
Cuando se menciona rule_files , se refiere al archivo utilizado para definir las reglas para alertar cuando se usa un sistema o aplicación en particular. Estos archivos suelen utilizar un formato y una sintaxis específicos para activar alertas en función de las condiciones.
A continuación se muestra el contenido de un first_rules.yml archivo de muestra con un ejemplo de una regla de alerta:
# first_rules.yml
rules:
- name: "Example Rule"
conditions:
- metric: "CPU Usage"
operator: "<"
threshold: 80
actions:
- email: "[email protected]"
subject: "High CPU Usage Alert"
message: "The CPU usage has exceeded the threshold of 80%."
En el ejemplo anterior, el archivo de reglas contiene una regla denominada "Regla de ejemplo". La regla define una condición que supervisa la métrica "Uso de la CPU" y comprueba si es inferior a un umbral de 80 mediante el operador "<". Si se cumple la condición, se realiza la acción correspondiente. En este ejemplo, la acción consiste en enviar un correo electrónico a la dirección de correo electrónico especificada con el asunto "Alerta de uso elevado de la CPU" y el mensaje contiene detalles sobre la alerta.
Tenga en cuenta que el formato y la sintaxis exactos del archivo de reglas pueden variar según el sistema o la aplicación utilizada. Los ejemplos anteriores son solo para fines ilustrativos y es posible que deban ajustarse según la herramienta en particular que se utilice.
scrape_configs:
El método 1 utiliza la configuración para escribir archivos de configuración para descubrir servicios, etc.:
scrape_configs se utiliza para especificar la lista de objetivos y las reglas de recopilación que se recopilarán. Contiene información como la dirección del servicio, el puerto y el tiempo de espera de la solicitud de cada objetivo, así como también cómo obtener datos del objetivo y las reglas de procesamiento de datos, etc.
scrape_configs:
- job_name: 'example_app'
scrape_interval: 5s
static_configs:
- targets: ['app1.example.com:8080', 'app2.example.com:8080']
La configuración anterior define una tarea de recopilación llamada "example_app" y utiliza una configuración estática para especificar dos direcciones de servicio de destino, a saber, "app1.example.com:8080" y "app2.example.com:8080". Al mismo tiempo, establezca el intervalo de rastreo en 5 segundos.
El método 2 usa archivos de configuración adicionales para descubrir servicios:
scrape_configs:
- job_name: "服务发现"
file_sd_configs:
- files:
- /prometheus/ClientAll/*.json # 用json格式文件方式发现服务,下面的是用yaml格式文件方式,都可以
refresh_interval: 10m
- files:
- /prometheus/ClientAll/*.yaml # 用yaml格式文件方式发现服务
refresh_interval: 10m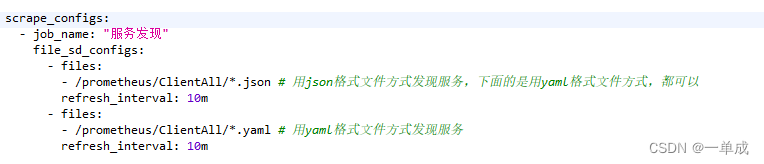
Interpretación del archivo de configuración:
Este archivo de configuración es un fragmento de archivo de configuración de Prometheus para configurar Service Discovery. El descubrimiento de servicios es un método para detectar y rastrear automáticamente los servicios y sus relaciones en el sistema, de modo que Prometheus pueda descubrir y monitorear automáticamente estos servicios.
En un archivo de configuración, scrape_configsmatriz que contiene uno o más elementos de configuración. Cada elemento de configuración es un diccionario que contiene algunos pares clave-valor para definir una configuración de detección de servicio específica.
En este ejemplo, hay dos elementos de configuración:
job_name: "服务发现"- Este elemento de configuración define el nombre de la tarea de monitoreo como "Descubrimiento de servicios".file_sd_configs- El valor correspondiente a esta clave es una matriz que contiene dos diccionarios, cada uno de los cuales define un método de descubrimiento de servicio diferente.
A. El primer diccionario:
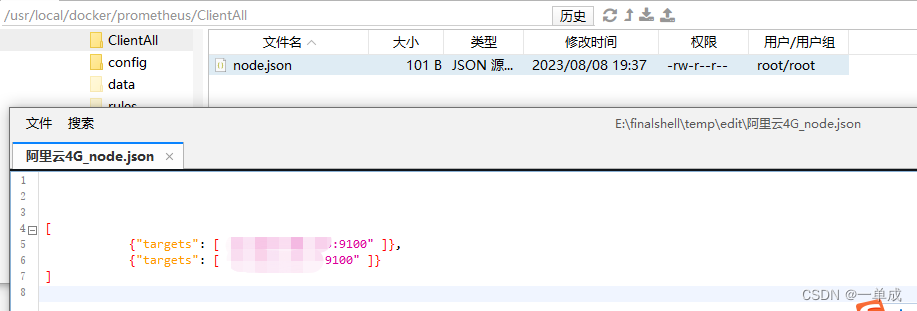
* `files` - 这个键对应的值是一个列表,其中包含一个文件路径`/prometheus/ClientAll/*.json`。这表示Prometheus将从该路径下查找所有满足正则表达式`*.json`的JSON文件。这些文件通常包含了关于服务的元数据和配置信息。
* `refresh_interval` - 这个键对应的值是一个字符串`10m`,表示每隔10分钟刷新一次服务发现配置。
* 总的来说,这个配置告诉Prometheus从指定的路径下读取JSON文件,然后根据这些文件的内容来自动发现并监控服务,并且每隔10分钟刷新一次服务发现配置。
B. El segundo diccionario:
* `files` - 这个键对应的值是一个列表,其中包含一个文件路径`/prometheus/ClientAll/*.yaml`。这表示Prometheus将从该路径下查找所有满足正则表达式`*.yaml`的YAML文件。这些文件通常也包含了关于服务的元数据和配置信息。
* `refresh_interval` - 这个键对应的值也是`10m`,表示每隔10分钟刷新一次服务发现配置。
* 总的来说,这个配置告诉Prometheus从指定的路径下读取YAML文件,然后根据这些文件的内容来自动发现并监控服务,并且每隔10分钟刷新一次服务发现配置。
A través de dicha configuración, Prometheus puede descubrir y monitorear automáticamente los servicios de acuerdo con diferentes formatos de archivo (JSON o YAML) e información de descripción del servicio. Esto es útil para entornos dinámicos o servicios que necesitan escalar automáticamente, porque cuando un servicio cambia, Prometheus puede actualizar automáticamente su configuración de monitoreo y comenzar a monitorear el nuevo servicio.
configuraciones_estáticas:
static_configs es una configuración estática que se utiliza para especificar manualmente la lista de objetivos que se recopilarán. A diferencia de scrape_configs, la configuración aquí no puede agregar o eliminar objetivos dinámicamente, por lo que es adecuada para entornos estables.
static_configs:
- targets: ['target1.example.com:8080']
La configuración anterior especifica manualmente una dirección de servicio de destino como "target1.example.com:8080", y los destinos no se pueden agregar ni eliminar dinámicamente.
global:
global contiene configuraciones predeterminadas globales, como el intervalo para capturar datos de monitoreo, el período de tiempo de espera para capturar interfaces de datos comerciales y el ciclo de ejecución de las reglas de alarma. Estas configuraciones afectan el funcionamiento de todo el sistema Prometheus.
global:
scrape_interval: 10s
evaluation_interval: 10s
La configuración anterior establece el intervalo de captura global en 10 segundos y el ciclo de ejecución de la regla de alarma en 10 segundos.
alertando:
Al usar esto, prepare e instale el componente alertmanager con anticipación
pretender estar conectado
alerta se utiliza para especificar la dirección del Alertmanager al que se envía la alerta. Alertmanager es un componente independiente para procesar y enviar información de alerta. Al configurar este archivo, Prometheus puede enviar información de alarma a Alertmanager para su procesamiento.
alerting:
alertmanagers:
- static_configs:
- targets: ['alertmanager1.example.com:9093']
La configuración anterior especifica que la dirección de Alertmanager a la que se envían las alertas es "alertmanager1.example.com:9093".
¿Viendo que algunos compañeros aquí tendrán dudas?
Estoy usando Prometheus+Grafana, entonces, ¿a quién uso para enviarme alertas?
Lo leí por un tiempo
Grafana en estas dos combinaciones es una plataforma de visualización que no tiene la capacidad de enviar alertas, por lo tanto, Prometheus solo puede enviar alertas.
Alertmanager es un componente independiente para procesar y enviar información de alerta. En Prometheus, Alertmanager se usa para recibir la información de alarma enviada por Prometheus y luego procesar la información, como enrutar la información de alarma a diferentes receptores, silenciar o suprimir la alarma y, finalmente, enviar la información de alarma al receptor.
En el archivo de configuración, alertingla sección se usa para especificar la dirección del Alertmanager al que se envían las alertas. La configuración anterior alerting: alertmanagers: - static_configs: - targets: ['alertmanager1.example.com:9093']especifica que la dirección de Alertmanager a la que se envían las alertas es "alertmanager1.example.com:9093".
En esta configuración, alertmanagerses una lista donde cada elemento contiene una static_configssección. static_configsEs un diccionario, el valor correspondiente a la targetsclave es una lista, incluida la dirección de Alertmanager. En este ejemplo, solo hay una dirección 'alertmanager1.example.com:9093'.
A través de dicha configuración, Prometheus puede enviar la información de la alarma al Alertmanager especificado para su procesamiento.
Un caso de alarma del uso de Alertmanager como componente independiente para enviar correos electrónicos y DingTalk
Alertmanager proporciona una forma de configurar el receptor de notificaciones (receptor) para recibir información de alerta. Un receptor de notificaciones define un conjunto de acciones relacionadas con las alertas, como enviar correos electrónicos, enviar mensajes SMS, almacenar información de alertas en un sistema, etc. Al configurar los receptores de notificaciones, puede especificar las acciones que deben realizarse cuando Prometheus activa una alerta.
Lo siguiente es parte de un archivo de configuración de Alertmanager de ejemplo que configura un receptor de notificaciones que envía correos electrónicos:
global:
smtp_smarthost: 'smtp.example.com:587'
smtp_from: '[email protected]'
smtp_auth_username: 'alertmanager'
smtp_auth_password: 'password'
smtp_require_tls: false
receivers:
- name: 'email'
email_configs:
- to: '[email protected]'
from: '[email protected]'
subject: '[Alertmanager] Alerts for {
{ .接收器的名字 }}'
smtp_auth:
username: 'alertmanager'
password: 'password'
smtp_smarthost: 'smtp.example.com:587'
require_tls: false
En esta configuración, definimos un receptor de notificaciones llamado "correo electrónico" y especificamos una configuración para enviar correos electrónicos. Puedes modificar esta configuración según tus necesidades, como modificar el destinatario, remitente, asunto, etc. del correo.
Luego, debe especificar este receptor de notificaciones en el archivo de configuración de Alertmanager. Lo siguiente es parte de un archivo de configuración de Alertmanager de muestra:
route:
receiver: 'email'
En esta configuración, especificamos que cuando Alertmanager recibe mensajes de alerta, deben enviarse a un receptor de notificaciones llamado "email".
Finalmente, debe implementar el archivo de configuración de Alertmanager en el servidor donde se encuentra Alertmanager y asegurarse de que Alertmanager pueda leer y cargar este archivo de configuración. Luego, cuando Prometheus activa una alarma, Alertmanager enviará una notificación por correo electrónico correspondiente según la configuración.
Existe una asociación entre Alertmanager y rule_files
Alertmanager es un componente para administrar y enviar información de alertas, y rule_files es un archivo para configurar reglas de alertas.
En Prometheus, las reglas de alerta se definen en función de las expresiones del lenguaje de expresiones de Prometheus, que se utilizan para detectar condiciones específicas y activar alertas. Estas reglas se almacenan en rule_files. Alertmanager compara y posteriormente procesa la información de alarma enviada por Prometheus al leer las reglas en rule_files.
El archivo de configuración de Alertmanager puede especificar varios archivos de reglas y cada archivo contiene un conjunto de reglas de alerta. Al asociar estos archivos de reglas con los archivos de configuración de Alertmanager, se puede realizar el procesamiento y la notificación de información de alarma.
Aquí está la sección relevante de un archivo de configuración de Alertmanager de ejemplo que especifica la ruta a rule_files:
global:
# rule_files字段指定了告警规则文件的路径
rule_files:
- 'rules/basic_rules.yml'
- 'rules/complex_rules.yml'
En esta configuración, especificamos dos archivos de reglas: basic_rules.yml y complex_rules.yml. Alertmanager leerá las reglas de alerta en estos dos archivos y realizará un procesamiento de comparación y seguimiento de la información de alerta recibida de acuerdo con estas reglas.
Al configurar los archivos de reglas, puede definir y administrar las reglas de alerta según sus necesidades y asociar estas reglas con el archivo de configuración de Alertmanager para realizar las acciones correspondientes cuando Prometheus activa una alerta.
Cómo especificar qué archivos de reglas quiero usar en estas advertencias
En el archivo de configuración de Alertmanager, rule_filesel archivo de reglas de alerta que se utilizará se puede seleccionar especificando un campo. rule_filesEl campo acepta una lista de cadenas, cada una de las cuales representa la ruta a un archivo de reglas. Los campos se pueden agregar o modificar en el archivo de configuración rule_filespara especificar qué archivo de reglas usar.
Lo siguiente es parte de un archivo de configuración de Alertmanager de muestra que muestra cómo especificar el archivo de reglas a usar:
global:
# rule_files字段指定了告警规则文件的路径
rule_files:
- 'path/to/rule_file_1.yml'
- 'path/to/rule_file_2.yml'
route:
# route字段指定了告警处理和通知的路由规则
receiver: 'ReceiverName'
En este ejemplo, especificamos dos archivos de reglas: 'ruta/al/archivo_de_reglas_1.yml' y 'ruta/al/archivo_de_reglas_2.yml'. Alertmanager rule_filesleerá estos archivos de reglas en el orden definido en ellos. Puede modificar o agregar más archivos de reglas según sea necesario, simplemente agregue sus rutas a rule_filesla lista.
Asegúrese de que, después de modificar el archivo de configuración de Alertmanager, lo implemente en el servidor donde se encuentra Alertmanager y asegúrese de que Alertmanager pueda leer y cargar este archivo de configuración. De esta forma, cuando Prometheus active una alarma, Alertmanager la comparará y la procesará de acuerdo con el archivo de reglas especificado.
El caso de usar Alertmanager para alertas
Al usar Alertmanager para enviar alertas, puede implementar reglas de alerta para situaciones específicas configurando rule_files. El siguiente es un ejemplo que muestra cómo usar Alertmanager y rule_files para enviar alertas, incluido el envío de información de alerta a DingTalk y correo electrónico.
Primero, asegúrese de haber instalado y configurado Alertmanager y Prometheus, y de haber creado receptores para enviar DingTalk y correos electrónicos.
Cree un archivo de reglas:
Cree un rules/alerting_rules.ymlarchivo de reglas llamado con el siguiente contenido:
groups:
- name: alerting_rules
interval: 1m
rules:
- alert: AlertName
expr: some_metric > 100
for: 1m
labels:
severity: high
annotations:
summary: High value detected
description: An alert has been triggered for the 'some_metric' metric exceeding 100.
En este archivo de reglas, definimos una AlertNameregla de alerta denominada , que utiliza una expresión some_metric > 100para detectar valores superiores a 100. La alarma se activará cuando el indicador supere los 100 durante 1 minuto. Configuramos la etiqueta severity: highy la información del comentario summaryy para la alerta description.
Configure el receptor de Alertmanager:
Según sus necesidades, configure el receptor de Alertmanager para recibir y procesar información de alertas. Por ejemplo, si utiliza DingTalk como receptor, configúrelo de acuerdo con la configuración del receptor DingTalk. Si utiliza el correo electrónico como receptor, siga la configuración del receptor de correo electrónico. Asegúrese de que el receptor esté configurado correctamente y habilitado.
La siguiente es la sección relevante de un archivo de configuración de Alertmanager de ejemplo (alertmanager.yml) para especificar los destinatarios de DingTalk:
global:
# 其他配置项...
receivers:
- name: 'DingTalkReceiver'
dingtalk_config:
webhook_url: 'https://oapi.dingtalk.com/robot/send?access_token=your_access_token'
send_resolved: true
route:
receiver: 'DingTalkReceiver'
En este ejemplo, creamos un DingTalkReceiverreceptor llamado y configuramos la información relacionada con DingTalk, incluida la URL del webhook y el envío de alertas resueltas. También especificamos este receptor como el receptor predeterminado ( receiver: 'DingTalkReceiver').
Configura las reglas de alerta de Prometheus:
En Prometheus, debe importar las reglas de alerta del archivo de reglas a Prometheus. Importa el archivo de reglas a Prometheus con el siguiente comando:
kubectl apply -f rules/alerting_rules.yml
-
Inicie Alertmanager y Prometheus:
Inicie los servicios Alertmanager y Prometheus y asegúrese de que se estén ejecutando. Puede iniciar Alertmanager con el siguiente comando:
kubectl apply -f alertmanager.yml
-
Activar una alerta:
Para activar una alerta, puede activar manualmente una condición que cumpla una regla de alerta. En Prometheus, puede usar pushgatewaypara simular datos y activar reglas de alerta. Por ejemplo, use el siguiente comando para enviar datos simulados a pushgateway:
curl -X POST -H "Content-Type: application/json" --data '{"some_metric": 200}' http://<pushgateway_address>:<pushgateway_port>/metrics/job/alerting_rules/instance/prometheus-k8s-01/prometheus-k8s-01/default/alerting_rules/DingTalkReceiver/alertname/AlertName/severity/high/summary/High value detected/description/An alert has been triggered for the 'some_metric' metric exceeding 100. --header "Content-Type: application/json"
-
Ver información de alarma:
Una vez que se cumple la condición de la regla de alerta, P·1·1·1·1·1rometheus enviará la información de alerta a Alertmanager. Alertmanager enviará información de alerta según los destinatarios configurados. En este ejemplo, recibiremos información de alarma a través de DingTalk. Puede ver la información de alarma recibida en DingTalk.
Lo anterior es un ejemplo simple que muestra cómo usar Alertmanager y rule_files para enviar información de alerta a DingTalk y correo electrónico. Puede realizar los ajustes y configuraciones correspondientes según las necesidades reales.
En esta columna, habrá un artículo de explicación sobre el componente Alertmanager.
escritura_remota y lectura_remota:
remote_write y remote_read se utilizan para publicar o leer datos desde una dirección remota. Esto permite que Prometheus se integre con otros sistemas para lograr capacidades de procesamiento y análisis de datos más potentes. Por ejemplo, los datos de monitoreo recopilados se pueden escribir de forma remota en otros sistemas de almacenamiento, o los datos se pueden leer desde una dirección remota para su posterior análisis y procesamiento.
remote_write:
- url: "http://remote-write-url"
write_relabel_configs:
- source_labels: ['__address__']
regex: '^localhost:(.*)$'
target_label: '__address__'
replacement: '${1}'
- url: "https://another-remote-write-url"
...
remote_read:
- url: "http://remote-read-url"
params: {'match[]': 'some_metric'}
- url: "https://another-remote-read-url"
...
La configuración anterior usa remote_write para escribir de forma remota los datos de monitoreo recopilados en dos direcciones diferentes y usa write_relabel_configs para reescribir la dirección de destino. Al mismo tiempo, use remote_read para leer datos de dos direcciones remotas diferentes y especifique el nombre de índice coincidente.
Caso personal:
Resumen:
Al usarlo, debe especificar la ruta del archivo de configuración
global:
scrape_interval: 15s # 设置抓取间隔为每15秒。
evaluation_interval: 15s # 每隔15秒评估规则。
rule_files:
- /prometheus/rules/*.yml # 这里匹配指定目录下所有的.rules文件
scrape_configs:
- job_name: "阿丹服务器" #使用配置来发现服务
static_configs:
- targets: ['ip:9090']
labels:
instance: prometheus
- job_name: "服务发现"
file_sd_configs:
- files:
- /prometheus/ClientAll/*.json # 用json格式文件方式发现服务,下面的是用yaml格式文件方式,都可以
refresh_interval: 10m
- files:
- /prometheus/ClientAll/*.yaml # 用yaml格式文件方式发现服务
refresh_interval: 10m