Ahora presentaré un experimento utilizando myCobot. Esta vez, los experimentos se realizarán utilizando simuladores Cuando se trata de realizar un aprendizaje de refuerzo profundo con robots , puede ser un desafío preparar grandes cantidades de datos de entrenamiento en máquinas físicas. Sin embargo, con los simuladores, es fácil recopilar grandes conjuntos de datos. Sin embargo, los emuladores pueden parecer intimidantes para aquellos que no están familiarizados con ellos. Así que tratamos de usar Isaac Gym, desarrollado por Nvidia, que nos permite lograr todo, desde crear entornos experimentales hasta hacer aprendizaje por refuerzo usando solo código Python . En esta publicación, describiré el método que usamos.
1. Introducción
1.1 ¿Qué es Gimnasio Isaac?
Isaac Gym es un entorno de simulación de física desarrollado por Nvidia para el aprendizaje por refuerzo. Basado en la biblioteca Open AI Gym, los cálculos físicos se realizan en la GPU y los resultados se pueden recibir como tensores de GPU Pytorch, lo que permite una simulación y un aprendizaje rápidos. Las simulaciones de física se realizan con PhysX, que también admite simulaciones de cuerpos blandos con FleX (aunque algunas funciones están limitadas cuando se usa FleX).
El último lanzamiento a partir de abril de 2023 es Preview 3. Si bien las versiones anteriores tenían errores evidentes, la versión 6000 y posteriores han visto mejoras y características adicionales, lo que lo convierte en un entorno de simulación muy atractivo. Se planea una versión futura de Omniverse Isaac Gym que se integra con Isaac Sim. Sin embargo, Isaac Gym es autónomo y está disponible para experimentos en Python. En una publicación de blog anterior ("GPU Server Scaling and A<> Benchmarking"), se mencionó que la investigación y el desarrollo con el simulador Omniverse Isaac habían comenzado, pero se priorizó Isaac Gym para las simulaciones de aprendizaje de refuerzo. Quizás el mayor beneficio de integrar Isaac Gym con Omniverse es la capacidad de usar imágenes fotorrealistas para el reconocimiento de imágenes y la simulación corporal continua de alta precisión, como el trazado de rayos. Será emocionante ver cómo se desarrolla el futuro.
PhysX es un motor de física desarrollado por Nvidia que realiza cálculos de física en tiempo real en la GPU del emulador. Si bien la versión utilizada por Isaac Gym no se ha especificado en el arXiv público ni en la documentación, es probable que se base en PhysX 4, dada su sincronización y separación de FleX. En Omniverse, se usa PhysX 5 y se integra FleX.
FleX también es un motor de física desarrollado por Nvidia, pero en comparación con la simulación de cuerpo rígido de PhysX, puede utilizar la simulación basada en partículas para representar cuerpos blandos y fluidos.
1.2 Propósito de este artículo
Te diré cómo creo y aprendo fácilmente tareas de aprendizaje por refuerzo usando Isaac Gym. como un caso de prueba real
1.3 Medio ambiente
PC1: Ubuntu 20.04, Python 3.8.10, Nvidia RTX A6000
PC2: Ubuntu 18.04, Python 3.8.0, Nvidia RTX 3060 Ti
Tenga en cuenta que se requiere Nvidia Driver 470 o superior.
2. Instalar
En este capítulo, instalaremos Isaac Gym e IsaacGymEnvs. El entorno recomendado es Ubuntu 18.04, 20.04, Python 3.6~3.8, Nvidia Driver==470. Tenga en cuenta que dado que python_requires<3.9 se describe en setup.py de Isaac Gym, no se puede usar tal cual para 3.9 y superior. No he probado en Ubuntu 22.04, pero probablemente esté bien.
2.1 Gimnasio Isaac
Puede descargar el paquete principal de Isaac Gym de forma gratuita desde la página de desarrollador de Nvidia . La documentación se mantiene en formato HTML en el directorio "docs" del paquete (no en el sitio web, nota). Una vez descargado, puedes instalarlo con el siguiente comando:
$ cd isaacgym/python$ pip install -e .Copiar
Sin embargo, dado que PyTorch se especifica como "torch==1.8.0" y "torchvision==0.9.0", al usar una GPU, primero debe instalarlo desde la página oficial que coincida con su entorno. Los archivos de configuración del entorno virtual Docker y Conda también están disponibles. Dado que uso venv para administrar mis entornos virtuales de Python, me quedaré con pip. Tenga en cuenta que he escrito ">" con caracteres de doble ancho debido a problemas con el bloque de código
2.2IsaacGymEnvs
IsaacGymEnvs es un paquete de Python para probar entornos de aprendizaje por refuerzo en Isaac Gym. Con las tareas implementadas de referencia, los entornos de aprendizaje por refuerzo se pueden construir fácilmente utilizando los algoritmos de aprendizaje por refuerzo implementados en rl-games. Incluso para aquellos que planean escribir sus propios algoritmos de aprendizaje por refuerzo, se recomienda probar este paquete para aprender con Isaac Gym. Originalmente se incluyó en Isaac Gym, se bifurcó en Preview3 y ahora está disponible públicamente en GitHub.
$ git clone https://github.com/NVIDIA-Omniverse/IsaacGymEnvs.git$ cd IsaacGymEnvs$ pip install –e .Copiar
Con eso, la instalación necesaria ahora está completa.
3. demostración
Cuando instala Isaac Gym y mira dentro del paquete, encontrará que hay muchos entornos de ejemplo disponibles. Estos también aparecen en la documentación, pero en este artículo nos centraremos en algunos ejemplos relevantes para la creación de entornos de aprendizaje de refuerzo personalizados en el Capítulo 4. Si tiene configurado su entorno, es una buena idea intentar ejecutar algunos de estos ejemplos y ver qué pueden hacer. Incluso puede encontrar que brindan alguna guía sobre cómo usar la API para lograr algo que le interese probar (siéntase libre de leer la documentación si aún no está seguro).
3.1.Isaac Gimnasio
A partir de la versión preliminar 4, hay 27 entornos de muestra disponibles.
● “1080_bolas_de_soledad.py”
El script "1080_balls_of_solitude.py" genera un conjunto de bolas en forma de pirámide que caen. Ejecutar el script sin opciones solo permite colisiones entre esferas dentro del mismo entorno (es decir, dentro de la misma pirámide). La opción "--all_collisions" permite colisiones con pelotas en otros entornos, mientras que la opción "--no_collisions" desactiva las colisiones entre objetos en el mismo entorno. Este script también demuestra cómo configurar los parámetros de la función "create_actor" para agregar objetos al entorno.
● "dof_controls.py"
Este guión tiene un Actor que se mueve en 3D, que es una variación del conocido problema Cartpole en OpenAI Gym. Demuestra cómo configurar un método de control para cada grado de libertad (DOF) del robot, ya sea posición, velocidad o fuerza. Una vez configurados, estos métodos de control no se pueden cambiar durante la simulación y los actores solo se pueden controlar con el método elegido. Olvidar configurar estos métodos de control puede provocar la inmovilización del actuador.
● “franka_nut_bolt_ik_osc.py”
Este guión muestra el brazo robótico articulado de Franka Robotics, Panda, recogiendo una tuerca y atornillándola en un perno. Los brazos se controlan mediante cinemática inversa (IK). El nombre del archivo incluye "OSC", pero el control de OSC no está implementado en este script. Sin embargo, el script "franka_cube_ik_osc.py" incluye control OSC.
Con la adición de colisiones SDF en la versión preliminar 4, se pueden cargar archivos de colisiones de alta resolución, lo que permite un cálculo preciso de las colisiones entre las ranuras de tuercas y pernos (Figura 1). Si bien la carga inicial de SDF puede demorar un tiempo, las cargas posteriores se almacenan en caché y se inician rápidamente.

Figura 1: Simulación de un brazo de panda colocando una tuerca en un perno
● interop_torch.py
Este script demuestra cómo usar la función get_camera_image_gpu_tensor para obtener datos del sensor directamente desde una cámara en la GPU . Los datos obtenidos se pueden generar como un archivo de imagen utilizando OpenCV, como una cámara física normal. Cuando se ejecuta, el script crea un directorio llamado interop_images y guarda las imágenes de la cámara allí. Dado que los datos de simulación no se intercambian entre la GPU y la CPU , las imágenes se pueden procesar rápidamente. Sin embargo, pueden ocurrir errores si se utiliza un entorno multi-GPU. Una solución sugerida en los foros es limitar el uso de GPU a CUDA_VISIBLE_DEVICES=0, pero esto no funciona en el entorno utilizado para este script.
3.2 Ambiente del Gimnasio Isaac
Se implementan 14 tareas de aprendizaje por refuerzo y se pueden evaluar mediante scripts en el directorio de tareas.
● Acerca de los archivos de configuración
Prepare un archivo de configuración escrito en YAML para cada tarea. Las configuraciones comunes se encuentran en config.yaml en el directorio cfg y se pueden cambiar con Hydra usando las opciones de la línea de comandos sin cambiar el archivo YAML. Las configuraciones detalladas para cada entorno de tareas y PhysX se almacenan en el directorio cfg/task/, y las estructuras y selecciones de algoritmos se almacenan en el directorio cfg/train/.
● Acerca de la implementación del algoritmo
El algoritmo de aprendizaje por refuerzo se implementa usando PPO en el juego Rl. Aunque docs/rl_examples.md menciona la opción para seleccionar SAC, actualmente no está incluido en el repositorio.
Las capas NN suelen ser MLP y algunos modelos también incluyen capas LSTM como capas RNN. No hay modelos de ejemplo que incluyan capas CNN, aunque también se pueden agregar capas CNN. En la Sección 5.2, discutimos la experiencia de agregar capas CNN al modelo.
El código de ejemplo se puede ejecutar en el directorio isaacgymenvs donde se encuentra train.py.
● varilla de Carter
python train.py task=Cartpole [opciones]
Esta es la clásica tarea del carro, y el objetivo es mover el carro de tal manera que el poste no se caiga. De forma predeterminada, el modelo se entrena durante 100 épocas, lo que lleva unos 3060 minutos en un entorno PC2 RTX 2Ti y solo 15 segundos en modo sin visor (sin visor). Al probar el modelo con inferencia, funciona bien y el poste se mantiene en posición vertical (después de 30 épocas de entrenamiento, el modelo está lo suficientemente entrenado para mantener el poste en posición vertical). Aunque aparentemente simple, el hecho de que el modelo pueda aprender a realizar esta tarea con éxito es tranquilizador.
● Pilas de cubos de Franke
python train.py task=FrankaCubeStack [opciones]
Esta es una tarea de apilar cajas usando un brazo panda. La articulación del brazo de 7 ejes se aprende paso a paso. La configuración predeterminada es de 10 000 épocas, pero los movimientos del brazo se pueden aprender en unas 1000 épocas. En un entorno PC1 RTX A6000, se tarda entre 20 y 30 minutos en completar el entrenamiento de 1000 épocas. Las Figuras 2 y 3 muestran el estado anterior y posterior del brazo, desde el movimiento aleatorio hasta el agarre y apilado exitoso de cajas.
El espacio de acción consta de 7 dimensiones de las articulaciones de los brazos, mientras que el espacio de observación tiene un total de 26 dimensiones. La función de recompensa está diseñada para escalar de manera diferente para acciones que implican acercarse a cajas, levantar cajas, acercar cajas entre sí y completar con éxito la tarea de apilar.
Es asombroso lo fácil que un brazo puede aprender este nivel de tarea. Sin embargo, es importante tener en cuenta que el aprendizaje asume un sistema de coordenadas mundial definido y posiciones y orientaciones conocidas de los objetos. Por lo tanto, puede que no sea tan sencillo aplicar este comportamiento aprendido a los robots físicos.
Subdivisión de observación de 26 dimensiones:
● 7 dimensiones para mover la posición y orientación de la caja
● 3 dimensiones del vector desde el cuadro apilado hasta el cuadro movido
● 7 tamaños para la posición y orientación de la pinza
● 9 tamaños de articulaciones de brazos y dedos de agarre

Figura 2: FrankaCubeStack antes del entrenamiento

Figura 3: FrankaCubeStack después del entrenamiento
Algunas opciones comunes en train.py incluyen:
● Sin cabeza (Predeterminado: Falso): cuando se establece en Verdadero, el visor no se iniciará. Esto es útil para un entrenamiento intenso o cuando se capturan imágenes de la cámara, ya que el espectador puede ralentizar el proceso considerablemente.
● Prueba (predeterminado: Falso): cuando se establece en Verdadero, el modo de aprendizaje se desactiva, lo que le permite ejecutar el entorno sin capacitación. Esto es útil para generar entornos y comprobar los resultados del aprendizaje.
● punto de control (predeterminado: "): especifica el archivo de pesos de PyTorch para cargar. Los resultados de aprendizaje se guardan en carreras//nn/.pth, esta opción se usa para reanudar el entrenamiento o la prueba.
● num_envs (predeterminado: int): especifica el número de entornos de aprendizaje paralelos. Es importante configurar un número apropiado para evitar una gran cantidad de espectadores durante la prueba (esta opción también se puede configurar durante el entrenamiento, pero cambiarla puede generar errores debido al tamaño del lote y al ruido).
Tenga en cuenta que train.py configura horizon_length y minibatch_size, pero batch_size = horizon_length * num_actors * num_agents, y batch_size deben ser divisibles por minibatch_size. Además, num_actors y num_agents son proporcionales a num_envs, por lo que cambiar solo num_envs puede causar errores.
Otras muestras son fáciles de probar en el entorno, así que pruebe algunas pruebas interesantes.
3.3 Consejos para el espectador
● Dibujar la malla de colisión
El simulador normalmente representa la malla visual del objeto, pero en el visor de Isaac Gym puede cambiar esto para generar una malla de colisión. Para hacer esto, vaya a la pestaña Visor en la ventana del menú y marque Render Collision Mesh. Si los objetos se comportan de manera extraña, es una buena idea verificar que la malla de colisión esté cargada correctamente (a veces, la malla de visión y la malla de colisión tienen orientaciones diferentes, o es posible que la malla no se haya cargado correctamente o no tenga suficiente detalle en el simulador).

Figura 4: Dibujar la malla de colisión
● Reducir el entorno de dibujo
Puede reducir el entorno de renderizado a uno solo sin cambiar ninguna configuración. Al marcar "Mostrar solo los entornos seleccionados" en el menú Actor (como se muestra en la Figura 5), solo se mostrarán los entornos seleccionados. Si hay algún comportamiento extraño, se puede depurar generando el número de entorno y representando solo ese entorno. Esto también aligera la carga de renderizado y puede mejorar el FPS.
Figura 5: Numeración del entorno de dibujo
● Cambiar la posición inicial de la cámara
La posición inicial de la cámara y la orientación se pueden configurar usando la función viewer_camera_look_at(viewer, middle_env, cam_pos, cam_target) de gymapi. En el script de tareas utilizado para el entrenamiento, la función set_viewer debe anularse para realizar cambios.
4. Entorno original y creación de tareas
Finalmente es hora de crear tareas originales para el tema principal.
4.1 Preparación
Preparar scripts y archivos de configuración. El objetivo es aprender una tarea sencilla, la selección de objetos con Mycobot. Así que continuaremos y crearemos una tarea llamada "MycobotPicking". Necesitamos tres archivos:
● Tarea: secuencia de comandos principal de Python
● cfg/task: archivo de configuración YAML para parámetros de entorno y simulación
● cfg/train: archivos de configuración YAML para aprender algoritmos, capas de redes neuronales y parámetros.
Podemos referirnos a la tarea "FrankaCubeStack" mencionada anteriormente y crear estos archivos en consecuencia. Los archivos de configuración son especialmente importantes, podemos copiarlos y modificarlos según nuestros requisitos.
Como muestra la demostración, podemos cargar scripts de tareas desde el archivo train.py usando las opciones de la línea de comandos. Por lo tanto, debemos agregar una declaración de importación para la clase de tarea en el archivo init.py en el directorio de tareas y agregar el nombre de la tarea al pasar los parámetros.
4.2 Creación de entorno
Las clases de tareas se crean heredando de la clase VecTask en el directorio tasks/base, y las tareas tienen la siguiente estructura, como se muestra en la Figura 6.
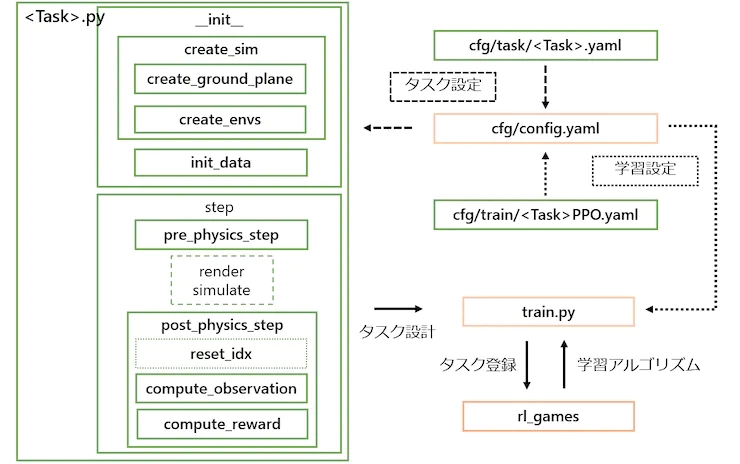
Figura 6: Configuración de tareas. Los que tienen un cuadro naranja no necesitan ser editados, y los que tienen un cuadro verde se crean para cada tarea.
4.2.1 Procesamiento __init__
1. Crear el simulador y el entorno.
● create_sim: esta función crea una instancia del simulador. El proceso en sí se define en la clase principal y las propiedades se establecen en el archivo de configuración, como la gravedad y el tiempo de paso. Similar a FrankaCubeStack, esta función utiliza las siguientes dos funciones para generar el plano de tierra y el actuador.
● create_ground_plane: esta función genera un plano de tierra a partir de la dirección normal del plano de entrada. Si desea crear un terreno irregular, puede consultar el ejemplo de terrain_creation.
● create_envs: esta función carga y establece las propiedades del archivo de caracteres, genera los actores y paraleliza el entorno. En esta tarea, generamos myCobot desde URDF y el objeto de destino desde la API create_box. El URDF para myCobot se basa en el URDF utilizado en experimentos anteriores con MoveIt, al que agregamos una pinza para recoger (los detalles sobre la pinza se explican en la Sección 5.1).
2. Inicialización de datos
● init_data: esta función define las variables de entorno del archivo de configuración y prepara búferes para los tensores de datos procesados por Isaac Gym (PhysX). Los datos necesarios para calcular estados y recompensas se definen como variables de clase. La API carga datos de tensor en un búfer, y el búfer se actualiza en cada paso llamando a la función de actualización correspondiente.
4.2.2 Pasos de procesamiento
1. Procesamiento paso a paso:
La función de paso principal se define en la clase principal y no es necesario modificarla. Sin embargo, se requieren los siguientes dos pasos como método abstracto:
● pre_physics_step: manipula al actor con acciones. El tamaño de las acciones se define en la configuración como ["env"]["numActions"]. Para el brazo y la pinza de 6 ejes de myCobot, lo configuramos en 7D.
● post_physics_step: Calcular observaciones y recompensas. Compruebe también para restablecer el entorno. Lo configuramos para que se reinicie después de alcanzar un máximo de 500 pasos o después de un ascenso exitoso.
Pasos fijos, aplicar simulación física → → observar la acción del cálculo de la recompensa, transferir datos para el aprendizaje. Incluso si solo escribe "aprobado" aquí, puede verificar el entorno al iniciar el visor.
● reset_idx: Devuelve el entorno a su estado inicial. Por supuesto, la aleatoriedad del estado inicial está estrechamente relacionada con la generalización del aprendizaje. Establecemos myCobot como una pose inicial y restablecemos aleatoriamente la posición del objeto de destino al alcance de myCobot.
2. Estado y cálculo de recompensas:
● compute_observation: actualiza cada búfer con la función de vaciado y coloca el estado deseado en obs_buf. El tamaño de obs_buf se define en la configuración como ["env"]["numObservation"].
● compute_reward: calcula la recompensa. Se obtiene una recompensa cuando la pinza está cerca de la posición de agarre del objeto objetivo (entre los dedos), y se obtiene una recompensa mayor a medida que aumenta la altura del objeto objetivo.
4.3 Implementación de la capacitación
Ahora que se creó el esqueleto de la tarea, entrenemos el modelo. Podemos comenzar a entrenar el modelo con el siguiente comando:
python train.py task=MycobotPicking --el anuncio menos
Después de 200 épocas, se guardarán los pesos iniciales, y si la recompensa aumenta, se guardarán los nuevos pesos. Sin embargo, las tareas que creamos pueden no funcionar a la perfección y el proceso de entrenamiento puede detenerse rápidamente. En la siguiente sección, discuto los ajustes que hice a la tarea para mejorar su rendimiento.
4.4 Coordinación de tareas
Al probar con los pesos aprendidos, puede depurar por qué el entrenamiento no funciona bien. ejecutaste el comando
python train.py task=MycobotPicking test=True checkpoint=runs/MycobotPicking/nn/[checkpoint].pth
para probar el modelo. Sin embargo, se encuentra con el problema de un movimiento deficiente de la pinza. A pesar de sus esfuerzos por resolver el problema, ha llegado a la conclusión de que los URDF no admiten estructuras de circuito cerrado, lo que dificulta la simulación precisa del movimiento de la pinza. Por lo tanto, decide utilizar un enfoque basado en reglas para controlar las acciones de cierre y elevación de la pinza. Adjunte los dedos de la pinza a los enlaces fijos y reduzca el espacio de manipulación de 7 a 6 dimensiones. También notó que cuando usa el simulador para controlar un brazo robótico, es mejor usar una pinza sin bucles cerrados, como el brazo panda.
Otro problema al que te enfrentas es que a cierta distancia el agente deja de acercarse al objeto y duda en tocarlo, lo que se traduce en una recompensa menor. El sistema de recompensas se modifica aumentando el valor de la función de recompensa usando la distancia umbral como una función de paso para que la recompensa se maximice cuando el agente alcance el punto objetivo. También eliminó el restablecimiento del entorno después de completar la tarea, ya que haría que el agente dejara de aprender antes de alcanzar el objetivo real. En su lugar, ajusta la cantidad máxima de pasos a la cantidad requerida para completar la tarea, lo que aumenta la tasa de aprendizaje.
También descubrió que castigar las tareas difíciles con demasiada dureza hace que el agente de aprendizaje por refuerzo sea demasiado conservador. Esto le da al agente una personalidad más humana, haciendo que el proceso de aprendizaje sea más interesante. Finalmente, encontró un fenómeno similar en la tarea comparativa de FrankaCabinet, donde el agente deja de aprender después de tirar de un cajón una cierta distancia, aunque tirar del cajón por completo generaría una recompensa mayor. En lugar de solucionar el problema, eliminó el restablecimiento del entorno después de completar la tarea y ajustó la cantidad máxima de pasos para completar con éxito la tarea.

Figura 7: myCobot se aleja del objeto
Las autocolisiones de brazos se ignoran. Si bien puedo llegar a la posición deseada, el brazo ahora está en una posición que ignora por completo la autocolisión, como una figura en ocho. Traté de investigar si es posible configurar el cálculo de autocolisión en la documentación, pero no funciona bien. En primer lugar, no es realista establecer todos los límites de los ángulos de las articulaciones en el URDF proporcionado en -3,14~3,14, por lo que decidí ajustar los límites superior e inferior de cada ángulo de las articulaciones para evitar la autocolisión. Aún se desconoce la razón del movimiento de los ángulos de las articulaciones al máximo valor posible.

Figura 8: myCobot ignora colisiones accidentales
El brazo no se detiene exactamente donde se supone que debe hacerlo, sino que gira a su alrededor. Queremos que el movimiento sea cercano a 0 cuando alcance la posición objetivo, pero es difícil de lograr y el brazo vibra constantemente alrededor de la posición objetivo. Intentamos penalizar las acciones y ajustar las recompensas al establecer con precisión la ubicación del objetivo, pero esto no mejoró los resultados. Decidimos no preocuparnos por este problema, ya que en la práctica puede manejarse mediante un control basado en reglas.
Aunque no es imprescindible, nos gustaría que la empuñadura mirara hacia abajo para que se viera mejor. Por lo tanto, agregamos un término de penalización en la función de recompensa que penaliza el ángulo de agarre. La Figura 9 muestra los resultados del aprendizaje antes del ajuste fino.

Figura 9: MyCobot después del aprendizaje antes del ajuste
Los resultados de los ajustes anteriores se muestran en la Figura 10. Si este nivel de precisión se puede lograr en un robot real, debería poder levantar objetos adecuadamente.

Figura 10: MyCobot después del entrenamiento después del ajuste
5. Otro
Presentaré las malas historias y las que quiero probar.
5.1 La historia del capturador URDF casero que no funciona
El URDF para myCobot se basa en el URDF utilizado en intentos anteriores de mover el robot real, pero no incluye la pinza. Aunque hay un modelo de pinza en la página oficial de GitHub, solo proporciona un archivo DAE con una representación visual, como se muestra en la Figura 11(a). Para crear un URDF que se pueda usar en el simulador, se requiere un modelo 3D separado para cada parte de la unión. Entonces, usando Blender, dividimos las partes por juntas (Fig. 11(c)) y creamos partes de colisión en forma de caja simplificadas, ya que era difícil reproducir formas complejas (Fig. 11(b)). Luego, describimos la estructura de enlaces y uniones en archivos URDF para completar el modelo. Sin embargo, dado que URDF no admite modelos con una estructura de enlace abierta, eliminamos la colisión de un enlace en la base y completamos la conexión con el lado de la yema del dedo. Si bien este enfoque es tosco, pudimos reproducir el movimiento del robot real en el simulador moviendo las seis articulaciones en el mismo ángulo. La Figura 11(d) muestra la comparación entre el modelo completo y el robot real (utilizando el modelo provisto, pero con detalles completamente diferentes). Sin embargo, cuando tratamos de moverlo, como se describe en la Sección 4.4, no funciona bien. La causa es la imposibilidad de mover la articulación de forma coordinada cuando se aplica una fuerza externa (si se implementa correctamente el control de torque, esto podría haberse solucionado).

Figura 11: Creación de la pinza para myCobot (a) Modelo de pinza publicado (b) Piezas del modelo de colisión creadas a partir del modelo (c) Piezas del modelo visual desmontadas del modelo de pinza (d) Dibujo del gimnasio de Isaac Comparación con la pinza real
5.2 Uso del reconocimiento de imágenes
En las tareas de referencia y MycobotPicking, usamos información de posición y orientación de objetos en las observaciones, pero no es fácil obtener esta información en tareas reales. Por lo tanto, sería más valioso realizar el aprendizaje por refuerzo usando solo información de la cámara 2D e información del ángulo de la articulación del servo de fácil obtención.
Intentamos reemplazar las observaciones con imágenes y usamos capas CNN para aprender en la tarea FrankaCubeStack. Sin embargo, solo modificamos el algoritmo para aceptar entradas de imágenes y, como era de esperar, no aprendimos bien. No existe un marco para agregar información del ángulo de la articulación del servo como datos unidimensionales a las capas de la CNN; el uso directo de la información de la imagen en las capas de la CNN aumenta la complejidad computacional y limita la paralelización del entorno. Además, necesitamos ajustar hiperparámetros como la tasa de aprendizaje y el valor de recorte, pero no lo hicimos porque el efecto no era lo suficientemente prometedor.
En esta prueba, solo confirmamos el método de agregar capas CNN para el aprendizaje. Sin embargo, en lugar de vincular directamente las capas de CNN con la cámara, las imágenes pueden ser más efectivas cuando se usan juntas.
5.3 Usando el modelo entrenado en un robot real
Como se mencionó en la publicación anterior, probé un experimento Sim2Real para el reconocimiento espacial usando el modelo entrenado junto con myCobot y RealSense. Sin embargo, no funciona muy bien. Si bien el estiramiento funciona hasta cierto punto, el movimiento se vuelve errático al acercarse a un objeto y no puede moverse con precisión a la posición para agarrar un objeto. Los posibles problemas incluyen que myCobot no tenga la capacidad suficiente para moverse con precisión a la posición del objetivo y que se acumulen pequeñas diferencias debido a que el simulador predice la siguiente posición del objetivo antes de alcanzar la posición del objetivo actual, mientras que el robot real no lo hace. Respecto a lo primero, el myCobot utilizado en este experimento es un brazo educativo económico con un peso portátil de 250g, por lo que si quieres moverte con mayor precisión, deberás utilizar un brazo robótico de gama superior, como el que se utiliza para el aprendizaje por refuerzo. levantar. Elephantrobotics, la empresa que fabrica myCobot, también vende un modelo con servomotores más potentes que pueden transportar hasta 1 kg, así que también quería probarlo.
6. Resumen
Esta vez, usé Isaac Gym para crear una tarea de aprendizaje por refuerzo y, de hecho, entrené al modelo. Experimenté diseñando problemas de aprendizaje por refuerzo para robótica y ejecutando modelos entrenados en un simulador de física 3D. Es atractivo poder probar un entorno de aprendizaje sin tener que escribir un algoritmo de aprendizaje por refuerzo desde cero. La disponibilidad de entornos de referencia facilita la comparación y validación de nuevos algoritmos de aprendizaje, lo que es una gran ventaja para investigadores y analistas con diversos antecedentes profesionales.