El componente de alta frecuencia ayuda a explicar la generalización de las redes neuronales convolucionales
Cuenta oficial: EDPJ
Tabla de contenido
3. Componentes de alta frecuencia y generalización de CNN
3.1 CNN utiliza componentes de alta frecuencia
3.2 El compromiso entre robustez y precisión
4. Repensar los datos antes de repensar la generalización
5. Heurística de entrenamiento
5.1 Comparación de diferentes heurísticas
5.2 Supuestos sobre la normalización de lotes
6. Ataque adversario y defensa
6.1 Suavidad del kernel y frecuencia de imagen
6.2 Los modelos robustos tienen núcleos suaves
6.3 El kernel suavizado mejora la robustez de los adversarios
7. Más allá de la clasificación de imágenes
7.1 Degradación del rendimiento de LFC
7.2 Mejora del rendimiento de LFC
8. Discusión: ¿El HFC es solo ruido?
S.2 Metodología de la investigación
S.5 Robustez y convolución Suavidad del núcleo
0. Resumen
Estudiamos la relación entre el espectro de frecuencias de los datos de imagen y el comportamiento de generalización de las redes neuronales convolucionales (CNN). Primero notamos la capacidad de las CNN para capturar componentes de imágenes de alta frecuencia. Estos componentes de alta frecuencia son casi imperceptibles para los humanos. Por lo tanto, las observaciones conducen a múltiples hipótesis relacionadas con el comportamiento de generalización de las CNN, incluidas posibles explicaciones para ejemplos adversarios, una discusión sobre el equilibrio entre robustez y precisión para las CNN, y algunas pruebas para comprender la heurística de entrenamiento.
1. Introducción
El aprendizaje profundo ha hecho muchos avances recientes en el modelado predictivo para varias tareas, pero la gente todavía está sorprendida por el comportamiento de generalización poco intuitivo de las redes neuronales, como la capacidad de memorizar datos mezclados con etiquetas y emparejar ejemplos adversarios de vulnerabilidad.
Para explicar el comportamiento de generalización de las redes neuronales, se han realizado gradualmente muchos avances teóricos, incluido el estudio de las propiedades del descenso de gradiente estocástico, diferentes medidas de complejidad, brecha de generalización y más perspectivas de diferentes modelos o algoritmos.
En este documento, inspirado en conocimientos previos de que las redes neuronales convolucionales (CNN) pueden aprender tanto de señales de desorden como de superficie, estudiamos el comportamiento de generalización de las CNN desde una perspectiva de datos. Al igual que [27], argumentamos que el comportamiento de generalización no intuitivo de las CNN es un resultado directo de las diferencias de percepción entre humanos y modelos (como se muestra en la Figura 1): las CNN pueden ver datos con una granularidad más alta que los humanos.

Sin embargo, a diferencia de [27], proporcionamos una interpretación altamente granular de la percepción del modelo: las CNN pueden explotar componentes de imagen de alta frecuencia que son imperceptibles para los humanos.

Por ejemplo, la Figura 2 muestra los resultados de predicción para ocho muestras de prueba del conjunto de datos CIFAR10 y los resultados de predicción para los componentes correspondientes de alta y baja frecuencia. Para estos ejemplos, los resultados de la predicción están determinados casi por completo por el contenido de alta frecuencia de la imagen, que es casi imperceptible para los humanos. Por otro lado, para los humanos, los componentes de baja frecuencia se ven casi iguales a la imagen original, pero el modelo los predice como algo significativamente diferente.
Inspirándonos en las observaciones empíricas anteriores, investigamos más a fondo el comportamiento de generalización de las CNN e intentamos explicar dichos comportamientos a través de respuestas diferenciales al espectro de la imagen de entrada ( Observación 1 ). Nuestras principales contribuciones se resumen a continuación:
- Arrojamos luz sobre la compensación existente entre la precisión y la robustez de las CNN al proporcionar un ejemplo de cómo las CNN explotan los componentes de alta frecuencia de las imágenes para cambiar la precisión por la robustez (Corolario 1).
- Utilizando el espectro de imágenes como herramienta, proporcionamos hipótesis para explicar varios comportamientos de generalización de las CNN, especialmente la capacidad de memorizar etiquetas para mezclar datos.
- Nuestro método de defensa propuesto puede ayudar a mejorar la solidez adversaria de las CNN frente a ataques simples sin entrenar ni ajustar el modelo.
2. Trabajo relacionado
El tremendo éxito del aprendizaje profundo ha atraído una gran cantidad de trabajo teórico dedicado a explicar el misterio de la generalización de CNN.
- Desde que Zhang et al.
- Arpit y otros demuestran que es poco probable que la capacidad efectiva explique el rendimiento de generalización de redes profundas entrenadas con métodos basados en gradientes, ya que los datos de entrenamiento determinan en gran medida la memoria.
- Demostrado empíricamente por Kruger et al., al mostrar el mayor aumento en los valores propios de Hessian cuando se entrena en etiquetas aleatorias en redes profundas.
El concepto de ejemplos contradictorios ha surgido como otra dirección interesante relacionada con el comportamiento de las redes neuronales. En esta línea, los investigadores han inventado poderosos métodos como FGSM, PGD y muchos otros para engañar a los modelos, que se denominan métodos de ataque. Para proteger los modelos de la suplantación de identidad, otro grupo de investigadores ha propuesto una variedad de métodos (llamados métodos de defensa). Estos son solo algunos aspectos destacados de la larga historia de métodos de ataque y defensa propuestos. Una discusión detallada se puede encontrar en la revisión general.
Sin embargo, mientras mejoran la robustez, estos métodos pueden experimentar una ligera disminución en la precisión de la predicción, lo que lleva a otro tema de discusión sobre el compromiso entre robustez y precisión. Algunos resultados empíricos muestran que los modelos precisos tienden a ser más sólidos en los ejemplos contradictorios generados. El trabajo adicional argumenta que, si bien la mayor robustez se debe principalmente a una mayor precisión, los modelos más precisos (por ejemplo, VGG, ResNet) son en realidad menos robustos que AlexNet.
3. Componentes de alta frecuencia y generalización de CNN
Primero configuramos la notación básica utilizada en este documento: <x,y> denota muestras de datos (imágenes y etiquetas correspondientes). f(·;θ) representa una red neuronal convolucional cuyos parámetros se denotan como θ. Usamos H para denotar el modelo humano, por lo que f(·;H) denota cómo un humano clasificará los datos. l(·,·) denota una función de pérdida genérica (por ejemplo, pérdida de entropía cruzada). α(·,·) representa la función que evalúa la precisión de la predicción (para cada muestra, esta función arroja 1,0 si la muestra se clasifica correctamente, 0,0 en caso contrario). d(·,·) representa una función que evalúa la distancia entre dos vectores. F( ) denota la transformada de Fourier, por lo tanto, F^(−1) ( ) denota la transformada inversa de Fourier. Usamos z para indicar los componentes de frecuencia de las muestras. Por lo tanto, tenemos z = F(x) y x = F^(−1) (z).
Tenga en cuenta que la transformada de Fourier o su inversa pueden introducir números complejos. En este artículo, simplemente descartamos la parte imaginaria del resultado F^(−1) ( ) para asegurarnos de que la imagen resultante se pueda enviar a la CNN como de costumbre.
3.1 CNN utiliza componentes de alta frecuencia
Descomponemos los datos originales x = {x_l, x_h}, donde x_l y x_h denotan el componente de baja frecuencia (abreviado como LFC ) y el componente de alta frecuencia (abreviado como HFC ) de x. Tenemos las siguientes cuatro ecuaciones:

donde t( ; r) denota la función de umbral que separa los componentes de baja y alta frecuencia de z según el radio del hiperparámetro r.
Para definir formalmente t( ; r), primero consideramos una imagen en escala de grises (de un solo canal) de tamaño n × n, con N posibles valores de píxeles (en otras palabras, x ∈ N^(n×n)), luego tenemos z ∈ C^(n×n), donde C denota un número complejo. Usamos z(i, j) para indexar el valor de z en la posición (i, j), y usamos c_i, c_j para denotar el centroide. Definimos formalmente la ecuación z_l, z_h = t(z; r) como:
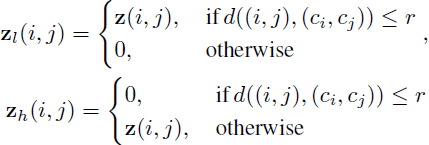
En este artículo, d(·,·) en t(·;r) se considera como distancia euclidiana. Si x tiene varios canales, el pase opera en cada canal del píxel de forma independiente.
comentario 1 . Suponiendo ( suposición 1, A1 ) "solo x_l es perceptible por humanos, pero tanto x_l como x_h son perceptibles por CNN", tenemos:
![]()
Pero cuando la CNN está entrenada con
![]()
Equivalente a
![]()
Una CNN podría aprender a usar x_h para minimizar la pérdida. Por lo tanto, el comportamiento de generalización de las CNN no es intuitivo para los humanos.
Tenga en cuenta que "CNN puede aprender a explotar x_h" no es lo mismo que "CNN overfits" porque x_h puede contener más información que las idiosincrasias específicas de la muestra, y esta información adicional puede generalizarse a través de conjuntos de entrenamiento, validación y prueba. Es solo que los humanos no puedo percibirlo.
Dado que se ha demostrado que la Hipótesis A1 se cumple en algunos casos (por ejemplo, en la Fig. 2), creemos que la Observación 1 puede servir como una de las explicaciones para el comportamiento de generalización de las CNN. Por ejemplo, se pueden generar ejemplos contradictorios al perturbar x_h; la capacidad de las CNN para reducir el error de entrenamiento a cero en los datos mezclados con etiquetas se puede ver como resultado de explotar x_h y sobreajustar las idiosincrasias específicas de la muestra. Discutiremos más en las siguientes secciones.
3.2 El compromiso entre robustez y precisión
Continuamos con la Observación 1 para discutir la compensación entre robustez y precisión de las CNN para un θ dado desde la perspectiva de la frecuencia de la imagen. Primero formulamos la precisión de θ formalmente como:
![]()
La robustez contradictoria de θ se expresa como
![]()
donde ε es el límite superior de la perturbación permisible.
Otra suposición ( A2 para abreviar ): Para el modelo θ, existe una muestra <x,y> tal que:
![]()
Podemos expandir nuestro argumento principal ( Observación 1 ) en una declaración formal:
Corolario 1 . Bajo los supuestos A1 y A2, existen muestras <x, y>, para cualquier medida de distancia d( , ) y límite ε, siempre que ε ≥ d(x, x_l), el modelo θ no puede ser exacto (por la Ecuación 1 1.0) y predecir de manera robusta (1.0 por la ecuación 2).
La demostración es una consecuencia directa de la discusión anterior y, por lo tanto, se omite. La hipótesis A2 también se puede verificar empíricamente (p. ej., en la Figura 2), por lo que podemos afirmar con seguridad que el Corolario 1 puede ser una de las explicaciones del equilibrio entre robustez y precisión de las CNN.
4. Repensar los datos antes de repensar la generalización
4.1 Supuestos
Nuestro primer objetivo es proporcionar algunas explicaciones intuitivas para los resultados empíricos observados de que las redes neuronales pueden adaptarse fácilmente a los datos codificados por etiquetas. Si bien no tenemos ninguna duda de que una red neuronal puede memorizar datos debido a su capacidad, surgen preguntas interesantes: "Si una red neuronal puede memorizar datos fácilmente, ¿por qué le importa aprender patrones generalizables a partir de datos en lugar de memorizar todo directamente para reducir la pérdida de entrenamiento?"
Dentro de las ideas presentadas en el comentario 1 , nuestra suposición es la siguiente: aunque el resultado es el mismo que el de la minimización de pérdidas de entrenamiento, el modelo considera diferentes niveles de características en dos casos:
- En el caso de la etiqueta original, el modelo primero se enfocará en el componente de baja frecuencia (LFC) y luego se enfocará gradualmente en el componente de alta frecuencia (HFC) para lograr una mayor precisión de entrenamiento.
- En el caso de la combinación aleatoria de etiquetas, dado que la asociación entre LFC y la etiqueta se elimina debido a la combinación aleatoria, el modelo debe memorizar imágenes cuando LFC y HFC se tratan por igual.
4.2 Experimento
Preparamos experimentos para probar nuestras hipótesis. Usamos ResNet-18 del conjunto de datos CIFAR10 como experimento base. La configuración común que usaremos en el resto de este documento es ejecutar experimentos durante 100 épocas con el optimizador de Adam, con la tasa de aprendizaje establecida en 10^(−4), el tamaño del lote establecido en 100 y los pesos inicializados con Xavier inicialización Todos los píxeles están normalizados a [0, 1]. Todos estos experimentos se repitieron en MNIST, FashionMNIST y un subconjunto de ImageNet. Estos esfuerzos se informan en el apéndice. Entrenamos dos modelos, utilizando la configuración de etiqueta natural y la configuración de etiqueta aleatoria, denominadas M_natural y M_shuffle respectivamente; M_shuffle requiere 300 épocas para lograr una precisión de entrenamiento comparable. Para probar qué parte de la información extrae el modelo, para cualquier x en el conjunto de entrenamiento, generamos componentes de baja frecuencia x_l, donde r se establece en 4, 8, 12, 16, respectivamente. Probamos cómo cambió la precisión del entrenamiento en estos conjuntos de datos de baja frecuencia durante el entrenamiento.
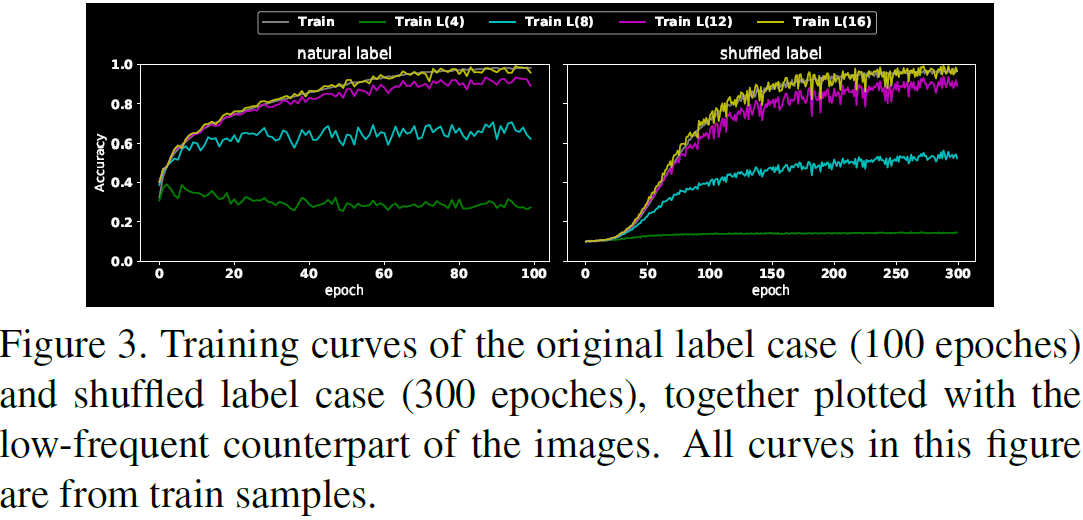
Los resultados se representan en la Figura 3.
- El primer mensaje es que M_shuffle tarda más en entrenarse que M_natural para lograr la misma precisión de entrenamiento (300 épocas frente a 100 épocas), lo que sugiere que memorizar muestras es "antinatural" en comparación con aprender patrones generalizables de comportamiento.
- Al comparar las curvas de muestras de entrenamiento de baja frecuencia, notamos que M_natural aprende más patrones de baja frecuencia que M_shuffle (es decir, cuando r es 4 u 8).
- Además, cuando r = 4, M_shuffle apenas aprende LFC, mientras que, por otro lado, incluso en la primera época, cuando r = 4, M_natural ha aprendido alrededor del 40% del LFC correcto. Esta diferencia muestra que mientras M_natural prefiere elegir LFC, M_shuffle no tiene preferencia entre LFC y HFC.
Si un modelo puede utilizar múltiples conjuntos diferentes de señales, ¿por qué M_natural preferiría aprender un LFC que coincide con las preferencias de percepción humana? Si bien hay explicaciones de que las redes neuronales tienden a favorecer características más simples, especulamos que esto se debe simplemente a que, dado que el conjunto de datos está organizado y anotado por humanos, la combinación de etiquetas LFC es más "común" que la combinación de etiquetas HFC: Uso de LFC - La combinación de etiquetas conducirá a la caída más pronunciada de la pérdida, especialmente en las primeras etapas del entrenamiento.
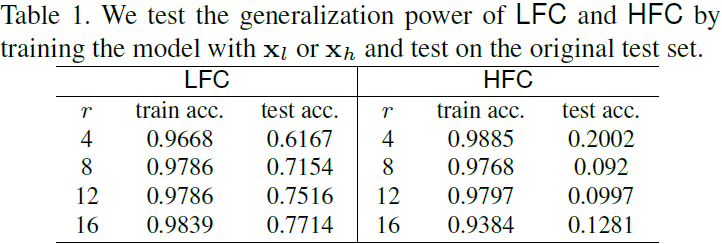
Para probar esta conjetura, repetimos el experimento de M_natural, pero usamos x_l o x_h (normalizado a la escala de píxeles estándar) en lugar del conjunto de entrenamiento original, y probamos cómo funciona el modelo en el conjunto de prueba original. La Tabla 1 muestra que LFC "generaliza" más que HFC. Por lo tanto, no es sorprendente que un modelo elija primero LFC, ya que conduce a la caída más pronunciada de la pérdida.
4.3 Cuestiones pendientes
Finalmente, nos gustaría plantear la pregunta de que la coincidencia entre las preferencias de red en LFC y las preferencias percibidas por humanos puede ser un simple resultado del "sesgo de supervivencia" inventado por muchas tecnologías a medida que suben la escalera del estado del arte. En otras palabras, la evolución de casi 100 años de las redes neuronales es como una "selección natural" de la tecnología. Las ideas que sobreviven pueden ser perfectas para el gusto humano, o puede que ni siquiera se publiquen debido a una dificultad para subir la escalera.
Sin embargo, una pregunta interesante es qué tan bien se alinean estas técnicas de subir escaleras con las preferencias visuales humanas. Ofrecemos evaluar estas técnicas utilizando nuestra herramienta de frecuencia.
5. Heurística de entrenamiento
Continuamos reevaluando las heurísticas que ayudan a subir la escalera de precisión de última generación. Evaluamos estas heurísticas para probar el rendimiento de generalización a LFC y HFC. Muchas técnicas bien conocidas en la escala de precisión parecen hacer uso de HFC en mayor o menor medida.
5.1 Comparación de diferentes heurísticas
Probamos varias heurísticas examinando la precisión predictiva de LFC y HFC, eligiendo r durante el entrenamiento y trazando las curvas de entrenamiento.

Tamaño del lote : Estudiamos cómo la elección del tamaño del lote afecta el comportamiento de generalización. Graficamos los resultados en la Figura 4.
- Los lotes más pequeños parecen hacer un buen trabajo al mejorar la precisión del entrenamiento y la prueba, mientras que los lotes más grandes parecen hacer un buen trabajo al cerrar la brecha de generalización (brecha de rendimiento del entrenamiento versus la prueba).
- Además, la brecha de generalización parece estar estrechamente relacionada con la tendencia de los modelos a capturar HFC: los modelos entrenados con lotes más grandes son más invariantes a HFC y tienen diferencias más pequeñas en la precisión del entrenamiento y las pruebas. La relación observada es intuitiva porque la brecha de generalización más pequeña se logra una vez que el modelo se comporta como un ser humano (ya que es un ser humano quien anota los datos).
Las observaciones en la Figura 4 también contribuyen a la discusión de las características "generalizables" en la sección anterior. Intuitivamente, con lotes más grandes, es más probable que las características que pueden conducir a la caída más pronunciada en la pérdida sean patrones "generalizables" de los datos, es decir, LFC.
Heurística : también probamos cómo los diferentes métodos de entrenamiento responden a LFC y HFC, que incluyen:
- Abandono: una heurística para dejar caer pesos aleatoriamente durante el entrenamiento. Aplicamos dropout en capas completamente conectadas con p = 0.5.
- Mezcla: una heurística para la integración lineal de muestras y sus etiquetas durante el entrenamiento. Lo aplicamos usando el hiperparámetro estándar α = 0.5.
- BatchNorm: un método para realizar la normalización en cada minilote de entrenamiento para acelerar el proceso de entrenamiento de redes profundas. Nos permite usar tasas de aprendizaje más altas y reducir el sobreajuste, similar a la deserción. Lo aplicamos estableciendo la escala γ en 1 y el desplazamiento β en 0.
- Entrenamiento antagónico: un método para aumentar los datos con ejemplos antagónicos generados durante el entrenamiento por un modelo de amenazas. Es ampliamente considerado como uno de los métodos de robustez adversaria (defensa) más exitosos. Siguiendo una elección popular, usamos PGD con ε = 8/255 (ε = 0.03) como modelo de amenaza.

Ilustramos los resultados en la Figura 5, donde la primera figura es la configuración original y luego cada una de las cuatro heurísticas se prueba en las cuatro figuras restantes.
- En nuestros experimentos, Dropout se comportó más o menos como una configuración normal.
- La confusión proporciona una precisión de predicción similar, sin embargo, captura más HFC, lo que probablemente no sea sorprendente, ya que la mejora de la confusión no fomenta explícitamente ninguna información sobre LFC, y la mejora del rendimiento puede deberse al enfoque.
- El entrenamiento adversario se comporta principalmente como se esperaba: informa una precisión de predicción más baja, probablemente debido a una compensación entre robustez y precisión. También informa una pequeña brecha de generalización, probablemente como resultado de elegir el modo "generalizable", como lo demuestra su invariancia a HFC (p. ej., r = 12 o r = 16). Sin embargo, cuando r = 4, el entrenamiento adversario parece ser sensible a HFC, que es ignorado incluso por la configuración estándar.
- El rendimiento de BatchNorm es notable: en comparación con la configuración estándar, BatchNorm selecciona más información tanto en LFC como en HFC, especialmente cuando r = 4 y r = 8. Esta propensión de BatchNorm a capturar HFC también está relacionada con el hecho de que BatchNorm fomenta la lucha contra la fragilidad.
Otras pruebas : también probamos otras heurísticas o métodos, cambiando solo a lo largo de una dimensión, mientras permanecía igual que la configuración original en la Sección 4.
Arquitectura modelo: Probamos LeNet, AlexNet, VGG y ResNet. La arquitectura ResNet parece superar a las invenciones anteriores en varios niveles: informa una mejor precisión de la prueba en la configuración original, una brecha de generalización más pequeña (la diferencia entre la precisión del entrenamiento y la prueba) y una tendencia más débil a capturar HFC.
Optimizadores: Probamos SGD, ADAM, AdaGrad, AdaDelta y RMSprop. Notamos que SGD parecía ser el único con una clara tendencia a capturar HFC, mientras que el resto eran idénticos en nuestros experimentos.
5.2 Supuestos sobre la normalización de lotes
Según las observaciones, planteamos la hipótesis de que uno de los puntos fuertes de BatchNorm es alinear las diferencias de distribución de diferentes señales de predicción a través de la normalización. Por ejemplo, los HFC generalmente muestran magnitudes más pequeñas que los LFC, por lo que es posible que los modelos entrenados sin BatchNorm no detecten estos HFC tan fácilmente. Por lo tanto, la mayor velocidad de convergencia también se puede considerar como un resultado directo de la captura simultánea de diferentes señales de predicción.
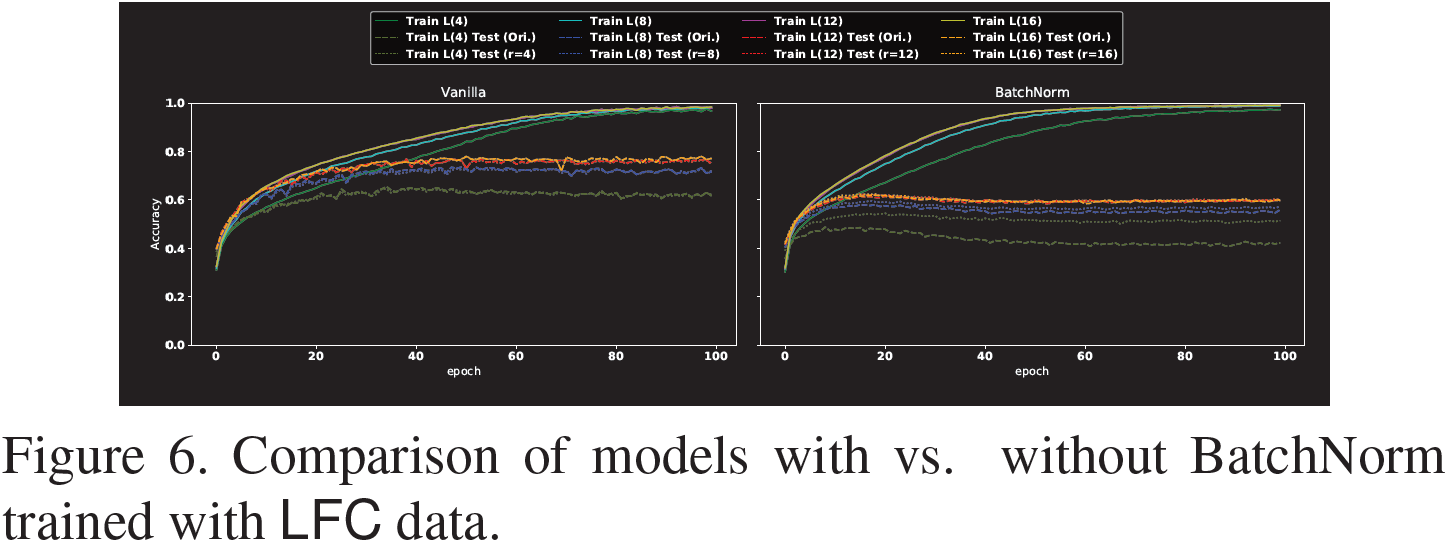
Para probar esta hipótesis, comparamos el rendimiento de los modelos entrenados con y sin BatchNorm en datos de LFC y graficamos los resultados en la Figura 6.
Como se muestra en la Figura 6, BatchNorm no siempre ayuda a mejorar el rendimiento predictivo cuando el modelo se entrena usando solo LFC, ya sea que se pruebe con los datos originales o con los datos LFC correspondientes. Además, cuanto menor es el radio, menos útil es BatchNorm. Además, en nuestra configuración, BatchNorm no generaliza tan bien como la configuración original, lo que puede generar dudas sobre las ventajas de BatchNorm.
Sin embargo, BatchNorm todavía parece al menos mejorar la convergencia de la precisión del entrenamiento. Curiosamente, la aceleración es menor cuando r = 4. Esta observación está más en línea con nuestra hipótesis: si una de las ventajas de BatchNorm es alentar al modelo a capturar diferentes señales de predicción, entonces la ganancia de rendimiento de BatchNorm es más limitada cuando r = 4 al entrenar el modelo con LFC.
6. Ataque adversario y defensa
Como se puede notar, nuestras observaciones de los HFC se pueden vincular directamente con el fenómeno de los "ejemplos adversarios": si las predicciones dependen de los HFC, entonces las perturbaciones de los HFC cambiarán significativamente la respuesta del modelo, pero es posible que los humanos no puedan observar este tipo. de perturbación conduce al comportamiento no intuitivo de la red neuronal.
Esta sección está dedicada a estudiar la relación entre la robustez contradictoria y la tendencia de los modelos a explotar HFC.
6.1 Suavidad del kernel y frecuencia de imagen
Como se establece en el teorema de convolución, la operación de convolución de una imagen es equivalente a la multiplicación en el dominio de la frecuencia de la imagen. Entonces, en términos generales, si un filtro tiene pesos insignificantes en el extremo superior del dominio de frecuencia, pondera el HFC en consecuencia. Es posible que esto solo sea cierto para los núcleos de la primera capa, ya que los núcleos de las capas superiores no están directamente relacionados con los datos, por lo que la relación es ambigua.
Por lo tanto, creemos que para forzar el modelo a ignorar HFC, se puede considerar obligar al modelo a aprender núcleos de convolución con pesos insignificantes en el extremo superior del dominio de frecuencia.
Intuitivamente (según el conocimiento del procesamiento de señales), si el kernel de convolución es "suave", es decir, no hay fluctuaciones bruscas entre pesos adyacentes, el dominio de frecuencia correspondiente verá señales de alta frecuencia insignificantes. Estos enlaces han sido probados matemáticamente, pero las relaciones exactas que estos prueban están más allá del alcance de este documento.
6.2 Los modelos robustos tienen núcleos suaves
Para comprender la conexión entre la "suavidad" y la robustez contradictoria, visualizamos en la Figura 7 (a) y (b) el kernel de convolución.
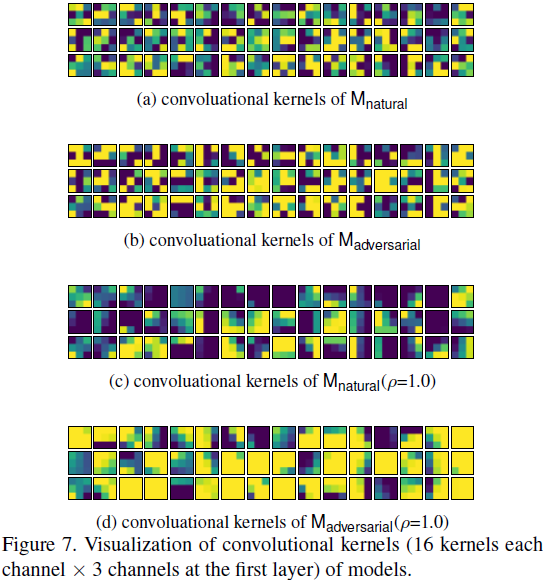
Comparando la Fig. 7(a) y la Fig. 7(b), podemos ver que los núcleos Madversarial tienden a mostrar patrones más suaves, lo que se puede observar por los pesos adyacentes de los núcleos M_adversarial que tienden a compartir el mismo color. La visualización puede no ser muy clara ya que los núcleos de convolución en ResNet son solo [3 × 3], cuando la primera capa tiene núcleos de convolución de tamaño [5 × 5], el mensaje se transmite más claramente en el apéndice utilizando otras arquitecturas. .
6.3 El kernel suavizado mejora la robustez de los adversarios
El argumento intuitivo en 6.1 y los resultados empíricos en 6.2 conducen directamente a la pregunta de si podemos mejorar la robustez contradictoria del modelo suavizando el núcleo de convolución de la primera capa.
Después de la discusión, presentamos un método extremadamente simple que parece mejorar la solidez de los adversarios contra FGSM y PGD. Para un kernel w, usamos i y j para denotar sus índices de columna y fila, por lo que w_i,j denota el valor de la fila i y la columna j. Si usamos N(i, j) para denotar el conjunto de vecinos espaciales de (i, j), nuestro enfoque es simple:
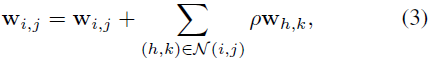
donde ρ es un hiperparámetro de nuestro método. Arreglamos N(i, j) para que tenga ocho vecinos. Si (i, j) está en el borde, simplemente copiamos los valores en el borde para generar valores fuera de los límites.
En otras palabras, tratamos de suavizar el kernel simplemente reduciendo las diferencias adyacentes mezclando valores adyacentes. Este método apenas tiene carga computacional, pero parece mejorar la robustez adversarial de M_natural y M_adversarial frente a FGSM y PGD, incluso cuando M_adversarial se entrena con PGD como modelo de amenaza.
En la Fig. 7, aplicamos el kernel de convolución con nuestro método a las visualizaciones M_natural y M_adversarial en ρ = 1.0, denotadas como M_natural (ρ = 1.0) y M_adversarial (ρ = 1.0), respectivamente. Como muestra la visualización, los núcleos resultantes tienden a mostrar patrones significativamente más suaves.
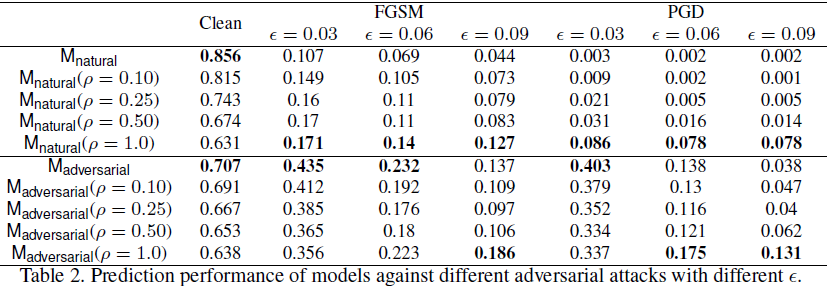
Probamos la robustez del modelo suavizado por nuestro método contra FGSM y PGD, eligiendo diferentes ε con una perturbación máxima de 1.0. Como se muestra en la tabla 2,
- Al aplicar nuestro método de suavizado, la precisión limpia cae directamente, pero la robustez adversaria mejora. En particular, nuestro método ayuda cuando las perturbaciones permitidas son relativamente grandes. Por ejemplo, cuando ε = 0,09 (alrededor de 23/255), M_natural (ρ = 1,0) incluso supera a M_adversarial.
- En general, nuestro método puede mejorar fácilmente la solidez contradictoria de M_natural, pero solo puede mejorar M_adversarial cuando ε es grande, lo que puede deberse a que M_adversarial usa PGD (ε = 0.03) como una amenaza. El modelo está entrenado.
7. Más allá de la clasificación de imágenes
Nuestro objetivo no es solo explorar tareas de clasificación de imágenes. Investigamos tareas de detección de objetos. Usamos RetinaNet y ResNet50 + FPN como columna vertebral. Entrenamos el modelo utilizando el conjunto de entrenamiento de detección de COCO y realizamos inferencias en su conjunto de validación de 5000 imágenes, logrando una precisión promedio promedio (MAP) del 35,6 %.
Luego elegimos r = 128 y mapeamos la imagen a x_l y x_h y probamos con el mismo modelo, obteniendo 27.5% MAP para LFC y 10.7% MAP para HFC. La caída del rendimiento del 35,6 % al 27,5 % nos intrigó, por lo que investigamos más a fondo si se debería esperar la misma caída en humanos.
7.1 Degradación del rendimiento de LFC
Se puede esperar la caída en el rendimiento de x a x_l, ya que es posible que x_l no tenga información rica de la imagen original cuando se descarta HFC. En particular, a diferencia de la clasificación de imágenes, HFC puede desempeñar un papel importante en la representación de ciertos objetos, especialmente los más pequeños.

La Figura 8 ilustra algunos ejemplos donde el reconocimiento de algunos objetos es peor cuando la imagen de entrada es reemplazada por su contraparte de baja frecuencia. Se puede esperar esta diferencia, ya que las imágenes de baja frecuencia tienden a ser borrosas y algunos objetos pueden no ser visibles para los humanos.
7.2 Mejora del rendimiento de LFC
Sin embargo, las diferencias se vuelven interesantes cuando examinamos la brecha de desempeño desde la dirección opuesta. Identificamos 1684 imágenes, para cada una de estas imágenes, algunos objetos se reconocieron mejor (puntuación MAP alta) en comparación con la imagen original.

Los resultados se muestran en la Figura 9. No parece haber una razón obvia por la que estos objetos se identifiquen mejor en imágenes de baja frecuencia cuando son inspeccionados por humanos. Estas observaciones fortalecen nuestro argumento de que las diferencias de percepción entre las CNN y los humanos también existen en tareas de visión por computadora más avanzadas más allá de la clasificación de imágenes.
8. Discusión: ¿El HFC es solo ruido?
Para responder a esta pregunta, probamos otro método de eliminación de ruido de imagen de uso común: descomposición de valor singular truncado (SVD). Descomponemos la imagen y separamos la imagen en una imagen reconstruida con valores singulares dominantes y una imagen reconstruida con valores singulares finales. Con esta configuración, encontramos muchas menos imágenes que respaldan el fenómeno de la Figura 2. Nuestras observaciones muestran que el HFC explotado por las CNN no es solo un "ruido" aleatorio.
9. Conclusión y perspectiva
Estudiamos cómo el espectro de la imagen afecta el comportamiento de generalización de las CNN, lo que lleva a varias explicaciones interesantes para el comportamiento de generalización de las redes neuronales desde una nueva perspectiva: hay múltiples señales en los datos, pero no todas corresponden a la preferencia de la visión humana. Dado que este artículo cubre muchos temas de manera integral, reiteramos brevemente las principales lecciones aprendidas:
- Las CNN pueden capturar HFC que son inconsistentes con las preferencias visuales humanas (§3), lo que genera misterios de generalización como la paradoja de aprender a etiquetar datos aleatorios (§4) y la fragilidad adversaria (§6).
- Las heurísticas que mejoran la precisión, como Mix-up y BatchNorm, pueden fomentar la captura de HFC (§5). Debido a la compensación entre precisión y robustez (§3), es posible que tengamos que reconsiderar su valor.
- Los modelos adversarios tienden a tener núcleos suaves, lo contrario no siempre es cierto (§6).
- Se han observado fenómenos similares en el contexto de la detección de objetos (§7), pero aún quedan por extraer más conclusiones.
En el futuro, esperamos que nuestro trabajo sirva como un llamado para una era futura de investigación de visión por computadora donde el estado del arte es menos importante de lo que pensamos.
- Un solo número en una tabla de clasificación, si bien puede impulsar significativamente la investigación en una dirección, no es un reflejo confiable del acuerdo entre modelos y humanos, que posiblemente sea lo más importante.
- Esperamos que nuestro trabajo conduzca a un nuevo escenario de prueba en el que el rendimiento de las contrapartes de baja frecuencia deba informarse junto con el rendimiento de las imágenes sin procesar.
- Tener en cuenta los sesgos inductivos explícitos en la forma en que los humanos perciben los datos puede desempeñar un papel importante en el futuro. En particular, la literatura de neurociencia muestra que los humanos tienden a depender de señales de baja frecuencia para reconocer objetos, lo que puede inspirar el desarrollo de métodos futuros.
referencia
Wang H, Wu X, Huang Z, et al. El componente de alta frecuencia ayuda a explicar la generalización de las redes neuronales convolucionales[C]//Actas de la conferencia IEEE/CVF sobre visión artificial y reconocimiento de patrones. 2020: 8684-8694.
[27] Andrew Ilyas, Shibani Santurkar, Dimitris Tsipras, Logan Engstrom, Brandon Tran y Aleksander Madry. Los ejemplos adversarios no son errores, son características. preimpresión de arXiv arXiv:1905.02175, 2019.
S. Resumen
S.1 Idea central
En este artículo, estudiamos la relación entre el espectro de la imagen y la capacidad de generalización de las CNN. Los autores argumentan que el comportamiento de generalización no intuitivo de las CNN es un resultado directo de las diferencias de percepción entre humanos y modelos: las CNN pueden capturar componentes de alta frecuencia que los humanos no pueden percibir.
S.2 Metodología de la investigación
Usando una combinación de transformada y filtro de Fourier, se obtienen el componente de baja frecuencia (LFC) y el componente de alta frecuencia (HFC) de la imagen. Luego, los componentes se reconstruyen usando la transformada inversa de Fourier, y estas imágenes reconstruidas se usan como un conjunto de prueba para verificar la precisión del modelo.
Tenga en cuenta que la transformada de Fourier o su inversa pueden introducir números complejos. En este documento, la parte imaginaria del resultado de la transformada inversa de Fourier simplemente se descarta para garantizar que la imagen resultante se pueda alimentar a la CNN como de costumbre.
S.3 Análisis
Los estudios han demostrado que las CNN prefieren aprender LFC que se alinean con las preferencias de percepción humana. Si bien hay explicaciones de que las redes neuronales tienden a favorecer características más simples, los autores especulan que esto se debe a que, dado que los conjuntos de datos están organizados y anotados por humanos, las combinaciones de etiquetas de baja frecuencia son más "comunes" que las combinaciones de etiquetas de alta frecuencia en el conjunto de datos
Un pasaje con el que estoy de acuerdo en este artículo "Finalmente, nos gustaría plantear la pregunta: la coincidencia entre las preferencias de red en LFC y las preferencias perceptivas humanas puede ser un simple "sesgo de supervivencia" inventado por muchas tecnologías en el proceso de escalar el estado- escalera de última generación. El resultado. En otras palabras, la evolución de casi 100 años de las redes neuronales ha sido como una "selección natural" de la tecnología. Las ideas que sobreviven pueden simplemente adaptarse a las preferencias humanas, o puede que ni siquiera sean publicado debido a malas escaleras para subir".
S.4 Heurística
Los autores estudian el efecto de diferentes heurísticas en el rendimiento de la generalización. Solo dos que afectan significativamente se enumeran aquí.
Tamaño del lote . Los lotes más grandes tienen brechas de generalización más pequeñas y, en este momento, el modelo no aprende muchos componentes de alta frecuencia. La relación observada es intuitiva, ya que la brecha de generalización más pequeña se logra una vez que el modelo se comporta como un humano (los humanos anotan los datos y los humanos no pueden observar los componentes de alta frecuencia).
BatchNorm . Con BatchNorm, el modelo puede utilizar más componentes de alta frecuencia. Uno de los puntos fuertes de BatchNorm es la normalización para alinear las diferencias de distribución de diferentes señales de predicción. Por ejemplo, los HFC generalmente muestran magnitudes más pequeñas que los LFC, por lo que es posible que los modelos entrenados sin BatchNorm no detecten estos HFC tan fácilmente.
S.5 Robustez y convolución Suavidad del núcleo
Los modelos robustos tienden a tener núcleos de convolución suaves. Si el modelo predice por componentes de alta frecuencia, una pequeña perturbación en los componentes de alta frecuencia puede tener un gran impacto en los resultados del modelo.
Si el kernel de convolución es "suave", es decir, no hay fluctuaciones bruscas entre pesos adyacentes, el dominio de frecuencia correspondiente verá señales de alta frecuencia insignificantes.
El uso de un kernel de convolución suave, aunque afectará la precisión del modelo, puede mejorar la robustez.