Prototipo de memoria y mecanismos de atención para la generación de imágenes de pocas tomas
Cuenta oficial: EDPJ
Tabla de contenido
3.1 Prototipo de aprendizaje de memoria
3.2 Atención del concepto de memoria (MEMORY CONCEPT ATENTION, MoCA)
3.3 Atención del contexto espacial
3.4 Integración de dos caminos de modulación
4.1 rendimiento de síntesis de imágenes de pocos disparos
4.3 Análisis del concepto de prototipo
8.1 Ablación: la importancia de la organización del clúster de memoria
8.6 Análisis de los conceptos de memoria
S.4 Análisis de conglomerados de conceptos
0. Resumen
Hallazgos recientes indican que la codificación neuronal en las capas superficiales de la corteza visual primaria (V1) en macacos es compleja, diversa e hiperescasa. Esto nos hizo pensar en las ventajas computacionales y los roles funcionales de estas 'células abuelas'. Aquí proponemos que estas unidades pueden servir como prototipos de memoria previos al procesamiento de características distribuidas de forma y sesgo durante la generación de imágenes en el cerebro. Estos prototipos de memoria se aprenden mediante el agrupamiento en línea de impulso y se explotan mediante operaciones de atención basadas en la memoria. Al incorporar este mecanismo, proponemos la atención del concepto de memoria (MoCA) para mejorar la calidad de la generación de imágenes de pocos disparos. Mostramos que la memoria prototipo con un mecanismo de atención puede mejorar la calidad de la síntesis de imágenes, aprender grupos de conceptos visuales interpretables y mejorar la solidez del modelo. Nuestros resultados demuestran que estos detectores de características complejas ultraescasas pueden servir como prototipos de memoria para regular el proceso de síntesis de imágenes en el sistema visual. .
1. Introducción
Hallazgos neurofisiológicos recientes basados en imágenes de calcio sugieren que muchas neuronas en la capa superficial V1 están fuertemente sintonizadas con patrones locales complejos (patrones) en lugar de simples bordes o barras orientados. Estas neuronas complejas mostraron respuestas más fuertes (aumento de 3 a 5 veces) cuando se expusieron a sus patrones preferidos que cuando se expusieron a estímulos simples de rejilla y tira. La alta especificidad de la selectividad de estas neuronas sugiere que pueden actuar como detectores de patrones específicos. Las respuestas de la población de estas neuronas V1 son muy escasas debido a la selectividad a estímulos complejos. Solo 4-6 de aproximadamente 1000 neuronas responden fuertemente a cualquier patrón dado o estímulo natural. Este hallazgo recuerda a un estudio anterior que encontró una codificación conceptual dispersa similar en el hipocampo. Los datos recientes en V4 también sugieren la existencia de células con un alto grado similar de escasez. Por lo tanto, especulamos que estas unidades deberían existir en cada capa del sistema visual jerárquico. Nos referimos a estos detectores de características de respuesta dispersa altamente selectivos como "neuronas abuelas" para enfatizar que pueden codificar explícitamente prototipos específicos, aunque en realidad los prototipos pueden consistir en grupos dispersos de neuronas en lugar de neuronas. No es una representación de una sola unidad. Las neuronas en diferentes capas de cada área visual exhiben diversos grados de escasez de respuesta, complementándose entre sí en varias funciones. Las observaciones de este conjunto diverso de detectores de características de respuesta ultraescasa plantean las siguientes preguntas: ¿Cuáles son las posibles ventajas computacionales y la justificación de tener tales neuronas en la corteza visual temprana?
En este artículo, planteamos la hipótesis de que estas "neuronas abuelas" pueden servir como recuerdos arquetípicos antes de regular el proceso de síntesis de imágenes. La síntesis de imágenes es un tema central de muchos modelos jerárquicos del sistema visual, incluida la activación interactiva y la codificación predictiva, y se supone que ocurre a través de conexiones de retroalimentación de arriba hacia abajo entre las regiones corticales visuales. Estos antecedentes permiten que el proceso de síntesis vaya más allá del contexto espacial actual y explote los recuerdos arquetípicos aprendidos y acumulados a lo largo del tiempo. Así, la "unidad abuela" actúa como un concepto estructural previo durante la atención de la memoria durante la generación de imágenes.
Para enfatizar la importancia de tener un mecanismo de atención que vaya más allá de las representaciones de imágenes actuales, llamamos a nuestro proceso de atención basado en la memoria propuesto Atención de concepto de memoria (MoCA). MoCA es un módulo que se puede conectar a cualquier capa de arquitectura de generador existente en el marco GAN. Llevamos a cabo extensos experimentos para probar nuestro modelo utilizando el StyleGAN2 de última generación y el generador de imágenes de pocos disparos FastGAN recientemente propuesto. Nuestros experimentos muestran que la explotación de la información del prototipo acumulada en grupos semánticos durante el entrenamiento puede mejorar la generación de imágenes de Animal-Face Dog, 100-Shot-human face, few-shot en ImageNet-100, COCO-300, CIFAR-10 y Caltech-UCSD Birds. (CACHORRO). Además, también encontramos que los generadores con MoCA son resistentes a cierto grado de corrupción de ruido inyectado durante las pruebas, lo que sugiere que abordar primero la memoria estructurada durante la generación mejora la solidez del modelo. Nuestro objetivo era explorar la utilidad de las unidades prototípicas como memoria previa en las tareas estándar de generación de imágenes de visión por computadora, con el fin de obtener información funcional sobre el predominio de estas "abuelas neuronales" en la corteza visual.
2. Trabajo relacionado
Aprendizaje de conceptos visuales .
- Se ha demostrado que los conceptos visuales, definidos como características semánticas de nivel medio, son efectivos para superar la clasificación errónea de objetos debido a la oclusión cuando se usan en un esquema de votación anticipada.
- Las representaciones explícitas de conceptos visuales utilizando neuronas prototípicas también pueden servir como piezas reconfigurables eficientes para construir máquinas combinatorias.
- En este artículo, exploramos el uso de conceptos visuales en forma de memorias previas prototípicas para proporcionar mecanismos de atención y modulación contextual temporal, espacial y temporal para la compleja tarea sintética de generación de imágenes.
Autoatención . Los mecanismos de atención en el aprendizaje profundo son populares en el procesamiento del lenguaje natural (NLP) y también se conocen como "redes no locales" en la comunidad de la visión.
- (2019) Zhang et al., introdujeron la autoatención en el modelo generativo de Self-Attention GAN. Desde entonces, agregar autoatención a las GAN se ha convertido en una práctica estándar.
- (2018) Brock et al., y (2020) Esser et al. demuestran los beneficios de utilizar la autoatención en modelos de síntesis de imágenes de alta fidelidad. Sin embargo, los mecanismos de autoatención actuales en las GAN solo utilizan información contextual dentro de la misma imagen para condicionar las activaciones.
En este trabajo, proponemos utilizar un caché en memoria de prototipos de conceptos visuales intermedios para proporcionar una modulación adicional más allá de la autoatención estándar. En nuestro trabajo, el mecanismo de activación no solo se centra en el contexto espacial de la imagen en sí, sino también en un conjunto de prototipos de memoria caché acumulados a lo largo del tiempo.
Prototipo de mecanismo de memoria . Los bancos de memoria pueden capturar diferentes características durante un largo período de tiempo y han demostrado ser efectivos en otros dominios.
- (2018) Wu y otros utilizan bancos de memoria en el aprendizaje contrastivo para obtener muestras negativas más diversas para comparar.
- (2020) Caron y otros también usan colas de memoria para acumular muestras negativas representativas durante el entrenamiento.
- (2020) He et al demostraron que el uso de un codificador de actualización de momento puede mejorar la estabilidad de las características acumuladas en un banco de memoria, una estrategia que también usaremos cuando aprendamos prototipos.
- (2017) SimGAN introdujo el truco de agrupación de imágenes, que utiliza un búfer para almacenar muestras generadas previamente, de modo que el discriminador no solo se centre en el lote de entrenamiento actual, sino que también se mejore basándose en la memoria.
La principal innovación de nuestro trabajo es que, inspirados en hallazgos neurofisiológicos recientes, deberíamos tener bancos de memoria en niveles intermedios y, en principio, en cada nivel de la jerarquía visual. Si bien el trabajo anterior del banco de miembros almacenaba imágenes a nivel de instancia para el reconocimiento de objetos, lo que no es útil para la generación de imágenes, argumentamos que los bancos de miembros en los niveles inferiores de la jerarquía podrían almacenar prototipos de partes y subpartes que son útiles para la generación de imágenes. Especialmente, la generación de imágenes de pocos disparos puede beneficiarse de los mecanismos de almacenamiento que admiten la combinación flexible y la descomposición de partes, especialmente cuando los datos son limitados.
Aprendizaje de prototipos de pocos disparos. El aprendizaje de pocos disparos se refiere a realizar tareas de visión por computadora con datos de entrenamiento muy limitados. Una de las ideas populares en la literatura de aprendizaje de pocos disparos es formar diferentes prototipos del conjunto de entrenamiento y usarlos durante las pruebas (Snell et al., 2017). Aunque MoCA también forma prototipos durante la fase de entrenamiento y los usa durante la inferencia, existen dos diferencias importantes entre nuestro trabajo y el de Snell et al.:
- Forman prototipos a nivel de instancia, mientras que los prototipos de MoCA se generan a nivel de componente intermedio.
- Simplemente eligen el prototipo más cercano para obtener predicciones de clases discretas. Mientras que MoCA emplea la atención para modular continuamente las funciones de activación de acuerdo con los prototipos y, por lo tanto, se puede aplicar a un conjunto más amplio de tareas, incluida la síntesis de imágenes, donde predice valores de píxeles continuos.
Generación de imágenes de pocos disparos . La tarea de generación de imágenes de pocos disparos es un desafío porque las GAN consumen muchos datos y son ineficientes. Entre los esquemas actuales de generación de imágenes de pocos disparos, la generación de imágenes incondicionales es especialmente difícil. En la literatura se han desarrollado diferentes soluciones.
- Trabajos recientes como (2020) DiffAug y (2020) StyleGAN-Ada proponen un aumento discriminativo para evitar el sobreajuste del discriminador.
- (2021) InsGen propone utilizar objetivos de aprendizaje contrastivos para mejorar las pérdidas adversarias en el entorno generativo de pocos disparos.
- La mayoría de estos trabajos proponen formas de mejorar los discriminadores para que puedan proporcionar mejores señales de error a los generadores, pero ninguno aborda específicamente las arquitecturas de los generadores.
- (2021) Otro estudio propone arquitecturas generadoras para evitar el colapso del esquema. La arquitectura de última generación para la generación de imágenes con pocos disparos (cientos de imágenes reales) es FastGAN.
Aquí, proponemos una nueva variación arquitectónica en el lado del generador y realizamos extensas comparaciones con la arquitectura FastGAN en la sección experimental.
3. Método
Nuestra principal contribución es introducir un nuevo módulo de modulación de memoria basado en prototipos para mejorar la red generadora de GAN. Las activaciones de la capa anterior son modificadas por dos procesos de atención:
- Modulación del contexto utilizando la atención del concepto de memoria (MoCA),
- Generar modulación del contexto espacial de la propia imagen (autoatención).

Nuestro módulo toma mapas de características en una jerarquía GAN como entrada y combina los resultados de estos dos mecanismos para modular los mapas de características para un procesamiento posterior posterior. La estructura del modelo se muestra en la figura anterior.
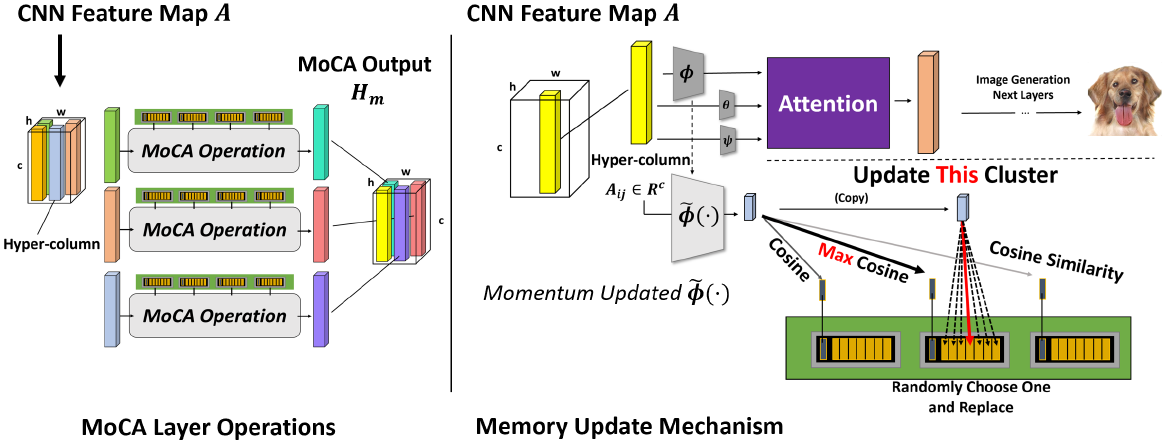
- En MoCA, la activación de entrada Aij se transforma primero en un espacio de baja dimensión mediante una convolución 1x1 θ( ) y se utiliza para seleccionar su unidad semántica más cercana en un proceso en el que el ganador se lo lleva todo.
- Las unidades semánticas seleccionadas permitirán que las unidades de memoria prototípicas en sus clústeres participen en el proceso MoCA, generando una modulación que luego se mapea desde el espacio de incrustación al espacio de características mediante una red 1x1 O(·).
- En la ruta de autoatención, todo el mapa de características A se convierte en clave y valor a través de dos convoluciones 1x1 correspondientes Φ(·) y Ψ(·), luego se enfoca en el vector de consulta (codificado desde Aij) y luego se vuelve a mapear a el espacio de características.
- Finalmente, las salidas de las dos rutas se agregan para formar la entrada de la siguiente capa.
- Tenga en cuenta que el decodificador O(·) y el codificador de consulta θ(·) se comparten entre las dos rutas.
Formalmente, denotamos la entrada de una capa MoCA como la activación específica de la capa A ∈ R^(nxcxhxw). La salida produce una modulación H ∈ R^(nxcxhxw) que actualiza A a ^A. Para permitir que la información se module de manera flexible, usamos la siguiente función para convertir A en un espacio de baja dimensión a través de una convolución 1x1
![]()
3.1 Prototipo de aprendizaje de memoria
En esta sección discutimos la organización de la memoria prototipo utilizada como ruta de modulación. Nuestra memoria de conceptos prototípicos está organizada jerárquicamente en unidades semánticas y prototípicas.
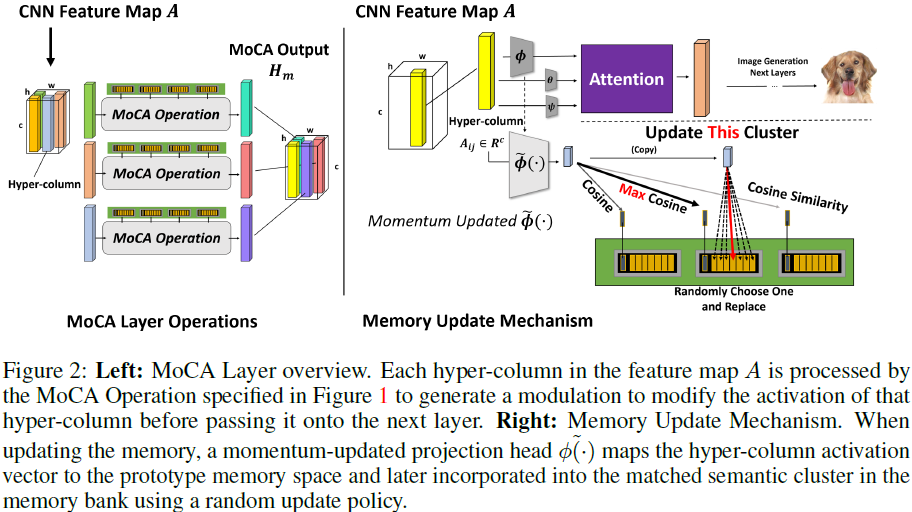
Como se muestra en la Figura 2, cada unidad semántica es la media del grupo que representa un conjunto de unidades prototipo. Formalmente, supongamos que nuestra memoria P consta de M unidades semánticas P = {K1, K2,..., KM}. Por cada unidad semántica Ki, existen T unidades prototipo
![]()
almacenado en la unidad de memoria asociada con Ki, donde
![]()
y
![]()
es el valor promedio de las celdas prototipo almacenadas. Estas unidades prototipo provienen de los mapas de características en iteraciones anteriores, transformadas por un codificador de contexto de actualización de momento ~Φ(), y actualizadas en la memoria al final de cada iteración de entrenamiento. ~Φ(·) es la contraparte del momento de Φ(·), cuyos parámetros se actualizan como se muestra en la Ecuación 1, donde el parámetro del momento es m. ~Φ( ) no cambia tan rápidamente como Φ( ), por lo que el prototipo aprendido es más estable y acumula información más allá del lote de entrenamiento actual.
![]()
Después de la transformación a un espacio de baja dimensión por ~Φ(·), la activación de cada hipercolumna (ubicación de píxel) en el mapa de características se asigna a su grupo semántico más cercano y reemplaza la unidad prototipo existente en el banco de memoria de ese grupo. Usamos una estrategia de reemplazo aleatorio para evitar el colapso total de las celdas prototipo en soluciones triviales. La actualización se realiza de manera síncrona por lotes, es decir, después de actualizar toda la memoria en función del último lote, actualizamos Ki para que sea el valor promedio del i-ésimo clúster prototipo.
3.2 Atención del concepto de memoria (MEMORY CONCEPT ATENTION, MoCA)
Como describimos en la Sección 3.1, nuestra memoria es un caché de patrones de activación de hipercolumnas recopilados de todo el conjunto de entrenamiento, así como de diferentes épocas de entrenamiento. Al organizarlos por unidades semánticas (Ki), podemos enrutar información más diversa a la activación final mientras mantenemos una alta eficiencia de datos, lo que resulta en tareas de síntesis de imágenes de mayor calidad. En esta sección, presentamos la operación detallada de la transformación dada una memoria P existente y las siguientes características de entrada.
![]()
Durante la atención de la memoria, la columna de activación de θ(A)
![]()
Primero seleccione la unidad semántica Ki más cercana y recupere la matriz de unidades prototipo asociada de la memoria
![]()
donde cada columna j de E ^(i) es una unidad prototipo perteneciente al grupo de la unidad semántica seleccionada Ki
![]()
El siguiente paso es procesar la columna de activación a utilizando la matriz de elementos prototipo E^ (i) . Primero, la puntuación de similitud s se calcula como
![]()
A continuación, se aplica una normalización softmax no lineal a s para obtener pesos de atención normalizados β, donde se aplica la Ecuación 2 para cada entrada β_t (t={1,2,...T}).

Usando los pesos de atención normalizados (suaves) β, podemos construir la memoria
![]()
información recuperada de . Aplicando la misma operación a la activación a en cada ubicación espacial y a cada imagen del lote, obtenemos
![]()
3.3 Atención del contexto espacial
Si bien la memoria previa es importante, la información contextual espacial también juega un papel en la modulación de la activación. Por lo tanto, también implementamos la modulación del contexto espacial en la misma capa utilizando una red no local. Específicamente, primero calculamos el mapa de afinidad entre θ(A) y Φ(A), denotado como
![]()
Luego, cada fila de S se normaliza mediante softmax para permitir el cálculo de pesos de atención más bien escasos ^ S . ^ S luego se multiplica por Φ(A) para obtener el tensor de modulación del contexto espacial
![]()
3.4 Integración de dos caminos de modulación
Finalmente, integramos la información de recuperación de la memoria H_m y la modulación del contexto espacial H_s a través del elemento - adición sabia
![]()
Luego se vuelve a transformar al espacio de características original mediante una convolución O(·) de 1x1. Un parámetro aprendible γ se usa como un peso, que se pondera y se vuelve a agregar a la activación de entrada, es decir,
![]()
Luego se envía a la siguiente capa del generador.
4. Experimenta
El módulo MoCA propuesto es una mejora en la arquitectura del generador y no es específico de la técnica de entrenamiento del discriminador. Tenga en cuenta que algunos trabajos existentes sobre la generación incondicional de imágenes de pocos disparos (DiffAug, ADA, etc.) mejoran la calidad de la síntesis de imágenes centrándose en el lado del discriminador.Aumentación para evitar el sobreajuste del discriminador. Si bien esta línea de trabajo es valiosa, es ortogonal y complementaria a MoCA porque MoCA es una arquitectura generadora que se puede entrenar bajo todas estas técnicas de entrenamiento de discriminadores. En los siguientes experimentos, utilizamos el generador aumentado MoCA con el discriminador aumentado DiffAug o ADA.
4.1 rendimiento de síntesis de imágenes de pocos disparos
Mostramos en la Tabla 1 (FastGAN) y la Tabla 2 (StyleGAN2) la comparación cuantitativa entre el mejor rendimiento de MoCA y el modelo de referencia para cada conjunto de datos. Tenga en cuenta que los niños se muestran en una escala de 10^(-3). Como muestran los resultados, observamos una mejora constante en la calidad de la síntesis de imágenes en este difícil estado de datos bajos al agregar MoCA al generador.

Como se muestra en la Tabla 1, en términos de puntajes FID, observamos que al usar la infraestructura FastGAN, MoCA puede lograr una mejora del 5,8 % para Animal Face Dog, 13,8 % para Obaxx, 21,7 % para ImageNet-100 y 12,4 % para COCO- 300 conjunto de datos. Se observaron mejoras similares utilizando la métrica KID.
Para probar aún más la mejora de MoCA en modelos más potentes, realizamos experimentos con la infraestructura StyleGAN2, como se muestra en la Tabla 2. Con la métrica de evaluación FID, observamos una mejora del 5,1 % en el conjunto de datos Animal Face Dog, del 8,1 % en el conjunto de datos Obaxx, del 14,1 % en el conjunto de datos ImageNet-100 y del 17,3 % en el conjunto de datos COCO-300. Tenga en cuenta que los conjuntos de datos ImageNet-100 y COCO-300 son muy desafiantes porque contienen muchas más escenas que Animal Face Dog y Obaxx. Para compensar el tamaño del modelo de la infraestructura StyleGAN2, reducimos ImageNet-100 y COCO-300 a un tamaño de imagen de 64x64 cuando entrenamos con StyleGAN2 y MoCA-StyleGAN2. A partir de los resultados, observamos que MoCA-StyleGAN2 sintetiza constantemente mejores imágenes que la línea de base, independientemente del tamaño de la imagen. Además, también observamos que los diferentes métodos de aumento en el lado del discriminador no afectan la mejora de MoCA, ya que el modelo basado en FastGAN usa DiffAug, mientras que el modelo basado en StyleGAN2 usa la técnica ADA.
4.2 Estudio de ablación
En esta sección, presentamos los estudios de ablación de las capas de MoCA en comparación con la autoatención sola y la importancia del diseño de la cabeza de impulso. En el Apéndice 8.1 se pueden encontrar más estudios de ablación sobre el diseño de organización de agrupamiento de memoria utilizado en MoCA, y se pueden encontrar más análisis de visualización en el Apéndice 8.6.

Autoatención y MoCA . En StyleGAN2 y FastGAN, comparamos el rendimiento de MoCA con un bloque de autoatención estándar para verificar que la mejora del rendimiento de nuestro modelo no se debe solo al bloque de autoatención, ya que varios trabajos anteriores han enfatizado la aplicación de autoatención en GAN. para capturar la ventaja de las dependencias no locales. La Tabla 3 muestra que, en comparación con las arquitecturas de referencia, MoCA supera constantemente al módulo de autoatención estándar, lo que indica que el módulo MoCA desempeña un papel insustituible en nuestro método.
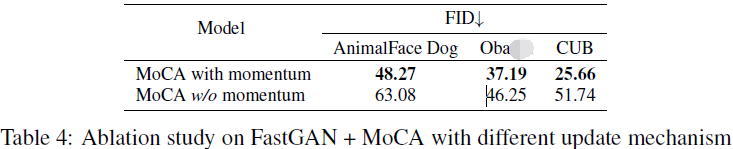
La importancia del mecanismo de actualización de impulso. También investigamos el efecto de diferentes formas de actualizar el concepto de codificador. La Tabla 4 muestra que cuando se utiliza el impulso para actualizar el codificador de concepto, generalmente se mejora la FID del modelo en múltiples conjuntos de datos. Aprovechando el impulso, FastGAN logra una FID significativamente mejor en conjuntos de datos más grandes y diversos, como AnimalFace Dog y CUB. Esto respalda nuestra motivación para usar codificadores de actualización de impulso para crear un banco de memoria más general que contenga información más amplia más allá del lote de entrenamiento actual.
4.3 Análisis del concepto de prototipo
Aquí demostramos que durante el aprendizaje de confrontación para la síntesis de imágenes, MoCA puede aprender de manera no supervisada diferentes conceptos semánticos, representados por "unidades abuelas" o sus representantes.

Conceptos semánticos en MoCA. Asignamos un grupo semántico a cada hipercolumna en el mapa de características de 16 x 16 durante la generación de avance (el mecanismo de selección de grupo se describe en Métodos Sección 3.2). Etiquetamos los campos receptivos o proyectados de todas las hipercolumnas asociadas con cada grupo semántico prototipo seleccionado como cuadros delimitadores blancos en las imágenes generadas, algunos ejemplos se muestran en la Fig. 4. Podemos observar que diferentes grupos codifican diferentes conceptos semánticos. Por ejemplo, el Clúster 0 a menudo se asocia con las vías del tren. El grupo 2 cubre áreas de color uniforme, como el cielo y el suelo. Grupo 17 Tenga en cuenta el lado del tren. El grupo 8 se centra en el tren en sí, especialmente en la parte delantera. A lo largo de cada fila, observamos que el efecto de MoCA en una imagen en particular se puede descomponer en diferentes grupos. Algunos grupos son más populares (por ejemplo, el Grupo 0, 2, 8), mientras que otros se usan de forma más selectiva (por ejemplo, la tercera imagen del Grupo 17).

Comprender las unidades prototipo. Para comprender las unidades prototipo almacenadas en caché en cada grupo MoCA, identificamos parches de imagen generados en el campo receptivo de cualquier hipercolumna cuyas activaciones estuvieran más cerca de la memoria de la unidad prototipo en el grupo especificado de las 100 hipercolumnas generadas por imágenes. los parches más cercanos a la memoria del prototipo son visualmente similares, y los prototipos que pertenecen al mismo grupo están relacionados semánticamente pero tienen características visuales distintas. Podemos ver que diferentes unidades prototípicas se especializan como subpartes de los grupos semánticos a los que pertenecen. Por ejemplo, en el grupo 0, el arquetipo 20 es una activación en caché de un ferrocarril o una vía de tren, pero otros arquetipos incluyen la parte superior de un tren. También se pueden hacer observaciones similares para los conglomerados 2 y 8 (Figura 5). Estos tres grupos se consultan con frecuencia y, por lo tanto, pueden contener memorias prototipo diferentes pero relacionadas semánticamente. La memoria de prototipo es similar al "concepto visual" propuesto por Wang et al. (2017) y puede usarse potencialmente como concepto visual para implementar un sistema de composición jerárquica para la síntesis de imágenes.
4.4 Robustez frente al ruido

Evaluamos la robustez del ruido de nuestro módulo de atención del concepto de memoria propuesto y lo comparamos con un módulo de autoatención estándar. La evaluación se realiza sobre el modelo FastGAN entrenado sin inyectar ruido en las capas intermedias. En la fase de evaluación, inyectamos ruido gaussiano de diferentes magnitudes con una variación de 0 a 1 en los mapas de características de entrada de la capa MoCA y la capa de autoatención estándar. Nuestros resultados (Tabla 5) muestran que la autoatención es más vulnerable al ruido sin la ayuda de la memoria externa, mientras que MoCA es generalmente menos sensible al ruido. Sospechamos que con MoCA, los mapas de características pueden centrarse en conceptos previamente almacenados en el banco de memoria para recuperar información de piezas sin ruido, mitigando así el efecto de las perturbaciones del ruido. También encontramos que MoCA sin clúster (todos los prototipos pertenecen al mismo clúster y juntos infieren cada activación Aij, es decir, M = 1) es más robusto a niveles de ruido más altos. Nuestra hipótesis es que los mapas de características pueden centrarse en más conceptos en MoCA no agrupados, lo que aumenta la posibilidad de obtener los bais correctos.
5. Conclusión
En este documento, presentamos un módulo llamado MoCA que se puede conectar a cualquier capa de una red neuronal en capas como GAN para mejorar la síntesis de imágenes. MoCA almacena en caché la memoria del prototipo de la pieza a lo largo del tiempo, la actualiza dinámicamente mediante un codificador de momento y es capaz de modular las respuestas continuas de las capas intermedias a través de un mecanismo de atención. En comparación con la investigación anterior del banco de memoria que almacena la representación de la imagen completa en el espacio latente de detección de objetos, el prototipo en MoCA es la parte y subparte de la memoria del objeto, que se puede extraer en cada nivel de la jerarquía y combinar de manera flexible. para la síntesis de imágenes. Nuestro trabajo está inspirado en un conjunto diverso de detectores de características complejas altamente selectivos en V1, que corresponden a las unidades prototipo en MoCA. La selección de grupos de prototipos distintos por unidades semánticas puede corresponder a circuitos de conmutación mediados por neuronas inhibitorias. Aunque no reclamamos ninguna correspondencia seria entre nuestro modelo y los mecanismos o circuitos neuronales, la efectividad de MoCA aún puede proporcionar una idea del papel de estas "neuronas abuelas" a nivel funcional.
6. Declaración de ética
Este estudio investiga una propuesta novedosa para comprender la ventaja computacional de las "neuronas abuelas" prototípicas en la corteza visual que pueden servir como antecedentes auxiliares de memoria para modificar el espacio de incrustación de los mecanismos de autoatención y los patrones de activación de las neuronas durante la síntesis de imágenes. Si bien estamos motivados para mejorar nuestra comprensión de la modulación contextual en los sistemas neuronales, nuestro trabajo también produce un mecanismo novedoso para la modulación contextual en los sistemas de aprendizaje profundo, particularmente en la generación de imágenes, y por lo tanto tiene implicaciones positivas más amplias para el aprendizaje automático. aprendiendo. Sin embargo, la tecnología de generación de imágenes puede utilizarse para desinformar, con un impacto social adverso, como la creación de "falsificaciones profundas". Por otro lado, profundizar nuestra comprensión de la generación de imágenes también es fundamental para combatir las falsificaciones profundas y otros usos indebidos de la tecnología de generación de imágenes por parte de malos actores.
8. Apéndice
8.1 Ablación: la importancia de la organización del clúster de memoria
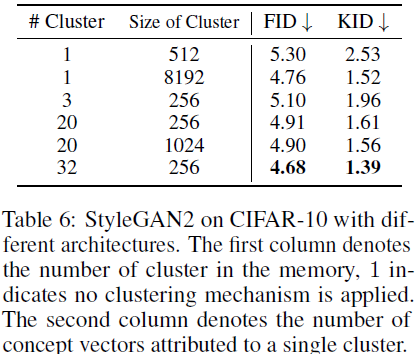
El segundo aspecto que investigamos es el efecto del mecanismo de agrupación en el rendimiento general del modelo. Encontramos que para MoCA, un grupo de concepto único con un tamaño suficientemente grande aún logra un rendimiento similar en comparación con MoCA con múltiples clústeres. Como se muestra en la Tabla 6, MoCA sin clúster con 8192 conceptos dentro se desempeña a un nivel similar a MoCA con 32 clústeres. Nuestra hipótesis es que esto se debe a que, si bien no existe un mecanismo de agrupamiento para obligar al banco de memoria a aprender conceptos distintos en MoCA sin agrupamiento, aún puede recordar conceptos distintos y útiles dado un conjunto de conceptos muy grande. Aunque se descubrió que MoCA sin clústeres puede funcionar de manera similar a MoCA de clústeres con un grupo suficientemente grande, creemos que el uso del mecanismo de clústeres sigue siendo superior. El uso de un mecanismo de agrupamiento reduce en gran medida la cantidad de vectores involucrados en el cálculo de atención, lo que nos permite construir bancos de memoria más grandes para conjuntos de datos complejos.
8.2 MOCA en LS-GAN
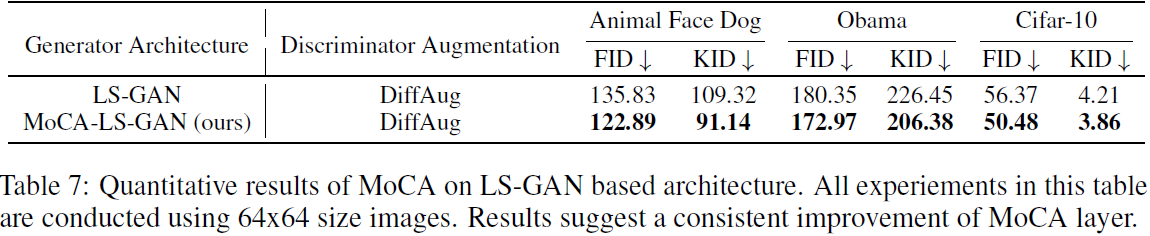
Para fortalecer nuestras conclusiones sobre MoCA, también llevamos a cabo experimentos en un marco GAN (mínimo cuadrado, LS-GAN) de mínimos cuadrados, que tiene una pérdida y una arquitectura diferentes en comparación con FastGAN y StyleGAN. Encontramos que MoCA aún puede proporcionar ciertas mejoras, consolidando las ventajas de la capa MoCA.
8.3 Limitaciones y fallas

Aunque MoCA puede aportar mejoras constantes en la mayoría de los conjuntos de datos con datos limitados, también observamos casos en los que MoCA tiene un desempeño deficiente. Descubrimos que agregar MoCA en StyleGAN para entrenar a Grumpy-cat da como resultado una ligera degradación del rendimiento, pero una pequeña mejora en FastGAN. Esto sugiere que cuando la diversidad del conjunto de datos subyacente es baja y la red subyacente es bastante grande, el concepto de caché de MoCA puede causar más ruido en el proceso de generación, lo que lleva a una degradación del rendimiento.
8.4 Algoritmos
Aquí, presentamos el algoritmo presentado en las Figuras 1 y 2 en el texto principal.

8.6 Análisis de los conceptos de memoria

Generamos 50 000 imágenes a partir de ruido aleatorio para CIFAR-10 y 1000 imágenes para Obaxx de 100 tomas. Para cada mapa de características y grupo i específico de concepto, contamos cuántos píxeles tiene el grupo más cercano (medido por el tamaño del producto escalar) i, y repetimos este proceso para todos los grupos. Luego sumamos los conteos y seleccionamos los K clústeres principales con la mayor cantidad de píxeles y visualizamos su mapa de calor de afinidad. Para interpretar las incrustaciones de vectores (conceptos) almacenadas en cada grupo de conceptos, realizamos tres visualizaciones: mapas de calor de afinidad correspondientes a diferentes grupos de conceptos, máscaras binarias de imágenes correspondientes a diferentes grupos de conceptos, y antes de participar en la memorización de conceptos y visualización t-SNE de los mapas de características después. El proceso de recuperación de información detallada se muestra en la Figura 6. Usamos los resultados de StyleGAN2+MoCA para la visualización, ya que funcionan mejor en la mayoría de los conjuntos de datos.
 concepto semántico . En la Fig. 7a y la Fig. 7b mostramos los mapas de afinidad calculados como se describió anteriormente (en la Fig. 6 se muestra un diagrama esquemático detallado del proceso de visualización). Tenga en cuenta que elegimos grupos e imágenes con fines de demostración. Los resultados se obtienen en CIFAR10 usando MoCA-StyleGAN (resolución 32x32) y el conjunto de datos Obaxx usando MoCA-FastGAN (resolución 256x256).
concepto semántico . En la Fig. 7a y la Fig. 7b mostramos los mapas de afinidad calculados como se describió anteriormente (en la Fig. 6 se muestra un diagrama esquemático detallado del proceso de visualización). Tenga en cuenta que elegimos grupos e imágenes con fines de demostración. Los resultados se obtienen en CIFAR10 usando MoCA-StyleGAN (resolución 32x32) y el conjunto de datos Obaxx usando MoCA-FastGAN (resolución 256x256).
- Encontramos que estos mapas de afinidad indican que los conceptos formados durante el entrenamiento MoCA cubren modos críticos y diversos de síntesis de imágenes.
- Como se muestra en las Figuras 7a y 7b, los patrones de diferentes grupos suelen ser semánticamente significativos y muy diferentes.
- En CIFAR-10, notamos que el grupo 11 almacena conceptos relacionados con el cielo, mientras que el grupo 13 almacena conceptos relacionados con el chasis del camión. El grupo 7 favorece los espacios en blanco, mientras que el grupo 18 se centra en el cuerpo y la cabeza del animal.
- Del mismo modo, en otro conjunto de datos, diferentes grupos se enfocan en patrones muy diferentes. Por ejemplo, en Obama de 100 disparos, el grupo 3 almacena conceptos estrechamente relacionados con las corbatas, y el grupo 9 contiene conceptos relacionados con el reflejo de la luz facial.
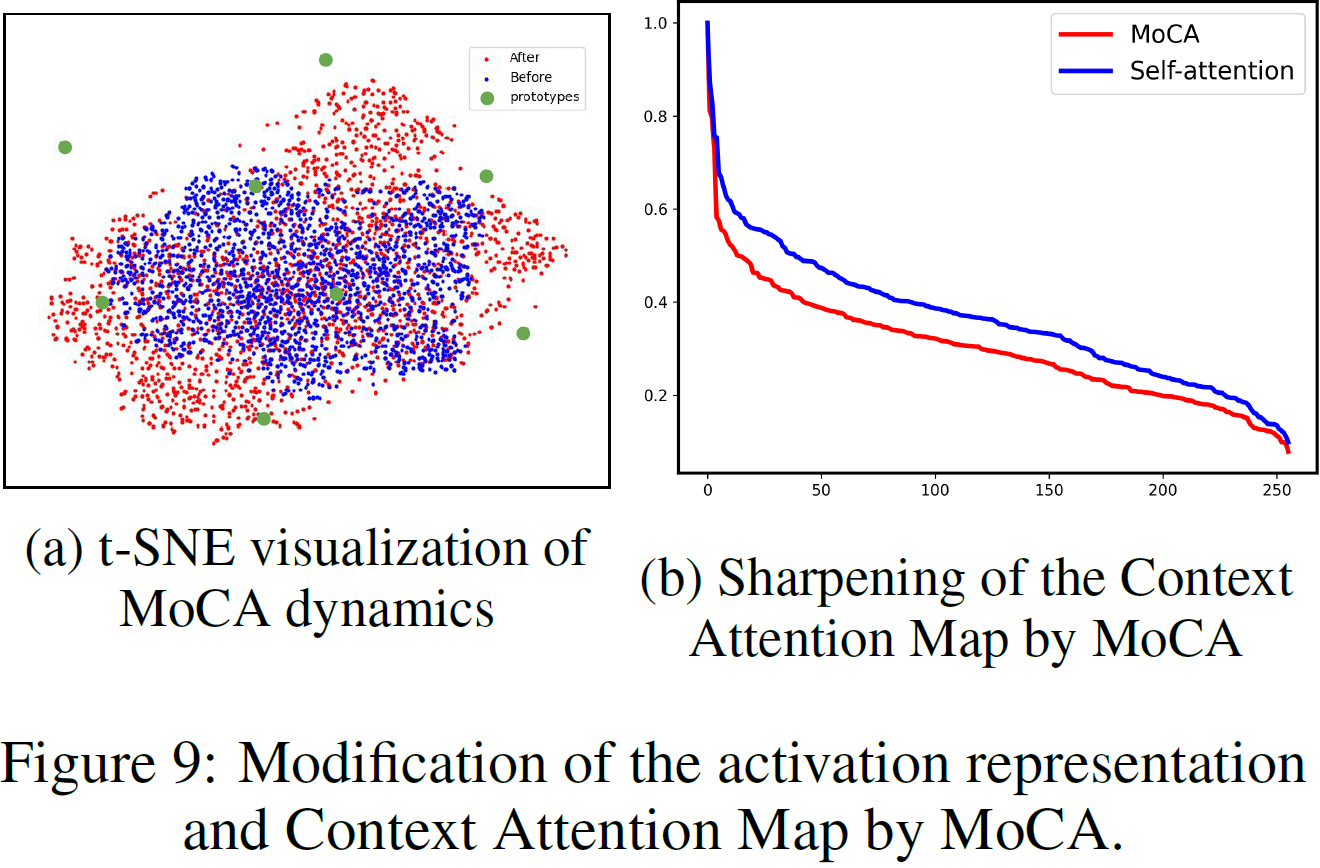
Atención prototipo . Investigamos la dinámica interna de MoCA mediante el uso de t-SNE para visualizar las tendencias cambiantes de los mapas de características antes y después de la atención a los conceptos en la memoria. Generamos 10.000 imágenes a partir de ruido aleatorio en CIFAR-10 y extraemos mapas de características antes y después de las capas MoCA. La Figura 9a muestra que el patrón de activación (puntos azules) de la capa anterior es transformado por MoCA (recuadro verde en la Fig. 1) en una representación (puntos rojos) que se reemplaza por un arrastre o estiramiento familiar.

La síntesis de imágenes como ensamblaje conceptual. Al visualizar la afinidad de cada píxel en un mapa de características con un prototipo, obtenemos una comprensión de alto nivel de los conceptos que los diferentes grupos están tratando de capturar. También podemos investigar más a fondo la relación entre diferentes conceptos y el proceso de síntesis de imágenes.
- Descomponemos la imagen en diferentes máscaras binarias con respecto a los 3 grupos principales. El desglose se muestra en la Figura 8.
- Específicamente, dado un clúster específico Ck y un mapa de características F, al consultar si el clúster más cercano (mayor afinidad) de un píxel (Fij) es Ck, generamos una máscara binaria correspondiente a Ck, donde el blanco representa verdadero y el negro indica falso.
- Seleccionamos los 3 grupos principales para cada imagen y visualizamos sus máscaras binarias, como se muestra en la Figura 8.
- Para la mayoría de las imágenes, los dos primeros grupos de conceptos suelen estar relacionados con la información de primer plano y de fondo, mientras que el tercer grupo contiene conceptos relacionados con detalles de alta frecuencia en la imagen.
- Esto sugiere que, usando MoCA, la síntesis de imágenes también puede verse como el proceso de recuperar diferentes conceptos de la memoria y combinarlos para crear imágenes realistas.
El impacto implícito de MoCA en los mecanismos de atención . Curiosamente, también observamos que tener módulos MoCA puede, a su vez, mejorar la actividad funcional de las interacciones horizontales. Para visualizar la conectividad funcional de las conexiones horizontales, trazamos el orden normalizado en la Fig. 9b, con la curva púrpura que representa la curva de orden sin MoCA instalado y la curva roja que representa la curva de orden con MoCA instalado. Aparentemente, MoCA fortalece la conectividad funcional entre las conexiones horizontales, aunque no modificamos explícitamente el proceso de autoatención en la capa MoCA. Esto sugiere que nuestra memoria prototípica influye implícitamente en la conectividad horizontal.
8.9 Visualización de detalles
Localización de los detalles del campo receptivo . Para generar el campo receptivo para cada hipercolumna (cuadro delimitador blanco en la Figura 4), calculamos el campo receptivo de acuerdo con la arquitectura de la red. La imagen final tiene una resolución de 256 x 256. Para una sola hipercolumna en una capa, instalamos MoCA (capa 16 x 16) con 4 capas de muestreo superior (cada una con un factor de 2) y 7 capas convolucionales (cada una con un tamaño de kernel de 3x3, 1 paso y 1 relleno), lo que resultó en un tamaño del campo receptivo de 66 x 66. El seguimiento de las posiciones se basa en una derivación recursiva de operaciones de convolución y sobremuestreo.
Detalles del prototipo de visualización. Dado que nuestro prototipo solo afecta las activaciones a través de la atención, no es trivial visualizar el prototipo. Sin embargo, dado que nuestros prototipos se utilizan para modular una hipercolumna ponderada por la similitud normalizada entre θ(Aij) y el vector prototipo, podemos tratar una hipercolumna en el espacio proyectado con una similitud de alto coseno con el vector prototipo como los Prototipos son una aproximación porque si son similares, hay un gran peso en el proceso de atención. Dado que cada hipercolumna corresponde a una generación de parches en la imagen, podemos visualizar el parche correspondiente y comprender qué representan las celdas prototipo individuales.
referencia
Li T, Li Z, Rockwell H, et al. Prototipo de memoria y mecanismos de atención para la generación de imágenes de pocos disparos [C] // Actas de la Undécima Conferencia Internacional sobre Representaciones de Aprendizaje. 2022, 18.
S. Resumen
S.1 Idea central
En el cerebro humano, hay grupos de neuronas que recuerdan prototipos (conceptos/características, por ejemplo: rostros humanos), por ejemplo, las "neuronas de la abuela" recuerdan a las abuelas y las "neuronas del padre" recuerdan a los padres.
Inspirándose en este estudio, este documento propone la atención del concepto de memoria (MoCA) para mejorar la calidad de la generación de imágenes de pocos disparos. MoCA es solo un módulo que se puede conectar a cualquier capa de arquitectura de generador existente en el marco GAN.
Estos prototipos de memoria se aprenden a través del agrupamiento en línea de impulso y se explotan a través de la atención basada en la memoria.
Método S.2
El módulo de modulación de memoria basado en prototipo se muestra en la figura anterior, y la entrada A del módulo es el mapa de características de la estructura jerárquica de GAN. Utilice la siguiente función para convertir la entrada en un espacio de baja dimensión y las tres salidas corresponden a la consulta, la clave y el valor en la atención.
![]()
Prototipo de aprendizaje de memoria . La tecla Φ( ) actualiza el prototipo en el banco de memoria del grupo semántico más cercano a él por impulso.
![]()
Atención del concepto de memoria (MoCA) . Query selecciona la unidad de memoria semántica más cercana (la media de grupo de un conjunto de unidades prototipo) por similitud de coseno. Después de que softmax normaliza la puntuación de similitud, la unidad semántica más cercana se pondera como un peso para obtener una matriz de unidad de memoria ponderada
![]()
Atención del contexto espacial (autoatención) . Calcule el mapa de afinidad (correlación) entre la consulta θ(A) y la clave Φ(A), use softmax para normalizarlo y pondere la clave Φ(A) como peso para obtener el tensor de modulación del contexto espacial
![]()
Integrar los dos caminos . Finalmente, integramos la memoria H_m y la modulación del contexto espacial H_s mediante la suma de elementos
![]()
A continuación, transforme H del espacio de incrustación de nuevo al espacio de características original mediante una convolución 1x1 O(·). Un parámetro aprendible γ se usa como un peso, que se pondera y se vuelve a agregar a la activación de entrada, es decir,
![]()
Luego se envía a la siguiente capa del generador.
S.3 Restricciones
Cuando la diversidad del conjunto de datos subyacente es baja y la red subyacente es bastante grande, el concepto de almacenamiento en caché de MoCA puede causar más ruido en el proceso de generación, lo que lleva a una degradación del rendimiento.
S.4 Análisis de conglomerados de conceptos
Los patrones de diferentes grupos suelen ser semánticamente significativos y muy diferentes, es decir, diferentes grupos almacenan diferentes conceptos.
Al descomponer una imagen en máscaras binarias distintas sobre los 3 grupos principales (según la afinidad de cada píxel en el mapa de características con el prototipo), los autores encuentran que para la mayoría de las imágenes, los conceptos de los 2 grupos principales generalmente están asociados con información de primer plano y de fondo, mientras que el tercer grupo contiene conceptos relacionados con detalles de alta frecuencia en la imagen. Esto sugiere que, usando MoCA, la síntesis de imágenes también puede verse como el proceso de recuperar diferentes conceptos de la memoria y combinarlos para crear imágenes realistas.