Explorando la transferencia de conocimientos incompatibles en la generación de imágenes de pocos disparos
Cuenta oficial: EDPJ
Tabla de contenido
4. Transferencia de conocimiento incompatible en FSIG
4.1 Investigación de conocimientos incompatibles
4.2 Configuración experimental
5.1 Truncamiento del conocimiento a través de la poda de red
6.1 Evaluación y comparación del desempeño
F. Estudio de ablación: efecto de los filtros de alta importancia
H. Estudios de ablación: medidas adicionales de importancia
0. Resumen
La generación de imágenes de pocos disparos (FSIG) aprende a generar imágenes diversas y de alta fidelidad a partir de un dominio de destino utilizando un pequeño número (por ejemplo, 10) de muestras de referencia. Los métodos FSIG existentes seleccionan, conservan y transfieren el conocimiento previo de los generadores de origen (entrenados previamente en dominios relacionados) para aprender de los generadores de destino. En este trabajo, investigamos un problema poco explorado en FSIG llamado transferencia de conocimiento incompatible, que puede reducir significativamente la autenticidad de las muestras sintéticas. Las observaciones empíricas muestran que el problema surge del filtro menos significativo en el generador fuente. Con este fin, proponemos el truncamiento del conocimiento para aliviar este problema en FSIG, que es una operación complementaria a la preservación del conocimiento e implementada mediante un enfoque basado en la poda ligera. Extensos experimentos demuestran que el truncamiento del conocimiento es simple y efectivo, logrando consistentemente un rendimiento de vanguardia, incluyendo escenarios desafiantes donde los dominios de origen y destino están más lejos.
1. Introducción
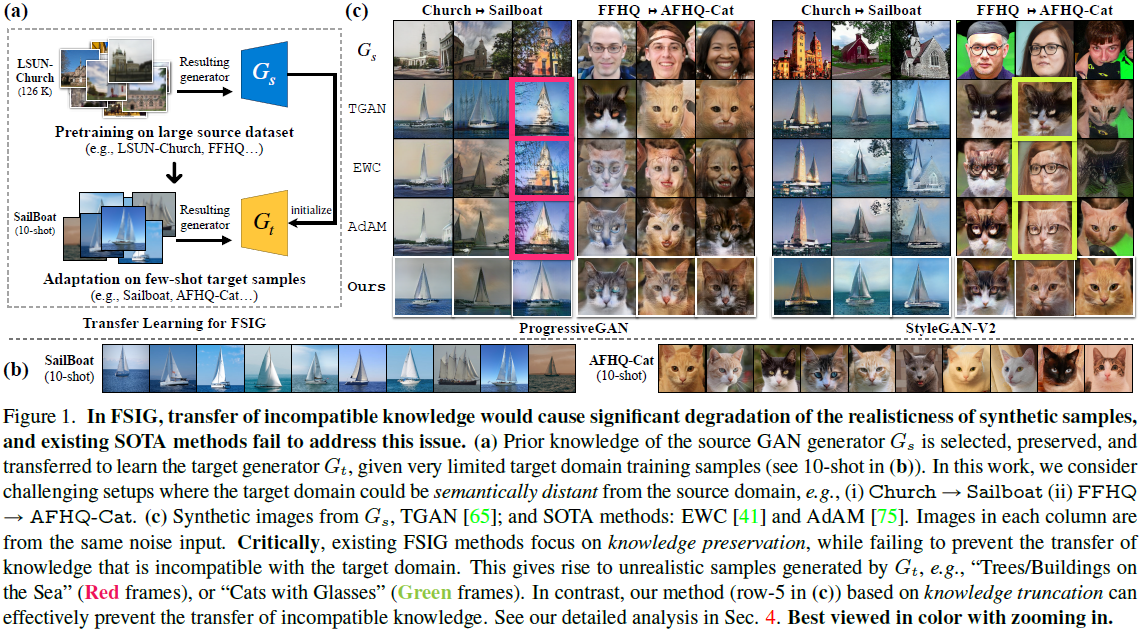
Transferencia de conocimiento incompatible . A pesar de las impresionantes mejoras logradas por diferentes métodos de preservación del conocimiento, en este trabajo argumentamos que prevenir la transferencia de conocimiento incompatible es igualmente importante. Esta transferencia de conocimiento incompatible se revela mediante investigaciones bien diseñadas en presencia de características semánticas inesperadas. Estas características son inconsistentes con el dominio de destino, lo que reduce el realismo de las muestras sintéticas. Como se muestra en la Figura 1, los árboles y los edificios no son compatibles con el dominio de Sailboat (observable al examinar las 10 muestras de referencia). Sin embargo, cuando se aplican métodos SOTA existentes [41, 75] junto con generadores de fuentes entrenados en Church, aparecen en imágenes sintéticas. Esto demuestra que los métodos existentes no pueden prevenir eficazmente la transferencia de conocimientos incompatibles.
Truncamiento del conocimiento . Sobre la base de nuestras observaciones, proponemos la eliminación de conocimientos incompatibles (RICK), un método ligero basado en la poda de filtros para eliminar los conocimientos incompatibles con la codificación durante la adaptación de FSIG (es decir, el filtro que se estima que tiene la menor importancia adaptativa). Si bien la poda de filtros se ha utilizado ampliamente para lograr redes profundas compactas con cómputo reducido, su aplicación para prevenir la transferencia de conocimiento incompatible no se ha explorado completamente. Observamos que nuestro truncamiento de conocimiento propuesto y poda de filtros incompatibles son ortogonales y complementarios a los métodos de preservación de conocimiento existentes en FSIG. De esta manera, nuestro método elimina de manera efectiva el conocimiento incompatible en comparación con el trabajo anterior y mejora significativamente la calidad de las imágenes generadas (por ejemplo, FID).
2. Trabajo relacionado
Recientes métodos de vanguardia proponen retener algunos conocimientos para la adaptación.
- FreezeD corrige algunas capas inferiores del discriminador para la adaptación
- EWC identifica parámetros importantes de la tarea de origen y penaliza los cambios de peso
- CDC tiene como objetivo mantener constante la distancia entre las imágenes generadas antes y después de la adaptación
- DCL maximiza la información mutua entre las imágenes generadas de origen y de destino a partir del mismo código latente de entrada para preservar el conocimiento.
- Recientemente, AdAM propone un enfoque basado en la modulación para identificar el conocimiento fuente importante para el dominio objetivo y retener el conocimiento para la adaptación.
3. Conceptos básicos
Los métodos FSIG existentes emplean métodos de aprendizaje de transferencia (TL) y utilizan GAN de origen previamente entrenados en grandes conjuntos de datos de origen. Denotamos el generador de fuente como Gs (y el discriminador de fuente como Ds). Durante el proceso de adaptación, el generador de destino Gt (discriminador de destino Dt) se obtiene mediante el ajuste fino de la fuente GAN en un pequeño número de imágenes de destino a través de una pérdida antagónica L_adv.
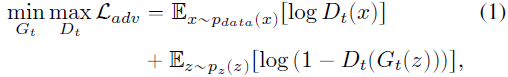
donde z es un código oculto unidimensional muestreado a partir de una distribución de ruido p_z(z) (p. ej., distribución gaussiana), y p_data(x) representa la distribución de datos objetivo de pocos disparos. Tenga en cuenta que los datos de origen no son accesibles. En el ajuste fino, los pesos de Gs (y Ds) se utilizan para inicializar Gt (y Dt), consulte la Fig. 1(a). El objetivo principal de FSIG es aprender Gt para capturar p_data(x).
Para mitigar el colapso del modo debido a muestras de destino muy limitadas, los enfoques recientes aumentan el ajuste con la preservación del conocimiento para seleccionar y preservar cuidadosamente un subconjunto de conocimiento de origen durante la adaptación, como congelación, regularización y métodos basados en modulación. Estos métodos tienen como objetivo preservar el conocimiento considerado útil para los generadores de objetos, por ejemplo, para aumentar la diversidad de la generación de muestras de objetos. Para los conocimientos considerados menos útiles, es una práctica común el ajuste fino utilizando la Ecuación 1, actualizando dichos conocimientos durante el proceso de adaptación.
4. Transferencia de conocimiento incompatible en FSIG
En esta sección, como nuestra primera contribución, observamos e identificamos un problema desapercibido de transferencia de conocimiento incompatible en los métodos FSIG existentes, y revelamos que la actualización del conocimiento basada en el ajuste fino no es suficiente para eliminar el conocimiento incompatible después de la adaptación del conocimiento compatible.
Para respaldar nuestra afirmación y encontrar la causa raíz de la transferencia de conocimiento incompatible, aplicamos la disección GAN, una correspondencia entre diferentes filtros de reconocimiento de imágenes y el marco de segmentación semántica de clases de objetos específicas (por ejemplo, árboles) para revelar filtros que preservan el conocimiento incompatible después del ajuste.
4.1 Investigación de conocimientos incompatibles
Los métodos anteriores de SOTA FSIG proponen diferentes criterios de preservación del conocimiento para seleccionar el conocimiento fuente preentrenado para la adaptación de pocos disparos. La adaptación generalmente se realiza ajustando el generador de origen (a través de la Ecuación 1) con una pequeña cantidad de muestras de destino. Una suposición en estos métodos es que el ajuste fino puede adaptar el generador de origen al generador de destino, de modo que el conocimiento de origen irrelevante e incompatible pueda eliminarse o actualizarse.
En este trabajo, mostramos que esta suposición se vuelve inválida en los casos en que los dominios de origen y de destino son semánticamente distantes (por ejemplo, caras humanas y de gato en la Figura 1), donde la transferencia de conocimiento incompatible es grave y compromete la autenticidad de las imágenes generadas. Notamos que esto no ha sido bien estudiado en trabajos anteriores de SOTA FSIG, ya que se enfocan principalmente en preservar el conocimiento desde la fuente (ver Sección 2), y prestan poca atención a la transferencia de conocimiento, lo cual es incompatible con la actualización de conocimiento basada en ajustes finos.
En una red neuronal convolucional, cada filtro puede verse como una codificación de una parte específica del conocimiento. Intuitivamente, en los modelos generativos, dicho conocimiento podría ser texturas de bajo nivel (como el pelaje) o conceptos interpretables por humanos de alto nivel (como los ojos). Por lo tanto, planteamos la hipótesis de que se pueden encontrar pistas sobre la transferencia de conocimiento incompatible centrándose en los filtros del generador. Recientemente, AdAM propuso un método de sondeo de importancia (IP) para determinar si un filtro GAN de origen es importante para la adaptación y logró un rendimiento impresionante. En nuestro análisis, empleamos IP para evaluar la importancia de los filtros generadores de fuentes para la adaptación del dominio de destino (presentamos brevemente IP en el Suplemento). Proponemos dos experimentos con diferentes granularidades:
- Exp-1: Generar imágenes con entradas fijas del generador . Visualizamos las imágenes generadas por diferentes métodos. Para comprender la transferencia de conocimientos antes y después de la adaptación, usamos el mismo ruido como entrada para los generadores de origen y de destino. Conceptualmente, esto nos proporciona una comparación intuitiva y directa de la transferencia de conocimiento.
- Exp-2: Disección de un generador preentrenado y adaptativo . Para encontrar los filtros que son más relevantes para un tipo específico de conocimiento a través de diferentes imágenes (por ejemplo, características de origen que son incompatibles con el objetivo) y realizar un seguimiento de su transferencia antes y después de la adaptación, etiquetamos los filtros Gs con importancia estimada (a través de IP) y La disección GAN se aplica para visualizar características semánticas correspondientes a los mismos filtros de Gs y Gt.
- Estos experimentos pueden ayudarnos a comprender la transferencia de conocimiento antes y después de la adaptación de grano grueso (visualización de imágenes generadas en el espacio de píxeles) y de grano fino (disección de Gs y Gt en el espacio de filtro). A continuación, discutimos la configuración y los resultados.
4.2 Configuración experimental
4.3 Resultados y análisis


Revelamos que los enfoques existentes de SOTA FSIG que se centran en la preservación del conocimiento fuente conducen a la transferencia de conocimiento incompatible. Más importante aún, la causa raíz de esta transferencia de conocimiento incompatible es que se determina que los filtros menos importantes en Gs son irrelevantes para la adaptación del dominio de destino, y el ajuste fino es insuficiente para eliminar el conocimiento incompatible después de la adaptación. Específicamente, resumimos nuestras observaciones en las Figuras 1 y 2:
- Observación 1 : En la Fig. 1 (c), visualizamos las imágenes generadas por diferentes métodos utilizando una entrada de ruido fijo. Curiosamente, las características que son incompatibles con el dominio de destino se transfieren después de la adaptación utilizando diferentes criterios de conservación del conocimiento, por ejemplo, "árbol en el mar", donde "árbol" es del dominio de la Iglesia, "Gato con gafas", donde "gafas" viene del campo FFHQ. Todas estas características de origen incompatibles debilitan gravemente el realismo de las imágenes de destino generadas. Se pueden hacer observaciones similares en TGAN, un enfoque simple basado en ajustes finos sin preservación explícita del conocimiento. Por el contrario, nuestro método (que analizamos en la Sección 5) puede resolver este problema.
- Observación 2 : En la Fig. 2, diseccionamos y visualizamos las características incompatibles observadas en la Fig. 1 y encontramos sus filtros más relevantes en Gs y Gt. Sorprendentemente, encontramos que los filtros en Gs identificados como menos importantes para el dominio de destino están más correlacionados con características incompatibles transferidas desde la fuente, que es la causa principal de la degradación de la autenticidad de las imágenes generadas. Después de la autoadaptación, el mismo filtro seguirá causando el mismo tipo de funciones incompatibles, y el ajuste fino de las actualizaciones de conocimiento no puede resolver este problema de manera efectiva. Esta observación se vuelve más pronunciada cuando el dominio objetivo se vuelve distante.
5. Enfoque sugerido
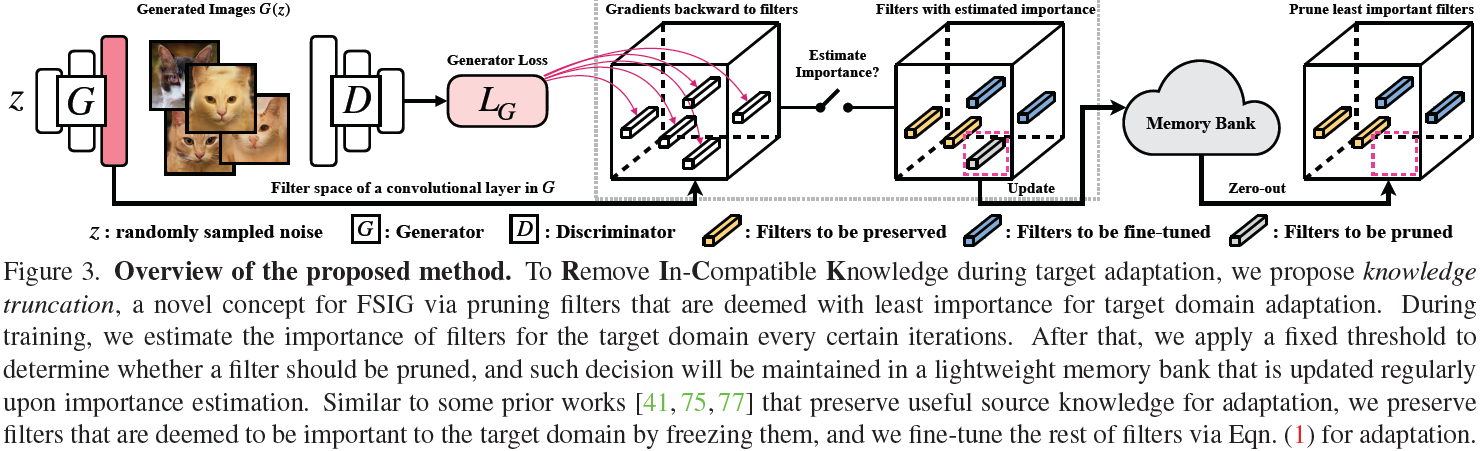
5.1 Truncamiento del conocimiento a través de la poda de red
La poda es una de las herramientas útiles para lograr redes neuronales compactas cuyo rendimiento es comparable a modelos completos más grandes. Los primeros trabajos sobre redes comprimidas se centraron en la aceleración del modelo, la eficiencia de la inferencia y el despliegue, y se centraron en tareas discriminatorias como la clasificación de imágenes y la traducción automática, a menudo mediante la eliminación de las neuronas menos importantes (la definición de importancia puede variar y se analiza en la Sección 5.2) . En comparación con el trabajo anterior de poda de red que persigue la escasez de modelos, nuestro objetivo es mejorar la calidad de las imágenes generadas, especialmente en la tarea FSIG, eliminando los filtros menos importantes asociados con el conocimiento incompatible del dominio de destino.
Nuestro método propuesto consta de dos pasos principales: 1) estimación de la importancia del filtro ligero sobre la marcha durante la adaptación; 2) las acciones del filtro se determinan en función de la importancia estimada. En el paso 1), usamos la información de gradiente durante el proceso de adaptación para evaluar la importancia del filtro para la adaptación objetivo una vez cada cierto número de iteraciones. Luego, en el paso 2), en función de la importancia estimada del filtro, podamos los filtros menos importantes, que se consideran irrelevantes para el dominio de destino, para eliminar el conocimiento incompatible para la adaptación. Mientras tanto, mantenemos filtros de gran importancia para lograr la preservación del conocimiento en FSIG y ajustamos los filtros restantes para adaptar el generador de origen al dominio de destino.
Estimación de la importancia del filtro propuesto . Estimamos la importancia de cada filtro explotando información de gradiente instantáneo durante la adaptación de FSIG. Denotamos el filtro como
![]()
donde k es el tamaño espacial del filtro y c^in es la dimensión (número) del mapa de características de entrada. Usamos Fisher Information (FI) como un estimador de importancia para cada filtro F( W ) (discutido más adelante en la Sección 5.2), que puede brindar información cuantitativa sobre la compatibilidad entre los pesos de filtro y las tareas de FSIG.
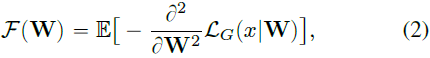
donde L_G es la pérdida de entropía cruzada binaria calculada a partir de la salida del discriminador. x representa un conjunto de imágenes generadas. En la práctica, usamos una aproximación de primer orden de FI para reducir el costo computacional.
Nuestra estimación de la importancia del filtro para la selección de conocimiento es ligera y eficiente: en comparación con los métodos anteriores de SOTA que proponen diferentes criterios de selección de conocimiento (aunque solo se enfocan en la preservación del conocimiento), nuestro método no requiere un modelo externo durante la adaptación. no introduce parámetros de aprendizaje adicionales ni iteraciones de adaptación previa para la estimación de importancia, y se beneficia de la salida de Gt y Dt durante el entrenamiento.
Truncamiento del conocimiento mediante propuestas de poda de filtros . En la Sección 4, hemos mostrado abundante evidencia de que los filtros menos importantes están asociados con características semánticas que son incompatibles con el dominio de destino (por ejemplo, "árboles en el mar" o "estructuras de edificios en el mar"). Es importante destacar que, dados los diferentes criterios de conservación del conocimiento, la actualización del conocimiento basada en el ajuste fino no puede eliminar correctamente el conocimiento incompatible después de la adaptación. Por lo tanto, proponemos un enfoque simple y novedoso para el truncamiento del conocimiento mediante la poda (reducción a cero) de los filtros que son menos importantes para la adaptación.
Específicamente, después de estimar la importancia del filtro en el paso 1), para el i-ésimo filtro W^i en la red, aplicamos un umbral (q%, es decir, el cuantil de su importancia en comparación con el número de todos los filtros) para determinar si W^ debería ser podado:
![]()
Notamos que una vez que se determina que un filtro se va a podar, ya no participa en el entrenamiento/inferencia y no se restaura para el resto de las iteraciones de entrenamiento. El truncamiento del conocimiento se aplica al generador y al discriminador, y usamos umbrales separados para Gt y Dt. Dado que periódicamente estimamos la importancia del filtro durante la adaptación y la propiedad "no recuperable" de los filtros podados, la cantidad de filtros anulados usando la Ecuación 3 se acumulará hasta un cierto valor p% al final de la adaptación.
Similar al trabajo previo que se enfoca en la preservación del conocimiento y propone diferentes criterios de selección de conocimiento, preservamos filtros con alta importancia adaptativa congelándolos durante el entrenamiento. Para el resto de los filtros, simplemente dejamos que se ajusten usando la Ecuación 3. El hecho de que un filtro deba ajustarse o conservarse depende de su importancia para el objetivo. Discutimos el efecto de seleccionar filtros de alta importancia en el material complementario. Dado que estimamos la importancia del filtro varias veces durante la adaptación, la operación en un filtro en particular puede cambiar después de diferentes evaluaciones, a menos que el filtro sea podado y no restaurado.
5.2 Opciones de diseño
Aquí, discutimos las opciones de diseño de nuestro método propuesto y las medidas de importancia adoptadas. Dado que evaluamos dinámicamente la importancia del filtro cada iteración determinada, debemos mantener la operación en cada filtro (que puede ser "mantener", "afinar" o "podar") hasta la siguiente estimación. Para reducir el costo computacional, mantenemos la decisión operativa de cada filtro (obtenida al estimar la importancia del filtro) en un banco de memoria liviano M: para cada filtro W de alta dimensión, solo necesitamos un carácter para registrar en la operación M correspondiente. Por ejemplo, para StyleGAN-V2 utilizado en los experimentos principales, su generador contiene alrededor de 30 millones de parámetros, donde M es una matriz unidimensional con un tamaño de alrededor de 5000.
Al igual que en trabajos anteriores, usamos FI como una medida de importancia para estimar el rendimiento de los parámetros de red (filtros en nuestro trabajo) en la tarea de adaptación. Observamos que existen otras medidas para estimar la importancia de los filtros para la adaptación, como la prominencia de clase o la pérdida de reconstrucción. En el material complementario, llevamos a cabo un estudio y descubrimos empíricamente que podemos lograr un rendimiento similar al de FI. Además, en la Sección 6.2, nos sorprende encontrar que, incluso sin poda (es decir, solo se pueden conservar o ajustar los filtros), nuestro método propuesto todavía puede lograr un rendimiento competitivo en comparación con los métodos SOTA, lo que implica que la eficacia propuesta de la estimador de importancia dinámica de .
6. Experimenta
6.1 Evaluación y comparación del desempeño

resultados cualitativos . En la figura anterior, visualizamos las imágenes generadas por diferentes métodos antes y después de la adaptación para comparar. En cada columna, las imágenes se generan a partir de la misma entrada ruidosa. Usamos FFHQ como dominio de origen. Los bebés y AFHQ-Cat son dominios de destino con diferente proximidad semántica a la fuente. Mostramos que nuestro método propuesto mejora la calidad de las imágenes generadas al eliminar de manera confiable el conocimiento incompatible con el objetivo y al mismo tiempo preservar el conocimiento fuente útil.
Resultados cuantitativos . Teniendo en cuenta que todo el conjunto de datos de destino suele contener alrededor de 5000 imágenes (por ejemplo, AFHQ-Cat), según un trabajo anterior, usamos un generador adaptativo para generar aleatoriamente 5000 imágenes y compararlas con todo el conjunto de datos de destino para calcular el FID. En la Tabla 1, mostramos los resultados completos de FID para seis conjuntos de datos de referencia. En la figura anterior, también calculamos intra-LPIPS como una medida de diversidad sobre 10 muestras objetivo, e informamos FID utilizando el mismo punto de control. Todos estos resultados demuestran la efectividad de nuestro método propuesto.
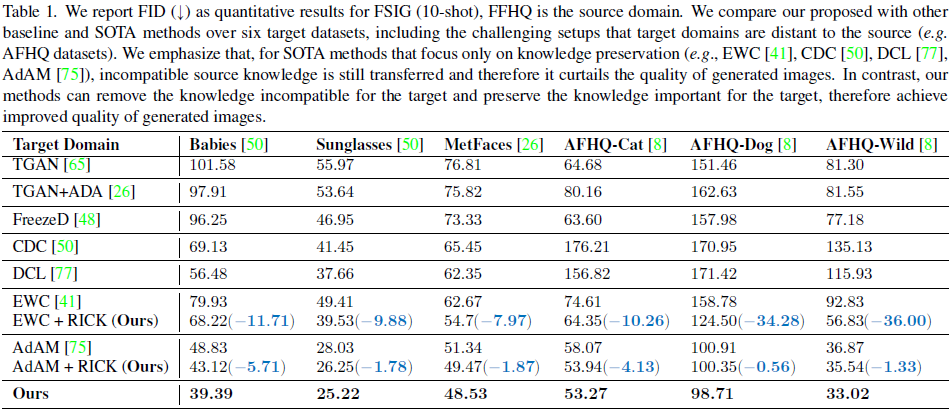
6.2 Discusión
Truncamiento del conocimiento para diferentes métodos . Idealmente, nuestro concepto propuesto de truncamiento del conocimiento FSIG se puede aplicar a diferentes métodos, siempre que podamos estimar la importancia del parámetro (por ejemplo, la importancia del filtro en nuestro método). En la literatura, EWC y AdAM proponen diferentes enfoques para evaluar la importancia de los parámetros: EWC estima directamente la importancia de los parámetros en el conjunto de datos de origen de Gs, mientras que AdAM utiliza un enfoque basado en la modulación para estimar la importancia de los parámetros de Gs en el conjunto de datos de destino. Por lo tanto, en la Tabla 1, también mostramos los resultados de aplicar nuestro truncamiento de conocimiento propuesto a EWC y AdAM. Dado que nuestro método puede eliminar efectivamente el conocimiento incompatible al eliminar los filtros menos importantes, podemos lograr un rendimiento mejorado consistente en diferentes conjuntos de datos.
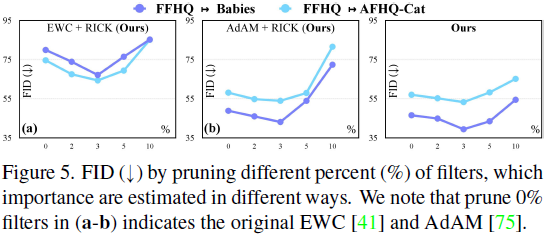
Recorte los filtros con diferentes porcentajes . Estudiamos empíricamente el impacto de podar diferentes porcentajes de filtros. De acuerdo con los resultados en la Fig. 5, podamos diferentes números de filtros en tres métodos diferentes. Idealmente, si podamos más filtros, se eliminarán algunos conocimientos importantes y el rendimiento disminuirá en consecuencia. Por lo tanto, podamos los filtros al 3 % (es decir, p=3 en la Sección 5.1) en diferentes entornos, lo que logra una mejora considerable y estable.
¿Podemos entrenar más tiempo para eliminar el conocimiento incompatible? Idealmente, una forma intuitiva y potencialmente útil de eliminar el conocimiento incompatible es simplemente entrenar para iteraciones más largas. Sin embargo, en el suplemento, llevamos a cabo un estudio y mostramos que, para los métodos FSIG existentes, dado que el conjunto de objetivos contiene solo 10 imágenes de entrenamiento, el entrenamiento para iteraciones más largas sobreajustará el generador y tenderá a replicar una pequeña cantidad de muestras de objetivos para que puede engañar al discriminador. La diversidad de imágenes generadas se reduce significativamente. Por lo tanto, es importante eliminar el conocimiento incompatible antes de que el sobreajuste se vuelva severo.
7. Conclusión
En este trabajo abordamos el problema de la generación de imágenes con pocos disparos (FSIG). Como primera contribución, descubrimos un problema desapercibido de transferencia de conocimiento incompatible en los métodos SOTA existentes, lo que conduce a una pérdida significativa de realismo en las imágenes generadas. Sorprendentemente, encontramos que la causa raíz de esta transferencia de conocimiento incompatible es el filtro considerado menos importante para la adaptación del objetivo, que no puede abordarse adecuadamente mediante métodos SOTA basados en ajustes finos. Por lo tanto, proponemos un nuevo concepto, el truncamiento de conocimiento de FSIG, que tiene como objetivo eliminar el conocimiento incompatible mediante la poda de filtros que son menos importantes para la aptitud. Nuestra estimación de importancia de filtro propuesta explota la información de gradiente de un proceso de entrenamiento dinámico y es computacionalmente ligera. A través de extensos experimentos, mostramos que nuestro método propuesto se puede aplicar a varios entornos de adaptación con diferentes arquitecturas GAN. Logramos un nuevo rendimiento de vanguardia, que incluye imágenes generadas visualmente agradables sin que se transfiera mucho conocimiento incompatible, y resultados cuantitativos mejorados.
Limitaciones y cuestiones éticas . La escala de nuestros experimentos es comparable a trabajos anteriores. No obstante, las extensiones de nuestro enfoque de truncamiento del conocimiento, conjuntos de datos adicionales y modelos generativos más allá de las GAN (por ejemplo, codificadores automáticos variacionales o modelos de difusión) pueden considerarse trabajos futuros. Si los usuarios malintencionados utilizan nuestro método FSIG propuesto, puede tener un impacto social negativo. Sin embargo, nuestro trabajo contribuye a mejorar la comprensión de la generación limitada de imágenes de datos.
apéndice
F. Estudio de ablación: efecto de los filtros de alta importancia
En el artículo principal, destacamos nuestra contribución a la investigación de la transferencia de conocimiento incompatible, su relación con el filtro menos importante y el método propuesto para que FSIG aborde este problema desapercibido. Además del truncamiento del conocimiento, siguiendo el trabajo previo, también preservamos el conocimiento fuente útil para la adaptación. Específicamente, preservamos los filtros considerados importantes para la adaptación del objetivo al congelarlos. Seleccionamos filtros de alta importancia utilizando el cuantil (t_h, por ejemplo, 75%) como umbral. En esta sección, llevamos a cabo un estudio para mostrar la efectividad y el impacto de retener diferentes números de filtros considerados más relevantes para la adaptación objetivo, los resultados se presentan en la Tabla S1. Tenga en cuenta que no eliminamos ningún filtro en este experimento.

Como se muestra en la Tabla S1, los diferentes números de filtros para guardar en realidad mejoran el rendimiento de diferentes maneras. En la práctica, elegimos t_h = 50 % para FFHQ → Bebés y t_h = 70 % para FFHQ → AFHQ-Cat. Esta elección es intuitiva: para los dominios de destino que están semánticamente más cerca de la fuente, retener más conocimiento de la fuente puede mejorar el rendimiento.
H. Estudios de ablación: medidas adicionales de importancia
La importancia de los pesos de evaluación en las tareas generativas sigue sin explorarse. En el documento principal, seguimos algunos trabajos previos y utilizamos la información de Fisher (FI) como medida para la estimación de la importancia y obtenemos un rendimiento superior en diferentes conjuntos de datos (consulte la Tabla 1 en el documento principal). Sin embargo, puede haber diferentes formas de evaluar qué tan bien se dan los pesos obtenidos a la tarea de adaptación. En la literatura, Class Salience (CS) se usa como una herramienta para estimar qué regiones/píxeles de una imagen de entrada dada se destacan para una decisión de clasificación particular, similar a FI que utiliza información de gradiente. Por lo tanto, notamos que CS puede estar relacionado con FI porque ambos usan el conocimiento codificado en el gradiente para la estimación de la importancia del conocimiento.
referencia
Zhao Y, Du C, Abdollahzadeh M, et al. Explorando la transferencia de conocimiento incompatible en la generación de imágenes de pocos disparos [C] // Actas de la Conferencia IEEE/CVF sobre visión por computadora y reconocimiento de patrones. 2023: 7380-7391.
S. Resumen
S.1 Idea principal
Este artículo estudia el problema de transferencia de conocimiento incompatible de la adaptación del dominio de pocos intentos: las entidades en el dominio de origen que no coinciden con el dominio de destino pueden aparecer en el dominio de destino después de la adaptación, lo que afecta la calidad de la adaptación. Los autores abordan este problema mediante la poda de red basada en la importancia del filtro.
S.2 Poda de red
El motivo de la transferencia de conocimiento incompatible son los filtros que no son importantes para la adaptación (extracción de características no importantes), y el problema se puede resolver eliminando estos filtros. Esta operación se divide en dos pasos: 1) Estimar la importancia del filtro para la adaptación 2) Con base en la importancia, realizar las siguientes operaciones:
- Filtros con importancia baja a cero: irrelevantes para el dominio de destino, eliminados para evitar la transferencia de conocimiento incompatible
- Filtros de congelación de gran importancia: para la preservación del conocimiento en la adaptación del dominio de pocos disparos
- Ajuste fino del filtro residual: para la adaptación del dominio