Atribución de imágenes falsas a gans: aprendizaje y análisis de huellas dactilares de gan
Cuenta oficial: EDPJ
Tabla de contenido
3. Aprendizaje de huellas dactilares para el rastreo de imágenes
3.2 Red de análisis de componentes
3.3 Visualización de huellas dactilares
4.2 Existencia y singularidad: ¿Qué parámetros GAN distinguen la procedencia de la imagen?
4.3 Persistencia: ¿Qué componentes de la imagen contienen huellas dactilares de procedencia?
4.5 Visualización de huellas dactilares
S.2 Huella digital del modelo e imagen de la huella digital
0. Resumen
Los avances recientes en las redes antagónicas generativas (GAN) han logrado un éxito creciente en la generación de imágenes realistas. Pero también plantean desafíos para la identificación visual y la procedencia del modelo. Presentamos el primer estudio de atribución de imágenes mediante el aprendizaje de huellas dactilares GAN y su uso para clasificar imágenes como reales o generadas por GAN. Para las imágenes generadas por la GAN, identificamos aún más sus fuentes. Nuestros experimentos muestran que: (1) las GAN tienen huellas dactilares de modelo únicas y dejan huellas dactilares estables en las imágenes generadas, lo que respalda la atribución de imágenes; (2) incluso las pequeñas diferencias en el entrenamiento de GAN pueden dar lugar a huellas dactilares diferentes, lo que permite la autenticación del modelo de grano fino; (3) las huellas dactilares persisten a través de diferentes frecuencias de imagen y bloques y son inmunes a los artefactos GAN; (4) el ajuste fino de huellas dactilares es efectivamente inmune a cinco tipos de perturbaciones adversarias de imágenes; (5) La comparación también muestra que nuestras huellas dactilares aprendidas superan consistentemente varias líneas de base en varios ajustes
1. Introducción
El éxito de las GAN ha planteado dos desafíos a la comunidad de la visión: la identificación visual y la protección de la propiedad intelectual.
El desafío GAN para la discriminación visual . Existen preocupaciones generalizadas sobre el impacto de la tecnología cuando se usa de manera maliciosa. El problema también está recibiendo una atención pública cada vez mayor en términos de seguridad visual, consecuencias destructivas legales, políticas y para toda la sociedad. Por lo tanto, es crucial estudiar la discriminación visual efectiva contra las amenazas GAN.
Si bien las técnicas forenses visuales de última generación recientes han demostrado resultados impresionantes en la detección de medios visuales falsos, solo se enfocan en inconsistencias semánticas, físicas o estadísticas en escenarios de falsificación específicos, como copiar manipulaciones de movimientos o cambiar caras. Las imágenes discriminatorias generadas por GAN muestran una buena precisión, pero cada método solo puede operar en una arquitectura GAN, opera mediante la identificación de sus artefactos únicos y los resultados se deterioran cuando cambia la arquitectura GAN. Si las GAN dejan marcas estables comunes sigue siendo una pregunta abierta.
Si las GAN dejan marcas estables comunes a las imágenes que generan sigue siendo una pregunta abierta. Esto nos motiva a investigar una representación de características efectiva para distinguir las imágenes generadas por GAN de las reales.
Desafíos de GAN para la protección de la propiedad intelectual . Al igual que otras aplicaciones exitosas de técnicas de aprendizaje profundo en reconocimiento de imágenes o procesamiento de lenguaje natural, crear productos basados en GAN no es una tarea fácil. Requiere grandes cantidades de datos de entrenamiento, potentes recursos informáticos, experiencia significativa en aprendizaje automático y extensas iteraciones de prueba y error para determinar la arquitectura de modelo óptima y sus hiperparámetros de modelo. Dado que los servicios GAN están ampliamente desplegados y tienen potencial comercial, serán cada vez más vulnerables a los piratas. Este tipo de plagio de derechos de autor puede dañar los derechos de propiedad intelectual de los propietarios de modelos y quitarles su cuota de mercado futura. Por lo tanto, los métodos para rastrear el origen de las imágenes generadas por GAN son muy deseables para la protección de la propiedad intelectual.
Dado el nivel de realismo que ha alcanzado la tecnología GAN en la actualidad, la atribución a través de la inspección manual ya no es factible (consulte el diagrama híbrido en la Figura 4). Las técnicas de identificación digital de última generación se pueden dividir en dos categorías: marca de agua digital y detección de huella digital. Ninguno de ellos es adecuado para la trazabilidad de GAN. El trabajo anterior sobre marcas de agua de redes neuronales profundas se basa en esquemas de seguridad incorporados durante el entrenamiento del modelo de "caja blanca", lo que requiere entradas de control y no es práctico cuando solo se puede acceder a las imágenes generadas por GAN en un escenario de "caja negra". a las huellas dactilares del dispositivo o las huellas dactilares de posprocesamiento en la cámara, que no se pueden adaptar fácilmente a las imágenes generadas por GAN. Esto nos motiva a estudiar las huellas dactilares GAN que rastrean el origen de diferentes imágenes generadas por GAN.
Presentamos el primer estudio para abordar estos dos desafíos de GAN simultáneamente al aprender las huellas digitales de GAN para la atribución de imágenes: presentamos las huellas digitales de GAN y las usamos para clasificar las imágenes como reales o generadas por GAN. Para las imágenes generadas por la GAN, identificamos aún más sus fuentes. Resolvemos este problema entrenando un clasificador de red neuronal y prediciendo el origen de la imagen. Nuestros experimentos muestran que GAN lleva huellas dactilares de diferentes modelos y deja huellas dactilares estables en las imágenes que genera, lo que respalda la atribución de imágenes.

Resumimos nuestra contribución como prueba de la existencia, singularidad, persistencia, inmunidad y visualización de huellas dactilares GAN. Resolvemos los siguientes problemas:
- Existencia y singularidad: ¿Qué parámetros GAN distinguen las propiedades de la imagen? Mostramos experimentos sobre parámetros GAN, incluida la arquitectura, los datos de entrenamiento y las semillas de inicialización aleatoria. Descubrimos que las diferencias en cualquiera de estos parámetros produjeron huellas digitales GAN únicas para la atribución de imágenes. Consulte la Figura 1, Secciones 3.1 y 4.2.
- Persistencia: ¿Qué componentes de la imagen contienen huellas dactilares de procedencia? Estudiamos componentes de imagen de diferentes bandas de frecuencia y diferentes tamaños de bloque. Para eliminar posibles sesgos en los componentes de artefactos de las GAN, aplicamos una métrica de similitud perceptual para extraer subconjuntos sin artefactos para la evaluación de procedencia. Encontramos que las huellas dactilares de GAN son persistentes en todas las frecuencias y tamaños de parche y no se ven afectadas por artefactos. Consulte las Secciones 3.2 y 4.3.
- Inmunidad: ¿Qué tan robusta es la atribución de los ataques de perturbación de imagen y qué tan efectiva es la defensa? Investigamos ataques comunes destinados a romper huellas dactilares de imágenes. Incluyen ruido, desenfoque, recorte, compresión JPEG, reiluminación y combinaciones aleatorias de ellos. También nos defendemos contra tales ataques ajustando nuestro clasificador de procedencia. Consulte la Sección 4.4.
- Visualización: ¿Cómo exponer las huellas dactilares de GAN? Proponemos una variante de clasificador alternativa para visualizar explícitamente las huellas dactilares de GAN en el dominio de la imagen para explicar mejor la eficacia de la procedencia. Consulte las Secciones 3.3 y 4.5.
- Comparación con la línea de base. En términos de precisión de procedencia, nuestro método supera constantemente a tres métodos de referencia (incluido uno reciente) en ambos conjuntos de datos en diversas condiciones experimentales. En términos de representación de características, nuestras huellas dactilares exhiben una discriminabilidad superior entre las fuentes de imágenes en comparación con las características iniciales.
2. Trabajo relacionado
Identificación visual (Visual forenses) . La autenticación visual tiene como objetivo detectar artefactos estadísticos o basados en la física y luego reconocer la autenticidad de los medios visuales en ausencia de evidencia de los mecanismos de seguridad integrados.
- Un ejemplo es un enfoque basado en estegoanálisis que utiliza características hechas a mano junto con máquinas de vectores de soporte lineal para detectar falsificaciones.
- Los métodos recientes basados en CNN pueden aprender características profundas y mejorar aún más el rendimiento de detección de manipulación de imágenes o videos.
- R¨ossler et al., presentan un conjunto de datos de manipulación facial a gran escala para comparar las tareas de segmentación y clasificación discriminatoria y demostrar un rendimiento superior cuando se utilizan conocimientos adicionales específicos del dominio.
- Para la discriminación de imágenes generadas por GAN, algunos trabajos existentes muestran una buena precisión. Sin embargo, cada método solo considera una arquitectura GAN y los resultados no se pueden generalizar entre arquitecturas.
huella digital Las técnicas anteriores de toma de huellas dactilares digitales se han centrado en detectar características artesanales de huellas dactilares de dispositivos o huellas dactilares de posprocesamiento. La toma de huellas dactilares del dispositivo se basa en el hecho de que, debido a defectos de fabricación, los dispositivos individuales dejan marcas únicas y estables, patrones de falta de uniformidad de fotorrespuesta (PRNU), en cada imagen adquirida. Del mismo modo, las huellas dactilares de posprocesamiento provienen de suites específicas de posprocesamiento en la cámara (demostración, compresión, etc.) durante la adquisición de cada imagen. Recientemente, Marra et al., visualizaron huellas dactilares de GAN basadas en PRNU y demostraron su aplicación para la identificación de fuentes de GAN. Reemplazamos su formulación de huellas dactilares hecha a mano con una basada en el aprendizaje que separa las huellas dactilares del modelo de las huellas dactilares de la imagen y demuestra un rendimiento superior en diversas condiciones experimentales.
Marca de agua digital . La marca de agua digital es una técnica forense complementaria para la autenticación de imágenes. Se trata de incrustar marcas de agua artificiales en las imágenes. Se puede usar para revelar el origen y la propiedad de la imagen para proteger sus derechos de autor. La investigación ha demostrado que las redes neuronales también pueden tener marcas de agua activas durante el entrenamiento. En dichos modelos, los patrones de características se pueden incorporar a las representaciones aprendidas, pero existe un equilibrio entre la precisión de la marca de agua y el rendimiento bruto. Sin embargo, dicha marca de agua no se ha estudiado para las GAN. Por el contrario, aprovechamos las huellas dactilares intrínsecas para la procedencia de la imagen sin ninguna carga de incrustación adicional ni degradación de la calidad.
3. Aprendizaje de huellas dactilares para el rastreo de imágenes
Inspirándonos en trabajos anteriores sobre huellas dactilares digitales, presentamos los conceptos de huellas dactilares modelo GAN y huellas dactilares de imagen. Ambos se aprenden simultáneamente a partir de la tarea de atribución de imágenes.
Modelo de huellas dactilares . Cada modelo GAN tiene muchos parámetros: distribución de conjuntos de datos de entrenamiento, arquitectura de red, diseño de pérdidas, estrategia de optimización y configuración de hiperparámetros. Debido a la no convexidad de la función objetivo y la inestabilidad del equilibrio contradictorio entre el generador y el discriminador en las GAN, los valores de los pesos del modelo son sensibles a su inicialización aleatoria y no convergen al mismo valor durante cada sesión de entrenamiento. Esto muestra que aunque dos modelos GAN bien entrenados pueden funcionar de la misma manera, generan imágenes de alta calidad de manera diferente. Esto indica la existencia y singularidad de las huellas dactilares GAN. Definimos la huella digital del modelo de cada instancia de GAN como un vector de referencia para que siempre interactúe con todas sus imágenes generadas. En casos especialmente diseñados, la huella del modelo puede ser una imagen RGB del mismo tamaño que la imagen que genera. Consulte la Sección 3.3.
Imagen de huella dactilar . Las imágenes generadas por GAN son el resultado de una gran cantidad de filtros fijos y procesos no lineales que generan patrones comunes y estables en la misma instancia de GAN, pero son diferentes en diferentes instancias de GAN. Esto indica la presencia de huellas digitales de imágenes y sus fuentes GAN. Introducimos la huella digital de cada imagen como un vector de características codificado a partir de esa imagen. En el caso de un diseño específico, la huella digital de la imagen puede ser una imagen RGB del mismo tamaño que la imagen original. Consulte la Sección 3.3.
3.1 Red de trazabilidad
Similar a la tarea de atribución del autor en el procesamiento del lenguaje natural, entrenamos un clasificador de atribución que puede predecir el origen de una imagen: imagen real o de un modelo GAN.
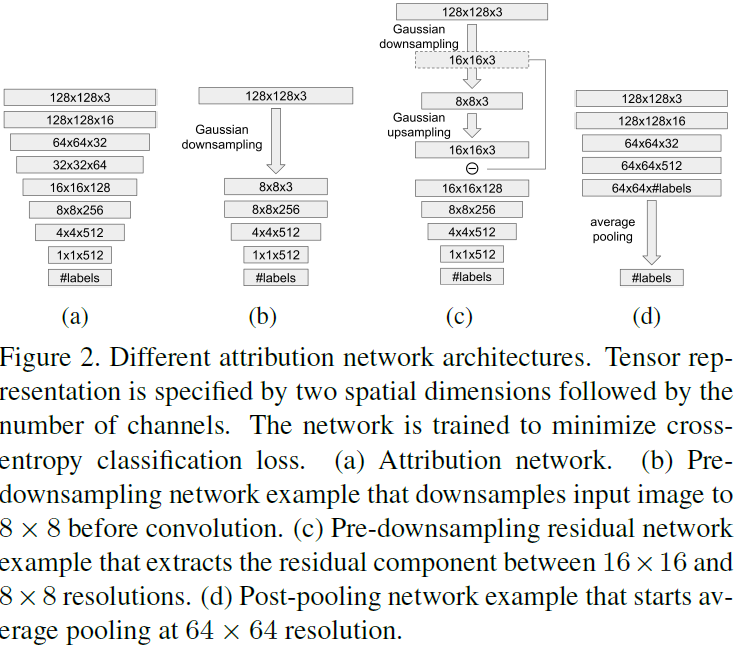
Hacemos esto utilizando una red neuronal convolucional profunda supervisada por pares de fuentes de imágenes {(I, y)}, donde I se muestrea del conjunto de imágenes e y ∈ Y es la etiqueta de verdad de la fuente que pertenece a un conjunto finito. Esta colección consta de instancias GAN preentrenadas e imágenes reales. La Figura 2(a) muestra una descripción general de nuestra red de procedencia.
Representamos implícitamente las huellas dactilares de la imagen como características del clasificador final (tensor 1 × 1 × 512 antes de la capa final completamente conectada), y las huellas dactilares del modelo GAN como parámetros de clasificador correspondientes (tensor 1 × 1 × 512 antes de la capa final completamente conectada). Tensor de peso 512).
¿Por qué es necesario usar un clasificador externo de este tipo cuando el entrenamiento GAN ya proporciona un discriminador? El discriminador aprende un hiperplano en su propio espacio de incrustación para distinguir las imágenes generadas de las imágenes reales. Los diferentes espacios de incrustación no están alineados. Por el contrario, el clasificador propuesto tiene que aprender un espacio de incrustación unificado para distinguir las imágenes generadas de diferentes instancias de GAN o imágenes reales.
Tenga en cuenta que nuestra motivación para estudiar GAN de "caja blanca" sujetas a parámetros conocidos es verificar la trazabilidad de diferentes dimensiones de parámetros GAN. De hecho, nuestro enfoque también es aplicable a los servicios API de GAN de "caja negra". La única supervisión requerida es la etiqueta de origen de la imagen. Simplemente podemos consultar diferentes servicios, recopilar las imágenes que generan y etiquetarlas con el índice de servicio. Nuestro clasificador probará la autenticidad de una imagen al predecir si es una muestra del servicio deseado. También probamos la autenticidad del servicio verificando que la mayoría de las imágenes generadas tengan las predicciones de origen deseadas.
3.2 Red de análisis de componentes
Para analizar qué componentes de la imagen contienen huellas dactilares, proponemos tres variantes de la red.
Red de pre-downsampling . Proponemos probar si las huellas dactilares y las propiedades se pueden derivar de diferentes bandas de frecuencia. Investigamos el rendimiento de trazabilidad de los factores de reducción de muestreo. La Figura 2(b) muestra una arquitectura de ejemplo para extraer bandas de baja frecuencia. Reemplazamos capas convolucionales entrenables con capas de reducción de muestreo gaussianas en la entrada y controlamos sistemáticamente la resolución en la que detenemos este reemplazo.
Red residual pre-reducida . Complementariamente a la extracción de bandas de baja frecuencia, la Figura 2(c) muestra una arquitectura de ejemplo que extrae bandas de alta frecuencia residuales entre una resolución y su resolución reducida a 2x. Es una reminiscencia de la pirámide de Laplace. Variamos sistemáticamente la resolución a la que se extraen dichos residuos.
Red de agrupación trasera . Recomendamos probar si las huellas dactilares y la procedencia se pueden exportar localmente en función de las estadísticas de parches. Investigamos la trazabilidad correspondiente al tamaño del parche. La figura 2(d) muestra una arquitectura de ejemplo. Inspirándonos en PatchGAN, consideramos un "píxel" en un tensor neuronal como una representación característica del parche de imagen local cubierto por el campo receptivo de ese "píxel". Por lo tanto, las operaciones posteriores a la agrupación son de gran importancia para las estadísticas neuronales basadas en parches. La agrupación posterior anterior corresponde a tamaños de parche más pequeños. Variamos sistemáticamente la resolución del tensor en el que comenzamos esta agrupación para cambiar entre estadísticas de parches más locales y más globales.
3.3 Visualización de huellas dactilares
Como alternativa a nuestra red de procedencia en la Sección 3.1, donde las huellas dactilares se representan implícitamente en el dominio de características, describimos un modelo similar en espíritu a Marra et al., que las representa explícitamente en el dominio de la imagen. Pero en comparación con su representación basada en PRNU hecha a mano, modificamos nuestra arquitectura de red de procedencia y aprendemos imágenes de huellas dactilares a partir de pares de fuentes de imágenes ({I, y}). También desacoplamos la representación de la huella digital del modelo de la huella digital de la imagen. La figura 3 muestra el modelo de visualización de huellas dactilares.
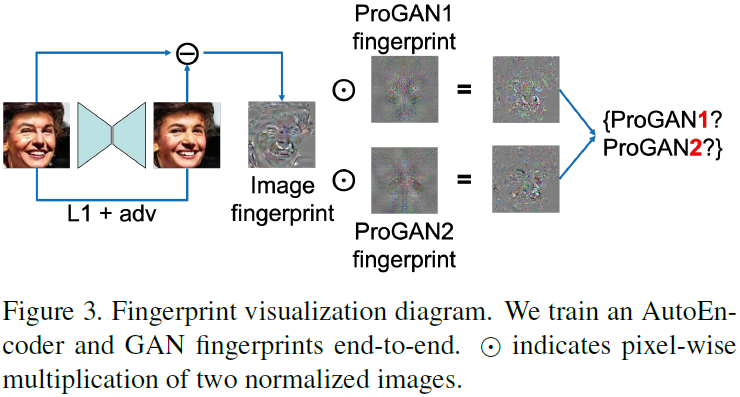
De manera abstracta, aprendemos un mapeo de una imagen de entrada a su imagen de huella digital. Pero en ausencia de supervisión de huellas dactilares, elegimos usar codificadores automáticos para construir mapas basados en la tarea de reconstrucción. Luego definimos los residuos de reconstrucción como huellas dactilares de imagen. Aprendemos simultáneamente una huella digital modelo para cada fuente (cada instancia de GAN más una imagen real), de modo que el índice de correlación entre una huella digital de imagen y cada huella digital modelo sirve como logit softmax para la clasificación.
Matemáticamente, dado un par de fuentes de imágenes (I, y), donde y ∈ Y pertenece a un conjunto finito Y de instancias de GAN más imágenes reales, formulamos un mapa de reconstrucción R de I a R(I). Realizamos una reconstrucción basada en una pérdida L1 de píxeles más una pérdida adversaria:
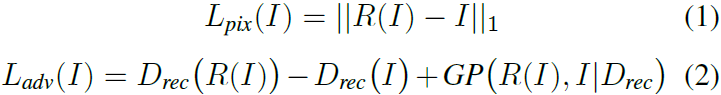
donde D_rec es el discriminador para entrenamiento adversario, y GP(·) es el término de regularización de penalización por gradiente.
Luego definimos explícitamente las huellas dactilares de la imagen como residuos de reconstrucción.
![]()
Además, definimos explícitamente la huella digital del modelo F^y_mod como un parámetro libremente entrenable del mismo tamaño que F^I_im, de modo que el índice de correlación entre F^I_im y F^y_mod
![]()
Maximizar en Y. Esto se puede formular como el logit softmax de la pérdida de clasificación de entropía cruzada supervisada por las etiquetas de verdad del terreno fuente:
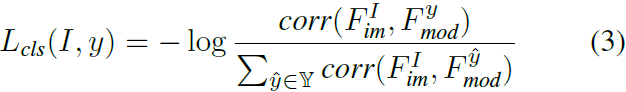
![]()
ˆA y ˆB son versiones de media cero, norma unitaria y vectorizadas de las imágenes A y B, mientras que ⊙ es la operación del producto interno.
Nuestro objetivo final de entrenamiento es
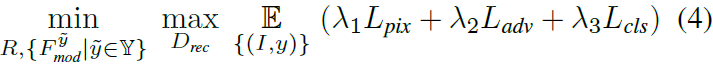
Entre ellos, λ1 = 20,0, λ2 = 0,1 y λ3 = 1,0 se utilizan para equilibrar la magnitud de cada elemento de pérdida, que no es sensible al conjunto de datos y es fijo.
Tenga en cuenta que esta variante de red se utiliza para visualizar y explicar mejor la eficacia de la atribución de imágenes. Sin embargo, introduce una complejidad de entrenamiento adicional y, por lo tanto, no se usa si solo nos enfocamos en la procedencia.
4. Experimenta
4.1 Configuración
conjunto de datos Usamos el conjunto de datos de rostros de CelebA y el conjunto de datos de escena de dormitorio de LSUN, los cuales contienen 20 000 imágenes RGB del mundo real.
modelo GAN . Consideramos cuatro arquitecturas GAN de última generación: ProGAN, SNGAN, Cramer-GAN y MMDGAN. Cada modelo se entrena desde cero usando la configuración predeterminada, excepto que fijamos el número de épocas de entrenamiento en 240 y el tamaño de salida del generador en 128×128×3.
método de línea de base . Dado un conjunto de datos del mundo real y cuatro modelos GAN preentrenados, comparamos con tres métodos de clasificación de referencia: k-vecinos más cercanos (kNN) en píxeles sin procesar, Eigenface y un método reciente de huellas dactilares basado en PRNU de Marra et al.
evaluación _ Utilizamos la precisión de la clasificación para evaluar el rendimiento de la atribución de imágenes.
Además, utilizamos la relación entre la distancia de Fr´echet entre clases y dentro de la clase, denominada relación FD, para evaluar la distinguibilidad de las representaciones de características entre clases. Cuanto mayor sea la relación, más distinguible será la representación de características entre las fuentes. Consulte el material complementario para obtener más detalles. Comparamos las características de la huella dactilar con las características iniciales de la imagen. El FD de las características iniciales (características de inicio) también se conoce como el FID de la evaluación GAN. Por lo tanto, la relación FD de las características iniciales se puede utilizar como referencia para mostrar lo difícil que es certificar imágenes generadas por GAN de alta calidad de forma manual o sin aprendizaje de huellas dactilares.
4.2 Existencia y singularidad: ¿Qué parámetros GAN distinguen la procedencia de la imagen?
Consideramos la arquitectura GAN, el conjunto de entrenamiento y la semilla de inicialización por separado al variar un tipo de parámetro y mantener los otros dos constantes.
diferentes arquitecturas . Primero, entrenamos ProGAN, SNGAN, CramerGAN y MMDGAN por separado usando todas las imágenes reales. Para las tareas de clasificación, configuramos conjuntos de entrenamiento y prueba de 5 categorías: {real, Pro-GAN, SNGAN, CramerGAN, MMDGAN}. Recolectamos aleatoriamente 100 000 imágenes de cada fuente para entrenamiento de clasificación y otras 10 000 imágenes de cada fuente para pruebas. Mostramos muestras de rostros de cada fuente en la Figura 4 y muestras de dormitorios en el material complementario.

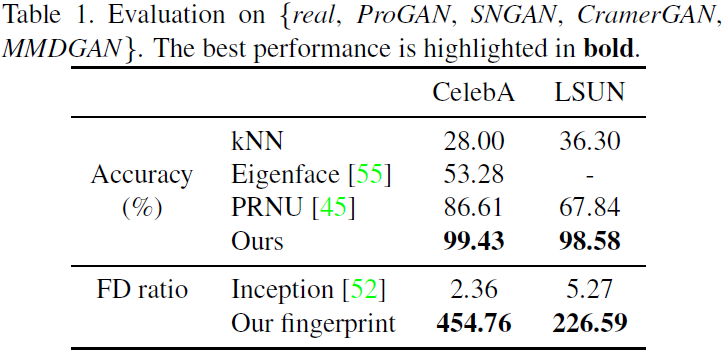
La Tabla 1 muestra que podemos distinguir efectivamente las imágenes generadas por GAN de las imágenes reales y atribuir las imágenes generadas a sus fuentes, simplemente usando un clasificador CNN normal. Las huellas dactilares únicas que distinguen las arquitecturas GAN existen en las imágenes, aunque es mucho más difícil rastrear estas imágenes manualmente o mediante características iniciales.
Diferentes conjuntos de entrenamiento GAN . Reducimos aún más el alcance de nuestra investigación sobre el conjunto de entrenamiento GAN. A partir de ahora, solo nos centraremos en ProGAN más conjuntos de datos reales. Primero seleccionamos aleatoriamente un subconjunto de verdad de campo de 100,000 imágenes, denotado real_subset_diff_0. Luego seleccionamos aleatoriamente los otros 10 subconjuntos reales que también contienen 100 000 imágenes, denominados real_subset_diff_#i, donde i ∈ {1, 10, 100, 1000, 10000, 20000, 40000, 60000, 80000, 100000} denota el número de imágenes que no son del subconjunto base. Recopilamos dicho conjunto de datos para explorar la relación entre el rendimiento de procedencia y la superposición del conjunto de entrenamiento GAN.
Para cada real_subset_diff_#i, entrenamos por separado el modelo Pro-GAN y consultamos 100 000 imágenes para el entrenamiento del clasificador y otras 10 000 imágenes para las pruebas, etiquetadas como ProGAN_subset_diff_#i. En la configuración de {real, Pro-GAN_subset_diff_#i}, mostramos la evaluación del rendimiento en la Tabla 2.
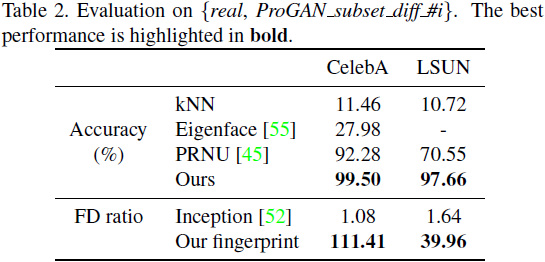
Sorprendentemente, encontramos que el rendimiento de procedencia sigue siendo igualmente alto independientemente de la cantidad de superposición del conjunto de entrenamiento GAN. Diferentes conjuntos de entrenamiento de GAN incluso para una sola imagen pueden dar como resultado diferentes instancias de GAN. Esto sugiere que los desajustes de una sola imagen durante el entrenamiento de GAN pueden conducir a diferentes pasos de optimización en una iteración y, en última instancia, a diferentes huellas dactilares. Esto nos motiva a investigar el rendimiento de procedencia entre instancias de GAN entrenadas con la misma arquitectura y conjunto de datos pero con diferentes semillas de inicialización aleatoria.
Diferentes semillas de inicialización . A continuación, investigamos el efecto de la inicialización del entrenamiento GAN en la procedencia de la imagen. Entrenamos 10 instancias de ProGAN utilizando todo el conjunto de datos reales y diferentes semillas de inicialización. Tomamos muestras de 100 000 imágenes para el entrenamiento del clasificador y otras 10 000 imágenes para pruebas. En esta configuración de {real, Pro-GAN_seed_v#i} donde i ∈ {1, ..., 10}, mostramos la evaluación del desempeño en la Tabla 3.
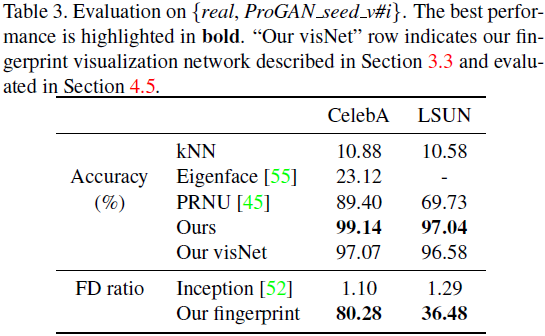
Llegamos a la conclusión de que son las diferencias en la optimización (por ejemplo, la aleatoriedad diferente) las que conducen a huellas dactilares rastreables. Para validar nuestra configuración experimental, realizamos una verificación de cordura. Por ejemplo, dos instancias ProGAN idénticas entrenadas con las mismas semillas siguen siendo indistinguibles y conducen a un rendimiento de procedencia estocástica.
4.3 Persistencia: ¿Qué componentes de la imagen contienen huellas dactilares de procedencia?
Exploramos sistemáticamente el rendimiento de la atribución de los componentes de la imagen correspondientes a diferentes bandas de frecuencia o con diferentes tamaños de parche. También investigamos posibles sesgos de rendimiento de los artefactos GAN.
diferentes frecuencias . Investigamos si las imágenes de banda limitada tienen huellas dactilares de atribución válidas. Aplicamos la red de pre-downsampling propuesta y la red residual de pre-downsampling para la atribución de imágenes, respectivamente. Dada la configuración de {real, Pro-GAN_seed_v#i}, la Tabla 4 muestra las precisiones de clasificación correspondientes a los factores de reducción de muestreo.
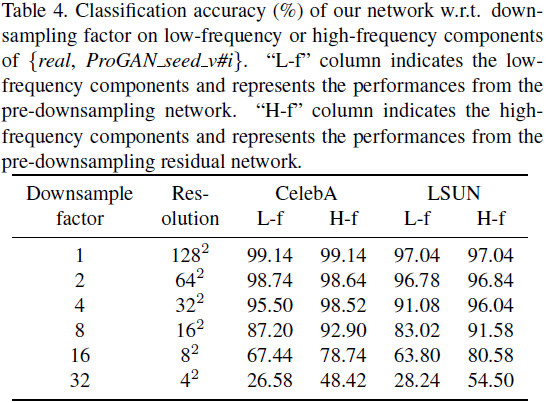
llegamos a la conclusión:
- Una banda de frecuencia más amplia transporta más información de huellas dactilares para la trazabilidad de la imagen.
- Los componentes de baja y alta frecuencia (incluso con una resolución de 8 × 8) por sí solos llevan huellas dactilares válidas y conducen a un rendimiento de atribución mejor que el aleatorio
- Con la misma resolución, los componentes de alta frecuencia transportan más información de huellas dactilares que los componentes de baja frecuencia.
Diferentes tamaños de parches locales . También investigamos si los parches de imágenes locales tienen huellas dactilares válidas para su procedencia. Aplicamos una red posterior a la puesta en común para la procedencia de la imagen. Dada la configuración de {real, Pro-GAN_seed_v#i}, la Tabla 5 muestra la precisión de clasificación correspondiente al tamaño del parche.
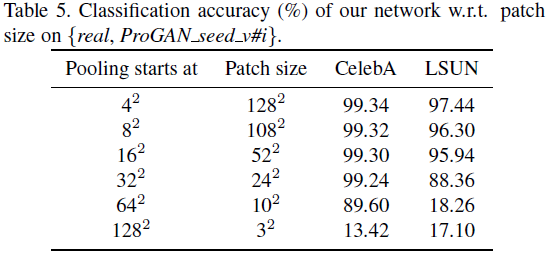
Concluimos que para el conjunto de datos faciales de CelebA, un parche de tamaño 24×24 o más grande contiene suficiente información de huellas dactilares para la atribución de imágenes sin deterioro; para LSUN, un parche de tamaño 52×52 o más grande puede contener suficientes huellas dactilares.
No hay conjuntos de sombras espurias . A lo largo de nuestros experimentos, los métodos GAN de última generación pueden generar imágenes de alta calidad, pero también generan artefactos notables en algunos casos. Existe la preocupación de que estos artefactos puedan sesgar la trazabilidad. Para solucionar este problema, usamos la similitud perceptiva para medir la similitud del vecino más cercano entre cada imagen generada por prueba y el conjunto de datos del mundo real, y luego seleccionamos el 10 % superior para la procedencia. Comparamos muestras de rostros entre grupos no seleccionados y seleccionados en la Figura 5, y comparamos muestras de dormitorios en Material complementario. Notamos que esta métrica es visualmente efectiva en la selección de muestras de mayor calidad y menos artefactos.

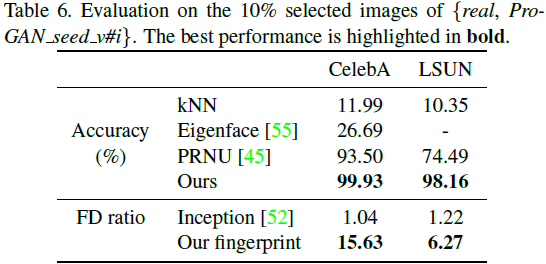
Dada una configuración elegida del 10 % de {real, Pro-GAN_seed_v#i}, mostramos la evaluación del rendimiento en la Tabla 6. En comparación con la Tabla 3, todas las mediciones de la relación FD continuaron disminuyendo. Esto sugiere que nuestra selección también acerca la distribución de imágenes de diferentes instancias de GAN al conjunto de datos real y, por lo tanto, entre sí. Esto hace que la tarea de trazabilidad sea más desafiante. De manera alentadora, nuestro clasificador, entrenado previamente en imágenes no seleccionadas, puede funcionar igualmente bien en imágenes seleccionadas de alta calidad y, por lo tanto, no sufre de artefactos.
4.4 Inmunidad: ¿Qué tan robusta es la trazabilidad de los ataques de perturbación de imagen y qué tan efectiva es la defensa?
ataque _ Aplicamos cinco tipos de ataques para perturbar las imágenes de prueba: ruido, desenfoque, recorte, compresión JPEG, reiluminación y combinaciones aleatorias de ellos. Su propósito es confundir la red de trazabilidad al destruir las huellas dactilares de las imágenes. En la Figura 6 se muestra un ejemplo de perturbación de la imagen de la cara. En el Material complementario se muestran ejemplos de imágenes de dormitorios.

El ruido agrega ruido gaussiano independiente e idénticamente distribuido a la imagen de prueba. La varianza gaussiana se extrae aleatoriamente de U[5.0, 20.0]. Blur realiza un filtrado gaussiano en la imagen de prueba con un tamaño de núcleo elegido aleatoriamente entre {1, 3, 5, 7, 9}. La imagen de prueba se recorta utilizando un desplazamiento aleatorio entre el 5 % y el 20 % de la longitud lateral de la imagen y luego se redimensiona al valor original. Compresión JPEG La compresión JPEG se realiza con factores de calidad muestreados aleatoriamente de U[10, 75]. Relighting usa SfSNet para reemplazar la condición de iluminación de la imagen actual con otra condición aleatoria del conjunto de datos de iluminación. La combinación realiza cada ataque con un 50 % de probabilidad en el orden de reiluminación, recorte, desenfoque, compresión JPEG y ruido.

Dada la imagen perturbada y la configuración de {real, Pro-GAN_Seed_v#i}, mostramos el rendimiento del clasificador preentrenado en la columna "Akt" de la Tabla 7 y la Tabla 8. Todo el rendimiento se ve degradado por el ataque. En detalle, el clasificador es completamente invulnerable al ruido ya los ataques de compresión JPEG. Todavía funciona mejor que el aleatorio frente a los otros cuatro tipos de ataques. El ataque de reencendido es el menos efectivo, ya que solo perturba componentes de imagen de baja frecuencia. Una huella dactilar con pocos cambios en los componentes de alta frecuencia permite una trazabilidad razonable.
defensa _ Para hacer que nuestro clasificador sea inmune a los ataques, ajustamos el clasificador bajo el supuesto de categorías de ataque conocidas. Dada la imagen perturbada y la configuración de {real, ProGAN_seed_v#i}, mostramos el rendimiento del clasificador ajustado en la Tabla 7 y la Tabla 8 en la columna "Dfs". Resulta que el clasificador inmunológico recupera completamente el rendimiento en los ataques de desenfoque, recorte y reencendido, y recupera parcialmente el rendimiento en otras perturbaciones. Sin embargo, debido a su mayor complejidad, la recuperación de los ataques combinatorios es mínima. Además, nuestro método supera sistemáticamente al de Marra et al. Bajo cada ataque después de la inmunización, mientras que su ataque no se beneficia efectivamente de esta inmunidad.
4.5 Visualización de huellas dactilares
Dada una configuración de {real, ProGAN_Seed_v#i}, también podemos aplicar la Red de visualización de huellas dactilares (Sección 3.3) a las imágenes de procedencia. Mostramos el rendimiento de la procedencia en la fila "Nuestra visNet" de la Tabla 3, que es comparable a la del modelo de procedencia. Figura 7 Visualización de huellas dactilares faciales. Las huellas dactilares de los dormitorios se muestran en el material complementario. Resulta que una huella digital de imagen solo maximiza la respuesta a su propia huella digital modelo, lo que admite una atribución eficiente. Para rastrear el origen de las imágenes del mundo real, es suficiente que la huella dactilar se enfoque solo en los ojos. Para rastrear el origen de otras imágenes, las huellas dactilares también tienen en cuenta las señales en el fondo, que son más variables que las caras en primer plano y más difíciles de aproximar de manera realista para las GAN.

5. Conclusión
Presentamos el primer estudio de aprendizaje de huellas dactilares GAN para la atribución de imágenes. Nuestros experimentos muestran que incluso las pequeñas diferencias en el entrenamiento de GAN (como las diferencias en la inicialización) dejan una huella distintiva que a menudo está presente en todas las imágenes generadas. Esto hace posible la trazabilidad de imágenes de grano fino y la trazabilidad de modelos. Más alentador, las huellas dactilares son persistentes a través de diferentes frecuencias y diferentes tamaños de bloque, y no sufren artefactos GAN. Aunque las huellas dactilares pueden deteriorarse por múltiples ataques de perturbación de imagen, son efectivamente inmunes a ellos con un simple ajuste fino. La comparación también muestra que, en diversas condiciones, nuestras huellas dactilares aprendidas superan consistentemente las líneas de base recientes en la procedencia y superan a las características iniciales en la distinguibilidad de origen cruzado.
referencia
Yu N, Davis LS, Fritz M. Atribución de imágenes falsas a gans: aprendizaje y análisis de huellas dactilares de gan[C]//Actas de la conferencia internacional IEEE/CVF sobre visión artificial. 2019: 7556-7566.
S. Resumen
S.1 Idea principal
GAN tiene una huella digital de modelo única y deja una huella digital estable (huella digital de imagen) en la imagen generada, lo que respalda la trazabilidad de la imagen. Incluso las pequeñas diferencias en el entrenamiento de GAN pueden dar lugar a diferentes huellas dactilares, lo que permite una autenticación detallada del modelo.
S.2 Huella digital del modelo e imagen de la huella digital
Huella digital del modelo : cada modelo GAN tiene muchos parámetros: distribución de conjuntos de datos de entrenamiento, arquitectura de red, diseño de pérdidas, estrategia de optimización y configuración de hiperparámetros. Debido a la no convexidad de la función objetivo y la inestabilidad del equilibrio contradictorio entre el generador y el discriminador en las GAN, los valores de los pesos del modelo son sensibles a su inicialización aleatoria y no convergen al mismo valor durante cada sesión de entrenamiento. Esto indica la existencia y singularidad de las huellas dactilares GAN. Los autores definen la huella digital del modelo de cada instancia de GAN como un vector de referencia para que siempre interactúe con todas sus imágenes generadas.
Huellas digitales de imágenes : las imágenes generadas por GAN son el resultado de una gran cantidad de filtros fijos y procesos no lineales que generan patrones comunes y estables en la misma instancia de GAN, pero son diferentes en diferentes instancias de GAN. Esto indica la presencia de huellas digitales de imágenes y sus fuentes GAN. Los autores introducen la huella digital de cada imagen como un vector de características codificado a partir de esa imagen.
S.3 Trazabilidad de imágenes
El proceso de huella digital visual se muestra en la figura anterior. Dado un par de fuentes de imágenes (I, y), donde y ∈ Y pertenece a la instancia de GAN más un conjunto finito Y de imágenes reales, formulamos un mapa de reconstrucción R de I a R(I).
La huella dactilar de la imagen se define como el residuo de reconstrucción:
![]()
La huella digital modelo F^y_mod se define como un parámetro libremente entrenable del mismo tamaño que F^I_im tal que el índice de correlación entre F^I_im y F^y_mod
![]()
Maximizar en Y. Esto se puede formular como el logit softmax de la pérdida de clasificación de entropía cruzada supervisada por las etiquetas de verdad del terreno fuente:
![]()
ˆA y ˆB son versiones de media cero, norma unitaria y vectorizadas de las imágenes A y B, mientras que ⊙ es la operación del producto interno.