Contenido: Guía
-
- prefacio
- 1. De la entrada al dominio de la programación en Python
- 2. Proyecto de automatización de interfaz de combate real.
- 3. Combate real del proyecto de automatización web
- 4. Combate real del proyecto de automatización de aplicaciones
- 5. Hoja de vida de los fabricantes de primer nivel
- 6. Probar y desarrollar el sistema DevOps
- 7. Herramientas de prueba automatizadas de uso común
- Ocho, prueba de rendimiento JMeter
- 9. Resumen (pequeña sorpresa al final)
prefacio
Cuando estamos haciendo la automatización de la interfaz, generalmente usamos expresiones regulares para extraer datos relacionados cuando tratamos con datos relacionados de los que depende la interfaz.
Expresión regular, también conocida como expresión regular, expresión regular, expresión regular, expresión regular, expresión regular (Expresión regular, a menudo abreviada como regex, regexp o RE en código).
Es una secuencia de caracteres especial que lo ayuda a verificar fácilmente si una cadena coincide con un patrón determinado. En muchos editores de texto, las expresiones regulares se utilizan a menudo para recuperar y reemplazar texto que coincide con un determinado patrón.
sintaxis de expresiones regulares
Indica un solo carácter.
Un solo carácter: significa un solo carácter, por ejemplo, \d se usa para hacer coincidir números y \D para hacer coincidir números que no son dígitos.
Además de la siguiente sintaxis, también puede coincidir con caracteres específicos especificados, que pueden ser uno o más.
| personaje | Función descriptiva |
|---|---|
| . | Coincide con cualquier 1 carácter (excepto \n) |
| [2a] | Coincide con los caracteres enumerados entre corchetes [], por ejemplo, coincide con uno de los dos caracteres 2 o a |
| \d | Coincidencia de dígitos, es decir, 0-9 |
| \D | coincidir sin dígitos |
| \s | Haga coincidir espacios en blanco, es decir, espacios, teclas de tabulación (las teclas de tabulación son dos espacios) |
| \S | partido no en blanco |
| \w | Coincidencia de caracteres de palabras, es decir, az, AZ, 0-9, _ (números, letras, guión bajo) |
| \W | coincide con caracteres que no son palabras |
El ejemplo es el siguiente, aquí hay una descripción de findall (reglas de coincidencia, la cadena que debe coincidir) Este método es para encontrar todos los datos coincidentes y devolverlos en forma de lista, que se explicará más adelante en el módulo re :
import re
# .:匹配任意1个字符
re1 = r'.'
res1 = re.findall(re1, '\nj8?0\nbth\nihb')
print(res1) # 运行结果:['j', '8', '?', '0', 'b', 't', 'h', 'i', 'h', 'b']
# []:匹配列举中的其中一个
re2 = r"[abc]"
res2 = re.findall(re2, '1iugfiSHOIFUOFGIDHFGFD2345a6a78b99cc')
print(res2) # 运行结果:['a', 'a', 'b', 'c', 'c']
# \d:匹配一个数字
re3 = r"\d"
res3 = re.findall(re3, "dfghjkl32212dfghjk")
print(res3) # 运行结果:['3', '2', '2', '1', '2']
# \D:匹配一个非数字
re4 = r"\D"
res4 = re.findall(re4, "d212dk?\n$%3;]a")
print(res4) # 运行结果:['d', 'd', 'k', '?', '\n', '$', '%', ';', ']', 'a']
# \s:匹配一个空白键或tab键(tab键实际就是两个空白键)
re5 = r"\s"
res5 = re.findall(re5,"a s d a 9999")
print(res5) # 运行结果:[' ', ' ', ' ', ' ', ' ']
# \S: 匹配非空白键
re6 = r"\S"
res6 = re.findall(re6, "a s d a 9999")
print(res6) # 运行结果:['a', 's', 'd', 'a', '9', '9', '9', '9']
# \w:匹配一个单词字符(数字、字母、下划线)
re7 = r"\w"
res7 = re.findall(re7, "ce12sd@#a as_#$")
print(res7) # 运行结果:['c', 'e', '1', '2', 's', 'd', 'a', 'a', 's', '_']
# \W:匹配一个非单词字符(不是数字、字母、下划线)
re8 = r"\W"
res8 = re.findall(re8, "ce12sd@#a as_#$")
print(res8) # 运行结果:['@', '#', ' ', '#', '$']
# 匹配指定字符
re9 = r"python"
res9 = re.findall(re9, "cepy1thon12spython123@@python")
print(res9) # 运行结果:['python', 'python']
Indica la cantidad
Si desea hacer coincidir un determinado carácter varias veces, puede agregar el número después del carácter para indicar, las reglas específicas son las siguientes:
| personaje | Función descriptiva |
|---|---|
| * | Coincide con el carácter anterior 0 veces o infinitas veces, puede ser opcional |
| + | Coincidir con el carácter anterior 1 vez o ilimitadas veces, es decir, al menos 1 vez |
| ? | Coincide con el carácter anterior 0 o 1 vez, es decir, ninguno o solo 1 vez |
| Coincide con el carácter anterior m veces | |
| Coincide con al menos m ocurrencias del carácter anterior | |
| Coincide con el carácter anterior de m a n veces |
Los ejemplos son los siguientes:
import re
# *:表示前一个字符出现0次以上(包括0次)
re21 = r"\d*" # 这里匹配的规则,前一个字符是数字
res21 = re.findall(re21, "343aa1112df345g1h6699") # 如匹配到a时,属于符合0次,但因为没有值所以会为空
print(res21) # 运行结果:['343', '', '', '1112', '', '', '345', '', '1', '', '6699', '']
# ? : 表示0次或者一次
re22 = r"\d?"
res22 = re.findall(re22, "3@43*a111")
print(res22) # 运行结果:['3', '', '4', '3', '', '', '1', '1', '1', '']
# {m}:表示匹配一个字符m次
re23 = r"1[3456789]\d{9}" # 手机号:第1位为1,第2位匹配列举的其中1个数字,第3位开始是数字,且匹配9次
res23 = re.findall(re23,"sas13566778899fgh256912345678jkghj12788990000aaa113588889999")
print(res23) # 运行结果:['13566778899', '13588889999']
# {m,}:表示匹配一个字符至少m次
re24 = r"\d{7,}"
res24 = re.findall(re24, "sas12356fgh1234567jkghj12788990000aaa113588889999")
print(res24) # 运行结果:['1234567', '12788990000', '113588889999']
# {m,n}:表示匹配一个字符出现m次到n次
re25 = r"\d{3,5}"
res25 = re.findall(re25, "aaaaa123456ghj333yyy77iii88jj909768876")
print(res25) # 运行结果:['12345', '333', '90976', '8876']
grupo de partido
| personaje | Función descriptiva |
|---|---|
| I | Coincide con cualquier expresión izquierda o derecha |
| (ab) | Tratar los caracteres entre paréntesis como un grupo |
Los ejemplos son los siguientes:
import re
# 同时定义多个规则,只要满足其中一个
re31 = r"13566778899|13534563456|14788990000"
res31 = re.findall(re31, "sas13566778899fgh13534563456jkghj14788990000")
print(res31) # 运行结果:['13566778899', '13534563456', '14788990000']
# ():匹配分组:在匹配规则的数据中提取括号里的数据
re32 = r"aa(\d{3})bb" # 如何数据符合规则,结果只会取括号中的数据,即\d{3}
res32 = re.findall(re32, "ggghjkaa123bbhhaa672bbjhjjaa@45bb")
print(res32) # 运行结果:['123', '672']
Indica el límite
| personaje | Función descriptiva |
|---|---|
| ^ | Coincide con el comienzo de la cadena, solo el comienzo |
| ps | Coincidir con el final de la cadena, sólo el final |
| \b | Coincide con un límite de palabra (palabra: letra, dígito, guión bajo) |
| \B | Coincidir con límites que no son palabras |
Los ejemplos son los siguientes:
import re
# ^:匹配字符串的开头
re41 = r"^python" # 字符串开头为python
res41 = re.findall(re41, "python999python") # 只会匹配这个字符串的开头
res411 = re.findall(re41, "1python999python") # 因为开头是1,第1位就不符合了
print(res41) # 运行结果:['python']
print(res411) # 运行结果:[]
# $:匹配字符串的结尾
re42=r"python$" # 字符串以python结尾
res42 = re.findall(re42, "python999python")
print(res42) # 运行结果:['python']
# \b:匹配单词的边界,单词即:字母、数字、下划线
re43 = r"\bpython" # 即匹配python,且python的前一位是不是单词
res43 = re.findall(re43, "1python 999 python") # 这里第1个python的前1位是单词,因此第1个是不符合的
print(res43) # 运行结果:['python']
# \B:匹配非单词的边界
re44 = r"\Bpython" # 即匹配python,且python的前一位是单词
res44 = re.findall(re44, "1python999python")
print(res44) # 运行结果:['python', 'python']
modo codicioso
Los cuantificadores en python son codiciosos por defecto. Siempre intentan hacer coincidir tantos caracteres como sea posible. El modo no codicioso intenta hacer coincidir la menor cantidad de caracteres posible. Agregue un signo de interrogación (?) a la expresión que indica la cantidad para apagar el modo codicioso.
El siguiente ejemplo coincide con más de 2 números. Si cumple las condiciones, coincidirá hasta que no coincida. Por ejemplo, 34656fya, 34656 coincide con más de 2 números, entonces coincidirá hasta 6. Si el modo codicioso está desactivado , luego se detendrá cuando se encuentre con 2 números, y finalmente puede hacer coincidir 34 y 65.
import re
# 默认的贪婪模式下
test = 'aa123aaaa34656fyaa12a123d'
res = re.findall(r'\d{2,}', test)
print(res) # 运行结果:['123', '34656', '12', '123']
# 关闭贪婪模式
res2 = re.findall(r'\d{2,}?', test)
print(res2) # 运行结果:['12', '34', '65', '12', '12']
re módulo
Cuando se usan expresiones regulares en python, el módulo re se usará para las operaciones. Los métodos provistos generalmente requieren que se pasen dos parámetros:
Parámetro 1: La regla de concordancia
Parámetro 2: La cadena a concordar
re.findall()
Encuentre todas las cadenas que coincidan con la especificación y devuélvalas como una lista.
import re
test = 'aa123aaaa34656fyaa12a123d'
res = re.findall(r'\d{2,}', test)
print(res) # 运行结果:['123', '34656', '12', '123']
re.search()
Encuentre la primera cadena que cumpla con la especificación y devuelva un objeto coincidente, y los datos coincidentes se pueden extraer directamente a través de group().
import re
s = "123abc123aaa123bbb888ccc"
res2 = re.search(r'123', s)
print(res2) # 运行结果:<re.Match object; span=(0, 3), match='123'>
# 通过group将匹配到的数据提取出来,返回类型为str
print(res2.group()) # 运行结果:123
En el objeto de coincidencia devuelto, span es el rango de subíndice de los datos coincidentes y match es el valor coincidente.
descripción del parámetro group():
no se pasa ningún parámetro: se obtiene todo el contenido coincidente
Valor entrante: se puede especificar mediante parámetros para obtener el contenido del primer grupo (obtener el primer grupo, pasar el parámetro 1, obtener el segundo grupo, pasar el parámetro 2, etc.)
import re
s = "123abc123aaa123bbb888ccc"
re4 = r"aaa(\d{3})bbb(\d{3})ccc" # 这里分组就是前面说到的匹配语法:()
res4 = re.search(re4, s)
print(res4)
# group不传参数:获取的是匹配到的所有内容
# group通过参数指定,获取第几个分组中的内容(获取第1个分组,传入参数1,获取第2个分组,传入参数2,依次类推..
print(res4.group())
print(res4.group(1))
print(res4.group(2))
revancha()
Haga coincidir desde la posición inicial de la cadena y devuelva el objeto coincidente si la coincidencia es exitosa. Si la posición inicial no cumple con las reglas de coincidencia, no seguirá coincidiendo y devolverá Ninguno directamente. Tanto re.match() como re.search() coinciden solo con uno. La diferencia es que el primero solo coincide con el comienzo de la cadena, mientras que el segundo coincide con la cadena completa, pero solo obtiene los primeros datos coincidentes.
import re
s = "a123abc123aaa1234bbb888ccc"
# match:只匹配字符串的开头,开头不符合就返回None
res1 = re.match(r"a123", s)
res2 = re.match(r"a1234", s)
print(res1) # 运行结果:<re.Match object; span=(0, 4), match='a123'>
print(res2) # 运行结果:None
re.sub()
Recuperación y reemplazo: se utiliza para reemplazar los elementos coincidentes en la cadena
re.sub() Descripción del parámetro:
Parámetro 1: la cadena que se reemplazará
Parámetro 2: la cadena de destino
Parámetro 3: la cadena que se reemplazará
Parámetro 4: se puede especificar número máximo de reemplazos, no requerido (de manera predeterminada, se reemplazan todas las cadenas que cumplen con la especificación)
import re
s = "a123abc123aaa123bbb888ccc"
# <font color="#FF0000">参数1:</font>待替换的字符串
# <font color="#FF0000">参数2:</font>目标字符串
# <font color="#FF0000">参数3:</font>要进行替换操作的字符串
# <font color="#FF0000">参数4:</font>可以指定最多替换的次数,非必填(默认替换所有符合规范的字符串)
res5 = re.sub(r'123', "666", s, 4)
print(res5) # 运行结果:a666abc666aaa666bbb888ccc
parametrización de casos de uso
En la prueba de automatización de la interfaz, todos nuestros datos de prueba se almacenan en Excel. Si algunos parámetros se escriben demasiado, es posible que no estén disponibles en una escena o entorno diferente. Al cambiar de entorno, primero debe guardar los datos de prueba en el nuevo Ambiente Está listo y puede soportar ejecutar nuestros scripts, o modificar los datos de Excel para probar los datos adecuados para el nuevo entorno, y el costo de mantenimiento es relativamente alto.
Por lo tanto, necesitamos parametrizar nuestros datos de prueba de script automatizados tanto como sea posible para reducir los costos de mantenimiento.
Veamos primero la parametrización de la versión simple. Tomando el inicio de sesión como ejemplo, el número de cuenta, la contraseña y otra información utilizada para iniciar sesión se pueden extraer y colocar en el archivo de configuración. Al modificar datos o cambiar el entorno, se puede modificado en el archivo de configuración.

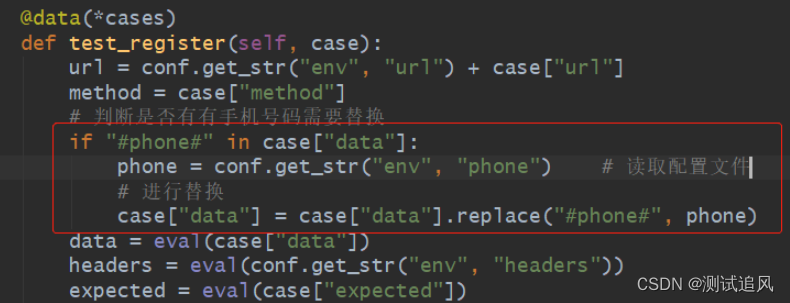
Pero si hay varios datos diferentes que deben parametrizarse, ¿debería cada parámetro agregar un juicio para reemplazar los datos? Dicho código es extenso y difícil de mantener. En este momento, se puede usar el módulo re. Veamos un ejemplo directamente:
import re
from common.myconfig import conf
class TestData:
"""用于临时保存一些要替换的数据"""
pass
def replace_data(data):
r = r"#(.+?)#" # 注意这个分组()内的内容
# 判断是否有需要替换的数据
while re.search(r, data):
res = re.search(r, data) # 匹配出第一个要替换的数据
item = res.group() # 提取要替换的数据内容
key = res.group(1) # 获取要替换内容中的数据项
try:
# 根据替换内容中的数据项去配置文件中找到对应的内容,进行替换
data = data.replace(item, conf.get_str("test_data", key))
except:
# 如果在配置文件中找不到就在临时保存的数据中找,然后替换
data = data.replace(item, getattr(TestData, key))
return data
Nota: ¿Se usa la expresión regular aquí? Desactive el modo codicioso, porque los datos de prueba pueden necesitar parametrizar 2 o más datos, si el modo codicioso no está desactivado, solo puede coincidir y coincidir con un dato, por ejemplo:
import re
data = '{"mobile_phone":"#phone#","pwd":"#pwd#","user":#user#}'
r1 = "#(.+)#"
res1 = re.findall(r1, data)
print(res1) # 运行结果:['phone#","pwd":"#pwd#","user":#user'] 注意这里单引号只有一个数据
print(len(res1)) # 运行结果:1
r2 = "#(.+?)#"
res2 = re.findall(r2, data)
print(res2) # 运行结果:['phone', 'pwd', 'user']
print(len(res2)) # 运行结果:3
Además, se menciona una clase para guardar datos temporalmente, que se usa principalmente para guardar los datos devueltos por la interfaz, porque algunos datos de prueba cambian dinámicamente y pueden depender de una determinada interfaz, y los casos de prueba posteriores necesitan estos datos.
Luego, podemos guardarlo en esta clase como un atributo de clase cuando la interfaz regrese, y luego extraer este atributo de clase y reemplazarlo en los datos de prueba cuando necesitemos un caso de prueba que use estos datos.
Sugerencia: configure el atributo setattr (objeto, nombre de atributo, valor de atributo), obtenga el valor de atributo getattr (objeto, nombre de atributo).
| El siguiente es el diagrama de sistema de arquitectura de conocimiento de aprendizaje de ingeniero de prueba de software más completo en 2023 que compilé |
1. De la entrada al dominio de la programación en Python
2. Proyecto de automatización de interfaz de combate real.
3. Combate real del proyecto de automatización web
4. Combate real del proyecto de automatización de aplicaciones
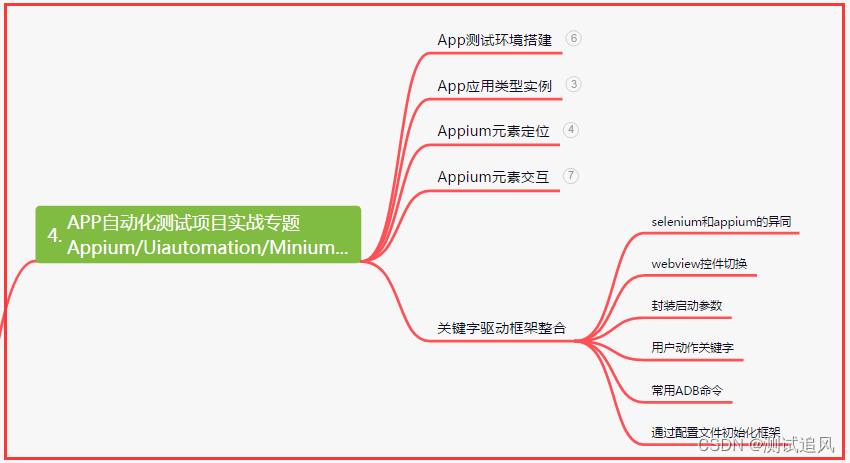
5. Hoja de vida de los fabricantes de primer nivel
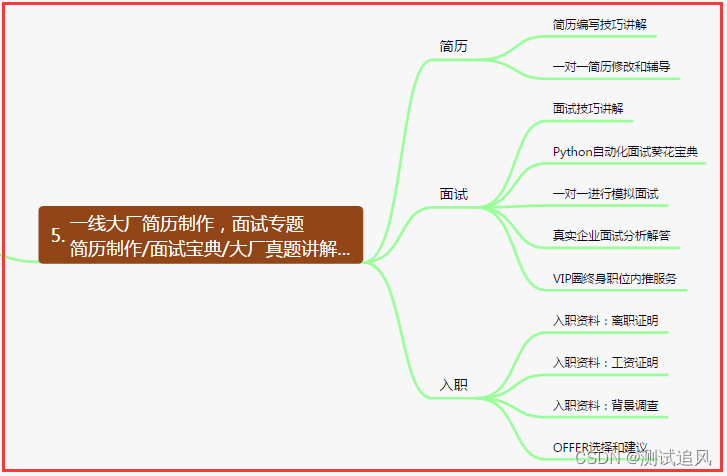
6. Probar y desarrollar el sistema DevOps
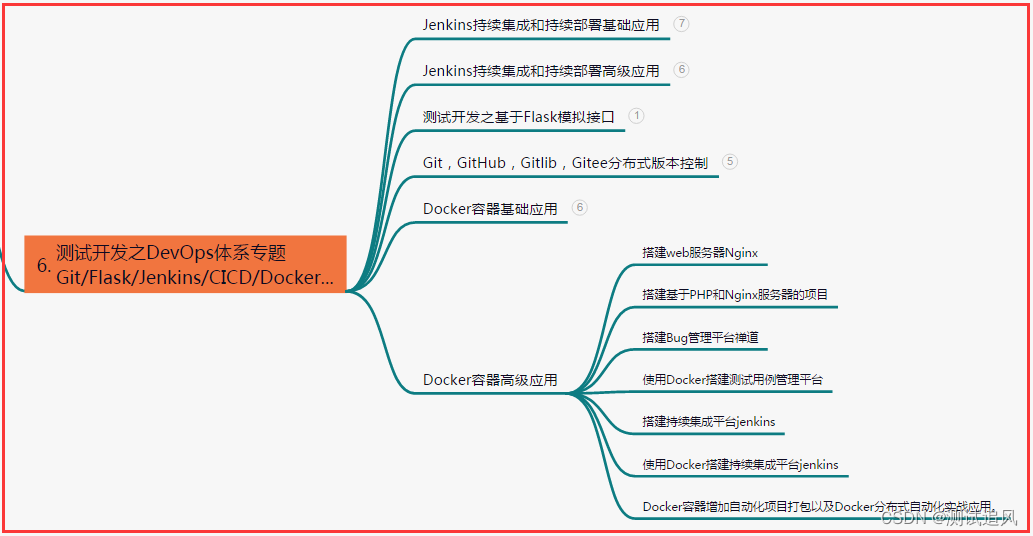
7. Herramientas de prueba automatizadas de uso común

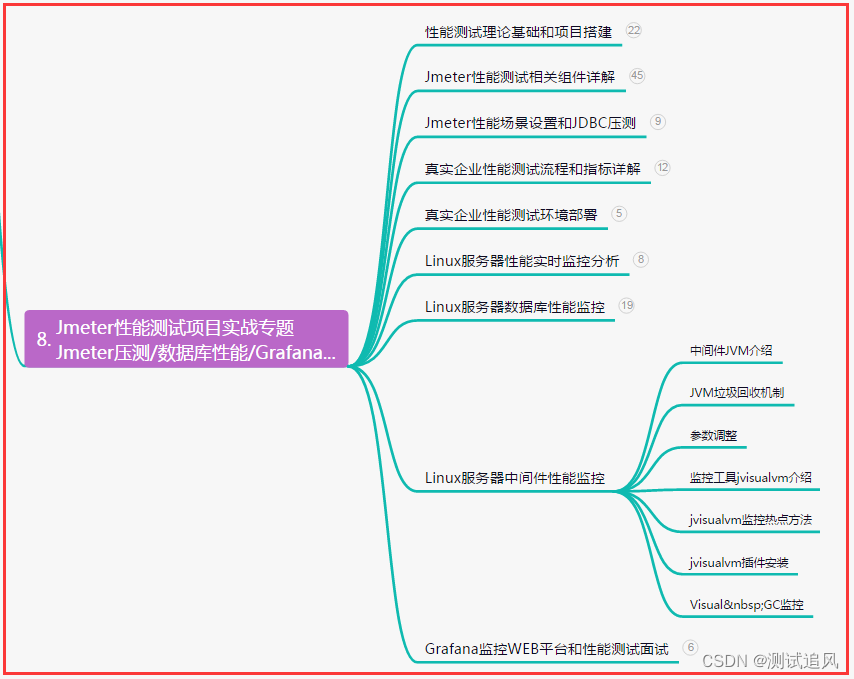
Ocho, prueba de rendimiento JMeter
9. Resumen (pequeña sorpresa al final)
Abraza los altibajos, marcha hacia la gloria y la lucha es el ritmo de la realización de los sueños. Avanza con valentía, sin miedo a las dificultades, y riega con sudor las flores de tu corazón. ¡Cree en tu propia fuerza, desarrolla tu potencial ilimitado, crea tu propia vida magnífica y deja que cada esfuerzo cree un brillo indeleble!
Rechaza la mediocridad, persigue la excelencia y la lucha es el fuego que inspira el corazón. Navegue, siga adelante y allane el camino hacia el éxito con trabajo duro. Creer en la persistencia y enfrentar los desafíos.
La determinación es como el fuego, perseguir sueños, y la lucha es la fuerza impulsora de la persistencia ardiente. Deja ir la pasión, ve más allá del límite y escribe el capítulo espléndido de la vida con trabajo duro. ¡Cree en los milagros, acepta los desafíos, deja que cada esfuerzo se convierta en una oportunidad para cambiar tu destino y florece tu propio brillo único!