
Con el rápido desarrollo de Elasticsearch a escala global, sus funciones y escenarios de aplicación son cada vez más abundantes. Hoy, en la ElasticConference 2023, aprendimos sobre una serie de funciones nuevas e interesantes para las series Elasticsearch 7 y 8. Este artículo presentará estas nuevas funciones y sus aplicaciones en detalle para ayudarlo a comprender y usar mejor Elasticsearch.

1. Nueva estrategia de equilibrio de clústeres
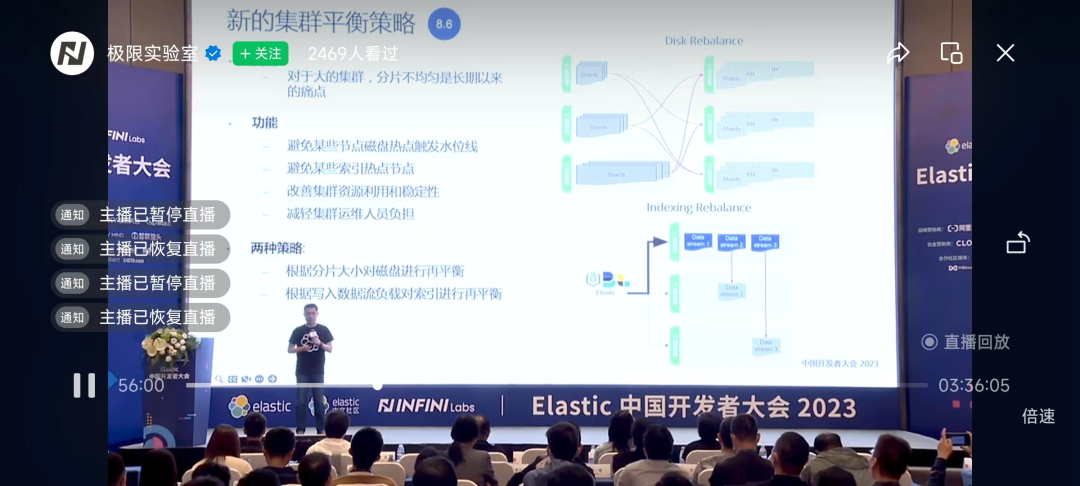
Estrategia 1: Vuelva a equilibrar el disco según el tamaño del fragmento En esta estrategia, el sistema supervisa el uso del disco en cada nodo del clúster. Si se descubre que el uso del disco de un nodo supera el umbral preestablecido, el sistema activará automáticamente una operación de migración de fragmentos para migrar algunos fragmentos del nodo a otros nodos con un uso menor. Esta estrategia de reequilibrio basada en el tamaño de los fragmentos ayuda a lograr una asignación equilibrada de recursos de disco en el clúster, lo que mejora el rendimiento general.
Estrategia 2: Reequilibrar el índice de acuerdo con la carga de datos importados Para la carga de solicitudes de lectura y escritura, el sistema monitoreará la carga de datos importados en cada nodo del clúster. De acuerdo con la carga de datos entrantes, el sistema ajustará automáticamente la distribución de fragmentos de índice en cada nodo, de modo que la cantidad de fragmentos en los nodos con mayor carga disminuya, mientras que la cantidad de fragmentos en los nodos con menor carga aumente. De esta forma, se puede realizar la distribución equilibrada de la carga de datos introducida en el clúster al mismo tiempo que se garantiza el rendimiento del sistema.
Esta nueva estrategia de equilibrio de clústeres tiene las siguientes ventajas: la nueva estrategia de equilibrio de clústeres puede aprovechar al máximo los recursos de cada nodo y mejorar el rendimiento general equilibrando la distribución del disco e introduciendo la carga de datos. Realice el equilibrio de carga entre los nodos, reduzca el impacto de una falla de un solo nodo en el clúster y mejore la estabilidad del sistema.
Además, esta estrategia puede ajustar automáticamente la asignación de recursos de acuerdo con las necesidades reales, evitar el desperdicio de recursos y mejorar la utilización de los recursos. Al mismo tiempo, el ajuste automático reduce la carga del personal de O&M, reduce el riesgo de intervención manual y ayuda a reducir los costos de O&M.
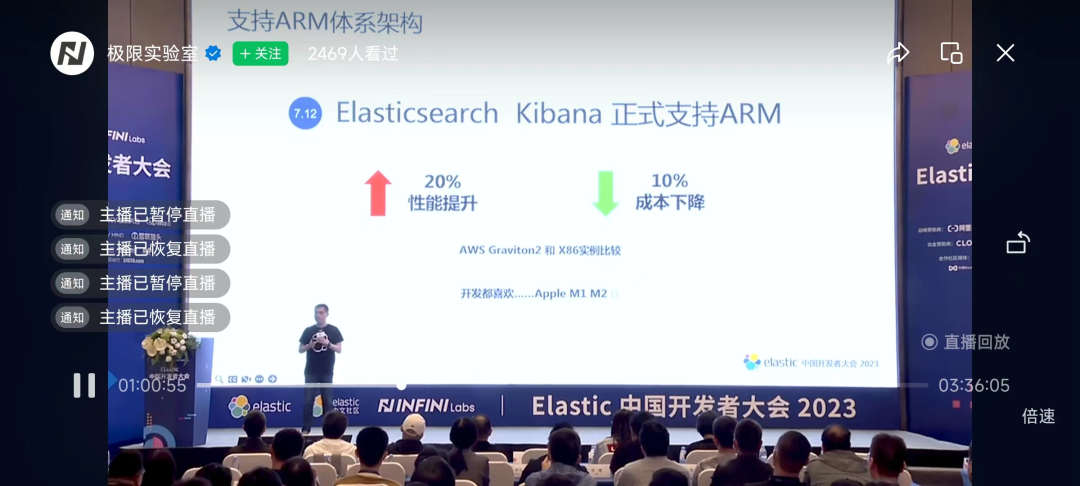
2. Kibana es compatible con la arquitectura ARM
3. Plataforma de recolección centralizada y funciones de escena de seguridad.

Elastic Stack presenta una plataforma de recopilación centralizada y proporciona una serie de soluciones de integración y una plataforma de administración unificada.
Además, en términos de escenarios de seguridad, Elastic Stack proporciona la función de serie temporal EQL, que es adecuada para escenarios que requieren coincidencia de secuencias.

4. Arquitectura de separación entre almacenamiento y computación y nuevo lenguaje de búsqueda ESQL
La dirección de desarrollo futuro de Elastic Stack gira principalmente en torno a la arquitectura de separación de servicio y almacenamiento y cálculo. En la arquitectura nativa de la nube, el uso del almacenamiento de objetos como medio puede reducir el costo del manejo de datos y mejorar la capacidad de escalado automático.

Además, Elastic Stack también presentará un nuevo lenguaje de búsqueda ESQL para brindar una mayor flexibilidad y rendimiento en el procesamiento de datos. ESQL utiliza canalizaciones para conectarse y puede realizar operaciones de búsqueda en varios pasos, como la conversión y el filtrado de datos.


5. Solución de observación completa
Elastic Stack proporciona soluciones de observación completas, incluidos registros, indicadores, APM, monitoreo de usuarios reales de RUM, monitoreo sintético, análisis de rendimiento general, etc. Estas funciones pueden ayudar a los usuarios a comprender y monitorear el estado de ejecución del sistema de manera más completa.


6. Soluciones de seguridad
Elastic Stack también proporciona soluciones de seguridad, incluida la recopilación de datos relacionados con la seguridad, el análisis y la detección de comportamientos anormales y la respuesta automática. Elastic Security puede proporcionar una solución de seguridad integral, integrando las funciones SIEM, Endpoint Security y Threat Hunting en una plataforma para ayudar a las empresas a lograr una protección de seguridad más eficiente.

7. Integración de aprendizaje automático
Elasticsearch tiene funciones integradas de aprendizaje automático, que se pueden usar para tareas como la detección de anomalías y la predicción de series temporales. La nueva versión de Elasticsearch optimizará aún más las funciones de aprendizaje automático, mejorará el entrenamiento de modelos y el rendimiento de la predicción, y proporcionará más algoritmos de aprendizaje automático para que los usuarios elijan.
Para esto, personalmente recomiendo ampliamente el GPT4 VS Elasticsearch que enseñó el Sr. Li Jie en la segunda parte, ¡es muy bueno y vale la pena aprenderlo repetidamente! (Como se muestra abajo)

¡Más rápido que rápido, se lanza oficialmente Elasticsearch 8.0!
8. Búsqueda y visualización geoespacial
Las series 7 y 8 de Elasticsearch mejoran aún más las capacidades de visualización y búsqueda geoespacial. Las nuevas características incluyen soporte para datos GeoJSON, optimizaciones para procesar datos geoespaciales y más herramientas de agregación y visualización geoespacial. Estas funciones ayudarán a los usuarios a procesar y analizar datos geoespaciales de manera más conveniente.

Visualización del mapa de distribución de direcciones IP basado en Elasticsearch + kibana
9. Programación flexible de recursos informáticos y optimización de costos
Elasticsearch presenta la función de programación de recursos informáticos elásticos, que puede asignar recursos informáticos de forma dinámica de acuerdo con las necesidades comerciales reales. Además, la nueva versión también proporciona herramientas de optimización de costos para ayudar a los usuarios a evaluar y optimizar los costos operativos de los clústeres de Elasticsearch.
10. API más potente y compatibilidad con la biblioteca del cliente
Las series 7 y 8 de Elasticsearch proporcionarán una API más potente y compatibilidad con la biblioteca del cliente para satisfacer las necesidades de varios lenguajes y plataformas de programación. Esto facilitará a los desarrolladores la integración y el uso de la funcionalidad de Elasticsearch.
11. Optimización a nivel de recuperación
Con respecto a la optimización a nivel de recuperación, las series Elasticsearch 7 y 8 también tienen muchas mejoras significativas. Aquí hay algunas características clave de optimización de búsqueda:

Explicación detallada de la clasificación de recuperación de Elasticsearch: artículos básicos
11.1. Punto en el tiempo (PIT)
Point In Time (PIT) es una nueva característica introducida después del lanzamiento de Elasticsearch 7.10. Permite a los usuarios crear una instantánea durante la búsqueda que permanece constante a lo largo del tiempo. Esto permite a los usuarios obtener una vista coherente de las diferentes solicitudes de búsqueda, evitando resultados incoherentes debido a las actualizaciones del índice.

Productos secos | Interpretación completa y profunda de la consulta de paginación de Elasticsearch
11.2 Tipos de campo comodín
El tipo de campo comodín es un nuevo tipo de campo diseñado para admitir consultas eficientes con comodines y expresiones regulares. Puede ayudar a los usuarios a ejecutar consultas complejas que contienen comodines y expresiones regulares más rápido y mejorar el rendimiento de las consultas.

Productos secos | Guía de selección del tipo de búsqueda de Elasticsearch
11.3. Campos de tiempo de ejecución
Runtime Fields es un nuevo tipo de campo que permite a los usuarios calcular dinámicamente valores de campo en el momento de la consulta. Esto significa que los usuarios no necesitan calcular ni almacenar estos campos al indexar, lo que ahorra espacio de almacenamiento y mejora el rendimiento de la indexación. Además, Runtime Fields también es compatible con el lenguaje de secuencias de comandos Painless, lo que permite a los usuarios definir de manera flexible la lógica de cálculo de campos.

Explicación detallada del tipo de tiempo de ejecución de Elasticsearch Campos de tiempo de ejecución
11.4 Recuperación de instantáneas
Las series 7 y 8 de Elasticsearch admiten la función de instantánea de recuperación, lo que permite a los usuarios especificar una instantánea de índice histórico al realizar consultas. Esto es muy útil para escenarios de aplicaciones que necesitan consultar datos históricos o analizar cambios de datos. Los usuarios pueden volver fácilmente al estado de los datos en cualquier momento para satisfacer diversas necesidades comerciales.
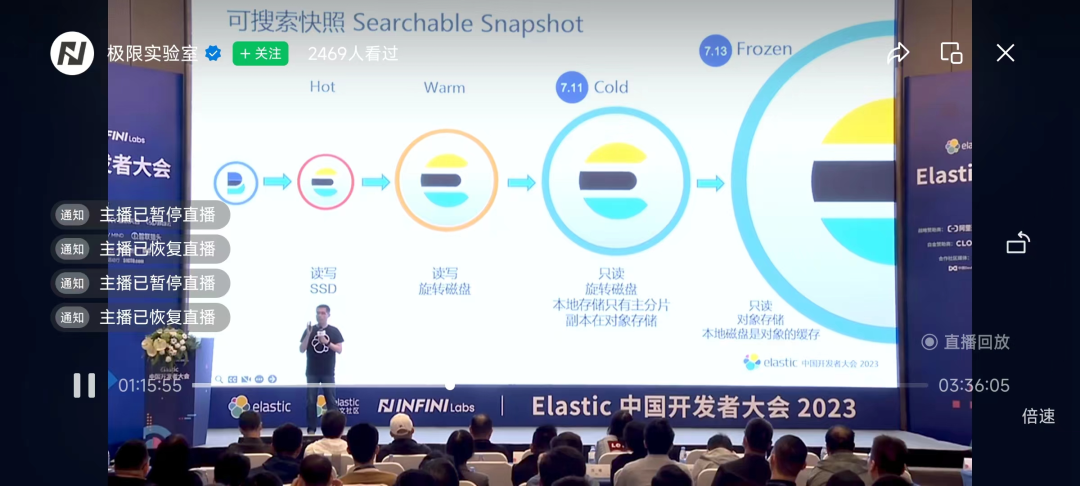
Productos secos | Explicación detallada de la instantánea de búsqueda de Elasticsearch
11.5. Enriquecer canalización
Enrich Pipeline es una nueva canalización de procesamiento de datos que permite a los usuarios encontrar y enriquecer datos en tiempo real mientras se indexan. Esto es similar a la operación de búsqueda en la base de datos, que puede ayudar a los usuarios a combinar datos relacionados en un documento para su posterior búsqueda y análisis. Enrich Pipeline admite múltiples estrategias de búsqueda, como la coincidencia exacta, la coincidencia aproximada y la coincidencia geoespacial, para satisfacer las necesidades de diferentes escenarios.

Enrich Processor: una nueva forma para que Elasticsearch vincule datos entre índices
11.6 Clasificación de optimización de búsqueda
El algoritmo Block Max WAND es un algoritmo de recuperación de documentos eficiente basado en un índice invertido, diseñado para identificar y omitir rápidamente documentos que no son competitivos, mejorando así la eficiencia de las consultas.

El proceso de implementación del algoritmo Block Max WAND incluye dividir la colección de documentos en varios bloques, crear un índice invertido para cada bloque y usar el índice invertido para calcular la puntuación del documento. Al seleccionar los fragmentos mejor clasificados para la siguiente ronda de recuperación, se omiten aquellos fragmentos con una puntuación inferior a la puntuación más baja de los documentos ya encontrados. Este proceso se repite hasta que se encuentra una cantidad suficiente de documentos o se saltan todos los bloques.
11.7 Solo coincidencia de texto
La consulta "Coincidir solo texto" es adecuada para escenarios que requieren consultas de coincidencia aproximada en campos de tipo texto, por ejemplo, en aplicaciones como motores de búsqueda y plataformas de comercio electrónico, los usuarios ingresan palabras clave para consultar o datos no estructurados o semiestructurados. Coincidencia de palabras, como datos de registro, datos de redes sociales, etc. Sin embargo, debe tenerse en cuenta que esta consulta generalmente no es adecuada para escenarios que requieren coincidencias exactas o consultas de rango. En este caso, se deben seleccionar otros tipos de consulta, como la consulta de "término" o la consulta de "rango".

A través de la optimización del nivel de recuperación anterior, las series 7 y 8 de Elasticsearch lograron mejoras significativas en el rendimiento de las consultas, el almacenamiento de datos, la computación en tiempo real y el procesamiento de datos, brindando a los usuarios funciones de recuperación más potentes y flexibles.
11.8 Guardar solo el campo Valor del documento
Elasticsearch puede optar por guardar solo valores de documentos al procesar datos de campo. Doc Values es un formato de almacenamiento en columnas en disco que permite que Elasticsearch realice consultas y agregaciones de manera más eficiente. Los beneficios de guardar solo los campos de valor de documento incluyen: Ahorro de espacio en disco: mantener solo valores de documento puede reducir el espacio en disco necesario para almacenar el índice, ya que contiene solo los datos realmente necesarios para la consulta y la agregación. Mejore el rendimiento de las consultas: dado que Doc Values es un almacenamiento en columnas, Elasticsearch puede procesar datos de manera más eficiente al realizar operaciones como agregación y clasificación.

Interpretación en profundidad de la estructura de datos internos de Elasticsearch
Esto ayuda a acelerar los tiempos de respuesta de las consultas. Uso de memoria reducido: los valores de documentos se almacenan en el disco, no en la memoria, por lo que se puede reducir el uso de la memoria, especialmente cuando se realizan operaciones de agregación pesadas. Apto para caché: dado que los valores de documentos se almacenan en columnas, las líneas de caché de la CPU se pueden utilizar mejor al almacenar en caché. Esto ayuda a mejorar el rendimiento de las consultas.
Cabe señalar que guardar solo el campo Valor del documento limita algunas funciones. Por ejemplo, el campo fuente del documento (_fuente) no estará disponible, lo que significa que el contenido del documento original no se puede actualizar ni recuperar con un documento parcial. Por lo tanto, estas limitaciones deben sopesarse con los beneficios anteriores cuando solo se retienen los valores de Doc.
12. Resumen
ElasticConference 2023 nos trae muchas características nuevas y emocionantes para las series Elasticsearch 7 y 8. Estas nuevas capacidades ayudarán a aumentar las capacidades de procesamiento de datos, reducir los costos de almacenamiento, mejorar la flexibilidad informática en tiempo real y mejorar la seguridad y la observabilidad. Como motor de búsqueda y análisis maduro, Elasticsearch se optimiza y mejora constantemente para brindar a los usuarios una mejor experiencia.
Nota: El contenido de este artículo se basa en el intercambio del Sr. Zhu Jie , el arquitecto senior oficial de Elastic .
La cuenta pública no oficial de ElasticStack más grande de China