Spaltenführer

Adresse des Kolumnenabonnements: https://blog.csdn.net/qq_35831906/category_12375510.html

1 Einführung in grundlegende Datenbankkenntnisse
1.1 Was ist eine Datenbank?
Eine Datenbank ist eine Sammlung strukturierter, gespeicherter und organisierter Daten, die effizient abgerufen, verwaltet und aktualisiert werden können. Der Zweck einer Datenbank besteht darin, eine zuverlässige Möglichkeit zum Speichern und Verwalten großer Datenmengen bereitzustellen, damit Benutzer und Anwendungen problemlos Datenmanipulationen, Abfragen und Analysen durchführen können.
1.2 Datenbankverwaltungssystem (DBMS)
Ein Datenbankverwaltungssystem (DBMS) ist ein Softwaresystem, das es Benutzern ermöglicht, Datenbanken zu erstellen, darauf zuzugreifen und sie zu verwalten. DBMS ist für die Abwicklung verschiedener Vorgänge der Datenbank verantwortlich, wie z. B. Datenspeicherung, -abruf, -aktualisierung und -löschung, und bietet außerdem eine sichere Möglichkeit zur Verwaltung des Datenzugriffs und der Datenintegrität. Das DBMS kann auch eine Abfragesprache bereitstellen, die es Benutzern ermöglicht, Daten in der Datenbank mithilfe einer bestimmten Syntax abzufragen.
Zu den gängigen DBMS gehören:
- MySQL
- PostgreSQL
- Oracle-Datenbank
- Microsoft SQL Server
- SQLite
1.3 Relationale und nicht-relationale Datenbanken
1.3.1 Relationale Datenbank
Eine relationale Datenbank ist eine Datenbank, die Daten in tabellarischer Form organisiert. Es verwendet Structured Query Language (SQL), um Daten zu verwalten und abzufragen. Daten in einer relationalen Datenbank werden in Zeilen und Spalten gespeichert, und jede Tabelle (auch als Relation bezeichnet) verfügt über feste Spalten und Datentypen.
Vorteil:
- Der Zusammenhang zwischen den Daten ist klar und leicht verständlich.
- Komplexe Abfragen werden unterstützt, beispielsweise Multi-Table-Joins.
- Sorgen Sie für Datenkonsistenz und -integrität.
Mangel:
- Nicht geeignet zum Speichern großer Mengen unstrukturierter Daten wie Text, Bilder usw.
- Möglicherweise geringere Leistung bei großen Datensätzen.
Zu den gängigen relationalen Datenbanken gehören MySQL, PostgreSQL, Oracle usw.
1.3.2 Nicht relationale Datenbank
Eine nicht relationale Datenbank (NoSQL-Datenbank) ist ein Datenbanktyp, der nicht die traditionelle relationale Tabellenstruktur zum Speichern von Daten verwendet. Sie eignen sich für Szenarien, die große unstrukturierte Daten verarbeiten müssen oder eine höhere Skalierbarkeit und Flexibilität erfordern.
Nicht relationale Datenbanken sind in mehrere Unterkategorien unterteilt, darunter:
- Dokumentendatenbank (Dokumentdatenbank): Speichert Daten in Form von Dokumenten, z. B. MongoDB.
- Spaltenfamiliendatenbank (Spaltenfamiliendatenbank): Speichern Sie Daten als Spaltenfamilie, z. B. Apache Cassandra.
- Schlüsselwertspeicher: Speichern Sie Daten als Schlüsselwertpaare, z. B. Redis.
- Graphdatenbank (Graph Database): Speziell für die Verarbeitung graphstrukturierter Daten, wie z. B. Neo4j.
Vorteil:
- Anwendbar auf unstrukturierte, verteilte, hohe Parallelität und andere Szenarien.
- Es verfügt über eine hohe Skalierbarkeit und Leistung.
Mangel:
- Datenmodelle und Abfragesprachen sind in der Regel spezifisch und teuer in der Erlernung und Verwendung.
- Die verschiedenen Arten nicht relationaler Datenbanken sind sehr unterschiedlich und die Auswahl einer geeigneten Datenbank hängt von der jeweiligen Situation ab.
Zusammenfassung: Eine Datenbank ist eine strukturierte Sammlung zum Speichern und Verwalten von Daten, und ein Datenbankverwaltungssystem (DBMS) ist ein Softwaresystem zum Betreiben und Verwalten einer Datenbank. Relationale und nicht relationale Datenbanken sind zwei verschiedene Arten von Datenbankmodellen, die jeweils für unterschiedliche Anforderungen an die Datenspeicherung und -verarbeitung geeignet sind.
2 Einführung in die Datenbankbetriebsbibliothek in Python
In Python stehen mehrere Datenbankmanipulationsbibliotheken zur Auswahl, um verschiedene Arten von Datenbanken zu verbinden, zu bearbeiten und zu verwalten. Hier ist eine Übersicht über einige gängige Python-Datenbankmanipulationsbibliotheken:
2.1 SQLite3
SQLite3 ist eine eingebettete relationale Datenbank-Engine, die ohne separaten Server verwendet werden kann. Es ist Teil der Python-Standardbibliothek und eignet sich für kleine Projekte und Prototyping.
Hauptmerkmal:
- Leicht und erfordert keine zusätzliche Konfiguration.
- In einer einzigen Datei gespeichert, geeignet für Einzelbenutzer- und kleine Anwendungen.
- Unterstützt Transaktionen und Mehrbenutzerzugriff.
2.2 MySQL-Connector/Python
MySQL Connector/Python ist eine offizielle Bibliothek für die Verbindung zu MySQL-Datenbanken. Es bietet leistungsstarke Verbindungs- und Datenbearbeitungsfunktionen.
Hauptmerkmal:
- Offiziell unterstützt für eine Vielzahl von Funktionen und Kompatibilität.
- Unterstützt Verbindungspooling, Transaktionsverwaltung und Batch-Vorgänge.
- Geeignet für kleine bis mittlere Anwendungen und Großprojekte.
2.3 psycopg2 (für die Verbindung zur PostgreSQL-Datenbank)
Psycopg2 ist eine Bibliothek zum Herstellen einer Verbindung zu und zum Bearbeiten von PostgreSQL-Datenbanken. Es bietet hohe Leistung und Flexibilität.
Hauptmerkmal:
- Unterstützt erweiterte PostgreSQL-Funktionen wie Datentypen, Abfrageoptimierung usw.
- Bietet Verbindungspooling, Transaktionsverwaltung und asynchrone Abfrageunterstützung.
- Geeignet für komplexe Datenverarbeitung und groß angelegte Anwendungen.
2.4 SQLAlchemy
SQLAlchemy ist ein voll funktionsfähiges SQL-Toolkit und eine ORM-Bibliothek (Object-Relational Mapping), mit der Sie Datenbanken über Python-Objekte manipulieren und die zugrunde liegenden Datenbankdetails abstrahieren können.
Hauptmerkmal:
- Unterstützt eine Vielzahl von Datenbank-Backends, einschließlich SQLite, MySQL, PostgreSQL usw.
- Bietet ORM-Unterstützung und ermöglicht die Verwendung von Python-Objekten zur Darstellung von Datenbanktabellen und -beziehungen.
- Unterstützt flexible Abfragen, Verbindungspooling und Transaktionsmanagement.
Jeweils 2,5
Peewee ist eine einfache, kleine Python-ORM-Bibliothek, die für kleine und mittlere Projekte geeignet ist.
Hauptmerkmal:
- Einfach und benutzerfreundlich, mit geringem Lernaufwand.
- Unterstützt SQLite, MySQL, PostgreSQL und andere Datenbanken.
- Bereitstellung von Datenmodelldefinitionen, Abfragen, Transaktionsverwaltung und anderen Funktionen.
2.6 SQLAlchemy-Kern
Zusätzlich zur ORM-Funktionalität bietet SQLAlchemy auch „SQLAlchemy Core“, eine Reihe von Tools zum Ausführen von SQL-Anweisungen und zum Verwalten von Datenbankverbindungen.
Hauptmerkmal:
- Stellt den zugrunde liegenden SQL-Ausdruck und die Abfragesprache bereit.
- Unterstützt Verbindungspooling, Transaktionsverwaltung usw.
- Es eignet sich für Szenarien, die eine detailliertere Kontrolle über Datenbankvorgänge erfordern.
Dies ist nur ein Überblick über einige gängige Python-Bibliotheken zur Datenbankmanipulation. Die Auswahl der richtigen Bibliothek für die Anforderungen Ihres Projekts hängt von der Größe des Projekts, den Leistungsanforderungen und der Vertrautheit des Entwicklers ab. Unabhängig davon, für welche Bibliothek Sie sich entscheiden, ist das Verständnis der Dokumentation und Beispiele der Schlüssel zum Beherrschen von Datenbankoperationen.
3. Datenbankoperationsbibliotheksprozess in Python
3.1 Der allgemeine Prozess von Python zum Betreiben der Datenbank
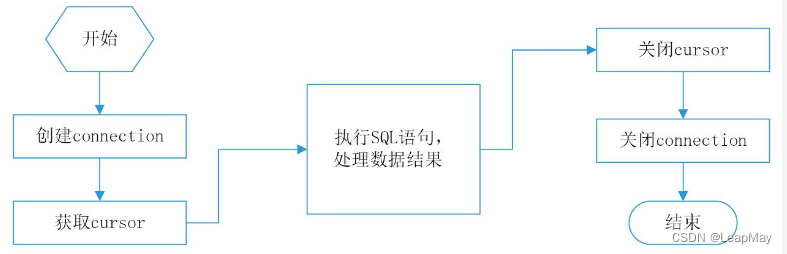
Der allgemeine Prozess für Python zum Betreiben einer Datenbank umfasst normalerweise die folgenden Schritte:
Datenbankbibliotheken importieren : Zunächst müssen Sie die entsprechenden Bibliotheken für die ausgewählte Datenbank importieren. Unterschiedliche Datenbanktypen erfordern unterschiedliche Bibliotheken wie SQLite, MySQL, PostgreSQL usw.
Stellen Sie eine Datenbankverbindung her : Verwenden Sie die von der Bibliothek bereitgestellte Methode, um eine Verbindung mit der Datenbank herzustellen. Dies erfordert in der Regel die Angabe von Informationen wie der Adresse der Datenbank, dem Benutzernamen, dem Passwort und dem Datenbanknamen.
Erstellen Sie ein Cursorobjekt : Erstellen Sie über die Datenbankverbindung ein Cursorobjekt, das zum Ausführen von SQL-Anweisungen und zum Verarbeiten von Abfrageergebnissen verwendet wird.
SQL-Anweisungen ausführen : Verwenden Sie Cursorobjekte, um verschiedene SQL-Operationen wie SELECT, INSERT, UPDATE, DELETE usw. auszuführen. Sie können hier SQL-Abfrageanweisungen verwenden oder die von der Bibliothek bereitgestellten Methoden zur Datenmanipulation verwenden.
Abfrageergebnisse verarbeiten : Wenn eine SELECT-Abfrage ausgeführt wird, können Sie das Cursorobjekt verwenden, um die Abfrageergebnisse abzurufen. Ergebnisse werden normalerweise als Tupel, Listen, Wörterbücher oder benutzerdefinierte Objekte zurückgegeben.
Transaktion festschreiben (optional) : Wenn ein Änderungsvorgang (INSERT, UPDATE, DELETE usw.) ausgeführt wird, muss die Transaktion festgeschrieben werden, um die Änderungen zu speichern. Bei den meisten Bibliotheken werden Änderungsvorgänge standardmäßig innerhalb einer Transaktion ausgeführt, Sie können die Transaktion jedoch manuell festschreiben oder zurücksetzen.
Schließen Sie Cursor und Verbindungen : Schließen Sie immer Cursor und Verbindungen, wenn Sie mit Datenbankoperationen fertig sind, um Ressourcen freizugeben und ein sicheres Schließen von Verbindungen sicherzustellen.
3.2 Beispiele
Das Folgende ist ein allgemeiner Python-Datenbankbetriebsprozess, am Beispiel der SQLite3-Bibliothek:
import sqlite3
# 1. 导入数据库库
# 2. 建立数据库连接
conn = sqlite3.connect('mydatabase.db')
# 3. 创建游标对象
cursor = conn.cursor()
# 4. 执行SQL语句
cursor.execute("SELECT * FROM users")
# 5. 处理查询结果
rows = cursor.fetchall()
for row in rows:
print(row)
# 6. 提交事务(如果有修改操作)
conn.commit()
# 7. 关闭游标和连接
cursor.close()
conn.close()
Dieser allgemeine Prozess ist grundsätzlich in verschiedenen Datenbankbibliotheken konsistent, die spezifischen Methoden und die Verwendung können jedoch etwas unterschiedlich sein. In praktischen Anwendungen können Sie je nach ausgewählter Datenbankbibliothek und Projektanforderungen entsprechende Anpassungen am Prozess vornehmen
4 Beispiele für die allgemeine Verwendung von Python-Datenbanken
4.1 SQLite3
SQLite3 ist eine eingebettete, leichte relationale Datenbank-Engine, die sich für kleine Projekte oder die Entwicklung von Prototypen eignet. Es ist Teil der Python-Standardbibliothek und erfordert keine zusätzliche Installation.
Beispiel :
import sqlite3
# 连接到SQLite数据库
conn = sqlite3.connect('mydatabase.db')
cursor = conn.cursor()
# 创建表
cursor.execute('''CREATE TABLE users (id INTEGER PRIMARY KEY, name TEXT)''')
# 插入数据
cursor.execute("INSERT INTO users (name) VALUES ('Alice')")
conn.commit()
# 查询数据
cursor.execute("SELECT * FROM users")
rows = cursor.fetchall()
for row in rows:
print(row)
# 关闭连接
conn.close()
4.2 MySQL-Connector/Python
MySQL Connector/Python ist eine offizielle Bibliothek für die Verbindung zu MySQL-Datenbanken.
import mysql.connector
# 连接到MySQL数据库
conn = mysql.connector.connect(
host="localhost",
user="username",
password="password",
database="mydatabase"
)
cursor = conn.cursor()
# 执行SQL语句
cursor.execute("SELECT * FROM users")
rows = cursor.fetchall()
for row in rows:
print(row)
# 关闭连接
conn.close()
4.3 psycopg2 (für die Verbindung zur PostgreSQL-Datenbank)
Psycopg2 ist eine Bibliothek zum Herstellen einer Verbindung zu und zum Bearbeiten von PostgreSQL-Datenbanken.
Beispiel :
import psycopg2
# 连接到PostgreSQL数据库
conn = psycopg2.connect(
host="localhost",
user="username",
password="password",
database="mydatabase"
)
cursor = conn.cursor()
# 执行SQL语句
cursor.execute("SELECT * FROM employees")
rows = cursor.fetchall()
for row in rows:
print(row)
# 关闭连接
conn.close()
4.4 SQLAlchemy
SQLAlchemy ist ein SQL-Toolkit und eine ORM-Bibliothek (Object-Relational Mapping), die eine höhere Abstraktionsebene für die Verarbeitung von Datenbankoperationen bietet. Es unterstützt eine Vielzahl von Datenbank-Backends.
Beispiel :
from sqlalchemy import create_engine, Column, Integer, String
from sqlalchemy.orm import sessionmaker
from sqlalchemy.ext.declarative import declarative_base
# 创建数据库连接引擎
engine = create_engine('sqlite:///mydatabase.db', echo=True)
Base = declarative_base()
# 定义数据模型
class User(Base):
__tablename__ = 'users'
id = Column(Integer, primary_key=True)
name = Column(String)
# 创建数据表
Base.metadata.create_all(engine)
# 创建会话
Session = sessionmaker(bind=engine)
session = Session()
# 插入数据
user = User(name='Alice')
session.add(user)
session.commit()
# 查询数据
users = session.query(User).all()
for user in users:
print(user.id, user.name)
# 关闭会话
session.close()
Im nächsten Abschnitt wird die Konfiguration der Datenbankverbindung beschrieben.