En el proceso de desarrollo continuo de la ciencia de datos, los modelos grandes se utilizan cada vez más en diversos campos, como el procesamiento del lenguaje natural, el reconocimiento de imágenes y la previsión financiera. Sin embargo, el entrenamiento y la optimización de modelos grandes también enfrenta cada vez más desafíos, como un volumen de datos excesivo, recursos informáticos insuficientes y dificultad en el ajuste de hiperparámetros. Los algoritmos de aprendizaje automático tradicionales a menudo son difíciles de tratar con estos problemas, por lo que se necesitan algoritmos más eficientes e inteligentes para solucionarlos. El aprendizaje por refuerzo a partir de la retroalimentación humana (RLHF), como algoritmo de aprendizaje por refuerzo, puede utilizar de manera efectiva la información de retroalimentación proporcionada por humanos para entrenar modelos grandes y mejorar su rendimiento. Este artículo presentará cómo usar RLHF para optimizar modelos grandes y proporcionar un soporte más potente para sus aplicaciones.
La siguiente es la estructura del artículo.
Optimización de modelos grandes mediante RLHF: mejora del rendimiento y la capacidad de aplicación
Preentrenar un modelo de lenguaje (LM)
El objetivo del pre-entrenamiento es dotar al modelo lingüístico de información estadística sobre el idioma, para que pueda predecir la probabilidad de aparición de palabras según el contexto. Se puede pensar en un modelo de lenguaje como una "máquina de finalización" que, dado un mensaje de texto, puede generar un texto de respuesta para completar el mensaje. A través del entrenamiento previo, obtenemos un modelo de lenguaje grande (LLM), también conocido como modelo preentrenado.
Una vez que tenga un modelo de lenguaje entrenado previamente, puede realizar un paso opcional adicional de ajuste fino supervisado (STF). En el ajuste fino supervisado, usamos pares de texto anotado por humanos (entrada, salida) para ajustar un modelo previamente entrenado para hacerlo mejor para una tarea específica. STF se considera una inicialización de alta calidad de RLHF, lo que sienta una buena base para el proceso RLHF posterior.
Al final de este paso, tenemos el modelo de lenguaje entrenado, nuestro modelo principal. Este modelo maestro es el que esperamos entrenar más con RLHF, a través del cual mejorará continuamente sus capacidades generativas en función de la retroalimentación humana.

Vale la pena mencionar que en la etapa de pre-formación, diferentes instituciones de investigación pueden adoptar diferentes modelos y métodos. Por ejemplo, OpenAI usa una versión más pequeña de GPT-3 en su popular modelo RLHF InstructGPT, Anthropic usa un modelo Transformer con una gran cantidad de parámetros y DeepMind usa su propio modelo de parámetros enorme Gopher. Además, al afinar el modelo pre-entrenado, algunas instituciones pueden usar texto o condiciones adicionales. Por ejemplo, OpenAI afina el texto generado artificialmente como "preferible", mientras que Anthropic usa el criterio de "útil, honesto e inofensivo". en contexto El modelo original se destila en el hilo. Estos pasos de ajuste fino pueden implicar datos de aumento costosos, pero no son necesarios para RLHF. Debido a que RLHF aún es un campo inexplorado, no hay una respuesta clara sobre qué modelo es adecuado como punto de partida para RLHF, por lo que diferentes instituciones pueden experimentar con diferentes enfoques.
Ajuste fino supervisado (SFT) del diálogo
El objetivo del ajuste fino supervisado (SFT) es optimizar un modelo previamente entrenado para que pueda generar las respuestas esperadas por los usuarios. En la etapa de pre-entrenamiento, el modelo optimiza su capacidad predictiva para textos completos mediante el aprendizaje de una gran cantidad de datos lingüísticos. Esto significa que cuando le hacemos una pregunta al modelo pre-entrenado, como "cómo aprender a programar", puede generar múltiples formas plausibles de hacerlo, como:
- Agregar contexto de pregunta: para principiantes
- Se agregó una pregunta de seguimiento: ¿Qué lenguajes de programación necesito aprender? ¿Cuánto tiempo lleva aprender a programar?
- Dé la respuesta directamente: aprender a programar requiere dominar la sintaxis y los algoritmos de programación.
De estas opciones, la tercera es la más adecuada si realmente queremos una respuesta. El objetivo del ajuste fino supervisado es optimizar el modelo preentrenado para hacerlo más propenso a generar las respuestas esperadas por los usuarios.
Al implementar el ajuste fino supervisado, le mostramos al modelo de lenguaje ejemplos de diferentes casos de uso (por ejemplo, respuesta a preguntas, resumen, traducción, etc.) para decirle al modelo cómo responder a estas señales de manera adecuada. El formato de estos ejemplos es (mensaje, respuesta), a menudo denominado datos de demostración. OpenAI llama a este enfoque de ajuste fino supervisado "clonación de comportamiento": le muestra al modelo cómo debe comportarse y el modelo clona ese comportamiento.
Como ejemplo, supongamos que tenemos un modelo de lenguaje preentrenado y queremos optimizar su rendimiento en escenarios de respuesta a preguntas. Podemos alimentar el modelo con varios ejemplos de respuestas a preguntas como:
- Indicación: "Por favor, dime cómo hacer brownies".
- Respuesta: "Primero prepara el chocolate, la harina, los huevos y la leche. Luego sigue la receta y finalmente hornea por unos 30 minutos".
- Pregunta: "¿Cuál es el planeta más grande del sistema solar?"
- Respuesta: "El planeta más grande del sistema solar es Júpiter".
Con ejemplos como este, enseñamos al modelo a responder correctamente diferentes tipos de preguntas. Con un ajuste fino supervisado, el modelo aprende gradualmente a generar las respuestas deseadas por el usuario a partir de las indicaciones, por lo que se adapta mejor a tareas y casos de uso específicos. A través de este paso, nuestro modelo principal se volverá gradualmente más inteligente y preciso, sentando las bases para la siguiente etapa RLHF. La siguiente figura es una ilustración simple del ajuste fino supervisado.

Entrenar el modelo de recompensa
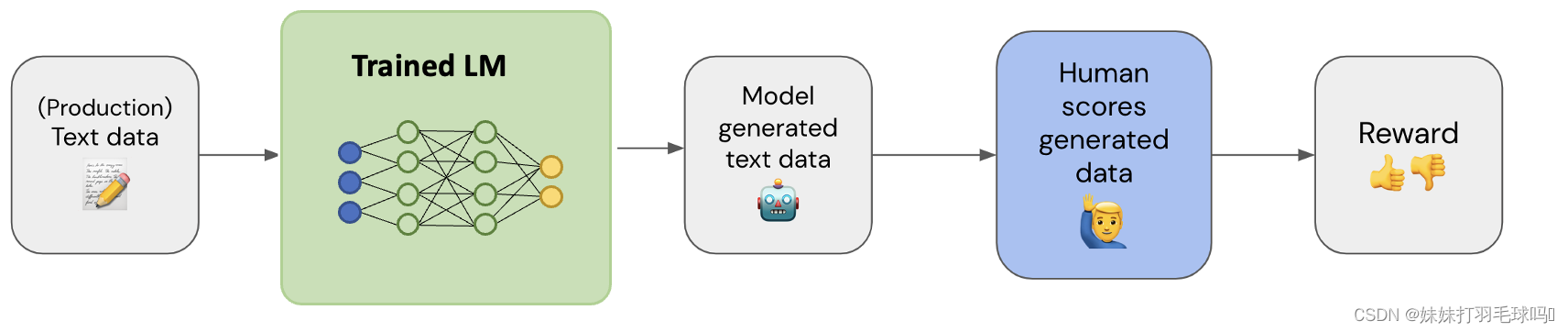
En este paso, nuestro objetivo es recopilar un conjunto de datos que contenga (texto de entrada, texto de salida, recompensa) triples.
Como se muestra en la figura anterior: use datos de texto de entrada (preferiblemente datos de producción), genere el texto de salida correspondiente a través de su modelo y asigne un valor de recompensa al texto de salida generado por humanos.
El valor de la recompensa suele estar entre 0 y 5, y también puede representarse como 0/1.
La tarea del modelo de recompensa (RM) es entrenar un modelo con un par (solicitud, respuesta) y una puntuación de recompensa. La salida de una puntuación en una entrada determinada es una tarea muy común en el aprendizaje automático, que puede verse como una clasificación. o misión de retorno. El modelo puntúa cada resultado desde la entrada de texto hasta la salida de texto para evaluar el rendimiento del modelo .
Para calcular el modelo de recompensa óptimo, usamos modelos grandes con diferentes parámetros (con diferentes ajustes finos o sin ajustes finos) para generar diferentes respuestas, y las puntuaciones de recompensa pueden ser diferentes. El propósito de optimizar el modelo de recompensa es hacer la misma entrada rápida a la salida de respuesta en diferentes modelos grandes tanto como sea posible, y las recompensas obtenidas al final son similares.
Ajuste: r θ r_\thetariPara el modelo de recompensa que se está entrenando, el parámetro del modelo es θ \thetai
XXx:prompt
yw y_wyw: la respuesta ganadora indica la respuesta con la mayor recompensa entre estos grandes resultados del modelo
yl y_lyyo: perder respuesta significa que estas salidas de modelos grandes obtienen la respuesta con la recompensa más baja
Para cada muestra de entrenamiento ( x , yw , yl ) (x, y_w, y_l)( X ,yw,yyo) , con:
sw = r θ ( x , yw ) s_w=r_\theta(x,y_w)sw=ri( X ,yw) : La puntuación del modelo de recompensa por la respuesta ganadora
sl = r θ ( x , yl ) s_l=r_\theta(x,y_l)syo=ri( X ,yyo) : La puntuación del modelo de recompensa por la respuesta perdedora
Valor de pérdida: − log ( σ ( sw − sl ) ) −log(\sigma(s_w−s_l))- l o gramo ( σ ( sw−syo))
Para entender mejor lo que hace esta función de pérdida, visualicémosla. Sea d = sw − sld=s_w−s_ld=sw−syo. Lo siguiente es f ( d ) = − log ( σ ( d ) ) f(d)=−log(\sigma(d))f ( re )=Gráfico de - l o gramo ( σ ( re )) . Para d negativa, el valor de pérdida es grande, lo que anima al modelo de recompensa a no hacer que la puntuación de la respuesta ganadora sea inferior a la puntuación de la respuesta perdedora.
En cuanto al valor de las recompensas de entrenamiento, es necesario clasificar manualmente las respuestas generadas por LM.
Para métodos de clasificación específicos, un enfoque exitoso es comparar la salida de diferentes LM con el mismo aviso y luego usar el sistema Elo para construir una clasificación completa. Estos diferentes resultados de clasificación se normalizarán a un valor de recompensa escalar para el entrenamiento.
Mecanismo ELo para jugar la gloria del rey, League of Legends debería ser familiar
Al derivar un modelo de recompensa, brindamos una medida confiable para el proceso RLHF posterior.
Ajuste fino con aprendizaje por refuerzo
El ajuste fino del aprendizaje por refuerzo es uno de los pasos clave en RLHF. Ayuda a entrenar modelos de lenguaje para poder generar respuestas más apropiadas a las indicaciones del usuario. Sin embargo, dado que la recompensa de salida en sí misma no es diferenciable, necesitamos usar el aprendizaje por refuerzo (RL) para construir una función de pérdida para poder retropropagar el LM.
Los grandes implementan técnicas de aprendizaje por refuerzo a través de la divergencia Kullback-Leibler (KL) y la optimización de políticas proximales (PPO).
Para ilustrar mejor por qué el aprendizaje por refuerzo se puede aplicar a LM, primero formulamos la tarea de ajuste fino como un problema de RL.
La política es un LM que toma una pista y devuelve una secuencia de textos (o una distribución de probabilidad de textos). El espacio de acción de esta estrategia son todos los tokens correspondientes al vocabulario LM (generalmente del orden de 50k), y el espacio de observación es la posible secuencia de tokens de entrada, que también es relativamente grande (vocabulario ^ cantidad de tokens de entrada). La función de recompensa es una combinación de un modelo de preferencia y una restricción de cambio de política.
Como se muestra en la figura a continuación, lo comprenderá mejor en comparación con el aprendizaje de refuerzo general.Al


comienzo del entrenamiento, crearemos un LM que es exactamente igual al LM con sus pesos entrenables congelados. Este modelo ayudará a evitar que un LM entrenable cambie por completo sus pesos y comience a generar texto sin sentido para satisfacer el modelo de recompensa.
Hacemos esto calculando la divergencia KL de la secuencia de distribuciones de salida de texto (distribuciones de probabilidad) entre los valores LM congelados y no congelados como una función de pérdida.
Con la recompensa y la pérdida de KL en su lugar, ahora podemos aplicar el aprendizaje por refuerzo para hacer que la pérdida de recompensa sea diferenciable.
Para que la pérdida sea diferenciable, ¡empleamos el algoritmo de optimización de política próxima (PPO)! Los siguientes son los pasos detallados de todo el ajuste fino:
- Paso 1: aprovechar el modelo de recompensas
En primer lugar, las entradas o indicaciones del usuario se envían a una política de RL, que es en realidad una versión optimizada de LM. La política de RL genera una respuesta que es evaluada por el modelo de recompensa junto con la salida del LM inicial. El modelo de recompensa luego genera un valor de recompensa escalar correspondiente a la calidad de la respuesta.
- Paso dos: Introducir un circuito de retroalimentación
Este proceso itera en un ciclo de retroalimentación, con el modelo de recompensa asignando recompensas a tantas muestras como permitan los recursos. Con el tiempo, las respuestas que reciben recompensas más altas guían la política de RL, ayudándola a generar respuestas más acordes con las expectativas humanas.
- Paso 3: Mida la diferencia usando la divergencia KL
La divergencia de Kullback-Leibler (KL), una medida estadística de la diferencia entre dos distribuciones de probabilidad, juega un papel crucial aquí. En RLHF, la divergencia KL se usa para comparar la diferencia entre la distribución de probabilidad de la respuesta actual de la política RL y una distribución de referencia que representa la respuesta ideal o mejor deseada por el ser humano.
- Paso 4: ajuste fino mediante la optimización de políticas proximales
Una parte importante del ajuste fino es la optimización de políticas proximales (PPO). PPO es un conocido algoritmo de aprendizaje por refuerzo conocido por su eficacia en la optimización de políticas en entornos complejos con estados de alta dimensión y espacios de acción. PPO es especialmente útil durante el ajuste fino de RLHF porque equilibra eficazmente la exploración y la explotación durante el entrenamiento. Para los agentes de RLHF, este equilibrio es fundamental para aprender de los comentarios humanos y la exploración de prueba y error. Por lo tanto, la integración de PPO permite un aprendizaje más rápido y sólido.
- Paso cinco: Evite las respuestas inapropiadas
El proceso de ajuste fino ayuda a evitar que los modelos de lenguaje produzcan resultados inapropiados o sin sentido. Dado que es menos probable que se repitan las respuestas con recompensas bajas, el modelo de lenguaje se ve impulsado a producir un resultado que está más en línea con las expectativas humanas.
El algoritmo PPO calcula la fórmula de pérdida y la explicación del diagrama (para pequeñas actualizaciones de LM) de la siguiente manera:
- Establezca "Pruebas iniciales" en "Probaciones nuevas" para inicializar.
- Calcula la relación entre la probabilidad del texto de salida nuevo y la probabilidad del texto de salida inicial.
- pérdida de corriente = r θ ( y ∣ x ) − λ KLDKL ( π ppo ( y ∣ x ) ∣ ∣ π base ( y ∣ x ) ) pérdida = r_\theta(y|x)- \lambda_{KL}D_{ KL }(\pi_{ppo}(y|x)||\pi_{base}(y|x))pérdida _=ri( y ∣ x )−yoK LDK L( pagpp o( y ∣ x ) ∣∣ πbase _( y ∣ x )) calcula la pérdida
- Los pesos del LM se actualizan mediante retropropagación.
- Los "nuevos probs" (es decir, las nuevas probabilidades de texto de salida) se calculan utilizando el LM recién actualizado.
- Repita los pasos 2 a 5 N veces (normalmente, N=4).
Los problemas aquí son la probabilidad de salida de texto π ( y ∣ x ) \pi(y|x) del modelo LMπ ( y ∣ x )

Ventajas y limitaciones de RLHF
El aprendizaje por refuerzo a partir de la retroalimentación humana (RLHF) proporciona una metodología poderosa para refinar los sistemas de IA. Sin embargo, como cualquier otro enfoque, tiene ventajas obvias y desafíos potenciales.
Ventajas de RLHF:
- Adaptabilidad : RLHF es una estrategia de aprendizaje dinámica que puede adaptarse en función de los comentarios que recibe. Esta adaptabilidad lo hace ideal para una variedad de tareas y le permite adaptar su comportamiento en función de la interacción y la retroalimentación en tiempo real.
- Sesgo reducido : en teoría, RLHF ayuda a reducir el sesgo del modelo. Con comentarios humanos cuidadosamente seleccionados y diversos, estos modelos pueden aprender desde una perspectiva más amplia y representativa, lo que reduce la sobregeneralización o el sesgo inherente a los datos de entrenamiento inicial.
- Mejora Continua : El modelo RLHF tiene la capacidad de mejora continua. A medida que estos modelos interactúan con los usuarios y obtienen más comentarios, pueden aprender y adaptarse, mejorando el rendimiento y la experiencia del usuario.
- Seguridad : RLHF puede desempeñar un papel clave en la mejora de la seguridad de los sistemas de IA. A través de la retroalimentación humana, estos sistemas pueden evitar comportamientos potencialmente dañinos o inapropiados, haciéndolos más seguros para la interacción y el uso.
Desafíos y limitaciones de RLHF:
1. Escalabilidad : La escalabilidad sigue siendo un gran desafío para RLHF. Debido a que estos modelos se basan en la retroalimentación humana para el aprendizaje, ampliarlos para tareas más grandes o más complejas puede requerir muchos recursos y tiempo.
2. Confiar en factores humanos : los modelos RLHF dependen en gran medida de la calidad de la retroalimentación humana. La retroalimentación ineficaz o insuficiente puede conducir a un rendimiento deficiente o incluso, sin darse cuenta, fomentar un comportamiento dañino en el modelo.
3. Sesgo humano : el problema potencial introducido por el sesgo es una preocupación clave de RLHF. La retroalimentación proporcionada por los evaluadores humanos puede estar intrínsecamente sesgada, lo que lleva a un aprendizaje sesgado. Estos sesgos pueden tomar muchas formas, incluido el sesgo de selección, el sesgo de confirmación, la variabilidad entre evaluadores y la retroalimentación limitada.
Vale la pena señalar, sin embargo, que existen estrategias efectivas para mitigar estos sesgos. La selección de evaluadores diversos, la evaluación por consenso, la calibración de los evaluadores, la evaluación regular del proceso de retroalimentación y el desempeño del agente, y los métodos para equilibrar la retroalimentación con otras fuentes pueden ayudar a reducir los efectos del sesgo en RLHF. Estas estrategias subrayan el enfoque reflexivo y sistemático de RLHF, enfatizando la importancia de la evaluación y el ajuste continuos durante el proceso.
A medida que RLHF continúa evolucionando, hay una serie de desafíos y limitaciones adicionales que deben abordarse:
- Interpretación y transparencia : los modelos de lenguaje grande tienden a volverse más opacos a medida que los modelos crecen en tamaño y complejidad. Esto dificulta la explicación del proceso de toma de decisiones del modelo, especialmente después del ajuste con RLHF. Para algunos escenarios de aplicación, especialmente en dominios que requieren interpretabilidad y transparencia, esto puede convertirse en un factor limitante.
- Diseño de recompensas : el diseño de una función de recompensa eficiente es un tema clave en RLHF. La función de recompensa debe reflejar con precisión el rendimiento del modelo y ser lo suficientemente discriminatoria para clasificar diferentes respuestas. Sin embargo, diseñar funciones de recompensa no siempre es intuitivo y simple, especialmente con tareas complejas y respuestas diversas.
- Ejemplos adversarios : el aprendizaje por refuerzo suele ser vulnerable a los ataques de ejemplos adversarios. En RLHF, si el modelo está dirigido, puede generar respuestas no deseadas. Esto requiere consideraciones de robustez y seguridad del modelo durante el entrenamiento RLHF para prevenir ataques de adversarios.
- Eficiencia del entrenamiento : dado que el entrenamiento de modelos grandes requiere muchos recursos informáticos y tiempo, el costo de entrenamiento de RLHF puede ser alto. Esto puede ser un desafío para algunos escenarios de aplicaciones y entornos con recursos limitados.
A pesar de estos desafíos, RLHF continúa evolucionando y mejorando como un poderoso método de aprendizaje. Los investigadores y desarrolladores están trabajando arduamente para resolver estos problemas y promover aún más la aplicación y el desarrollo de RLHF. Al mismo tiempo, la credibilidad de la sociedad y la capacidad de control de los sistemas de inteligencia artificial también están aumentando, y los requisitos de interpretabilidad, transparencia y explicabilidad también recibirán más atención durante el desarrollo de RLHF.
En el futuro, podemos esperar ver más innovaciones y mejoras para hacer de RLHF un método más general y confiable, brindando un soporte más sólido para aplicaciones en varios campos y promoviendo el avance continuo de la tecnología de inteligencia artificial.
epílogo
A medida que el campo de la ciencia de datos y la inteligencia artificial continúa desarrollándose, los modelos de lenguaje a gran escala y RLHF como herramientas poderosas se están convirtiendo gradualmente en componentes importantes en varios campos. A través del entrenamiento previo y el ajuste fino, los modelos de lenguaje a gran escala pueden tener capacidades ricas de expresión del lenguaje, mientras que RLHF puede mejorar continuamente el rendimiento del modelo en función de la retroalimentación humana, haciéndolo más inteligente y adaptable a diferentes tareas.
Sin embargo, también debemos darnos cuenta de que RLHF aún enfrenta algunos desafíos, como la escalabilidad, el sesgo humano, la interpretabilidad, etc. Abordar estos problemas requiere investigación y colaboración interdisciplinaria para garantizar la aplicación de RLHF para enfrentar los desafíos del mundo real de manera segura, confiable y eficiente.
En el futuro, tenemos razones para creer que con el avance continuo de la tecnología y la comprensión profunda de la inteligencia artificial, RLHF continuará creciendo y brindando más beneficios e innovaciones a la sociedad humana. Al mismo tiempo, también debemos prestar mucha atención a los problemas morales y sociales que puedan surgir durante su desarrollo, y continuar promoviendo el equilibrio entre el desarrollo tecnológico y el valor social. Solo de esta manera, RLHF puede convertirse realmente en un impulsor para el desarrollo de la tecnología de inteligencia artificial y crear un futuro mejor para la humanidad.