Tabla de contenido
¿Por qué necesitas alineación de memoria?
Resumen de clases de diseño estándar y triviales
Alineación de memoria para clases de diseño estándar
Clase de diseño estándar ordinaria
Clase de diseño estándar con campos de bits
Una clase de diseño estándar que especifica manualmente el tamaño de alineación
Alineación de memoria para clases de diseño no estándar
Alineación de memoria de GLSLang
Decoración de diseño de búfer.
Como todos sabemos, el programa en ejecución necesita ocupar memoria.Al codificar, se supone que el espacio en la pila es continuo, y todas las variables definidas se distribuyen continuamente en la pila.
De hecho, aunque las variables se distribuyen continuamente en la pila, el compilador reorganizará las variables según diferentes tipos y alineaciones para lograr la situación óptima.
#include <stdio.h>
#define print_position(type, n) \
type n; \
printf(#n ": %p\n", &n);
int main(void) {
print_position(int, a); // a: 0x7ffe84765408
print_position(double, b); // b: 0x7ffe84765410
print_position(char, c); // c: 0x7ffe84765407
print_position(float, d); // d: 0x7ffe8476540c
}
Este artículo se centra principalmente en la alineación de estructuras.
¿Por qué necesitas alineación de memoria?
actuación
Los procesadores modernos tienen múltiples niveles de cachés a través de los cuales deben pasar los datos; admitir lecturas de un solo byte vincula estrechamente el rendimiento de la memoria al rendimiento de la unidad de ejecución (llamados vinculados a la CPU, vinculados a la CPU). Esto tiene muchas razones similares a las que DMA anula PIO en los controladores de hardware.
La CPU siempre lee en tamaño de palabra (4 bytes en un procesador de 32 bits), cuando accede a una dirección no alineada; el procesador lee varias palabras si la CPU lo admite. La CPU leerá la dirección solicitada por el programa a través de palabras, lo que resultará en lecturas y escrituras de memoria del doble del tamaño de los datos solicitados. Por lo tanto, puede darse fácilmente el caso de que leer 2 bytes sea más lento que leer 4 bytes.
Si un dato de dos bytes no está alineado dentro de una palabra, el procesador solo necesita leerlo una vez y realizar un cálculo de compensación, que generalmente toma solo un ciclo.
Además, la alineación puede determinar mejor si están en la misma línea de caché y algunos tipos de aplicaciones optimizarán la línea de caché para lograr un mejor rendimiento.
alcance
Dado un espacio de direcciones arbitrario, si la arquitectura considera que los 2 bits menos significativos (LSB) son siempre 0 (como una máquina de 32 bits), puede acceder a cuatro veces más memoria (2 bits pueden representar 4 estados diferentes), o el memoria del mismo tamaño pero con dos bits de bandera adicionales. 2 bits menos significativos significa alineación de 4 bytes, la dirección solo cambiará desde el segundo bit cuando se incremente, los 2 bits más bajos siempre son 00.
Esto puede afectar la estructura física del procesador, lo que significa dos bits menos en el bus de direcciones, dos pines menos en la CPU o dos cables menos en la placa de circuito.
atomicidad
La CPU puede operar atómicamente en la memoria de palabras alineadas, lo que significa que ninguna instrucción puede interrumpir la operación. Esto es fundamental para el correcto funcionamiento de muchas estructuras de datos sin bloqueo y otros paradigmas de concurrencia .
en conclusión
El sistema de memoria de un procesador es mucho más complejo que lo que se describe aquí, y aquí hay una discusión sobre cómo se abordan realmente los procesadores x86 , lo que sería útil de entender (muchos procesadores funcionan de manera similar).
Hay muchos otros beneficios de insistir en la alineación de la memoria, que se pueden leer en este artículo. El objetivo principal de una computadora es transferir datos, y las arquitecturas y tecnologías de memoria modernas se han optimizado durante décadas para facilitar el procesamiento de más entrada y salida de datos entre más unidades de ejecución y más rápidas de una manera altamente confiable.
modelo de datos
En C y sus lenguajes derivados, en muchos casos, el tamaño del tipo está relacionado con la plataforma, por lo que el modelo de datos se usa para definir el tamaño de los datos en diferentes plataformas.
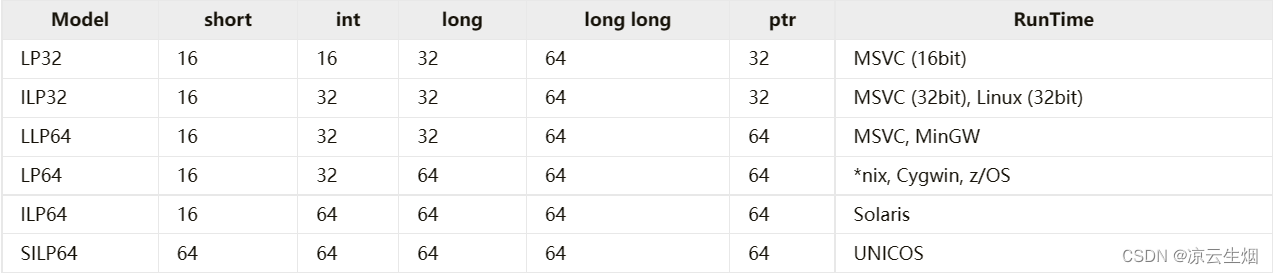
Aunque la definición del modelo de datos es muy clara, cuando se trata de código multiplataforma, el manejo del tamaño del tipo de datos es un dolor de cabeza.
Afortunadamente, C/C++ stdint.h también proporciona más tipos de enteros de longitud fija, las longitudes son principalmente , 8y bit , y proporciona enteros de longitud fija con diferentes requisitos .163264fastleast
- Entero de longitud fija, por ejemplo
uint8_t,int16_t. Los enteros de longitud fija son opcionales para el compilador, por lo que es posible que no haya un tipo específico. La longitud de bits especificada por el tipo entero de longitud fija no puede ser mayor o menor, es decir, la coincidencia de longitud de bits es obligatoria. - El entero de longitud fija más cercano, por ejemplo
int_least16_t,uint_least16_t. El entero de longitud fija más cercano puede ser mayor pero nunca menor que la longitud de bits especificada. Como usaruint_least8_t, pero la plataforma no lo admite,uint16_tpero lo admiteuint32_t, por lo que el tipo esuint32_t. - El entero de longitud fija más rápido, por ejemplo
int_fast32_t,uint_fast32_t. El tipo de entero de longitud fija más rápido se refiere al tipo de entero que puede ser mayor pero no menor que la longitud de bit especificada, y el tipo de entero de ejecución más rápida se usa cuando se satisface la longitud de bit especificada. Como usaruint_fast8_t, la plataforma admiteuint32_tyuint16_t, pero la más rápida esuint32_t, por lo que la primera se usa para este tipo.
Finalmente, debido a que los punteros tienen diferentes tamaños en diferentes plataformas, al convertir números enteros de bits de puntero, puede elegir la suma opcional de la biblioteca estándar para la intptr_t compatibilidad entre plataformas uintptr_t.
Alineación de memoria C++
El modelo de datos en este capítulo es el modelo de datos LP64
solicitud de firma
clase ordinaria
Primero, 可平凡复制类型 cumplir con todas las siguientes condiciones
- Al menos uno sin descartar
复制构造函数,移动构造函数o复制赋值运算符移动赋值运算符 - Cada constructor de copia es trivial o eliminado
- Cada constructor de movimiento es trivial o eliminado
- Cada operador de asignación de copia es trivial o se elimina
- Cada operador de asignación de movimiento es trivial o se elimina
- tiene un destructor trivial no eliminado
Uno 平凡类, cumpliendo todas las siguientes condiciones
- es un tipo trivialmente copiable
- tiene uno o más constructores predeterminados, todos triviales o eliminados, y al menos uno de ellos no se elimina
struct A {}; // is trivial
struct B { B(B const&) = delete; }; // is trivial
struct C { C() {} }; // is non-trivial
struct D { ~D() {} }; // is non-trivial
struct E { ~E() = delete; }; // is non-trivial
struct F { private: ~F() = default; } // is non-trivial
struct G { virtual ~G() = default; } // is non-trivial
struct H {
H() = default;
H(const H &) = delete;
H(H &&) noexcept = delete;
H &operator=(H const &) = delete;
H &operator=(H &&) noexcept = delete;
~H() = default;
}; // is non-trivial
struct I { I() = default; I(int) {} }; // is trivial
struct J {
J() = default;
J(const J &) {}
}; // is non-trivial
struct K { int x; }; // is trivial
struct L { int x{0}; }; // is non-trivial
Si compila con gcc o clang, encontrará que el compilador muestra Ey F son H clases ordinarias. De acuerdo con el estándar, no deberían ser clases ordinarias. Puede consultar los informes de errores de gcc y clang en bugzilla.
Además, las clases copiables trivialmente se pueden usar para copiar ::memcpy o ::memmove copiar entre dos objetos sin superposición potencial.
struct A { int x; };
A a = { .x = 10 }; // C++20
A b = { .x = 20 };
::memcpy(&b, &a, sizeof(A)); // b.x = 10
Se puede considerar que las clases ordinarias no contienen recursos, por lo que los objetos se pueden sobrescribir o descartar directamente sin causar fugas de recursos.
template <typename T, size_t N>
void destroy_array_element(
typename ::std::enable_if<::std::is_trivial<T>::value>::type (&/* arr */)[N]) {}
template <typename T, size_t N> void destroy_array_element(T (&arr)[N]) {
for (size_t i = 0; i < N; ++i) {
arr[i].~T();
}
}
Clase de diseño estándar
Una clase de diseño estándar que cumple todas las condiciones siguientes
- todos los miembros de datos no estáticos son tipos de clase de diseño estándar o referencias a ellos
- Sin funciones virtuales y clases base virtuales
- Todos los miembros de datos no estáticos tienen la misma accesibilidad
- Sin clase base para diseños no estándar
- Los miembros de datos no estáticos y los campos de bits de esta clase y todas sus clases base se declaran primero en la misma clase
- Dada la clase S, y como clase base el conjunto
M(S)no tiene elementos, donde M(X) para el tipo X se define como sigue:- Si X es un tipo de clase no unido sin miembros de datos no estáticos (posiblemente heredados), entonces el conjunto M(X) está vacío.
- Si X es un tipo de clase sin unión cuyo primer miembro de datos no estáticos (posiblemente una unión anónima) tiene el tipo X0, entonces el conjunto M(X) contiene elementos de X0 y M(X0).
- Si X es un tipo de unión, el conjunto M(X) es la unión del conjunto que contiene todos los conjuntos UiU_{i}Ui y cada conjunto M(UiU_{i}Ui), donde cada UiU_{i}Ui es el tipo del iésimo miembro de datos no estático de X .
- Si X es un tipo de matriz cuyo tipo de elemento es XeX_{e}Xe, el conjunto M(X) contiene elementos de XeX_{e}Xe y M(XeXeXe).
- Si X no es un tipo de clase o un tipo de matriz, entonces el conjunto M(X) está vacío.
struct A { int a; }; // is standard layout
struct B : public A { double b; }; // isn't standard layout
struct C { A a; double b; }; // is standard layout
struct D {
int a;
double b;
}; // is standard layout
struct E {
public: int a;
private: double b;
}; // isn't standard layout
struct F {
public: int fun() { return 0; }
private: double a;
}; // is standard layout
Resumen de clases de diseño estándar y triviales
Obviamente, todos los tipos en el lenguaje C tienen un diseño estándar, pero C++ introduce el concepto de POD (datos antiguos simples) para representar estos tipos en C (C++20 eliminó este concepto), es decir, se cumplen todas las condiciones siguientes el tipo:
- clase ordinaria
- Clase de diseño estándar
- Todos los miembros de datos no estáticos son del tipo de clase POD
Se puede entender que la clase ordinaria especifica que un tipo no se preocupa por ningún recurso, es decir, los métodos más básicos de construcción y destrucción; la clase de diseño estándar especifica cómo un tipo presenta cada campo. Siempre que sea una clase de diseño estándar, se puede operar sin problemas con programas C, pero este tipo puede no ser un tipo trivial, por lo que el POD se divide en dos conceptos.
Lo mejor que hay que entender es que ::std::vectorusa RAII para administrar recursos por sí mismo, con construcciones complejas y destructores. No es una clase ordinaria, pero es una clase de diseño estándar , por lo que sigue completamente el método de alineación de memoria, y también puede ser used memcpy Copia su valor interno.
// #include <stdint.h>
// #include <stdlib.h>
// #include <string.h>
// #include <iostream>
// #include <vector>
::std::vector<char> v{'a', 'b', 'c'};
uintptr_t *copy = reinterpret_cast<uintptr_t *>(::alloca(sizeof v));
::memcpy(copy, &v, sizeof v);
for (size_t i = 0, e = sizeof(v) / sizeof(uintptr_t); i < e; ++i) {
::std::cout << copy[i] << ::std::endl;
}
// maybe output:
// 94066226852544
// 94066226852547
// 94066226852547
Alineación de memoria para clases de diseño estándar
Hay algunas reglas a seguir para la alineación de la memoria:
- La dirección inicial del objeto es divisible por su tamaño de alineación
- El desplazamiento del miembro en relación con la dirección de inicio puede ser divisible por su propio tamaño de alineación; de lo contrario, complete los bytes después del miembro anterior
- El tamaño de la clase es divisible por su tamaño de alineación; de lo contrario, complete los bytes al final
- Si es una clase vacía, los objetos de esta clase deben ocupar un byte según el estándar (a menos que se optimice la clase base vacía ), y el tamaño de una clase vacía en C es de 0 bytes
- De forma predeterminada, el tamaño de alineación de un tipo es el mismo que el tamaño de alineación máximo de todos sus campos
Clase de diseño estándar ordinaria
Para cualquier clase de diseño estándar, puede usar fácilmente las reglas anteriores para determinar el tamaño del tipo
struct S {}; // sizeof = 1, alignof = 1
struct T : public S { char x; }; // sizeof = 1, alignof = 1
struct U {
int x; // offsetof = 0
char y; // offsetof = 4
char z; // offsetof = 5
}; // sizeof = 8, alignof = 4
struct V {
int a; // offsetof = 0
T b; // offsetof = 4
U c; // offsetof = 8
double d; // offsetof = 16
}; // sizeof = 24, alignof = 8
struct W {
int val; // offset = 0
W *left; // offset = 8
W *right; // offset = 16
}; // sizeof = 24, alignof = 8
Finalmente, quiero explicar la matriz. La matriz es como si hubiera introducido la longitud de la matriz y las variables de este tipo en esta posición.
struct S { int x[4]; }; // sizeof = 16, alignof = 4
struct T {
int a; // offsetof = 0
char b[9]; // offsetof = 4
short c[2]; // offsetof = 14
double *d; // offsetof = 24
}; // sizeof = 32, alignof = 8
struct U {
char x; // offsetof = 0
char y[1]; // offsetof = 1
short z; // offsetof = 2
}; // sizeof = 4, alignof = 2
¿Crees que este es el final? Por supuesto que no, hay un uso muy interesante en el lenguaje C, es decir, la declaración de matriz flexible que apareció en C99 . Defina el último campo como una matriz con una longitud de 0. En este momento, el tipo de datos subyacente de la matriz afectará el tamaño de alineación del tipo, pero no afectará el tamaño de todo el tipo. Por supuesto, no hay soporte para el estándar C++ y depende completamente del compilador para expandirse.
struct S {
int i; // offset = 0
double d[]; // offset = 8
}; // sizeof = 8, alignof = 8
struct T {
int i; // offset = 0
char c[0]; // offset = 4
}; // sizeof = 4, alignof = 4
Las clases con miembros de matriz flexibles necesitan usar asignación dinámica, porque los miembros de matriz flexibles no se pueden inicializar. De hecho, el compilador no puede determinar la longitud de la matriz, por lo que incluso si el espacio adicional proporcionado no es suficiente para almacenar los datos de tipo subyacentes, el programador garantiza la corrección del acceso y el desbordamiento del alcance del acceso será UB. .
S s1; // sizeof(s1) = 8, length(d) = 1, accessing d is a UB
// S s2 = {1, {3.14}}; // error: initialization of flexible array member is not allowed
S* s3 = reinterpret_cast<S*>(alloca(sizeof(S))); // equivalent to s1
// s4: sizeof(*s4) = 8, length(d) = 6
S *s4 = reinterpret_cast<S *>(alloca(sizeof(S) + 6 * sizeof(S::d[0])));
// s5: sizeof(*s5) = 8, length(d) = 1, accessing d[1] is a UB
S *s5 = reinterpret_cast<S *>(alloca(sizeof(S) + 10));
*s4 = *s5; // copy size = sizeof(S)
Clase de diseño estándar con campos de bits
Para las clases de diseño estándar con campos de bits, también es muy simple. Los campos de bits no se almacenarán en los datos subyacentes, es decir, cuando los bits restantes no sean suficientes, el siguiente campo de bits se almacenará en el siguiente campo subyacente. datos. El campo de campo de bits sin nombre puede desempeñar un papel de marcador de posición. Además, después de declarar el campo de bits, en realidad se llenará con datos subyacentes en la clase, y el tamaño y la alineación de la clase se verán afectados por los datos subyacentes.
struct S {
// offsetof = 0
unsigned char b1 : 3, : 2;
// offsetof = 1
unsigned char b2 : 6, b3 : 2;
}; // sizeof = 2, alignof = 1
El tamaño de un campo de bits se puede especificar como 0, lo que significa que el siguiente campo de bits se declarará en los siguientes datos subyacentes. Pero el campo de campo de bits de longitud 0 real no introduce datos subyacentes para la clase.
struct S { int : 0; }; // sizeof = 1, alignof = 1
struct T {
uint64_t : 0;
uint32_t x; // offsetof = 0
}; // sizeof = 4, alignof = 4
struct U {
// offsetof = 0
unsigned char b1 : 3, : 0;
// offsetof = 1
unsigned char b2 : 2;
}; // sizeof = 2, alignof = 1
Una clase de diseño estándar que especifica manualmente el tamaño de alineación
Volviendo a las cinco reglas al principio de este capítulo, de hecho, también es aplicable cuando se especifica la alineación manualmente.
#pragma pack(N) Al especificar y gnu::packed organizar campos, se lleva a cabo de forma empaquetada, es decir, cada campo se organiza de forma continua y no se generarán huecos de memoria adicionales entre campos, lo que puede reducir el desperdicio innecesario de memoria.
struct [[gnu::packed]] S {
uint8_t x; // offsetof = 0
uint16_t y; // offsetof = 1
}; // sizeof = 3, alignof = 1
struct [[gnu::packed]] T {
uint16_t x : 4;
uint8_t y; // offsetof = 1
}; // sizeof = 2, alignof = 1
struct [[gnu::packed]] alignas(4) U {
uint8_t x; // offsetof = 0
uint16_t y; // offsetof = 1
}; // sizeof = 4, alignof = 4
struct [[gnu::packed]] alignas(4) V {
uint16_t x : 4;
uint8_t y; // offsetof = 1
}; // sizeof = 4, alignof = 4
Pero hoy el foco está en alignas los declaradores introducidos por C++11. De hecho, no solo puede especificar cómo alinear la estructura, sino también especificar cómo alinear un objeto. El tamaño de alineación especificado debe ser una potencia entera positiva de 2. Si la alineación especificada es más débil que la alineación predeterminada, el compilador puede ignorarla o informar un error.
Lo más simple es comenzar con la declaración de la estructura especificada.
struct alignas(4) S {}; // sizeof = 4, alignof = 4
struct SS {
S s; // offsetof = 0
S *t; // offsetof = 8
}; // sizeof = 16, alignof = 8
struct alignas(SS) T {
S s; // offsetof = 0
char t; // offsetof = 4
short u; // offsetof = 6
short v; // offsetof = 8
}; // sizeof = 16, alignof = 8
struct alignas(1) U : public S {}; // error or ignore
// struct alignas(5) V : public S {}; // error
struct alignas(4) W : public S {};
alignas La aplicación de es principalmente para obtener un mejor rendimiento o para hacer coincidir las instrucciones SIMD.
Alineación de memoria para clases de diseño no estándar
Para las clases de diseño no estándar causadas por restricciones de acceso, no podemos asumir que están diseñadas de acuerdo con el diseño estándar y su comportamiento depende del compilador. En el estándar C++11, solo se garantiza que las variables con el mismo acceso se ordenen en el orden de declaración, pero no se garantiza el orden de las variables con diferente acceso.
struct S {
public: int s;
int t;
private: int u;
public: int v;
};
Es decir, en el ejemplo anterior, solo está garantizado &S::s < &S::t < &S::v, pero no garantizado &S::s < &S::u. En otras palabras, en la memoria, s, t, u, v el orden en que puede aparecer y u, s, t, v el orden en que puede aparecer.
Por supuesto, no sólo los problemas de orden causados por la accesibilidad, sino también los campos declarados en diferentes clases causarán problemas de orden. En otras palabras, no podemos asumir que las variables declaradas en la clase base deben ubicarse antes que las variables declaradas en la clase derivada.
struct S { int s; };
struct T { int t; };
struct U : public S, T { int u; };
Dicho esto, en el ejemplo anterior, no hay garantías &U::s < &U::u. Pero el estándar garantiza que cuando un puntero de clase derivado se convierte en un puntero de clase base, el desplazamiento del objeto de palabra de clase base se calcula automáticamente. Pero no hay garantía de que la primera dirección del objeto de U sea la primera dirección de la palabra objeto de S.
U *up = reinterpret_cast<U *>(alloca(sizeof(U)));
S *ssp = static_cast<S *>(up); // offset adjustment
T *stp = static_cast<T *>(up); // offset adjustment
S *rsp = reinterpret_cast<S *>(up); // no offset adjustment
T *rtp = reinterpret_cast<T *>(up); // no offset adjustment
Finalmente, hablemos sobre la alineación de la memoria de las clases virtuales, que es una pregunta muy interesante. El estándar no especifica cómo implementar funciones virtuales, pero la mayoría de los compiladores usan tablas virtuales para implementarlas, es decir, insertan un puntero a una tabla de funciones virtuales en el objeto. Pero debe tenerse en cuenta que la tabla virtual solo existe en un objeto y no habrá ninguna tabla virtual en el subobjeto de la clase base.
struct S {
bool s; // offsetof = 0
}; // sizeof = 1, alignof = 1
struct T {
virtual ~T() = default;
int t;
};
struct U : public S, T {
virtual ~U() = default;
int u;
};
En la implementación del compilador, es probable que primero organice las clases base virtuales y luego las clases base no virtuales, por lo que el tamaño y el diseño de la clase no se pueden determinar en diferentes arreglos.
Alineación de memoria de GLSLang
GLSL 4.60, encuadernación Vulkan
En GLSLang, una palabra tiene una longitud de 4 bytes. La alineación en GLSLang también es muy similar a la de C/C++, por lo que la alineación descrita en la alineación de memoria de la clase de diseño estándar es básicamente la misma que aquí. Además, el tamaño del tipo básico en GLSLang es un múltiplo de la longitud de la palabra, por lo que la sizeof unidad de resultado subsiguiente tiene como valor predeterminado la palabra.
Decoración de diseño de búfer.
buffer Como objeto global de lectura y escritura, su diseño está definido por la implementación a menos que se especifique manualmente. uniform Es un búfer global especial, solo legible, el diseño predeterminado std140 y no se puede modificar; push_constant es un uniforme especial, que se almacena en un registro, con un tamaño de aproximadamente 16 palabras. La implementación puede usar uniforme en su lugar. Cuando el tamaño se excede, también será La parte sobrante se almacena en el búfer uniforme, el diseño predeterminado es std430, el diseño se puede modificar.
En el búfer, la matriz predeterminada es la matriz principal de columnas ( column_major ), que se puede modificar en el diseño
layout(binding = 0, column_major) buffer CMTest {
// matrix stride = 16
mat2x3 cm; // is equalent to 2-elements array of vec3
};
layout(binding = 1, row_major) buffer RMTest {
// matrix stride = 8
mat2x3 rm; // is equalent to 3-elements array of vec2
};
packedEs coherente con el concepto de la CPU, organizar los campos de la forma más compacta posible, ahorrar memoria, independientemente de la alineación. Sin embargo, SPIRV prohíbe el uso packedy el shareddiseño.
En el diseño de GLSLang, el desplazamiento también es un múltiplo entero del tamaño de la alineación. El diseño std140 tiene las siguientes reglas
- Un tipo escalar cuyo tamaño alineado es el mismo que su propio tamaño
- Un vector binario o cuaternario con un tipo subyacente de tamaño N, el tamaño del vector es el mismo que el tamaño de la alineación y el tamaño de la alineación es 2N2N2N o 4N4N4N. En particular, el tamaño del vector ternario es 3N3N3N, pero el tamaño de alineación es 4N4N4N
- Rellene cada elemento de la matriz con un múltiplo de 4 palabras
- El tamaño de alineación de la variable de estructura se rellena con un múltiplo de 4 palabras
- Una matriz de columnas principales con columnas C y filas R es equivalente a una matriz con vectores de elementos C R; de manera similar, una matriz con matrices de columnas principales de N elementos es equivalente a una matriz con matriz N×CN \times CN×C de vectores de elementos R
- Una matriz de filas principales con columnas C y filas R es equivalente a una matriz con vectores de elementos R C; de manera similar, una matriz con matrices de filas principales de N elementos es equivalente a una matriz con matriz N×RN \times RN×R de vectores de elementos C
struct S {
vec2 v;
};
layout(binding = 0, std140) buffer BufferObject {
mat2x3 m; // offsetof = 0
bool b[2]; // offsetof = 8
vec3 v1; // offsetof = 16
uint u; // offsetof = 19
S s; // offsetof = 20
float f2; // offsetof = 24
vec2 v2; // offsetof = 26
dvec3 dv; // offsetof = 32
} bo; // sizeof = 40, alignof = 8
Para el diseño std430, ya no existe el requisito en std140 de alinear y llenar la matriz y los elementos de estructura en 4 palabras, es decir, std430 es más compacto y más cercano a nuestro diseño en la CPU.
struct S {
vec2 v;
};
layout(binding = 0, std430) buffer BufferObject {
mat2x3 m; // offsetof = 0
bool b[2]; // offsetof = 8
vec3 v1; // offsetof = 12
uint u; // offsetof = 15
S s; // offsetof = 16
float f2; // offsetof = 18
vec2 v2; // offsetof = 20
dvec3 dv; // offsetof = 24
} bo; // sizeof = 32, alignof = 8
Aunque el diseño predeterminado ya es muy bueno, a veces puede modificar manualmente el desplazamiento de los siguientes campos. Necesita ser usado en este momento offset. Pero el compilador no verifica si las compensaciones establecidas manualmente se superponen con otros campos.
layout(binding = 0, std430) buffer BufferObject {
mat2x3 m; // offsetof = 0
bool b[2]; // offsetof = 8
layout(offset = 48) uint u; // offsetof = 12
vec2 v; // offsetof = 14
layout(offset = 0) int i; // offset = 0
} bo;
align El uso de la CPU también es similar al uso de la CPU mencionado anteriormente.
layout(binding = 0, std430) buffer BufferObject {
vec2 a; // offsetof = 0
layout(align = 16) float b; // offsetof = 4
} bo; // sizeof = 8, alignof = 4
ubicación
La ubicación es equivalente a un punto de almacenamiento para cada transmisión de datos de shader, y la ubicación se compara según el número, que coincide con el shader anterior in y el shader siguiente out. La misma ubicación no se puede declarar varias veces en el shader, dentro y fuera son ubicaciones completamente diferentes.
layout(location = 0) in vec2 i;
// layout(location = 0) in vec2 i2; // error
layout(location = 0) out vec2 o; // okay
El tamaño de la ubicación es de 4 palabras. Cada variable declarada ocupa una ubicación, y cuando el tamaño de la variable sea mayor a 4 palabras, ocupará la siguiente ubicación.
layout(location = 0) in dvec4 dv;
// location = 1, occupied by dv
// layout(location = 1) in vec4 v; // error
layout(location = 2) in vec4 v;
Cada elemento de la matriz ocupa una ubicación, y el valor de ubicación ocupado por el elemento se incrementa secuencialmente, por lo que
layout(location = 0) in float a[2];
// location = 1, occupied by a[1]
layout(location = 2) in float f1;
layout(location = 3) in mat2 m[2]; // cxr matrix is equialent to c-elements array of r-vector
// location = 4, occupied by m[0]
// location = 5, occupied by m[1]
// location = 6, occupied by m[1]
layout(location = 7) in float f2;
Es demasiado complicado especificar ubicaciones una por una, por lo que puede usarlo block para especificar el valor de ubicación inicial de la primera variable y luego dejar que los valores de ubicación de otras variables aumenten automáticamente.
layout(location = 3) in block {
float a[2]; // location = 3
mat2 m; // location = 5
vec2 v; // location = 7
layout(location = 0) mat2 m2; // location = 0
bool b; // location = 2
// vec3 v3; // error
layout(location = 8) vec3 v3; // location = 8
};
También puede usar struct para incrementar la ubicación, pero la diferencia es que la ubicación no se puede especificar en struct.
layout(locaton = 3) in struct {
vec3 a; // location = 3
mat2 b; // location = 4, 5
// layout(location = 6) vec2 c; // error
};
Dije antes que el tamaño de una ubicación es de 4 palabras. Si una ubicación solo usa una parte de ella para almacenar variables, obviamente es ineficiente. component Puede especificar el desplazamiento de la variable en la ubicación. Sin embargo, debe tenerse en cuenta que la parte restante del componente después del desplazamiento debe poder almacenar la variable.
layout(location = 0, component = 0) in float x; // l = 0, c = 0
layout(location = 0, component = 1) in float y; // l = 0, c = 1
layout(location = 0, component = 2) in float z; // l = 0, c = 2
layout(location = 1) in vec2 a; // l = 1, c = 0
// layout(location = 1, component = 2) in dvec3 b; // error
layout(location = 2, component = 0) in float b; // l = 2, c = 0
layout(location = 2, component = 1) in vec3 c; // l = 2, c = 1
Si se especifica el componente de la matriz, cada elemento de la matriz seguirá ocupando cada ubicación de forma incremental, pero la posición inicial de cada ubicación es el componente especificado.
layout(location = 0, component = 2) in float f[6]; // every element c = 2
// layout(location = 2, component = 0) in vec4 v; // error
layout(location = 1, component = 0) in vec2 v; // l = 1, c = 0
// f[1] at location 1, component 2
Pasar datos con GLM y GLSLang
La razón para escribir este artículo es que se encontró un error relacionado con la alineación al transferir datos entre el host y el dispositivo.
struct PCO {
uint32_t time; // offsetof = 0
::glm::vec2 extent; // offsetof = 4
}; // sizeof = 12, alignof = 4
layout(push_constant) uniform PCO {
int time; // offsetof = 0
vec2 extent; // offsetof = 2
}; // sizeof = 4, alignof = 2
Después de verificar repetidamente que no hay ningún problema con el código, intente intercambiar time campos y extent campos, y el programa puede ejecutarse normalmente. Obviamente, la alineación del host es inconsistente con la del dispositivo. Dado que SPIRV no se puede usar packed para comprimir el tamaño de la memoria, la alineación solo se puede lograr manualmente.
A través de estudios previos, aquí hay varias formas más elegantes de resolver este problema.
- Use el campo de bits para generar agujeros, obligando a la estructura a ser consistente con el diseño en glsl
- El campo especificado es consistente con el tamaño de alineación en glsl
struct PCO {
uint32_t time; // offsetof = 0
uint32_t : 1, : 0;
::glm::vec2 extent; // offsetof = 8
}; // sizeof = 16, alignof = 4
struct PCO {
uint32_t time; // offsetof = 0
alignas(8)::glm::vec2 extent; // offsetof = 8
}; // sizeof = 16, alignof = 8