01
fondo
El equipo de I+D de back-end en el extranjero de iQIYI respalda el negocio relacionado con el back-end de tres terminales de TELÉFONO/PCW/TV en el extranjero de iQIYI. Además de ser responsable de los servicios de back-end de las tres terminales, también incluye negocios de puntos en el extranjero, ventanas emergentes, sistemas de reserva para varios programas, etc. Además, también hay una serie de infraestructuras, como el fondo IQ que admite rápidamente varias configuraciones operativas y demandas experimentales de productos; el motor de estrategia que ayuda a las operaciones de productos a lograr operaciones refinadas; la plataforma de control de calidad que realiza la reproducción de tráfico y la presión prueba de espera.
El funcionamiento estable de varios negocios depende de un sistema de registro completo, por lo que los códigos comerciales a menudo imprimen muchos registros para ayudar a monitorear y solucionar problemas en la operación de los códigos comerciales. Sin embargo, la impresión del registro tiene un cierto impacto en el desempeño del proyecto. Hemos leído mucha información y podemos encontrar muchas comparaciones de rendimiento de registros de diferentes marcos, pero hay una falta de SOP de impresión de registros refinados necesarios para la práctica de la ingeniería. Además, los sistemas distribuidos son actualmente la corriente principal. En el proceso de impresión de registros, los nodos no tienen estado e imprimen de forma independiente la información de la misma solicitud, lo que generará mucha redundancia de información y desperdicio de recursos. El rendimiento del servicio tampoco es amigable.
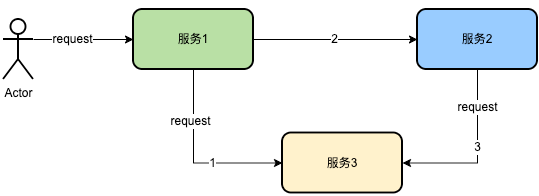
Como se muestra arriba, el servicio 1 llama al servicio 3 y luego llama al servicio 2 en serie, y el servicio 2 depende del servicio 3 internamente. En los casos anteriores, el servicio 1 registrará la información detallada del servicio solicitado 3, el servicio 2 registrará la información detallada del servicio solicitado 3 y el servicio 3 registrará toda la información solicitada. Entonces, un enlace contiene 4 veces el mismo registro.
Para resolver los problemas anteriores, hemos llevado a cabo la construcción especial del esquema de optimización de impresión de registros del sistema distribuido, que incluye principalmente dos partes:
(1) Obtener datos cuantitativos sobre la pérdida real de rendimiento del proyecto causada por el registro y refinar el SOP de impresión de registros para ayudar a mejorar el rendimiento del proyecto y proporcionar referencia para la impresión de registros en el futuro.
(2) Considere la globalidad del enlace de la impresión de registros y realice registros de registro con estado entre los nodos de servicios distribuidos.
A través de la construcción de las dos partes anteriores, se puede reducir el consumo de recursos y rendimiento de la impresión de registros bajo el enlace distribuido. Mejore el rendimiento del sistema y reduzca la pérdida del sistema.
Este artículo comparte principalmente nuestro proceso de exploración, pensamiento y práctica en el esquema de optimización de impresión de registros de sistemas distribuidos.
02
Exploración y práctica de la impresión de registros de optimización de un solo sistema
Actualmente, los marcos más populares son log4j, log4j2 y logback. En general, se cree que log4j2 es una actualización de log4j, por lo que realizaremos comparaciones experimentales entre los marcos de trabajo más comunes de log4j2 y logback 1.3.0, obtendremos datos de rendimiento y resumiremos las mejores prácticas para proporcionar especificaciones de proceso para que nuestro sistema comercial imprima registros.
2.1 Comparación de múltiples dimensiones para obtener el plan de mejores prácticas para la impresión de registros
Elegimos la implementación de contenedores, recurso: 2c4g, proyecto de implementación independiente. El proyecto contiene una API cuya función es controlar y generar registros de diferentes tamaños según los parámetros de entrada.
2.1.1 Investigación cuantitativa sobre el rendimiento de impresión de log4j2
log4j2 asíncrono
Tamaño de registro: 2 KB, asíncrono
 sincronización log4j2
sincronización log4j2
 Conclusión de la prueba de presión Log4j2
Conclusión de la prueba de presión Log4j2
A partir de los datos anteriores es fácil generar el siguiente gráfico.
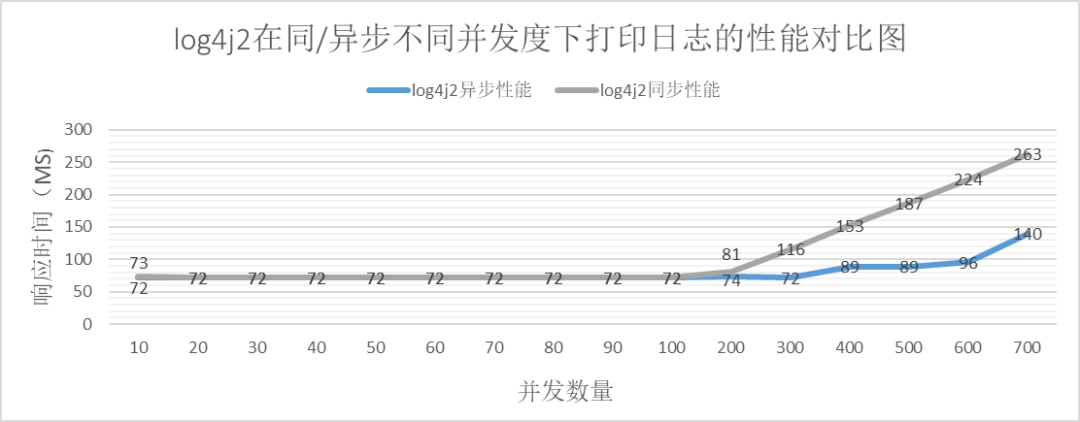
De la figura anterior podemos ver:
Cuando el número de simultaneidad es pequeño, el rendimiento de log4j2 es constante. Cuando el número de simultaneidad aumenta hasta cierto número, el rendimiento de la impresión asíncrona es obviamente mejor que el de la impresión síncrona.
La impresión asíncrona Log4j2 también tiene cuellos de botella en el rendimiento.
El cuello de botella de rendimiento de la impresión síncrona de log4j2 radica en el cuello de botella de IO, y el tamaño de IO por segundo es de aproximadamente 2635 ✖️ 2kb = 5,15 MB.
2.1.2 Investigación cuantitativa sobre el rendimiento de impresión de logback
inicio de sesión asíncrono

impresión síncrona de inicio de sesión

Conclusión de la prueba de presión Logback
Es fácil generar los siguientes gráficos a través de los datos de medición de presión del registro.
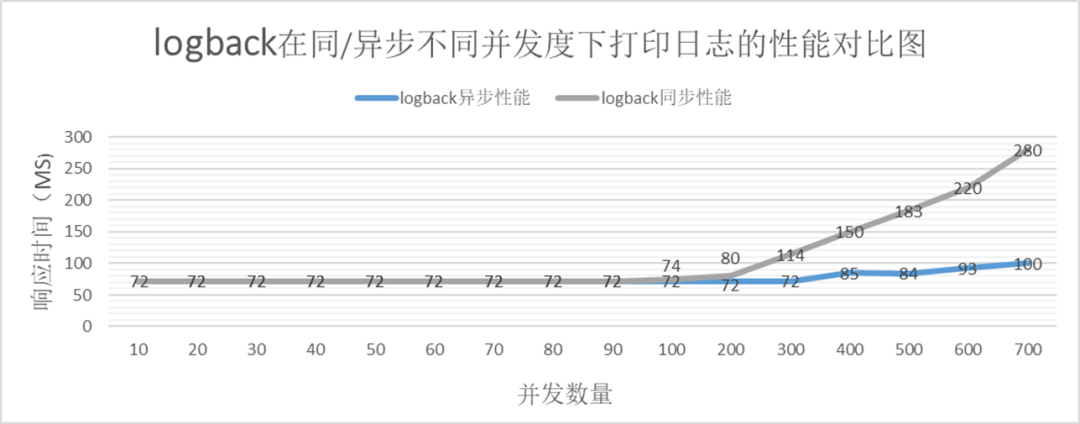
De la figura anterior podemos ver:
Cuando el número de simultaneidad es pequeño, el rendimiento de log4j2 es constante. Cuando el número de simultaneidad aumenta hasta cierto número, el rendimiento de la impresión asíncrona es obviamente mejor que el de la impresión síncrona.
La impresión asincrónica de inicio de sesión también tiene cuellos de botella en el rendimiento
El cuello de botella de rendimiento de la impresión síncrona de log4j2 radica en el cuello de botella de E/S. El tamaño de E/S por segundo es de aproximadamente 2650 ✖️ 2kb = 5,2 MB, y el tamaño de E/S es aproximadamente el mismo que el de log4j2.
2.1.3 Comparación entre logback y log4j2
comparación síncrona

A través de los datos de la tabla anterior, se puede obtener el siguiente cuadro de comparación
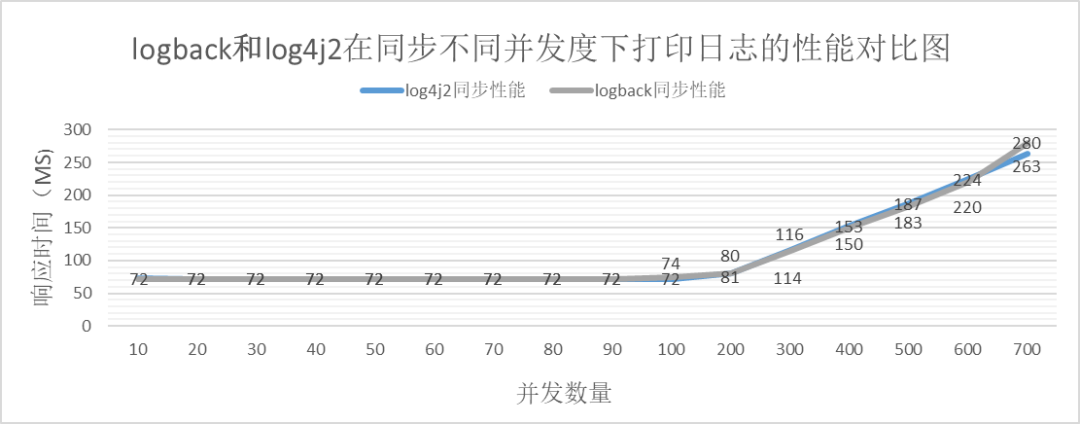
comparación asíncrona

A través de los datos de la tabla anterior, se puede obtener el siguiente cuadro de comparación
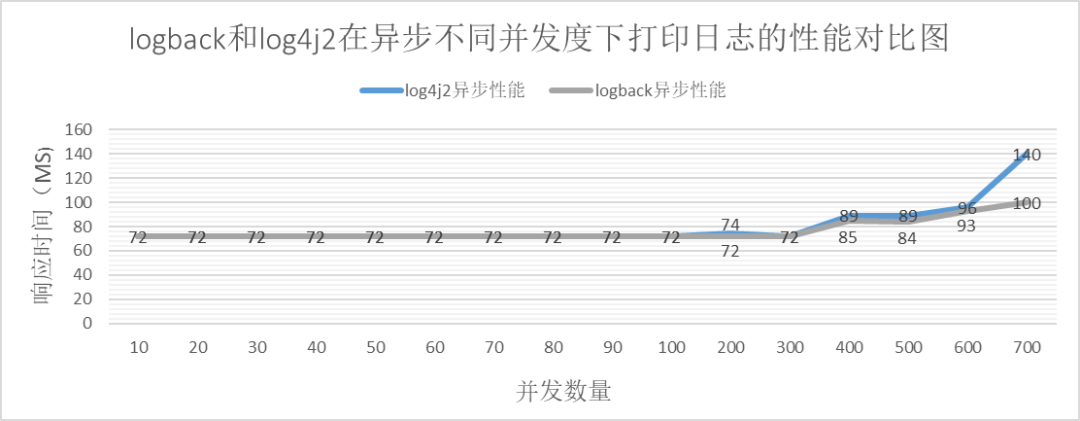
De lo anterior podemos ver que:
Ya sea sincrónico o asincrónico. Después de que la simultaneidad supere un cierto umbral, el rendimiento de logback es mejor que log4j2.
Dentro de un determinado rango de simultaneidad, el rendimiento de logback es comparable al de log4j2.
2.1.4 Comparación cuantitativa del rendimiento del logback en diferentes escenarios
De la conclusión en la Sección 2.1.3, se puede ver que no importa si es sincrónico o asincrónico. Antes de que la simultaneidad sea inferior al umbral, el rendimiento de logback y log4j2 es equivalente.Después de que la simultaneidad supera cierto umbral, el rendimiento de logback es mejor que log4j2. Por lo tanto, a continuación exploraremos en detalle el rendimiento del inicio de sesión en diferentes escenarios.
Logback imprime sincrónicamente registros de diferentes tamaños bajo la misma cantidad de datos de rendimiento de la interfaz de simultaneidad
Concurrencia = 100, síncrono

Logback imprime de forma asincrónica registros de diferentes tamaños con la misma cantidad de datos de rendimiento de la interfaz de simultaneidad
Concurrencia = 100, asíncrono

A partir de los datos anteriores, se puede dibujar el siguiente diagrama de relaciones
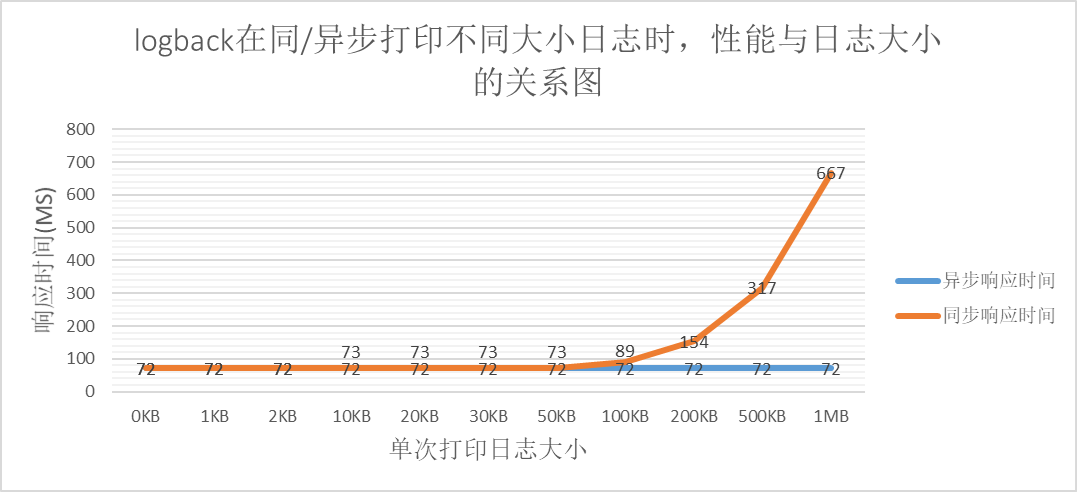
De la figura anterior podemos obtener:
Si el tamaño del registro está dentro de un cierto rango, no tendrá impacto en el rendimiento, si excede un cierto límite, el rendimiento se reducirá significativamente.
A partir de los datos de los registros impresos sincrónicamente, se puede saber que cuando el número de concurrencia es constante, existe un cuello de botella en el número de IO, es decir, el tamaño de IO por unidad de tiempo no aumenta proporcionalmente con el aumento de cada OI. El cuello de botella de los datos experimentales es de alrededor de 160 MB.
La impresión asíncrona de inicio de sesión es menos sensible al tamaño del registro, porque una vez que la cola de impresión asíncrona está llena, se puede adoptar una estrategia de descartar registros comerciales.
2.2 Resumen de Mejores Prácticas
Priorizar el uso de logback como marco para la salida de registros para reducir el impacto de la impresión de registros en el rendimiento del proyecto
En el caso de alta simultaneidad y los registros comerciales no son necesarios, use el inicio de sesión para imprimir de forma asíncrona
Al juzgar que los registros de negocios son fuertemente dependientes, el inicio de sesión debe prestar especial atención a la configuración de neuralBlock = true para imprimir registros de forma asíncrona. En este momento, si el tamaño del registro de impresión de una sola solicitud del proyecto es inferior a 2 KB, los datos de E/S por segundo del proyecto no deben superar los 5 MB.
2.3 Optimización de proyectos de ingeniería
Con base en las mejores prácticas anteriores, seleccionamos un proyecto del equipo de I+D de back-end en el extranjero de iQIYI para la transformación piloto y analizamos los cambios de rendimiento.
2.3.1 Introducción del proyecto
El equipo de I+D de back-end en el extranjero de iQIYI es responsable del correspondiente negocio de back-end de iQIYI en el extranjero de PHONE/PCW/TV, que incluye principalmente el servicio TOC para la salida estable de datos comerciales de páginas, y el fondo de operación IQ flexible, eficiente y escalable para Un motor de estrategia para operaciones refinadas y un servicio de centro de datos para sincronizar datos de programas.
Elegimos un servicio TOC con una estructura sin tarjeta como piloto, porque el proyecto contiene muchas API y hay muchos escenarios de impresión de registros. El proyecto se implementa en Singapur, implementación en contenedores 4C8G, el QPS independiente máximo es de alrededor de 120.
2.3.2 Resultados de la optimización del rendimiento

Después de la transformación asíncrona, P99 cayó de 78,8 ms a 74 ms y P999 cayó de 180 ms a 164,5 ms.
La situación de los diferentes proyectos es diferente.Si se trata de un proyecto con un gran tráfico de una sola máquina o una gran cantidad de registros impresos, se cree que la transformación asincrónica tiene una mayor mejora del rendimiento.
2.4 Resumen
El trabajo principal de la optimización del rendimiento de los registros independientes es obtener el rendimiento de diferentes marcos de registro y obtener el rendimiento del mismo marco de registro en diferentes escenarios. Espero que esta parte de los datos pueda ayudar a los colegas que se encuentran con el mismo dilema. Además, también hemos estandarizado el método de impresión de registros. Al calificar el SLA comercial, podemos explicar el motivo del registro aquí a nivel de registro y, si es una excepción, qué nivel de excepción es, para que todos los estudiantes de negocios pueden conocer las diferentes alarmas de manera oportuna.El grado de urgencia es propicio para hacer juicios de prioridad y respuestas basadas en procesos.
03
Aplicación del uso compartido de variables distribuidas en la impresión de registros
Los capítulos anteriores introdujeron la optimización de la impresión de registros del sistema independiente, pero los sistemas actuales son básicamente sistemas distribuidos, entonces, ¿cuáles son los puntos débiles y las soluciones para la impresión de registros en el sistema distribuido? Hemos pensado en el esquema de optimización de la impresión de enlaces de registros en el sistema distribuido. Lo siguiente es el pensamiento y la práctica de la optimización de la impresión de registros en el sistema distribuido.
3.1 Introducción
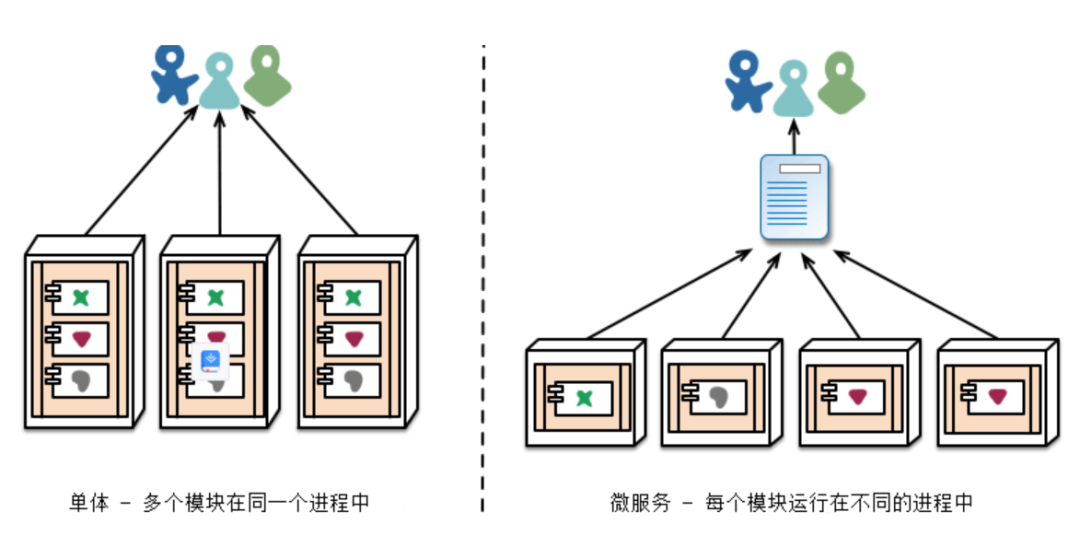
Mirando el proceso de evolución de la tecnología de Internet, la evolución de un sistema único a un sistema distribuido es una característica muy importante. Pero es innegable que los cambios en las cosas son más ventajosos en general, pero siempre se encontrarán nuevos desafíos en las sucursales. Los sistemas monolíticos también tienen ventajas que los sistemas distribuidos no tienen, como transacciones locales, código compartido y variables compartidas. Desde la perspectiva de la impresión de registros, el sistema monolítico puede recibir llamadas al mismo servicio. Debido a que los registros se encuentran en el mismo proyecto, se pueden ver e incluso acordar. En un sistema distribuido, los módulos funcionales generalmente se dividen y pertenecen a diferentes equipos de desarrollo, por lo que la impresión de registros de los diferentes nodos de servicio generalmente no puede comunicarse. Por esta razón, básicamente todos los equipos de desarrollo harán su mejor esfuerzo. El registro de todo el enlace será muy redundante, lo que resultará en el desperdicio de recursos y la degradación del rendimiento del sistema distribuido.
3.2 Introducción al sistema completo de seguimiento de enlaces
En un sistema distribuido, una solicitud externa a menudo requiere múltiples módulos internos, múltiples middleware y múltiples máquinas para llamarse entre sí para completar. En esta serie de llamadas, algunas pueden ser en serie y otras en paralelo. En este caso, ¿cómo podemos determinar qué aplicaciones fueron invocadas por toda esta solicitud? ¿Qué módulos? ¿Qué nodos? ¿Y cuál es su secuencia y el desempeño de cada parte? El propósito del seguimiento de enlaces es resolver los problemas mencionados anteriormente, es decir, restaurar una solicitud distribuida a un enlace de llamada y mostrar el estado de la llamada de una solicitud distribuida de manera centralizada, por ejemplo, el tiempo y solicitudes específicas en cada nodo de servicio, qué máquina alcanzar, el estado de la solicitud de cada nodo de servicio, etc. Por ejemplo, zipkin, uno de los sistemas de enlace completo, tiene un diagrama de arquitectura de la siguiente manera:
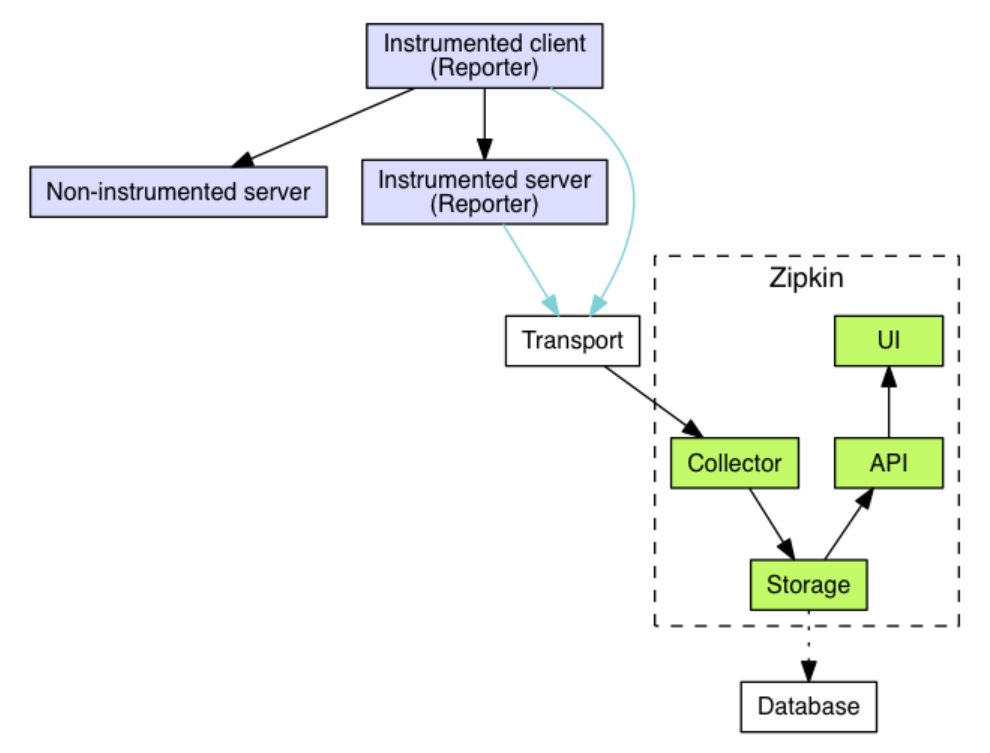
El sistema de seguimiento de enlace completo admite muestreo de registro de enlace y transmisión transparente variable. Nos referimos a la idea de diseño de enlace completo para optimizar nuestro sistema distribuido.
3.3 El uso de variables compartidas para el muestreo logarítmico
3.3.1 Introducción a los antecedentes
Este problema se concentra en nuestro sistema de motor de estrategia. El sistema de motor de estrategia es un sistema diseñado e implementado para lograr operaciones refinadas. Es principalmente capaz de identificar e identificar los retratos de diferentes grupos de personas, y desplegar diferentes estrategias en consecuencia. Con la implementación del sistema, el negocio de acceso ha crecido rápidamente. En la actualidad, el negocio de CARD, el negocio de ventana emergente, el negocio de publicidad, el negocio de marketing interactivo, el negocio de recomendación, el negocio de navegación y el viaje de los datos de la página en el extranjero de iQIYI se han conectado. Sin embargo, los diferentes sistemas anteriores tienen ciertas dependencias y se llaman entre sí. Y debido a las necesidades comerciales, la solicitud del motor de políticas depende de la solicitud posterior, y el registro de la puerta de enlace no puede analizar los parámetros de solicitud de la publicación, por lo que necesitamos que la empresa registre los detalles de cada solicitud. Además, el motor de políticas se basa en gran medida en los datos de retratos de usuarios, que se almacenan en los servicios de BI y Facebook respectivamente. Según experiencias anteriores, alrededor del 90 % de las razones por las que fallan las políticas se deben a que los datos de retratos de usuarios no se actualizan a tiempo. Para facilitar la resolución de problemas Para localizar el problema, el motor de políticas registrará los datos de retrato de usuario solicitados por cada usuario. El QPS del motor de políticas es muy alto, por lo que el volumen de registro diario es de aproximadamente 150 G. Cómo optimizar con elegancia esta parte del registro es un problema que hemos encontrado.
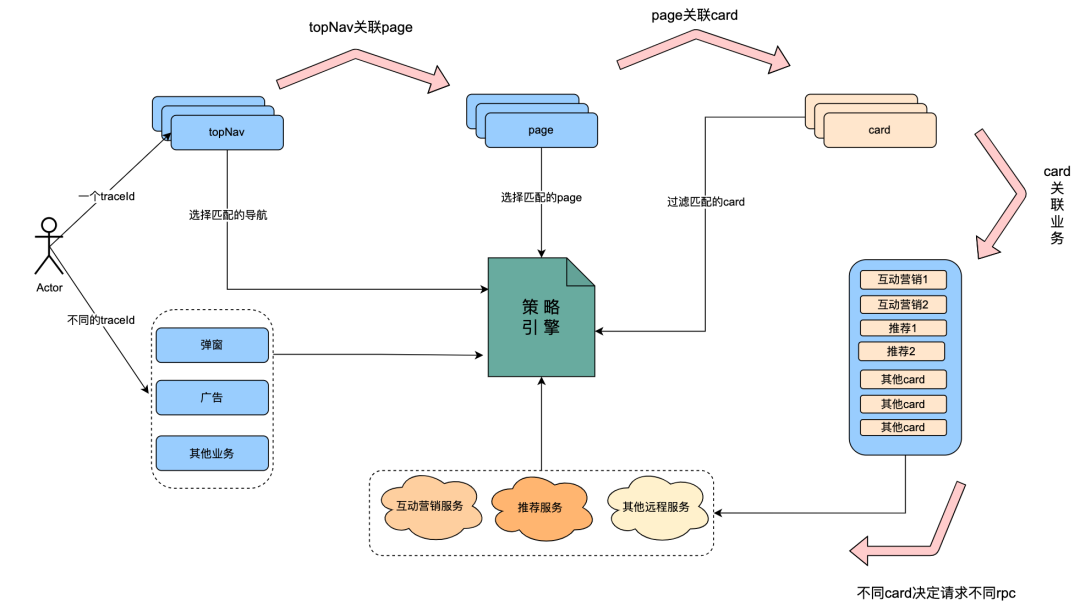
El tráfico del motor de estrategia incluye principalmente ventanas emergentes, anuncios, navegación superior, iq, recomendación y marketing interactivo.
Sin embargo, encontramos que parte del tráfico tiene características de enlace obvias. Cuando la petición del cliente determine la navegación superior, se obtendrá la página asociada.
Puede haber un conjunto de datos asociados a la página, en este caso es necesario solicitar al motor de políticas que obtenga una página que coincida con el perfil del usuario.
Hay varios conjuntos de tarjetas asociadas a la página. En este momento, es necesario solicitar al motor de políticas que obtenga una tarjeta que coincida con el retrato del usuario.
La tarjeta en realidad está asociada con diferentes datos comerciales, incluidos los servicios de marketing interactivo y los servicios de recomendación. Y el marketing interactivo y la recomendación solicitarán al motor de estrategia que obtenga datos que coincidan con el retrato de la multitud.
Se puede concluir del análisis que una vez que un usuario solicita, los microservicios incluidos solicitan el motor de políticas respectivamente. En un ciclo de vida de la solicitud, los datos de la solicitud del usuario son definitivamente los mismos y los datos del retrato del usuario son definitivamente los mismos.
3.3.2 Soluciones
De acuerdo con el análisis anterior, es fácil pensar que el motor de políticas lo registra de manera uniforme. El motor de políticas agrega un identificador al TraceContext para indicar si hay un registro en el ciclo de vida de la solicitud, si lo hay, no se registrará, y si no lo hay, se registrará.
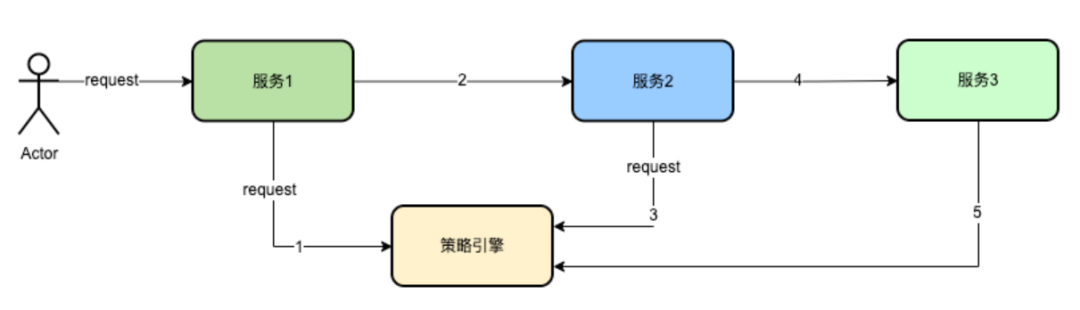
Como se muestra en la figura anterior, después de que el Servicio 1 solicita el motor de políticas, se agrega un identificador al TraecContext, lo que indica que se ha registrado el seguimiento de la solicitud. Cuando los nodos posteriores, a saber, el servicio 2 y el servicio 3, solicitan el motor de políticas nuevamente, no es necesario repetir el registro. Hacerlo puede reducir mucho el registro.
Sin embargo, habrá los siguientes problemas: si hay un error 5xx, el servicio del motor de políticas falla y la solicitud correspondiente no se registra, y el registro de la solicitud se pierde, lo que dificultará mucho el agente de solución de problemas.
Después del análisis comparativo, finalmente se determina que los dos problemas anteriores pueden resolverse bien compartiendo variables en un sistema distribuido.
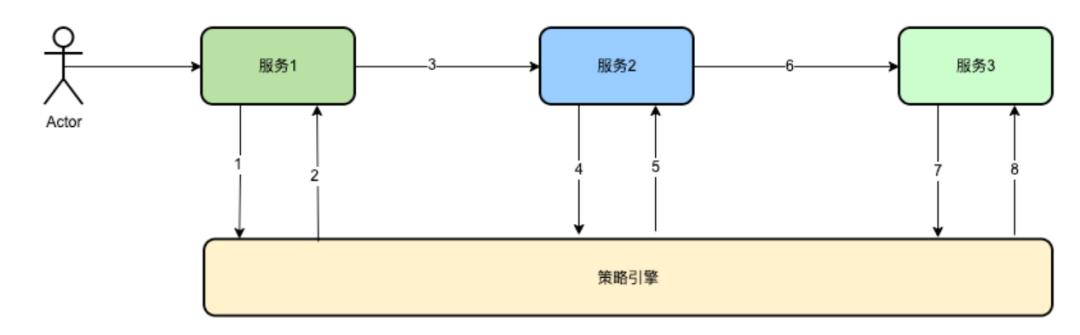
Las solicitudes anteriores 1, 2, 4, 5, 7 y 8 deben evaluar el campo logBusiness del contexto traceContext. Si existe, no es necesario registrarlo. Si no existe, registrará el registro. y establezca logBusiness en verdadero.
Por ejemplo, esto es un total de 200 solicitudes, luego de que 1 solicitud llegue al motor de políticas y juzgue que el campo logBusiness del contexto traceContext es falso, registrará la solicitud y establecerá logBusiness en verdadero, y en los siguientes 4 , 5, 7, 8, no es necesario volver a iniciar sesión. Incluso si hay excepciones en 4, 5, 7 y 8, la escena del motor de políticas de solicitud aún se puede restaurar a través de traceId y la solicitud registrada en 1.
Otro ejemplo es que falla la solicitud 1. Si es una solicitud de tiempo de espera 499, porque el tiempo de espera es transparente para el servidor y el motor de políticas continúa ejecutándose, entonces el motor de políticas imprime el registro y establece el campo logBusiness del contexto traceContext en verdadero . Pero para el servicio 1, debido al tiempo de espera, se registrará de forma redundante una copia de los datos. En la cuarta solicitud, debido a que logBusiness del contexto traceContext aún es falso, se volverá a registrar y logBusiness se establecerá en verdadero y no se registrará en la séptima solicitud posterior.
Por ejemplo, si falla 1 solicitud y es una solicitud 5xx, se registrará 1 y 4 se registrará nuevamente.
Por lo tanto, este método puede minimizar el registro del enlace con la premisa de garantizar la integridad del enlace del registro de restauración.
3.3.3 Resumen
Hemos optimizado el servicio del motor de políticas y el registro se puede reducir de los 150 G/día anteriores a 30 G/día. El consumo de recursos de la cola para la recopilación de tareas de flink y el procesamiento de registros también se reduce en consecuencia.
04
Perspectiva resumida
Este documento presenta principalmente el proceso de exploración y práctica del esquema de optimización de impresión de registros del sistema distribuido desde los aspectos de optimización de registro único y optimización de registro de sistema distribuido. Compare el rendimiento de los marcos de registro convencionales actuales, obtenga datos, forme mejores prácticas, brinde una solución de acceso estándar para el método de impresión de registros de nuestros proyectos comerciales e introduzca los beneficios obtenidos por nuestro proyecto de equipo al mejorar el método de impresión de registros. En un escenario específico, se da una solución innovadora al problema sin estado de los registros de impresión del sistema distribuido, que resuelve el problema del registro repetido de diferentes o los mismos nodos distribuidos. Una cosa más para mencionar aquí. Después de nuestra serie de ideas, las variables compartidas distribuidas tienen amplias perspectivas de aplicación. Además de la impresión de registro optimizada con estado presentada en este artículo, este método se puede usar para escenarios con tolerancia cero o tolerancia débil para la inconsistencia de datos. Es bueno reducir la presión de tráfico de los servicios de cuello de botella y mejorar el rendimiento del enlace Por supuesto, esto requiere la cooperación de los algoritmos de compresión y descompresión de datos. En la práctica futura, tendremos la oportunidad de compartir nuestro proceso de pensamiento y práctica con nuestros compañeros.

tal vez quieras ver
Recorrido de investigación de pausa de GC bajo Spring Cloud Gateway
Diseño y práctica del sistema de operaciones en el extranjero de iQIYI