catálogo de conocimientos
prefacio
1. Cargar datos
En el pasado, cuando practicábamos, básicamente usábamos los datos que simulamos, pero en escenarios comerciales reales, los datos generalmente ya existen y algunos necesitan usar tecnología de rastreo para obtenerlos. Los datos que ya existen generalmente tienen
CSVformato,Excelformat y数据库中存储的数据.
A continuación, daremos pandasuna breve introducción sobre cómo cargar y almacenar datos en estos formatos.
Tips⭐️: almacenar datos en un archivo es una llamada de objeto de marco de datos, y leer un archivo es una llamada de pandas.
1 - Cargar archivo CSV
Los archivos CSV (valores separados por comas) se pueden transferir y leer fácilmente entre diferentes sistemas operativos, software y plataformas, por lo que a menudo se utilizan para el almacenamiento y el intercambio de datos.
Por ejemplo, los datos de registro de usuarios del sitio web, los datos de estudios de mercado, etc., pueden almacenarse y transmitirse en forma de archivos CSV.
- Guardar en archivo CSV
df.to_csv(path_or_buf=None,
sep=',',
columns=None,
header=True,
index=True
)
| parámetro | significado |
|---|---|
| camino_o_buf | Ruta de almacenamiento y nombre de archivo |
| sep | delimitador, coma por defecto |
| columnas | Columnas para almacenar, o todas las columnas si no se especifica |
| encabezamiento | Ya sea para mantener los nombres de las columnas |
| índice | Ya sea para mantener el índice de fila |
Aquí hay un ejemplo de código:
# 导入模块
import numpy as np
import pandas as pd
# 创建要存储到csv文件的dataframe对象
data = np.random.randint(0,100,(5,3))
df = pd.DataFrame(data,columns=['Python','Java','BigData'])
# 存入到当前目录下的07.csv文件中
df.to_csv(path_or_buf='./07.csv',sep=',',header=True,index=False)
- leer archivo CSV
pd.read_csv(
filepath_or_buffer: Union[str, pathlib.Path, IO[~AnyStr]],
sep=',',
header='infer',
names=None,
index_col=None,
usecols=None,
)
| parámetro | efecto |
|---|---|
| ruta_archivo_o_búfer | ruta de archivo y nombre de archivo, o un objeto IO |
| sep | delimitador, el valor predeterminado es coma |
| encabezamiento | Predeterminado = 0, significa usar la primera fila como nombre de columna |
| nombres | Tipo de lista, si no se especifica ningún encabezado, si se especifican nombres, los nombres se utilizarán como nombres de columna |
| index_col | Especificar una columna como índice de fila |
| usecols | Leer solo ciertas columnas, por defecto leer todo |
Aquí hay un ejemplo de código:
# 读取当前路径下的07.csv的Java列
pd.read_csv(filepath_or_buffer='./07.csv',sep=',',header=0,usecols=['Java'])
2 - Cargar archivo Excel
Para las personas que no conocen la programación (como contadores, oficinistas y otras ocupaciones que no están relacionadas con la experiencia informática), los
excelarchivos son el formato de almacenamiento de archivos de datos que más utilizan.
- Guardar en archivo de Excel
df.to_excel(
excel_writer,
sheet_name='Sheet1',
columns=None,
header=True,
index=True,
)
| parámetro | significado |
|---|---|
| excelente_escritor | ruta de archivo y nombre de archivo |
| nombre_hoja | sheetEl nombre de la página actual al escribir en excel |
| columnas | columna de atributos para escribir |
| encabezamiento | Qué fila del objeto df se usa como nombre de columna |
| índice | Ya sea para mantener el índice de fila |
Ejemplo de código:
df.to_excel('./07.xlsx',sheet_name='Program Language',index=False)
- leer archivo de excel
pd.read_excel(
io,
sheet_name=0,
header=0,
names=None,
index_col=None,
usecols=None,
El significado del parámetro es similar al de leer el archivo CSV, así que no lo explicaré aquí~
3 - Cargar datos de la base de datos
La carga de datos de la base de datos es un escenario comercial que involucra muchos datos de almacenamiento de back-end. Aquí hay
MySQLun ejemplo de datos.
La carga de datos de la base de datos MySQL primero requiere la instalación de dos paquetes ( pymysqly sqlalchemy)
pip install pymysql -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install sqlalchemy -i https://pypi.tuna.tsinghua.edu.cn/simple
- Almacenar en MySQL
df.to_sql(
name,
con,
schema=None,
if_exists='fail',
index=True,
)
| parámetro | significado |
|---|---|
| nombre | Especifique el nombre de la tabla para almacenar |
| estafa | objeto de conexión |
| esquema | Motor de base de datos, si no se especifica, se utilizará el motor predeterminado del tipo de base de datos, como MySQLinnoDB |
| si_existe | La operación cuando la tabla ya existe, hay {'fail', 'replace', 'append'} tres valores, que indican respectivamente el informe de errores, el reemplazo y la adición |
| índice | Ya sea para escribir el índice de fila |
Ejemplo de código:
# 导入创建数据库连接的引擎
from sqlalchemy import create_engine
# 获取连接对象
conn = create_engine("mysql+pymysql://root:123456!!!!@localhost:3306/pytest")
# 保存到MySQL数据库
df.to_sql(name='program_language',con=conn,if_exists='append',index=False)
Nota: En la cadena para crear el objeto de conexión, solo es necesario modificar la cuenta y la contraseña de la base de datos (
root:123456!!!!,IP, ).端口

- leer de mysql
pd.read_sql(
sql,
con,
index_col=None,
coerce_float=True,
parse_dates=None
)
| parámetro | significado |
|---|---|
| sql | cadena de comando SQL |
| estafa | El motor conectado a la base de datos sql generalmente se puede construir con paquetes como SQLalchemy o pymysql |
| index_col | Seleccionar una columna como índice |
| coaccionar_flotar | Es muy útil leer la cadena en forma de número directamente como un flotante |
| parse_dates | Convierta una columna de cadenas de fecha en datos de fecha y hora |
Ejemplo de código:
sql = 'SELECT Python FROM program_language;'
pd.read_sql(sql,conn)
dos, boxeo
La operación de binning se refiere a la división
连续数据离散化(hablando comúnmente, dividir los datos en varios intervalos, como 100 números del 1 al 100, divididos en 0-25, 25-50, 50-75, 75-100, esta es la operación de binning) . Los métodos comunes de agrupamiento incluyen el método de igual ancho y el método de igual frecuencia.
Método de ancho igual : la diferencia de cada intervalo después de la discretización es igual.
La desventaja de esto es que el número de elementos contenidos en diferentes intervalos puede variar mucho.
Método de igual frecuencia : el número de elementos contenidos en cada intervalo después de la discretización es igual.
La desventaja de esto es que los mismos elementos pueden dividirse en diferentes intervalos.
1 - Agrupación monoespaciada
cut()El agrupamiento de igual ancho se realiza a través de la función de pandas .
# 待分箱数据
year = [1992, 1983, 1922, 1932, 1973]
# 指定箱子的分界点
bins = [1900, 1950, 2000]
# 分箱操作
result = pd.cut(year, bins)
# 结果显示的是每个数据在哪个区间内
print(result)

# 对不同箱子中的数进行计数
print(pd.value_counts(result))

# labels参数为False时,返回结果中用不同的整数作为箱子的标签
result2 = pd.cut(year, bins,labels=False)
# 输出结果中的数字对应着不同的箱子
print(result2)
# 对不同箱子中的数进行计数
print(pd.value_counts(result2))

# 给箱子指定标签
group_names = [ '50_before', '50_after']
result3 = pd.cut(year, bins, labels=group_names)
print(pd.value_counts(result3))

2 - Agrupación de igual frecuencia
Use la función en pandas
qcutpara realizar un agrupamiento de igual frecuencia. Después del agrupamiento, la cantidad de datos en cada cuadro es la misma.
# 待分箱数据
year2 = [1992, 1983, 1922, 1932, 1973, 1999, 1993, 1995]
# 参数q指定所分箱子的数量
result4 = pd.qcut(year2,q=4)
# 从输出结果可以看到每个箱子中的数据量时相同的
print(result4)

print(pd.value_counts(result4))

3. Serie temporal
Al realizar análisis de datos relacionados con series temporales, el procesamiento de series temporales es algo natural, y pandas proporciona muchos métodos para procesar series temporales. Nota : este artículo solo presenta brevemente los métodos relacionados con el procesamiento de series temporales de pandas. Para obtener más información, consulte otros materiales.

Antes de introducir series de tiempo, necesitamos introducir dos conceptos: marca de tiempo pd.Timestampy período de tiempo pd.Period.
Marca de tiempo: La marca de tiempo es la serie de datos de tiempo más básica, utilizada para asociar valores con puntos de tiempo. Los objetos pandas llaman a datos de un punto en el tiempo por marca de tiempo.
Período de tiempo: el período de tiempo representado por Período es más intuitivo y también se puede inferir con una cadena en formato de fecha y hora.
Tanto la marca de tiempo como el período de tiempo se pueden sumar y restar con números enteros, con freqel parámetro especificado como unidad.
1 - Creación de Marca de tiempo y Período
# 创建时间戳
ts1 = pd.Timestamp('2023-8-5')
# 创建时间段
pd1 = pd.Period('2023-8-5',freq='M')
# 创建时间戳范围(periods表示数据量,freq 表示精确到年/月/日)
ts2 = pd.date_range('2022-02-7',periods=4,freq='M')
# 创建时间段范围
pd2 = pd.period_range('2023-8-5',periods=4,freq='M')
display(ts1,ts2,pd1,pd2)

# 时间戳索引
index = pd.date_range('2023-8-5',periods=4,freq='D')
s = pd.Series(np.random.randint(0,10,4),index=index)
s

Además, hay algunas conversiones relacionadas con las marcas de tiempo. pd.to_datetime: convierte la cadena o la marca de tiempo al formato de hora, pd.DateOffset: calcula la diferencia horaria.
# 字符串转日期
pd.to_datetime(['2023-8-4','2023/8/4','08/04/2023','2023.8.4'])
# 时间戳转日期
pd.to_datetime([1233123123],unit='ms')
# 计算时间差
ts = pd.Timestamp('2023-8-5')
ts + pd.DateOffset(hours=1,days=-1)
2 - Indexación y corte
La indexación y división de marcas de tiempo, de forma similar a la indexación y división de matrices, utiliza corchetes.
# 首先创建时间戳对象
index = pd.date_range('2023-8-5',periods=100,freq='D')
ts = pd.Series(range(len(index)),index)
# 索引
ts['2023-8-12'] # 取一天
ts['2023-8'] # 取8月整个月
ts['2023'] # 取一年
ts[pd.Timestamp('2023-8-20')] # 时间戳索引
# 切片
ts['2023-8-7':'2023-8-20']
ts[pd.Timestamp('2023-8-10'):pd.Timestamp('2023-8-20')] # 时间戳切片
ts[pd.date_range('2023-8-10',periods=4,freq='D')]
3 - Propiedades y Movimiento
# 属性
ts.index # 索引
ts.index.year # 年份
ts.index.month # 月份
ts.index.dayofweek # 星期
# shift方法
index = pd.date_range('2023-1-20',periods=365,freq='D')
ts = pd.Series(np.random.randint(0,100,len(index)),index)
ts.shift() # 向下移动1位
ts.shift(2) # 向下移动两位
ts.shift(-2) # 向上移动两位
4 - Conversión de frecuencia
La conversión de frecuencia es la operación de cambiar el intervalo de fechas.
# 频率转换
# 由天变为星期,由少变多,去掉了一些数据
ts.asfreq(pd.tseries.offsets.Week())
# 由天变小时,多了一些空数据
ts.asfreq(pd.tseries.offsets.Hour())
# 使用 fill_value 填充
ts.asfreq(pd.tseries.offsets.Hour(),fill_value=0)
5 - Agregación de datos
# 首先查看 ts
ts
# 将两天的日期合并,数据相加
ts.resample('2D').sum()
# 将两周的日期合并,数据相加
ts.resample('2W').sum()
d = {
'price':np.random.randint(0,50,8),
'score':range(10,90,10),
'week':pd.date_range('2023-8-5',periods=8,freq='w')
}
df = pd.DataFrame(d)
df
# 对week列按月汇总
df.resample('M',on='week').sum()
# 按照月汇总,price求平均值,score求和
df.resample('M',on='week').agg({
'price':np.mean,'score':np.sum})

Cuarto, los pandas dibujan gráficos.
Pandas es una poderosa herramienta para el procesamiento de datos. De hecho, también puede dibujar rápidamente gráficos simples basados en él
matplotlib. Para gráficos complejos , necesita usar matplotlib u otras bibliotecas . pandas dibuja varios gráficos a través de funciones.plot()
Debido a que pandas dibuja gráficos basados en matplotlib, es necesario importar el paquete matplotlib.
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
Hay dos formas de escribir gráficos en pandas, que son formas equivalentes de escribir, donde pdse refiere a objetos Series u objetos DataFrame.
Las siguientes dos formas de escribir
pd.plot.图象类型()
pd.plot(kind = '图象类型')
Por ejemplo
df = pd.DataFrame(np.random.randint(0,100,(4,2)),columns=list('AB'))
df.plot(kind = 'line')
# =====等价于=====
df.plot.line()
# =====都表示绘制折线图,饼图、直方图等都是这样=====
1 - Gráfico de líneas
El gráfico de la serie se muestra a continuación.
data = np.random.randint(0,50,20)
s = pd.Series(data=data)
# 等价于 s.plot(),s.plot(kind='line'),kind默认等于line,所以可以省略
s.plot.line()
Debido a que los datos se generan aleatoriamente, el gráfico de líneas que dibuje puede ser diferente al mío.

A continuación se muestra la trama de DataFrame
data = np.random.randint(0,50,(4,3))
df = pd.DataFrame(data=data,index=list('ABCD'),columns=['Chinese','Math','English'])
df.T.plot(kind='line') # 转置后绘制折线图

2 - Histograma
Serie para dibujar un histograma
data = np.random.randint(0,100,5)
s = pd.Series(data=data,index=['Chinese','Math','English','history','computer'])
s.plot(kind='bar')

DataFrame dibuja histograma
data = np.random.randint(0,50,(4,3))
df = pd.DataFrame(data=data,index=list('ABCD'),columns=['Chinese','Math','English'])
df.plot(kind='bar')

gráfico de columnas apiladas
df.plot(kind = 'bar',stacked = True)

# 条形图
df.plot(kind='barh')
# ====== df.plot.barh()

3 - Histograma
data = np.random.randint(0,50,(4,3))
df = pd.DataFrame(data=data,index=list('ABCD'),columns=['Chinese','Math','Englist'])
df.plot(kind='hist',density=True)

4 - Gráfico circular
data = np.random.randint(0,50,(4,3))
df = pd.DataFrame(data=data,index=list('ABCD'),columns=['Chinese','Math','Englist'])
df['Chinese'].plot(kind='pie',autopct='%.1f%%')

Si desea dibujar un gráfico circular en el objeto del marco de datos, debe agregar subplots=Trueel parámetro.
df.plot(kind='pie',autopct='%.2f%%',subplots=True) # 绘制子图

5 - Diagrama de dispersión
df = pd.DataFrame(np.random.rand(50, 4), columns=['a', 'b', 'c', 'd'])
df.plot.scatter(x='a', y='b')

6 - Diagrama de caja
df.plot(kind='box')
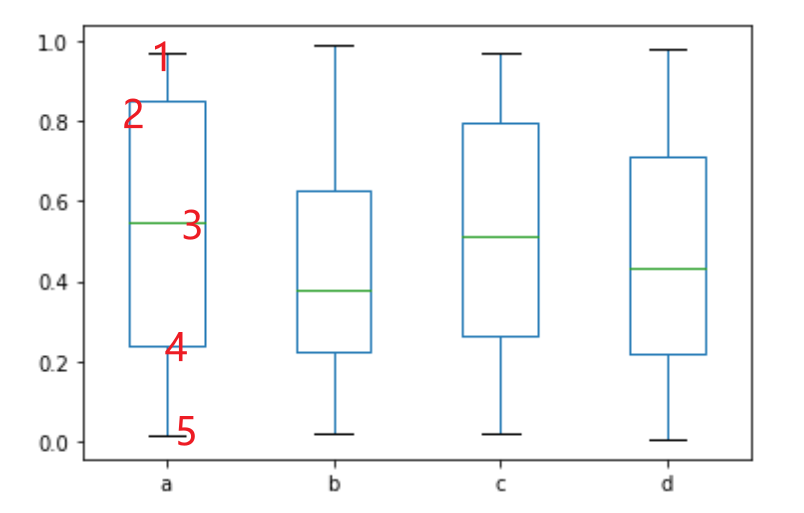
El significado de los números en la figura: 1 representa el valor máximo, 2 es 75% mayor, 3 es 1/2 mayor, 4 es 25% mayor y 5 es el mínimo.
7 - Gráfico de áreas
df.plot.area(stacked=True)
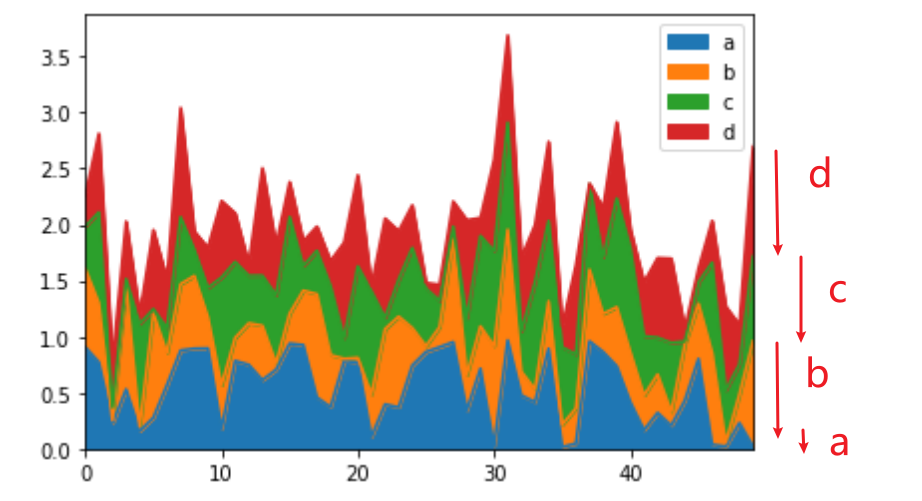
El área correspondiente a cada color representa su tamaño.
epílogo
Este artículo explica principalmente los pandas cargando datos, agrupando operaciones y series de tiempo, y dibujando varios gráficos.
⭐️Si hay algo que no entiende, discútalo conmigo~
Soy Xiangyanghuahuahuahua, en el camino de la ciencia de datos, caminaré contigo⭐️