Quién hubiera pensado que nació ChatGPT , y ahora es obvio que si no aprendes o dominas estas herramientas de IA, serás eliminado.
Por lo tanto, después de pensarlo un poco, decidí seguir el viento y actualizar el contenido relacionado de ChatGPT . La dirección de planificación actual incluirá la explicación conceptual del capítulo de introducción, el uso diario del capítulo básico, los datos de ajuste fino del entrenamiento capítulo, y el desarrollo real del capítulo de desarrollo.
Esto puede incluir tanto a usuarios comerciales como a desarrolladores de código bajo o incluso profesionales.
Hoy es nuestro primer pasado y presente de ChatGPT
Este artículo hablará de GPT-1 a GPT-4 y echará un vistazo a lo que sucedió detrás del ahora popular ChatGPT.
Si queremos saber por qué explotó ChatGPT, debemos calmarnos y comprender algunas historias históricas en el campo de la PNL.
NLP es un acrónimo de Natural Language Understanding, que pertenece a una rama del campo de la inteligencia artificial AI, cuyo objetivo principal es permitir que las computadoras comprendan, interpreten y generen el lenguaje humano.

De hecho, ya en 2018, la comprensión del lenguaje natural de PNL se encontraba básicamente en un estado de desperdicio medio, y casi no había productos en el mercado que pudiera decirse que existían. Esto se debe a que la PNL carecía antes de conjuntos de datos a gran escala, poder de cómputo y algoritmos y modelos efectivos, lo que resultó en un desarrollo muy lento del campo general de la PNL.
En junio de 2018, OpenAI lanzó el modelo de lenguaje pregenerado GPT .
GPT-1
Entre ellos, la primera generación de GPT, es decir, GPT-1, utilizó 7.000 libros como conjunto de entrenamiento, con un tamaño total de alrededor de 5 G. Lo más importante es que GPT-1 es un modelo de lenguaje generativo de pre-entrenamiento, que se desarrolla a través de dos etapas: Capacitación, que incluye primero la capacitación del modelo de lenguaje general a través del modo no supervisado, y luego el ajuste para tareas posteriores especiales, como clasificación de texto, respuesta a preguntas y otras tareas .
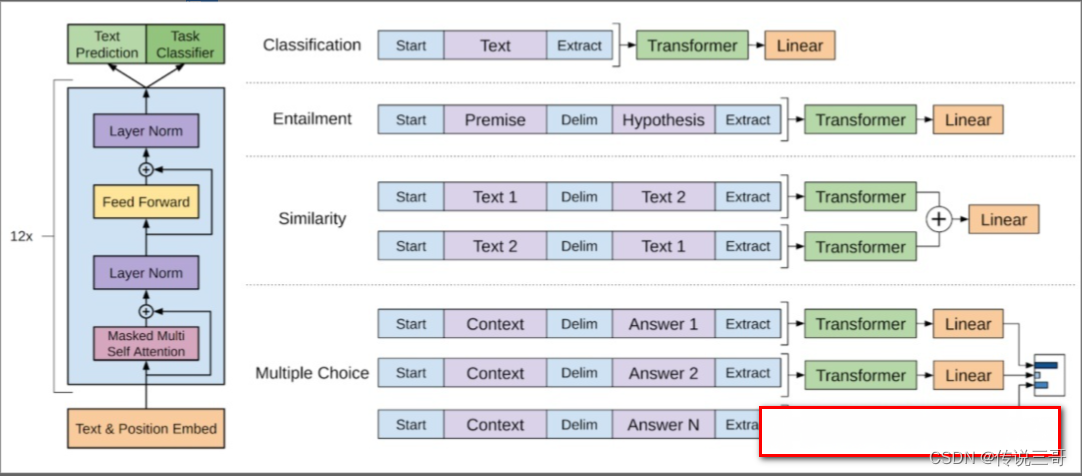
Aunque el modelo GPT-1 ajustado supera al modelo original en varias tareas, también hace que GPT-1 sea más problemático de usar porque todas las tareas posteriores deben ajustarse .
GPT-2
Para el momento de GPT-2 en febrero de 2019, utilizó 8 millones de documentos y alrededor de 40 GB de datos como conjunto de entrenamiento Al mismo tiempo, para resolver el problema de ajustar todas las tareas, OpenAI propuso un concepto llamado cero -shot Es decir, el modelo entrenado no necesita ningún ajuste fino, sin importar cuál sea su tarea posterior, el modelo puede manejarla directamente .
¿Cómo hacerlo?
Lo que se pasa aquí es una sugerencia, o una sugerencia, que es decirle al modelo qué tarea debe completar .

Es como cuando usamos ChatGPT ahora, si queremos que haga algo, le decimos, por ejemplo, quieres que haga la traducción.
Entonces dígalo, por favor traduzca las siguientes oraciones. En este momento, el mensaje "Por favor, traduzca la siguiente oración" se pasa al modelo junto con la pregunta misma. El modelo sabe lo que va a hacer. Ya sea que se trate de traducción, clasificación u otras tareas posteriores, GPT-2 aún puede manejarlo sin necesidad de ajustes.
En ese momento, la aparición de GPT-2 realmente hizo que el campo de la PNL viera esperanza. Esta esperanza es que todas las tareas posteriores se puedan completar a través de un gran modelo generativo unificado, en lugar de requerir capacitación separada para cada tarea como es habitual. Modelo.
Entonces, ¿por qué no todos escucharon sobre GPT-2 en 2019?
Esto se debe principalmente a que GPT-2 tiene el concepto de cero-corto, pero el efecto no es ideal, el contenido generado puede no ser adecuado, habrá mucha información falsa, información discriminatoria e incluso caer en un bucle sin fin. Esto se debe a que GPT-2 no sabe qué información es amigable para los humanos durante el proceso de capacitación, qué información se considera discriminatoria y la diversidad de contenido generado no es buena.
GPT-3
En mayo de 2020, GPT-3 hizo su debut. Su entrenamiento incluye múltiples conjuntos de datos de aproximadamente 45 TB de datos de entrenamiento, lo que le permite al modelo GPT-3 conocer astronomía y geografía. Ha logrado un rendimiento sorprendente en tareas de procesamiento . Más tarde, OpenAI también lanzó una API para permitir a los desarrolladores llamar al modelo por experiencia. En ese momento, según las estadísticas, se generaban 45 mil millones de palabras todos los días, lo que equivale a escribir 1 millón de libros por hora. ,
Todos deben saber que el público apenas había oído hablar de GPT en ese momento, por lo que uno puede imaginar lo aterrador que será este dato en marzo de 2023.
Además del conjunto de entrenamiento más grande, GPT-3 amplía el concepto de tiro cero de GPT-2. Lanzó otros dos conceptos Few-shot y One-shot.

Acabamos de aprender sobre zero-shot, que es equivalente a agregar un comando rápido al hacer una pregunta, como traducir la siguiente oración al inglés.
One-shot es equivalente a dar un ejemplo al hacer una pregunta, o tomar una oración traducida como ejemplo. Si desea un formato fijo, puede darle al modelo un ejemplo por adelantado, para que el modelo pueda referirse a su ejemplo para generar contenido.
Si un ejemplo no es suficiente o el efecto no es bueno, necesita pocos disparos para dar múltiples ejemplos para que el modelo entienda qué hacer con más detalle.
Ninguno de estos tres métodos actualiza el modelo en sí, pero permiten que el modelo realice diferentes tareas posteriores.
Y zero-shot, one-shot, few-shot Cuantos más ejemplos demos, más preciso será el efecto de la generación del modelo. Aunque es preciso, conducirá a otro problema en este momento, es decir, el costo de La llamada modelo se vuelve más grande , porque cada vez que haces una pregunta, la cantidad de palabras que se preguntan es demasiado.
Pero este tipo de datos de entrenamiento enormes también genera un problema. Si comprende demasiado contenido, lo asociará aleatoriamente al responder preguntas. A veces parece una tontería y el contenido que dice no está restringido.
Entonces, ¿por qué solo OpenAI ha hecho esto?
Porque tiene un padre maestro de oro: Microsoft.
Microsoft ha establecido un centro de datos específicamente en la sede de OpenAI para entrenar estos modelos. Entre ellos, los recursos de potencia informática consumidos cada año dan mucho miedo. Según los datos oficiales de OpenAI, GPT-3 utiliza decenas de miles de GPU para el entrenamiento, y el costo de la fotoelectricidad cuesta más de 12 millones de dólares estadounidenses . Por lo tanto, GPT no es un gran modelo de lenguaje de cualquier empresa Las pequeñas empresas pueden jugar, y solo los principales fabricantes de computación en la nube están dispuestos a continuar invirtiendo en el futuro incierto, por lo que es posible hacerlo.
ChatGPT
Entonces, lo que mencionamos anteriormente es GPT, no ChatGPT.
Esto se debe a que ChatGPT en sí mismo es equivalente a una extensión del modelo GPT Basado en el modelo GPT, una capa de aplicación creada por OpenAI permite que el modelo en sí mismo resuelva realmente algunos problemas y brinde más experiencia a los usuarios.

Lo más importante aquí es cómo hacer que GPT se parezca más a un ser humano, en lugar de generar contenido de texto como una máquina.
En este momento, es necesario utilizar el aprendizaje supervisado sobre la base del modelo pre-entrenado, porque el modelo hecho puramente por aprendizaje no supervisado no puede controlar si las cosas que genera son buenas o malas.
Para resolver este problema, OpenAI emplea a muchas personas para realizar una intervención manual, lo que equivale a generar manualmente algunos resultados de alta calidad. Estos ejemplos son equivalentes a la forma en que hablan los humanos reales, y estos datos se utilizan para ajustar el entrenamiento GPT3 , lo que da como resultado el modelo GPT3.5.
Este es el punto clave. Cuando se lanzó ChatGPT, utilizó el modelo GPT3.5 . Este modelo puede darle a ChatGPT la capacidad inicial de comprender las intenciones humanas. Sin embargo, la API del modelo 3.5 no se reveló en ese momento, y fue disponible en el mercado en ese momento. La API todavía es GPT-3, por lo que la única forma de experimentar el efecto del modelo GPT3.5 en ese momento era usar ChatGPT.

Cuando ChatGPT se ajuste y entrene mediante anotaciones manuales, se utilizará otro concepto del modelo GPT3.5, llamado aprendizaje de refuerzo de retroalimentación humana RLHF .
En términos simples, significa que cuando el modelo genera contenido, se utilizan seres humanos para calificar los resultados de salida, a fin de mejorar continuamente el modelo y hacer que la generación del modelo esté más en línea con las expectativas humanas.
Tenga en cuenta que la clave aquí es calificar el contenido, no juzgar directamente si es correcto o incorrecto. Esto se debe a que el resultado de la respuesta no se puede juzgar completamente por correcto o incorrecto.
No puede decir que la respuesta del modelo es incorrecta, solo puede decir que su respuesta no es lo suficientemente buena y el mecanismo de puntuación es muy crítico en este momento.
A través del mecanismo de puntuación, el propio modelo pensará, ¿por qué puntuaste mi respuesta con 7 puntos?, ¿hay algo mal en mi respuesta? En este momento, el modelo puede generar resultados más diversos. Por ejemplo, cuando la puntuación es baja, intentará generar diferentes resultados de respuesta para obtener una puntuación más alta .
El mecanismo de puntuación en este aprendizaje por refuerzo se implementa a través de un modelo de recompensa (versión pequeña de GPT) de OpenAI.
Suponga que para cualquier pregunta hay cuatro respuestas A, B, C y D, y los humanos necesitan calificar estas cuatro respuestas por separado.
Posteriormente, se ordenará de acuerdo con los resultados de la puntuación y, a continuación, los datos etiquetados se utilizarán para el entrenamiento para obtener un modelo de recompensa.
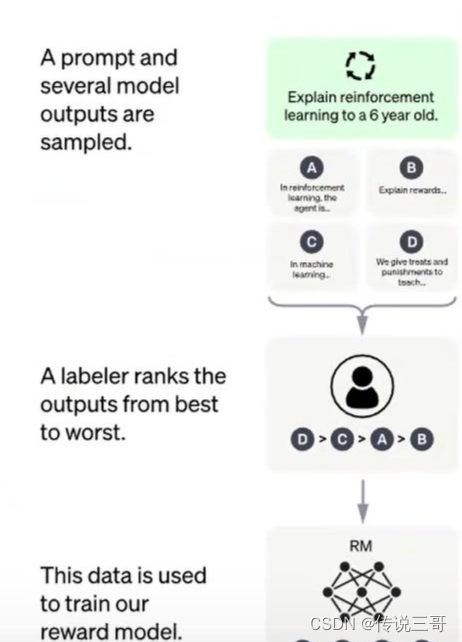
Y cuando se entrena este modelo de recompensa, el modelo GPT3.5 ajustado y este modelo de recompensa se utilizan para actualizar la estrategia de comportamiento mediante el aprendizaje por refuerzo, de modo que ChatGPT en su conjunto pueda comprender mejor las intenciones humanas, y el resultado es más en en consonancia con el contenido literal de las necesidades humanas.
Por ejemplo, después de que tenemos un modelo de recompensa, sacamos una pregunta para hacerle ChatGPT. En este momento, ChatGPT da un resultado de salida, que se pasará al modelo de recompensa. El modelo de recompensa dará una puntuación, y luego de acuerdo con El nivel de esta puntuación se usa para actualizar el modelo ChatGPT , y este método de actualización se llama PPO. No es necesario que entiendas esto. Se trata de matemáticas. Todo el mundo sólo necesita saber un proceso general.
Después de esta serie de capacitación continua, finalmente se formó el modelo GPT3.5. Al mismo tiempo, OpenAI también lanzó ChatGPT, una capa de aplicación que utiliza el modelo GPT3.5, en noviembre de 2022, lo que permite a los usuarios chatear con robots en páginas web. el robot puede responder preguntas, redactar texto, generar código, resumir y más. Y después de la experiencia de una gran cantidad de usuarios en todo el mundo, se descubre que ChatGPT no es como otras IA del pasado, y unas pocas palabras más revelarán sus fallas. ChatGPT puede estar casi cerca de las conversaciones humanas reales, así como la comprensión del lenguaje contextual, aplastando directamente a todos los productos similares anteriores en términos de experiencia , hasta ahora ChatGPT se ha vuelto popular en todo el mundo.
GPT-4
Y llegó el momento del 14 de marzo de 2023. OpenAI anunció un nuevo modelo multimodal a gran escala: GPT-4, que es mejor que la versión anterior GPT3.5 en términos de rendimiento general y precisión, y puede escribir mejor varios modelos. estilos de escritura , al mismo tiempo, también puede ayudar a los usuarios a ingresar imágenes para comprender la información en las imágenes. Además, en comparación con las 4096 palabras de ChatGPT, GPT-4 admite la entrada de texto de 25 000 palabras , lo que permite que GPT-4 realice tareas posteriores a partir de contenido de texto más largo, como artículos que solo podían analizar miles de palabras, pero ahora pueden analizar 2 palabras. artículos para escribir un informe resumido.

Complemento ChatGPT
Hasta hace dos días, el 24 de marzo de 2023, OpenAI lanzó la función de complemento ChatGPT, que permite que ChatGPT interactúe con las API definidas por el desarrollador . Esta actualización le dio directamente a ChatGPT la capacidad de usar otras herramientas y redes . Por ejemplo, solo podíamos pedir a ChatGPT algunas recomendaciones de hoteles, pero ahora podemos usar ChatGPT directamente para reservar hoteles , originalmente solo podíamos pedir datos antes del 21 de septiembre, porque el propio modelo de ChatGPT usa datos de Internet antes del 21 de septiembre. ahora, a través del complemento de navegación, ChatGPT puede acceder a la información más reciente de Internet basada en la API de búsqueda de Microsoft Bing , rompiendo así la limitación de los datos del modelo.

Después de que ChatGPT actualice la función del complemento, creo que no tomará mucho tiempo en el futuro y todos los métodos de interacción de aplicaciones existentes cambiarán.
Resumir
A lo largo de la historia de desarrollo de GPT, podemos encontrar que detrás de la explosión de ChatGPT está el resultado de los esfuerzos de innumerables investigadores y una gran cantidad de apoyo financiero. Muchas personas pueden sentirse asustadas y ansiosas por ChatGPT, pero ¿qué podemos hacer? La vida continuará, todo lo que podemos hacer es adoptar la tecnología y seguir aprendiendo.
