Introducción al trabajo de tesis
El paradigma dominante para la predicción de relaciones en los gráficos de conocimiento implica el aprendizaje y la manipulación de representaciones latentes ( es decir, incrustaciones ) de entidades y relaciones.
Sin embargo, estos métodos basados en incrustaciones no capturan explícitamente las reglas lógicas de composición detrás del gráfico de conocimiento y se limitan al entorno transductivo, donde se debe conocer el conjunto completo de entidades durante el entrenamiento.
En este artículo, proponemos GraIL , un marco de predicción de relaciones basado en redes neuronales gráficas que razona sobre estructuras de subgrafos locales con un fuerte sesgo inductivo para aprender semántica relacional independiente de entidades.

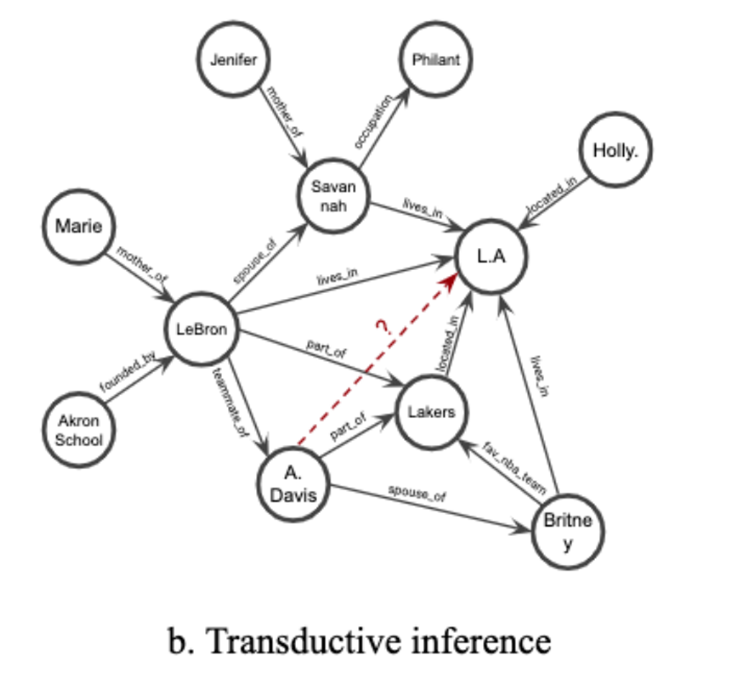
Como se muestra a la derecha, las incorporaciones de LeBron y A. Davis contendrán información de que ambos son parte del equipo de los Lakers , que luego se puede recuperar para predecir que son compañeros de equipo. Asimismo, cualquier persona estrechamente relacionada con los Lakers tendrá una alta probabilidad de vivir en Los Ángeles.
Los métodos basados en la incrustación han logrado un gran éxito al explotar este patrón de conectividad local y la homogeneidad.

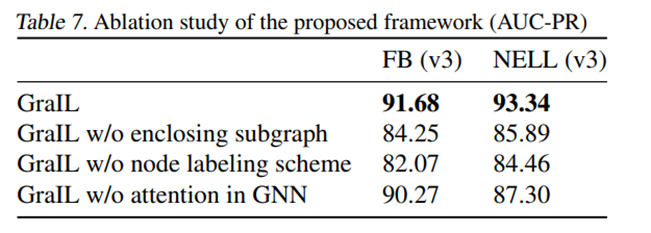
La idea clave de este documento es predecir la relación entre dos nodos a partir de la estructura del subgrafo alrededor de los dos nodos.Nuestro método se desarrolla en torno a la red neuronal gráfica ( GNN) , sin utilizar ningún atributo de nodo, para probar GraIL únicamente . de la estructura Capacidad de aprender y generalizar.
Dado que siempre solo recibe información estructural ( es decir, la estructura del subgrafo y las características del nodo estructural ) como entrada, la única forma en que GraIL puede realizar la tarea de predicción de relaciones es aprender la semántica estructural detrás del gráfico de conocimiento.
La tarea general es puntuar un triplete (u , rt , v) , es decir, predecir la posibilidad de una posible relación rt entre un nodo principal u y un nodo final v en un KG , donde nos referimos a los nodos u y v como nodos objetivo , y llame a rt la relación de destino. Nuestro enfoque para anotar tales triples se puede dividir ampliamente en tres subtareas ( que detallamos a continuación ):
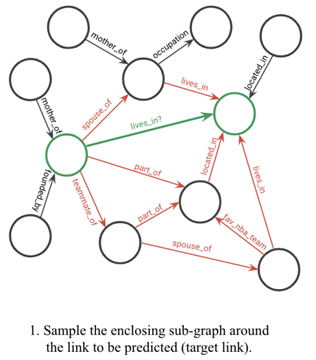
( i ) Extraiga subgrafos cerrados alrededor del nodo de destino.
(ii) Etiquete los nodos en el subgrafo extraído.
(iii) Puntúe los subgráficos etiquetados usando GNN .
Detalles del modelo : extracción de subgráficos
Paso 1 : Extracción de subgrafos . Presumimos que la vecindad del grafo local de un triplete particular en el KG contendrá la evidencia lógica necesaria para inferir las relaciones entre los nodos de destino. En particular, asumimos que una ruta que conecta dos nodos de objetivos contiene información que puede implicar una relación de objetivos. Por lo tanto, como primer paso, extraemos un subgrafo cerrado que rodea el nodo de destino.
Defina un subgrafo cerrado entre los nodos u y v como el gráfico inducido de todos los nodos que ocurren en el camino entre u y v , que viene dado por la intersección de los vecinos de los dos nodos de destino y el proceso de poda posterior.
(Tenga en cuenta que ignoramos las orientaciones de los bordes al extraer subgráficos cerrados. Sin embargo, al pasar mensajes con redes neuronales gráficas, la orientación se conserva, un punto que se revisa más adelante. Además, en los subgráficos extraídos se agregó la tupla objetivo / borde ( u , rt , v) para habilitar el paso de mensajes entre dos nodos de destino.)
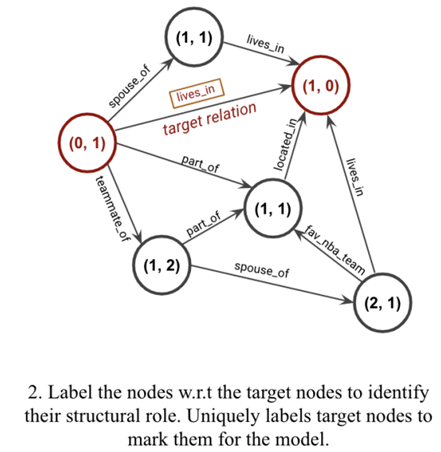
Detalles del modelo - Etiquetado de nodos
Paso 2 : Etiquetado de nodos . Los GNN requieren una matriz de características de nodo X∈R|V|×di como entrada, que se utiliza para inicializar el algoritmo de paso de mensajes neuronales. En el subgrafo alrededor de los nodos u y v , cada nodo i se etiqueta como una tupla (d( i , u) , d( i , v)) , donde d( i , u) representa la diferencia entre los nodos i y u . distancia más corta entre , sin contar ningún camino a través de v ( lo mismo es cierto para d( i , v) ) . Esto captura la posición topológica de cada nodo en relación con el nodo de destino y refleja su función estructural en el subgrafo. Los dos nodos de destino u y v están etiquetados de forma única como (0,1) y (1,0) para que el modelo los reconozca.
Entonces, la característica del nodo es [one-hot(d( i , u))⊕ one-hot(d( i , v))] , donde ⊕ representa la concatenación de dos vectores.
Tenga en cuenta que la dimensionalidad de las características de los nodos construidas de esta manera está limitada por el número de saltos considerados al extraer subgrafos cerrados.
Detalles del modelo - Puntuación GNN
Paso 3 : Puntuación GNN . El paso final en nuestro marco es usar un GNN para calificar la probabilidad de una tupla (u , rt , v) dada G( u,v,rt ) , extrayendo y etiquetando un subgrafo alrededor del nodo de destino. Actualizamos iterativamente las representaciones de los nodos combinando las representaciones de los nodos con agregaciones de las representaciones de sus vecinos .

donde akt es el mensaje agregado de los vecinos, hkt denota la representación potencial del nodo t en el nivel k y N(t) denota el conjunto de vecinos inmediatos del nodo t .
La representación de nodo potencial inicial h0i para cualquier nodo i , inicializada en las características del nodo Xi construidas de acuerdo con el esquema de etiquetado descrito en el paso 2 .
Inspirándonos en R-GCN multirelacional ( Schlichtkrull et al. , 2017) y atención marginal, definimos la función de agregación como:
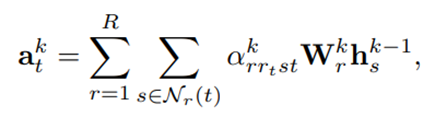
Nr(t) denota los vecinos salientes inmediatos del nodo t bajo la relación r
Wrk es la matriz de transformación para propagar mensajes en la capa k en la relación r
Α rrtst es el peso de atención del borde en la capa k correspondiente al borde que conecta los nodos s y t a través de la relación r
Este peso de atención es una función del nodo de origen t , el nodo vecino s , el tipo de borde r y la relación de destino rt que se va a predecir
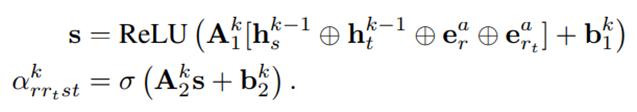
hks y hkt denotan las representaciones de nodos latentes de los respectivos nodos en la capa k de GNN , y ear y eart denotan las incrustaciones de atención aprendidas de las respectivas relaciones.
La función COMBINE que produjo los mejores resultados también es de la arquitectura R-GCN :
![]()
Usando la arquitectura GNN descrita anteriormente , obtenemos representaciones de nodos después del paso de mensajes de capa L. Se obtiene una representación de subgrafo de G( u,v,rt ) promediando la agrupación de todas las representaciones de nodos potenciales :
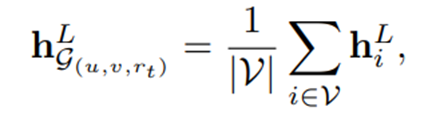
Finalmente, para obtener el puntaje de probabilidad para el triplete (u , rt , v) , concatenamos cuatro vectores : la representación del subgrafo ( hLG ( u,v,rt )) , la representación latente del nodo objetivo ( hLu y hLv ) , y las incorporaciones relacionales de destino aprendidas ( ert ) , y pasar estas representaciones conectadas a través de una capa lineal :
![]()
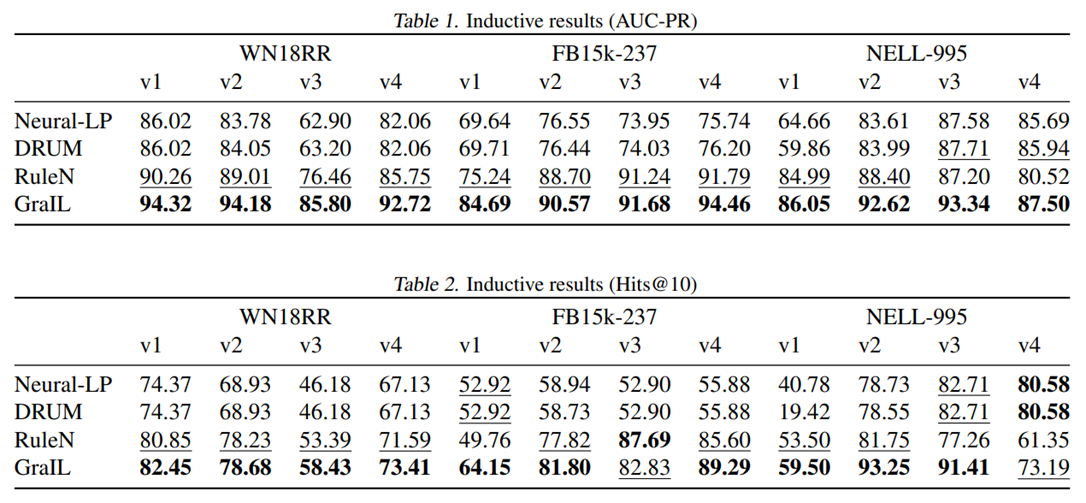
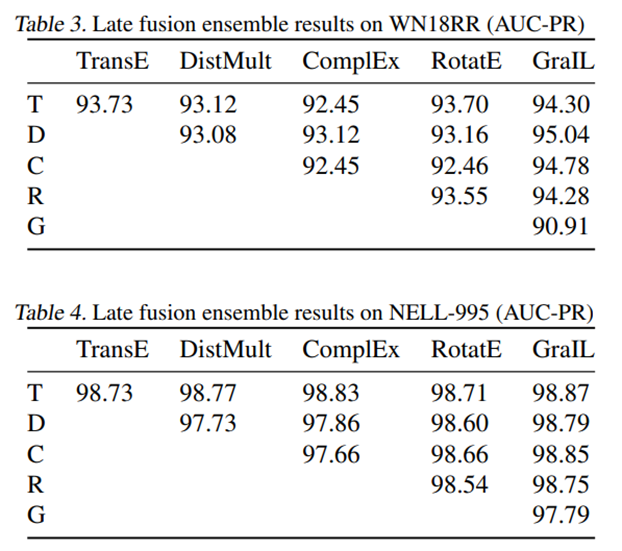
Resultados experimentales